使用 AWS Amplify 和 AppSync 批处理请求
我们经常听到构建 CRUD 应用程序的故事。虽然这很好,但现实情况是,许多用例需要超越创建、读取、更新和删除单个项目的能力。
以店面为例:店主可能需要一次上传多个产品的能力。要求他们一一输入 100 种产品会造成糟糕的客户体验。
这篇文章将展示如何扩展我们使用 Amplify 创建的 GraphQL 模式,以创建一个自定义解析器,该解析器接受一组项目,而不是一个。
在此过程中,我们将讨论 AWS AppSync 如何利用 VTL 生成我们的请求和响应解析器,以及 Amplify 如何与 CDK 集成以将所有内容联系在一起!
必备知识
此项目假定您具备 AppSync、Amplify 和 VTL 的一些知识。如果您想快速了解 AWS AppSync 的全部内容,不用担心!我专门为您制作了一个入门视频:
https://www.youtube.com/watch?vu003dOK2B8cp1EyE&tu003d1771s
此外,如果您熟悉 AppSync 如何与 Amplify 一起工作,但想快速了解 VTL 是什么,请查看我的上一篇文章,其中我发现了这一点:
https://blog.focusotter.com/the-frontend-engineers-guide-to-vtl
项目初始化
我们用作启动文件的项目基于上一篇文章。它没有什么特别之处,但我们肯定会为其添加一些功能,以使其更加突出。
从下面的链接克隆启动项目——确保你在amplify-batch-upload-starter分支上
https://github.com/Focus-Otter/batch-upload/tree/amplify-batch-upload-starter
克隆项目后,通过在终端中运行以下命令来安装包文件
npm install
安装我们的软件包后,通过运行以下命令启动 repo
npm start
在浏览器中查看应用程序时,确保可以看到主页和管理页面

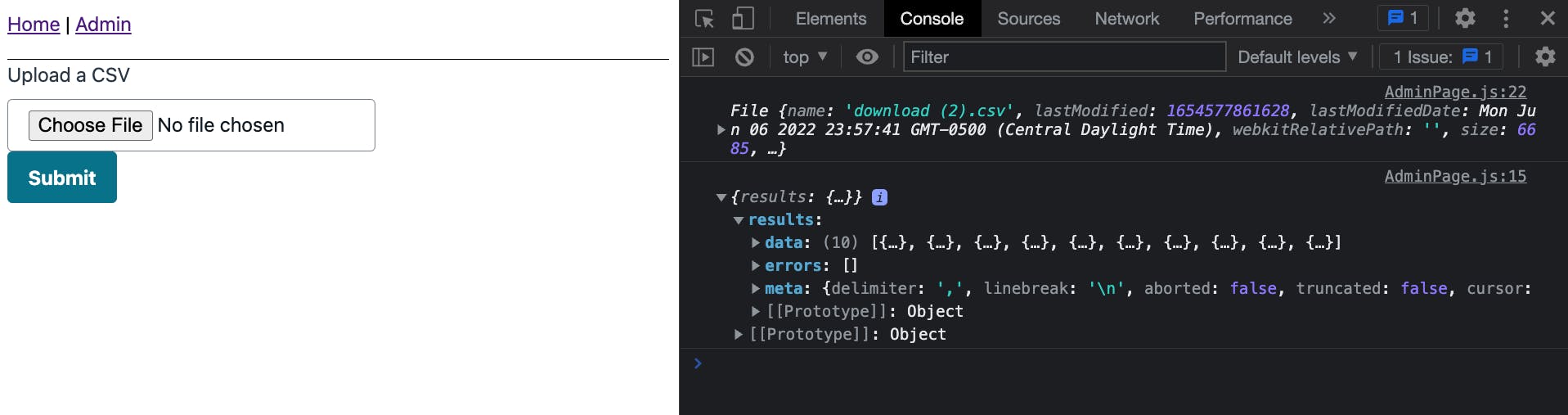
🗒️ 管理页面展示了一个已上传的 CSV,并将其内容发送到 devTools 控制台。
项目概况
在这个应用程序中,我们将模拟上传一个完整的配置文件数据的 CSV。 CSV 将从randomUserAPI 生成。您可以通过单击以下链接生成自己的 CSV:
randomuser.me/api/?formatu003dcsv&resultsu003d10
为了使项目更加真实,我们将添加以下功能/约束:
-
任何访问我们应用程序的人都可以读取个人资料数据
-
只有
admin组内的用户才能创建、更新、删除和批量上传个人资料数据
这意味着我们至少需要该项目的身份验证和 API。
项目设置
我们将利用 Amplify CLI 搭建后端服务,并利用 Amplify 库将前端绑定到后端。
要开始使用,请确保您安装了最新版本的 Amplify CLI(当前为8.4.0:
npm i -g @aws-amplify/cli && npm i aws-amplify
接下来,通过运行以下命令来初始化我们的项目:
amplify init -y
🗒️ 随意离开
-y标志。将它放在那里只是告诉 Amplify 接受所有默认值。
完成后,我们现在就可以使用 CLI 创建服务了!
