最全MPC教材!MPC官方introduction~
1 Introduction
MPC:一个组共同计算,不泄露隐私输入。参与者在一个函数上进行计算,然后用MPC协议共同计算函数的输出,不泄露秘密输入。
外包计算和多方计算是安全计算的两种主要模式,它们的核心目标都是在保护数据隐私和保证计算结果正确的前提下完成计算任务。
1.1 Outsourced Computation
外包计算:一方拥有数据,想要得到该数据的计算结果。第二方以加密的形式接收和存储数据,在加密后的数据上进行计算,将加密后的结果提供给数据所有者,不能了解关于输入数据、中间值或最终结果的任何信息。
同态加密(HE)可以在加密数据上进行计算,是外包计算的一个自然的原语。全同态加密(FHE)的要求:为了能对加密数据执行任意计算,加密方案必须支持一组在计算上“完备”(Turing-complete)的操作。
FHE和MPC是MPC的两个不同方面,但也提供了相似的函数,可以将FHE适配到MPC当中。
对于高带宽环境,例如设备在数据中心内连接,MPC比FHE性能好得多。未来的 FHE 算法会变得越来越高效,计算成本会不断降低。随着网络越来越拥堵,或者在移动网络、物联网等带宽受限的环境下,带宽资源会比计算资源(如CPU、GPU算力)更加宝贵和昂贵。如果这两个条件成立,FHE 这种计算密集、通信较少的方案,在未来很多应用中可能会追上甚至超过 MPC,成为一个很有竞争力的选项。
1.2 Multi-Party Computation
混淆电路是一种生成协议,可以用来计算任何可以用固定大小电路表示的离散函数。
MPC的一个重要的子领域侧重于特殊的函数,比如PSI。特殊函数的传统协议会比最好的生成协议还要高效。
1.3 MPC Applications
安全拍卖、投票、机器学习安全
1.3.1 Deployments
关键问题:如何建立对协议执行系统(即运行多方计算协议的软硬件)的信任,如何理解可以从MPC(多方计算)公开的输出结果中推断出哪些敏感信息,如何让那些负责保护敏感数据、但又缺乏密码学技术背景的决策者,能够理解参与MPC所带来的安全影响。
1.4 Overview
我们主要讨论生成MPC技术,着重于两方的场景,并且强调只有一方恶意的场景。
2 Defining Multi-Party Computation
2.1 Notations and Conventions
MPC:Secure Multi-Party Computation
SFE:Secure Function Evaluation
SFE和MPC通常表示一种东西,SFE也可以用于只有一方将输入提供给函数,被外包服务器评估的场景。
2PC:两方MPC
计算安全性 (Computational Security):指的是能够抵御计算能力有限的攻击者的安全。具体来说,这里的攻击者被限制在“多项式时间”内,意味着他们只能在现实的时间内完成计算,无法解决极其困难的数学问题(如大数分解)。
信息论安全性 (Information-Theoretic Security):指的是能够抵御计算能力无限的攻击者的安全。这种安全级别也被称为“无条件安全”,它不依赖于任何未解决的数学难题,即使攻击者拥有最强大的超级计算机,也无法破解。
2.3 Security of Multi-Party Computation
2.3.1 Real-Ideal Paradigm
ideal world:有完全可信方计算函数,敌手可以控制任何参与方,但不能控制可信方。敌手除了最终结果之外学不到任何其他信息,因为这是它唯一收到的消息。诚实方收到的输出结果都是一致且合法的。敌手对自己输入的选择与诚实方的输入是相互独立的。
尽管理想世界易于理解,但由于存在一个完全可信的第三方,它终究只是一个假想场景。我们使用理想世界作为衡量和评判一个真实协议安全性的基准。
real world:没有可信方,所有参与方都使用一个协议相互通信。敌手可以“腐化”参与方——如果在协议开始时就被腐化,就相当于该参与方本身就是敌手。根据不同的威胁模型,被腐化的参与方可能会继续遵循协议规定,也可能会任意偏离协议做出任何行为。
如果一个敌手在真实世界中能达成的任何效果,都有一个对应的敌手可以在理想世界中达成同样的效果,那么我们就认为这个真实世界的协议是安全的。换句话说,一个协议的目标就是在真实世界中(在给定一组假设的前提下),提供与理想世界中等价的安全性。
2.3.2 Semi-Honest Security
“半诚实敌手”指的是那种会“腐化”参与方,但依然遵循协议规定的敌手。换句话说,被腐化的参与方会诚实地执行协议,但他们可能会试图从收到的其他参与方的消息中,尽可能多地学习信息。需要注意的是,这可能涉及多个被腐化的参与方相互“勾结”(colluding),将他们各自看到的信息(view)汇集在一起以获取更多情报。半诚实敌手也被认为是“被动的”(passive),因为除了通过观察协议执行过程来试图学习私密信息外,他们不会采取任何其他行动(例如,发送虚假消息或中止协议)。半诚实敌手通常也被称为“诚实但好奇的”(honest-but-curious)。
在理想世界中,敌手的视图只包含发送给可信方T的输入和从T那里收到的输出。因此,一个理想世界的敌手必须能利用这些有限的信息,去生成一个看起来像是真实世界视图的东西。我们将这样的理想世界敌手称为“模拟器”(simulator),因为它在理想世界中生成了一个“模拟的”真实世界视图。证明这样一个模拟器的存在,就等于证明了:任何敌手在真实世界中能做到的事情,在理想世界中也同样能做到(因此,真实协议是安全的)。
2.3.3 Malicious Security
恶意(亦称主动)攻击者可能导致受损方任意偏离既定协议,企图破坏安全性。恶意攻击者在分析协议执行时拥有与半诚实攻击者同等的权限,但可在协议执行过程中采取任意行动。这涵盖了能够控制、操纵并在网络上任意注入消息的攻击者。
应对恶意敌手(即不遵守协议、任意行动的攻击者)时,密码学安全证明(“真实/理想”范式)需要解决的两个核心问题:
- 对诚实方输出的影响:当敌手是恶意的,他们可以不遵守协议,这可能会破坏或篡改诚实参与方的计算结果。例如,一个恶意攻击者可能导致两个诚实方得到完全不同、互相矛盾的输出,而在理想世界中这是绝不可能发生的。因此,在定义恶意安全时,我们必须重点保证诚实方的输出是正确和一致的。至于被腐化的恶意参与方,我们无法对他们的输出做任何保证,因为他们可以任意伪造自己的结果。
- 输入的“提取”:在真实世界中,一个恶意敌手的“输入”并非一个明确的值,而是其一整套复杂的攻击策略。这就带来一个问题:在理想世界中进行模拟时,我们应该告诉可信方 T 这个恶意敌手的“输入”到底是什么?解决方法是,我们要求模拟器(Simulator) 必须能够从真实世界敌手的复杂行为中,“提取”出一个等效的输入值。这个被提取出的输入,必须能在理想世界中产生和真实世界攻击同样的效果。这个过程被称为“提取”,它是证明恶意安全的关键,因为它表明了任何真实世界的攻击都可以在理想世界中被“解释”和“复制”。
reactive functionalities:在理想世界中,与函数的交互只包含一个回合:输入,然后输出。我们可以将函数的行为进行推广,使其能与参与方进行多回合的交互,并在回合之间保持其自身的私有内部状态。这样的函数被称为“反应式”的(reactive)。
output fairness:在任何需要来回通信的双方协议中,总会有一方比另一方先算出最终结果。如果先算出结果的一方是恶意的,他可以在得到自己想要的结果后,立刻中止协议(比如不发送最后一条消息),从而让诚实的另一方永远得不到结果。这被称为“提前中止”攻击。这种行为在“理想世界”中是不允许的。理想世界遵循“输出公平性”原则,即要么所有人都得到输出,要么所有人都得不到。绝不允许出现攻击者单方面获利而诚实方一无所获的情况。然而,并非所有计算问题都能设计出完美保证“输出公平性”的协议。对于某些问题,这种攻击是理论上无法完全避免的。
security abort:更弱一点的性质,使理想函数有如下改动:允许函数知道哪些是腐化的参与方。函数的行为被修改为轻微的“反应式”:在所有参与方都提供了输入后,函数会计算出结果,并只将结果先发送给腐化的参与方。函数会等待来自腐化方的“发送”(deliver)或“中止”(abort)指令。如果收到“发送”指令,函数就会将输出发送给所有诚实方。如果收到“中止”指令,函数则会向所有诚实方发送一个特殊的中止符号。
在这个修改后的理想世界中,攻击者被允许在诚实方之前获取输出结果,并阻止诚实方接收任何输出。但需特别注意的是,诚实方是否终止操作只能取决于攻击方的输出结果。尤其需要强调的是,若诚实方的终止概率取决于其自身输入,则将构成安全漏洞。
在对于恶意敌手的安全性讨论中,敌手对于诚实参与方的输出发送存在控制,输出安全性不能被满足。
adaptive corruption:攻击者可能在协议执行过程中选择要破坏的参与方,其决策可能基于交互过程中获取的信息。对于适应性腐坏的安全可以模拟为真实-理想模式。
2.3.4 Hybrid Worlds and Composition
理想世界只包含一个函数,现实世界会包含其他函数(如用来发送信息给其他参与方)。
一些非常自然的模型定义方式无法保证安全协议的组合性,实现这种有保证的组合性的标准方法,是使用Canetti(2001)提出的“通用组合性”(Universal Composability, UC)框架。UC框架在我们之前勾勒的安全模型之上,增加了一个额外的实体,称为“环境”(environment),这个“环境”同时存在于理想世界和真实世界中。“环境”的作用是捕捉协议执行的“上下文”(context)(例如,我们正在分析的这个协议,可能只是某个更庞大协议中的一个小步骤被调用)。“环境”负责为诚实方选择输入并接收他们的输出。它还可以与敌手进行任意的交互。
同一个“环境”同时存在于真实世界和理想世界中,而它的“目标”就是判断自己当前到底身处于真实世界还是理想世界。
在UC框架中,可以考虑将敌手A吸收到环境Z中,从而剩余部分即为所谓的“虚拟对抗者”(其仅按Z的指令转发协议消息)。
模拟器必须是直线模拟器:每当环境需要发送协议消息时,模拟器必须立即以模拟响应进行回馈。直线模拟器必须一次性生成模拟记录,而先前定义中允许无限制生成模拟记录或消息。假设协议中使用的其他基本组件(如第2.4节所述的不经意传输和承诺机制)均具备UC安全性,则本书所述的恶意安全协议均满足UC安全性要求。
2.4 Specific Functionalities of Interest
不经意传输(OT):理论上等同于MPC,用OT可以不用任何附加条件构造出MPC,MPC中也可以得到OT。1 out of 2 OT中接收方R得到比特x_b,无法得到有关x{1-b}的任何信息。发送方S无法得到任何信息。
Commitment:发送方承诺一个秘密值,之后再揭示给接收方。接收方在发送方揭示前无法得到任何信息(hiding),接收方在承诺之后无法修改值(binding)。
Zero-Knowledge Proof:证明方向验证方证明自己知道x使得C(x)=1,并且不泄露关于x的信息,C是公共的谓词。这种具体变体更精确地说是一种零知识论证。
3 Fundamental MPC Protocols
所有的方法都可以视作输入数据的秘密分享以及份额上的计算。
一些常见的生成方法(半诚实敌手):Yao’s GC、GMW、BGW、BMR、GESS。这些方法都可以由不经意传输构造。
3.1 Yao’s Garbled Circuits Protocol
该协议通常被视为性能最优,我们所探讨的诸多协议均基于姚的GC协议构建。尽管其通信复杂度并非已知最佳,但它能在恒定轮次内运行,并避免了诸如GMW(详见第3.2节)等方案中随电路深度增长而增加的通信轮次所导致的高昂延迟成本。
3.1.1 GC Intuition
P1在X中选x,P2在Y中选y,计算F(x,y)。
Function as a look-up table:当输入范围很小时,可以迭代所有可能的输入对(x,y)。F可以视作查找表,有|X|·|Y|行,T{x,y}=<F(x,y)>。
一个简化的视角:P1将会通过为每一个可能的输入x和y都分配一个随机选择的强密钥,来加密整个查找表T。也就是说,对于每一个x∈X和每一个y∈Y,P1都会选择密钥 k_x和 k_y。然后,P1会用密钥k_x和k_y共同加密T中的每一个元素T{x,y}(枚举每一个元素,P1并不知道y的具体值),并将加密后的(且随机打乱顺序的)整个表发送给P2。我们的任务就是让P2能够(且只能)解密出与双方输入(x, y)相对应的那一个条目T{x,y}。这通过让P1将密钥k_x和 k_y发送给P2来实现。P1知道自己的输入x,因此它直接将密钥k_x发送给P2。而k_y则是通过一次|Y|选1的不经意传输来发送给P2的。一旦P2收到了k_x和k_y,它就可以用这两个密钥解密T{x,y},从而获得最终输出F(x,y)。
重要的是,P2无法获得任何其他信息。这是因为P2只拥有唯一一对密钥,这对密钥只能用来打开(解密)唯一一个表格条目。我们特别强调,任何单个密钥(无论是k_x 还是k_y)自身都不能用于获得部分解密信息,甚至不能用来判断某个加密条目是否使用了这个密钥,这一点至关重要。
Point-and-Permute:P2是如何知道解密哪一行的?最简单的方法:在T的加密元素中编码一些额外信息。例如P1在每一行T的末尾加一串0,如果解密错误的行,则结果的结尾不是那一串0。但这种方法对P2是不高效的。一种更好的方法是“标定并置换”(point-and-permute),思路是用第一个密钥的最后log|X|个比特和第二个密钥的最后log|Y|个比特解释为一个指针,这个指针指向随机打乱后的表T中的某个位置,用于存放对应的加密条目。为了避免在分配表格位置时发生冲突(collision),P1必须确保所有k_x的指针部分互不相同,所有列密钥k_y 的指针部分也互不相同;这可以通过多种方式实现。严格来说,为了达到相应的安全级别,密钥的密码学长度必须保持不变。因此,参与方并不是将密钥的一部分“看作”指针,而是在保持原有密钥长度不变的同时,将这些指针位“附加”到密钥上。简易理解:具体怎么乱序呢?这里给出了一个绝妙的答案:让密钥本身来决定每个加密条目的最终位置。
在接下来的讨论中,我们假设评估者知道解密哪一行。是否使用point-permute视上下文而定。
Managing look-up table size:上述方案效率较低,与F的域的大小成线性关系。下一个思路是,将函数F表示为一个布尔电路C,然后使用大小为4的查找表来计算每一个门。和之前一样,P1负责生成密钥并加密这些查找表,而P2则负责使用这些解密密钥,且P2并不知道每个密钥对应的真实含义。然而,在这种设定下,我们不能揭露中间门的明文输出。这个问题可以通过让门的输出本身也变成一个密钥来解决,而这个新密钥所对应的真实值对于计算方P2来说是未知的。
对于电路C中的每一根导线 w_i(wire),P1都会为其分配两个密钥k_i0 和k_i1,分别对应了这根导线上的两种可能值(0和1)。我们将这些密钥称为“导线标签”(wire labels),而将导线上的明文值(0或1)简称为“导线值”(wire values)。在(协议)执行过程中,根据计算的输入,每一根导线都会关联上一个特定的明文值和一个对应的导线标签。我们称之为“激活值”(active value)和“激活标签”(active label)。计算方(evaluator)只能知道“激活标签”,但既不知道它所对应的真实值,也不知道那另一个“未激活标签”(inactive label)。
P1会遍历电路C,为每一个拥有输入导线w_i和w_j、输出导线为w_t 的门G,构建如下的加密查找表(也称“混淆表”):
第一行:用输入导线i和j对应值0的两个标签(k_i0,k_j0)作为密钥,加密输出导线t在输入为(0,0)时应有的标签k_t^G(0,0)。第二到四行是(0,1),(1,0),(1,1)。
