
docker 详细介绍安装步骤以及简单的运用
docker从入门到放弃。
目录
2.3 案例:演示创建一个新镜像,ubuntu安装ifconfig命令
2.5 将新镜像testubuntu:1.2 修改符合私服规范的Tag
一,docker的简单介绍
docker官网地址: http://www.docker.com
docker Hub 仓库地址: https://www.hub.docker.com
docker 的基本组成:
1.镜像(images)
Docker 镜像(Image)就是一个只读的模板。镜像可以用来创建 Docker 容器,一个镜像可以创建很多容器。
它也相当于是一个root文件系统。比如官方镜像 centos:7 就包含了完整的一套 centos:7 最小系统的 root 文件系统。
相当于容器的“源代码”,docker镜像文件类似于Java的类模板,而docker容器实例类似于java中new出来的实例对象。
2. 容器 (container)
2.1从面向对象角度
Docker 利用容器(Container)独立运行的一个或一组应用,应用程序或服务运行在容器里面,容器就类似于一个虚拟化的运行环境,容器是用镜像创建的运行实例。就像是Java中的类和实例对象一样,镜像是静态的定义,容器是镜像运行时的实体。容器为镜像提供了一个标准的和隔离的运行环境,它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台
2.2从镜像容器角度
可以把容器看做是一个简易版的 Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
3. 仓库 (repository)
仓库(Repository)是集中存放镜像文件的场所。类似于
Maven仓库,存放各种jar包的地方;
github仓库,存放各种git项目的地方;
Docker公司提供的官方registry被称为Docker Hub,存放各种镜像模板的地方。
仓库分为公开仓库(Public)和私有仓库(Private)两种形式。
最大的公开仓库是 Docker Hub(https://hub.docker.com/),
存放了数量庞大的镜像供用户下载。国内的公开仓库包括阿里云 、网易云等。
总结
需要正确的理解仓库/镜像/容器这几个概念:
Docker 本身是一个容器运行载体或称之为管理引擎。我们把应用程序和配置依赖打包好形成一个可交付的运行环境,这个打包好的运行环境就是image镜像文件。只有通过这个镜像文件才能生成Docker容器实例(类似Java中new出来一个对象)。
image文件可以看作是容器的模板。Docker 根据 image 文件生成容器的实例。同一个 image 文件,可以生成多个同时运行的容器实例。
镜像文件
* image 文件生成的容器实例,本身也是一个文件,称为镜像文件。
容器实例
* 一个容器运行一种服务,当我们需要的时候,就可以通过docker客户端创建一个对应的运行实例,也就是我们的容器
仓库
* 就是放一堆镜像的地方,我们可以把镜像发布到仓库中,需要的时候再从仓库中拉下来就可以了。
Docker 是一个 C/S 模式的架构,后端是一个松耦合架构,众多模块各司其职。

一次构建,随处运行
更快速的应用交付和部署
传统的应用开发完成后,需要提供一堆安装程序和配置说明文档,安装部署后需根据配置文档进行繁杂的配置才能正常运行。Docker化之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像里已经内置好,大大节省部署配置和测试验证时间。
更便捷的升级和扩缩容
随着微服务架构和Docker的发展,大量的应用会通过微服务方式架构,应用的开发构建将变成搭乐高积木一样,每个Docker容器将变成一块“积木”,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容,使应用系统的扩容从原先的天级变成分钟级甚至秒级。
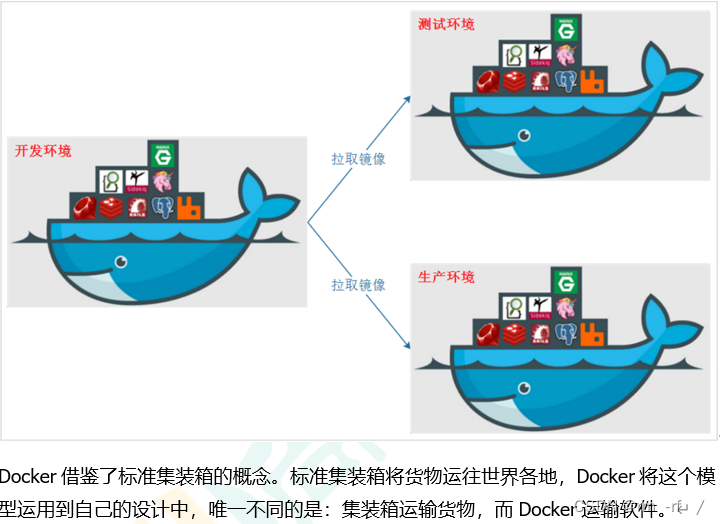
更简单的系统运维
应用容器化运行后,生产环境运行的应用可与开发、测试环境的应用高度一致,容器会将应用程序相关的环境和状态完全封装起来,不会因为底层基础架构和操作系统的不一致性给应用带来影响,产生新的BUG。当出现程序异常时,也可以通过测试环境的相同容器进行快速定位和修复。
更高效的计算资源利用
Docker是内核级虚拟化,其不像传统的虚拟化技术一样需要额外的Hypervisor支持,所以在一台物理机上可以运行很多个容器实例,可大大提升物理服务器的CPU和内存的利用率。
Docker应用场景:

