Apache Spark 和 Docker
伦敦制造me
返回索引
我第一次发表这里
§1 Apache Spark 和 Docker
Apache Spark 最近新增的主要功能之一是对 Kubernetes 的完整支持。当 Kubernetes 被选为集群管理器时,用户必须提交容器化的应用程序。 Kubernetes 支持多种容器格式,但 Docker 是最受欢迎的选项。本文介绍了如何将包含 Python 和 Scala 源以及混合第三方依赖项的双语代码库容器化并作为 Docker 应用程序运行:首先,程序在单个 Docker 容器中以本地模式执行。第二部分展示了如何在多容器 Docker 应用程序中使用 Spark 的集群模式启动小型集群,下面贴上一个偷偷摸摸的高峰:
本文的实际部分使用来自 bdrecipes 项目的代码,序言描述了如何轻松地在本地设置此代码库。或者,可以在此处获取包含所有应用程序代码和工件的完整 Docker 映像。
父 Docker 镜像
Docker image 是 Docker 引擎可以用来实例化容器的蓝图。根据官方文档,容器是“您机器上的另一个进程,它已与主机上的所有其他进程隔离开来”。图像定义不必从头开始,但可以导入现有图像并对其进行修改。此处将使用这种定制方法:DataMechanics 最近发布了一组免费的 Docker 镜像。这些图像中的每一个都包含一个 Spark 分发和一些额外的花里胡哨,如 Jupyter 笔记本支持或连接到对象存储(如 S3)的连接器。
数十个 Docker 镜像是可用因此需要确定最适合给定代码库的 docker 化的镜像:bdrecipesPOM 文件指定 Spark 版本 3.1.1、Scala 2.12.10 和 Java 8。可以在python文件夹下找到,我在本地使用 Python 3.8.2。除此之外,我在这里从下载了 Spark 发行版spark-3.1.1-bin-hadoop3.2以供本地使用。这种组合的最佳匹配似乎是带有注释3.1.1-hadoop-3.2.0-java-8-scala-2.12-python-3.8-dm13的 Docker 映像,这是 bdrecipes 的第一个条目Dockerfile(稍后描述)将指定。
派生的 Docker 镜像
下一节将详细介绍从3.1.1-hadoop-3.2.0-java-8-scala-2.12-python-3.8-dm13等父映像派生自定义映像时所涉及的步骤。对于想要跳过必要的 bdrecipes 安装和映像构建过程的不耐烦的读者,可以使用一个快捷方式:完成的自定义映像被推送到 docker存储库并且可以使用docker pull bdrecipes/spark-on-docker获取
$ docker pull bdrecipes/spark-on-docker
Using default tag: latest
latest: Pulling from bdrecipes/spark-on-docker
[...]
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
bdrecipes/spark-on-docker latest e6fcd107d 6 hours ago 2.34GB
如果使用这个预构建的镜像,下面示例中的 docker 命令需要稍作修改:示例将使用bdrecipes/spark-on-docker,而不是参考下一节中手动组装的镜像my-app:dev,例如命令docker run --rm -i -t my-app:dev bash更改为docker run --rm -i -t bdrecipes/spark-on-docker bash。以下部分解释了bdrecipes/spark-on-docker映像在推送到存储库之前是如何组装的:
Dockerfile
代码库 docker 化的第一步是在项目的根目录中创建一个 Dockerfile。这是一个包含指令的简单文本文件,Docker 守护进程运行此文件来组装图像。 bdrecipes 的Dockerfile包含以下条目:
FROM gcr.io/datamechanics/spark:3.1.1-hadoop-3.2.0-java-8-scala-2.12-python-3.8-dm13
COPY tutorials/ tutorials/
COPY resources/ resources/
COPY target/bdrecipes-phil.jar .
COPY scripts/launch_spark_daemon.sh .
COPY requirements.txt .
RUN pip3 install -r requirements.txt
COPY setup.py setup.py
RUN pip3 install -e .
以下段落更详细地解释了此 Dockerfile 中的各个说明。第一行初始化一个新的构建阶段并声明我们的自定义图像派生自的父图像。上一节已经确定最合适的父级是spark:3.1.1-hadoop-3.2.0-java-8-scala-2.12-python-3.8-dm13,这导致以下初始指令:
FROM gcr.io/datamechanics/spark:3.0.2-hadoop-3.2.0-java-8-scala-2.12-python-3.8-dm13
bdrecipes 项目的所有 Spark 程序都放在教程文件夹中,而输入文件位于资源文件夹中。 Dockerfile 中接下来的两个 copy 行使这两个文件夹在容器中可用:
COPY tutorials/ tutorials/
COPY resources/ resources/
通过这些指令,可以在容器文件系统的/opt/spark/work-dir/tutorials/module1/python/query_plans.py下找到像/Users/me/IdeaProjects/bdrecipes/tutorials/module1/python/query_plans.py这样的本地文件。类似地,像/Users/me/IdeaProjects/bdrecipes/resources/warc.sample这样的输入文件参数必须作为/opt/spark/work-dir/resources/warc.sample传递给query_plans.py的 dockerized 运行,如下所示。
在执行 Scala 或 Java 源代码之前,需要通过mvn clean install组装一个 fat JAR。之前的文章解释了如何正确设置 bdrecipes 代码库。 Maven 构建过程完成后,可以在target/bdrecipes-phil.jar找到胖 JAR。使用以下指令将此程序集添加到容器文件系统中:
COPY target/bdrecipes-phil.jar .
创建了一个帮助脚本launch_spark_daemon.sh,这将减少本文后半部分启动 Spark 守护程序时所需的手动工作。下一行添加了这个脚本:
COPY scripts/launch_spark_daemon.sh .
