

一文带你走进【内存泄漏】
没想到项目放到线上后,随着请求量的增多,却感觉到首屏速度越来越慢,并且是在持续性地变慢。而且在发布完后(也就是容器重建了),耗时又陡然降下来了。因此很合理地怀疑是内存泄漏了。故而在 STKE 的监控面板瞧一瞧,内存确实是一波一波似浪花。知道是内存泄漏,我们就需要找到泄漏的点。因为不能轻易操作线上环境,线上代码也是压缩的,因此我们需要先搭建本地环境看能否方便调试问题。这里我们我们可以在本地起 Ser
0. 背景

没想到项目放到线上后,随着请求量的增多,却感觉到首屏速度越来越慢,并且是在持续性地变慢。而且在发布完后(也就是容器重建了),耗时又陡然降下来了。

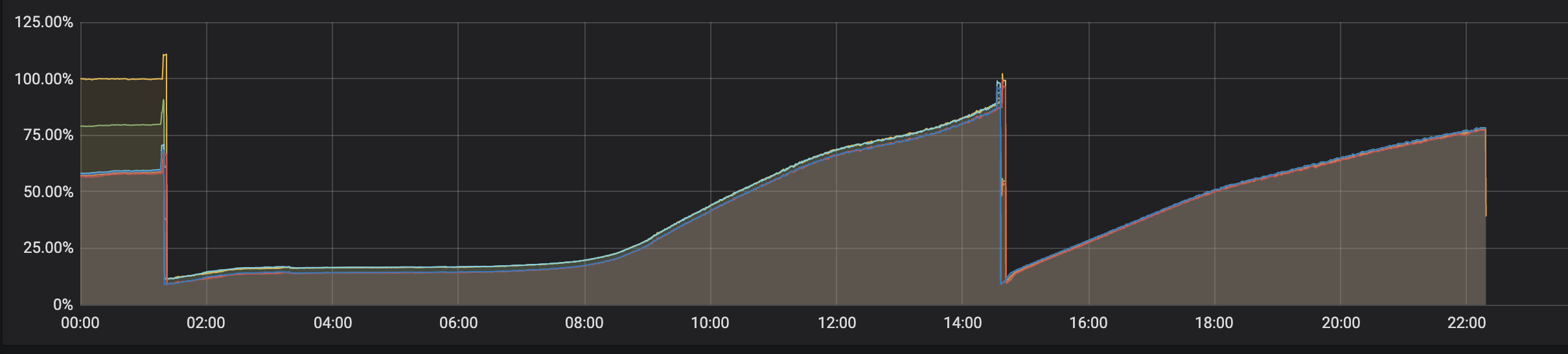
因此很合理地怀疑是内存泄漏了。故而在 STKE 的监控面板瞧一瞧,内存确实是一波一波似浪花。
1. 复现问题
知道是内存泄漏,我们就需要找到泄漏的点。因为不能轻易操作线上环境,线上代码也是压缩的,因此我们需要先搭建本地环境看能否方便调试问题。这里我们我们可以在本地起 Server 后,写脚本发起请求,来模拟线上环境。(但是看过上篇文章的小伙伴都知道,我们还有个骨架屏的模式,可以跳过发起 CGI 请求的步骤,大大降低单次请求耗时,让这个结果几秒钟就出来了)
我们可以使用 heapdump 包来将堆栈信息写入本地文件。heapdump 的基本使用姿势是这样的:
const heapdump = require('heapdump');
heapdump.writeSnapshot('./test.heapsnapshot');
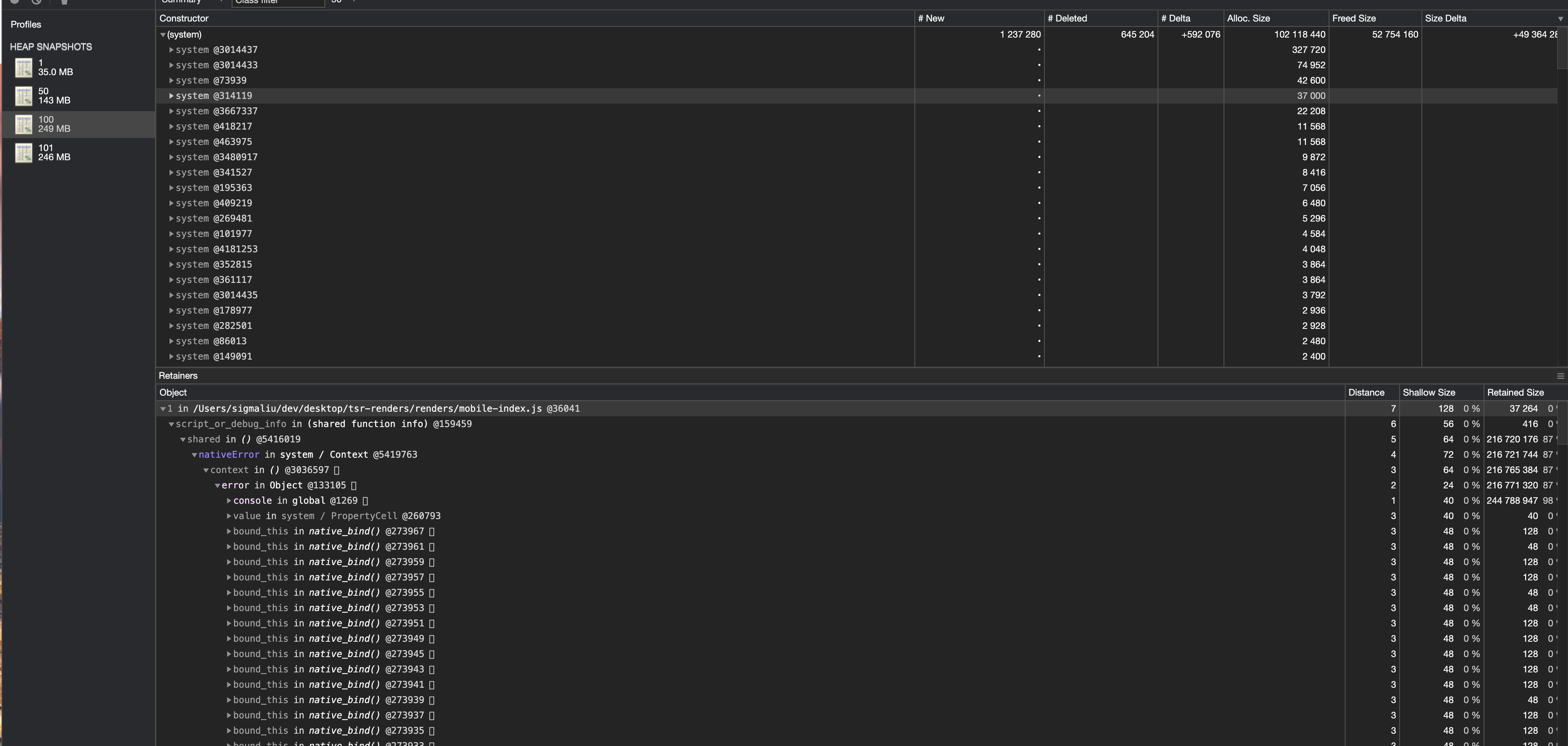
然后就可以将堆栈文件导入到 Chrome 开发者工具的 Memory 栏来分析。这里我选择了分别是运行了 1 次、50 次、100 次 以及等待几秒钟垃圾回收后再写个 101 次的堆栈信息。可以看到堆栈文件越变越大,从 35M 增大到 249M。
选择两个堆栈文件做比较来分析,这里有个技巧就是按内存大小排序,然后看到同一个大小的对象个数非常多,那么很有可能就是它被引用了很多次,泄漏的点就可能在那里。然后就发现了问题可能出在 console 对象上。
2. 分析问题
正常地使用 console 对象不会造成内存泄漏,因此就怀疑是否是对 console 做了什么操作。搜索了一番代码,排除正常调用外,发现有个赋值的操作,就类似于下面这段代码:
const nativeError = console.error;
console.error = (...argv) => {
// 省略一些操作
nativeError(...argv);
};
这段代码在前端开发中其实是比较常见的,比如需要在 log 中自动添加时间:
const nativeError = console.error;
console.error = (...argv) => {
nativeError(`[${(new Date()).toTimeString()}]`, ...argv);
};
console.error('Test');
// [20:58:17 GMT+0800 (中国标准时间)] Test
还有一个更常见的场景是,我们要在生产环境下屏蔽大部分的 log 输出,但是又要保留一个 log 函数引用,用来有时候在浏览器终端上输出一些关键信息,这时候会这么写:
// 引用,用来有时候在需要的时候上报
const logger = console.log;
// 必需用函数赋值,原有的一大堆使用 console.log('...') 的地方才不会报错
console.log = () => {};
logger('浏览器终端 AlloyTeam 招聘信息');
但是在我们的环境下,原来客户端的代码是被编译后放在 vm 里反复运行的,这会带来什么问题呢?
