AI-Native 应用(图解+秒懂): 什么是 AI-Native 应用(AI原生应用)?如何设计一个 AI原生应用?
本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
2025年开始,尼恩一直在辅导小伙伴们做 AI 架构面试, 很多小伙伴 拿到了 Java + AI 架构offer ,比如下面的案例:
34岁无路可走,一个月翻盘,拿 3个架构offer,靠 Java+Al 逆天改命!!!
3年 程序媛 被裁, 25W-》40W 上岸, 逆涨60%。 Java+AI 太神了, 架构小白 2个月逆天改命
36岁/失业7个月/彻底绝望 。狠卷 3个月 Java+AI ,终于逆风翻盘,顺利 上岸
尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
- 《Python学习圣经:从0到1精通Python,打好AI基础》
- 《LLM大模型学习圣经:从0到1吃透Transformer技术底座》
- 《LangChain学习圣经:从0到1精通LLM大模型应用开发的基础框架》
- 《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
- 《SpringCloud + Python 混合微服务架构,打造AI分布式业务应用的技术底层》
- 《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
- 《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
- 《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
- 《 阿里面试:RAG 怎么优化?探讨一下 RAG优化的7大黄金法则 ?》
- 《LangChain 源码 + GOF设计模式:基于GOF的设计模式,穿透 LangChain 源码》
大厂最新的面试题: 如何设计一个 AI原生应用?
前段时候小伙伴面试网易,遇到一个最新的面试题:
什么是 AI-Native 应用(AI原生应用)?如何设计一个 AI原生应用?
在这里, 尼恩借助自己的 <LLM大模型学习圣经>, 基因尼恩20年的架构内功,给大家 做一个 起底式 + 穿透式的解答。
AI 原生应用(AI-Native App)的“原生”并不是指“只能在 AI 芯片上跑”,而是指:产品立项第一天就把大模型当成“CPU”来设计——模型即架构、数据即燃料、体验即对话。
一、AI 原生应用的核心原理
“AI-native” 目前非常 火, 和 曾经 的 " Internet-native “、” Cloud-native “或” Mobile-native "一样。
为何这么火?为何要使用这个概念? 主要是为了区分两类应用:
-
一类是通过 ai 强化和扩展现有产品的应用。这类叫做 AI插件应用(AI Plugin)
-
另一类是基于全新 ai 能力和理念从 0 开始构建的应用。这类叫做 AI原生应用(AI-native )
很多人一听到“AI原生”,就觉得是“只能在高级AI芯片上跑的复杂APP”——其实完全错了。
AI-native 应用的核心,是从设计第一天起,就把“AI大模型”当成了产品的“心脏”(就像汽车的发动机),而不是后来才贴上去的“小贴纸”(比如给传统APP加个AI客服插件)。
打个最通俗的比方:
- 传统软件:先盖好房子的框架(比如先设计“用户表”“订单表”),等房子盖完了,再装空调、洗衣机(加各种功能,包括AI);
- AI原生应用:先确定要装一台“超级发动机”(选好LLM大模型),再围绕这台超级发动机设计整个汽车的结构(比如电池放哪、座椅怎么摆)—— 从一开始就规划:这台超级发动机能跑多快?续航够不够?加油贵不贵? 这个超级发动机 (选好的LLM大模型)就是 核心。 。
二、 AI-native 设计范式
AI原生的核心逻辑, 总结起来就是 三句话:
-
靠“大模型”当骨架(不是先画表格);
-
靠“用户的每一次点击/停留”当“汽油”(用得越多越聪明);
-
靠“聊天”当主要操作方式(不用点半天菜单)。
AI-native 应用 设计范式 如下:
(1) 模型优先(Model-First)
传统软件先画 ER 图,AI 原生先选/训模型:用 LLM 的上下文长度决定会话窗口,用推理延迟决定交互节拍,用 Token 成本决定商业模型 。
(2) 数据飞轮(Data Flywheel)