Pyspark 和 pythonic 项目依赖项由以下两条指令处理:
COPY requirements.txt .
RUN pip3 install -r requirements.txt
Docker 映像的最后一层安装了 bdrecipes Python 包。这将使诸如和之类的 Python 模块中的自定义功能可用于容器化 PySpark 程序:
COPY setup.py setup.py
RUN pip3 install -e .
容器创建
以下部分的实际部分依赖于 Docker 引擎,可以从下载。一旦 Docker 守护进程启动并运行,我们的自定义镜像可以通过导航到 bdrecipes 项目根目录并执行命令docker build -t my-app:dev .来构建
$ cd ~/IdeaProjects/bdrecipes
$ docker build -t my-app:dev .
[+] Building 1.0s (14/14) FINISHED
=> [internal] load build definition from Dockerfile
=> => transferring dockerfile: 37B
=> [internal] load .dockerignore
=> => transferring context: 2B
=> [internal] load metadata for gcr.io/datamechanics/spark:3.1.1-hadoop-3.2.0-java-8-scala-2.12-python-3.8-dm13
=> [1/9] FROM gcr.io/datamechanics/spark:3.1.1-hadoop-3.2.0-java-8-scala-2.12-python-3.8-dm13@sha256:4ec1977ea8...
=> [internal] load build context
=> => transferring context: 5.63kB
=> CACHED [2/9] COPY tutorials/ tutorials/
=> CACHED [3/9] COPY resources/ resources/
=> CACHED [4/9] COPY target/bdrecipes-phil.jar .
=> CACHED [5/9] COPY scripts/launch_spark_daemon.sh .
=> CACHED [6/9] COPY requirements.txt .
=> CACHED [7/9] RUN pip3 install -r requirements.txt
=> CACHED [8/9] COPY setup.py setup.py
=> CACHED [9/9] RUN pip3 install -e .
=> exporting to image
=> => exporting layers
=> => writing image sha256:6a...
=> => naming to docker.io/library/my-app:dev
这个终端输出看起来很有希望,创建了九层,对应于Dockerfile中的九条指令。我们的新自定义镜像my-app:dev可以通过执行 dockerized 版本的强制性 HelloWorld 示例来测试: 两个源文件是HelloWorld.scala和helloworld.py,这个 HelloWorld 的相关目录和文件的本地布局例子是
bdrecipes/
target/
bdrecipes-phil.jar
tutorials/
module1/
scala/
HelloWorld.scala
python/
helloworld.py
让我们通过在终端窗口中输入命令docker run --rm -i -t my-app:dev bash来研究正在运行的 Docker 容器中的布局。这将启动一个容器并将其以交互方式(-i标志)附加到本地终端会话(-t标志):
$ docker run --rm -i -t my-app:dev bash
$ pwd
/opt/spark/work-dir
$ ls -l
-rw-r--r-- 1 root root 113942259 Jun 19 09:53 bdrecipes-phil.jar
drwxr-xr-x 2 185 root 4096 Jun 19 10:00 bdrecipes.egg-info
-rwxr-xr-x 1 root root 149 Jun 13 20:49 launch_master.sh
-rwxr-xr-x 1 root root 151 Jun 13 14:29 launch_worker.sh
-rw-r--r-- 1 root root 19 Jun 19 10:00 requirements.txt
drwxr-xr-x 2 root root 4096 Jun 19 09:54 resources/
-rw-r--r-- 1 root root 78 May 10 10:08 setup.py
drwxr-xr-x 4 root root 4096 Jun 19 09:54 tutorials/
$ exit;
exit
$
使用预建镜像bdrecipes/spark-on-docker时,run 命令变为docker run --rm -i -t bdrecipes/spark-on-docker bash。从上面的终端输出中,我们可以推断出从 Docker 镜像my-app:dev实例化的容器中相关文件的布局如下:
/opt/spark/work-dir/
bdrecipes-phil.jar
tutorials/
module1/
scala/
HelloWorld.scala
python/
helloworld.py
现在我们拥有了将 HelloWorld 程序作为 Docker 应用程序执行所需的所有信息。docker run命令应在本地终端会话中输入以下参数(即,容器的“外部”):
执行HelloWorld.scala(如果需要,将my-app:dev更改为bdrecipes/spark-on-docker):
$ docker run my-app:dev driver --class module1.scala.HelloWorld local:///opt/spark/work-dir/bdrecipes-phil.jar
[...]
+ CMD=("$SPARK_HOME/bin/spark-submit" --conf "spark.driver.bindAddress=$SPARK_DRIVER_BIND_ADDRESS" --deploy-mode client "$@")
+ exec /usr/bin/tini -s -- /opt/spark/bin/spark-submit --conf spark.driver.bindAddress= --deploy-mode client
--class module1.scala.HelloWorld local:///opt/spark/work-dir/bdrecipes-phil.jar
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
@@@ HELLO WORLD @@@
执行helloworld.py(如果需要,将my-app:dev更改为bdrecipes/spark-on-docker):
$ docker run my-app:dev driver local:///opt/spark/work-dir/tutorials/module1/python/helloworld.py
[...]
