隔板模式:信号量与线程池
为什么有两种不同的实现方式?
在本文中,我将参考 Spring 和 Resilence4j。
如果您正在阅读本文,您可能已经了解了隔板模式,它打算解决什么问题以及最常见的实现:基于信号量和基于线程池。
至少对我来说,何时使用信号量实现以及何时使用线程池实现并不容易。
我知道信号量是如何工作的,并且我也了解线程池模式,因此一个简短的答案,最明显的可能是:使用线程池来限制异步调用的数量并使用信号量来限制同步调用。
那么为什么是困难的部分呢?原因是这些问题:
-
为什么不将@Async 与基于隔板信号量的实现结合起来呢?
-
两个注解可以一起使用吗?如果是,为什么是 threadPool 实现的原因?
@Async 和 @Bulkhead 组合。
@Bulkhead(name = "Service3", fallbackMethod = "futureFallback")
@Async
public CompletableFuture<String> doSomeWork() {
System.out.println("Excecuting service 3 - " + Thread.currentThread().getName());
Util.mockExternalServiceHttpCall(DELAY);
return CompletableFuture.completedFuture("ok");
}
进入全屏模式 退出全屏模式
完整代码。
是的,您可以同时使用这两个注释。它们允许您根据隔板信号量配置生成有限数量的异步调用。
但是,有一些含义是有用的。
SimpleAsyncTaskExecutor。
当你用@Async注解注解一个方法时,Spring可以使用TaskExecutor接口的不同实现。
默认情况下,框架使用SimpleAsyncTaslExecutor。
每次调用带注释的方法时,此实现都会创建一个新线程;该线程将不会被重用。
这种方法的问题在于,即使信号量计数器为 0(舱壁已满),您也会创建一个新线程
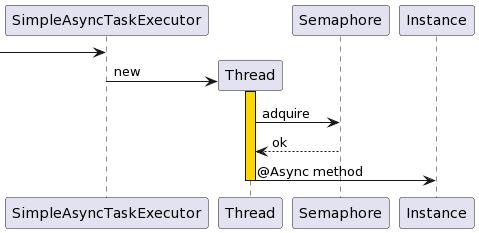
正如您在下面的堆栈跟踪中看到的那样,框架首先创建一个线程,然后调用舱壁模式,以确定是否有可用的权限来继续执行。如果信号量计数器是 cero,则隔板将拒绝方法执行。
Thread [_simpleAsyncTask1] (Suspended (breakpoint at line 18 in Service3))
Service3.doSomeWork() line: 18
Service3$$FastClassBySpringCGLIB$$6085f5a4.invoke(int, Object, Object[]) line: not available
MethodProxy.invoke(Object, Object[]) line: 218
CglibAopProxy$CglibMethodInvocation.invokeJoinpoint() line: 793
CglibAopProxy$CglibMethodInvocation(ReflectiveMethodInvocation).proceed() line: 163
CglibAopProxy$CglibMethodInvocation.proceed() line: 763
MethodInvocationProceedingJoinPoint.proceed() line: 89
BulkheadAspect.lambda$handleJoinPointCompletableFuture$0(ProceedingJoinPoint) line: 225
1457434357.get() line: not available
Bulkhead.lambda$decorateCompletionStage$1(Bulkhead, Supplier) line: 100
1251257755.get() line: not available
SemaphoreBulkhead(Bulkhead).executeCompletionStage(Supplier<CompletionStage<T>>) line: 557
BulkheadAspect.handleJoinPointCompletableFuture(ProceedingJoinPoint, Bulkhead) line: 223
BulkheadAspect.proceed(ProceedingJoinPoint, String, Bulkhead, Class<?>) line: 162
BulkheadAspect.lambda$bulkheadAroundAdvice$5eb13a26$1(ProceedingJoinPoint, String, Bulkhead, Class) line: 129
1746723773.apply() line: not available
1746723773(CheckedFunction0<R>).lambda$andThen$ca02ab3$1(CheckedFunction1) line: 265
1151489454.apply() line: not available
BulkheadAspect.executeFallBack(ProceedingJoinPoint, String, Method, CheckedFunction0<Object>) line: 139
==> here
BulkheadAspect.bulkheadAroundAdvice(ProceedingJoinPoint, Bulkhead) line: 128
NativeMethodAccessorImpl.invoke0(Method, Object, Object[]) line: not available [native method]
NativeMethodAccessorImpl.invoke(Object, Object[]) line: 62
DelegatingMethodAccessorImpl.invoke(Object, Object[]) line: 43
Method.invoke(Object, Object...) line: 566
AspectJAroundAdvice(AbstractAspectJAdvice).invokeAdviceMethodWithGivenArgs(Object[]) line: 634
AspectJAroundAdvice(AbstractAspectJAdvice).invokeAdviceMethod(JoinPoint, JoinPointMatch, Object, Throwable) line: 624
AspectJAroundAdvice.invoke(MethodInvocation) line: 72
CglibAopProxy$CglibMethodInvocation(ReflectiveMethodInvocation).proceed() line: 175
CglibAopProxy$CglibMethodInvocation.proceed() line: 763
ExposeInvocationInterceptor.invoke(MethodInvocation) line: 97
CglibAopProxy$CglibMethodInvocation(ReflectiveMethodInvocation).proceed() line: 186
CglibAopProxy$CglibMethodInvocation.proceed() line: 763
AnnotationAsyncExecutionInterceptor(AsyncExecutionInterceptor).lambda$invoke$0(MethodInvocation, Method) line: 115
1466446116.call() line: not available
AsyncExecutionAspectSupport.lambda$doSubmit$3(Callable) line: 278
409592088.get() line: not available
CompletableFuture$AsyncSupply<T>.run() line: 1700
==> here
SimpleAsyncTaskExecutor$ConcurrencyThrottlingRunnable.run() line: 286
Thread.run() line: 829
进入全屏模式 退出全屏模式
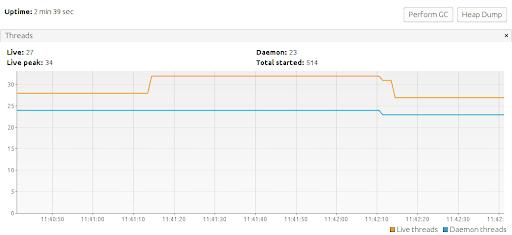
在执行调用@Aync 和@Bulkhead 注释方法60 秒的负载测试后,您可以从分析工具图片中看到,该应用程序仅使用了514 个创建线程中的34 个。这显然是对资源的浪费。
ThreadPoolTaskExecutor
另一种选择可能是使用 TreadPoolTaskExecutor 实现。
在使用此实现执行相同的测试后,创建的线程数减少了很多(41)。
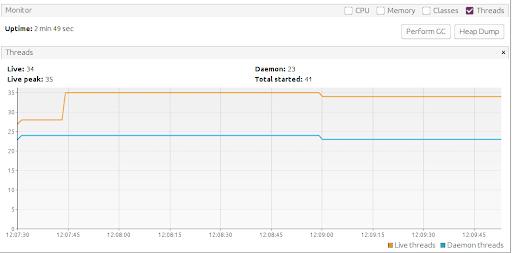
然而,这种方法的问题是我们使用了不必要的冗余。在我看来,一起使用线程池和信号量并没有真正的优势。
结论。
要限制异步调用,请使用 Bulkhead threadPool 实现而不是 @Async 和 Bulkhead 信号量的组合。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35526条内容
已为社区贡献35526条内容

所有评论(0)