4.ZooKeeper Leader选举原理也不过如此,看完这篇你不再懵逼了「第五章 ZooKeeper 原理」「架构之路ZooKeeper理论和实战」
相关历史文章(阅读本文前,您可能需要先看下之前的系列????)国内最全的SpringBoot系列之四享元模式:共享女友-第355篇什么是ZooKeeper-第347篇ZooKeeper安装-第348篇ZooKeeper数据结构和实操-第349篇ZooKeeper的watch机制-第350篇ZooKeeper的acl权限控制-第351篇ZooKeeper内存数据和持久化-第352篇ZooKeeper

相关历史文章(阅读本文前,您可能需要先看下之前的系列👇)
ZooKeeper Java客户端的基本使用 - 第356篇
ZooKeeper客户端Curator的进阶使用 - 第359篇
ZooKeeper客户端Curator实现Watch事件监听 - 第361篇
Spring Boot 使用 Curator 操作 ZooKeeper - 第363篇
Spring Boot使用Apache Curator实现服务的注册和发现 - 第364篇
Spring Boot使用Apache Curator实现分布式锁(可重入排它锁) - 第365篇
Spring Boot使用Apache Curator实现leader选举 - 第366篇
Spring Boot使用Apache Curator实现分布式计数器 - 367篇
ZooKeeper Session 基本原理 - 第369篇
ZooKeeper分桶策略实现高性能的会话管理 - 第371篇
ZooKeeper Leader选举原理也不过如此,看完这篇你不再懵逼了 - 第374篇
Zookeeper 集群节点为什么要部署成奇数呢?- 第376篇
分布式一致性算法Paxos,ZooKeeper的ZAB协议 - 第381篇
在前面的小节中,咱们一起学习了ZK的集群架构,在集群中我们介绍了三个角色:Leader、Follower、Observer,其中的Leader是Follower进行选举选举出来的。
ZooKeeper的 leader 选举存在两个阶段:一个是服务器启动时 leader 选举,另一个是运行过程中 leader 服务器宕机。
我们可以简单把 ZooKeeper 理解为分布式家庭的大管家,那么管家团队是如何选出 Leader 的呢?好奇吗,接下来带领大家一探究竟。
一、人类选举的基本原理
讲解 ZooKeeper 选举过程前先来介绍一下人类的选举。
我们每个人或多或少都经历过几次选举,在投票的过程中可能会遇到这样几种情况:
1.1 人类投票的几种情况
1.1 情况1
情况1:自己与几个候选人都比较熟,你会将票投给你认为能力比较强的人;
1.2 情况2
情况2:自己也是候选人,并且与其他几个候选人都不熟,这个时候你肯定想着要去拉票,因为觉得自己才是最厉害的人呀,所有人都应该把票投给我。但是遗憾的是在拉票的过程中,你发现别人比你强,你开始自卑了,最终还是把票投给了自己认为最强的人。
所有人投票完后,统计投票箱中票数最多的候选人,当选领导。
1.2 核心概念
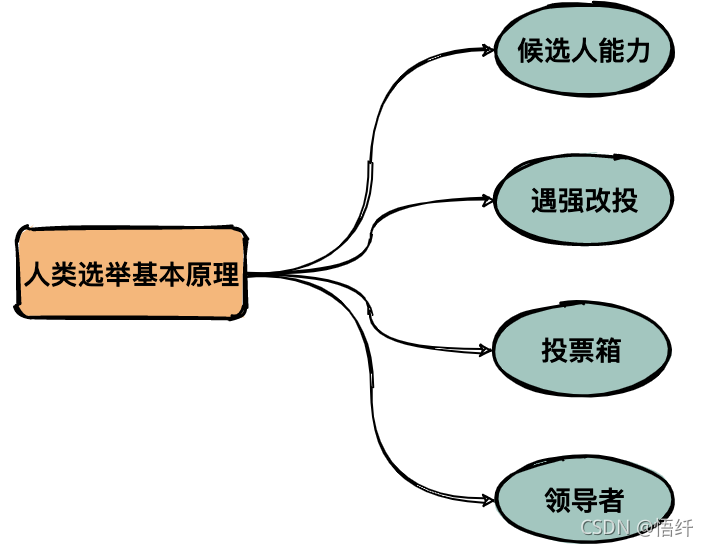
在整个投票过程中我们可以提炼出四个最核心的概念:
(1)候选人能力:投票的基本原则是选最强的人。
(2)遇强改投:如果后面发现更强的人可以改投票。
(3)投票箱:所有人的票都会放在投票箱。
(4)领导者:得票最多的人即为领导者。
二、从人类选举来理解ZooKeeper 选举的基本原理
从人类选举的原理我们来简单推导一下 ZooKeeper 的选举原理。
注意如果 ZooKeeper 是单机部署是不需要选举的,集群模式下才需要选举。
ZooKeeper 的选举原理和人类选举的逻辑类似,套用一下人类选举的四个基本概念详细解释一下ZooKeeper。
2.1 个人能力:数据新:zxid大
如何衡量 ZooKeeper 节点个人能力?答案是靠数据是否够新,如果节点的数据越新就代表这个节点的个人能力越强,是不是感觉很奇怪,就是这么定的!