这里附个代码,感兴趣的小伙伴可以跑一下:
const vm = require('vm');
const heapdump = require('heapdump');
const total = 5000;
const writeSnapshot = (count) => {
heapdump.writeSnapshot(`./${count}-${total}.heapsnapshot`);
};
const code = `
const nativeError = console.error;
console.error = (...argv) => {
nativeError(argv);
}
`;
const script = new vm.Script(code);
for (let i = 1; i <= total; i++) {
script.runInNewContext({
console,
});
console.log(`${i}/${total}`);
switch (i) {
case 1:
case Math.floor(total * 0.5):
case total:
writeSnapshot(i);
}
}
setTimeout(() => {
writeSnapshot(total + 1);
}, 3000);
很小一段代码,运行 5000 次后内存占用到了 1G 多,并且还没有回收的迹象。

我们先来考虑在 vm 的环境下,差异点在于:
- vm 里是没有 console 对象的,vm 里的 console 对象是宿主环境传递进去的,在 vm 里针对 console 的修改,也会反映在宿主环境的 console 对象上;
- 在同一段代码多次执行的情况下,也就意味着这几次执行环境是共享 console 对象的,而在浏览器环境下,刷新页面后,代码被多次执行,环境都是独立的;
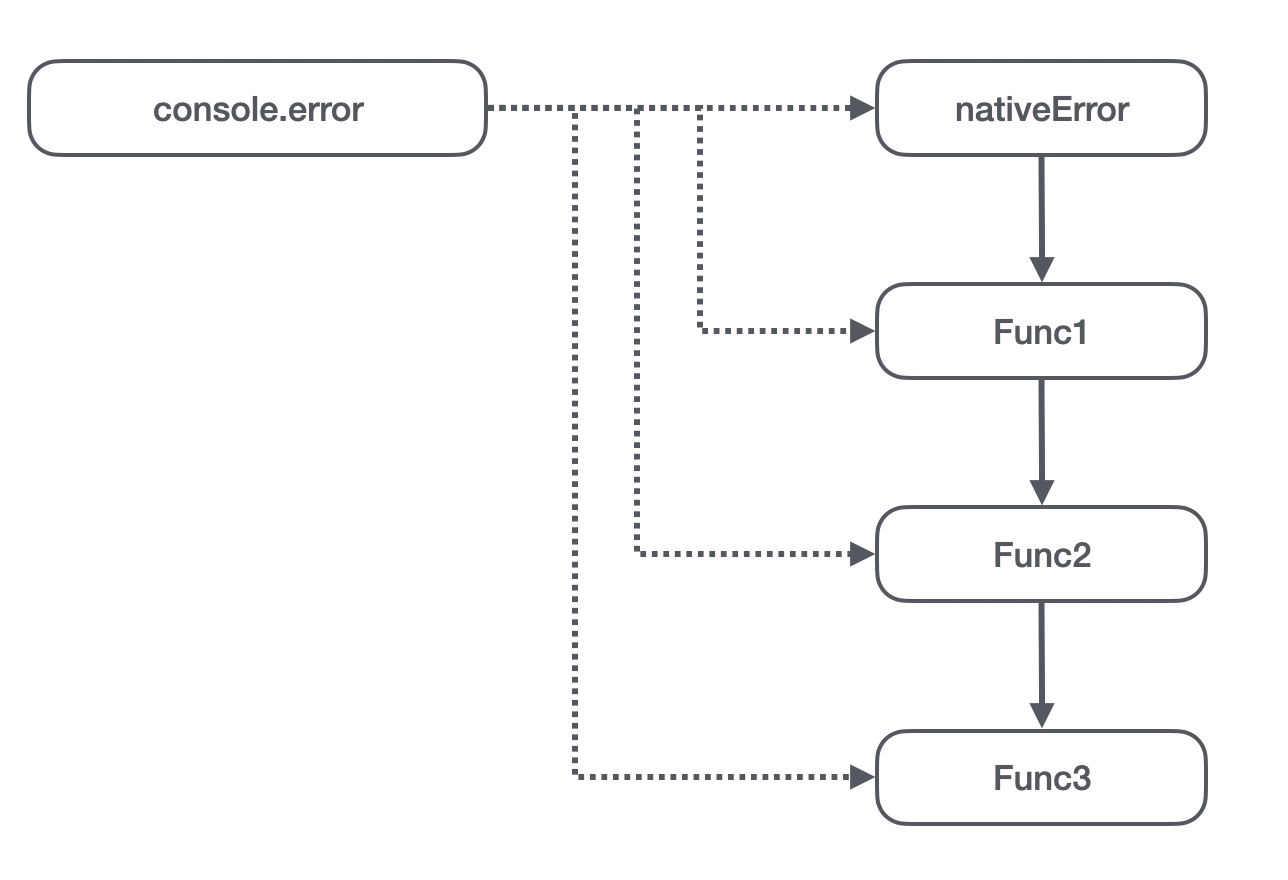
那么我们的问题就会出现如上图所示:
- 在宿主环境上,
console.error原来指向的是原生的 error 方法; - 在 vm 第一次执行的时候(假设这个过程要赋值的函数是 Func1),先是引用了
console.error,也就是引用了原生的 error 方法,同时通过赋值操作将宿主环境上的console.error指向了 Func1; - 在 vm 第二次执行的时候,也是先引用了
console.error方法,但是引用到的已经是第 2 步设置的 Func1,也就是 Func2 引用了 Func1。同时它又将宿主环境上的console.error设置成了 Func2; - 同理,Func3 引用了 Func2,并且
console.error指向了 Func3;
所以聪明的小伙伴们发现问题没有,这变成了一个链式引用。这条链上的对象一个都别想被回收,都被牢牢绑死了。

如果我们要解决这个问题,理想的引用模型应该是什么样的呢?