查找表中的每一个单元格,都加密了该门计算出的输出结果所对应的(输出)导线标签。至关重要的是,这使得计算方P2能够在加密状态下获得电路内部导线上的中间“激活标签”,并用它们来继续计算函数F,而自始至终都不知道这些标签的任何语义值(即它们代表0还是1)。
P1会随机打乱每一个查找表(通常称为“混淆表”或“混淆门”)中条目的顺序,然后将所有的表都发送给P2。此外,P1还会将与双方的输入值相对应的所有输入导线的“激活标签”(active labels)发送给P2。对于那些属于P1自身输入的导线,P1直接将对应的导线标签(密钥)发送给P2即可。而对于那些属于P2输入的导线,这个发送过程则需要通过“2选1不经意传输”(1-out-of-2 Oblivious Transfer)来完成。
在这种4行混淆表的例子中,“指向并置换”技术尤其简单高效——每个输入导线的标签需要一个“指针位”,因此P2手上的两个输入标签总共提供了两个指针位,P2可以根据这两个指针位的组合来定位并解密混淆表四个条目中正确的那一个。最终,P2完成了对整个混淆电路的计算,并获得了电路输出导线所对应的密钥(激活标签)。这些输出标签可以被发送给P1进行解密,从而完成对函数F的私有计算。
我们注意到,P2将输出标签发送给P1解密的这个步骤可以被省略,从而节省一轮通信。
要实现这一点,P1只需在发送混淆电路时,附加上输出导线的“解码表”(decoding tables)即可。解码表就是一个简单的映射表,它指明了每一个输出导线上的每一个标签所对应的语义(即其对应的明文值)。这样,当P2获得最终的输出标签后,它就可以直接查询这个解码表,从而获得明文输出结果。
从直觉来讲,这种基于电路的构造在半诚实模型中是安全的。如果P1是腐坏的,P1除了OT,无法在协议中接收到任何信息。如果P2是腐坏的,安全性的关键可以归结为一个观察:作为计算方的P2,对于同一根导线,永远无法同时看到其对应的两个标签。这一点对于输入导线来说显然成立,并且通过归纳法,它对所有中间导线也成立(因为计算方只知道门的每根输入导线上的一个标签,所以它只能解密混淆门中的一个密文)。由于P2不知道导线标签和明文值之间的对应关系,它对所有导线上的明文值一无所知——除了最终的输出导线,因为P1明确提供了输出标签和值之间的关联。为了模拟P2的视图,模拟器SimP2会为每一根导线都选择一个随机的“激活标签”,然后将每个混淆门中另外三个“未激活”的密文模拟为虚拟的垃圾密文,并生成相应的解码信息,使得最终的激活输出标签能够被正确地解码为函数的输出结果。
3.1.2 Yao’s GC Protocol
遵循“指向并置换”(point-and-permute)技术,每一个导线标签都会被附加一个“指针位”p_i。由于这些指针位是随机选择的,它们不会泄露任何信息,但它们允许计算方(evaluator)根据其手上两条输入导线的“激活标签”的指针位,来确定应该解密混淆表中的哪一行。




3.2 Goldreich-Micali-Wigderson(GMW) Protocol
在Yao’s GC中,激活导线值的秘密分享是由一方(生成这)拥有两个可能的导线标签,另一方(计算者)拥有激活标签来完成的。在GMW协议中,导线值的秘密共享更为直接:参与者持有导线当前值的可加性份额。GMW通常多于两方。
3.2.1 GMW Intuition
过程:对于每一个输入比特x_i,P1生成随即比特r_i,并将所有的r_i发送给P2。P1通过将每个xi的份额设置为x_i ⊕ r_i,在P1和P2之间实现对每个x_i的秘密共享。对称地,P2为其输入y_i生成随机位掩码,并将掩码发送给P1,以类似方式对其输入进行秘密共享。
P1和P2依次对C的门进行计算。考虑门G的输入导线为w_i和w_j,输出导线为w_k。输入导线被分成两个份额,使得s_x1⊕s_x2=w_x。令P1拥有w_i和w_j的份额s_i1和s_j1,P2拥有s_i2和s_j2。
异或门:P1计算s_k1=s_i1⊕s_j1,P2计算s_k2=s_i2⊕s_j2。s_k1⊕s_k2=(s_i1⊕s_j1)⊕(s_i2⊕s_j2)=(s_i1⊕s_i2)⊕(s_j1⊕s_j2)=v_1⊕v_2。
计算与门需要交互,并且使用了1-out-of-4 OT基础原语。从P1的角度来看,它的份额s_i1和s_j1是固定的,P2有两个布尔输入份额,共有四种可能。如果P1知道P2的份额,那么在加密下计算门就会很平凡:P1重构激活输入值,计算激活输出值,秘密分享给P2。但P1的行为如下:为P2的每一个可能输入准备一个秘密份额,然后运行1-out-of-4 OT去传输相应的份额。令
KaTeX parse error: Undefined control sequence: \and at position 47: …=(s_i^1⊕ s_i^2)\̲a̲n̲d̲ ̲(s_j^1⊕ s_j^2)
作为计算门输出值的函数。P1选择一个随机的掩码比特r,计算OT秘密表T_G,第一行为r⊕S(0,0),接下来每一行为(0,1),(1,0),(1,1)。然后运行1-out-of-4 OT,P1用表中的行作为四个秘密输入,P2用两个秘密份额比特去选择对应的行。
Generalization to more than two parties:推广到多方的场景。P_j随机选择r_i,然后发送给每个P_i。P_1,P_2……P_n计算C的每个门G如下:
对于异或门,如两方的场景,不需要额外的交互,正确性和安全性同样被保证。
对于与门,c=a^b。令a_1,……,a_n,b_1,……,b_n分别表示参与方拥有的a,b,考虑
KaTeX parse error: Undefined control sequence: \and at position 5: c=a\̲a̲n̲d̲ ̲b=(a_1⊕……⊕a_n)\…
每个参与方本地可以计算a_jb_j。每一对参与方可以利用两方的GMW计算a_ib_j。最后全都异或到一起,得到a^b。
3.3 BGW protocol
BGW协议由加法、乘法和常数轮除法门组成,依赖于Shamir秘密分享。
对于域 F 中的一个值v,我们用 [v] 来表示所有参与方共同持有v的Shamir秘密份额。一个“分发者”(dealer)会选择一个次数至多为 t 的随机多项式P(x),并使其满足 。然后,每一个参与方Pi会持有P(i)这个值作为他自己的份额。我们将 t 称为分享的“门限值”(threshold),任何t个或更少的份额都无法泄露关于秘密值v的任何信息。BGW协议的一个“不变量”(invariant)是:对于算术电路中的每一根导线w,所有参与方都共同持有着该导线上真实值v_w的一个秘密分享[v_w] 。
input wires:对于属于参与方 Pi 的输入导线,该参与方知道该导线上明文值 v,并将 [v] 的份额分发给所有参与方。
addition gate:输入导线为a,b,输出导线为c。参与方共同持有[v_a]和[v_b],想要得到[v_a+v_b]。假设对应于多项式p_a和p_b,每方Pi本地计算份额p_a(i)+p_b(i),结果是每一方拥有p_c(x)=p_a(x)+p_b(x)的一个点。p_c(x)的次数不超过t,且p_c(0)=p_a(0)+p_b(0)=v_a+v_b。
multiplication gate:每一方可以乘自己的份额,拥有q(x)=p_a(x)·p_b(x)的一个点,但q(x)的次数不超过2t。接下来的目标是得到q(0)的秘密分享,并且在正确的门限值下。次数降低步骤如下:
- 每一个参与方Pi都会生成并分发自己的q(i)的一个门限为t的秘密分享[q(i)]。为了简化标记,我们不给生成这些新份额的多项式命名,只需记住每一个参与方Pi都会选择一个次数至多为t的多项式,并使其常数项等于自己的份额q(i)。
- 参与方计算[q(0)],使用本地计算。涉及对秘密份额进行加法和常数乘法运算。因为[q(i)]的门限值为t,所以[q(0)]的门限值为t。
BGW协议中的乘法门需要交流/交互,因为2t+1≤n,所以BGW满足t腐化安全性,即诚实大多数(2t<n)。
output wires:对于输出导线a,参与方最终得到秘密份额[v_a],每一方将这个值的份额广播给其他参与方。
3.4 MPC From Preprocessed Multiplication Triples
如何在将大部分的交互移到预处理阶段?
Intuition:Beaver triple(multiplication triple):秘密分享值[a],[b],[c],a和b随机选取,c=ab。在离线阶段,Beaver triple可以以很多种方式生成,比如在随机输入上简单运行BGW乘法子协议。
考虑乘法门,输入导线为a,b,参与方拥有秘密份额[v_a],[v_b],想要得到v_a和v_b的乘法结果。
-
本地计算[v_a-a],公开d=v_a-a。
-
本地计算[v_b-b],公开e=v_b-b。
-
观察以下式子
vavb=(va−a+a)(vb−b+b)=(d+a)(e+b)=de+db+ae+ab=de+db+ae+c v_av_b=(v_a-a+a)(v_b-b+b)=(d+a)(e+b)=de+db+ae+ab=de+db+ae+c vavb=(va−a+a)(vb−b+b)=(d+a)(e+b)=de+db+ae+ab=de+db+ae+c因为d和e是公开的,参与方拥有[a],[b],[c]的秘密份额,所以可以计算出
[vavb]=de+d[b]+e[a]+[c] [v_av_b]=de+d[b]+e[a]+[c] [vavb]=de+d[b]+e[a]+[c]
使用这项技术,乘法可以化为两个公开值以及本地计算。总的来说,每一个参与方必须公开两个域中的元素,对比普通的BGW协议公开n个元素。存在批量生成三元组的方法,每个三元组的摊销成本为美方固定数量的域元素。
Abstraction:Beaver三元组将BGW协议中的Shamir秘密分享细节抽象化。
- 同态加法:给定[x]、[y]和公共值z,参与方可以不需要交互得到[x+y],[x+z],[xz]。
- 公开:给定[x],参与方可以选择揭示x给所有的参与方。
- 隐私:敌手从[x]中无法得知x的信息。
- Beaver三元组:对于每个乘法门,参与方拥有随机三元组[a]、[b]、[c],c=ab。
- 随机输入工具:对于每个属于参与方Pi的输入导线,参与方有随机数[r],r只被Pi所知。当Pi选择导线的输入值为x时,可以公开δ=x-r,于是参与方可以通过同态性之计算[x]=[r]+δ。
Instantiations:Shamir秘密共享方案构造出抽象共享机制[·],针对t<n/2敌手,满足以上所有属性。另一个合适的方法是域F上的简单加法分享。在加法分享中,[v] 意味着每个参与方Pi持有v_i,且所有份额v_i的总和=v。该机制满足同态性之,且能抵抗n-1个半诚实腐化方。当使用比特域F={0,1}时,我们得到GMW协议的一个离线/在线变体,因为此时的域运算对应于AND和XOR。当然,也可以使用任意的域F,从而得到一个用于算术电路的GMW版本。
3.5 Constant-Round Multi-Party Computation:BMR
3.5.1 BMR Intuition
基本BMR理念是执行分布式GC生成,确保没有任何单一参与方(甚至所有参与方的真子集)知晓GC生成的秘密——标签分配及其对应关系。这个混淆电路的生成过程,可以利用MPC对所有门并行地完成。具体来说,可以通过首先(并行地)独立生成所有导线标签,然后独立且并行地生成所有混淆表来实现。由于可以对所有门/导线进行并行处理,混淆电路的生成过程与被计算电路CGEN的“深度”(depth)无关。因此,用于生成混淆电路的电路 ,对于任何被计算的电路 CGEN 来说,都是“常数深度”的(一旦安全参数κ固定)。最终,即使参与方们执行的用于计算CGEN的MPC协议本身轮数依赖于CGEN的深度,整个BMR协议的通信总轮数也依然是常数轮。通俗来讲,就是大家一起当生成电路的P1(即Yao’s GC两方中的一方)。
这次MPC计算的输出——即通过安全计算CGEN所产生的混淆电路(GC)——可以被发送给一个指定的参与方(例如P1)。然后,该参与方会像在Yao’s GC中那样对这个混淆电路进行计算。这里最后一个技术细节是,如何将“激活的输入标签”(active input labels)交付给P1。实现这一点有多种方法,具体取决于MPC生成混淆电路的确切过程。也许,在概念上最简单的理解方式是,将这个交付过程也看作是混淆电路生成计算的一部分。
在MPC内部计算混淆行加密函数(以伪随机函数或哈希函数形式实现)会导致高成本,可以将计算从MPC内部提取出来,转而由各方在本地执行。
然而,我们还没有完全解决问题。回想一下,混淆电路的计算方P1将会重构出“激活标签”。一个细心的读者会注意到,由于P1知道自己贡献的那部分“子标签”,这将使其能够识别出“激活标签”所对应的明文值,从而破坏了安全保证。
解决方案是,让每一个参与方Pj为每一根导线w_a都额外贡献一个“翻转位”(flip bit)f_aj。所有n个翻转位的异或总和f_a,决定了哪个明文比特对应于导线标签w_a^v。这些翻转位将作为额外的输入,参与到生成混淆电路的MPC计算中。现在,由于加入了翻转位,任何参与方的子集都无法知道最终的导线翻转位是多少。因此,即使计算方识别并匹配了自己贡献的子标签,也无法将标签与明-文值对应起来,也无法完整地计算出“未激活标签”。




3.6 Information-Theoretic Garbled Circuits
Yao’s GC和GMW展示了MPC中秘密共享的两种方法,本节展示第三种方法,即不在参与方之间进行秘密共享,而在导线之间。
我们在此介绍Kolesnikov(2005)提出的“门计算秘密分享”(Gate Evaluation Secret Sharing, GESS)方案,这是混淆电路(GC)在信息论安全领域最有效的对应方案。Kolesnikov的主要成果是一个用于布尔公式F的两方协议,其通信复杂度约等于各叶子节点深度的平方和。
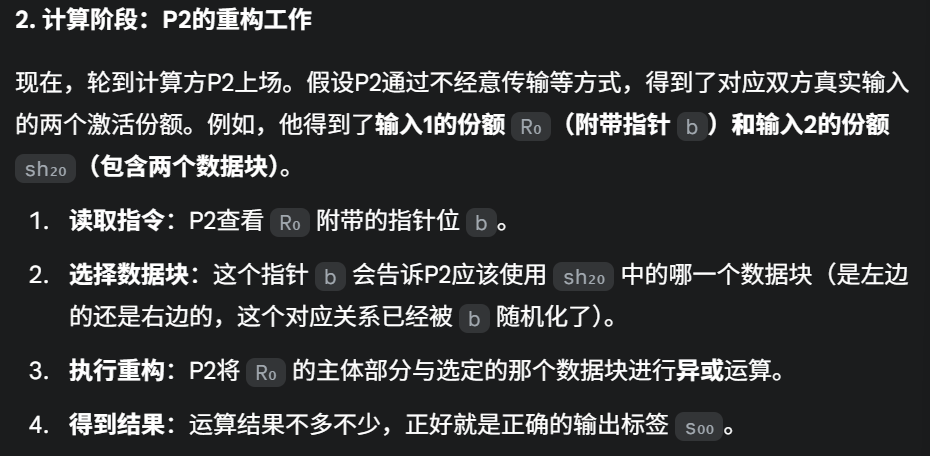
在宏观层面,GESS是一种秘密分享方案,其设计目的是允许在加密状态下对一个布尔门G进行计算。门G的两个输出导线标签是这次分享的“秘密”。P1会根据这两个秘密,为四种可能的输入标签组合,分别生成一个秘密份额。GESS保证,一个有效的份额组合(即每个输入导线对应一个份额)可以被用来重构出正确的输出导线标签。这与姚氏混淆电路(Yao’s GC)很相似,但GESS不需要使用混淆表,因此可以被看作是姚氏混淆电路的一种推广。与姚氏混淆电路的方法类似,这个秘密分享方案可以逐个门地应用,而无需解密或重构出任何明文值。
考虑一个双输入布尔门G。给定该门可能的输出值s_0,s_1, 以及门G的逻辑功能,P1会生成输入标签(sh_10,sh_11)和(sh_20,sh_21)。这些标签的生成方式要确保,任何一对可能的编码组合(sh_1i,sh_2j)(其中i, j∈{0,1})都恰好能够重构出对应的输出G(i,j),但不会携带任何其他信息。现在,如果P2获得了与其门输入相对应的“份额”(shares),它就能够重构出输出导线上的标签,并且学不到任何其他东西。这在很大程度上符合我们对秘密分享方案的直觉。实际上,正是门可能的输出值扮演了“秘密”的角色,这些秘密被“分享”出去,然后通过输入导线的编码(即“份额”)被重构出来。
3.6.1 GESS for Two-Input Binary Gates
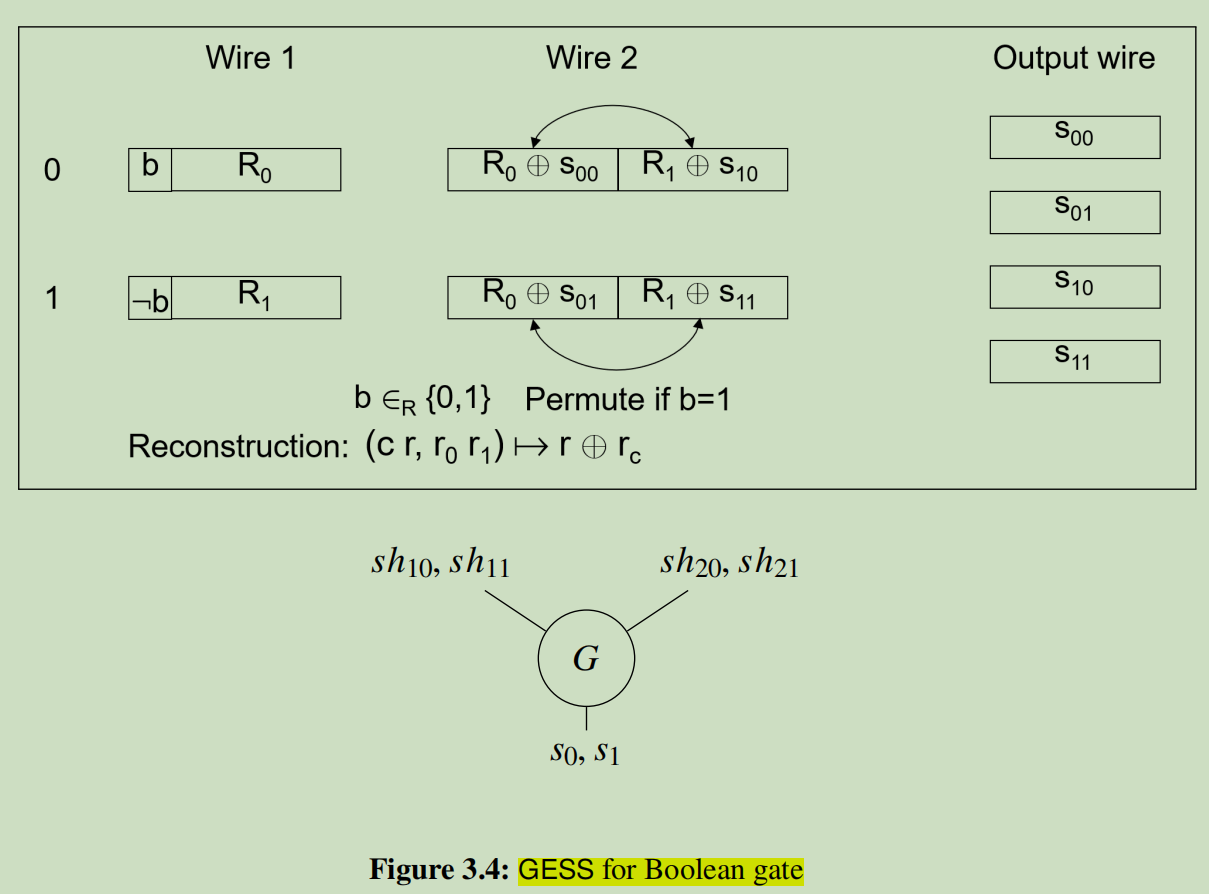
GESS的核心思想是抛弃混淆表,转而使用秘密分享的逻辑来安全地计算一个门。生成者P1会精心设计一套“份额”(即输入标签),使得计算者P2将他得到的两个份额组合在一起时,就能不多不少、刚刚好地“拼凑”出正确的输出结果(输出标签)。



3.6.2 Reducing Share Growth