每一次用户点击、停留、修正都是“标注”。应用把隐式反馈(停留时长)+ 显式反馈(点赞)回流到模型,24 h 内完成微调或强化学习,越用越聪明 。
(3) 事件驱动 & Agent 编排
用户输入不是“调接口”,而是“发事件”。
LLM 当大脑,Agent 调度工具:事件→意图识别→规划子任务→调用 API/数据库→汇总结果→自然语言返回。
(4) 多模态统一语义空间
文本、语音、图像在同一向量空间计算相似度,实现“拍一张图+一句话”混合查询,无需提前定义字段 。
(5) 持续学习 & 伦理对齐
用 Online RLHF(实时人类反馈)把“说错话”即时纠正;同时用 Constitutional AI 做价值观对齐,避免越学越偏 。
三、 AI-native 5个“核心零件”
就像汽车需要发动机、变速箱、油箱配合,AI原生应用也有5个“核心零件”,每个零件都有明确的作用,缺一不可:
1. 零件1:“心脏”——大模型(决定产品的“基础能力”)
传统软件一上来先想“要存哪些数据”(比如做购物APP,先列“用户表”“商品表”);
AI原生应用一上来先选“心脏”(大模型),还要想清楚三个关键问题:
- 能记多少话? 比如能记住你之前聊的10句话,还是100句话——这决定“你不用反复说同一件事”(比如你之前说过“我家在上海”,AI下次不会再问);
- 反应有多快? 点一下按钮,是0.1秒出结果还是1秒——反应慢了用户会不耐烦(比如你问“现在几点”,AI等3秒才回答,你可能早就打开手机时钟了);
- 用一次要花多少钱? 比如发1000个字要几分钱——这决定“怎么赚钱”(比如按使用次数收费,用100次收5块)。
简单说:先把“心脏”的性能定好,再设计其他部分。
2. 零件2:“加油站”——数据飞轮(越用越聪明)
你用APP时的每一个小动作,对AI来说都是“学习资料”,就像汽车加的汽油,能让“心脏”转得更有力:
- 显式反馈:你点“有用”“没用”“重新生成”——相当于直接告诉司机“这条路不对,换一条”;
- 隐式反馈:看了3秒就划走(可能觉得答案没用)、反复看某段内容(可能觉得有用)——相当于你没说话,但司机从你皱眉的表情里知道“你不满意”。
这些反馈会实时“喂”给大模型,24小时内就能调整:比如你觉得AI写的文案太官方,反馈后第二天它就会变得更口语化。就像你的助理跟你久了,越来越懂你的说话习惯。
3. 零件3:“手脚”——智能助手(帮你“动手干活”)
你跟AI说的话,不是“点个按钮调接口”(比如点“查天气”按钮,就是调天气API),而是“给它派个任务”(比如“帮我查今天北京天气,再推荐穿什么”)。
这时候,“智能助手”就像你的专属秘书,会按步骤干活:
(1) 先懂你要啥:知道你要“查天气+要穿搭建议”;
(2) 拆成小任务:第一步查天气,第二步根据天气推衣服;
(3) 自己找工具:查天气用天气API,不用你手动搜;
(4) 汇总结果:用大白话告诉你“北京今天25℃晴天,穿短袖+薄外套就行”;
(5) 有问题再调整:如果API查不到天气,会自动换另一个工具再试。
比如你让秘书订会议室,秘书会自己查空房间、发邀请邮件,不用你一步步教——这就是“智能助手”的作用。
4. 零件4:“全感官”——多模态(能看、能听、能读)
传统软件处理“文字”“图片”“语音”是分开的:比如你传一张蛋糕图,再问“怎么做”,它可能只认图片或只认文字,需要你额外说明“这是蛋糕”;
AI原生应用能把“文字、图片、语音”放进同一个“理解池”——比如你拍一张蛋糕图,再问“这个蛋糕要哪些材料”,AI能同时“看懂图片”(知道是奶油蛋糕)和“读懂文字”(知道要材料清单),直接给答案,不用你多解释。
就像人能同时“看路标+听导航”找路,不用分开处理。
5. 零件5:“刹车”——规矩清单(不让AI“乱说话”)
AI再聪明,也不能想说啥就说啥,得给它定“规矩”,就像汽车的刹车,防止“失控”:
- 实时纠错:你发现AI说错了(比如把“北京”说成“上海”),反馈后它马上改,下次不会再犯(比如你说“我刚说的是北京,不是上海”,AI会道歉并纠正);
- 守底线:提前给AI列“不准做的事”(比如不能说“老年人学不会用手机”“感冒了吃XX药”)——如果AI想输出违规内容,系统会自动拦住,改成合规的话(比如把“老年人学不会”改成“老年人多练习就能熟练用”)。
这些“规矩”就像给AI戴了个“紧箍咒”,确保它不会越界。
四、从零搭AI原生应用 7个 核心步骤
很多人觉得“搭AI原生应用要懂深度学习”——其实不用,先跟着下面的流程走,每一步都有明确的判断标准和简单操作:
步骤1:先判断:这个问题,真的需要AI吗?