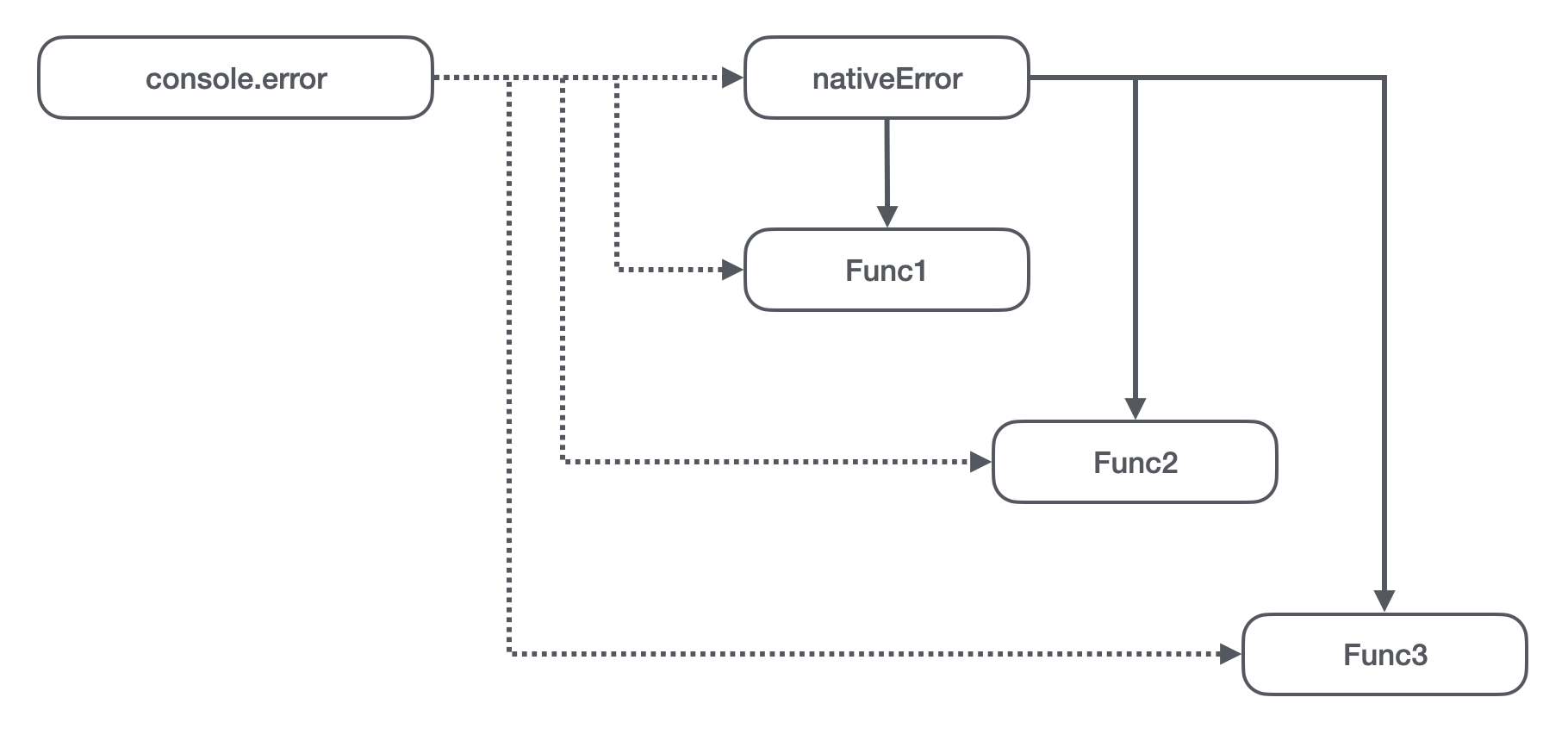
理想的一个引用模型应该是无论 vm 代码被执行了多少次,在我们取值和赋值操作应该做到:
- 取值操作始终取的是原生的 error 方法,因为如果取到了上次运行赋值的方法,那么就会存在引用关系;
- 赋值操作将不能操作到宿主环境的 console 对象,因为这样将会影响到其他批次 vm 里的全局 console 对象;
- 赋值操作后的取值操作将需要取到赋值后的方法,这样才能执行到自定义的逻辑;
这其实就要求我们不仅对 vm 的上下文做隔离,对 vm 创建的上下文所传递的属于宿主环境的引用对象也要做隔离。

3. 解决问题
有什么简单的解决办法吗?假设我们很清楚的认识到代码执行环境(多次执行且共享宿主对象),那么只需要做个标志位防止多次执行就可以了:
const nativeError = console.error;
if (!nativeError.hasBeenRewrite) {
console.error = (...argv) => {
nativeError(argv);
};
console.error.hasBeenRewrite = true;
}
但是在原来运行于客户端的代码里会这么写的,感觉要么是已经遭遇过了这个问题,要么只能说优秀,一开始就有了这个意识!