在 ZooKeeper 中通常是以事务 id(后面简称 zxid)来标识数据的新旧程度(版本),节点最新的 zxid 越大代表这个节点的数据越新,也就代表这个节点能力越强。
zxid 的全称是 ZooKeeper Transaction Id,即 ZooKeeper 事务id。
2.2 遇强改投
在集群选举开始时,节点首先认为自己是最强的(即数据是最新的),然后在选票上写上自己的名字(包括 zxid 和 sid),zxid 是事务 id,sid(server id)唯一标识自己。
紧接着会将选票传递给其他节点,同时自己也会接收其他节点传过来的选票。每个节点接收到选票后会做比较,这个人是不是比我强(zxid比我大),如果比较强,那我就需要改票,明明别人比我强,我也不能厚着脸皮对吧。
2.3 投票箱
与人类选举投票箱稍微有点不一样,ZooKeeper 集群会在每个节点的内存中维护一个投票箱。节点会将自己的选票以及其他节点的选票都放在这个投票箱中。由于选票是互相传阅的,所以最终每个节点投票箱中的选票会是一样的。
2.4 领导者
在投票的过程中会去统计是否有超过一半的选票和自己选择的是同一个节点,即都认为某个节点是最强的。一旦集群中有超过半数的节点都认为某个节点最强,那该节点就是领导者了,投票也宣告结束。
三、ZooKeeper选举原理详细解说
3.1什么场景下需要选举呢?
当 ZooKeeper 集群中的一台服务器出现以下两种情况之一时,需要进入 Leader 选举。
(1)服务器初始化启动。
(2)服务器运行期间 Leader 故障。
3.2 参数和选举状态
在分析选举原理前,先介绍几个重要的参数。
(1)服务器 ID(sid):编号越大在选举算法中权重越大,比如有三台服务器,编号分别是 1,2,3。编号越大在选择算法中的权重越大,比如初始化启动时就是根据服务器 ID 进行比较。
(2)事务 ID(zxid):值越大说明数据越新,权重越大。服务器中存放的数据的事务 ID,值越大说明数据越新,在选举算法中数据越新权重越大。
(3)逻辑时钟(epoch-logicalclock):同一轮投票过程中的逻辑时钟值是相同的,每投完一次值会增加。
选举状态:
(1)LOOKING: 竞选状态;
(2)FOLLOWING: 随从状态,同步 leader 状态,参与投票;
(3)OBSERVING: 观察状态,同步 leader 状态,不参与投票;
(4)LEADING: 领导者状态
3.1启动时期的 Leader 选举
假设一个 ZooKeeper 集群中有 5 台服务器,id 从 1 到 5 编号,并且它们都是最新启动的,没有历史数据。
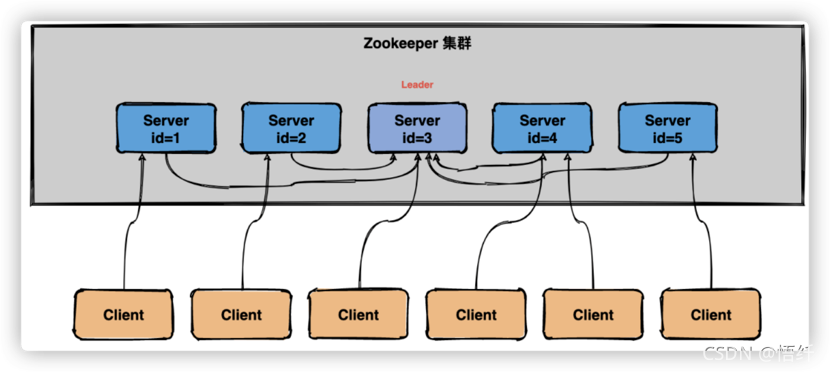
3.1.1 集群刚启动选举过程
假设服务器依次启动,我们来分析一下选举过程:
(1)服务器 1 启动
发起一次选举,服务器 1 投自己一票,此时服务器 1 票数一票,不够半数以上(3 票),选举无法完成。
投票结果:服务器 1 为 1 票。
服务器 1 状态保持为 LOOKING(竞选状态)。
(2)服务器 2 启动