不是所有“用户烦恼”都需要AI来解决。比如“算1+1”用计算器就行,“整理杂乱的会议记录”才需要AI。
先画个简单的判断流程,按这个来就行:
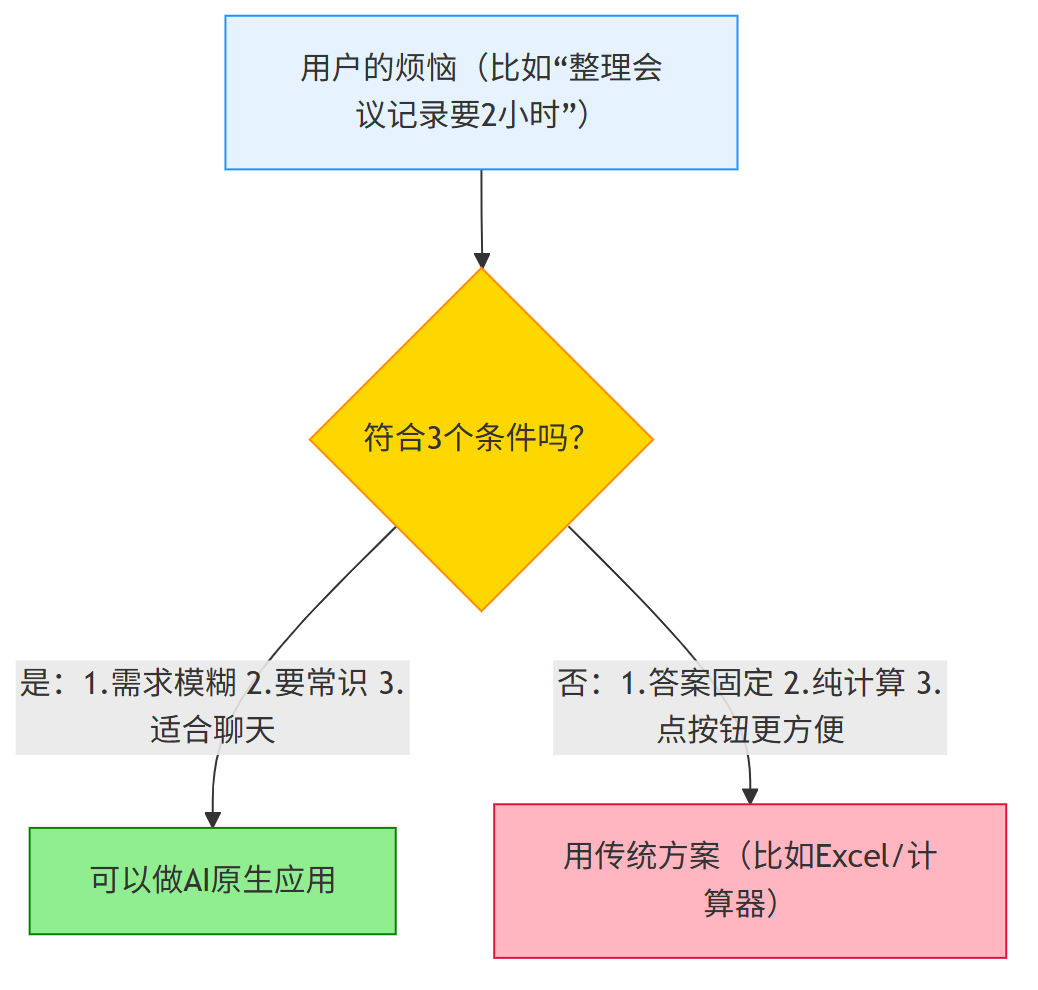
关键判断标准(举例说明):
| 条件 | 符合(适合AI) | 不符合(传统方案更好) |
|---|---|---|
| 需求模糊(没有固定答案) | “帮我把会议记录整理得简洁点”(简洁的标准因人而异) | “查今天北京的PM2.5数值”(答案是固定的) |
| 需要常识/推理 | “根据客户聊天内容,写一封跟进邮件”(要懂客户需求) | “按模板生成报销单”(填数据就行,不用懂) |
| 适合聊天操作 | “帮我退掉昨天买的黑色T恤”(说一句话比点5步菜单快) | “给文件重命名”(点一下输入框就行) |
比如“整理会议记录”符合所有条件,适合做AI原生应用;“算房租”不符合(纯计算),用Excel更简单。
步骤2:设计“汽油”——要收集用户的哪些行为数据?
AI需要“数据汽油”才能变聪明,所以先想:用户用APP时,哪些行为能反映“满意/不满意”?
流程很简单:
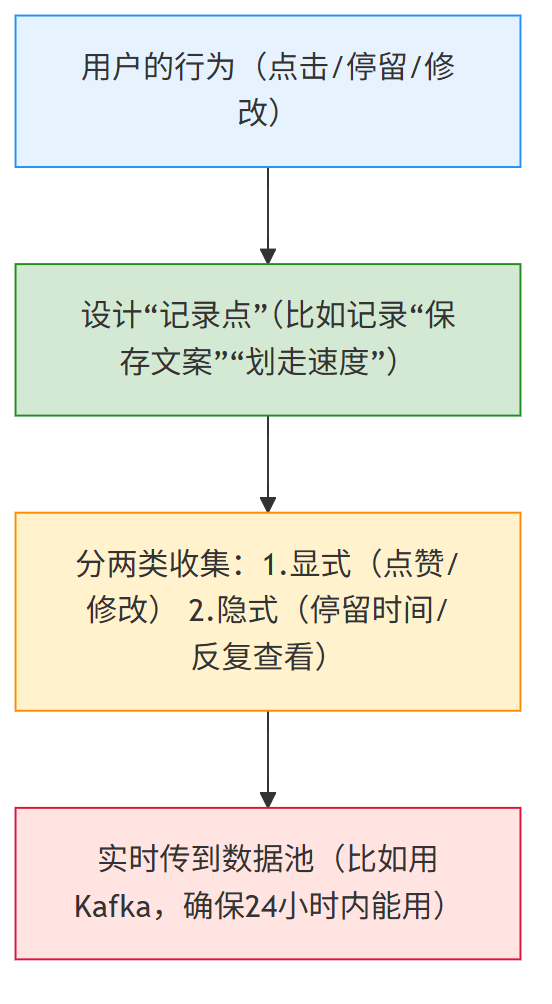
举个实际例子(做AI文案工具):
- 显式数据:用户点“保存文案”(满意)、“重新生成”(不满意)、“修改语气”(需要调整);
- 隐式数据:看文案超过10秒(可能满意)、看2秒就划走(可能不满意)、反复修改某句话(这句话需要优化)。
这些数据会实时存起来,给AI“喂饭”——比如发现很多用户划走“官方文案”,就调整模型,多生成口语化内容。
步骤3:选“心脏”——大模型+小模型配合
不用全靠“最顶级的大模型”(比如GPT-4),就像家里做饭,不用每次都用“米其林大厨”——简单的活让“小厨师”干,复杂的活让“大厨”上,又快又省钱。
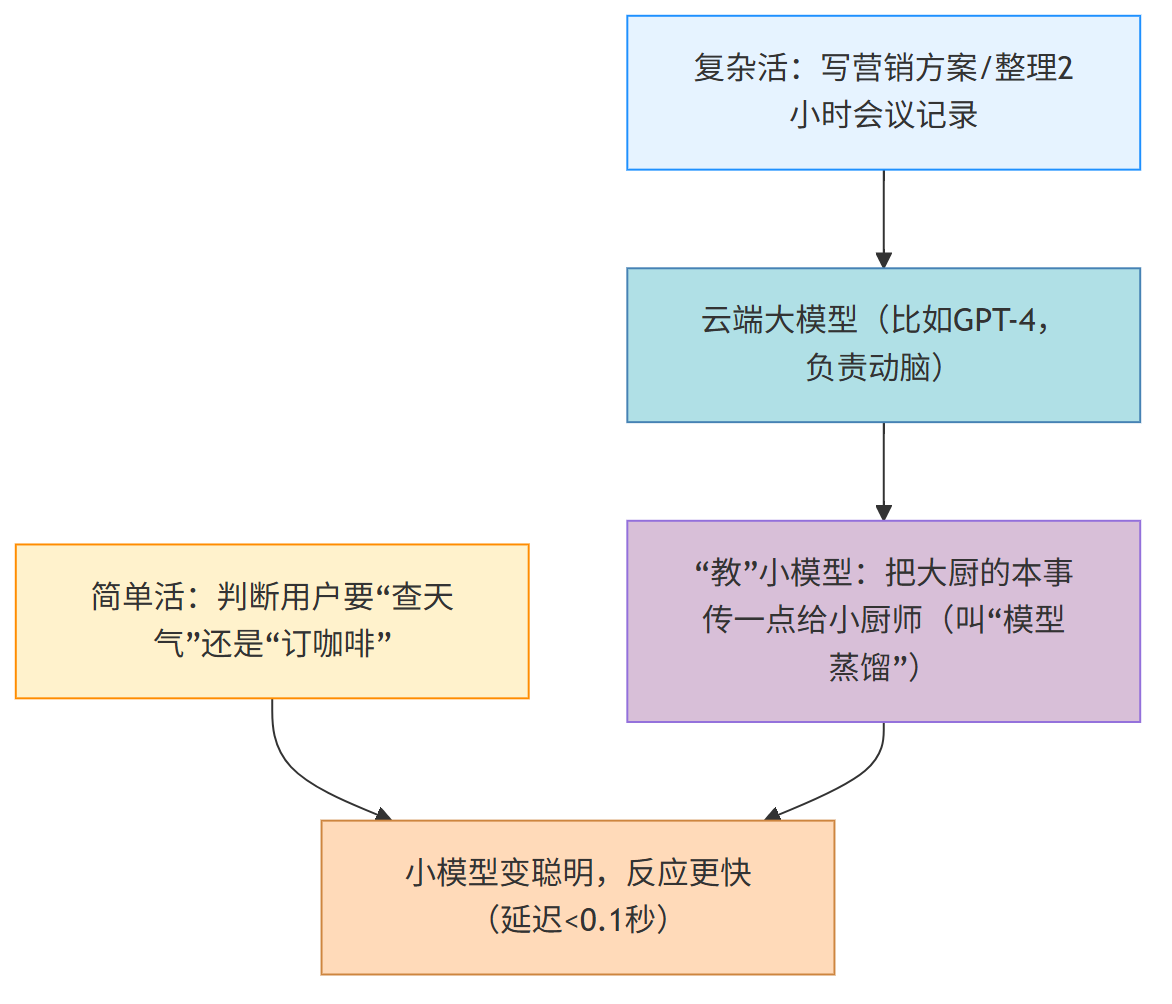
实际策略(比如做AI助手APP):
- 云端大模型(GPT-4):处理“写周报”“分析客户需求”这种需要“动脑”的活;
- 边缘小模型(MobileBERT):处理“识别语音指令”“判断用户要查天气”这种简单活,在手机本地运行,0.1秒就能反应;