那么当我们要做一个基础运行库的时候,可以做到不需要业务关心这么细的问题吗?也就是我们可能对对象隔离出上下文环境里的上下文环境吗?有这么几个条件是支持我们这么做的:
- 我们传递到 vm 里属于宿主环境的引用对象其实很有限,因此可以对这么几个有限的对象做隔离;
- 我们需要隔离的对象是跟随着 vm 创建的上下文的;
那么回到我们上文提到的理想模型,这里先附上代码,再来对整个方案做解读:
const vm = require('vm');
const heapdump = require('heapdump');
const total = 5000;
const writeSnapshot = (count) => {
heapdump.writeSnapshot(`./${count}-${total}.heapsnapshot`);
};
const code = `
const nativeError = console.error;
console.error = (...argv) => {
nativeError(...argv);
}
`;
const script = new vm.Script(code);
const vmProxy = (context, obj, name) => {
const proxyStore = {};
const proxyObj = new Proxy(obj, {
get: function (target, propKey) {
if (proxyStore[name] && proxyStore[name][propKey]) {
return proxyStore[name][propKey];
}
return target[propKey];
},
set: function (target, propKey, value) {
if (!proxyStore[name]) {
proxyStore[name] = {};
}
const defineObj = proxyStore[name];
if ((typeof value === 'function' || typeof value === 'object') && value !== null) {
defineObj[propKey] = value;
}
},
});
context[name] = proxyObj;
context.proxyStore = proxyStore;
return context;
