
Java中的NIO与Netty框架
前言 随着移动互联网的爆发性增长,小明公司的电子商务系统访问量越来越大,由于现有系统是个单体的巨型应用,已经无法满足海量的并发请求,拆分势在必行。 在微服务的大潮之中, 架构师通常会把系统拆分成了多个服务,根据需要部署在多个机器上,这些服务非常灵活,可以随着访问量弹性扩展。 世界上没有免费的午餐, 拆分成多个“微服务”以后虽然增加了弹性,但也带来了一个巨大的挑战:各个服务之间互相调用的开销
前言
随着移动互联网的爆发性增长,小明公司的电子商务系统访问量越来越大,由于现有系统是个单体的巨型应用,已经无法满足海量的并发请求,拆分势在必行。

在微服务的大潮之中, 架构师通常会把系统拆分成了多个服务,根据需要部署在多个机器上,这些服务非常灵活,可以随着访问量弹性扩展。
世界上没有免费的午餐, 拆分成多个“微服务”以后虽然增加了弹性,但也带来了一个巨大的挑战:各个服务之间互相调用的开销。
比如说:原来用户下一个订单需要登录,浏览产品详情,加入购物车,支付,扣库存等一系列操作,在单体应用的时候它们都在一台机器的同一个进程中,说白了就是模块之间的函数调用,效率超级高。
现在好了,服务被安置到了不同的服务器上,一个订单流程,几乎每个操作都要越网络,都是远程过程调用(RPC), 那执行时间、执行效率可远远比不上以前了。
远程过程调用的第一版实现使用了HTTP协议,也就是说各个服务对外提供HTTP接口。HTTP协议虽然简单明了,但是太过繁琐太多,仅仅是给服务器发个简单的消息都会附带一大堆无用信息:
GET /orders/1 HTTP/1.1
Host: order.myshop.com
User-Agent: Mozilla/5.0 (Windows NT 6.1; )
Accept: text/html;
Accept-Language: en-US,en;
Accept-Encoding: gzip
Connection: keep-alive看看那User-Agent,Accept-Language ,这个协议明显是为浏览器而生的!对于各个应用程序之间的调用,用HTTP协议得不偿失。
能不能自定义一个精简的协议? 在这个协议中我们只需要把要调用方法名和参数发给服务器即可,根本不用这么多乱七八糟的额外信息。
但是自定义协议客户端和服务器端就得直接使用“低级”的Socket了,尤其是服务器端,得能够处理高并发的访问请求才行。
阻塞IO与非阻塞IO
至于服务器端的socket编程,最早的Java是所谓的阻塞IO(Blocking IO), 想处理多个socket的连接的话需要创建多个线程, 一个线程对应一个。

这种方式写起来倒是挺简单的,但是连接(socket)多了就受不了了,如果真的有成千上万个线程同时处理成千上万个socket,占用大量的空间不说,光是线程之间的切换就是一个巨大的开销。
更重要的是,虽然有大量的socket,但是真正需要处理的(可以读写数据的socket)却不多,大量的线程处于等待数据状态(这也是为什么叫做阻塞的原因),资源浪费得让人心疼。
后来Java为了解决这个问题,又搞了一个非阻塞IO(NIO:Non-Blocking IO,有人也叫做New IO), 改变了一下思路:通过多路复用的方式让一个线程去处理多个Socket。