二,docker的安装步骤
docker 官方Centos7安装连接 https://docs.docker.com/engine/install/centos/
Centos7安装
1.确定版本是否是Centos7以上
[root@docker ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
2.卸载旧版docker (如果有的话)
[root@docker ~]# yum remove docker \
> docker-client\
> docker-client-latest\
> docker-common \
> docker-latest \
> docker-latest-logretate \
> docker-logrotate \
> docker-engine
已加载插件:fastestmirror
参数 docker 没有匹配
参数 docker-clientdocker-client-latestdocker-common 没有匹配
参数 docker-latest 没有匹配
参数 docker-latest-logretate 没有匹配
参数 docker-logrotate 没有匹配
参数 docker-engine 没有匹配
不删除任何软件包
3.安装一些软件
yum -y install gcc gcc-c++ yum yum-utils
4.设置docker安装镜像源
这里我们不选择官方的源。
而是采用国内阿里云的源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
5.更新yum缓存及查看是否阿里云源设置成功
yum makecache && yum repolist
6.安装docker-ce
yum -y install docker-ce docker-ce-cli containerd.io
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.aliyuncs.com
* extras: mirrors.aliyuncs.com
* updates: mirrors.aliyuncs.com
软件包 3:docker-ce-20.10.16-3.el7.x86_64 已安装并且是最新版本
软件包 1:docker-ce-cli-20.10.16-3.el7.x86_64 已安装并且是最新版本
软件包 containerd.io-1.6.4-3.1.el7.x86_64 已安装并且是最新版本
7.启动docker并测试是否安装成功
启动服务
systemctl start docker
查看docker服务状态并设置为开机自启
systemctl status docker && systemctl enable docker
测试docker
[root@docker ~]# docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
2db29710123e: Pull complete
Digest: sha256:80f31da1ac7b312ba29d65080fddf797dd76acfb870e677f390d5acba9741b17
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
8.如何卸载docker
停止服务
ystemctl stop docker
卸载yum安装的软件
yum remove docker-ce docker-ce-cli containerd.io
删除本地文件
rm -rf /var/lib/docker
rm -rf /var/lib/containerd
9.设置阿里云镜像加速
登录阿里云——打开控制台——找到容器镜像服务——镜像工具——镜像加速器

您可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://3rpm59wi.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker三.docker的常用命令
1 帮助启动类命令
启动docker:systemctl start docker
停止docker: systemctl stop docker
重启docker:systemctl restart docker
查看docker状态: systemctl status docker
开机自启: systemctl enable docker
查看docker概要信息:docker info
查看docker总体帮助文档: docker --help
查看docker命令帮助文档: docker 具体命令 --help
2 镜像命令
2.1 docker images 列出本地主机上的镜像

各个选项说明:
| REPOSITORY:表示镜像的仓库源 TAG:镜像的标签版本号 IMAGE ID:镜像ID CREATED:镜像创建时间 SIZE:镜像大小 |
同一仓库源可以有多个 TAG版本,代表这个仓库源的不同个版本,我们使用 REPOSITORY:TAG 来定义不同的镜像。
如果你不指定一个镜像的版本标签,例如你只使用 ubuntu,docker 将默认使用 ubuntu:latest 镜像
OPTIONS说明:
docker images -a : 列出本地所有的镜像(含历史映像层)
docker images -q : 只显示镜像ID
2.2 docker search 搜索某个镜像名字

OFFICIAL 下面有OK 的一般是代表官方的镜像
2.3 下载镜像
docker pull 某个镜像的名字
格式为 : docker pull 镜像名称[:TAG]
如镜像名字后面没添加TAG 那么默认pull下来的镜像为最新板的等价于 docker pull 镜像名字:latest
列:没加:TAG 默认会下载最新的镜像
[root@docker ~]# docker pull ubuntu
Using default tag: latest
latest: Pulling from library/ubuntu
7b1a6ab2e44d: Pull complete
Digest: sha256:626ffe58f6e7566e00254b638eb7e0f3b11d4da9675088f4781a50ae288f3322
Status: Downloaded newer image for ubuntu:latest
docker.io/library/ubuntu:latest
列:添加了TAG 下载ubuntu 18.04的版本镜像
[root@docker ~]# docker pull ubuntu:18.04
18.04: Pulling from library/ubuntu
284055322776: Pull complete
Digest: sha256:0fedbd5bd9fb72089c7bbca476949e10593cebed9b1fb9edf5b79dbbacddd7d6
Status: Downloaded newer image for ubuntu:18.04
docker.io/library/ubuntu:18.04
最后查看刚pull下来的镜像
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest ba6acccedd29 7 months ago 72.8MB
ubuntu 18.04 5a214d77f5d7 7 months ago 63.1MB
hello-world latest feb5d9fea6a5 8 months ago 13.3kB
REPOSITORY : 表示镜像名字
TAG : 版本号
IMAGE ID : 镜像唯一的ID
CREATED : 镜像下载下来的时间
SIZE : 镜像容量大小
2.4 查看镜像/容器/数据卷所占的空间
docker system df
[root@docker ~]# docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 3 1 135.9MB 135.9MB (99%)
Containers 1 0 0B 0B
Local Volumes 0 0 0B 0B
Build Cache 0 0 0B 0B
2.5 镜像删除
docker rmi 某个镜像名字ID 如加上-f 表示强制删除
docker rmi -f 镜像ID #删除单个
docker rmi -f 镜像名1:TAG 镜像名2:TAG #删除多个
docker rmi -f $(docker images -qa) #删除全部
3 容器命令
有镜像才能创建容器,这是根本的前提。
本次使用ubuntu 演示
docker pull ubuntu #下载一个最新的ubuntu 镜像也可以使用新建和启动容器在一起执行的命令 如: docker run +指令 IMAGE +镜像名字
3.1 docker 启动容器所有参数指令:
OPTIONS说明(常用):有些是一个减号,有些是两个减号
--name="容器新名字" 为容器指定一个名称;
-d: 后台运行容器并返回容器ID,也即启动守护式容器(后台运行);
-i:以交互模式运行容器,通常与 -t 同时使用;
-t:为容器重新分配一个伪输入终端,通常与 -i 同时使用;
也即启动交互式容器(前台有伪终端,等待交互);
-P: 随机端口映射,大写P
-p: 指定端口映射,小写p