添加认证
设置身份验证是在 Amplify 中添加的最简单的服务之一。 Amplify 支持询问一些提示并接受合理默认值的“基本流程”,或允许我们浏览大量配置选项的“手动流程”。
在我们的用例中,我们希望未经身份验证的用户读取Profile数据。我们可以使用 API 密钥,相反,我们将使用 IAM 权限,这样我们就不必担心轮换密钥。
运行以下命令:
amplify add auth
迅速的
回复
笔记
使用默认的身份验证和安全配置?
手动配置
这有很多步骤,但提供了最大的灵活性
选择您要使用的 authN/authZ 服务:
注册/登录,与 AWS IAM 连接
在几乎所有应用程序中,这将是您的默认设置
提供一个友好的名称
[进入]
这是将显示在我们的代码编辑器中的名称
输入身份池的名称
[进入]
Amazon Cognito 有 2 个部分:用户池(用户)和身份池(权限)。
🚨允许未经身份验证的登录?🚨
是的
选择“是”意味着根本不登录的用户将拥有一定级别的访问权限。
启用第 3 方身份验证提供程序
不
用于允许 Facebook 和 Google 等社交注册
输入用户池名称
[进入]
注册我们的应用程序的用户将在此处分组
您希望用户如何登录?
用户名
添加用户池组?
是的
以后,我们可能希望客户也登录。所以我们将创建一个admin组来区分这两者
为您的组提供一个名称
行政
添加另一个组?
ñ
按[enter]后,再按一次为sort选项
添加管理员查询 API
ñ
选择 [yes] 将允许我们拥有一个可以控制其他用户访问的登录用户
启用多因素身份验证 (MFA)
离开
首次登录需要输入代码,但之后,他们的用户名和密码就可以了。
基于电子邮件的注册
启用
此处的选项是将访问代码发送到用户的电子邮件或电话
🚨 对于其余选项:
如果y/n选择n否则按enter
简而言之,用户将使用用户名注册/登录,未注册的用户可以使用我们的 API(只要我们设置 API 这样做),我们创建了一个admin组。
这样,我们的身份验证类别就完成了。在推送到 AWS 之前,让我们添加我们的 API。
添加API
如前所述,我们将使用 AppSync 作为我们的 GraphQL API。当与 Amplify 结合使用时,我们可以利用 Amplify 的指令为我们的Profile数据模型创建 CRUD 操作。
要开始,请在终端中运行以下命令:
amplify add api
迅速的
回复
笔记
从其中一项服务中选择
GraphQL
选择要编辑的设置:
授权方式
我们将允许登录用户和来宾用户进行不同的访问
选择默认的身份验证类型
亚马逊认知
这将适用于admin用户。
配置其他身份验证类型
是的
选择其他身份验证类型
我是
回想一下,对于 Cognito,我们允许“未经身份验证的访问”。这就是我们允许使用 Cognito 对我们的 API 进行 public 访问的方式
这是我们将创建的 GraphQL API
继续
选择架构模板
空白时间表
实际上,我们选择什么并不重要,因为我们将提供自己的模式
立即编辑架构
是的
最后选择“是”,我们的模式应该已经在我们的编辑器中打开了。此外,通过设置 Cognito 和 IAM 身份验证,我们现在已经使用了我们之前定义的身份验证类别。
让我们定义我们的 API 并告诉 Amplify 我们的Profile模型的哪些部分是公开的,哪些是私有的。
在现在生成的schema.graphql文件中,粘贴以下内容:
type Profile
@model
@auth(
rules: [
{ allow: public, provider: iam, operations: [read] }
{ allow: groups, groups: ["admin"] }
]
) {
id: ID!