- 模型蒸馏:把大模型“怎么判断‘查天气’意图”的经验,教给小模型——下次小模型自己就能处理,不用每次都找大模型,省成本。
步骤4:装“手脚”——把传统工具变成 AI的“手脚”
智能助手就是AI的“手脚”,能帮你调用工具(比如查天气API、发邮件),不用你手动操作。
比如你说“查今天北京天气并推荐穿什么”,智能助手会自己完成所有步骤。
先看智能助手的工作流程:
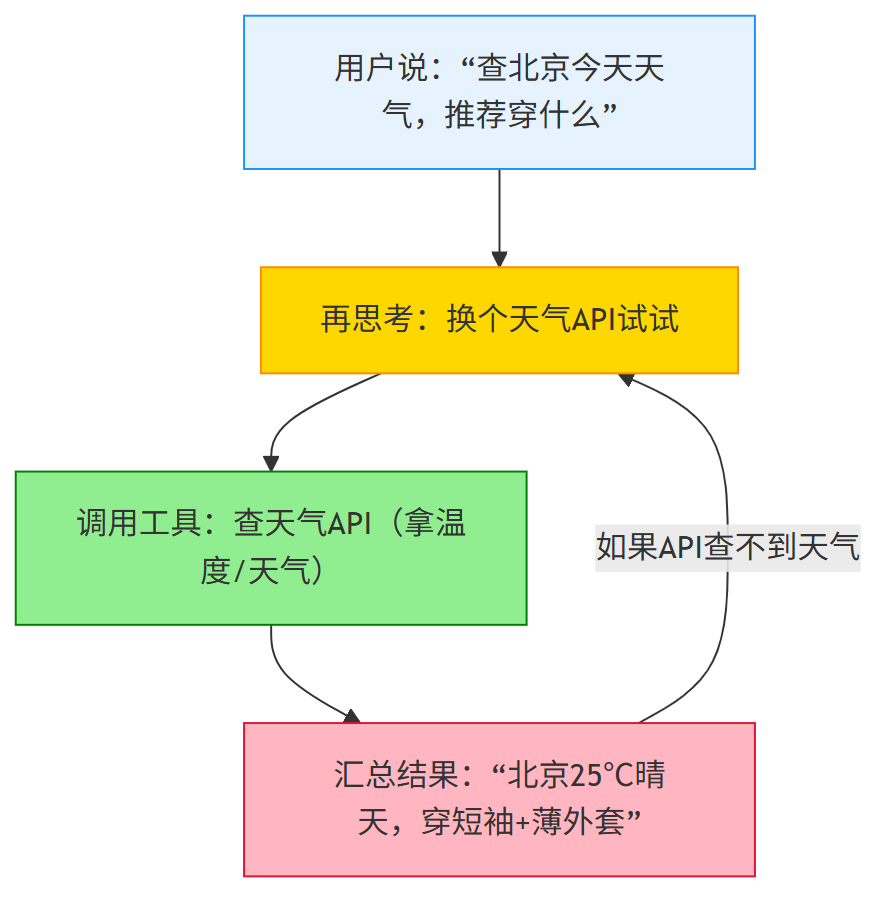
再看简单代码实现(Python):
不用懂复杂框架,这段代码模拟了智能助手“查天气+推穿搭”的过程,注释写得很清楚,跟着跑一遍就懂:
// 1. 工具1:查天气(这里用模拟数据,实际项目中换真实API)
def get_weather(city):
// 真实场景下,会换成高德/百度天气API(比如请求"https://restapi.amap.com/v3/weather/weatherInfo")
// 这里用模拟数据方便测试,避免调用真实API需要密钥
mock_weather = {
"北京": {"temperature": 25, "condition": "晴天"},
"上海": {"temperature": 28, "condition": "阴天"},
"广州": {"temperature": 30, "condition": "雨天"}
}
// 如果查不到城市,返回默认天气
return mock_weather.get(city, {"temperature": 20, "condition": "多云"})
// 2. 工具2:根据天气推荐穿搭(靠常识判断)
def recommend_outfit(weather):
temp = weather["temperature"] # 提取温度
condition = weather["condition"] # 提取天气状况
if temp >= 25 and condition == "晴天":
return "推荐穿短袖+薄外套,记得带防晒!"
elif 15 <= temp < 25:
return "推荐穿长袖+牛仔裤,早晚有点凉~"
elif temp < 15:
return "推荐穿毛衣+厚外套,注意保暖!"
else: # 雨天/阴天
return "推荐穿防水外套+运动鞋,记得带伞!"