发起一次选举,服务器 1 和 2 分别投自己一票,此时服务器 1 发现服务器 2 的 id 比自己大,更改选票投给服务器 2。
投票结果:服务器 1 为 0 票,服务器 2 为 2 票。
服务器 1,2 状态保持 LOOKING。
(3)服务器 3 启动
发起一次选举,服务器 1、2、3 先投自己一票,然后因为服务器 3 的 id 最大,两者更改选票投给为服务器 3;
投票结果:服务器 1 为 0 票,服务器 2 为 0 票,服务器 3 为 3 票。此时服务器 3 的票数已经超过半数(3 票),服务器 3 当选 Leader。
服务器 1,2 更改状态为 FOLLOWING,服务器 3 更改状态为 LEADING。
(4)服务器4启动
发起一次选举,此时服务器 1,2,3 已经不是 LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器 3 为 3 票,服务器 4 为 1 票。此时服务器 4 服从多数,更改选票信息为服务器 3。
服务器 4 并更改状态为 FOLLOWING。
(5)服务器5启动
与服务器 4 一样投票给 3,此时服务器 3 一共 5 票,服务器 5 为 0 票。
服务器 5 并更改状态为 FOLLOWING。
最终的结果:
服务器3是 Leader,状态为 LEADING;其余服务器是 Follower,状态为 FOLLOWING。
3.1.2运行时期的 Leader 选举
在 ZooKeeper 运行期间 Leader 和 非 Leader 各司其职,当有非 Leader 服务器宕机或加入不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个 ZooKeeper 集群将暂停对外服务,会触发新一轮的选举。
初始状态下服务器 3 当选为 Leader,假设现在服务器 3 故障宕机了,此时每个服务器上 zxid 可能都不一样,server1 为 99,server2 为 102,server4 为 100,server5 为 101。
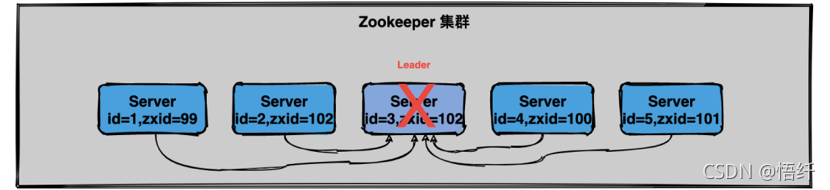
投票的过程和初始化的基本类似,主要为以下几个步骤:
1)状态变更,除 Obsever 状态的其他服务器全部变更为 looking,然后进行 leader 的选举过程
2)每个服务器先投自己一票,然后同步选票
3)每个服务器都会收到各个服务器的投票,如果发现有 txid 比自己大的,会进行改票
4)处理和统计投票,每一轮投票结束后都会统计投票,超过半数即可当选。
5)改变服务器的状态,宣布当选。
直接看图:
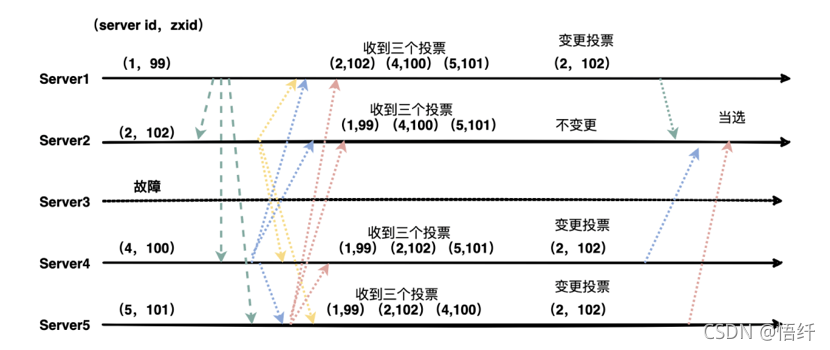
很显然,最后服务器 2 被当选为新的 leader。
四、ZooKeeper选举原理理解2
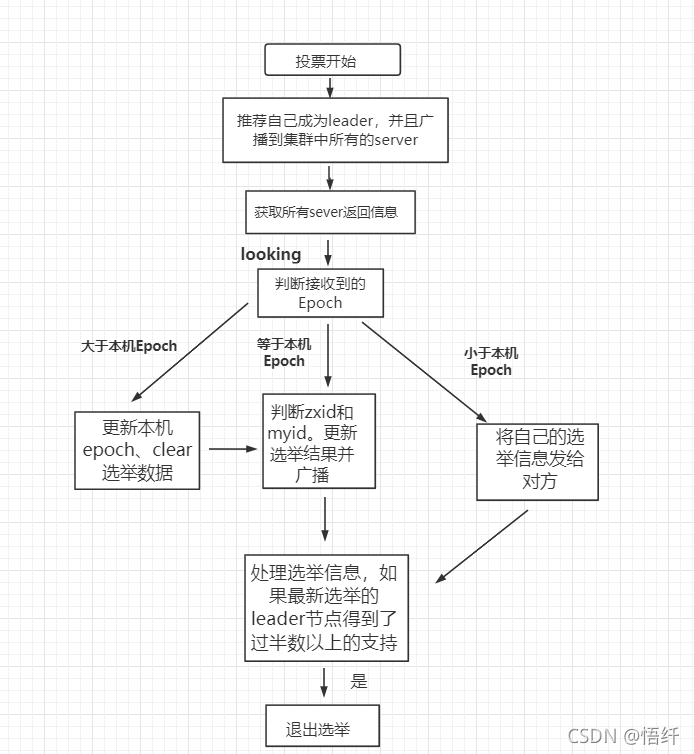