firstName: String!
lastName: String!
email: AWSEmail!
images: Images
}
type Images {
thumbnail: AWSURL
medium: AWSURL
large: AWSURL
}
type Mutation {
batchCreateProfile(profiles: [BatchCreateProfile]): [Profile]
}
input BatchCreateProfile {
id: ID
firstName: String!
lastName: String!
email: AWSEmail!
images: ImagesInput
}
input ImagesInput {
thumbnail: AWSURL
medium: AWSURL
large: AWSURL
}
由于@modelgraphql 指令,我们的 Profile 模型将有一个与之关联的数据库,并且 CRUD 操作应用了 auth 规则,这样 unauth 用户(“public”)可以读取,admin用户可以执行所有操作。
但是,作为一个固执己见的框架,Amplify 不支持将批处理操作作为其代码生成的一部分。好消息是,Amplify 将让我们回退到使用普通 AppSync,这就是为什么还有一个名为batchCreateProfile的额外Mutation。
对于输入,它将接收与BatchCreateProfile输入类型匹配的profiles数组,并返回Profile数据数组。
如果我们现在将 Amplify 应用程序推送到 AWS,Amplify 会看到新的 Mutation,但不知道如何将任何解析器附加到它。
🗒️ 通过不将解析器附加到模型,Amplify 将为
batchCreateProfile字段创建一个NONE数据源。这有一些优势,我们将在后面的文章中探讨。
我们将使用 CDK 自己创建解析器,而不是推送到 AWS!
使用 AWS CDK 扩展我们的 Amplify 项目
我们将利用 Amplify 的可扩展性功能将自定义资源添加到我们的项目中。在这种情况下,资源将是我们的两个解析器:一个 request 映射解析器和另一个 response 映射解析器。
🗒️ 要了解有关 Amplify 中可扩展性的更多信息,请查看以下资源:
https://blog.focusotter.com/the-complete-guide-to-adding-aws-resources-to-your-amplify-project
要开始,请运行以下命令:
amplify add custom
按照提示添加名为MyCustomResolvers的 CDK 资源。
完成后,这将创建一个cdk-stack.ts文件。请注意,这个文件是我们可以开发的,当我们推送我们的应用程序时,它将被注入到同级的build目录中。
设置的最后一件事是添加 appSync 节点模块包:
cd ./amplify/backend/custom/MyCustomResolvers
npm i @aws-cdk/aws-appsync@~1.124.0
完成后,请务必导航回根目录:
cd ../../../..