#使用镜像ubuntu:latest以交互模式启动一个容器,在容器内执行/bin/bash命令。
[root@docker ~]# docker run -it ubuntu /bin/bash
root@df3cda00885b:/#
| 参数说明: -i: 交互式操作。 -t: 终端。 ubuntu : ubuntu 镜像。 /bin/bash:放在镜像名后的是命令,这里我们希望有个交互式 Shell,因此用的是 /bin/bash。 要退出终端,直接输入 exit: |
3.2 退出容器
退出容器有两种方法
exit —— run 进去容器,exit退出,容器会停止。
Ctrl+p+q ——run 进去容器, Ctrl+p+q退出,容器不会停止。
3.3 查看当前所有正在运行的容器
docker ps [参数]
OPTIONS说明(常用):
-a :列出当前所有正在运行的容器+历史上运行过的
-l :显示最近创建的容器。
-n:显示最近n个创建的容器。
-q :静默模式,只显示容器编号。
3.4 容器的启动、重启、停止、强制停止、删除容器命令
启动已停止运行的容器 —— docker start 容器ID或者容器名
重启容器 —— docker restart 容器ID或者容器名
停止容器 —— docker stop 容器ID或者容器名
强制停止容器 —— docker kill 容器ID或者容器名
删除已经停止的容器 —— docker rm 容器ID
一次性删除多个容器实例 —— docker rm -f $(docker ps -a -q)
3.5 容器的一些重要知识
有镜像才能创建容器,这是根本前提(下载一个redis6.0.8镜像演示)
docker pull redis:6.0.8
前台交互式启动 —— docker run -it redis:6.0.8 ##一般是能与用户交互的程序,比如 /bin/bash /bin/sh 等
后台交互式启动 —— docker run -d redis:6.0.8 ## 一般是一个程序服务,比如 apache nginx redis 等
3.6 启动守护式容器(后台服务器)
在大部分的场景下,我们希望 docker 的服务是在后台运行的,我们可以过 -d 指定容器的后台运行模式。
docker run -d 容器名
#使用镜像centos:latest以后台模式启动一个容器
docker run -d centos
问题:然后docker ps -a 进行查看, 会发现容器已经退出
很重要的要说明的一点: Docker容器后台运行,就必须有一个前台进程.
容器运行的命令如果不是那些一直挂起的命令(比如运行top,tail),就是会自动退出的。
这个是docker的机制问题,比如你的web容器,我们以nginx为例,正常情况下,
我们配置启动服务只需要启动响应的service即可。例如service nginx start
但是,这样做,nginx为后台进程模式运行,就导致docker前台没有运行的应用,
这样的容器后台启动后,会立即自杀因为他觉得他没事可做了.
所以,最佳的解决方案是,将你要运行的程序以前台进程的形式运行,
常见就是命令行模式,表示我还有交互操作,别中断,O(∩_∩)O哈哈~
3.7 查看容器内部的一些命令
查看容器日志 —— docker logs 容器ID
查看容器内运行的进程 —— docker top 容器ID
查看容器内部细节 —— docker inspect 容器ID
3.8 进入正在运行的容器并以命令行交互
进入正在运行的容器有两个命令 attach和exec, 这两个的区别在于:
attach 直接进入容器启动命令的终端,不会启动新的进程,用exit退出,会导致容器的停止。
exec 是在容器中打开新的终端,并且可以启动新的进程,用exit退出,不会导致容器的停止。
所以推荐使用 docker exec 命令,因为退出容器终端,不会导致容器的停止。
列: docker exec -it 容器ID /bin/bash
[root@docker ~]# docker pull redis:6.0.8
docker.io/library/redis:6.0.8
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest ba6acccedd29 7 months ago 72.8MB
ubuntu 18.04 5a214d77f5d7 7 months ago 63.1MB
hello-world latest feb5d9fea6a5 8 months ago 13.3kB
redis 6.0.8 16ecd2772934 19 months ago 104MB
[root@docker ~]# docker run -d redis:6.0.8
1e4d73ad87dddf4d213a0031e2c18d651db713ff9330071418113e2c9f8916f5
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1e4d73ad87dd redis:6.0.8 "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 6379/tcp compassionate_gauss
df3cda00885b ubuntu "/bin/bash" 51 minutes ago Up 50 minutes goofy_boyd
[root@docker ~]# docker exec -it 1e4d73ad87dd /bin/bash
root@1e4d73ad87dd:/data# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>
root@1e4d73ad87dd:/data# exit
[root@docker ~]#
3.9 从容器内拷贝文件到主机上
docker cp 容器ID:容器内路径 目的主机路径
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1e4d73ad87dd redis:6.0.8 "docker-entrypoint.s…" 4 minutes ago Up 4 minutes 6379/tcp compassionate_gauss
df3cda00885b ubuntu "/bin/bash" 55 minutes ago Up 55 minutes goofy_boyd
[root@docker ~]# docker cp df3cda00885b:/tmp/test.txt ~/
[root@docker ~]# ls
anaconda-ks.cfg test.txt
[root@docker ~]#
3.10 导入和导出容器
export 导出容器的内容留作为一个tar归档文件[对应import命令]
import 从tar包中的内容创建一个新的文件系统再导入为镜像[对应export]
列:docke export 容器ID > 文件名.tar
cat 文件名.tar | docker import -镜像用户/镜像名:镜像版本号
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1e4d73ad87dd redis:6.0.8 "docker-entrypoint.s…" 11 minutes ago Up 11 minutes 6379/tcp compassionate_gauss
df3cda00885b ubuntu "/bin/bash" About an hour ago Up About an hour goofy_boyd
[root@docker ~]# docker export df3cda00885b > ubuntu-backup.tar
[root@docker ~]# ls
anaconda-ks.cfg test.txt ubuntu-backup.tar
[root@docker ~]# cat ubuntu-backup.tar | docker import - test/ubuntu/8.8
sha256:818ad51728a8222e4929bc5a385cae967214e9500759f51f6c44aa3651ca2602
root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
test/ubuntu/8.8 latest 818ad51728a8 8 seconds ago 72.8MB
四.docker常用命令总结
attach Attach to a running container # 当前 shell 下 attach 连接指定运行镜像
build Build an image from a Dockerfile # 通过 Dockerfile 定制镜像
commit Create a new image from a container changes # 提交当前容器为新的镜像
cp Copy files/folders from the containers filesystem to the host path #从容器中拷贝指定文件或者目录到宿主机中
create Create a new container # 创建一个新的容器,同 run,但不启动容器
diff Inspect changes on a container's filesystem # 查看 docker 容器变化
events Get real time events from the server # 从 docker 服务获取容器实时事件
exec Run a command in an existing container # 在已存在的容器上运行命令
export Stream the contents of a container as a tar archive # 导出容器的内容流作为一个 tar 归档文件[对应 import ]
history Show the history of an image # 展示一个镜像形成历史
images List images # 列出系统当前镜像
import Create a new filesystem image from the contents of a tarball # 从tar包中的内容创建一个新的文件系统映像[对应export]
info Display system-wide information # 显示系统相关信息
inspect Return low-level information on a container # 查看容器详细信息
kill Kill a running container # kill 指定 docker 容器