+ CMD=("$SPARK_HOME/bin/spark-submit" --conf "spark.driver.bindAddress=$SPARK_DRIVER_BIND_ADDRESS" --deploy-mode client "$@")
+ exec /usr/bin/tini -s -- /opt/spark/bin/spark-submit --conf spark.driver.bindAddress= --deploy-mode client
local:///opt/spark/work-dir/tutorials/module1/python/helloworld.py
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
@@@ HELLO WORLD @@@
Spark 应用程序作为 Docker 应用程序
在上一节中,两个 HelloWorld 程序作为 Docker 应用程序成功执行。涉及到相当多的设置工作,所以对于这些琐碎的例子来说,使用 Docker 似乎有点过头了。但是,当QueryPlans.scala/query_plans.pyfrom§10.1之类的不那么琐碎的程序进入图片时,容器化的好处已经变得显而易见。它们是解析输入文件、依赖第三方库并应用打包在同一代码库中的业务逻辑的 Spark 应用程序。直接从以前的成功执行中恢复命令会导致运行时错误:
QueryPlans.scala运行失败(如果需要,将my-app:dev更改为bdrecipes/spark-on-docker):
$ docker run my-app:dev driver --class module1.scala.QueryPlans local:///opt/spark/work-dir/bdrecipes-phil.jar
[...]
org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/Users/me/IdeaProjects/bdrecipes/
resources/warc.sample
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:332)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:274)
query_plans.py运行失败(如果需要,将my-app:dev更改为bdrecipes/spark-on-docker):
$ docker run my-app:dev driver local:///opt/spark/work-dir/tutorials/module1/python/query_plans.py
[...]
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.newAPIHadoopFile.
InvalidInputException: Input path does not exist: file:/Users/me/IdeaProjects/bdrecipes/resources/warc.sample
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:332)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:274)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:396)
QueryPlans.scala/query_plans.py的输入处理逻辑是导致此失败的原因:程序解析文本文件并执行与内存中映射的连接。如果输入文件位置未作为参数传递,则将使用默认位置/Users/me/IdeaProjects/bdrecipes/resources/warc.sample。我们的 Dockerfile 应该将此输入文件放在/opt/spark/work-dir/resources/下,因此当位置/opt/spark/work-dir/resources/warc.sample作为参数传递给程序时,运行时错误将消失:
成功运行QueryPlans.scala(如果需要,将my-app:dev更改为bdrecipes/spark-on-docker):
$ docker run my-app:dev driver --class module1.scala.QueryPlans \
local:///opt/spark/work-dir/bdrecipes-phil.jar \
/opt/spark/work-dir/resources/warc.sample
[...]
: +- Scan[obj#27]
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, string, true]),false), [id=#95]
+- LocalTableScan [tag#7, language#8]
成功运行query_plans.py(如果需要,将my-app:dev改为bdrecipes/spark-on-docker):