};
for (let i = 1; i <= total; i++) {
const context = vmProxy({}, console, 'console');
script.runInNewContext(context);
console.log(`${i}/${total}`);
switch (i) {
case 1:
case Math.floor(total * 0.5):
case total:
writeSnapshot(i);
}
}
setTimeout(() => {
writeSnapshot(total + 1);
}, 3000);
这里有几个关键的点:
- 用
Proxy方法,对 console 的属性 get 操作做拦截; - 我们将在 vm 上下文对象上设置
proxyStore对象用来存储 set 操作设置的值,这个proxyStore将跟随着上下文的回收而回收; - 对 console 的 set 操作将不会设置到 console 上而影响宿主环境的引用对象,但是又需要做存储;
分步骤来看:
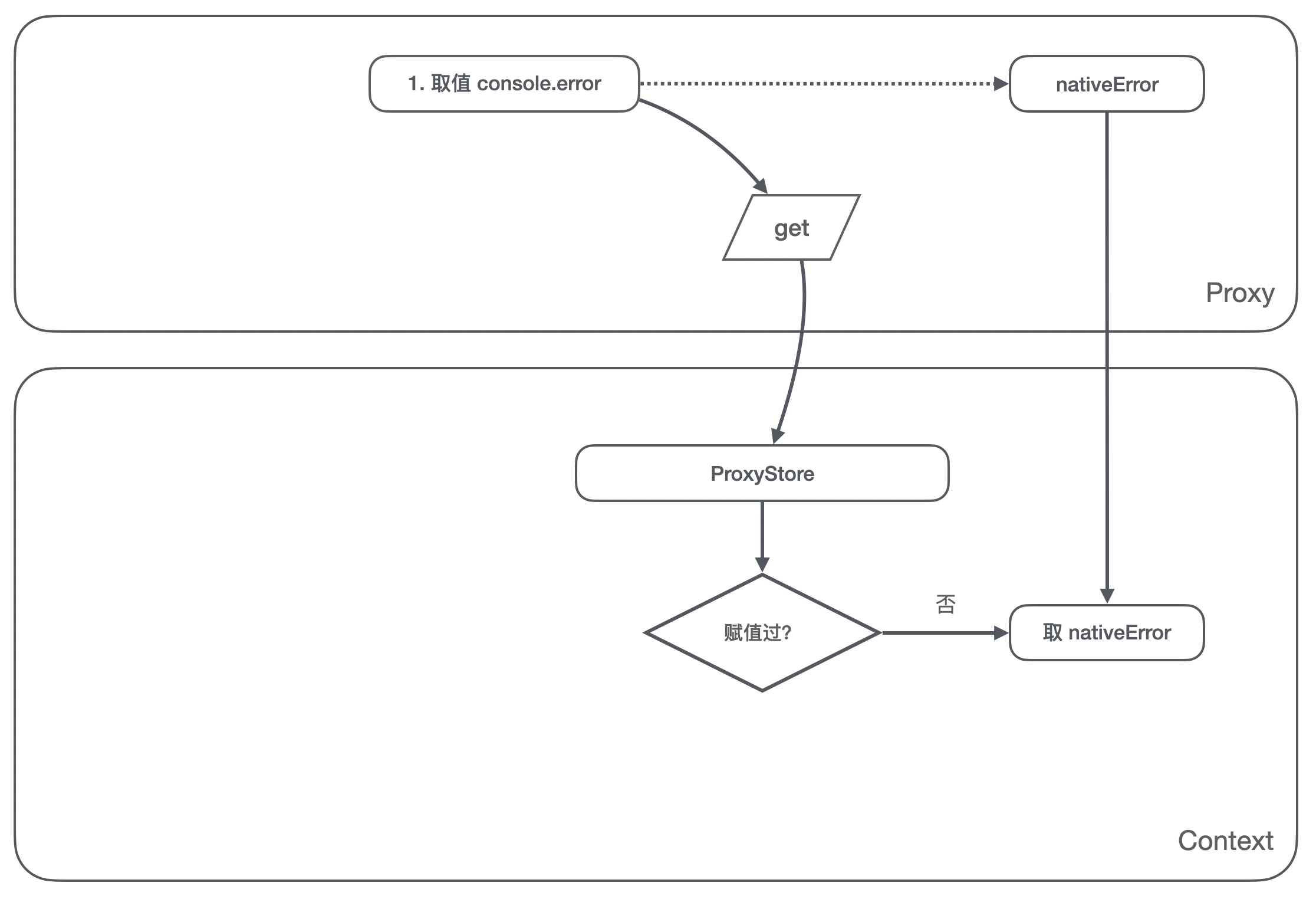
- 对
console.error的取值操作,我们判断 ProxyStore 里是否被当前环境设置过了,这时候没有,那么我们给取值操作返回原生的 error 方法;
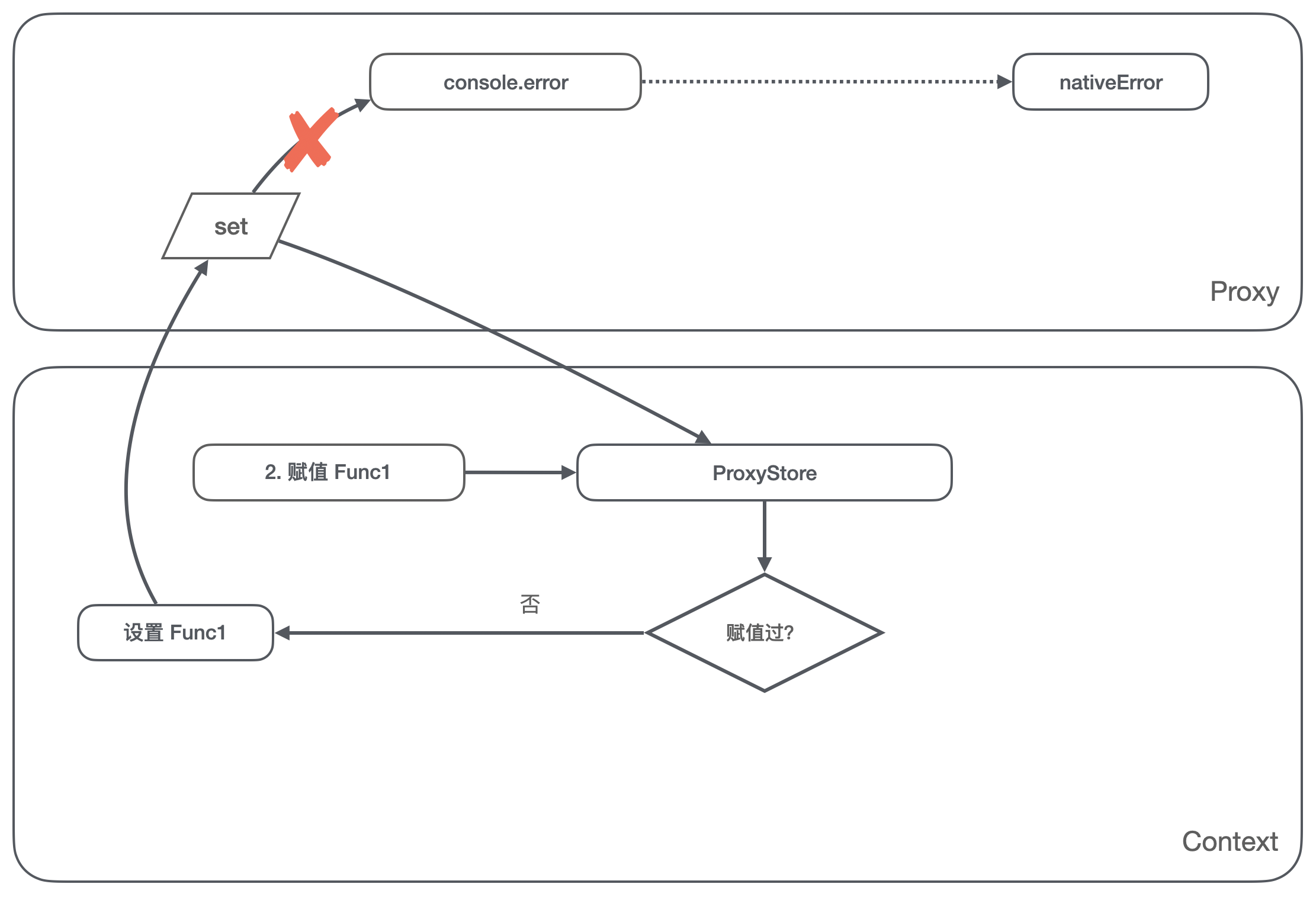
- 对
console.error赋值 Func1 的操作,我们判断 ProxyStore 里没有存储对这个属性的赋值,那么将 Func1 存储到 ProxyStore,这里注意我们不能将 Func1 设置到console.error上;
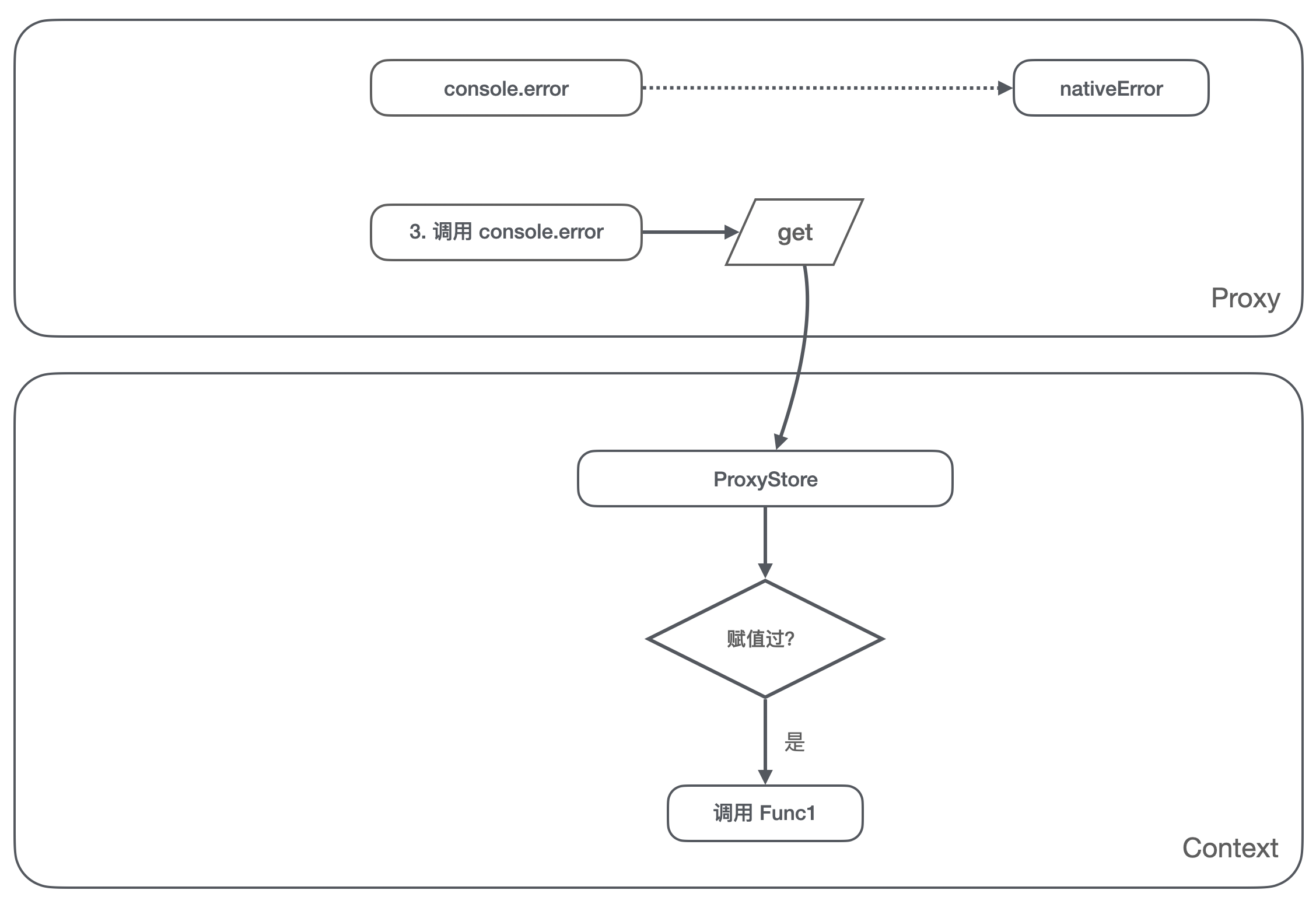
- 在后续的调用
console.error操作,又会被我们拦截 get 方法,我们判断到 ProxyStore 里有被赋值过 Func1,这时候返回 Func1,调用console.error就变成了调用Func1;
通过以上的操作,我们维持了 console.error 始终指向原生 error 方法,每次的引用也都是引用的原生的 error 方法,而不是上一次设置的方法。
然后我们就解决了这个内存泄漏的问题:

4. 规避问题
用这么个聪明的方法解决了这个问题,貌似都有点欣赏自己了呢。

但是我们再来考虑 Proxy 会带来什么问题,会有性能问题吗?