上面的构造是不高效的,因为对应第二根输入导线的份额大小,是门秘密大小的两倍。我们只讨论与门(AND)和或门(OR),因为非门(NOT)可以简单地通过生成者翻转导线标签的语义来实现。对于上述构造中的或门和与门,(输入2的)两个份额(sh_20和sh_21)的左边数据块或右边数据块是相等的(这是因为对于与门,s_00=s_01(0,0和0,1的输出都是0);对于或门,s_10=s_11(1,0和1,1的输出都是1))。当秘密具有上述形式时,我们利用这个性质来减小份额的大小。其关键思想是,将第二根导线的两个份额看作是除了一个数据块之外,其余部分都相同。
假设四个秘密中的每一个都由n个数据块组成,并且它们仅在第j个数据块上有所不同。其思想是“按列”分享秘密,将秘密的每一“列”数据块都视为一个子秘密元组,并分别对这个元组进行分享,以产生对应的子份额。考虑分享相同的列(例如第1列):所有四个子秘密都相等(都等于t_1),我们可以用一种平凡的方式来分享它们:将第一根导线的两个子份额都设为一个随机字符串R_1,并将第二根导线的两个子份额都设为R_1⊕t_1。第3列也用类似的方式分享。我们像之前的(基础版GESS)构造一样分享不同的第2列,但省略附加指针和应用置换的最后一步。
剩下的“置换并指向”步骤是,应用一个(相同的)随机置换π来重排第二根导线两个份额的所有列,并将指针附加到第一根导线份额的每一个块上,以告知重构者该使用第二根份额的哪一个块。这使得GESS方案可以被重复应用于或门和与门。
概括一下基于GESS的MPC协议:P1将函数F表示为一个公式。然后,从F的输出导线开始,并将明文输出(0/1)作为最初的秘密,P1对电路的所有门重复地、从后向前地应用GESS分享方案,将份额分配给门的输入导线,直到他为公式的所有最前端输入都分配了标签。然后,P1将输入导线上的激活标签传送给P2。P2则重复地、从前向后地使用GESS的重构程序,最终获得F的输出标签(即明文结果)。
3.7 Oblivious Transfer
OT的批量执行仅需少量公钥操作。Beaver的构造属于非黑盒性质——即要求将PRF表示为电路并通过多方计算(MPC)进行评估。因此,其成果主要具有理论意义。Ishai等人(2003)通过提出一种极其高效的批量OT方案,彻底改变了这一局面。该方案仅需κ次公钥运算即可完成整个批次处理,且每个OT仅需进行两到三次哈希运算。
3.7.1 Public Key-Based OT

该构造的安全性,依赖于存在这样一种公钥加密方案:它能够随机采样一个公钥,而无需知道其对应的私钥。这个半诚实协议无法抵御恶意接收方
——接收方R可以简单地自己生成两对公私钥,并将两个公钥(pk₀, pk₁)都发送给S,然后用自己持有的两个私钥解密收到的两个密文,从而获知S的两个秘密值x₁和x₂。
3.7.2 Public Key Operations in OT
Beaver’s non-black-box construction:Beaver(1996)提出了“自举”(bootstrapping)姚氏混淆电路协议的方法,旨在从少量公钥操作中生成多项式数量级别的不经意传输(OT)。将P1称作S,将P2称作R。R向F输入k比特的字符串r,G是将k比特扩展到m比特的为随机函数,S获得b⊕G®,输入给F相应的m对秘密值(x_i0,x_i1)和比特字符串b⊕G®。给定r,F计算G®,得到选择字符串b,输出给R相应的秘密值x_bi。
Reducing the number of public key operations:在实践中,上面的方法是不高效的,因为要执行较大的GC。我们的目标:用小数量k个基础OT加上对称密钥操作,达到m>>k个有效的OT。
OT扩展方法,m个1-out-of-2随机字符串的OT。



Coding interpretation and cheaper 1-out-of-2^l OT:在IKNP中,接收方准备T和U的秘密份额,使得T ⊕ U的每行要么全是零,要么全是一。Kolesnikov和Kumaresan(2013)将IKNP的这一特性释为重复码,并建议改用其他编码方案。实现1-out-of-2^l OT,对于接收方,r_i不再是一个选择比特,而是l比特的选择字符串。令C为一个l维纠错码,码长为k。接收方准备矩阵T和U,t_j⊕u_j=C(r_j)。S收到q_j=t_j⊕[C(r_j)·s],·代表两个k长字符串的比特AND(C是一个重复码)。对于l长的值r’,发送方分配秘密值H(q_j⊕[C(r’)·s]),同时接收方计算H(t_j)。此时H(t_j)=H(q_j⊕[C(r_j)·s])。因此,接收方学习到的值就是发送方为接收方选择字符串r’=r_j赋予的秘密值。




OT扩展矩阵中的宽度k等于C中码字的长度。参数k决定了基础OT的数量和协议的总消耗。IKNP协议令k等于安全参数κ。为实现与IKNP OT相同的具体安全性,KK13协议(Kolesnikov和Kumaresan,2013)要求设置k = 2κ,以应对更高效底层密码C所需的更大空间。
3.8 Custom Protocols
基于电路的协议的贷款开销是与电路大小成线性的,这样可以阻止较大的计算量。另一种方法是为具体的问题涉及定制化的协议。尽管针对通用协议的加固技术已有相关研究(第6章),但针对恶意安全环境定制协议的加固(高效加固)可能难以实现。
3.8.1 Private Set Intersection(PSI)
PSI的目标是让参与方共同计算出他们输入集合的交集,而不泄露其他信息。虽然一些PSI协议是基于生成MPC构建的,但更多高效的定制协议可以由利用问题的解构来达成。
Oblivious PRF(OPRF):是一个MPC协议,允许两个参与方计算PRF函数F,其中一方拥有PRF密钥k,另一方拥有输入x,第二个参与方计算F_k(x)。
PSI from OPRF:现在讨论PSSZ结构。PSSZ中的参数为参与方都拥有n个物体。协议基于布谷鸟哈希,其中有三个哈希函数。为了将n个物品分配到b个桶中,首先选择三个随机哈希函数h1,h2,h3:{0,1}^*->[b],初始化空白的B[1,……,b]。检查B[h1(x)],B[h2(x)],B[h3(x)]是否是空的。如果是,则将物品x放入其中一个空的桶并终止。否则,选择一个随机的i,将当前位于 B[hi(x)] 的元素驱逐并替换为 x,然后递归尝试插入被驱逐的元素。如果该过程在经过一定次数的迭代后仍未终止,则最后被驱逐的元素会被放入一个名为暂存区(stash)的特殊容器中。P2使用布谷鸟哈希算法和大小为s的缓存区,将物品映射到1.2n个桶中。此时,每个桶最多包含一个物品,缓存区最多包含s个物品。P2通过虚拟(dummy)物品填充输入,确保每个桶恰好包含一个物品,缓存区恰好包含s个物品。
参与方进行1.2n+s个OPRF的实例运算,P2作为接收方,将1.2n+s个物品作为OPRF的输入。令F(k_i,·)作为第i个OPRF的实例中计算的PRF,如果P2通过布谷鸟哈希将物品y映射到桶i,则P2得到F(k_i,y)。如果P2将y映射到暂存区中的位置j,则P2得到F(k_1.2n+j,y)。P1可以对任意的i计算F(k_i,·),故P1计算候选PRF的输出集合:
H={F(khi(x),x)∣x∈Xandi∈{1,2,3}} H=\{F(k_{h_i(x)},x)|x \in X \quad and \quad i \in \{1,2,3\}\} H={F(khi(x),x)∣x∈Xandi∈{1,2,3}}
S={F(k1.2n+j,x)∣x∈Xandj∈{1,……,s}} S=\{F(k_{1.2n+j},x)|x \in X \quad and \quad j \in \{1,……,s\}\} S={F(k1.2n+j,x)∣x∈Xandj∈{1,……,s}}
P1将H的元素与S的元素随机排列后发送给P2,P2可通过以下方式确定X与Y的交集。若P2拥有映射进暂存区的元素y,则检查是否对应的OPRF输出在S中存在。如果P2拥有映射进桶中的元素y,则检查对应的OPRF输出是否在H中。直观而言,该协议通过伪随机函数(PRF)属性抵御半诚实参与者P2的攻击。对于元素x ∈ X \ Y,对应的PRF输出F(k_i, y)具有伪随机性。同样地,若PRF输出在相关密钥下仍保持伪随机性,则OPRF协议使用相关密钥实例化PRF实例是安全的。
只要伪随机函数不引入额外碰撞(即对于任意x和x₀,不存在F(k_i, x) = F(k_i₀, x₀)),协议即为正确的。我们必须谨慎设定防止此类碰撞所需的参数。
More efficient OPRF from 1-out-of-∞ OT:可以利用3.7.2节的编码思想构建PSI协议,其中C不需要有很多纠错码的性质。不需要使用解码,因此码不需要有高效解码的性质。只要求对所有可能的r和r’,C® ⊕ C(r
0 )具有大于等于计算安全参数κ的汉明距离。即使汉明距离保证仅为概率性的——即在选择C时以压倒性概率成立——也已足够。
令C为一个具有合适的长输出的随机寓言机,当k=4κ时,几乎不会找到碰撞(C® ⊕ C(r’ )具有较小的汉明距离)。将这样的C成为伪随机码(PRC)。通过将对C的要求从“纠错码”放宽到“伪随机码”,我们移除了对接收方选择字符串大小的先验限制。本质上,接收方可以使用任意字符串作为其选择;发送方也可以为任意字符串r’关联一个秘密值H(q_j⊕[C(r’)·s])。如前所述,接收方只能计算出与他自己选择的字符串r相对应的那个秘密。伪随机码的性质在于:对于接收方可能尝试的任何其他选择r*,其对应的值都与接收方的真实值有很大差异,这种差异会要求接收方必须猜中秘密s中至少κ个比特才能弥补,而这(成功的概率)是压倒性地低的。
实际上,我们可以将上述“无穷选一”OT(1-out-of-∞ OT)所实现的功能,看作是一种“不经意伪随机函数”。直观上,r|->H(q_j⊕[C®·s])这个函数,发送方可以在任何输入上求值,其输出是伪随机的,而接收方只能在自己选定的那个输入r上求值。将“无穷选一”OT视为OPRF存在两个主要的微妙之处:接收方学到的东西比这个“PRF”的输出要多一点(他知道未哈希的中间值);协议实现了该“PRF”的多个实例,但它们的密钥是相关的(所有实例共享秘密s和伪随机码C)。这个构造可以在PSSZ协议(一种PSI协议)中安全地替代OPRF
多个集合的交集可以通过迭代计算两两之间的交集来得到。然而,将上述的两方PSI协议直接扩展到多方场景并非易事。有几个障碍需要克服,例如在两方计算中,一个参与方会学到两个输入集合的交集。在多方场景下,这个(中间的)交集信息必须得到保护。Kolesnikov等人(2017a)提出了将上述PSI协议高效扩展到多方场景的方案。
4 Implementation Techniques
4.1 Less Expansive Garbling
执行混淆电路协议的主要成本在于:传输混淆门所需的带宽,以及生成和评估混淆表所需的计算量。
4.1.1 Garbled Row Reduction
GRR是一种减少每个门传输的密文数量的方法。关键在于,每个密文不必都是导线标签的(不可预测的)加密结果。事实上,每个混淆表中的条目之一可以固定为预先确定的值(例如 0^κ),因此根本无需传输。
4.1.2 FreeXOR
Kolesnikov(2005)的研究成果之一指出,对于异或门,GESS密钥共享可在不增加密钥长度的情况下实现(第3.6节)。Kolesnikov(2005)确立了最小份额的下界,解释了独立密钥需呈指数增长的必然性。但该下界并不适用于异或门(或更普遍地,适用于真值表中含两个0和两个1的“偶数”门)。
GESS中的XOR:设s0 ⊕ s1 = ∆,可观察到该偏移量∆在各导线标签中保持不变:sh10 ⊕ sh11 = sh20 ⊕ sh21 = s0 ⊕ s1 = ∆。由于所有门线上的份额具有相同偏移量,上述GESS异或门构造无法直接应用于姚氏通用密码(GC),因为标准姚氏GC要求各线独立随机。这将同时破坏GC的正确性与安全性:正确性受损源于GESS异或无法生成预设的输出线密钥。标准GC安全性证明失效,因GESS异或会在导线标签(即加密密钥)间产生关联性。更严重的安全隐患在于密钥与密文存在关联性,导致循环依赖关系形成。
FreeXOR:动机:在GESS中,异或门无需任何成本(无需生成混淆表,共享密钥也不会增长),而传统的姚氏通用密码则需为异或门支付生成和评估混淆表的全部代价。GC FreeXOR构造通过调整GC密钥生成机制,修复了将GESS异或构造直接引入GC时造成的正确性缺陷。该方案观察到:只要加强构建GC混淆表时所用加密原语的假设强度,即可确保新方案的安全性。FreeXOR通过要求电路所有导线标签均采用相同的偏移量Δ生成,将GESS异或门集成到通用电路中。
为解决安全性保障问题,FreeXOR采用随机预言机(RO)对门输出标签进行加密,而非采用姚式通用密码(Yao GC)允许的较弱(基于伪随机数生成器)加密方案。这是必要的,因为不同H实例的输入通过Δ相关联,且H输出掩盖的不同值也通过Δ相关联。标准的伪随机生成器安全性定义在此情况下无法保证H的输出具有伪随机性,但随机预言机可以做到。
Kolesnikov和Schneider指出,相较于RO,相关性鲁棒性(correlation robustness)这一较弱的概念已足够满足需求。FreeXOR的完整混淆协议如图4.1所示。其混淆校验协议流程与图3.2的标准姚氏混淆校验协议完全一致,仅在步骤4中,P2处理异或门时无需任何密文或加密操作:对于具有混淆输入标签wa = (ka, pa), wb =(kb, pb),则输出标签直接计算为(ka ⊕ kb, pa ⊕ pb)。
Kolesnikov等人(2014)提出名为fleXOR的FreeXOR泛化方案。在fleXOR中,异或门可根据电路的结构与组合特性使用0、1或2个密文进行混淆。该方案可与应用于与门的GRR2兼容,从而支持双密文与门。然而下节所述的半门技术既规避了fleXOR的复杂性,又将AND门的成本降至两个密文,同时完全兼容FreeXOR。

4.1.3 Half Gates
Zahur等人提出了一种有效的混淆技术,每个AND门只需要两个密文文本(将传统的与门的4个密文降低为2个),且完全支持FreeXOR。核心思想是将与门表示为两个半门的异或运算,这些半门本身是与门,其中一方已知其中一个输入。由于半门需要包含两个条目的混淆表,可通过混淆行缩减(GRR3)技术使用单个密文进行传输。使用半门实现与门需要构造生成器半门(生成器知晓其中一个输入)和评估器半门(评估器知晓其中一个输入)。
Generator Half Gate:首先考虑输入导线为a、b,输出导线为c的AND门。生成者半AND门算v_c=v_a^v_b,v_a被电路生成者所知晓。当v_a=0时,v_c=0。当v_a=1时,v_c=v_b。用a0、b0和c0表示编码false的导线标签。利用FreeXOR设计,导线b的标签要么是b0,要么是b1=b0⊕ ∆。生成者产生两个密文:H(b0)⊕ c0和H(b1) ⊕ c0 ⊕ v_a · ∆。这些密文根据b0的指针位进行置换。
为了计算半门,计算者(evaluator)对其持有的导线b的标签(b0或b1)取哈希,并解密相应的密文。如果他有b0,他就能得到c0。如果他有b1,他会得到c0 ⊕ v_a · ∆。如果v_a=0,结果是c0;如果v_a=1,结果是c1。
Evaluator Half Gate:对于计算者半门,v_c = v_a ∧ v_b,当门被计算时,计算者知道v_a的值,而生成者对两个输入都一无所知。因此,计算者可以根据已知的v_a值采取不同行动。生成者提供两个密文:H(a0) ⊕ c0和H(a1) ⊕ c0 ⊕ b0。不需要permute,因为计算着知道v_a,所以必须以这个顺序提供。当v_a为假时,计算者知道自己有a0,计算H(a0)即可得到输出c0。当va为真时,计算者知道自己有a1,计算H(a1)得到c0 ⊕ b0。然后,他将此结果与自己手上持有的导线b的标签进行异或,就能得到正确的输出标签c0或c1。
和生成者半门一样,可以使用GRR,将2个密文减为1个。在这种情况下,生成者只要设置c0=H(a0)(使第一个密文为全0),发送第二个密文。