$ docker run my-app:dev driver local:///opt/spark/work-dir/tutorials/module1/python/query_plans.py \
/opt/spark/work-dir/resources/warc.sample
[...]
+- *(4) Sort [tag#0 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(tag#0, 200), true, [id=#115]
+- *(3) Filter (isnotnull(tag#0) AND NOT (tag#0 = ))
+- *(3) Scan ExistingRDD[tag#0,language#1]
刚刚执行的程序取自§10.1,它探索了 Catalyst 的查询计划。执行在最后被冻结 10 分钟,以便有足够的时间调查 Spark UI。要跳过此等待时间并停止 Spark 应用程序(和容器),始终可以手动中止运行(例如,通过在 macOS 上按control和c)。
但是,访问 Spark 的 WebUI(通常为localhost:4040)的 URL 将导致失望,即使 UI 服务已成功启动,如执行开始时的日志输出所示:
INFO Utils: Successfully started service 'SparkUI' on port 4040.
INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://59a0411f4157:4040
这可以通过将容器的端口发布到 Docker 主机(我的 MacBook)的标志-p 4040:4040来修复,从而产生以下增强的docker run命令:
- Scala 执行与可在
localhost:4040访问的 Web UI:
docker run -p 4040:4040 my-app:dev driver --class module1.scala.QueryPlans local:///opt/spark/work-dir/bdrecipes-phil.jar /opt/spark/work-dir/resources/warc.sample
- PySpark 执行与可在
localhost:4040访问的 Web UI:
docker run -p 4040:4040 my-app:dev driver local:///opt/spark/work-dir/tutorials/module1/python/query_plans.py /opt/spark/work-dir/resources/warc.sample
半场战绩
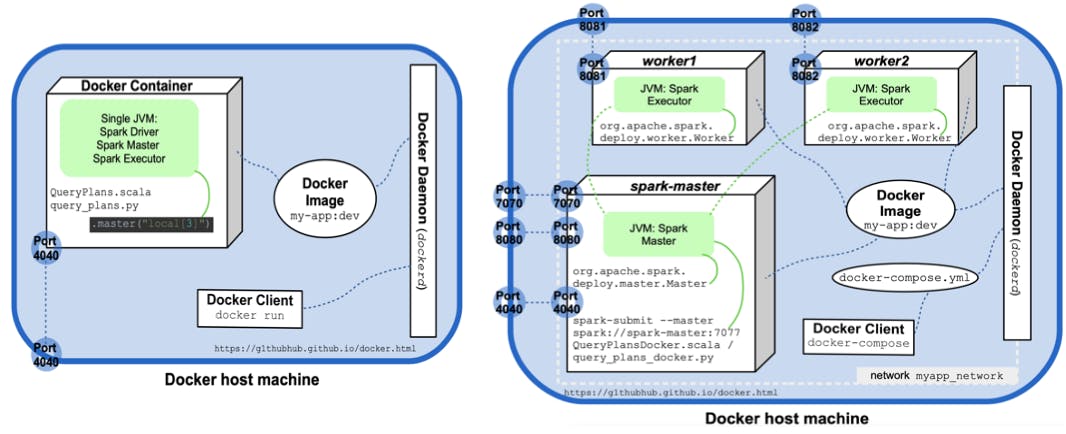
下图试图可视化上次执行以及涉及的最相关的 Spark 和 Docker 实体:
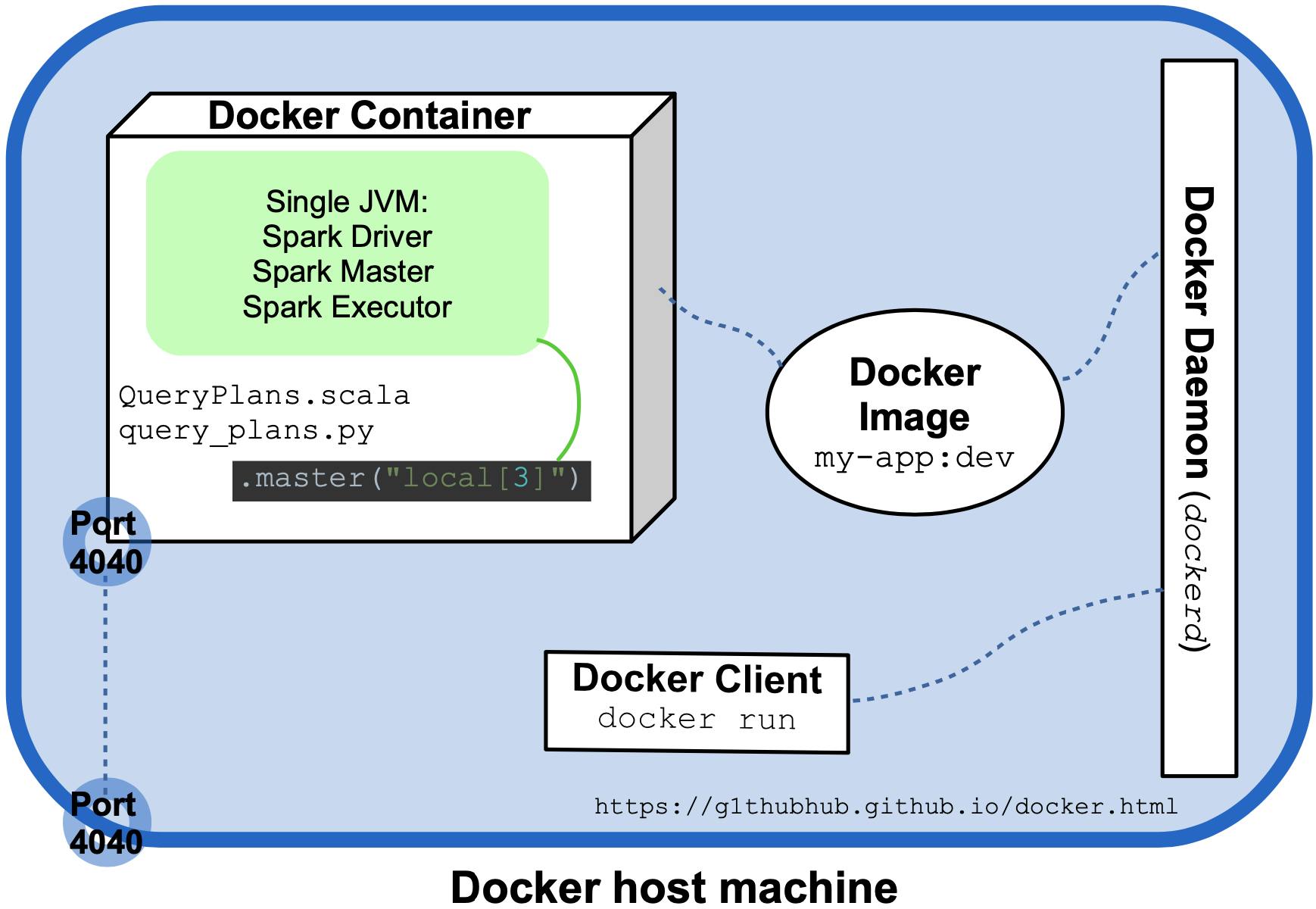
Both QueryPlans.scala and query_plans.py delegate the creation of the SparkSession object to a utility method (createSession and create_session) which sets the master URL as.master("local[3]").通常,Spark Driver、Worker 和 Master 是在不同主机上产生的不同进程,但在这种本地、非分布式模式下,它们重合并在单个 Docker 容器中运行的单个 JVM 中创建。这是本地使用的常规方法,但 Docker 允许我们通过将程序作为多容器 Docker 应用程序运行来轻松创建小型 Spark 集群。这是本文后半部分的主题:
多容器 Docker 应用
如果我们的两个程序应该在多个容器上作为集群应用程序运行,则需要对源代码进行少量修改:SparkSession 对象的主 URL 必须指向集群主节点,因此不能以local开头。本文其余部分将使用的两个稍作修改的程序是QueryPlansDocker.scala/query_plans_docker.py。与上一节的兄弟姐妹的唯一区别是在创建_SparkSession_ 对象时没有显式设置主 URL,该 URL 将从命令行作为参数提供给spark-submit。
到目前为止,不需要明确指定networking 选项。要使多容器方案正常工作,必须使用docker network命令创建网络myapp_network(至少在 MacBook 上):
$ docker network create myapp_network
现在可以手动启动模拟小型 Spark 集群的多容器 Docker 应用程序:从同一个 Docker 映像my-app:dev(或bdrecipes/spark-on-docker)启动多个容器后,必须在它们上生成不同的 Spark 守护进程:我们需要一个实例生成一个 Spark Master(使用org.apache.spark.deploy.master.Master)和一个或多个启动org.apache.spark.deploy.worker.Worker并成功注册到 Spark Master 的“Worker 实例”。然而,正如本文开头已经提到的,Dockerfile 将帮助脚本launch_spark_daemon.sh复制到容器中,这将使生活变得更加轻松。