使用 AWS CDK 附加 AppSync 解析程序
在cdk-stack.ts文件中,我将提供代码片段。我也留下了评论,以便我们讨论相关部分。
粘贴以下代码:
import * as cdk from '@aws-cdk/core'
import * as AmplifyHelpers from '@aws-amplify/cli-extensibility-helper'
import * as appsync from '@aws-cdk/aws-appsync'
import { AmplifyDependentResourcesAttributes } from '../../types/amplify-dependent-resources-ref'
const fs = require('fs')
export class cdkStack extends cdk.Stack {
constructor(
scope: cdk.Construct,
id: string,
props?: cdk.StackProps,
amplifyResourceProps?: AmplifyHelpers.AmplifyResourceProps
) {
super(scope, id, props)
/* Do not remove - Amplify CLI automatically injects the current deployment environment in this input parameter */
new cdk.CfnParameter(this, 'env', {
type: 'String',
description: 'Current Amplify CLI env name',
})
// 1. Access other Amplify Resources
const retVal: AmplifyDependentResourcesAttributes =
AmplifyHelpers.addResourceDependency(
this,
amplifyResourceProps.category,
amplifyResourceProps.resourceName,
[
{
category: 'api',
resourceName: 'batchupload',
},
]
)
// 2. Access variables from our API when the application synths
const apiIdRef = cdk.Fn.ref(retVal.api.batchupload.GraphQLAPIIdOutput)
const envRef = cdk.Fn.ref('env')
// 3. Create a function that will replace strings in a given string
function injectVariables(
replacements: { [s: string]: string },
template: string
) {
const injectedTemplate = Object.entries(replacements).reduce(
(prev, _, i, arr) => prev.replace(arr[i][0], arr[i][1]),
template
)
return injectedTemplate
}
// 4. Create a config that contains all of the values that need to be injected
const config = {
INSERT_GROUP_NAME: 'admin',
INSERT_APIID: apiIdRef,
INSERT_PROJECT_ENV: envRef,
}
// 5. Grab the request template, relative to the build directory
const requestTemplate = fs.readFileSync(
`${__dirname}/../Mutation.createBatchProfile.req.vtl`,
{
encoding: 'utf-8',
}
)
// 6. Grab the request template, relative to the build directory
const responseTemplate = fs.readFileSync(
`${__dirname}/../Mutation.createBatchProfile.res.vtl`,
{
encoding: 'utf-8',
}
)
// 7. Call the function to inject the variables
const injectedRequestTemplate = injectVariables(config, requestTemplate)
const injectedResponseTemplate = injectVariables(config, responseTemplate)
// 8. Attach the resolvers to our AppSync API
new appsync.CfnResolver(this, 'custom-resolver', {
apiId: cdk.Fn.ref(retVal.api.batchupload.GraphQLAPIIdOutput),
fieldName: 'batchCreateProfile',
typeName: 'Mutation', // Query | Mutation | Subscription
requestMappingTemplate: injectedRequestTemplate,
responseMappingTemplate: injectedResponseTemplate,
dataSourceName: 'ProfileTable', // DataSource name
})
}
}
- 运行
amplify add custom命令创建一个支持 Amplify 的 CDK 后端。因此,使用这种格式,我们可以访问我们现有的 Amplify 生成的资源。随意检查AmplifyDependentResourcesAttributes值以查看您可以使用哪些选项。
2.返回值(retVal)只包含string、number等占位符值。为了获取实际值,我们使用cdk.Fn.ref函数说,“当应用程序构建时,获取实际值并在这里注入”。
3-7。我们的模式定义了我们的数据,但由我们来告诉 AppSync 如何获取它。这些步骤就是这样做的。injectVariables函数接受一个值对象 (4) 和一个字符串。该字符串来自我们的 VTL 模板(5 和 6)。使用这种方法,我们可以在编辑器中利用智能感知并创建通用的可重用模板。
1.模板有占位符值,所以我们调用injectVariables函数来获取相应的请求和响应模板。
- 我们使用之前导入的
appsync模块将它们放在一起,以创建一个附加到我们的 graphql API 的新解析器。
🗒️ 请注意,VTL 模板 (
Mutation.createBatchProfile.req.vtl) 的命名只是一种约定,但您会看到一个常见的约定。
下一步是实际创建我们的 VTL 模板。
创建请求模板
在我们刚刚处理的cdk-stack.ts文件旁边,创建一个新文件:Mutation.createBatchProfile.req.vtl。
在该文件中,粘贴以下内容:
$util.log.info($util.toJson($context))
#set($isAuthorized = false)
#set( $createdAt = $util.time.nowISO8601() )
#set($profilesArray = [])
#foreach($group in $ctx.identity.claims.get("cognito:groups"))
$util.log.info($group)
#if($group == "INSERT_GROUP_NAME")
#set($isAuthorized = true)
#end
#end
#if(!$isAuthorized)
$util.unauthorized()
#end
#foreach($item in \${ctx.args.profiles})
$util.qr($item.put("id", $util.defaultIfNullOrBlank($item.id, $util.autoId())))
$util.qr($item.put("createdAt", $util.defaultIfNull($item.createdAt, $createdAt)))
$util.qr($item.put("updatedAt", $util.defaultIfNull($item.updatedAt, $createdAt)))
$util.qr($item.put("__typename", "Profile"))
$util.qr($profilesArray.add($util.dynamodb.toMapValues($item)))
#end
## [End] Initialization default values. **
$util.toJson( {
"version": "2018-05-29",
"operation": "BatchPutItem",
"tables": {
"Profile-INSERT_APIID-INSERT_PROJECT_ENV": $profilesArray
}
} )
源于我上一篇关于 VTL的介绍文章,这是学习一些额外 VTL 指令的好地方!