load Load an image from a tar archive # 从一个 tar 包中加载一个镜像[对应 save]
login Register or Login to the docker registry server # 注册或者登陆一个 docker 源服务器
logout Log out from a Docker registry server # 从当前 Docker registry 退出
logs Fetch the logs of a container # 输出当前容器日志信息
port Lookup the public-facing port which is NAT-ed to PRIVATE_PORT # 查看映射端口对应的容器内部源端口
pause Pause all processes within a container # 暂停容器
ps List containers # 列出容器列表
pull Pull an image or a repository from the docker registry server # 从docker镜像源服务器拉取指定镜像或者库镜像
push Push an image or a repository to the docker registry server # 推送指定镜像或者库镜像至docker源服务器
restart Restart a running container # 重启运行的容器
rm Remove one or more containers # 移除一个或者多个容器
rmi Remove one or more images # 移除一个或多个镜像[无容器使用该镜像才可删除,否则需删除相关容器才可继续或 -f 强制删除]
run Run a command in a new container # 创建一个新的容器并运行一个命令
save Save an image to a tar archive # 保存一个镜像为一个 tar 包[对应 load]
search Search for an image on the Docker Hub # 在 docker hub 中搜索镜像
start Start a stopped containers # 启动容器
stop Stop a running containers # 停止容器
tag Tag an image into a repository # 给源中镜像打标签
top Lookup the running processes of a container # 查看容器中运行的进程信息
unpause Unpause a paused container # 取消暂停容器
version Show the docker version information # 查看 docker 版本号
wait Block until a container stops, then print its exit code # 截取容器停止时的退出状态值
五.docker 镜像
1 docker镜像是什么?
镜像
是一种轻量级、可执行的独立软件包,它包含运行某个软件所需的所有内容,我们把应用程序和配置依赖打包好形成一个可交付的运行环境(包括代码、运行时需要的库、环境变量和配置文件等),这个打包好的运行环境就是image镜像文件。
只有通过这个镜像文件才能生成Docker容器实例(类似Java中new出来一个对象)。
以我们的pull为例,在下载的过程中我们可以看到docker的镜像好像是在一层一层的在下载
UnionFS(联合文件系统):Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。Union 文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
特性:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录
Docker镜像加载原理:
docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS。
bootfs(boot file system)主要包含bootloader和kernel, bootloader主要是引导加载kernel, Linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层是引导文件系统bootfs。这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs (root file system) ,在bootfs之上。包含的就是典型 Linux 系统中的 /dev, /proc, /bin, /etc 等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。 平时我们安装进虚拟机的CentOS都是好几个G,为什么docker这里才200M??
对于一个精简的OS,rootfs可以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接用Host的kernel,自己只需要提供 rootfs 就行了。由此可见对于不同的linux发行版, bootfs基本是一致的, rootfs会有差别, 因此不同的发行版可以公用bootfs。
镜像分层最大的一个好处就是共享资源,方便复制迁移,就是为了复用。
比如说有多个镜像都从相同的 base 镜像构建而来,那么 Docker Host 只需在磁盘上保存一份 base 镜像;
同时内存中也只需加载一份 base 镜像,就可以为所有容器服务了。而且镜像的每一层都可以被共享。
2 重点理解
Docker镜像层都是只读的,容器层是可写的,当容器启动时,一个新的可写层被加载到镜像的顶部。这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”。
当容器启动时,一个新的可写层被加载到镜像的顶部。这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”。
所有对容器的改动 - 无论添加、删除、还是修改文件都只会发生在容器层中。只有容器层是可写的,容器层下面的所有镜像层都是只读的。
3 Docker镜像commit操作案例
docker commit提交容器副本使之成为一个新的镜像
模板: docker commit -m="提交的描述信息" -a="作者" 容器ID 要创建的目标镜像名:[标签名]
案例演示ubuntu 安装vim :
3.1 从Hub上下载ubuntu镜像到本地并成功运行
[root@docker ~]# docker pull ubuntu
Using default tag: latest
latest: Pulling from library/ubuntu
7b1a6ab2e44d: Pull complete
Digest: sha256:626ffe58f6e7566e00254b638eb7e0f3b11d4da9675088f4781a50ae288f3322
Status: Downloaded newer image for ubuntu:latest
docker.io/library/ubuntu:latest
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest ba6acccedd29 7 months ago 72.8MB
[root@docker ~]# docker run -it ubuntu /bin/bash
root@e43f21208a53:/#
3.2 原始的默认ubuntu镜像是不带vim命令的
root@e43f21208a53:/# vim a.txt
bash: vim: command not found
root@e43f21208a53:/#
3.3 在外网连通的情况下,安装vim
root@e43f21208a53:/# apt update #更新源里面的软件
Get:1 http://security.ubuntu.com/ubuntu focal-security InRelease [114 kB]
Get:2 http://archive.ubuntu.com/ubuntu focal InRelease [265 kB]
Get:3 http://archive.ubuntu.com/ubuntu focal-updates InRelease [114 kB]
...............略
root@e43f21208a53:/# apt -y install vim #安装vim
3.4 安装完成后,commit我们自己的新镜像
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e43f21208a53 ubuntu "/bin/bash" 7 minutes ago Up 7 minutes objective_villani
[root@docker ~]# docker commit -m="add vim" -a="dc" e43f21208a53 testcommit/myubuntu:1.1
sha256:731506b7270d788daaa23731c6975edae409db42eeb5d797c5bb5bb0c99d6804
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
testcommit/myubuntu 1.1 731506b7270d 9 seconds ago 177MB
ubuntu latest ba6acccedd29 7 months ago 72.8MB
3.5 启动我们的commit的新镜像并和原来的对比
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
testcommit/myubuntu 1.1 731506b7270d 9 seconds ago 177MB
ubuntu latest ba6acccedd29 7 months ago 72.8MB
[root@docker ~]# docker run -it testcommit/myubuntu:1.1 /bin/bash
root@0d3426747a01:/# vim a.txt
root@0d3426747a01:/#
官网是默认下载的Ubuntu没有vim命令,我们自己commit构建的镜像,新增加了vim功能,可以成功使用。
3.6 小总结
Docker中的镜像分层,支持通过扩展现有镜像,创建新的镜像。类似Java继承于一个Base基础类,自己再按需扩展。
新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层