Combining Half Gates:剩下的问题是如何用这两个半门来计算一个通用的与门vc = va ∧ vb,其中没有任何一方知道任何输入的语义值。这里的技巧是,让生成者生成一个均匀随机的比特r,并将原始的与门转换为两个半门和一次异或:v_c = (v_a ∧ r) ⊕ (v_a ∧ (r ⊕ v_b))。第一个与门(v_a ∧ r)可以用生成者半门来混淆。第二个与门(v_a ∧ (r ⊕ v_b))可以用计算者半门来混淆,但这需要将r ⊕ v_b的值泄露给计算者。由于r是均匀随机且计算者未知的,这不会泄露任何关于v_b的敏感信息。生成者如何零开销地将r ⊕ v_b传递给计算者呢?生成者会将r选择为导线b上“假”标签b0的指针位(point-and-permute的指针位),这个指针位本身就是随机选择的。因此,计算者可以直接从他所持有的b导线标签的指针位中,直接学到r ⊕ v_b的值,而对v_b本身一无所知。













4.1.4 Garbling Operation
混淆电路的计算开销主要来自于对加密函数H(通常实现为随机预言机)的大量调用。为了提升性能,研究者们试图利用现代处理器内置的硬件加密指令(如Intel的AES-NI指令)来加速这一过程。
两种主要的优化路线:
1.固定密钥AES方案(Fixed-key AES):
核心思想:由Bellare等人提出,该方案利用了“AES密钥设置虽慢,但使用已设置好的密钥进行加密极快”这一特性。因此,他们建议在整个混淆电路的生成过程中,始终使用一个固定的、公开的AES密钥。
理论基础:这种方法需要一个非标准的密码学假设,即假定固定密钥的AES表现得像一个随机置换(random permutation)。
主要缺陷:Gueron等人指出,这个“随机置換”的假设在学术界没有得到广泛认可,其安全性在实践中可能存在问题。
2.基于标准假设的方案(Pipelined AES):
核心思想:由Gueron等人提出,旨在只使用标准的、更安全的密码学假设来获得类似的性能提升。他们发现,大部分性能增益并非来自固定密钥,而是可以通过在处理器中巧妙地流水线化(pipelining)AES的密钥生成过程来实现。
理论基础:这种方法只依赖于AES是一个伪随机函数(PRF)这一标准假设,这在密码学界是广泛接受的。
问题:最高效的混淆电路优化技术,如FreeXOR(零开销异或门)和半门(最优的与门构造),其安全性证明同样依赖于非标准的假设。
Gueron等人的替代方案:他们提出了一种替代FreeXOR的构造,该构造仅依赖于标准假设,但代价是每个XOR门需要传输一个密文(不再“免费”)。重要的是,该构造仍然兼容一种高效的、仅需两个密文的AND门方案。Gueron等人的方案虽然因为XOR门需要开销而比“半门”方案的带宽略高。但它的巨大贡献在于,证明了我们可以在只使用标准密码学假设的前提下,构建出效率极高(性能差距在两倍以内)的混淆电路方案,为追求更高安全保障的场景提供了坚实的理论和实践基础。
4.2 Optimizing Circuits
因为执行基于电路的MPC协议与电路的大小线性相关,所以减小电路大小可以影响协议的cost。
4.2.1 Manual Design
若干项目通过手动设计电路来最小化安全计算的成本,通常侧重于在使用FreeXOR时减少非自由门数量。手动电路设计能利用自动化工具无法发现的优化机会,但因其耗费巨大,仅适用于广泛使用的电路。接下来我们将讨论一个典型示例;类似方法已被用于设计针对安全计算优化的通用构建模块(如多路复用器和加法器),以及更复杂的功能(如AES加密算法)。
Oblivious permutation:在不经意置换中对数据数组进行打乱,是许多隐私保护算法的重要构建模块,包括PSI和平方根ORAM算法。不经意置换(oblivious permutation)以及许多其他算法的一个基础组件是“条件交换器”(conditional swapper),它接收两个输入a1和a2,并产生两个输出b1和b2。
根据一个“交换位”p的值,输出要么与输入匹配(b1 = a1 且 b2 = a2),要么是输入的交换顺序(b1 = a2 且 b2 = a1)。这个交换位p为电路生成者所知,但绝不能泄露给计算者。
Kolesnikov和Schneider(2008b)提供了一种交换器的设计,它利用了FreeXOR的优势,并且只需要一个两行的混淆表(这可以用行消减技术减少到一个密文)。该交换器通过以下公式实现:b1=a1⊕(p∧(a1⊕a2)),b2=a2⊕(p∧(a1⊕a2))。整个计算中唯一的“昂贵”操作是与门 p ∧ d。这个与门的特殊之处在于,它的一个输入p是为生成者所知的,这完美地匹配了我们之前讨论的“生成者半门”的场景。一个生成者半门经过优化后,只需要一个密文来表示。因此,整个功能强大且复杂的条件交换器,最终只需要生成者发送一个极小的密文就能实现,效率极高。
Low-depth circuits——optimizing for GMW:在GMW中每个与门计算需要一次OT,因此需要一轮通信。成本严重依赖于电路的深度,特别是与门(AND Gate)的深度。这是因为GMW协议中,每一层的与门都需要一轮独立的网络通信(通过不经意传输OT实现)。Schneider和Zohner等人没有改变GMW协议本身,而是为加法、比较、乘方等常用计算功能,专门设计了AND深度极低的定制化电路。同时,他们利用OT扩展技术降低了每一轮通信的计算成本,并使用SIMD(单指令多数据)指令集来并行处理数据,进一步提升效率。
4.2.2 Automated Tools
产生高效布尔电路的工具,输出可以适配到基于电路的安全计算。
CBMC-GC:CBMC-GC是一个将C语言程序自动编译成布尔电路,以用于混淆电路(Garbled Circuits, GC)安全计算的工具。该工具基于一个名为CBMC的“有界模型检测器”。CBMC原本的用途是验证C程序的正确性,其工作原理是将C程序转换为一个布尔电路,再进一步转换为布尔公式,最后用SAT求解器进行分析。Holzer等人利用了CBMC的这个内部机制,对其进行了修改,使其直接输出中间步骤生成的布尔电路,而不是最终的布尔公式。这个输出的电路随后就可以被用于任何基于电路的安全计算框架中,例如混淆电路协议。
CBMC-GC的一个关键优化是针对混淆电路的成本模型进行的。原始的CBMC为SAT求解器优化电路,这使得它更偏好使用与门(AND gates)。在混淆电路中,由于FreeXOR技术,异或门(XOR gates)的计算开销几乎为零,是“免费”的,因此是首选。为了最小化“非免费”门(如与门)的数量,CBMC-GC的作者替换了CBMC内部用于实现加法、比较等运算的默认电路,采用了最大化使用免费XOR门的新设计。通过这种方式,CBMC-GC能够将高级语言(C语言)编写的复杂程序,自动编译成对混淆电路执行环境高度优化的布尔电路,极大地降低了安全计算的门槛和开销。
TinyGarble:是一个利用硬件电路综合工具,将高级算法描述(如Verilog)自动编译成适用于混淆电路(Garbled Circuits, GC)协议的布尔电路的框架。传统的硬件综合工具无法直接用于安全计算,因为它们可能生成带有循环的电路,且它们的成本优化模型是为物理硬件设计的,与混淆电路中(以通信量为主要成本)的成本模型不匹配。
TinyGarble通过两大创新解决了这些问题。
1.使用顺序逻辑与电路展开 (Sequential Logic & Unrolling)。TinyGarble将程序表示为紧凑的顺序电路,这种电路可以维持内部“状态”(如硬件中的触发器)。在执行时,它将这个顺序电路“展开”,把前一个时钟周期的状态作为下一个周期的额外输入。优势:这种方法使得电路的表示非常紧凑,即使执行的迭代次数很多。这能有效利用处理器缓存,避免访问慢速内存,从而提升性能。它通过略微增加门的总数,换取了电路表示大小的大幅减小。
2.定制化的成本模型 (Custom Cost Model)。TinyGarble为硬件综合工具提供了一个定制的“技术库”,以适配混淆电路的成本模型。为了充分利用FreeXOR技术,这个库将XOR门的“面积”(即成本)设置为0,而将其他门(如AND门)的成本设置为其所需的密文数量。优势:当配置综合工具去“最小化电路面积”时,它会自动地、最大限度地减少昂贵的非XOR门的使用,从而生成对GC协议高度优化的电路。
4.3 Protocol Execution
Pipelined Execution:并行混淆电路可以让任何一方都不要存储整个混淆电路。流水线执行的核心思想是将电路的“生成”和“计算”两个阶段交织在一起,而不是严格地分步执行,从而避免了任何一方需要存储整个庞大的混淆电路。
准备阶段:协议开始前,双方先共享一份电路的“蓝图”(电路结构)。这份蓝图很小,因为它只描述了门的连接关系。
交织执行:生成者按照电路的拓扑顺序,边生成混淆门,边将其发送给计算者。计算者每收到一个混淆门,就立即进行计算(只要该门的输入标签已经就绪)。
这种“即产即用”的模式带来了显著的性能提升:
消除海量存储:最关键的优势是,协议的任何一方都不再需要存储整个混淆电路。
内存复用:一个门一旦被计算完毕,其占用的内存可以立即被释放和复用。
性能飞跃:极大地减小了内存占用,并因此显著提升了整体性能。
Compressing Circuits:即使使用了流水线执行,协议双方依然需要加载整个电路的结构,这对于包含大量循环的超大规模程序来说,内存开销是无法承受的。设计一种紧凑的电路表示格式——便携式电路格式(Portable Circuit Format, PCF),并在执行循环时,重复使用同一段电路结构,而不是将循环完全“展开”成一长串重复的门。
编译:一个专门的编译器将高级语言程序转换成一种紧凑的PCF字节码。
解释执行:协议双方(生成者和计算者)不再直接处理庞大的电路文件,而是各自运行一个“解释器”来执行这段PCF字节码。
循环处理:当遇到循环时,双方在本地各自维护一个循环计数器。在每次迭代中,他们都重复使用对应于循环体的同一段电路结构。生成者会为每一次迭代都动态地“即时”生成新的混淆门。
极高的可扩展性:这是该方法最大的优势。由于电路的表示大小和本地内存占用与循环的迭代次数无关,该技术能够处理传统方法无法企及的、拥有数十亿甚至上百亿门的超大规模电路(例如,计算1024位RSA加密)。
安全保障:为了防止信息泄露,协议规定,被加密的秘密值(garbled wire values)不能被用作条件分支(如if语句)的判断条件。
Mixed Protocols:为了提升安全多方计算(MPC)的效率,最佳实践往往是混合使用多种不同的安全计算协议,而不是只依赖单一的通用协议。像姚氏混淆电路(Yao’s GC)或GMW这样的通用MPC协议虽然能计算任何函数,但对于某些特定运算(如大规模加法),它们的效率很低。相比之下,加法同态加密(Homomorphic Encryption, HE)在处理加法运算时效率要高得多。我们可以将一个复杂的计算任务拆分开来,用最高效的协议去执行对应的部分。例如,用同态加密来完成所有的加法,用混淆电路来完成比较、乘法等非线性操作。
混合协议最大的技术挑战是:如何安全地将一个值从一种“加密”状态(如同态加密的密文)转换到另一种“加密”状态(如混淆电路的秘密分享/标签),而不在中途泄露任何信息。“随机掩码” (Random Mask) 技术是实现这种转换的标准方法:
1.一方(P2)在同态加密的结果Enc(x)上,再加密地加上一个随机数r,得到Enc(x+r)。
2.另一方(P1)解密后得到x+r,由于r的存在,x的真实值依然是保密的。
3.随后,在进入混淆电路计算时,P1将x+r作为输入,P2将r作为输入。电路的第一步就是做一个减法,将掩码r安全地移除,从而得到x的混淆电路表示。
为了让这种复杂的混合协议更易于使用,学术界和工业界开发了多种高级工具,如TASTY编译器、ABY框架和自动选择方法。
Outsourcing MPC:为了解决在智能手机等低功耗设备上直接运行安全多方计算(MPC)协议时,带宽和电量开销过大的问题,我们可以将协议中最繁重的计算部分“外包”给一个不可信的云服务器。该方案专门针对一个“手机用户”与一个“强大服务器”进行安全计算的场景。
- 引入第三方:协议引入了一个云服务作为计算的“主力”。大部分繁重的混淆电路(Garbled Circuit)执行工作,发生在云服务和强大服务器之间,而不是手机和服务器之间。
- 云服务可以是恶意的,但有一个关键前提:它不会与另一方(强大服务器)合谋。协议必须保证云服务对手机用户和服务器的任何输入或输出都一无所知。
- 外包不经意传输 (Outsourced OT):为了以极低的开销安全地获取手机用户的输入,协议使用了一种专门的外包OT技术。致盲电路 (Blinding Circuit):为了向云服务隐藏最终的计算结果,协议在原始电路的末尾增加了一个“致盲电路”。这个电路会用一个只有手机和强大服务器知道的随机掩码来加密最终输出,云服务只能看到加密后的无意义结果。
通过将绝大部分的计算和通信负担转移到云服务上,该方案可以极大地降低移动设备所需的资源开销,使得在资源受限设备上进行复杂的安全计算成为可能。
4.4 Programming Tools
Obliv-C:Obliv-C是一种C语言的严格扩展,旨在让程序员能够更轻松地编写将通过安全多方计算(MPC)协议执行的数据无关(data-oblivious)程序。Obliv-C引入了obliv类型修饰符。用obliv声明的变量在程序执行期间会保持加密状态,其真实值对程序本身是不可见的。只有通过一个显式的reveal函数,才能将其值解密并公开。
数据无关的控制流:常规的控制流(如if语句)不能依赖于obliv变量,因为程序在运行时不知道这些变量的真实值。为此,Obliv-C提供了数据无关的控制结构,例如obliv if。工作原理:obliv if (condition) { statement; }并不会根据condition的真假来决定是否执行statement。相反,它会生成一个“多路选择器”(multiplexer)电路。在MPC协议内部,这个电路会安全地根据condition的秘密值,来决定statement的执行是产生实际效果还是无效。从外部看,两条分支似乎都被执行了,从而隐藏了真实的执行路径。
类型系统:Obliv-C的类型系统可以防止程序员犯一些逻辑错误,比如在obliv if块中更新一个非obliv变量。这主要是为了在编译时发现无意义的代码,帮助程序员避免bug,而不是为了提供安全保障(安全由底层的MPC协议负责)。
高级优化:对于实现不经意RAM(ORAM)等底层库,Obliv-C提供了一个unconditional代码块。它允许程序员在数据无关的上下文中执行必须无条件运行的代码,从而能够进行低级别的性能优化,而无需直接编写电路。
5 Oblivious Data Structures
标准的电路安全计算(如混淆电路)在处理对内存的随机访问时效率极低,需要更高效的解决方案。
在安全计算中,当程序需要访问一个数组 a[],而索引 i 本身是一个需要保密的私有值时,标准方法无法直接只读取第 i 个元素,因为这会泄露 i 的值。为了隐藏访问位置,最直接的方法是构建一个巨大的电路,读取或更新数组中的每一个元素,但只对第 i 个元素进行有效操作,其他操作都是“伪装”。这种方法的开销与数组大小成正比,对于大型数据结构完全不现实。
利用可预测的访问模式:如果程序的内存访问模式不依赖于任何私有数据,那么就不需要隐藏访问位置,也就不需要扫描整个数据结构。但这只适用于特定情况。
通用方案:不经意RAM (Oblivious RAM, ORAM):对于任意的、依赖于私有数据的内存访问,我们需要一种通用的、开销低于线性的方法。这可以通过将通用的MPC协议与一种专门的密码学工具——不经意RAM(ORAM)——相结合来实现。ORAM专门用于在隐藏真实访问位置的同时,以亚线性(sublinear)的开销完成对内存的读写操作。
5.1 Tailored Oblivious Data Structures