Docker 编写
launch_spark_daemon.sh脚本在位于 Dockerfile 旁边的特殊 YAML 文件docker-compose.yml中被引用(在其他几个实体中)。此文件由Docker Compose使用,这是一个用于协调多容器 Docker 应用程序的工具。 bdrecipes 项目的 compose文件的内容是:
services:
spark-master:
image: my-app:dev
container_name: spark-master
hostname: spark-master
ports:
- "4040:4040"
- "7077:7077"
- "8080:8080"
networks:
- myapp_network
environment:
- UI_PORT=8080
- MASTER_PORT=7077
command: "sh launch_spark_daemon.sh master"
worker1:
container_name: worker1
hostname: worker1
image: my-app:dev
depends_on:
- spark-master
ports:
- "8081:8081"
networks:
- myapp_network
environment:
- UI_PORT=8081
- MASTER_URL=spark://spark-master:7077
- CORES=1
- MEM=800m
command: "sh launch_spark_daemon.sh worker"
worker2:
container_name: worker2
hostname: worker2
image: my-app:dev
depends_on:
- spark-master
ports:
- "8082:8082"
networks:
- myapp_network
environment:
- UI_PORT=8082
- MASTER_URL=spark://spark-master:7077
- CORES=1
- MEM=800m
command: "sh launch_spark_daemon.sh worker"
networks:
myapp_network:
预建镜像bdrecipes/spark-on-docker的稍微修改的文件被粘贴到此处。 compose 文件定义了三个由容器支持并最终一起运行的服务,主要的是 Spark Master(spark-master),两个 Worker(worker1,worker2)依赖于它。实际的计算工作将在两个 Worker 上执行,Master 将充当协调器,稍后将通过spark-submit启动集群应用程序。 compose 文件中的大多数条目应该是不言自明的,一些一般性说明:
-
所有三个服务都从同一个底层 Docker 镜像
my-app:dev(或bdrecipes/spark-on-docker)实例化,它们都使用之前设置的网络myapp_network -
environment部分设置了几个在launch_spark_daemon.sh中引用的环境变量。脚本本身由三个服务使用command指令调用。 -
只要 Spark 守护进程处于活动状态,三个服务容器就会处于活动状态,因此必须手动停止它们,因为没有超时。
-
每个由 Worker 托管的 Spark 执行器只能使用一个内核和最多 800 MB 的内存。这些是环境变量
CORES和MEM指定的最大资源,当然可以增加。
集群模式和Docker
如前所述,使用 Docker Compose 来设置本地 Spark 集群并不是必须的,几个手动步骤可以达到相同的效果:例如,可以通过以下方式生成 Spark Master 守护程序
-
使用
docker run --rm -it --network myapp_network --name spark-master --hostname spark-master -p 7077:7077 -p 8080:8080 my-app:dev bash创建并进入一个新的容器实例 -
使用如下命令启动镜像中的Master进程:
/opt/spark/bin/spark-class org.apache.spark.deploy.master.Master --host`hostname`--port 7077 --webui-port 8080
显然,当多容器 Docker 应用程序在没有 Compose 工具的情况下运行时,会涉及很多样板文件。有了它,用户除了编写一个撰写文件外,只需要做两件事,即导航到包含该文件的目录并输入命令docker-compose up -d:
$ cd ~/IdeaProjects/bdrecipes