实践出真知,我们对比上面两种解决方法的性能差异:
const vm = require('vm');
const total = 10000;
const vmProxy = (context, obj, name) => {
const proxyStore = {};
const proxyObj = new Proxy(obj, {
get: function (target, propKey) {
if (proxyStore[name] && proxyStore[name][propKey]) {
return proxyStore[name][propKey];
}
return target[propKey];
},
set: function (target, propKey, value) {
if (!proxyStore[name]) {
proxyStore[name] = {};
}
const defineObj = proxyStore[name];
if ((typeof value === 'function' || typeof value === 'object') && value !== null) {
defineObj[propKey] = value;
}
},
});
context[name] = proxyObj;
context.proxyStore = proxyStore;
return context;
};
(() => {
const code = `
const nativeError = console.error;
console.error = (...argv) => {
nativeError(...argv);
}
`;
const script = new vm.Script(code);
console.time('proxy');
for (let i = 1; i <= total; i++) {
const context = vmProxy({}, console, 'console');
script.runInNewContext(context);
}
console.timeEnd('proxy');
})();
(() => {
let code = `
const nativeError = console.error;
if (!nativeError.hasBeenRewrite) {
console.error = (...argv) => {
nativeError(argv);
};
console.error.hasBeenRewrite = true;
}
`;
let script = new vm.Script(code);
console.time('flag');
for (let i = 1; i <= total; i++) {
script.runInNewContext({
console,
});
}
console.timeEnd('flag');
})();
看起来几乎没什么性能差异
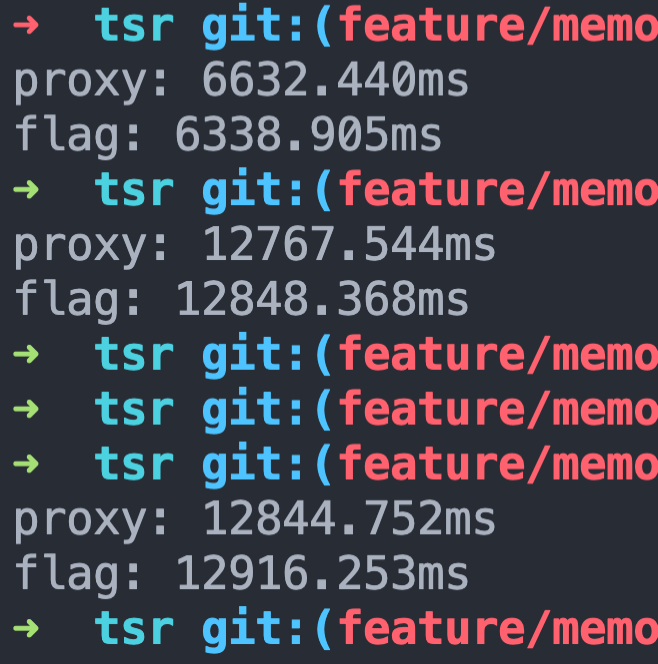
但是 Proxy 有个 this 指向的问题,因为 Proxy 不是个透明代理,被 Proxy 代理的对象内部的 this 指向会指向 proxy 实例,因此如果是这么个简单例子还好,但是放到线上代理比较复杂的对象,心里还是毛毛的。(还需要考虑对象里的对象)