我们可以通过利用程序中可预测的内存访问模式,来大幅优化安全计算的效率,避免昂贵的线性扫描。
在安全计算中,对一个私有数组进行简单的for循环操作(如将每个元素翻倍),如果按标准方法为每次访问都执行一次“线性扫描”,总开销会达到Θ(N^2),效率极低。如果一个算法的内存访问模式是完全可预测的,并且不依赖于任何私有数据(例如,for循环的索引i是公开的),那么直接按顺序访问每个元素并不会泄露任何信息。因此,我们可以省去昂贵的“不经意”操作,直接更新每个元素,将总开销降至线性级别。
许多算法的访问模式虽然不像简单的for循环那样完全可预测,但也并非完全依赖于私有数据。也就是说,我们通常可以预先知道某些访问模式是绝对不可能发生的。基于这一洞察,我们可以设计出专门的“不经意数据结构”(oblivious data structures),它们能够利用许多算法中常见的、可预测的访问模式,从而实现比通用方法更高的效率。
Oblivious Stack and Queue:遗忘数据结构(如栈或队列)主要用于安全计算(如 MPC)中,确保操作模式(Access Pattern)不会泄露关于正在处理的数据的信息。
标准栈的问题: 栈操作(push/pop)总是在栈顶,具有局部性。但在实际程序中,这些操作可能发生在条件分支中(例如 if (x > 10) { stack.push(y); })。这使得访问模式依赖于秘密数据(x的值)。
遗忘栈的需求: 需要支持条件性操作,例如 condPush(b, v)。
condPush(b, v) 的定义:如果b (受保护的布尔变量) 为 True,则将v压入栈。如果 b为 False,则栈的状态保持不变。无论b是真是假,这个操作(例如,它读取和写入的内存地址)对外界观察者来说必须看起来完全一样,以防止信息泄露。
朴素实现(低效):使用一系列多路复用器(Multiplexer)。对于栈中的每个元素 stack[i],电路都会根据b的值来决定其新值:如果b为 True(发生 PUSH):stack[i] = stack[i-1] (栈顶元素 stack[0] 设为v)。如果b为 False(不 PUSH):stack[i] = stack[i]。缺点: 每次操作都需要一个与栈的最大容量N 成正比(O(N))的电路。如果栈很大,这个成本就无法接受。
高效实现(分层设计):将栈的表示分解为一组具有“闲置空间”(Slack Space)的分层缓冲区(Buffer)。这样,大多数操作只触及顶部的小缓冲区,而不需要触及整个数据结构。栈被分为多个层级(Level i),Level 0 代表栈顶,第i级缓冲区的大小为5x2i个数据槽。数据以“块”(Block)为单位管理,第i级的块大小为2i。
condPush 操作流程:
推入 Level 0: condPush 总是将数据推入 Level 0。因为 Level 0 的大小是固定的(5 个槽),所以使用多路复用器在这里的成本很低(O(1))。
触发“移位”(Shift): Level 0 填满后(例如,在执行了2^0=1次 condPush 后),会触发一次向右移位,将 Level 0 中的一个数据块(Block)推入 Level 1。
级联移位: 同样,当 Level 1 累积了2^1=2次来自 Level 0 的移位后,它会触发一次向右移位,将一个块推入 Level 2。以此类推,第i级的移位在2^i次操作后发生。
condPop 操作: 类似地,condPop 会触发向左移位(例如,Level 0 为空时,从 Level 1 拉取一个块)。
成本分析:在基于电路的多方计算(MPC)中,主要成本是电路中的门(Gate)数量,这与带宽消耗成正比。对于一个最大容量为N的栈,需要O(logN)个层级。对于k次操作,第i级(Level i)会被访问(需要移位)约k/2i次。在第i级移动一个数据块的成本是O(2i)(因为块大小为2i)。因此,在k次操作中,第i级的总成本为:(访问次数)x(单次成本)=O(k/2i)xO(2^i)=O(k)。由于所有O(logN)个层级的成本都是O(k),所以k次操作的总电路规模(总成本)为O(klogN)。
朴素实现的单次操作成本是O(N)。分层设计的 摊销(Amortized)单次操作成本 仅为O(logN)。

Other Oblivious Data Structures:除了简单的线性扫描之外,利用可预测的内存访问模式来设计更高效的不经意数据结构 (Oblivious Data Structures) 的方法。利用可预测性实现亚线性开销:当程序的内存访问模式具有一定的局部性和可预测性时,我们可以设计出开销低于线性扫描(即 Θ(N))的不经意数据结构,因为此时不需要支持完全任意的随机访问。
不经意队列 (Oblivious Queue):Zahur和Evans设计了一种基于两个特殊栈(一个只进,一个只出)的层级队列,利用简化的3块缓冲区,实现了 Θ(log N) 的均摊操作开销。
批量处理 (Batching):不经意数据结构还可以通过将多个无内部依赖的读写操作批量组合成一次数据结构扫描来进一步优化。
关联映射 (Associative Map):Zahur和Evans提出的不经意关联映射,可以通过排序的方式,将多达N个独立的更新操作合并,总开销为 Θ(N log² N),均摊到每次更新的开销为 Θ(log² N)。
编程模型:最大的挑战是如何编写程序来有效利用这些可预测的访问模式。
理想方案 (尚不存在):一个足够智能的编译器或许能自动识别并转换代码,但这需要深度分析且目前尚无此类编译器。
当前方案:程序员需要手动重写代码,调用实现了这些不经意数据结构的库。
通用替代方案:使用通用的不经意RAM (Oblivious RAM, ORAM) 来处理任意访问模式。
5.2 RAM-Based MPC
标准的安全计算协议(如基于电路的MPC)在处理需要随机访问大内存(如数组 a[],其中 i 是秘密)的操作时效率极低。ORAM是一种内存抽象技术,它允许用户读写内存,同时隐藏真实的访问位置模式,即使是存储数据的服务器也无法知道用户访问了哪些地址。
引入MPC:将ORAM的数据结构(内存内容)以秘密分享的方式分散存储在参与MPC的各方本地。使用一个通用的、基于电路的安全计算协议(如姚氏混淆电路)来安全地执行ORAM的访问算法(即计算出需要访问哪些物理地址、如何读写数据的逻辑)。
流程:
1.输入秘密地址:参与方将想要访问的逻辑地址(如数组索引 i)作为秘密输入,提供给执行ORAM访问算法的MPC电路。
2.计算物理地址:MPC电路安全地计算出为了完成这次访问,需要读取或写入的物理内存地址。
3.公开物理地址:这些计算出的物理地址会被公开给所有参与方。由于ORAM的设计保证,这些物理地址本身不会泄露关于原始逻辑地址的任何信息。
4.本地数据获取:每个参与方根据公开的物理地址,从自己本地存储的ORAM数据份额中取出对应的数据。
5.数据送回MPC:各方将取出的数据份额作为秘密输入,再次送入MPC电路。
6.MPC内部操作:MPC电路根据取回的数据份额完成最终的读操作(将数据秘密分享给请求方)或写操作(计算出需要写回的新数据份额)。
7.写回本地存储:对于写操作,MPC电路会输出需要更新的物理地址(公开)以及对应的新数据份额(秘密分享),各方据此更新自己本地的存储。
Gordon等人证明,将一个半诚实安全的ORAM协议(状态在两方间共享)与一个半诚实安全的两方计算协议(2PC)结合,可以得到一个在半诚实模型下安全的RAM-based MPC协议。
5.3 Tree-Based RAM-MPC
核心数据结构二叉树:存储N个元素的基础结构是一个高度为log N的二叉树。每个逻辑内存地址被随机映射到一个叶子节点。该地址对应的数据值,以加密形式存储在从根节点到该叶子节点路径上的某个节点中。
访问流程:
1.映射查询:首先需要知道逻辑地址对应哪个叶子节点。这个“地址-叶子”映射表本身也很大,不能直接存在客户端。解决方案是用另一个(更小的)树状ORAM来存储这个映射表。可能需要递归地使用多层映射树。
2.路径读取:确定叶子节点后,客户端需要从服务器取回从根到该叶子整条路径上所有节点的内容。
3.解密与扫描:客户端(或在MPC中,双方)解密路径上的每个节点,并进行线性扫描,以找到包含所需逻辑地址数据的那个节点。
在RAM-MPC中的实现:
树的共享:ORAM的整个二叉树结构以秘密分享的方式,分散存储在参与MPC的两方本地。
访问的执行:
1.双方通过一个2PC协议(如混淆电路)安全地执行ORAM的访问逻辑。
2.输入是逻辑地址的份额,输出是需要访问的物理路径(这部分可以公开)。
3.双方根据公开的路径信息,从本地存储中取出对应节点的数据份额。
4.将这些数据份额送入另一个2PC电路,进行解密和线性扫描,最终得到目标数据值的份额。
保持不经意性:为了防止重复访问同一地址时泄露模式,每次访问后都需要进行处理。
1.重新映射:被访问的逻辑地址会被重新随机映射到一个新的叶子节点。
2.写回根节点:更新后的数据值会被暂时存入根节点。
3.平衡与驱逐 (Eviction):为了防止根节点溢出,每次访问后,会随机选择一些节点中的元素,并将它们沿着树向下“推”,更新其子节点的内容(同时更新两个子节点以隐藏真实路径),从而将数据逐步分散回树中。
安全性:由于每次访问都读取一条完整路径,并且访问后元素会被随机重新定位,使得任何两次访问的物理模式都无法区分,从而隐藏了真实的访问逻辑。
溢出风险:存在节点无法容纳所有被推下来的元素的微小风险。通过将每个节点的容量(bucket size)设置为O(log N),可以将溢出概率控制在可忽略的范围内。
优化方向:后续研究通过引入一个额外的“暂存区”(stash)来存储溢出元素,从而可以减小节点容量,并改进驱逐算法,进一步提升性能。
Path ORAM:核心改进:在基础树状ORAM上增加了“暂存区”(stash),一个固定大小的辅助空间,用于存放溢出元素,每次访问时都需要扫描。
更高效的驱逐策略:不再随机选择节点进行驱逐,而是在访问路径(从根到被访问叶子的路径)上进行驱逐,将元素尽可能地沿着这条路径向下推。因为这条路径本来就要被访问,所以驱逐操作无需额外的掩盖。
MPC应用:被Wang等人适配到了RAM-MPC中,并设计了更高效的驱逐电路。
Circuit ORAM:设计理念:专为RAM-MPC场景下的最优电路复杂度而设计。它认识到,在MPC中,ORAM的主要成本是执行其访问逻辑所需的电路大小(即MPC带宽),而不是传统ORAM关注的客户端-服务器带宽。
核心改进:用一种更高效的单次扫描驱逐方法取代了Path ORAM的驱逐逻辑。先对小得多的元数据标签进行两次扫描,确定哪些数据块需要移动以及它们的新位置。然后,再沿着路径进行单次扫描来移动实际的大数据块,每次只需暂存一个待移动的数据块。
效果:由于主要的扫描操作都在小元数据上进行,显著降低了实际的电路成本(以非免费门数量衡量),相比最初的二叉树ORAM设计,效率提升了30倍以上(针对特定参数)。
5.4 Square-Root RAM-MPC
Zahur等人发现,经典的平方根ORAM设计(Goldreich & Ostrovsky, 1996)可以通过一种巧妙的方式适配到RAM-MPC中。关键在于将不经意置换 (oblivious permutation) 中的伪随机函数(PRF)计算移到通用MPC协议之外,由双方协同完成。
优势:
1.无统计失败概率:与树状ORAM不同,它没有节点溢出的风险,因此是确定性的。
2.具体性能优越:对于中等大小的内存(例如最多2^16个块),其单次访问的具体开销(包括初始化)比Circuit ORAM更低,且很快就优于线性扫描。
3.初始化快:初始化只需要一次不经意置换,网络轮数仅为 Θ(log N),远快于Circuit ORAM的 Θ(N log N)。
工作原理:
1.维护一个层级结构,每层有一个不经意的“暂存区”(stash)。
2.每次访问都会向每层的stash添加一个元素,并需要对所有stash进行线性扫描。
3.当stash大小达到 Θ(√N) 时,需要进行一次昂贵的不经意洗牌(reshuffling)来清空stash,并将数据重新随机分布到底层存储。
Floram:Doerner和Shelat指出,在RAM-MPC场景下,不一定需要传统ORAM追求的亚线性访问开销。由于安全计算本身的开销远超普通计算,即使ORAM访问是线性的,只要能减少MPC内部的计算量,也可能更优。基于分布式不经意RAM(Lu & Ostrovsky, 2013)和两服务器私有信息检索(PIR)的思想。它放松了ORAM的安全性要求:单个服务器的访问记录可以泄露信息,但只要两个服务器不合谋,就无法知道真实的访问模式。
关键技术:
1.分布式点函数 (Distributed Point Functions, DPF):由Gilboa和Ishai引入,可以将一个“点函数”(只在一个点上非零的函数)进行秘密分享,份额大小远小于定义域,用于高效实现两服务器PIR。
2.读写分离:Floram使用DPF分别构建了不经意只写存储 (OWOM) 和不经意只读存储 (OROM)。
3.刷新机制:写操作先暂存在OWOM和一个线性扫描的stash中。当stash满时,执行一次“刷新”,将OWOM转换为新的OROM,并清空OWOM和stash。
优势:在许多实际参数下,性能比Square-Root ORAM和Circuit ORAM提升超过100倍。
Square-Root ORAM通过优化不经意置换,在中等规模下提供了优异的具体性能和快速初始化。而Floram则通过放松安全模型、利用PIR和DPF技术,实现了线性访问开销但极低的MPC内部计算量,从而达到了更高的可扩展性和效率。
Reading:存储在OROM中的每个值首先被一个在其索引处评估的伪随机函数(PRF)值所掩盖(masked),然后这个被掩盖的值再以秘密分享的方式存储在两个OROM服务器上。
读取流程:
1.获取DPF密钥:参与方首先通过MPC协议获取用于其分布式点函数(DPF)份额的密钥k_i^p。
2.本地DPF评估:每个参与方p在其本地存储的所有OROM元素上评估其DPF份额P_k_i^p(x)。
3.本地结果聚合:将所有本地评估结果进行异或(XOR)。由于DPF的特性,对于所有x≠i的位置,结果都是0的份额,因此最终的异或和就是所请求值v_i的掩盖份额v_i^p。
4.MPC中合并份额:双方将各自得到的份额v_ip输入MPC协议,并进行异或,得到被掩盖的值R_i=v_i1异或v_i^2。
5.MPC中计算PRF并去掩码:在MPC内部安全地计算PRF_k(i),并将其与R_i进行异或,最终得到未掩盖的、真实的元素值。PRF掩码是必要的,以防止在OROM刷新时泄露信息。
6.扫描Stash:此外,每次读取还需要在MPC内部对“暂存区”(stash)进行一次线性扫描,以检查请求的元素是否在上次刷新后被更新过。
成本分析:
DPF生成:需要 O(log N) 的安全计算和通信。
本地DPF评估:每个服务器需要 O(N) 的本地计算量。
PRF去掩码:需要常数大小的安全计算。
Stash扫描:需要与Stash大小成正比的安全计算(线性扫描)。
Refreshing:当Floram的“暂存区”(stash,属于只写存储OWOM的一部分)写满时,需要执行一次刷新操作。刷新的核心是将当前只写存储(OWOM)的内容固化成一个新的只读存储(OROM),并清空暂存区,为后续的写操作腾出空间。
刷新流程:
1.生成新密钥:每个参与方p(P1, P2)各自生成一个新的伪随机函数(PRF)密钥k_p。
2.本地掩盖:每个参与方用自己的新密钥k_p和地址索引i计算PRF值,并用该值掩盖(异或)自己本地OWOM存储份额中的每一项W_p[i]。
3.交换掩盖值:双方交换各自掩盖后的OWOM份额。
4.计算新OROM份额:每一方将收到的对方份额与自己本地的掩盖份额进行异或,得到新的OROM存储内容R[i]。此时,R[i]实际上等于PRF_{k1}(i) ⊕ PRF_{k2}(i) ⊕ v[i],其中v[i]是原始的秘密值。