// 3. 智能助手核心逻辑:处理用户需求→拆任务→调用工具→返回结果
def ai_assistant(user_input):
// 第一步:简单识别用户需求(实际项目中会用小模型识别,这里简化)
if "天气" in user_input and any(city in user_input for city in ["北京", "上海", "广州"]):
// 提取城市(比如用户说"查北京天气",就提取"北京")
city = next(city for city in ["北京", "上海", "广州"] if city in user_input)
// 第二步:调用查天气工具
weather_data = get_weather(city)
// 第三步:调用穿搭推荐工具
outfit_advice = recommend_outfit(weather_data)
// 第四步:汇总结果,用大白话返回
return f"【{city}今日天气】\n天气:{weather_data['condition']}\n温度:{weather_data['temperature']}℃\n【穿搭建议】{outfit_advice}"
else:
return "抱歉呀,我目前只能查北京、上海、广州的天气~"
// 测试:模拟用户输入
user_say = "查一下今天北京的天气,顺便推荐下穿什么衣服"
result = ai_assistant(user_say)
print(result)
代码详细解释(小白也能懂):
(1) get_weather函数:模拟“查天气”的工具,实际项目中,你只需要替换成“高德天气API”(需要去高德开放平台申请密钥),就能拿到真实天气数据;
(2) recommend_outfit函数:根据天气给穿搭建议,靠的是“常识逻辑”(比如温度≥25℃穿短袖),实际项目中可以让AI从用户反馈里学习(比如很多用户说“25℃穿短袖冷”,就调整成“26℃穿短袖”);
(3) ai_assistant函数:智能助手的“大脑”,先识别用户要查哪个城市的天气,再调用两个工具,最后把结果整合成大白话;
(4) 运行结果:会输出清晰的天气和穿搭建议,比如:
【北京今日天气】
天气:晴天
温度:25℃
【穿搭建议】推荐穿短袖+薄外套,记得带防晒!