$ docker-compose up -d
Creating network "bdrecipes_myapp_network" with the default driver
Creating spark-master ... done
Creating worker1 ... done
Creating worker2 ... done
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS NAMES
f993eb56b525 my-app:dev "/opt/dm_entrypoint.…" 24 seconds ago Up 20 seconds worker1
5bc05f7260c3 my-app:dev "/opt/dm_entrypoint.…" 24 seconds ago Up 19 seconds worker2
41f2f6482419 my-app:dev "/opt/dm_entrypoint.…" 30 seconds ago Up 24 seconds spark-master
如果使用的是预建镜像bdrecipes/spark-on-docker,则应该将compose文件的这个版本复制到一个新目录下。进入目录后,启动服务的命令不变,即docker-compose up -d。
Docker 在行动
根据终端输出,一个mini Spark集群启动成功。这可以通过访问三个 Spark 守护程序的 UI 来确认,这要归功于 compose 文件的端口转发部分,可以通过以下方式访问:
-
localhost:8080用于主 UI -
localhost:8081用于第一个 Spark Worker 的 UI -
localhost:8082用于第二个 Spark Worker 的 UI
在http://localhost:8080/显示的页面应该表明 Spark Master 已启动并运行,并且两个 Worker 已注册成功:
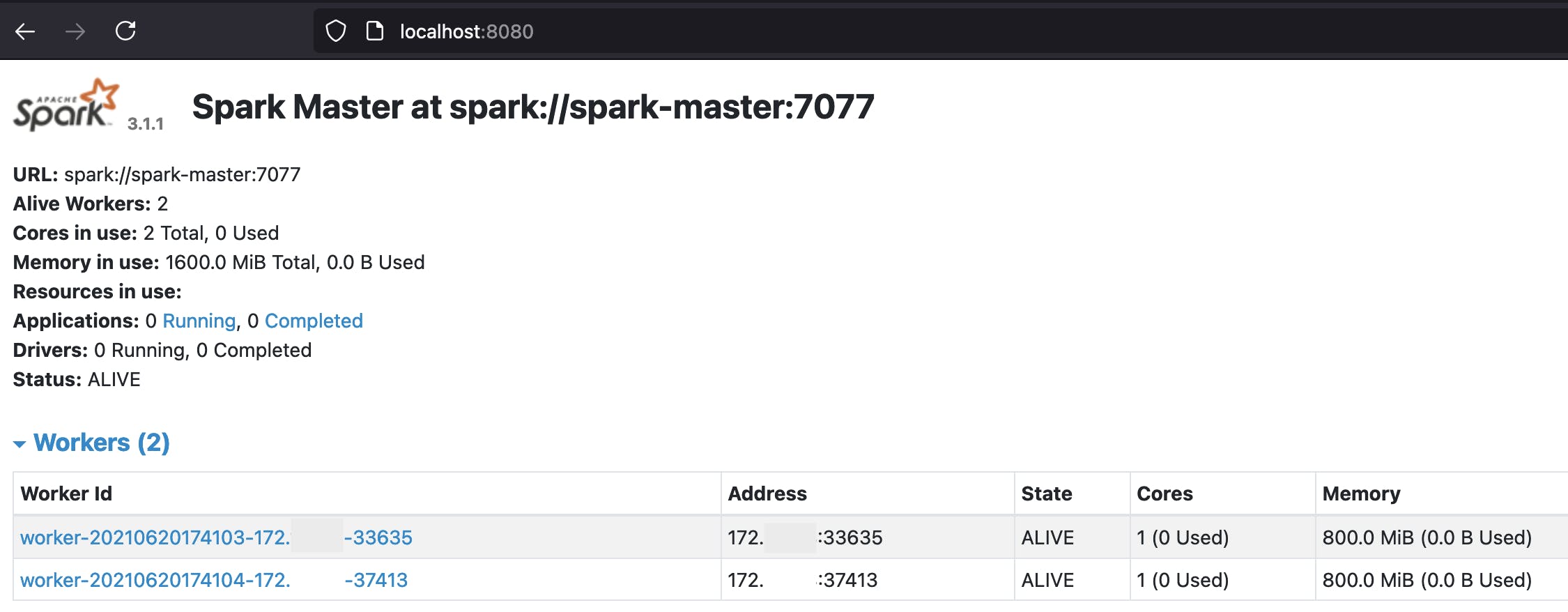
下面是在localhost:8081访问的第一个工作人员的 UI 截图:
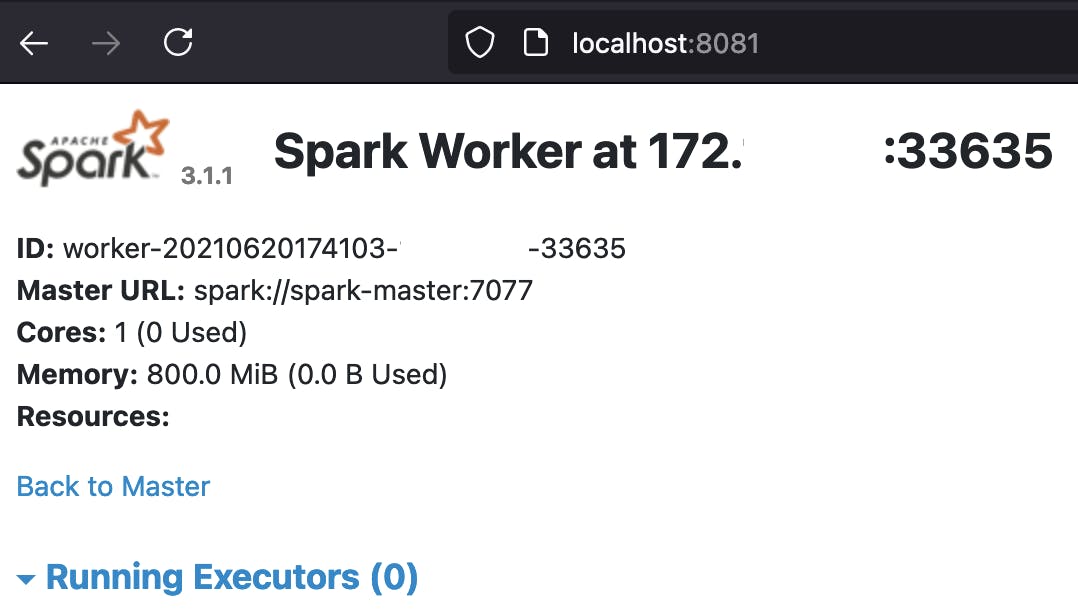
最后一个屏幕截图底部的 Running Executors 表是空的,因为尚未启动 Spark 应用程序,因此 Spark Worker 处于空闲状态。这很快就会改变,QueryPlansDocker.scala/query_plans_docker.py现在可以作为集群应用程序从spark-master容器中运行,只需两个命令:
-
使用
docker exec -it spark-master bash将spark-master容器附加到本地命令行会话 -
Scala:使用
/opt/spark/bin/spark-submit --master spark://spark-master:7077 --executor-memory=768m --class module1.scala.QueryPlansDocker /opt/spark/work-dir/bdrecipes-phil.jar /opt/spark/work-dir/resources/warc.sample启动应用程序 -
PySpark:使用
/opt/spark/bin/spark-submit --master spark://spark-master:7077 --executor-memory=768m /opt/spark/work-dir/tutorials/module1/python/query_plans_docker.py /opt/spark/work-dir/resources/warc.sample启动应用程序
使用docker exec -it spark-master bash附加主容器后执行QueryPlansDocker.scala:
$ /opt/spark/bin/spark-submit --master spark://spark-master:7077 --executor-memory=768m \
--class module1.scala.QueryPlansDocker \
/opt/spark/work-dir/bdrecipes-phil.jar \
/opt/spark/work-dir/resources/warc.sample
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark`s default log4j profile: org/apache/spark/log4j-defaults.properties
INFO SparkContext: Running Spark version 3.1.1
INFO ResourceUtils: ==============================================================
INFO ResourceUtils: No custom resources configured for spark.driver.
