
老黄砸40倍性能牌,昇腾甩出3倍性价比,下一个破局者是谁?
围绕推理范式的竞赛已悄然开始
3月19日凌晨,黄仁勋在NVIDIA GTC上发布了新一代AI芯片——Blackwell,代号为Ultra,也就是GB300 AI芯片,接棒去年的全球最强AI芯片B200,再一次实现性能上的突破,预计下半年问世。
据介绍,其性能是Hopper的40倍,配备了1.1 EF的密集FP4推理能力和0.36 EF的FP8训练能力,达到了GB200 NVL72的1.5倍。单个配备8块Blackwell GPU的NVIDIA DGX系统,可实现每位用户每秒超过250个token,或每秒超过30000个token的最大吞吐量。
值得注意的是,根据英伟达官方博客介绍,Blackwell已经让DeepSeek-R1打破了推理性能的世界纪录。

通过硬件和软件的结合,NVIDIA自2025年1月以来将DeepSeek-R1 671B模型的吞吐量提高了约36倍,相当于每个token的成本降低了约32倍。
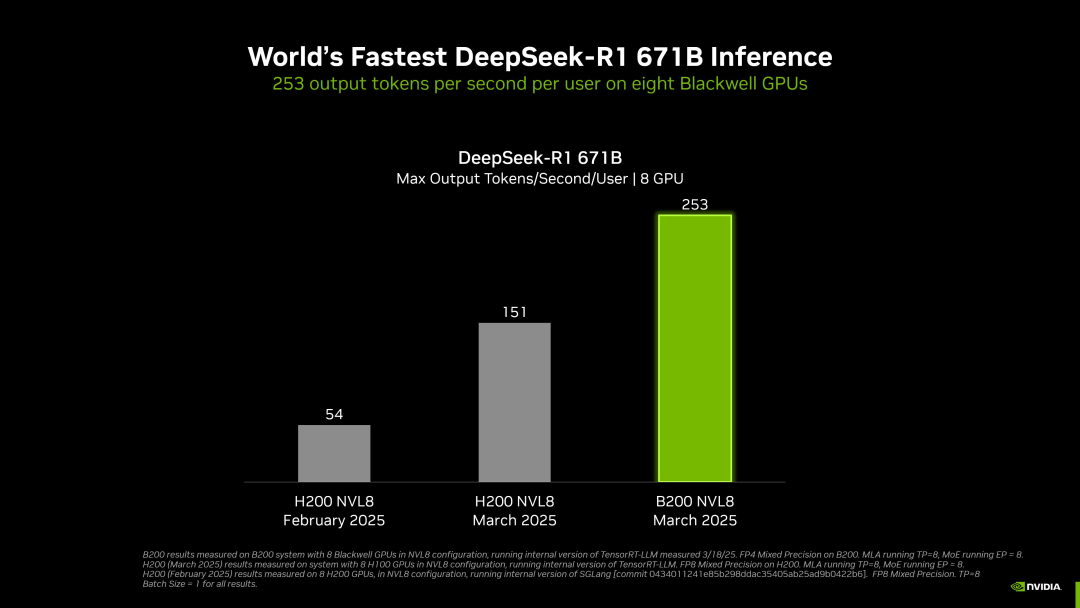
这一突破性的性能提升,无疑将推理范式的竞赛推向了更高处。