步骤5:设计“操作方式”——多动嘴,少动手
传统应用 是 点击式 交互,主要用手, 要“点半天菜单” 才能完成自己的目标。 比如退个货:我的→订单→售后→申请退款 ;
AI原生应用 是 聊天 交互,主要用嘴, AI原生应用直接“聊天”就行。比如 你说“帮我退掉昨天买的黑色T恤”,AI会自己找到订单、发起退款,不用你多操作一步。
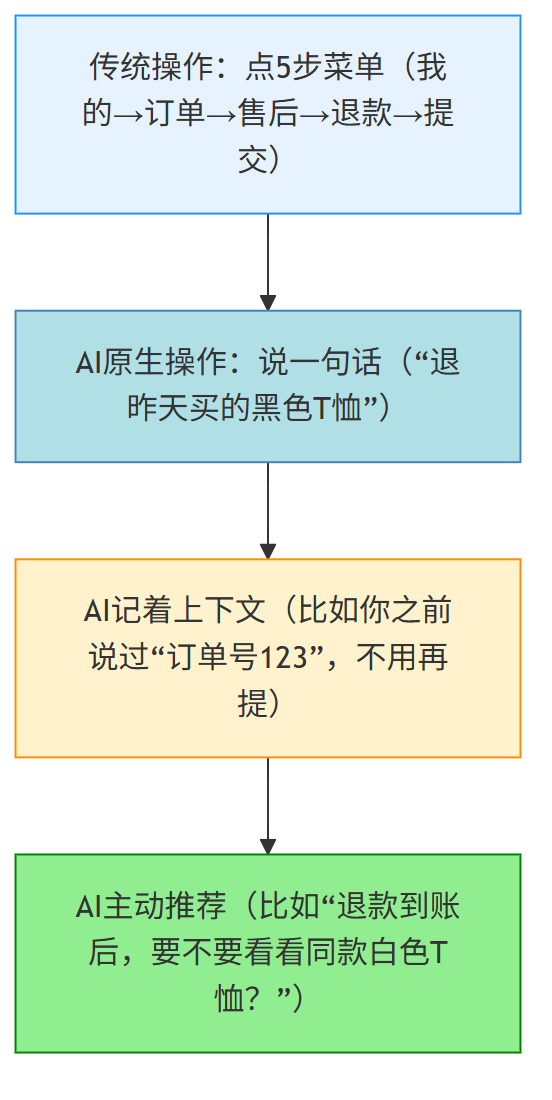
核心体验:让用户“少动手、少思考” , 多动嘴。
比如你用AI原生的“旅行APP”:
- 传统APP:你要先点“景点”→搜“北京”→选“故宫”→看攻略→再返回首页点“酒店”→搜“故宫附近”→选酒店;
- AI原生APP:你说“帮我规划北京2日游,住故宫附近,预算1000元/天”,AI直接给你整理好“第一天故宫+景山,住XX酒店;第二天颐和园+圆明园,住XX酒店”,还能直接帮你订酒店。
步骤6:设计 “自升级闭环”——24小时内让AI变聪明
传统APP 升级方式: 等版本更新(比如1个月更一次AI客服功能)
AI原生APP 升级方式: 实时升级(24小时内根据反馈调整),
设计一个 自升级闭环 。AI原生APP 收集用户反馈后,不能等一个月再更新。
自升级闭环 要24小时内调整AI,还要“小范围试错”,避免出问题。
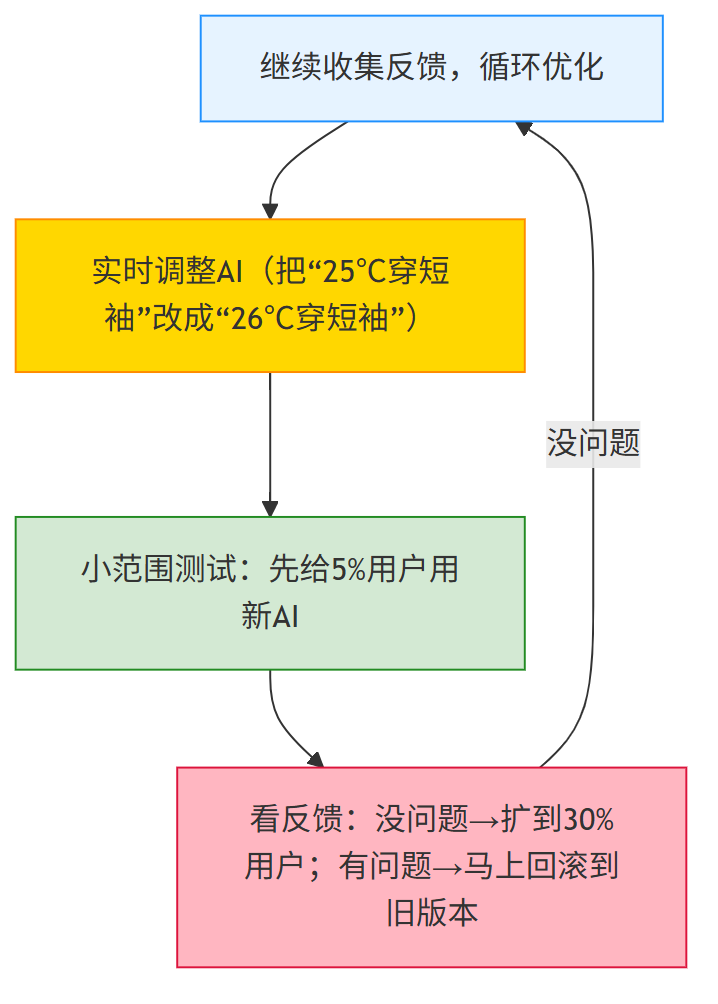
关键操作:避免“一错全错”
- 回滚窗口:30分钟内如果发现新AI有问题(比如把“25℃”改成“30℃”,用户全说热),马上切回旧版本,减少影响;
- 灰度发布:先给5%用户用,没问题再扩到30%,最后全量——就像新药上市,先给少数人试,确认安全再推广。
步骤7:装“刹车”——给AI定“规矩清单”(不让它乱说话)
AI再聪明,也不能想说啥就说啥,得提前列好“不准做的事”,比如不能歧视人、不能给错误医疗建议。
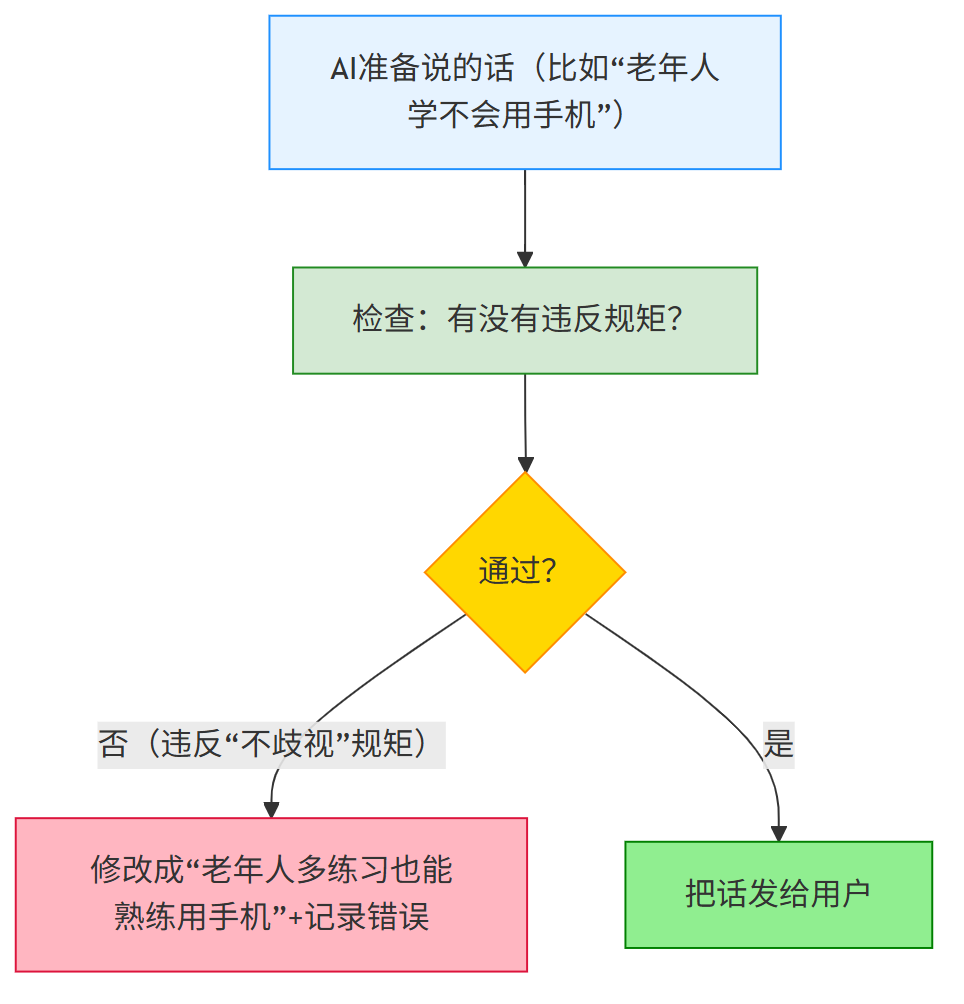
常见“规矩清单”(参考):
(1) 不准有年龄/性别/地域歧视(比如“女生学不好编程”“东北人都能喝”);
(2) 不准给医疗建议(比如“感冒了吃XX药”——要让用户找医生);
(3) 不准输出违法内容(比如“怎么破解密码”“怎么骗钱”);
(4) 不准造谣(比如“吃XX能治癌症”)。
五、 AI原生应用 vs AI插件应用
很多APP加了个AI客服,就说自己是“AI原生应用”。 这个 不对,其实和AI原生差远了, 那就是一个 普通AI插件。