5.密钥输入MPC:双方将各自的PRF密钥k1, k2作为秘密输入提供给后续的MPC计算。
低刷新成本:刷新操作只需要O(N)的本地计算和通信,完全不需要昂贵的安全计算(MPC)。
高效率:由于刷新成本低,可以更频繁地刷新(最优周期O(√N)),使得暂存区可以保持较小,提高了整体访问效率。
性能优越:尽管OROM和OWOM的本地操作是线性的O(N),但由于这些操作不在MPC内部执行,其具体开销远小于MPC内部的计算开销。因此,Floram在实际中性能远超其他(渐进复杂度更优的)RAM-MPC ORAM方案,尤其是在MPC成本占主导的中大规模内存场景下。
快速初始化:使用与刷新相同的机制,初始化过程简单高效。
存储高效:与需要存储κ倍大小(κ为安全参数)的导线标签的其他方案不同,Floram只需存储与原始数据同样大小的秘密份额。
5.6 Further Reading
利用不经意RAM(ORAM)原理来设计高效MPC数据结构的进一步发展和研究方向。
专用不经意结构:除了通用的RAM-MPC,研究者们还为特定数据结构(如数组、优先队列)设计了高效的MPC实现。这些设计要么基于ORAM,要么利用了特定应用中稀疏或可预测的访问模式。还提出了基于指针的技术来支持树状访问模式。
ORAM研究活跃:ORAM本身是一个持续活跃的研究领域,存在多种设计方案和权衡。
自动化选择:已有研究开发了编译器,可以分析高级程序中的数组访问,并自动选择最合适的MPC-ORAM设计。
多方ORAM:ORAM设计也被扩展到了多方计算场景(如三方、诚实多数模型),并实现了显著的成本降低。
新方向:有限泄露:一个新兴的研究方向是探索允许少量、受控的访问模式信息泄露,以换取更高的效率。
6 Malicious Security
半诚实威胁模型是非常弱的。对于大部分场景而言,它的假设低估了真实的敌手。
6.1 Cut-and-Choose
Yao’s GC在恶意敌手面前是不安全的。特别的,P1要生成并发送一个混淆后的F给P2。P1可能发送P2未同意评估的其他电路的混淆版本,但P2无法确认该电路是否正确。恶意生成的混淆电路输出可能泄露超出P2同意披露范围的信息(例如P2的全部输入)。
Main idea:检查一些电路,计算其他的电路。cut and choose的思想可以追溯到Chaum的盲签名。
多造、抽查、再使用:为了防止P1(生成者)偷偷构造一个错误的或泄露信息的混淆电路,P1需要生成很多份(例如100份)相同功能的混淆电路。P2(计算者)会随机挑选其中的一部分(例如50份)要求P1“打开”(cut),即 P1 公开用于生成这些电路的所有秘密信息(如导线标签)。P2会检查这些被打开的电路是否都构造正确。如果发现任何作弊行为,P2就中止协议。如果所有被检查的电路都合格,P2就相信剩下的未被打开的电路(另外50份)大概率也是好的,然后随机选择(choose)其中的一个(或多个)进行实际的计算。
威慑:P1不知道P2会抽查哪些电路。如果P1想作弊,他制造的坏电路就有一定的概率被P2抽中并发现,导致作弊失败。
概率保证:通过生成足够多的电路并检查足够多的比例,P2可以获得很高的统计学保证——未被检查的电路中绝大多数(甚至全部)都是正确的。
安全性:被检查过的电路因为秘密已被公开,不能再用于安全计算。计算只在那些未被检查、秘密仍受保护的电路上进行。
Generating an output:即使经过随机抽查,也不能保证所有未被检查的电路都是正确的。总有一定(不可忽略的)概率,一个错误的电路会“侥幸”躲过检查,进入最终的计算阶段。如果计算者(P2)同时计算多个电路(为了提高置信度),而其中混入了错误的电路,P2可能会得到互相矛盾的输出结果。虽然看到不一致的结果就表明P1在作弊,但P2不能因此中止协议。因为P1可能故意让错误的电路只在P2的特定输入下才给出错误结果。如果P2只在这种情况下中止,那么中止行为本身就会泄露关于P2输入的信息给P1。因此,即使明知P1作弊,P2也必须继续执行协议。
传统解决方案:取多数结果。P2计算所有未被检查的电路,然后取大多数电路输出的结果作为最终答案。通过精心选择切分选择的参数(总电路数、检查比例),可以从数学上保证:只要所有被检查的电路都是正确的,那么未被检查的电路中,错误的数量占不到大多数的可能性是极小的(可忽略)。
Input consistency:由于“切分选择”会涉及多个混淆电路,恶意方可能会尝试对不同的电路使用不同的输入值,从而破坏协议的安全性。
确保P2(计算者)的输入一致性(较容易):P2通过不经意传输(OT)获取其输入导线的标签。P1(生成者)在准备OT时,可以将对应P2同一个输入比特的所有电路的标签打包在一起,作为一次OT的两个消息。这样,P2无论选择哪个消息,都将获得与该选择比特对应的、适用于所有电路的标签,从而被迫在所有电路上使用一致的输入。
确保P1(生成者)的输入一致性(更具挑战):Shelat和Shen的方案:修改要计算的函数。不再只计算 F(x, y),而是计算 (F(x, y), H(x, r)),其中:H 是一个2-全域哈希函数(2-universal hash function),r 是P1加入的额外随机数。
1.P1先承诺其输入(例如,发送所有混淆电路)。
2.P2随机选择一个哈希函数H。
3.双方共同计算包含H的新函数。
4.如果P1在不同电路中使用了不一致的输入x和x’,那么由于H的性质, 和 的输出值大概率会不同,P2可以通过检查输出的一致性来检测作弊。
5.随机数r的作用是隐藏P1的真实输入x,防止其通过哈希输出H(x, r)泄露。
效率:通过选择特定的2-全域哈希函数(如乘以随机布尔矩阵),计算H的电路可以只包含异或(XOR)门,利用FreeXOR技术,增加的开销很小。
Selective abort:即使混淆电路本身是正确的,恶意的生成者P1仍然可以在不经意传输(OT)阶段作弊,提供错误的导线标签。P1可以故意让这种错误只在计算者P2的输入满足特定条件时才发生(例如,当P2的第一个输入比特为1时,才给错误的标签)。如果P2在收到错误标签时中止协议,那么中止行为本身就向P1泄露了关于P2输入的信息。
解决方案:k-探针抗性矩阵 (k-probe-resistant matrices)
1.核心思想:由Lindell和Pinkas提出,其思路是让P2先将其真实输入y编码成一个更长的、随机化的版本ỹ,使得y = Mỹ,其中M是一个公开的特殊矩阵。
2.协议修改:P2在OT中使用编码后的ỹ的比特作为选择位,而不是原始的y。混淆电路计算的目标函数也相应修改为F(x, Mỹ)。
3.矩阵的关键性质 (k-probe-resistance):这种矩阵保证,编码后的ỹ中任意k个比特的联合分布都是均匀随机的,并且与原始输入y完全无关。
4.安全原理:如果P1最多只在k个OT中作弊,那么P2是否中止将取决于ỹ中的最多k个比特。因为这k个比特是完全随机且独立于y的,所以P2的中止条件与真实输入y无关。如果P1在超过k个OT中作弊,P2将以极高的概率(至少1 - 1/2^k)检测到并中止,无论其输入y是什么。
5.效率:编码操作Mỹ只涉及异或运算,在FreeXOR优化下几乎没有计算开销。主要的代价是由于ỹ比y长,需要执行更多的基础OT。
Concrete parameters:复制因子 (ρ):生成者(P1)必须生成的混淆电路的总数量。检查概率/数量 ©:在切分选择阶段,每个电路被选中进行检查的概率(或直接指定检查的数量)。目标:在保证足够安全性的前提下,最小化所需的复制因子ρ。
安全要求:必须防止攻击者成功做到:所有被检查的电路都正确,但未被检查的电路中大多数是错误的。
抽象游戏:可以将攻击者的任务想象成一个游戏:玩家准备ρ个球,任意涂成红色(错误电路)或绿色(正确电路)。随机选择c个球进行检查。如果检查的球中有任何红球,玩家输。如果未被检查的球中,红球占多数,玩家赢。
参数选择:我们需要找到最小的ρ和最优的c,使得任何玩家赢下这个游戏的概率不超过2^{-λ}(λ是安全参数)。
Shelat和Shen (2011) 的分析发现,最优参数为:复制因子 ρ ≈ 3.12λ。检查数量 c = 0.6ρ (令人意外的是,不是0.5ρ)。
Cost-aware cut-and-choose:标准方法的局限性:Shelat和Shen (2011) 给出的最优参数假设“检查”电路和“计算”电路的成本相同。
实际成本差异:
计算成本:“计算”一个混淆电路比“检查”它要便宜得多(大约便宜50-75%),因为计算只涉及电路的一条路径,而检查需要验证所有混淆表条目。
通信成本:在某些使用哈希承诺和种子重构的协议变体中,“检查”电路的通信成本几乎为零(只需发送种子),只有“计算”电路需要大量通信。
成本感知的优化:Zhu等人 (2016) 重新分析了切分选择游戏,推导出了新的最优参数,这些参数明确考虑了“检查”和“计算”操作在计算和通信上的不同成本。
6.2 Input Recovery Technique
传统切分选择需要计算者(P2)计算多个电路并取多数结果,其电路复制因子约为 3.12λ(λ为安全参数)。Lindell (2013) 和 Brandão (2013) 独立提出了一种新协议,它能让P2即使在计算结果不一致时也能识别出正确的输出。因此,恶意的P1必须让所有未被检查的电路都以相同的方式输出错误结果才能成功作弊,这比仅仅让大多数电路出错要困难得多。在这种新方法下,P1作弊成功的概率(即所有坏电路都躲过检查)约为2^{-ρ}(ρ为总电路数)。这意味着,只需要 ρ = λ 的电路复制因子就能达到2^{-λ}的安全强度,远优于之前的 3.12λ。
执行分为两个阶段:
1.双方执行一个相当标准的切分选择流程:P1生成许多混淆电路,P2检查一部分,计算另一部分。如果P2在计算阶段发现不同电路给出了不一致的输出,这意味着他获得了对应同一个输出导线的、代表相反值的两个标签(例如,一个标签代表0,另一个代表1)。这对矛盾的标签本身就是P1作弊的铁证,因为诚实的P1不可能生成这样的标签。但P2绝不能向P1透露他是否获得了这个“作弊证据”,因为这个事件可能与P2的输入有关,透露它会泄露P2的隐私。
2.双方再进行一次恶意安全的多方计算(MPC),计算一个特殊的“输入恢复函数”。如果P2能(在这次MPC中安全地)出示他在阶段一获得的“作弊证据”,那么这个函数就会“惩罚”P1,将其原始输入x泄露给P2。此时P2拥有双方输入,可以直接在本地计算出正确结果。如果P2没有作弊证据,那么这次MPC计算不会给P2任何额外信息。无论哪种情况,P1都不会从阶段二的计算中学到任何关于P2的信息。
关键技术细节与保证:
1.阶段二的实现:阶段二的安全计算本身可以用传统的、基于多数结果的切分选择来实现,但其电路大小只依赖于P1输入的大小,与阶段一计算的复杂电路无关,因此开销可控。
2.防止伪造证据:需要特殊处理输出导线标签,并延迟打开阶段一的检查电路,以防止P2伪造作弊证据。
3.输入一致性:必须确保P1在两个阶段都使用相同的输入x,即使作弊也不能阻止x在阶段二被恢复。
4.隐藏执行路径:P1最终无法知道P2是通过阶段一正常获得结果,还是通过阶段二的“惩罚”获得结果。因此,阶段二必须始终执行,即使P1在阶段一被抓包。
6.3 Batched Cut-and-Choose
批量切分选择(Batch Cut-and-Choose)是一种用于摊销多次执行相同函数的安全计算(如混淆电路)开销的优化技术。
问题:为N次独立计算执行N次标准的切分选择,总开销巨大。
解决方案:只执行一次更大规模的切分选择,其结果用于所有N次计算。
修改后的流程:
1.P1生成一个巨大的电路池(Nρ + c个)。
2.P2随机选择c个进行检查。
3.P2将剩余的Nρ个电路随机分配到N个“桶”(buckets)中,每个桶ρ个,对应一次计算。
4.安全目标变为:确保没有任何一个桶只包含错误的电路(假设协议只需要桶内至少有一个正确电路即可,如使用了输入恢复技术)。
更高的安全性/效率:对攻击者来说,作弊更难了。错误的电路不仅要躲过初始检查,还必须“运气爆棚”地被集中分配到同一个桶里。
显著降低复制因子:所需的每个计算实例的电路数量ρ大大减少。渐进分析表明,ρ可以降低到几乎是常数(2 + Θ(λ/log N)),远优于单实例所需的O(λ)。
实际效果显著:即使对于中等数量的批量计算(如N=1024),每个实例所需的计算电路数量可以降至非常小的值(如ρ=5)。
6.4 Gate-level Cut-and-Choose:LEGO
LEGO范式是一种用于构建恶意安全两方计算协议的高效方法。
基础:利用了“批量切分选择”中,随着批量增大,摊销到每个实例的成本会降低的特性。
创新:LEGO将“切分选择”的应用粒度从整个电路缩小到了单个逻辑门(具体来说是与非门NAND)。
流程:
1.批量生产与抽检:P1生成大量独立的混淆与非门。双方对这些门进行一次“批量切分选择”:P2检查一部分,将剩下的随机分到不同的“桶”(buckets)里。
2.焊接组装 (Soldering):将这些桶里的门“焊接”起来,组装成目标电路。容错门:每个桶内的门被特殊连接,共同构成一个“容错的混淆与非门”。即使桶里混入少数坏门,通过取多数输出的方式,也能得到正确的计算结果。
更低的复制因子:即使只计算一个电路,LEGO也能利用批量切分选择的优势,达到 O(1) + O(λ/log N) 的有效复制因子(N是电路大小,λ是安全参数)。
优于传统方法:对于大型电路,这个复制因子显著优于传统电路级切分选择所需的 O(λ) 因子。
代价:“焊接”过程会引入额外的开销。
Variations on LEGO:研究者们提出了一系列优化LEGO协议的方法,主要包括:
更强的桶安全性:设计了一种新的桶构造方式,不再需要桶内大多数门正确,只要有一个门是正确的,桶的计算结果就是安全的。
更大的切分粒度:将“切分选择”的操作单位从单个门提升到由多个门组成的子电路。
“池化”与动态补充:不再需要一开始就生成所有可能用到的门,而是维护一个固定大小的门“池”,并在计算过程中动态地补充。
6.5 Zero-Knowledge Proofs
不同于“切分选择”通过大量重复和抽查来概率性地保证安全性,使用零知识证明(Zero-Knowledge Proofs, ZK)来增强半诚实协议这种方法是让参与方在执行(原本的)半诚实协议的每一步时,都附带一个零知识证明,向对方证明自己确实是按照协议规则来执行的。
ZK证明允许一方(证明者)向另一方(验证者)证明某个论断为真(例如,“我正确地执行了协议的这一步”),同时不泄露任何与该论断相关的秘密信息(例如,计算中使用的私有数据)。
基础:从一个只能抵抗半诚实攻击者的MPC协议开始。
增强:在协议的每一步,发送消息的一方都需要同时生成一个零知识证明,证明其发送的消息是根据协议规则和其(秘密)内部状态诚实计算得出的。
验证:接收消息的一方在收到消息和证明后,会先验证这个零知识证明。只有证明通过,他才会接受这条消息并继续协议;否则,他知道对方在作弊,可以中止协议。
确定性:与切分选择的概率性保证不同,ZK方法通常能提供更强的确定性保证。
通用性:Goldreich等人证明,原则上任何半诚实MPC协议都可以通过这种方式转化为恶意安全的协议。
6.5.1 GMW Compiler
GMW编译器是一个利用零知识证明(ZK)将半诚实安全的多方计算(MPC)协议自动转换为恶意安全协议的通用方法。
目标:将任何仅能抵抗“诚实但好奇”攻击者的半诚实协议 π,升级为能抵抗任意“作恶”攻击者的恶意安全协议。
方法:在运行原始协议 π 的同时,要求每一方在发送每一条消息时,都必须附带一个零知识证明。这个证明向接收方证实:这条消息确实是该发送方诚实地按照协议 π 的规则,基于其(秘密)输入和(秘密)内部状态计算得出的。
验证与安全:接收方在收到消息后,会先验证附带的ZK证明。如果验证失败,接收方就知道发送方作弊并中止协议。ZK证明保证了恶意方要么诚实执行(此时半诚实安全性生效),要么作弊但被抓住。同时,ZK证明的“零知识”特性确保了验证过程本身不会泄露任何关于发送方秘密输入的信息。
输入一致性:如何确保恶意方在协议的不同阶段始终使用同一个输入?