让我们从模板的作用开始:
👨🏽u200d🏫 当用户调用
createBatchProfile突变时,我们会检查他们是否是管理员。如果是,我们获取参数,添加一些额外的值,然后将它们插入到相关的 DynamoDB 表中。
随着高级概述的结束,让我们谈谈我们是如何做到这一点的。
首先,我们使用新发布的$util.log.info指令将$context对象注销到 CloudWatch。这是一个很好的补充,因为它现在可以更轻松地查看我们的 VTL 中正在发生的事情。
请注意,最好将$context对象视为类似于传递给 Lambda 函数的event对象。
从那里,我们只需使用更多指令!
-
$isAuthorized是我们创建的用于跟踪 authState 的变量, -
我们使用
$util.time.nowISO8601()助手创建时间戳并将值传递给$createdAt变量 -
我们还创建了一个名为
profilesArray的数组
接下来,我们将使用#foreach指令来遍历认知组数组。为此,$ctx.identity.claims.get("cognito:groups")完成了所有繁重的工作。值得注意的是$context和$ctx是同一个东西。一种只是简写。
#if指令检查它是否是正确的组(请记住,我们的配置将插入admin代替INSERT_GROUP_NAME。
很酷的是$util助手甚至带有错误处理功能。例如,如果用户不是管理员,那么我们会使用$util.unauthorized引发未经授权的错误。
现在,假设用户是管理员,我们遍历他们传入的参数,并添加一些额外的字段,如id和createdAt,然后使用dynamodb.toMapValues帮助程序将数据从 JSON 转换为 DynamoDB JSON。
$util.qr是一个很好的助手,它说:“如果你运行一个返回值的函数,请使用我不必创建该值而只需运行该函数”

$util.defaultIfNullOrBlank说得很好,“如果有就用这个值,否则就用这个。”。这与生成随机字符串`的$util.autoId帮助器配合得很好。
最后$util.toJson照它说的做,但重要的是这个对象被称为 AppSyncdocument。
特别是,这将调用BatchPutItem文档进而调用BatchWriteItemDynamoDB 表达式。
创建响应模板
请求模板通常较长,因为它必须转换数据,而响应模板只需返回它。