AI原生应用 vs 普通AI插件 的区别, 看这张表就懂:
| 对比维度 | AI插件应用(外挂式,比如“购物APP+AI客服”) | AI原生应用(AI 内核,比如“AI助手APP”) |
|---|---|---|
| 架构核心 | 先有传统业务(比如购物订单系统),再加AI插件 | 先有大模型,再围绕大模型搭业务 |
| 数据用法 | 数据是“报表”(比如看“AI客服解决了多少问题”) | 数据是“汽油”(用户行为实时喂给AI,让它变聪明) |
| 操作方式 | 主要靠点菜单,AI是“辅助”(比如你先选“售后”,再找AI客服) | 主要靠聊天,AI是“主力”(你直接跟AI说需求) |
| 升级方式 | 等版本更新(比如1个月更一次AI客服功能) | 实时升级(24小时内根据反馈调整) |
| 赚钱方式 | 卖会员/广告(比如买年度会员免运费) | 按使用收费(比如用100次收10块,用得多收得多) |
六、为什么说AI原生是“一次大变革”?
就像10年前“功能机到智能机”的转变——不是加个“能上网”的功能,而是整个架构都变了(智能机有触摸屏、APP生态,功能机没有);
AI原生范式 的最终定义 , 这不仅需要定义其核心理念,更要将其与前代技术进行明确区分,从而揭示其作为一次根本性范式转移的本质。
软件行业向AI的演进并非铁板一块,而是呈现出两种截然不同的路径:
“AI插件”(AI-Plugin)和“AI原生”(AI-Native)。
两种截然不同的哲学、架构和商业模式。
AI插件(改造模式): 这是指在传统软件的基础上,通过增加AI功能模块来提升其能力。这种方式通常表现为“插件化”增强,即将AI作为一种辅助工具,嵌入到现有的工作流程中 。例如,一个传统的照片管理应用,增加一个需要用户手动触发的、基于AI的图像识别功能来为照片打上标签,这就是典型的AI插件 。在这种模式下,AI支持工作流程,但并非其核心。
AI原生(重构模式): 与之相反,AI原生应用从设计之初就将AI作为其核心驱动力 。AI不是一个可有可无的功能,而是应用的底层架构和操作系统 。继续以照片管理为例,一个AI原生应用无需用户任何操作,就能自动理解“汽车”这个概念,并从图库中找出所有包含汽车的照片,因为它从一开始就被构建为拥有这种认知能力 。其核心目标是解决那些“过去无法解决或解决得不好的问题”,创造全新的能力和用户体验 。
云原生类比: 这场从AI插件到AI原生的转变,与十年前业界经历的从“云赋能”到“云原生”的变革高度相似 。