围绕推理范式的竞赛已悄然开始
事实上,早在英伟达之前,华为昇腾便率先复现了DeepSeek跨节点专家并行(EP)架构,推出8机64卡的跨节点专家并行推理集群方案,通过专家动态分配、分层通信协议(如AllToAll优化)和混合量化技术,将DeepSeek-R1 671B模型的推理显存需求压缩至1/4,效率提升75%,专家计算密度增加4倍,推理吞吐提升3.2倍(单卡在相同时间内可完成3.2倍的推理请求,也就意味着性价比也提升3倍),端到端时延降低50%。
具体来看,华为昇腾的突破主要体现在以下几方面。
在算子融合方面,MLA预处理阶段通过Vector与Cube异构计算单元并行流水,并将多个小算子融合重构为原子级计算单元,消除小算子下发开销,MLA前处理时延降低50%+,实现性能的显著提升。
在混合并行策略和通信计算并行优化方面,构建了TP(张量并行)+EP(专家并行)混合范式:对MLA计算层采用机内TP并行,发挥机内高速互联优势,降低跨机通信损耗;创新MoE专家分层调度,64卡均衡分配专家计算节点,定制AllToAll通信协议,专家数据交换效率提升40%,构建跨机/机内双层通信架构,通过分层优化降低跨机流量60%;同时研发路由专家负载均衡算法,实现卡间负载差异小于10%,集群吞吐提升30%。
除华为昇腾和英伟达之外,我们也发现,在推理范式赛道也涌入了其他破局者。
例如,摩尔线程基于DeepSeek开源的DeepEP通信库,推出MT-DeepEP框架,优化国产MUSA架构GPU的All-to-All通信效率,支持FP8数据分发与计算-通信重叠,MoE模型推理速度达A100的75%,并且在成本上实现了显著降低。
清华系科创企业清程极智与清华大学翟季冬教授团队联合宣布开源大模型推理引擎赤兔(Chitu),率先实现了非H卡设备(英伟达Hopper架构之前的GPU 卡及各类国产卡)运行原生FP8模型的突破。在A800集群上的实测数据显示,用赤兔引擎部署DeepSeek-671B满血版推理服务,相比于vLLM部署方案,不仅使用的GPU数量减少了50%,而且输出速度还提升了3.15倍。
可以看到,这场由大规模跨节点专家并行(大EP)引发的技术革命,正在重塑全球AI产业的格局,也将推理性能与成本控制推向新的临界点。这也进一步向我们展示了一个趋势:未来的人工智能竞争不在于谁的模型更大,而在于谁的模型具有更低的推理成本和更高推理的效率。

开发者怎么看?
从卷训练向卷推理的演变,开发者既是技术革新的受益者,也是生态演进的关键参与者。
那么,开发者如何看待从训练到推理的范式变化?
对此,CSDN也采访了多位博主。他们普遍认为,这一转变既充满挑战也充满机遇。
CSDN博主小雨青年表示:“对开发者而言是利大于弊的,训练层面个人开发者基本用不到,推理成本降低了,对应的是成本降低了,本地部署的门槛也降低了,这也就意味着更多开发者能够参与到AI的前沿应用中来。”
猫头虎则表示:“从深度学习模型的部署和应用角度来看,模型推理效率的提高将推动AI技术更广泛地应用于实时场景,对于开发者而言,可以采用专门针对推理优化的架构,提高推理速度。同时,还能根据任务需求定制架构,有助于更有效的利用计算资源,降低功耗,开发者可根据不同阶段的需求,选择最适合的架构,灵活性显著增强。”
同时,猫头虎也坦言这种变化也相应的带来了一些挑战,比如开发复杂性增加,开发者需要为训练和推理分别设计和维护不同的架构,增加开发和维护的复杂度,并且不同架构之间可能存在兼容性问题,迁移模型在不同平台部署时可能会遇到困难,也进一步加大了开发者的学习成本。
综合来看,一方面,技术突破为开发者提供了更丰富的工具链和更灵活的部署方案,让开发者能根据业务需求选择性价比更高的硬件组合,而非绑定单一厂商;另一方面,技术迭代也需要开发者们不断持续学习,例如FP8量化、MoE模型结构等新特性要求开发者更新知识储备以适应快速变化的技术环境。开发者正从被动接受技术变革,转变为主动参与生态塑造。他们既希望厂商提供更高效、更低成本的工具,也警惕技术垄断带来的路径依赖。
在更低成本更高性能的大潮推动下,推理范式赛道破局者却屈指可数,原因何在?欢迎在评论区留言讨论~
更多推荐



 18
18 0
0- 0



 已为社区贡献172条内容
已为社区贡献172条内容

所有评论(0)