创建一个名为Mutation.createBatchProfile.res.vtl的文件。
当我们的请求模板完成将数据放入 DynamoDB 时,它会向客户端发出响应。这就是我们格式化该响应的方式。
添加以下内容:
## [Start] ResponseTemplate. **
$util.log.info($util.toJson($context))
#if( $ctx.error )
$util.error($ctx.error.message, $ctx.error.type)
#else
$util.toJson($ctx.result.data.Profile-INSERT_APIID-INSERT_PROJECT_ENV)
#end
## [End] ResponseTemplate. **
🗒️ 回想一下 VTL 中的
##是您指定注释的方式。
像以前一样记录上下文后,我们检查是否存在由于尝试将数据添加到数据库而导致的任何错误。如果有,我们使用$util.error($ctx.error.message, $ctx.error.type)助手来抛出它。
从那里,我们简单地返回数据——仍然使用我们的配置来注入我们的值,而不是占位符INSERT_APIID和INSERT_PROJECT_ENV。
测试我们的解析器
使用我们的自定义解析器,让我们将资源推送到 AWS。
确保您位于项目的根目录并运行以下命令:
amplify push -y
这将推送我们的 Auth 和 API 资源,并在为我们自动生成 graphql 文件时接受任何提示。
在我们的index.js文件中,让我们通过配置 Amplify 将前端绑定到后端。在页面顶部添加以下代码段:
import {Amplify} from 'aws-amplify'
import config from './aws-exports'
Amplify.configure(config)
接下来,我们将使用withAuthenticator()模块向我们的AdminPage添加身份验证。在AdminPage.js文件中,添加以下导入:
import {withAuthenticator} from '@aws-amplify/ui-react'
此外,使用以下导出包装我们的 AdminPage:
export default withAuthenticator(AdminPage)