同样地,AI原生也代表着对整个软件技术栈和开发理念的彻底重构。简单地为传统SaaS产品“嫁接”AI功能,就如同当年为桌面应用套上一个网页外壳,终将在新的技术浪潮中失去竞争力。
这预示着一个价值数万亿美元的软件产业“大重构”(The Great Re-platforming)周期的开启,传统的SaaS系统将面临来自基于全新、更强大架构的AI原生挑战者的颠覆性冲击 。
AI原生应用也是如此:不是给传统APP加个AI插件,而是从“骨架”到“心脏”都用AI重构。 未来,越来越多的软件会变成“AI原生”。
这个趋势, 有点像 功能机 和 智能机 一样, 就像现在没人用功能机一样 —— 不是因为功能机不好,而是智能机能解决功能机解决不了的问题。
七、最后一句话总结
“AI插件”(AI-Plugin) 应用 (传统软件)的特点是: “做完就定型”,比如计算器做出来就是算加减乘除,不会变;
“AI原生”(AI-Native) 应用 (传统软件)的特点是:应用“出生只是开始”。用的人越多、反馈越多,它就越懂你,慢慢“长大”变好用。
尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
- 《Python学习圣经:从0到1精通Python,打好AI基础》
- 《LLM大模型学习圣经:从0到1吃透Transformer技术底座》
- 《LangChain学习圣经:从0到1精通LLM大模型应用开发的基础框架》
- 《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
- 《SpringCloud + Python 混合微服务架构,打造AI分布式业务应用的技术底层》
- 《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
- 《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
- 《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
- 《 阿里面试:RAG 怎么优化?探讨一下 RAG优化的7大黄金法则 ?》
- 《LangChain 源码 + GOF设计模式:基于GOF的设计模式,穿透 LangChain 源码》

助力合肥开发者学习交流的技术社区,不定期举办线上线下活动,欢迎大家的加入
更多推荐

 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)