六. 本地镜像发布到阿里云
1 本地镜像发布到阿里云流程

2 镜像的生成方法
镜像生成有两种方法: commit 基于当前的容器创建一个新的镜像,新功能增强,另外一种就是DockerFile,文章后面会说到如何生成。
3 将本地镜像推送到阿里云
登录到阿里云开发者平台:https://promotion.aliyun.com/ntms/act/kubernetes.html
选择控制台,进入容器镜像服务

选择个人实例




进入管理界面获取脚本


将镜像推送到阿里云registry

脚本实例:
| docker login --username=zzyybuy registry.cn-hangzhou.aliyuncs.com |
| docker tag cea1bb40441c registry.cn-hangzhou.aliyuncs.com/atguiguwh/myubuntu:1.1 |
| docker push registry.cn-hangzhou.aliyuncs.com/atguiguwh/myubuntu:1.1 |
| 上面命令是我自己本地的,你自己酌情处理,不要粘贴我的。 |

4 将阿里云上的镜像下载到本地

七. 本地镜像发布到私有库
1 私有库(Registry)是什么?
14.1.1 官方Docker Hub地址:https://hub.docker.com/,中国大陆访问太慢了且准备被阿里云取代的趋势,不太主流。
14.1.2 Dockerhub、阿里云这样的公共镜像仓库可能不太方便,涉及机密的公司不可能提供镜像给公网,所以需要创建一个本地私人仓库供给团队使用,基于公司内部项目构建镜像。
14.1.3 Docker Registry是官方提供的工具,可以用于构建私有镜像仓库
2 将本地镜像推送到私有库全流程演示
2.1 下载镜像 Docker Registrt
[root@docker ~]# docker pull registry
2.2 运行私有库Registry
运行私有库Registry,相当于本地有个私有Docker hub
[root@docker ~]# docker run -d -p 5000:5000 -v ~/test/myregistry/:/tmp/registry --privileged=true registry
默认情况,仓库被创建在容器的/var/lib/registry目录下,建议自行用容器卷映射,方便于宿主机联调

2.3 案例:演示创建一个新镜像,ubuntu安装ifconfig命令
首先我们从Hub上下载ubuntu镜像到本地并成功运行,我们可以发现原始的ubuntu镜像是不带有ifconfig命令的。

在外网连通的情况下,安装ifconfig命令并测试通过
docker容器内执行上述两条命令:
apt-get update
apt-get install net-tools
root@a1982e9f1318:/# apt update
root@a1982e9f1318:/# apt -y install net-tools

安装完成后,commit我们自己的新镜像
公式:
docker commit -m="提交的描述信息" -a="作者" 容器ID 要创建的目标镜像名:[标签名]
命令:在容器外执行,记得
docker commit -m="ifconfig cmd add" -a='test " a69d7c825c4f testubuntu:1.2

接下来启动我们新提交的镜像和原来的镜像相比,会发现官网是默认下载的Ubuntu没有ifconfig命令,我们自己commit构建的新镜像,新增加了ifconfig功能,可以成功使用。
2.4 curl 验证私服库上有什么镜像
[root@docker ~]# curl -X GET http://192.168.50.38:5000/v2/_catalog

2.5 将新镜像testubuntu:1.2 修改符合私服规范的Tag
按照公式: docker tag 镜像:Tag Host:Port/Repository:Tag
自己host主机IP地址,填写你们自己的,不要粘贴错误
使用命令 docker tag 将tesrubuntu:1.2 这个镜像修改为192.168.50.38:5000/testubuntu:1.2
[root@docker ~]# docker tag testubuntu:1.2 192.168.50.38:5000/testubuntu:1.2

2.6 修改配置文件使之支持http.

| 别无脑照着复制,registry-mirrors 配置的是国内阿里提供的镜像加速地址,不用加速的话访问官网的会很慢。 2个配置中间有个逗号 ','别漏了,这个配置是json格式的。 2个配置中间有个逗号 ','别漏了,这个配置是json格式的。 2个配置中间有个逗号 ','别漏了,这个配置是json格式的。 |
vim命令新增如下红色内容:vim /etc/docker/daemon.json
| { "registry-mirrors": ["https://aa25jngu.mirror.aliyuncs.com"], "insecure-registries": ["192.168.50.38:5000"] } |
上述理由:docker默认不允许http方式推送镜像,通过配置选项来取消这个限制。====> 修改完后如果不生效,建议重启docker
2.7 push 推送到私服库
[root@docker ~]# docker push 192.168.50.38:5000/testubuntu:1.2

2.8 再次curl 验证私服库上有什么镜像
[root@docker ~]#
[root@docker ~]# curl -X GET http://192.168.50.38:5000/v2/_catalog
{"repositories":["testubuntu"]}
[root@docker ~]#

2.9 pull到本地并运行测试
先删除掉之前commit出来的镜像,避免混淆。

pull 到本地
[root@docker ~]# docker pull 192.168.50.38:5000/testubuntu:1.2
1.2: Pulling from testubuntu
Digest: sha256:2b40f1db08a8a80d26bcb9855b52eaa097f203f35d1cf1a3461f497673ca0cc6
Status: Downloaded newer image for 192.168.50.38:5000/testubuntu:1.2
192.168.50.38:5000/testubuntu:1.2