现在我们的身份验证已经到位,添加以下导入以添加到我们的 API 中:
import {API} from 'aws-amplify'
import {batchCreateProfile} from '../graphql/mutations'
最后,在handleCSVSubmit函数中,将Papa.parse函数替换为以下内容:
Papa.parse(uploadedCSV, {
header: true,
complete: async (results) => {
const data = results.data.map((item) => ({
firstName: item['name.first'],
lastName: item['name.first'],
email: item.email,
images: {
thumbnail: item['picture.thumbnail'],
medium: item['picture.medium'],
large: item['picture.large'],
},
}))
console.log(data)
await API.graphql({
query: batchCreateProfile,
variables: { profiles: data },
}).catch((e) => console.log(e))
},
})
🗒️ 这是遵循我们在项目开始时从 randomUser API 导入的 CSV 文件的格式。
保存应用程序,然后运行项目:
npm start
在管理页面上,创建一个用户——记住这个用户必须是管理员。
创建用户后——为简洁起见,进入 Cognito 控制台并将用户移动到管理员组。
进入组后,通过向我们的 AdminPage 添加一个signOut属性(在使用AmplifyProvider和withAuthenticator时提供)以及一个注销按钮来注销应用程序
<Button onClick={signOut}>Signout</Button>
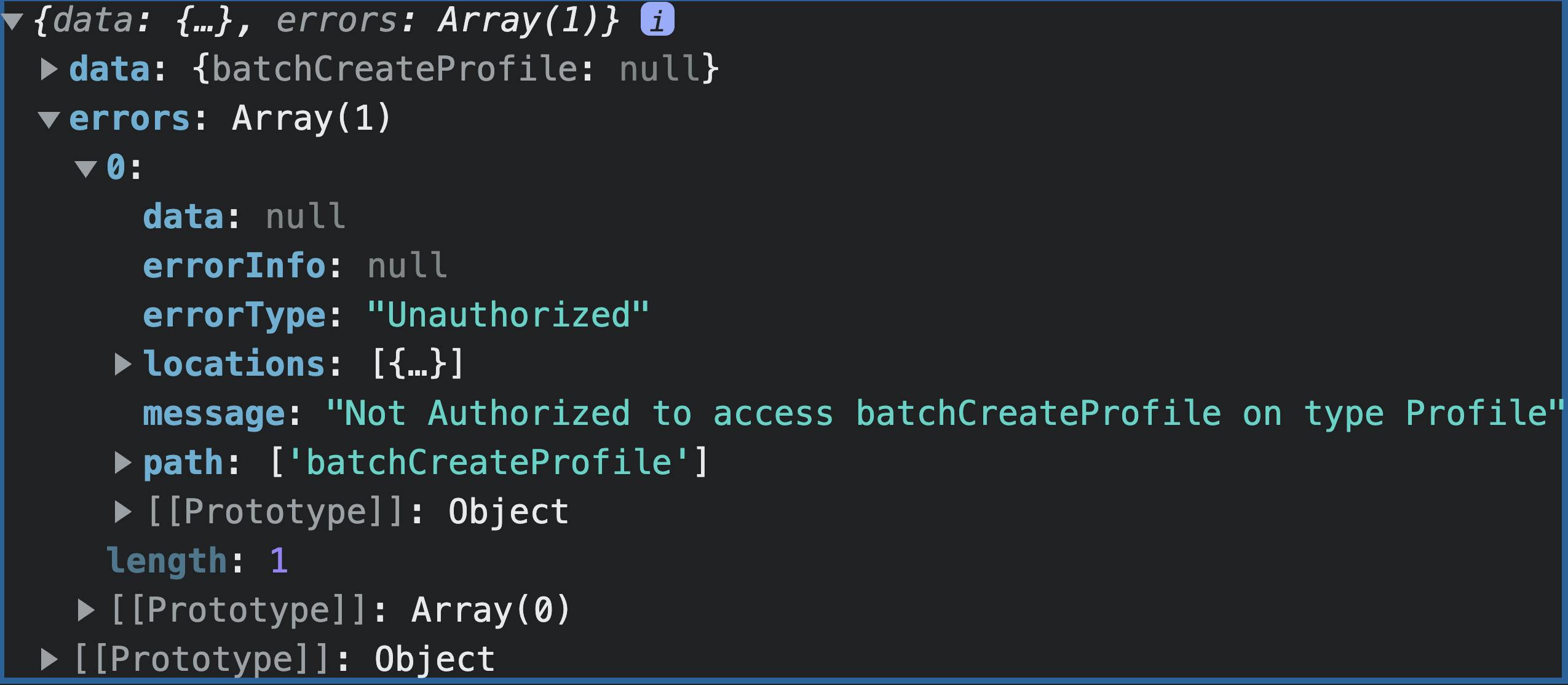
注销后,上传 CSV 并在网络选项卡中查看输出。
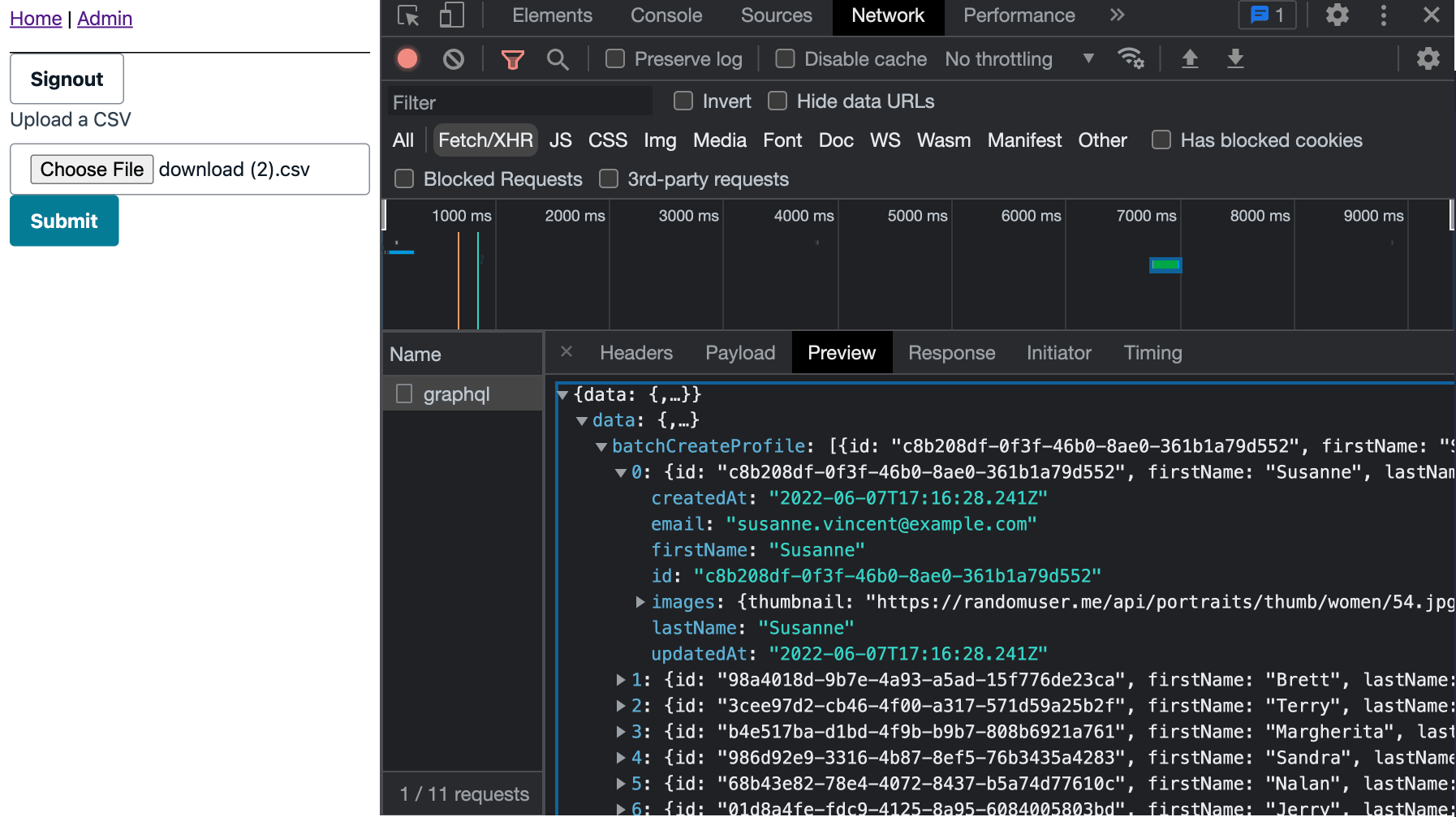
可选:在 DynamoDB 中查看结果!