这样一来,只需要使用少量的线程就可以搞定多个socket了,线程只需要通过Selector去查一下它所管理的socket集合,哪个Socket的数据准备好了,就去处理哪个Socket,一点儿都不浪费。
这样一来,只需要使用少量的线程就可以搞定多个socket了,线程只需要通过Selector去查一下它所管理的socket集合,哪个Socket的数据准备好了,就去处理哪个Socket,一点儿都不浪费。
Java NIO 由三个核心组件组件:
Buffer
Channel
Selector
缓冲区和通道是NIO中的核心对象,通道Channel是对原IO中流的模拟,所有数据都要通过通道进行传输;Buffer实质上是一个容器对象,发送给通道的所有对象都必须首先放到一个缓冲区中。
Buffer是一个数据对象,它包含要写入或者刚读出的数据。这是NIO与IO的一个重要区别,我们可以把它理解为固定数量的数据的容器,它包含一些要写入或者读出的数据。在面向流的I/O中你将数据直接写入或者将数据直接读到stream中,在Java NIO中,任何时候访问NIO中的数据,都需要通过缓冲区(Buffer)进行操作。读取数据时,直接从缓冲区中读取,写入数据时,写入至缓冲区。缓冲区实质上是一个数组。通常它是一个字节数组,但是也可以使用其他种类的数组。但是一个缓冲区不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。简单的说Buffer是:一块连续的内存块,是NIO数据读或写的中转地。NIO最常用的缓冲区则是ByteBuffer。下图是 Buffer 继承关系图:
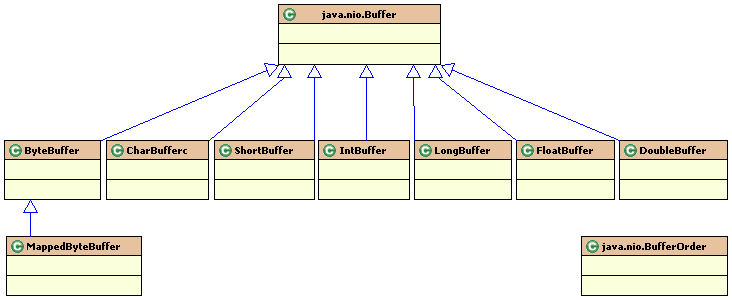
从类图可以看出NIO为所有的原始数据类型都实现了Buffer缓存的支持。并且看JDK_API可以得知除了ByteBuffer中的方法有所不同之外,其它类中的方法基本相同。
Channel 是一个对象,可以通过它读取和写入数据。拿 NIO 与原来的 I/O 做个比较,通道就像是流。正如前面提到的,所有数据都通过 Buffer 对象来处理。你永远不会将字节直接写入通道中,相反,你是将数据写入包含一个或者多个字节的缓冲区。同样,你不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。简单的说Channel是:数据的源头或者数据的目的地,用于向buffer提供数据或者读取buffer数据,并且对I/O提供异步支持。
下图是 Channel 的类图