运行并验证是否带有ifconfig命令

八. Docker容器卷
!!! 容器卷记得加入 --privileged=true 这条参数
Docker挂载主机目录访问如果出现cannot open directory .: Permission denied
解决办法:在挂载目录后多加一个--privileged=true参数即可
如果是CentOS7安全模块会比之前系统版本加强,不安全的会先禁止,所以目录挂载的情况被默认为不安全的行为,
在SELinux里面挂载目录被禁止掉了额,如果要开启,我们一般使用--privileged=true命令,扩大容器的权限解决挂载目录没有权限的问题,也即使用该参数,container内的root拥有真正的root权限,否则,container内的root只是外部的一个普通用户权限。
1 Docker容器卷是什么
卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过Union File System提供一些用于持续存储或共享数据的特性:
卷的设计目的就是数据的持久化,完全独立于容器的生存周期,因此Docker不会在容器删除时删除其挂载的数据卷。 一句话:有点类似我们Redis里面的rdb和aof文件。
运行一个带有容器卷存储功能的容器实例:
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名
2 Docker容器卷能干嘛
* 将运用与运行的环境打包镜像,run后形成容器实例运行 ,但是我们对数据的要求希望是持久化的
Docker容器产生的数据,如果不备份,那么当容器实例删除后,容器内的数据自然也就没有了。
为了能保存数据在docker中我们使用卷。
特点:
1:数据卷可在容器之间共享或重用数据
2:卷中的更改可以直接实时生效,爽
3:数据卷中的更改不会包含在镜像的更新中
4:数据卷的生命周期一直持续到没有容器使用它为止
3 数据卷案列
3.1 宿主VS容器之间映射添加容器卷
命令格式:
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名
[root@docker ~]# docker run -it --name test-data --privileged=true -v /tmp/myHostData:/tmp/myDockerData ubuntu /bin/bash


3.2 查看数据卷是否挂载成功
docker inspect 容器ID


可以看到已经挂载成功
3.3 验证容器和宿主机之间数据是否能共享
1 docker修改,主机同步获得
2 主机修改,docker同步获得
3 docker容器stop,主机修改,docker容器重启看数据是否同步。

3.4 数据卷读写规则映射添加说明
1. 读写(默认)
数据卷添加之后系统模式是有读写(rw)权限的,默认就是rw
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录:rw 镜像名
2. 只读
容器实例内部被限制,只能读取不能写入

docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录:ro 镜像名
/容器目录:ro 镜像名 就能完成功能,此时容器自己只能读取不能写
ro = read only
此时如果宿主机写入内容,可以同步给容器内,容器可以读取到。但是容器内就没有写入权限。
3.5 卷的继承和共享
容器1完成和宿主机的映射
docker run -it --privileged=true -v /mydocker/u:/tmp --name u1 ubuntu
容器2继承容器1的卷规则
docker run -it --privileged=true --volumes-from 父类 --name u2 ubuntu

九. Docker常规安装简介
1 总体步骤
docker search xxx —— docker pull xxx —— docker images —— docker run -it -pxxx:xxx xxx —— docker stop xxx —— docker rm xxx
搜索镜像——拉取镜像——查看镜像——启动镜像(服务端口映射)——停止容器——移除容器
2 安装Tomcat
1.docker hub 上面查找Tomcat镜像—— docker search tomcat

2. 从docker hub上拉取Tomcat镜像到本地—— docker pull tomcat

3. docker images 查看是否有拉取到tomcat

4. 使用tomcat镜像创建容器实例(也叫运行镜像)
docker run -d -p 8080:8080 tomcat
参数解释: -p: 小写,主机端口:docker容器端口 -P: 大写,随机分配端口 比如 :32487:8080
-i : 交互 -t:终端 -d: 后台

5. 访问Tomcat首页
问题:
解决:
① 可能没有映射端口或者没有关闭防火墙

② 把容器内Tomcat里面的webapps.dist目录换成webapps

③ 验证是否可以访问到首页

6. 免修改版说明
这个版本的镜像是不用修改webapps的,运行即可直接访问到首页。
docker pull billygoo/tomcat8-jdk8
docker run -d -p 8080:8080 --name mytomcat8 billygoo/tomcat8-jdk8

3 安装MySQL
1. docker hub 上面查找MySQL镜像

2. 从docker hub上(阿里云加速器)拉取mysql镜像到本地标签为5.7

3. 使用mysql5.7镜像创建容器(也叫运行镜像)
命令出处,来自docekr 官网

① 安装简单版
使用mysql镜像
| docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7 |
| docker ps |
| docker exec -it 容器ID /bin/bash |
| mysql -uroot -p |

建库建表插入数据

使用外部Win10 SQLyog 来连接运行在dokcer上的mysql容器实例服务

问题1:
插入不了中文数据——docker上默认字符集编码隐患
docker里面的mysql容器实例查看,内容如下:
SHOW VARIABLES LIKE 'character%'

问题2:
删除容器后,里面的mysql数据如何办?
容器实例一删除,你还有什么? 删容器到跑路。。。。。?
所以需要创建下面的实战版的MySQL
② 实战版
新建mysql容器实例
docker run -d -p 3306:3306 --privileged=true -v /test/mysql/log:/var/log/mysql -v /test/mysql/data:/var/lib/mysql -v /test/mysql/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=123456 --name mysql mysql:5.7

新建my.cnf ——通过容器卷同步给mysql容器实例
| [client] default_character_set=utf8 [mysqld] collation_server = utf8_general_ci character_set_server = utf8 |

重新启动mysql容器实例在重新进入并查看字符编码

再新建库新建表再插入中文测试


结论:
之前的DB 无效
修改字符集操作+重启mysql容器实例,之后的DB 有效,需要新建。
结论:docker安装完MySQL并run出容器后,建议请先修改完字符集编码后再新建mysql库-表-插数据

4 安装Redis
1. 从docker hub上(阿里云加速器)拉取redis镜像到本地标签为6.0.8

2. 入门命令

命令提醒:容器卷记得加入--privileged=true
3. 在CentOS宿主机下新建目录/app/redis
mkdir -p /app/redis
4. 将一个redis.conf文件模板拷贝进/app/redis目录下,并修改redis.conf文件
/app/redis目录下修改redis.conf文件
开启redis验证 可选
requirepass 123
允许redis外地连接 必须
注释掉 # bind 127.0.0.1

daemonize no
将daemonize yes注释起来或者 daemonize no设置,因为该配置和docker run中-d参数冲突,会导致容器一直启动失败