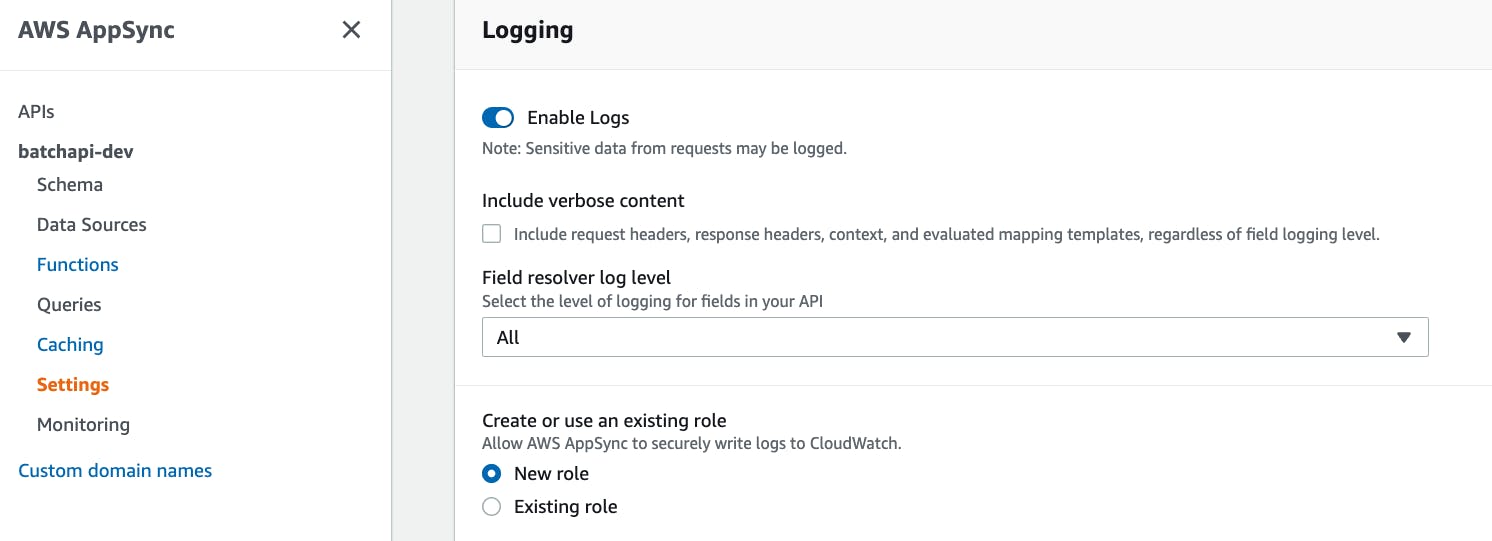
要在 CloudWatch 中查看日志,请确保您的 API 在其设置中启用了日志记录:
结论
这个项目很有趣,因为它让我们更深入地了解 VTL 及其所扮演的角色。一个经常被谈论的对 Amplify 的批评是它把用户锁在里面或者它是一个黑匣子。然而,通过这样的项目表明情况并非如此🙂
通过使用可扩展性并了解一点 VTL,构建适合您用例的各种应用程序变得很容易!
一如既往,感谢焦点水獭查看帖子,下次我会赶上你们的✌️

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35528条内容
已为社区贡献35528条内容

所有评论(0)