有没有可能在开发阶段就能发现类似的内存泄漏问题,而不是等到发布线上才发现呢?

当然是想到了办法我才会说了,之前想这个问题的时候想了一下午,想得太复杂了,所以试了好多种方法也没有想出来。我们先来澄清一点,这里是因为要赋值的函数里又调用了存储的 nativeError 吗?其实是无关的,即使你将 nativeError(...argv) 注释掉,仍然是会存在内存泄漏的问题。
const nativeError = console.error;
console.error = (...argv) => {
nativeError(...argv);
}
这里的原因在于只要同一个 vm 虚拟机里对宿主环境的引用对象的同一个 key 同时做 get 和 set 操作,那么就会存在内存泄漏。我们来考虑下面这三种情况是否会存在内存泄漏:
相同的 key:
const nativeError = console.undefined;
console.undefined = (...argv) => {
nativeError(argv);
}
不同的 key:
const nativeError = console.undefined;
console.notExist = (...argv) => {
nativeError(argv);
}
设置的不是引用对象:
const nativeError = console.error;
console.error = 'AlloyTeam';
答案是第一个会存在内存泄漏,第二和第三不会。好奇的小伙伴可以用上面的例子代码跑一下。
我们将这个问题简化了,再来看检测的方案,照例先上代码:
const { workerData, Worker, isMainThread } = require('worker_threads');
const vm = require('vm');
const log = console.log;
const memoryCheckStore = {};
const isReferenced = value => !!(value && typeof value === 'object' || typeof value === 'function');
const vmProxy = (context, obj, name) => {
const proxyObj = new Proxy(obj, {
get: function (target, propKey) {
const propValue = target[propKey];
if (!memoryCheckStore[obj]) {
memoryCheckStore[obj] = {};
}
// todo: 需要处理数组和迭代子对象
if (!memoryCheckStore[obj][propKey]) {
memoryCheckStore[obj][propKey] = 1;
}
return propValue;
},
set: function (target, propKey, value) {
if (isReferenced(value) && memoryCheckStore[obj][propKey]) {
log(new Error('[警告] 可能存在内存泄漏'));
}
target[propKey] = value;
},
});
context[name] = proxyObj;
return context;
};
const code1 = `