开启redis数据持久化 appendonly yes 可选
默认出厂的原始redis.conf文件如果本地没有,就去百度或google下载下来。
5. 使用redis6.0.8镜像创建容器(也叫运行镜像)
redis-server /etc/redis/redis.conf ##指定以这份配置文件来启动redis
| docker run -p 6379:6379 --name myredis --privileged=true -v /app/redis/redis.conf:/etc/redis/redis.conf -v /app/redis/data:/data -d redis:6.0.8 redis-server /etc/redis/redis.conf |

6. 测试redis-cli连接上来

7. 证明docker启动使用了我们自己指定的配置文件
修改前:

修改后:

宿主机的修改会同步给docker容器里面的配置。(记得重启服务) docker restar myredis
8. 再次测试redis-cli连接上来

十. Docker 复杂安装案列
1 安装MySQL主从复制
1.2 主从复制原理:
MySQL主从复制是一个异步的复制过程,主库发送更新事件到从库,从库读取更新记录,并执行更新记录,使得从库的内容与主库保持一致。
binlog:binary log,主库中保存所有更新事件日志的二进制文件。binlog是数据库服务启动的一刻起,保存数据库所有变更记录(数据库结构和内容)的文件。在主库中,只要有更新事件出现,就会被依次地写入到binlog中,之后会推送到从库中作为从库进行复制的数据源。
binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。 对于每一个即将发送给从库的sql事件,binlog输出线程会将其锁住。一旦该事件被线程读取完之后,该锁会被释放,即使在该事件完全发送到从库的时候,该锁也会被释放。
在从库中,当复制开始时,从库就会创建从库I/O线程和从库的SQL线程进行复制处理。
从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。 从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。
综上所述,可知:
对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
从库通过创建两个独立的线程,使得在进行复制时,从库的读和写进行了分离。因此,即使负责执行的线程运行较慢,负责读取更新语句的线程并不会因此变得缓慢。比如说,如果从库有一段时间没运行了,当它在此启动的时候,尽管它的SQL线程执行比较慢,它的I/O线程可以快速地从主库里读取所有的binlog内容。这样一来,即使从库在SQL线程执行完所有读取到的语句前停止运行了,I/O线程也至少完全读取了所有的内容,并将其安全地备份在从库本地的relay log,随时准备在从库下一次启动的时候执行语句。
1.3 主从搭建步骤
1. 新建主服务器实例3307
docker run -p 3307:3306 --name mysql-master \
-v /mydata/mysql-master/log:/var/log/mysql \
-v /mydata/mysql-master/data:/var/lib/mysql \
-v /mydata/mysql-master/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
2. 进入/mydata/mysql-master/conf目录下新建my.cnf
[root@docker ~]# cd /mydata/mysql-master/conf/
[root@docker conf]# vim my.cnf
[root@docker conf]# cat my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
[root@docker conf]#
3. 修改完配置后重启master实例
[root@docker ~]# docker restart mysql-master
mysql-master
[root@docker ~]#
4. 进入mysql-master容器
[root@docker ~]# docker exec -it mysql-master /bin/bash
root@5c402990f0aa:/# mysql -uroot -proot
5. master容器实例内创建数据同步用户
| CREATE USER 'slave'@'%' IDENTIFIED BY '123456'; |
| GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%'; |
mysql> CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
Query OK, 0 rows affected (0.01 sec)
6. 新建从服务器容器实例3308
docker run -p 3308:3306 --name mysql-slave \
-v /mydata/mysql-slave/log:/var/log/mysql \
-v /mydata/mysql-slave/data:/var/lib/mysql \
-v /mydata/mysql-slave/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=root \
-d mysql:5.7
7. 进入/mydata/mysql-slave/conf目录下新建my.cnf
[root@docker ~]# cd /mydata/mysql-slave/conf/
[root@docker conf]# ls
[root@docker conf]# vim my.cnf
[root@docker conf]# cat my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1
[root@docker conf]#
8. 修改完配置后重启slave实例
[root@docker ~]# docker restart mysql-slave
mysql-slave
[root@docker ~]#
9. 在主数据库中查看主从同步状态
| show master status; |

10. 进入mysql-slave容器

11. 在从数据库中配置主从复制
| change master to master_host='宿主机ip', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=617, master_connect_retry=30; |
mysql> change master to master_host='192.168.50.38', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysqll-bin.000001', master_log_pos=617, master_connect_retry=30;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
主从复制命令参数说明
master_host:主数据库的IP地址;
master_port:主数据库的运行端口;
master_user:在主数据库创建的用于同步数据的用户账号;
master_password:在主数据库创建的用于同步数据的用户密码;
master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
master_connect_retry:连接失败重试的时间间隔,单位为秒。
12. 在从数据库中查看主从同步状态
| show slave status \G; |

13. 在从数据库中开启主从同步
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
14. 查看从数据库状态发现已经同步

15. 主从复制测试
主机新建库-使用库-新建表-插入数据,
mysql> create database db1;
mysql> use db1;
mysql> create table aa(id int , name varchar(10));
mysql> insert into aa values(1,"test");
mysql> insert into aa values(2,"test2");
进入从机使用库-查看记录,

2 安装redis集群 (大厂面试题-分布式存储案例真题)
cluster(集群)模式-docker版——哈希槽分区进行亿级数据存储
2.1 面试题
1~2亿条数据需要缓存,请问如何设计这个存储案例?
回答: 单机单台100%不可能,肯定是分布式存储,用redis如何落地?
上述问题阿里P6~P7工程案例和场景设计类必考题目,
一般业界有3种解决方案:
1. 哈希取余分区
| 2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式: hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。 |
| 优点: 简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。 |
| 缺点: 原来规划好的节点,进行扩容或者缩容就比较麻烦了额,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。 某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。 |
2. 一致性哈希算法分区
是什么?
一致性Hash算法背景
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。
能干嘛?
提出一致性Hash解决方案。目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系。
三大步骤:
算法构建一致性哈希环:
一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对2^32取模,简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。