每个节点启动的时候都 LOOKING 观望状态,接下来就开始进行选举主流程。这里选取三台机器组成的集群为例。第一台服务器 server1启动时,无法进行 leader 选举,当第二台服务器 server2 启动时,两台机器可以相互通信,进入 leader 选举过程。
(1)每台 server 发出一个投票,由于是初始情况,server1 和 server2 都将自己作为 leader 服务器进行投票,每次投票包含所推举的服务器sid、zxid、epoch,使用(sid,zxid)表示,此时 server1 投票为(1,0),server2 投票为(2,0),然后将各自投票发送给集群中其他机器。
(2)接收来自各个服务器的投票。集群中的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自 LOOKING 状态的服务器。
(3)分别处理投票。针对每一次投票,服务器都需要将其他服务器的投票和自己的投票进行对比,对比规则如下:
a. 优先比较 epoch
b. 检查 zxid,zxid 比较大的服务器优先作为 leader
c. 如果 zxid 相同,那么就比较 sid,sid 较大的服务器作为 leader 服务器
(4)统计投票。每次投票后,服务器统计投票信息,判断是都有过半机器接收到相同的投票信息。server1、server2 都统计出集群中有两台机器接受了(2,0)的投票信息,此时已经选出了 server2 为 leader 节点。
(5)改变服务器状态。一旦确定了 leader,每个服务器响应更新自己的状态,如果是 follower,那么就变更为 FOLLOWING,如果是 Leader,变更为 LEADING。此时 server3继续启动,直接加入变更自己为 FOLLOWING。
五、总结
(1)ZooKeeper 选举会发生在服务器初始状态和运行状态(Leader宕机)下。
(2)初始状态下会根据服务器 sid 的编号对比,编号越大权值越大,投票过半数即可选出 Leader。
(3)Leader 故障会触发新一轮选举,zxid 代表数据越新,权值也就越大。
(4)在运行期选举还可能会遇到脑裂的情况(后文展开说明)。
我就是我,是颜色不一样的烟火。
我就是我,是与众不同的小苹果。à悟空学院:悟空学院
学院中有Spring Boot相关的课程!!
SpringBoot视频:从零开始学Spring Boot Plus - 网易云课堂
SpringBoot交流平台:https://t.cn/R3QDhU0
SpringSecurity5.0视频:权限管理spring security - 网易云课堂
ShardingJDBC分库分表:分库分表Sharding-JDBC实战 - 网易云课堂
分布式事务解决方案:分布式事务解决方案「手写代码」 - 网易云课堂
JVM内存模型调优实战:深入理解JVM内存模型/调优实战 - 网易云课堂
Spring入门到精通:Spring零基础从入门到精通 - 网易云课堂
大话设计模式之爱你:大话设计模式之爱你一万年 - 网易云课堂

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)