Channel 为最顶层接口,所有子 Channel 都实现了该接口,它主要用于 I/O 操作的连接。定义如下:
public interface Channel extends Closeable {
/**
* 判断此通道是否处于打开状态。
*/
public boolean isOpen();
/**
*关闭此通道。
*/
public void close() throws IOException;
} 最为重要的Channel实现类为:
FileChannel:一个用来写、读、映射和操作文件的通道
DatagramChannel:能通过UDP读写网络中的数据
SocketChannel: 能通过TCP读写网络中的数据
ServerSocketChannel:可以监听新进来的 TCP 连接,像 Web 服务器那样。对每一个新进来的连接都会创建一个SocketChannel
使用以下三个方法可以得到一个FileChannel的实例
FileInputStream.getChannel()
FileOutputStream.getChannel()
RandomAccessFile.getChannel()上面提到Channel是数据的源头或者数据的目的地,用于向bufer提供数据或者从buffer读取数据。那么在实现了该接口的子类中应该有相应的read和write方法。
在FileChannel中有以下方法可以使用:
/**
* 读取一串数据到缓冲区
*/
public long read(ByteBuffer[] dsts)
/**
* 将缓冲区中指定位置的一串数据写入到通道
*/
public long write(ByteBuffer[] srcs)多路复用器 Selector,它是 Java NIO 编程的基础,它提供了选择已经就绪的任务的能力。从底层来看,Selector 提供了询问通道是否已经准备好执行每个 I/O 操作的能力。简单来讲,Selector 会不断地轮询注册在其上的 Channel,如果某个 Channel 上面发生了读或者写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来,然后通过 SelectionKey 可以获取就绪 Channel 的集合,进行后续的 I/O 操作。
Selector 就是你注册对各种 I/O 事件的地方,而且当那些事件发生时,就是这个对象告诉你所发生的事件。Selector 允许一个线程处理多个 Channel ,也就是说只要一个线程复杂 Selector 的轮询,就可以处理成千上万个 Channel ,相比于多线程来处理势必会减少线程的上下文切换问题。
/**
* 第一步:创建一个Selector
*/
Selector selector = Selector.open();
/**
* 第二步:打开一个远程连接
*/
InetSocketAddress socketAddress =
new InetSocketAddress("www.baidu.com", 80);
SocketChannel sc = SocketChannel.open(socketAddress);
sc.configureBlocking(false);
/**
* 第三步:选择键,注册
*/
SelectionKey key = sc.register(selector, SelectionKey.OP_CONNECT);
/**
* 注册时第一个参数总是当前的这个selector。
* 注册读事件
* 注册写事件
*/
SelectionKey key = sc.register(selector, SelectionKey.OP_READ);
SelectionKey key = sc.register(selector, SelectionKey.OP_WRITE);
/**
* 第四步:内部循环处理
*/
int num = selector.select();
Set selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = (SelectionKey)it.next();
SelectionKey selectionKey = iterator.next();
iterator.remove();
//handleKey(selectionKey);
// ... deal with I/O event ...
}首先,我们调用 Selector 的 select() 方法。这个方法会阻塞,直到至少有一个已注册的事件发生。当一个或者更多的事件发生时, select() 方法将返回所发生的事件的数量。该方法必须首先执行。
接下来,我们调用 Selector 的 selectedKeys() 方法,它返回发生了事件的 SelectionKey 对象的一个集合。SelectionKey中共定义了四种事件,OP_ACCEPT(socket accept)、OP_CONNECT(socket connect)、OP_READ(read)、OP_WRITE(write)。我们通过迭代 SelectionKeys 并依次处理每个 SelectionKey 来处理事件。对于每一个 SelectionKey,您必须确定发生的是什么 I/O 事件,以及这个事件影响哪些 I/O 对象。
在处理 SelectionKey 之后,我们几乎可以返回主循环了。但是我们必须首先将处理过的 SelectionKey 从选定的键集合中删除。如果我们没有删除处理过的键,那么它仍然会在主集合中以一个激活的键出现,这会导致我们尝试再次处理它。我们调用迭代器的 remove() 方法来删除处理过的 SelectionKey。
基于NIO的高并发RPC框架
开发一个具有较好的稳定性和可靠性的 NIO 程序还是挺有难度的。于是 Netty 出现,把我们从水深火热当中解救出来。说说Netty到底是何方神圣, 要解决什么问题吧。回到前言中提到的例子,如果使用Java NIO来自定义一个高性能的RPC框架,调用协议,数据的格式和次序都是自己定义的,现有的HTTP根本玩不转,那使用Netty就是绝佳的选择。
使用Netty的开源框架,可以快速地开发高性能的面向协议的服务器和客户端。 易用、健壮、安全、高效,你可以在Netty上轻松实现各种自定义的协议!其实游戏领域是个更好的例子,长连接,自定义协议,高并发,Netty就是绝配。
因为Netty本身就是一个基于NIO的网络框架, 封装了Java NIO那些复杂的底层细节,给你提供简单好用的抽象概念来编程。
注意几个关键词,首先它是个框架,是个“半成品”,不能开箱即用,你必须得拿过来做点定制,利用它开发出自己的应用程序,然后才能运行(就像使用Spring那样)。一个更加知名的例子就是阿里巴巴的Dubbo了,这个RPC框架的底层用的就是Netty。 另外一个关键词是高性能,如果你的应用根本没有高并发的压力,那就不一定要用Netty了。
参考资料:https://blog.csdn.net/bjweimengshu/article/details/78786315

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)