const nativeError = console.undefined;
// 泄漏
console.undefined = (...argv) => {}
`;
const code2 = `
const nativeError = console.undefined;
// 不会泄漏
console.notExist = (...argv) => {}
`;
const code3 = `
const nativeError = console.undefined;
// 不会泄漏
console.error = 'AlloyTeam';
`;
const code4 = `
const nativeError = console.error;
// 泄漏
console.error = (...argv) => {}
`;
if (isMainThread) {
for (let i = 1; i <= 4; i++) {
new Worker(__filename, {
workerData: {
code: eval(`code${i}`),
flag: i,
},
});
}
} else {
const { code, flag } = workerData;
const script = new vm.Script(code, {
filename: `code${flag}`,
});
const context = vmProxy({}, console, 'console');
script.runInNewContext(context);
}
仅一次运行,就知道 code1、code4 可能存在内存泄漏:
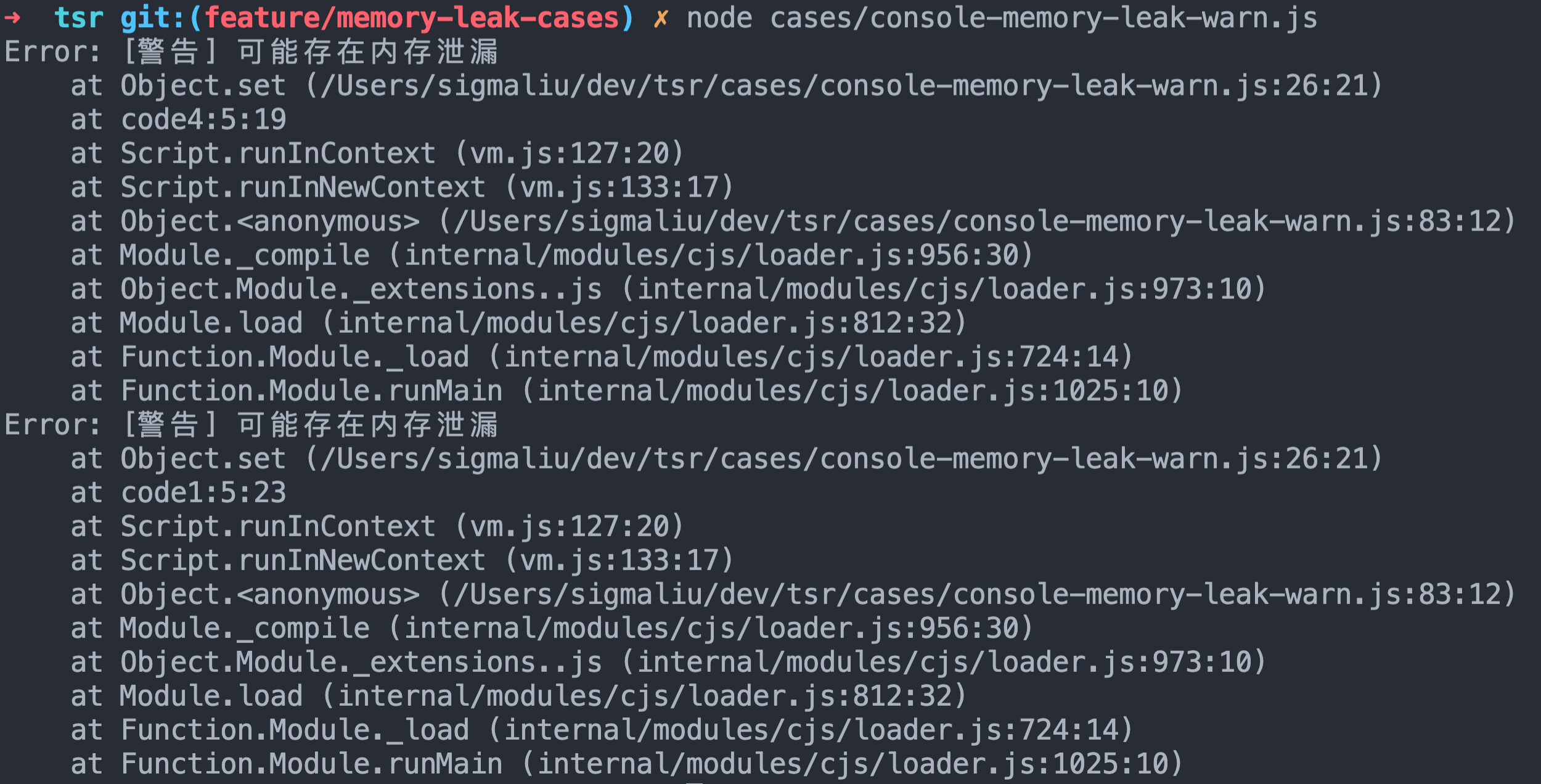
方案图解 1,get 阶段:
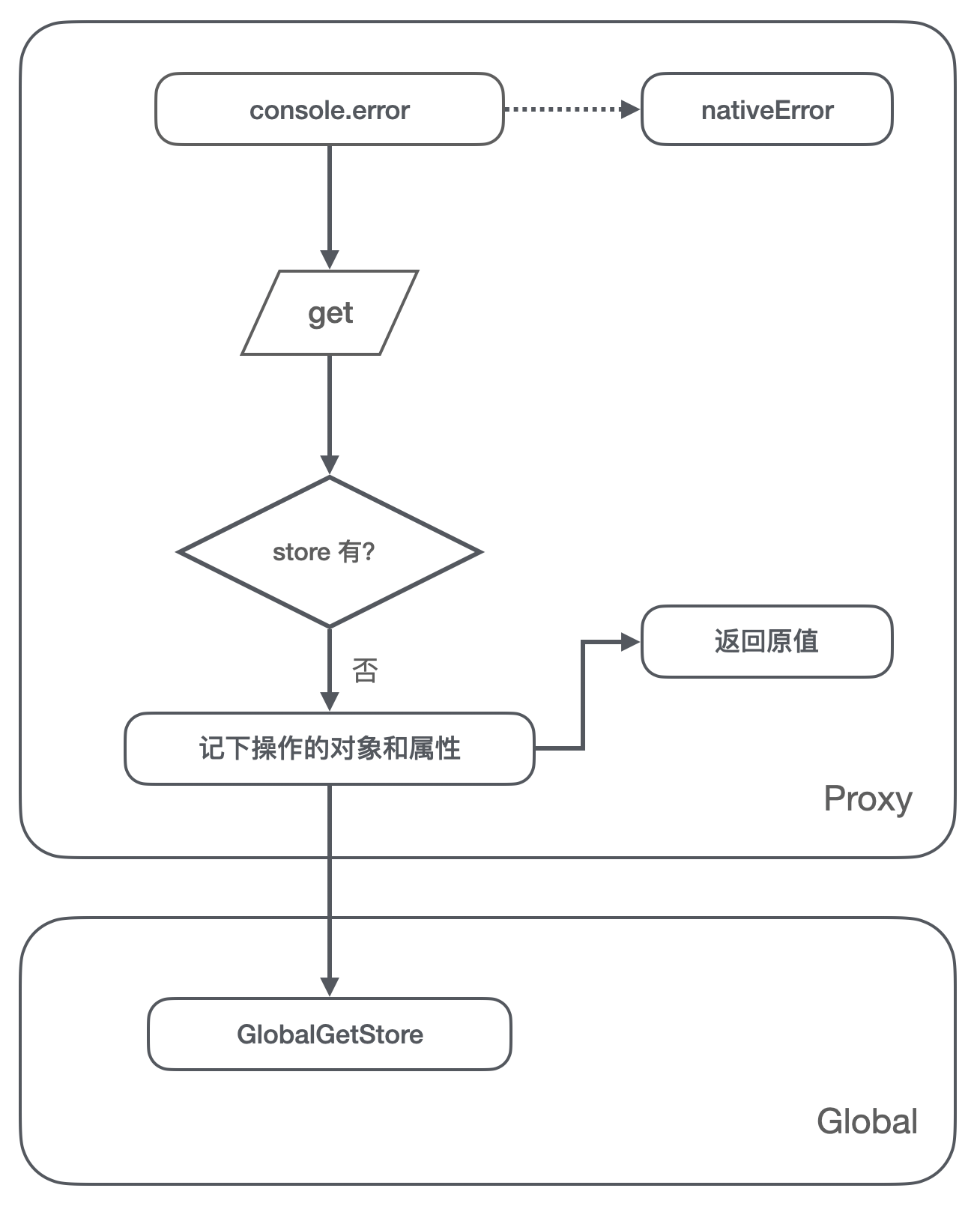
- 一开始
console.error指向原生的 error 方法; - 我们在全局设置个 GlobalGetStore 对象,用来记录被引用的对象和被引用的属性名;
- 第一次运行,拦截的 get 方法里判断 store 里没有这个对象,就记录对象到 store,同时也记录被引用的 key 值;
方案图解 2,set 阶段:
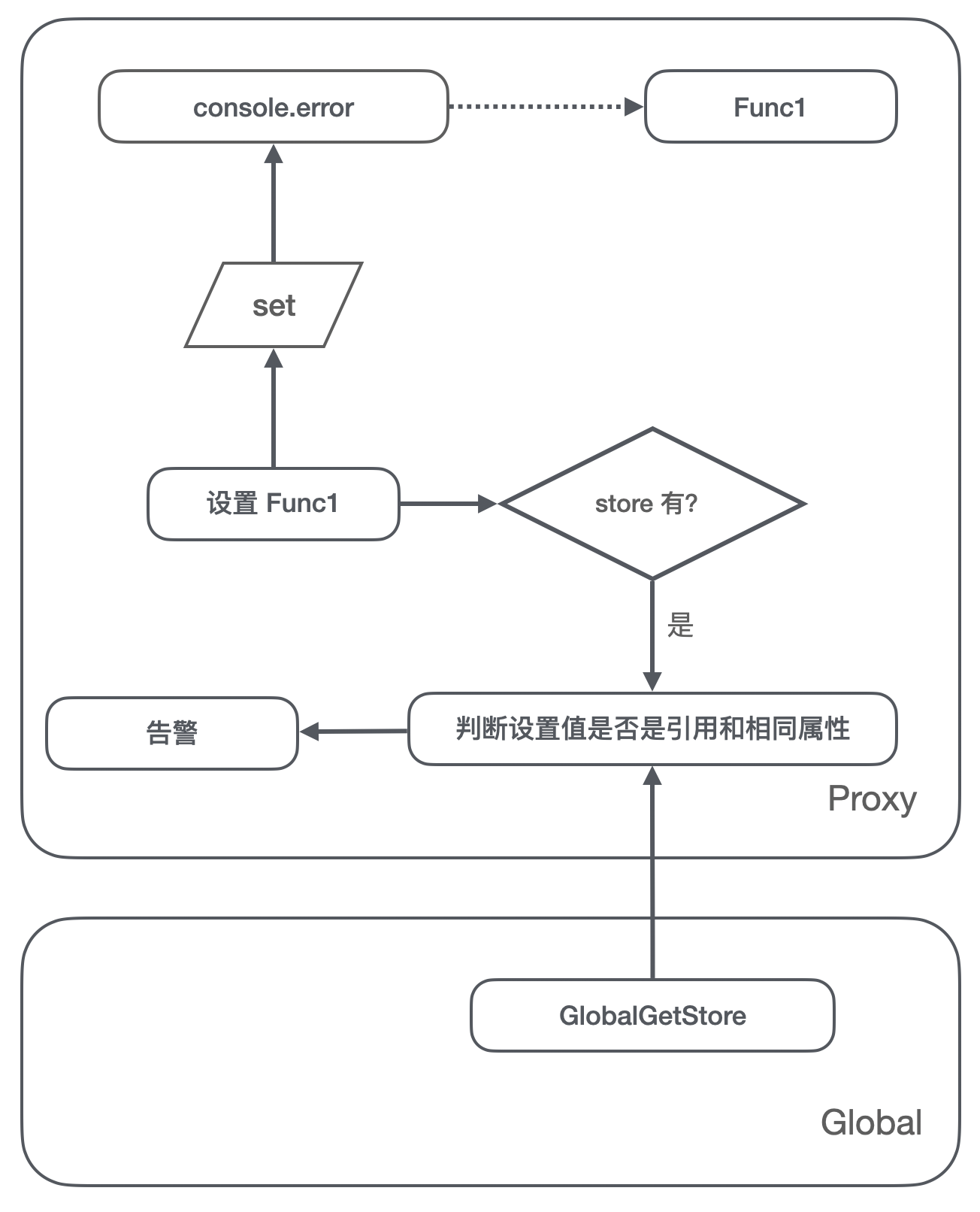
- 拦截的 set 方法里判断了 store 里已经有存储了被引用的对象,同时当次操作的 key 值也已经被引用过了,因此判定在 vm 这样多次执行的环境里,可能存在内存泄漏,打印出告警信息;
这样我们就可以在开发阶段部署这样内存检测代码(demo 代码仍然需要处理数组和对象属性是引用类型的情况),在生产环境上移除或失效。
当然了,一个较优秀的项目,上线前后仍然有两件相关的事情可以做:
- 自动化测试,通过模拟发起多个用户请求,检测内存变化,上线前检测到可能的内存泄漏;
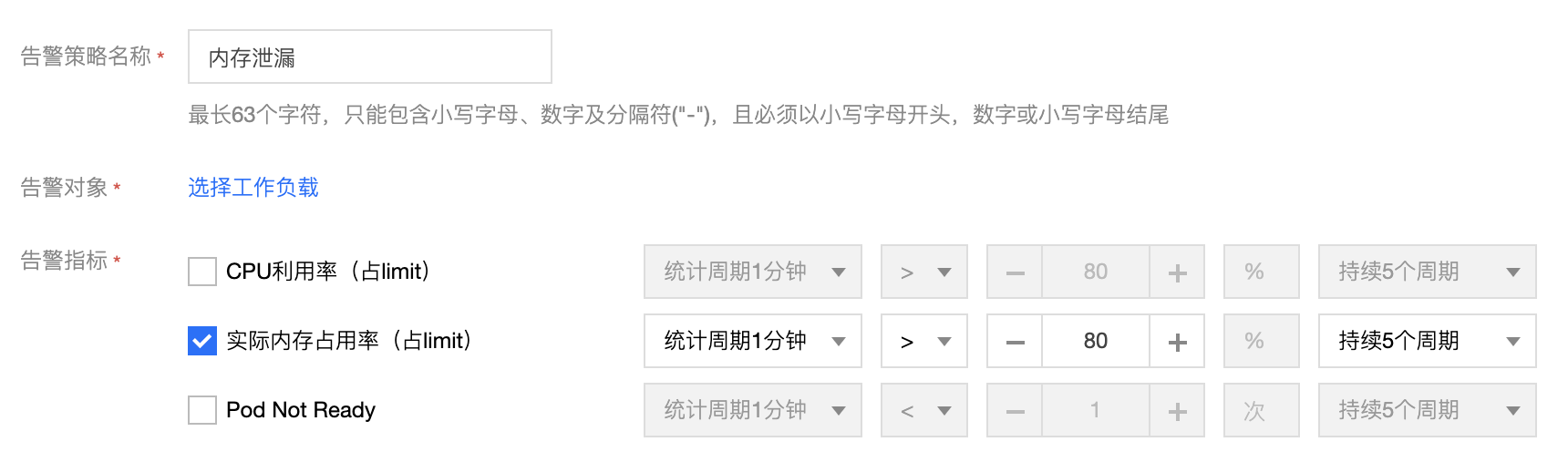
- 设置告警策略,在内存超限时告警,查看内存变化,确认是否泄漏;
5. 后记
遇到这样一个问题,其实还挺有趣的,虽然是一个小点,但是梳理了一个比较完整的思考过程,希望能对小伙伴们解决相关问题带来参考和想法。


权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 144
144 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)