服务器ip节点映射:
节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:

key落到服务器的落键规则:
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。

优点:
一致性哈希算法的容错性
容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。

一致性哈希算法的扩展性
扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那受到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,
不会导致hash取余全部数据重新洗牌。

缺点:
一致性哈希算法的数据倾斜问题
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,
例如系统中只有两台服务器:

小总结:
为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。
而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
3. 哈希槽分区
是什么?
为什么出现:

哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
能干什么:
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。

槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
多少个hash槽:
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
哈希槽计算:
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上


2.2 Redis 安装详细步骤
2.2.1 3主3从redis集群配置
1. 关闭防火墙+启动docker后台服务
[root@docker ~]# systemctl stop firewalld.service
[root@docker ~]# systemctl start docker
2. 新建6个docker容器Redis实例
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386

命令参数分步解释:
docker run —— 创建并运行docker容器实例
-- name redis-node-6 —— 容器名字
-- net host —— 使用宿主机的ip和端口,默认
-- privileged=true —— 获取宿主机root用户权限
-v /data/redis/share/redis-node-6:/data —— 容器卷,宿主机地址:docker内部地址
redis:6.0.8 —— redis镜像和版本号
-- cluster-enabled yes —— 开启持久化
-- prot 6386 —— redis 端口号
3. 进入容器redis-node-1并为6台机器构建集群关系
进入容器:
[root@docker ~]# docker exec -it redis-node-1 /bin/bash
root@docker:/data#
构建主从关系:
//注意,进入docker容器后才能执行以下命令,且注意自己的真实IP地址
| redis-cli --cluster create 192.168.50.38:6381 192.168.50.38:6382 192.168.50.38:6383 192.168.50.38:6384 192.168.50.38:6385 192.168.50.38:6386 --cluster-replicas 1 |
--cluster-replicas 1 表示为每个master创建一个slave节点

一切显示ok的话,就说明3主3从搞定。
4. 连接进入6381作为切入点,查看集群状态
cluster info
cluster nodes

2.2.2 主从容错切换迁移案例
1. 数据读写存储
随便进入一台redis节点,对该节点新增两个key
redis集群如果要进入存储数据,需要加上-c参数,优化路由。

查看集群信息:
| redis-cli --cluster check 192.168.50.38:6381 |

2. 容错切换迁移测试
主6381和从机切换测试,先停止主机6381:
[root@docker ~]# docker stop redis-node-1
redis-node-1
6381主机停了,对应的真实从机上位,6381作为1号主机分配的从机以实际情况为准,具体是几号机器就是几号。
再次查看集群信息:

备注:本次笔记6381为主 ,下面的6385为从
每次案例下面挂的从机以实际情况为准,具体是几号机器就是几号
还原之前的3主3从:
启动6381机器前

开启6381
[root@docker ~]# docker start redis-node-1
redis-node-1
[root@docker ~]#
启动6381机器后

我们可以看到6381启动后,没有变成之前的主,现在变为了6385的从了。
如果我们需要让6381变为之前的主,6385变为之前的从的话,那只需要把6385停掉,然后再启动一下,就可以了。

#备注: 主从机器分配情况以实际情况为准
最后在查看一下集群的状态:
redis-cli --cluster check 自己IP:6381

2.2.3 主从扩容案列
1. 新建6387、6388两个节点+新建后启动+查看是否8节点
| docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387 |
| docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388 |
| docker ps |
2. 进入6387容器实例内部
[root@docker ~]# docker exec -it redis-node-7 /bin/bash
3. 将新增的6387节点(空槽号)作为master节点加入原集群
| 将新增的6387作为master节点加入集群 redis-cli --cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381 6387 就是将要作为master新增节点 6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群 |

4. 检查集群情况第1次
redis-cli --cluster check 真实ip地址:6381

5. 重新分派槽号
| 重新分派槽号 命令:redis-cli --cluster reshard IP地址:端口号 redis-cli --cluster reshard 192.168.50.38:6381 |


6. 检查集群情况第2次
redis-cli --cluster check 真实ip地址:6381

槽号分派说明:”
| 为什么6387是3个新的区间,以前的还是连续? 重新分配成本太高,所以前3家各自匀出来一部分,从6381/6382/6383三个旧节点分别匀出1364个坑位给新节点6387 |
7. 为主节点6387分配从节点6388
| 命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID redis-cli --cluster add-node 192.168.50.38:6388 192.168.50.38:6387 --cluster-slave --cluster-master-id e4781f644d4a4e4d4b4d107157b9ba8144631451-------这个是6387的编号ID,按照自己实际情况 |

8. 检查集群情况第3次
| redis-cli --cluster check 192.168.50.38:6382 |

2.2.4 主从缩容案例
目的:6387和6388下线
1. 检查集群情况获得6388的节点ID
| redis-cli --cluster check 192.168.50.38:6382 |

2.将6388从集群从节点删除
| 命令:redis-cli --cluster del-node ip:从机端口 从机6388节点ID redis-cli --cluster del-node 192.168.50.38:6388 98c01ad5e765d2794f199b2f5abf2e863ad23c97 |

| redis-cli --cluster check 192.168.50.38:6382 |
检查一下发现,6388被删除了,只剩下7台机器了。

3. 将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
| redis-cli --cluster reshard 192.168.50.38:6381 |

![]()
4. 检查集群情况第二次
| redis-cli --cluster check 192.168.50.38:6381 4096个槽位都指给6381,它变成了8192个槽位,相当于全部都给6381了,不然要输入3次,一锅端 |

5. 将6387删除
| 命令:redis-cli --cluster del-node ip:端口 6387节点ID redis-cli --cluster del-node 192.168.50.38:6387 c447e1ea1cc07511e41f27b85dd0296ce39371f1 |

6.检查集群情况第三次
| redis-cli --cluster check 192.168.50.38:6381 |

收工~

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)