INFO ResourceUtils: ==============================================================
INFO SparkContext: Submitted application: Query Plans Docker
INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: ...
INFO ResourceProfile: Limiting resource is cpu
[...]
INFO Utils: Successfully started service 'sparkDriver' on port 37959.
INFO Utils: Successfully started service 'SparkUI' on port 4040.
INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://spark-master:4040
INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://spark-master:7077...
INFO TransportClientFactory: Successfully created connection to spark-master/172.xxxxxxx:7077 after 55 ms (0 ms spent in bootstraps)
[...]
: +- Scan[obj#27]
+- BroadcastExchange HashedRelationBroadcastMode(List(input[0, string, true]),false), [id=#95]
+- LocalTableScan [tag#7, language#8]
使用docker exec -it spark-master bash附加主容器后执行query_plans_docker.py:
/opt/spark/bin/spark-submit --master spark://spark-master:7077 --executor-memory=768m \
/opt/spark/work-dir/tutorials/module1/python/query_plans_docker.py \
/opt/spark/work-dir/resources/warc.sample
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Sparks default log4j profile: org/apache/spark/log4j-defaults.properties
INFO SparkContext: Running Spark version 3.1.1
INFO ResourceUtils: ==============================================================
INFO ResourceUtils: No custom resources configured for spark.driver.