解决方案:协议开始时,让每一方先对其输入进行承诺(Commitment)。之后的所有ZK证明都必须引用这个承诺,证明消息与承诺的输入是一致的。
随机性控制:如何防止恶意方通过精心挑选对自己有利的随机数(random tape)来进行攻击?
解决方案:“抛币入井”(Coin-tossing into the well)技术。以P1为例:P1先承诺一个随机串r;P2再发送一个公开的随机串r’;P1必须使用r ⊕ r’作为其后续协议执行的随机源。这样,P1就无法单方面控制其随机性。ZK证明同样需要验证P1确实使用了这个合成的随机源。

6.5.2 ZK from Garbled Circuits
JKO协议是一种基于混淆电路 (Garbled Circuits, GC) 的高效零知识证明 (Zero-Knowledge Proof, ZK) 方案。
问题:传统的基于切分选择的MPC协议来实现ZK需要生成大量混淆电路,效率低下。
JKO的创新:利用ZK证明中验证者(Verifier)没有秘密输入这一特性,让验证者扮演混淆电路的生成者(Garbler)角色,从而仅需一个混淆电路即可完成证明。
假设证明者P1想向验证者P2证明,它知道一个秘密w使得公开函数F(w)=1。
1.假设证明者P1想向验证者P2证明,它知道一个秘密w使得公开函数F(w)=1。
2.证明者(P1)获取输入:P1使用不经意传输(OT)获取其秘密w对应的混淆电路输入标签。
3.证明者计算并承诺:P1计算混淆电路,得到代表输出1的标签,并对该标签生成一个承诺(Commitment)发送给P2。
4.验证者打开电路,证明者检查:P2公开生成该混淆电路的所有秘密(导线标签等)。P1检查电路是否被正确生成。
5.证明者打开承诺,验证者验证:如果电路正确,P1打开之前对输出标签的承诺。P2检查该标签是否确实是代表1的那个正确标签。
抵抗作弊证明者(Soundness):P1在不知道电路内部秘密的情况下(步骤4之前)就必须提交承诺(步骤3)。如果P1不知道有效的w,它无法猜中正确的输出标签来生成承诺。
零知识性(Zero-Knowledge):P2(作弊验证者)只在P1确认电路正确后才能看到最终的输出标签承诺,无法从中获取关于秘密w的任何额外信息。
效率:由于此协议主要保证真实性而非隐私性(验证者自己生成电路,不怕自己知道秘密),可以使用更廉价的混淆电路构造(如半门技术),将每个与门(AND gate)的开销降至一个密文。
6.6 Authenticated Secret Sharing:BDOZ and SPDZ
基于海狸三元组 (Beaver triples) 的安全多方计算 (MPC) 范式,可以通过选择合适的秘密分享机制来抵抗恶意攻击者。
要达到恶意安全,所使用的秘密分享机制必须满足三个关键属性:
1.加法同态性:份额可以直接进行加法运算。
2.隐私性(抗恶意):即使面对恶意攻击者,单个份额也不能泄露任何关于原始秘密值的信息。
3.可靠的“打开”机制(抗恶意):即使有恶意参与方捣乱,也能保证在“打开”份额(恢复秘密)时得到正确、一致的结果,或者检测到作弊行为。
6.6.1 BDOZ Authentication
BDOZ(Bendlin-Damgård-Orlandi-Zakarias)技术是一种通过信息论MAC(消息认证码)来增强秘密分享,使其能够抵抗恶意攻击者的方案。
目标:实现一种秘密分享机制,使其满足恶意安全下Beaver三元组范式的要求(隐私性、可靠打开、同态性)。
核心思想:在基础的加法秘密分享之上,为每个份额附加一个信息论MAC,用于验证份额的完整性。
MAC构造:使用一种简单高效的一次性信息论MAC:MAC_{K,Δ}(x) = K + Δ · x。Δ是一个全局共享的MAC密钥。K是与特定份额关联的本地MAC密钥。这个MAC能抵抗伪造,因为不知道Δ就无法为新消息生成有效MAC。
BDOZ分享机制
对于秘密x,其BDOZ分享[x]包含:
1.加法份额:P1持有x1,P2持有x2,满足x1 + x2 = x。
2.交叉认证:P1额外持有m1 = MAC_{K2, Δ2}(x1),即用P2的密钥对x1进行的认证。P2额外持有m2 = MAC_{K1, Δ1}(x2),即用P1的密钥对x2进行的认证。
满足恶意安全要求
隐私性:仅持有加法份额和对方MAC无法泄露秘密。
可靠打开:双方公开自己的份额和收到的MAC。P1用自己的密钥Δ1验证P2的份额x2和MAC m2是否匹配;P2用Δ2验证x1和m1。任何篡改都会导致MAC验证失败,从而检测到作弊。
同态性:当所有参与方使用相同的全局MAC密钥Δ时,MAC本身也具有加法同态性,允许本地计算份额的和、与常数的和/积。
适用性:BDOZ分享满足Beaver三元组范式的所有要求。
常用方法:实践中,常用于分享单个比特(在GF(2^k)域上)。生成BDOZ格式的海狸三元组(尤其是比特三元组)的当前最优方法是TinyOT方案,它利用OT扩展来高效生成大量经过BDOZ认证的比特份额,并进一步安全地计算它们的乘积以形成三元组。
6.6.2 SPDZ Authentication
SPDZ(Damgård-Pastro-Smart-Zakarias)协议是一种旨在实现常数大小份额的恶意安全MPC方案,克服了BDOZ份额大小随参与方数量线性增长的问题。
共享的全局MAC密钥:与BDOZ不同,SPDZ引入了一个全局MAC密钥 Δ,这个密钥不被任何单个参与方完全知晓。相反,每个参与方持有Δ的一个加法份额(例如,两方情况下 Δ = Δ₁ + Δ₂)。
SPDZ份额 [x]:对于秘密x,其SPDZ分享包含两部分:
1.x的加法份额(x = x₁ + x₂)。
2.Δ · x(可以看作x的一个信息论MAC)的加法份额(t₁ + t₂ = Δ · x)。
隐私性:仅持有加法份额无法泄露秘密。
可靠打开(关键创新):
1.双方先公开各自的x份额(x₁, x₂),得到一个(未经认证的)候选秘密值x。
2.核心验证:如果x是正确的,那么Δx - (t₁ + t₂) 应该等于0。这个验证可以拆分为两部分:P₁本地计算 Δ₁x - t₁,P₂本地计算 Δ₂x - t₂。双方各自承诺(Commit)自己的计算结果。
3.双方打开承诺,检查两者之和是否为0。若不为0,则中止协议。使用承诺是为了防止后行动的一方作弊。
安全性:成功伪造一个错误的x’并通过验证,等同于能够猜测出秘密的Δ,这是不可能的。
同态性:由于份额是加法形式的,自然支持加法和与常数乘/加的同态运算。与常数c相加时,需要利用Δ的份额来更新Δx的份额(即 Δx → Δx + Δc)。
适用性:SPDZ分享满足Beaver三元组范式所需的所有属性。
生成方法:最初的SPDZ论文使用半同态加密(Somewhat Homomorphic Encryption)来生成SPDZ格式的三元组。后续工作提出了更高效的方法,例如基于OT扩展。
6.7 Authenticated Garbling
认证混淆(Authenticated Garbling)技术是一种结合了信息论协议(如BDOZ认证分享、海狸三元组)和计算协议(如混淆电路、BMR)优点的恶意安全多方计算(MPC)方案。
出发点:重新审视BDOZ认证分享机制,发现其不仅分享了比特x,还隐含地分享了x · Δ₁(Δ₁是P1的全局MAC密钥)。
分布式混淆 (Distributed Garbling):
1.秘密置换位:不再让P1(生成者)单独知道混淆电路的置换指针位pᵢ。相反,双方共同持有这些比特的BDOZ认证分享 [pᵢ]。
2.海狸三元组:为每个与门准备相应的Beaver三元组,如[pₐ], [p<0xC2><0x82>], [pₐ · p<0xC2><0x82>]。
3.本地计算份额:P1知道混淆电路的导线标签kᵢ⁰。双方利用BDOZ分享和Beaver三元组的同态性,通过纯本地计算,得到最终混淆表条目(如e₀,₀)的加法份额。
4.发送与打开:P1将其计算出的混淆电路份额发送给P2,P2合并双方份额得到完整的混淆电路并进行计算。
安全性保证 (抵抗恶意P1)
解决选择性中止:即使P1发送了错误的混淆电路份额,导致P2在特定输入下中止,这不会泄露P2的输入信息。因为P1不知道底层的秘密置换位pᵢ,所以P2的中止行为对P1来说是输入无关的。
保证正确性 (Authenticating the Garbling):
1.问题:P1仍可能通过发送错误的份额来篡改计算结果(例如,翻转某个p<0xE1><0xB5><0xA9> ⊕ pₐ · p<0xC2><0x82>比特)。
2.解决方案:利用已有的pᵢ比特的BDOZ认证分享。将混淆电路进行增强:每个密文不仅包含输出导线标签,还包含P1对“正确”指针位(根据秘密pᵢ计算得出)的BDOZ份额及其MAC。
3.验证:P2在计算过程中,每解密一个门,就使用BDOZ的验证机制检查其可见的指针位是否与附带的MAC匹配。任何不匹配都表示P1作弊,P2可以安全中止。
显著提升:该协议带来了巨大的性能改进。
具体数据:在局域网(LAN)环境下,每秒可执行超过80万个与门,单个AES加密仅需16.6毫秒(在线时间0.93毫秒)。即使在广域网(WAN)下,也仅需1.4秒(在线时间77毫秒)。批量执行时,摊销成本更低。
历史对比:其恶意安全性能甚至远超几年前最好的半诚实协议。
6.8 Further Reading
Cut-and-Choose:早期作为“民间传说”存在,后来有无证明的方案提出,首个带完整证明的方案由Lindell和Pinkas (2007) 给出。需要解决选择性中止攻击(有多种方法,如k-探针抗性矩阵或承诺OT) 和输入一致性(有多种机制)。
Authenticated Secret Sharing:代表方案:BDOZ 和 SPDZ。存在其他高效方案及生成份额的优化技术。
GMW编译器 (基于零知识证明):利用零知识证明(ZK)强制参与方诚实执行半诚实协议。通常效率不高,因为它需要以“非黑盒”方式访问半诚实协议的内部逻辑,将其转换为电路进行证明。
MPC-in-the-Head (黑盒转换):一种“黑盒”方法,让真实参与方想象并安全地模拟一组“虚拟”参与方执行(只需半诚实安全的)协议。用于模拟的MPC协议可以满足较弱的安全要求,整体效率较高,尤其在零知识证明领域产生了目前最高效的一些协议。
7 Alternative Threat Models
可以通过放宽安全假设来设计更高效的安全多方计算(MPC)协议,以寻求更好的安全性与性能之间的权衡。
两种主要的放宽思路:
1.假设“诚实占多数” (Honest Majority)
核心思想:不再假设任意数量的参与方都可能是恶意的,而是假设至少有一半以上的参与方会遵守协议。
优势:这个假设能带来显著的性能提升。
2.超越“半诚实/恶意”的二元模型
核心思想:即使仍然允许任意数量的参与方被腐化,也可以探索介于纯粹“半诚实”和完全“恶意”之间的、更贴近现实场景的安全模型。
动机:标准的将半诚实协议转化为恶意协议的方法开销巨大,不一定实用。现实应用往往有更细致的安全需求。
7.1 Honest Majority
传统模型:通常的安全模型假设敌手可以腐化任意数量的参与方,最坏情况是n-1个(共n个)。
诚实多数假设:这是一种更宽松的假设,即敌手最多只能腐化严格少于一半(< n/2)的参与方。
“自然”的阈值:这个假设之所以“自然”,是因为它是一个重要的安全分界线。
关键优势:在保证诚实占多数的前提下,任何函数都可以实现信息论安全的MPC协议(即,即使敌手拥有无限算力也无法破解)。而如果允许腐化一半或更多参与方,则存在无法实现信息论安全的函数。
7.1.1 Building on Garbled Circuits
问题:标准的两方姚氏混淆电路(Yao’s GC)要实现恶意安全,开销巨大。
解决方案:引入第三个参与方,改变角色分工。
1.双生成者:让两方(P1, P2)共同扮演电路生成者(Garbler)的角色。
2.单计算者:让第三方(P3)扮演电路计算者(Evaluator)的角色。
安全性保证:
1.P1和P2先约定好随机数,然后独立地用相同的随机数生成混淆电路,并将结果都发送给P3。
2.P3只需检查收到的两个混淆电路是否完全相同。
3.由于假设至少有一方(P1或P2)是诚实的,如果两个电路相同,那么这个唯一的电路必定是正确生成的。
无需OT:协议巧妙地避免了昂贵的不经意传输(OT)操作。
输入处理:计算者P3将其输入进行秘密分享,并将份额(明文)分别发送给P1和P2。P1和P2各自发送其收到的份额对应的混淆输入标签给P3。电路本身会先重构P3的输入份额。
高效率:整个协议只依赖于廉价的对称密钥密码学(如哈希函数、分组密码),计算和通信效率很高。
该基础协议已被进一步扩展,以提供公平性(Fairness)和保证输出交付(Guaranteed Output Delivery)等更强的安全属性,并被推广到能抵抗更多(约√n个)腐化方的场景。
7.1.2 Three-Party Secret Sharing
本章节讲述了了在“诚实占多数”(具体是3方中最多1方被腐化)假设下,如何实现极高效率的安全多方计算(MPC),特别是优化乘法操作。
信息论安全可行:在诚实多数假设下,可以实现信息论安全(抵抗无限算力攻击者)。
极低通信成本:这些协议性能极高,通信开销可以做到极低,甚至每个门只需要一个比特。
基础:沿用经典协议(如BGW)的思想,电路中的值都以加法秘密分享 [v] 的形式存在。
加法:通过本地计算即可完成(利用同态性)。
乘法(核心挑战):需要交互和通信。
乘法优化方案(3方,最多1方腐化)
1.Sharemind (Bogdanov et al.)