INFO ResourceUtils: ==============================================================
INFO SparkContext: Submitted application: Query Plans Docker
[...]
INFO Utils: Successfully started service 'sparkDriver' on port 40105.
INFO Utils: Successfully started service 'SparkUI' on port 4040.
INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://spark-master:4040
INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://spark-master:7077...
INFO TransportClientFactory: Successfully created connection to spark-master/172.19.0.2:7077 after 49 ms (0 ms spent in bootstraps)
INFO StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20210621204759-0003
[...]
+- *(4) Sort [tag#0 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(tag#0, 200), ENSURE_REQUIREMENTS, [id=#115]
+- *(3) Filter (NOT (tag#0 = ) AND isnotnull(tag#0))
+- *(3) Scan ExistingRDD[tag#0,language#1]
如前所述,本文中使用的程序在计算结果后将执行冻结 10 分钟,从而留出足够的时间来探索 SparkUI。访问localhost:4040/executors确认应用程序以分布式方式执行:
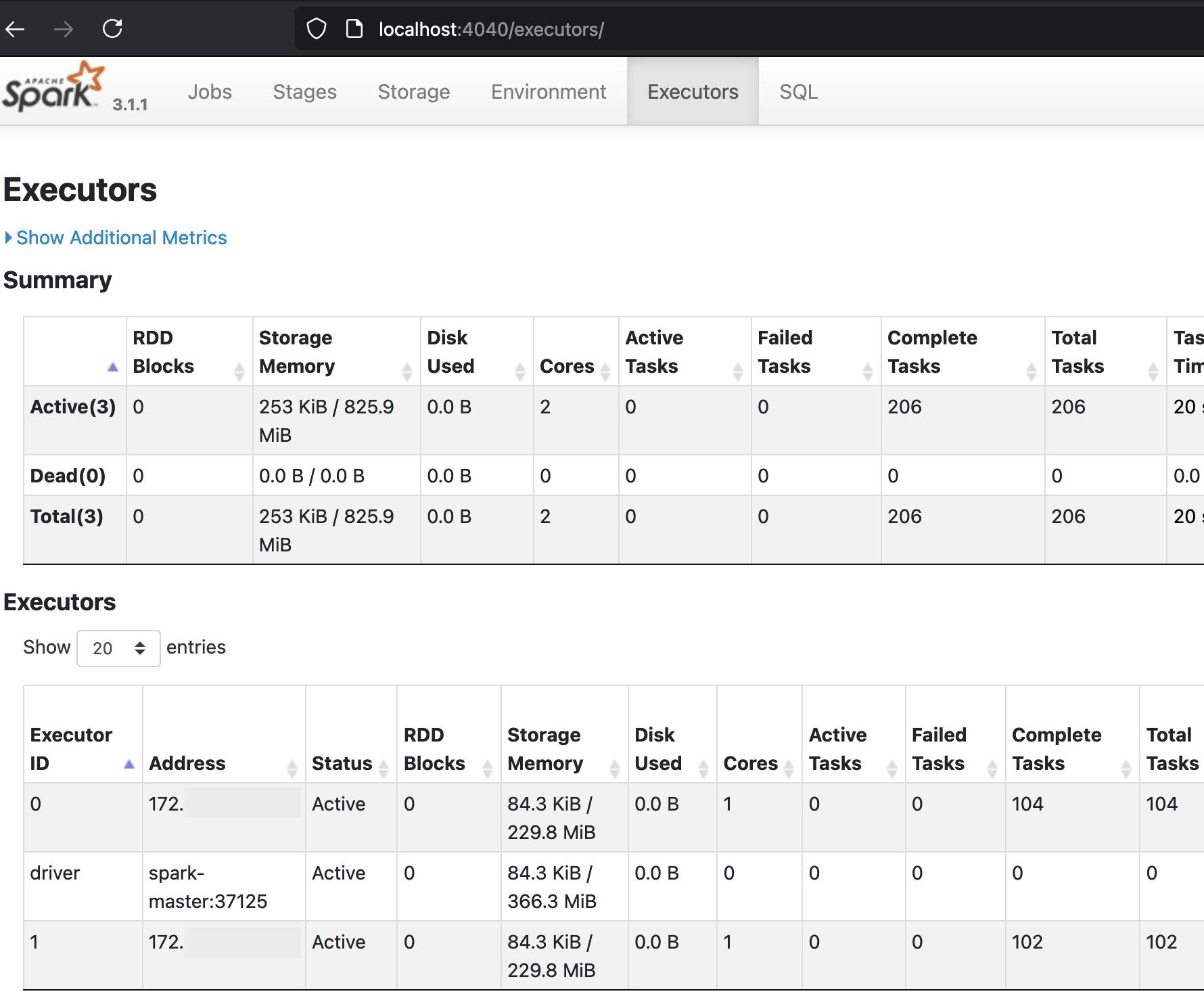
截图后半部分的 Executors 表有两行用于两个执行器,一行用于驱动程序。根据 Completed Tasks 列,Executor 0 上完成了 104 个任务,Executor 1 上完成了 102 个任务,驱动程序上没有。 Executors 表将包含 PySpark 运行的类似条目,任务总数略高,但它们也应该相当均匀地分布在两个执行器之间。
总结
使用上一节中介绍的其他 Docker 和 Spark 实体更新之前的图表会导致图片非常拥挤:
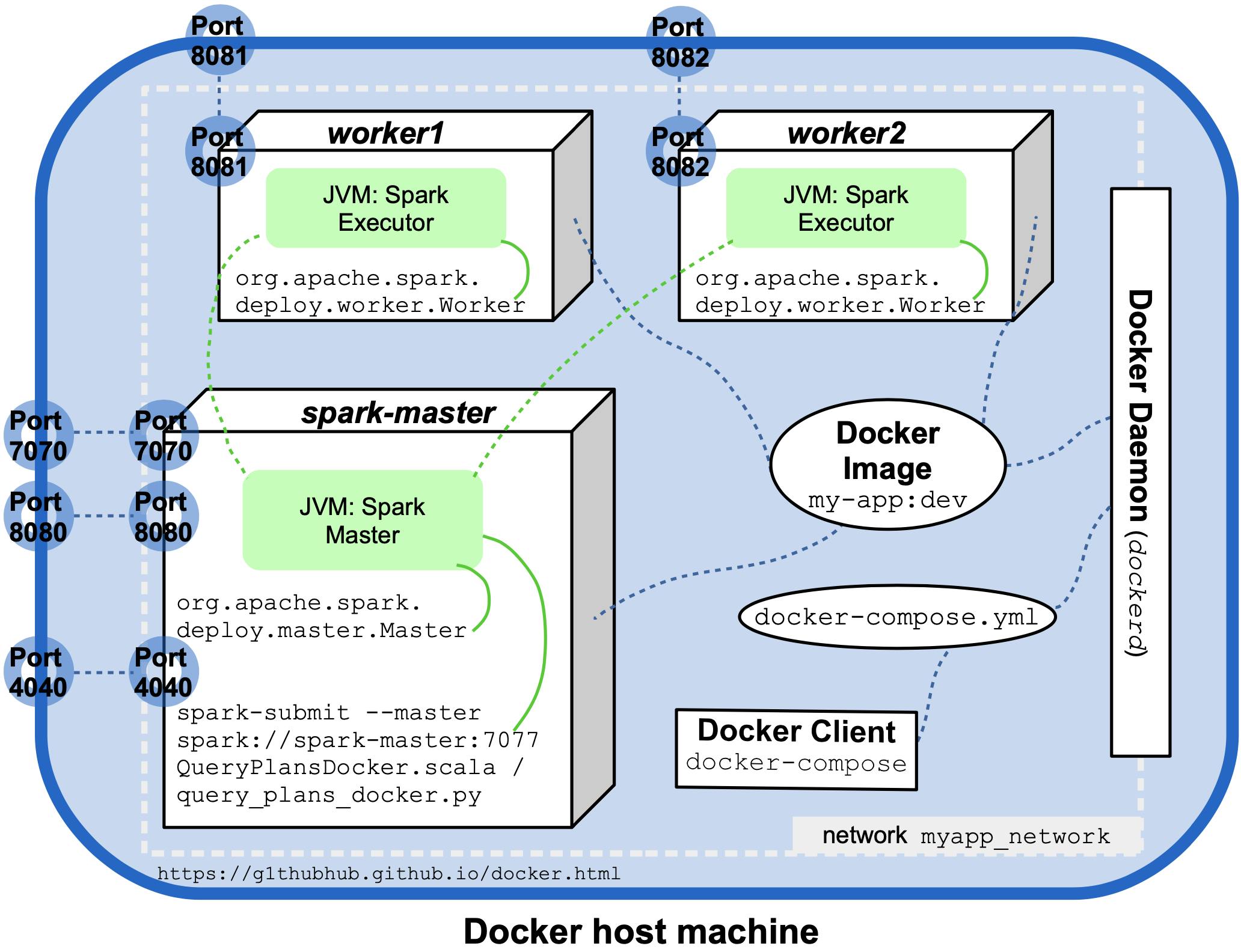
后续文章将演示我们的自定义镜像如何在 Kubernetes 上运行。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35528条内容
已为社区贡献35528条内容

所有评论(0)