分享方式:使用简单的3-out-of-3加法分享(v = v₁ + v₂ + v₃),而非需要门限的Shamir分享。
乘法协议:更简单,每个参与方发送7个环元素。
2.Launchbury et al. (Round-Robin)
乘法协议:效率更高,每个参与方只需发送3个环元素。
通信模式:采用轮循(Round-Robin)模式(P₁→P₂→P₃→P₁)。
原理:通过一轮轮循分享,使得每个参与方都能计算出x*y展开式中的部分交叉项,足以恢复[xy]的份额。最后需要加入一个随机的0的分享来保证结果的随机性。
3.Araki et al. (Replicated Sharing Variant)
分享方式:一种复制秘密分享的变体,每个参与方持有两个值。
乘法协议(最高效):每个参与方仅需发送1个环元素,同样采用轮循模式。
无交互随机数:利用巧妙的密钥共享(P1持有k1,k2;P2持有k2,k3;P3持有k3,k1)和伪随机函数(PRF),可以非交互地生成协议所需的“0的加法分享”,极大降低了通信开销。
性能:达到了惊人的每秒70亿门的计算速度,足以用MPC替代Kerberos认证服务器。
上述Araki等人的协议是半诚实安全的。Furukawa et al. 的扩展:将其扩展到了恶意安全(针对布尔电路)。
方法:采用Beaver三元组范式,利用Araki等人的高效乘法协议来生成所需的三元组 [a], [b], [ab]。
关键性质利用:Araki协议的乘法即使被恶意方干扰,也只会产生一个合法的、但值可能错误的分享 [ab’],而不会产生无效分享。
交叉检查:通过生成多组三元组并进行“交叉检查”,可以验证三元组的正确性。
7.2 Asymmetric Trust
现实场景:标准MPC模型假设所有参与方互相不信任,但现实中往往存在信任程度的差异(例如,客户对银行的信任度通常高于银行对客户的信任度)。
动机:客户可能信任银行不会主动作恶(可视为半诚实),但仍希望通过MPC防止因数据泄露或法律强制导致的信息暴露。
问题:直接套用标准的半诚实MPC协议,虽然保护了客户隐私,却反而将银行置于恶意客户的攻击之下(客户有机会在协议中作弊)。
1.混合安全模型:提出一种更贴合实际的模型,假设一方(如银行/生成者P1)是半诚实的,而另一方(如客户/计算者P2)是恶意的。
姚氏混淆电路 (Yao’s GC) 的优势:幸运的是,姚氏GC协议及其变体天然地就能抵抗恶意计算者(P2)。只要基础的OT协议安全,恶意计算者偏离协议只会导致计算失败,无法获得错误结果或泄露信息。这使得在该混合模型下,可以实现接近半诚实协议的效率。
2.服务器辅助计算 (Server-aided MPC):这是另一种利用非对称信任的模式。
模型:引入一个没有输入输出的、拥有较强计算资源的外部服务器(如云服务商)来协助其他(可能恶意的)参与方进行计算。
信任假设:通常假设这个服务器是半诚实的,并且不会与其他任何参与方合谋。
优势:利用这种非对称信任和无合谋假设,可以获得显著的性能提升,例如实现极大规模的隐私集合求交(PSI)。
7.3 Covert Security
问题:在某些场景下(如银行),假设一方(P1)完全半诚实可能不够安全,因为即使是受信任的机构也有作弊动机,且缺乏外部验证手段。但直接采用完全恶意模型又会导致不可接受的性能损失。
解决方案:引入概率性检查。允许计算者(P2)在协议执行过程中,以一定的概率随机挑战生成者(P1),要求P1证明其构造的混淆电路是正确的。
安全保证:作弊的P1会被以一个固定的概率 ε(称为威慑因子)抓住。如果P1无法通过挑战,P2就知道其作弊并采取相应措施。
如何精确定义这种“可能被抓住”的安全性是一个微妙的问题。Aumann和Lindell提出了三种形式化模型:
1.失败模拟 (Failed Simulation):允许理想世界中的模拟器(代表作弊方)有时会“失败”(即其模拟结果与真实世界可区分)。模型保证,抓住作弊的概率至少是模拟器失败概率的 ε 倍。
缺陷:无法阻止P1根据P2的输入选择性地尝试作弊。
2.显式作弊 (Explicit Cheat):在理想世界模型中,明确赋予敌手(模拟器)一个“作弊”指令。作弊必须独立于诚实方的输入。如果敌手选择作弊,他能得到诚实方的输入,但诚实方会以概率 ε 检测到作弊。
缺陷:即使作弊被抓住,作弊者依然能得到秘密输入(“抢银行被抓还能保留赃款”)。
3.强显式作弊 (Strong Explicit Cheat):与“显式作弊”类似,但关键区别在于:如果作弊被检测到,作弊者无法获得诚实方的输入。
结果:前两种(较弱的)模型并未流行,因为第三种“强显式作弊”模型提供了强得多的安全保证(更有效的威慑),同时存在效率相近的协议能够实现它。
结论:由于其简洁性、有效的威慑力以及存在简单高效的实现协议,“强显式作弊”模型成为了带有威慑的安全的标准定义。
7.3.1 Covert Two-Party Protocol
本章节讲述了Aumann和Lindell提出的、用于实现**带有威慑(covert security)**的两方计算(2PC)的协议,该协议基于姚氏混淆电路(Yao’s GC)和恶意安全的OT。
核心流程 (以威慑因子 ε = 1/2 为例)
1.生成双份电路:P1(生成者)使用两个独立的随机种子s₀, s₁,通过伪随机生成器(PRG)确定性地生成两个相同功能的混淆电路C0和C1,并将它们都发送给P2。
2.执行恶意安全OT:双方执行恶意安全的OT协议,P2获取其输入对应的导线标签(这些标签也是由种子生成的)。
3.P2随机挑战:P2随机选择一个比特b(0或1)。
4.P1打开被挑战电路:P1将对应于b的种子s_b发送给P2。
5.P2检查:P2使用收到的种子s_b重新生成混淆电路Cb,并与之前收到的版本进行比较。如果不一致,则检测到P1作弊。
6.P2计算未被挑战电路:如果检查通过,P2使用未被打开的那个电路C1-b进行计算,得到最终结果,并将结果也发送给P1。
抓住电路构造作弊:如果P1构造了错误的混淆电路,有50%的概率会被P2抽中检查并发现。
防御OT输入替换/选择性中止:问题:仅仅检查电路本身不够,P1还可能在OT阶段提供错误的标签,特别是针对P2的特定输入(选择性中止)。解决方案(输入XOR树):修改原始电路。将P2的每个原始输入比特xᵢ替换为σ个随机比特xᵢ₁, …, xᵢ<0xE2><0x82><0x83>,要求它们的异或和等于xᵢ。电路首先计算这些比特的异或和来恢复xᵢ,然后再进行后续计算。P1必须同时猜中所有σ个随机比特才能成功进行选择性攻击,这发生的概率极小。
防御备用密钥攻击 (Alternate Keys):问题(理论上):P1可能构造一个具有两套密钥的电路,一套用于通过检查,另一套用于在计算时作恶。解决方案:P1在发送混淆电路时,同时发送对其输入导线标签的承诺。之后不再直接发送标签,而是发送相应的去承诺值。
威慑效果:整个协议保证P1的任何作弊行为都有至少ε=1/2的概率被抓住。通过生成更多电路并检查除一个之外的所有电路,可以任意提高这个概率。
7.4 Publicly Verifiable Covert(PVC) Security
隐蔽安全模型的局限性:标准的隐蔽安全模型虽然能以一定概率抓住作弊者,但提供了较弱的威慑力。被抓住的一方(诚实方)很难向公众可信地指控作弊方,因为这可能需要泄露自己的隐私,或者协议本身不提供消息来源的认证。
PVC的目标:增强威慑力。要求当诚实方抓住作弊行为时,能够生成一个公开可验证的“作弊证明”(cryptographic proof of cheating),任何第三方都可以验证该证明的有效性。这将极大地增加作弊的风险和成本。
PVC的三个核心属性:
1.检测到作弊时,诚实方总能生成可验证的作弊证明。
2.作弊证明无法被伪造(不能诬陷诚实方)。
3.作弊证明本身不泄露诚实方的任何私有数据。
Asharov-Orlandi PVC协议 протокол
基础:基于Aumann-Lindell的隐蔽安全协议(生成λ个电路,检查λ-1个)。
核心机制:
1.签名:要求生成者P1拥有公私钥对,并对其发送的所有消息(包括混淆电路)进行签名。
2.通过OT隐藏挑战:为了防止P1根据P2的挑战选择性中止或发送假签名,P1打开被检查电路的操作是通过1-out-of-λ OT完成的。P1为每个可能的未被检查电路i准备一份“开路资料包”(包含其他所有电路的种子和i电路的输入标签),P2随机选择一个γ通过OT获取对应的资料包。这样P1就不知道哪个电路最终被计算。
3.签名OT (Signed-OT):为了防止P1在OT阶段提供无效的“开路资料”,协议使用了一种特殊的签名OT。签名OT保证接收方收到的消息m_b必然附带发送方对(b, m_b)的有效签名。
结果:如果P2检测到作弊(例如收到的电路种子与之前承诺的不符,或电路构造错误),他将拥有一份由P1签名的、包含不一致信息的消息记录,这就是公开可验证的作弊证明。
局限性:该协议的签名OT严重依赖公钥操作,无法使用高效的OT扩展。
Kolesnikov-Malozemoff (KM) 签名OT扩展
目标:设计一个高效的、基于OT扩展的签名OT协议,消除每次OT都需要公钥操作的瓶颈。
核心挑战:
1.保护接收方R的隐私:作弊证明(R的视图)不能泄露R的选择比特。
2.防止R诬陷发送方S:防止恶意的R篡改自己的视图来伪造作弊证明。
KM的解决方案:
1.利用IKNP结构:观察到在IKNP OT扩展中,发送方S实际上能看到接收方R构造的矩阵M的部分列(对应S秘密s中为0的比特位)。
2.签名绑定:S在对其消息签名时,会包含其看到的M的这些列的信息。
3.基于种子的行验证:要求R的每一行都由一个种子生成,R的作弊证明必须包含这些种子,并且种子生成的行必须与S签名中包含的列信息一致。这使得R难以伪造证据。
优势:将签名OT的开销大幅降低到接近恶意OT扩展的水平,且可以从任何恶意安全的OT协议构建而来。
7.5 Reducing Communication in Cut-and-Choose Protocols
本节主要介绍了两种优化“切分选择”(Cut-and-Choose)协议通信开销的技术,特别是针对那些被检查(check)而非被计算(evaluate)的混淆电路。
使用哈希承诺 (Hashing / Commitments)
核心思想:与其让P1(生成者)发送许多完整的混淆电路(GCs)给P2(计算者),不如让P1先发送这些GCs的哈希值(作为承诺)。
流程:
1.P1发送ρ个GC的哈希值。
2.P2随机选择c个哈希值进行挑战。
3.P1只发送这c个被挑战GC的生成种子。
4.P2使用种子重新生成GC,计算哈希,并与P1最初发送的哈希值比较,以验证正确性。
5.P1只需要完整发送那些未被挑战、用于最终计算的GC。
优势:极大地减少了用于检查的电路所带来的通信开销,因为发送种子比发送整个GC要便宜得多。Kolesnikov和Malozemoff甚至利用此技术使PVC协议的通信成本接近半诚实的姚氏GC。
免费哈希 (Free Hash)
动机:虽然上述方法节省了通信,但计算哈希本身仍然有不可忽略的计算开销。
核心思想:由Fan等人提出,设计一种计算成本几乎为零的哈希方法。
实现:通过简单地异或(XOR)混淆表中(经过轻微修改的)条目来计算哈希值。
安全性权衡:放宽了对哈希函数的要求:不再要求找到碰撞是困难的。允许碰撞,但前提是:如果攻击者构造了一个哈希碰撞的恶意电路Ĉ’,那么这个Ĉ’在计算时极大概率会失败(从而暴露作弊行为)。
优势:哈希的生成与验证过程可以和GC的生成与计算过程深度融合,使得哈希计算几乎没有额外的计算成本。
7.6 Trading Off Leakage for Efficiency
本节主要讨论了在安全多方计算(MPC)中,通过放宽严格的恶意安全要求,来寻求更有吸引力的安全性与性能权衡。
1.双重执行 (Dual Execution)
动机:获得比半诚实安全更强、但比完全恶意安全开销更小的安全性。
核心思想:利用姚氏混淆电路(Yao’s GC)中“只有生成者容易作弊”的特性(假设OT是恶意安全的)。让双方同时扮演一次生成者和一次计算者,即并行执行两次姚氏协议,角色互换。
验证:双方在解码最终结果之前,通过一个恶意安全的相等性测试协议,比较两次执行得到的混淆输出是否一致。如果不一致,则中止协议。
安全保证与局限性:可以抓住大部分作弊行为。不是完全恶意安全。恶意方可以通过构造特殊的电路,使得协议是否中止依赖于诚实方的输入,从而泄露关于诚实方输入的最多一个比特的信息。
优化:后续工作优化了协议,如通过交织执行减少延迟,以及限制和降低泄露发生的概率。
2.内存访问泄露 (Memory Access Leakage) - 特别针对私有数据库查询
动机:对于涉及大规模数据(如数据库查询)的应用,完全安全的亚线性访问(如ORAM)开销极其巨大(慢3-4个数量级)。而简单的线性扫描又不现实。
核心思想:为了大幅提升效率,故意允许协议泄露一些关于访问模式的“受控”信息。
基本泄露:即使在半诚实模型下,任何亚线性的访问都会泄露信息(例如,服务器知道哪些数据没有被访问)。
实际系统:一些加密数据库系统(如Blind Seer)使用MPC作为底层技术(例如,安全地遍历搜索树),但接受了一定的访问模式泄露以换取实用性。
开放性问题:如何精确理解和量化这种泄露信息的实际影响,并在泄露与效率之间做出恰当的权衡,仍然是一个重要的开放性研究问题,并且已有利用此类泄露进行攻击的研究。
7.7 Further Reading
本节讲述了在追求实用高效的安全多方计算(MPC)时,研究者们探索的几种安全性与性能权衡的策略。
1.放宽安全模型
动机:完全恶意安全的MPC开销巨大,不一定适用于所有场景。
方法:隐蔽安全 (Covert) / 公开可验证 (PVC):相比完全恶意安全,能带来10倍至40倍的成本降低。允许受控泄露 (Controlled Leakage):例如在私有数据库查询中泄露部分访问模式,可以带来数量级的性能提升。
关键考量:必须仔细分析泄露信息的影响,判断其风险是否可接受。
2.利用安全硬件 (Secure Hardware)
代表:Intel SGX、安全智能卡等。
权衡:以信任硬件制造商(能力、意图)为代价,换取显著的性能提升。
风险:硬件安全是一个持续的攻防博弈,严重漏洞(如密钥恢复、侧信道攻击)不断涌现。复杂硬件难以避免漏洞。
适用性:可能适用于MPC过慢、数据价值相对较低的场景,不适合需要高安全保证的场景。
3.理论与实践中的硬件安全研究
抗泄露密码学 (Leakage-Resilient Cryptography):理论研究方向,旨在构建能抵抗侧信道攻击(功耗、时序、电磁辐射等)的理想无泄露硬件。通常假设存在小的安全组件或泄露有界。
实用硬件安全:承认现实世界泄露的复杂性,更多采用启发式、实验性和缓解性的方法。
MPC结合硬件:一些MPC研究也利用(假设安全的)硬件令牌来计算基础功能(如PRF),以消除某些假设或提升性能。
8 Conclusion
本节讲述了安全多方计算(MPC)在过去十年取得的巨大进步、当前面临的主要挑战以及未来发展方向。
巨大进步
从理论到实践:MPC已从理论上的好奇心转变为构建隐私保护应用的实用工具。
成本急剧下降:部署MPC的成本在过去十年下降了3到9个数量级。
性能飞跃:
半诚实2PC:从约625门/秒提升到约300万门/秒。
恶意安全2PC:从约0.13门/秒提升到超过80万门/秒,提升了600万倍。
恶意安全3PC(诚实多数):甚至可以达到每秒10亿门。
当前挑战
尽管进步显著,MPC尚未广泛普及,主要面临以下挑战:
1.成本 (Cost):
绝对开销:相比普通计算,MPC仍有几个数量级的性能差距,尤其是在恶意安全模型下。
带宽瓶颈:当前主流的高效协议(如姚氏GC、GMW)的带宽开销与电路大小线性相关,在广域网或大规模计算中可能无法接受。
亚线性带宽方案:基于全同态加密(FHE)或函数秘密分享(FSS)的方案理论上可行,但离实用还有距离。
2.泄露与性能的权衡 (Leakage Trade-offs):
性能瓶颈:进一步提升通用协议(如姚氏GC)性能面临理论瓶颈(如AND门至少需2个密文)。
放宽安全保证:通过接受一定程度的受控信息泄露(如访问模式、输出噪声)来换取大幅性能提升成为一个重要研究方向。
ORAM瓶颈:安全随机内存访问(ORAM)仍然是扩展MPC到大数据应用的主要瓶颈,效率有待提高。
3.输出泄露 (Output Leakage):
问题:MPC只保护输入和中间过程,最终输出本身也可能泄露隐私。
解决方案:结合差分隐私 (Differential Privacy) 等技术来控制输出泄露,但这方面的研究尚处早期。
4.有意义的信任 (Meaningful Trust):
现实鸿沟:密码学协议假设参与方完全信任自己的执行环境,但现实中软件硬件复杂且可能存在漏洞或后门。
信任根问题:用户需要信任执行MPC协议的软硬件本身不会窃取其明文数据。即使运行相同的开源软件,理论上与直接交出数据给软件提供商差别不大。
MPC的潜在优势:如果能将数据分成份额,在两个独立系统上用MPC计算,则可能消除对单个系统实现的信任。
挑战:如何向普通用户清晰地传达数据风险和信任假设,是MPC等隐私技术普及的关键。
未来方向
混合协议 (Hybrid Protocols):结合通用MPC、定制协议、同态加密等多种技术,自动或半自动地为不同计算部分选择最优方案。
安全硬件 (Secure Hardware):利用Intel SGX等可信执行环境,在信任硬件厂商的前提下大幅降低成本。
泄露与效率的量化权衡:深入理解不同泄露模式的实际影响,并形式化地分析如何在满足特定隐私需求的前提下最大化效率。
MPC与差分隐私的深度融合:发展成熟的理论和工具,提供端到端的隐私保护。
构建可信执行环境与用户信任:研究如何降低对执行平台本身的信任依赖,并向用户提供可理解、有意义的安全保证。
总而言之,MPC领域虽然挑战重重,但发展迅速,潜力巨大,为设计新一代隐私保护应用提供了丰富的可能性。

助力合肥开发者学习交流的技术社区,不定期举办线上线下活动,欢迎大家的加入
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)