
关于 YOLO v3 你需要知道的一切(你只看一次)
本博客将对 YOLOv3(你只看一次)进行详尽的研究,它是广泛用于对象检测、语义分割和图像分类的最流行的深度学习模型之一。在这篇博客中,我将解释 YOLOv3 模型的架构及其不同的层,并查看我在使用该模型在一些测试图像上运行推理程序时得到的一些目标检测结果。 因此,请继续阅读博客以了解有关 YOLOv3 的更多信息。 什么是YOLO? “You Only Look Once”或 YOLO 是为快速
本博客将对 YOLOv3(你只看一次)进行详尽的研究,它是广泛用于对象检测、语义分割和图像分类的最流行的深度学习模型之一。在这篇博客中,我将解释 YOLOv3 模型的架构及其不同的层,并查看我在使用该模型在一些测试图像上运行推理程序时得到的一些目标检测结果。
因此,请继续阅读博客以了解有关 YOLOv3 的更多信息。
什么是YOLO?
-
“You Only Look Once”或 YOLO 是为快速目标检测而设计的一系列深度学习模型。
-
YOLO主要有3个变种,分别是YOLOv1、YOLOv2和YOLOv3。
-
第一个版本提出了通用架构,第二个版本细化了设计并利用预定义的锚框来改进bounding box proposal,第三个版本进一步细化了模型架构和训练过程。
-
它基于以下想法:
" A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. "
1\。 YOLOv3的网络架构图
[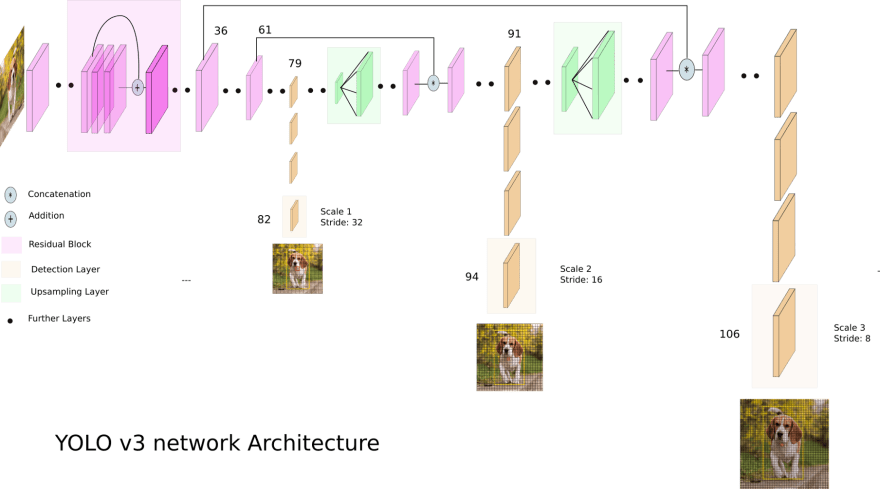 ](https://res.cloudinary.com/practicaldev/image/fetch/s---OWUOygh--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/nr5oq1n6ukg89z8e6ytl.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s---OWUOygh--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/nr5oq1n6ukg89z8e6ytl.png)
2\。架构描述
使用 YOLO v3 进行对象检测的步骤:
-
输入是一批形状为 (m, 416, 416, 3) 的图像。
-
YOLO v3 将此图像传递给卷积神经网络 (CNN)。
-
将上述输出的最后两个维度展平,得到输出量为(19,19,425):
-
在这里,19 x 19 网格的每个单元格返回 425 个数字。
-
425 u003d 5 * 85,其中 5 是每个网格的锚框数量。
-
85 u003d 5 + 80,其中 5 是 (pc, bx, by, bh, bw),80 是我们要检测的类别数。
-
输出是边界框列表以及已识别的类。每个边界框由 6 个数字表示 (pc, bx, by, bh, bw, c)。如果我们将 c 扩展为一个 80 维的向量,每个边界框由 85 个数字表示。
-
最后,我们做了IoU(Intersection over Union)和Non-Max Suppression,以避免选择重叠框。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--2eEwXvfe--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/xr8792eyt5d5q8479es9.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--2eEwXvfe--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/xr8792eyt5d5q8479es9.png)
关于架构:
-
YOLO v3 使用了 Darknet 的一个变种,它最初有 53 层网络在 Imagenet 上训练。
-
对于检测任务,上面堆叠了 53 层以上,为 YOLO v3 提供了 106 层的全卷积底层架构。
-
在 YOLO v3 中,检测是通过在网络中三个不同位置的三个不同大小的特征图上应用 1 x 1 检测内核来完成的。
-
检测核的形状为1 x 1 x (B x (5 + C))。这里B是特征图上一个单元格可以预测的边界框数量,'5'是4个边界框属性和一个对象置信度,C是没有。类。
-
YOLO v3 使用二元交叉熵计算每个标签的分类损失,而对象置信度和类别预测通过逻辑回归预测。
使用的超参数
-
class_threshold - 定义预测对象的概率阈值。
-
非最大抑制阈值 - 它有助于克服在图像中多次检测对象的问题。它通过获取具有最大概率的框并抑制具有非最大概率(小于预定义阈值)的附近框来做到这一点。
-
input_height & input_shape - 要输入的图像大小。
Darknet-53的CNN架构
-
Darknet-53 用作特征提取器。
-
Darknet-53 主要由 3 x 3 和 1 x 1 过滤器组成,具有跳跃连接,如 ResNet 中的残差网络。
[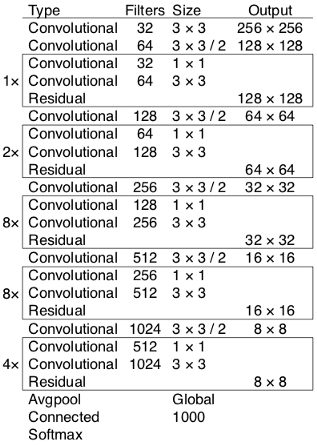 ](https://res.cloudinary.com/practicaldev/image/fetch/s--08LZokE3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/jqbj6s9qlivvkncmft6u.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--08LZokE3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/jqbj6s9qlivvkncmft6u.png)
2\。 YOLOv3架构图
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--5kVLEyT3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/zdmk2adlckbnm8k9n0p8.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--5kVLEyT3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/zdmk2adlckbnm8k9n0p8.png)
3.图层详细信息
-
YOLO 仅使用卷积层,使其成为全卷积网络(FCN)
-
在 YOLOv3 中,使用了称为 Darknet-53 的更深层次的特征提取器架构。
YOLOv3中的卷积层
-
它包含 53 个卷积层,每个卷积层后面跟着批归一化层和 Leaky ReLU 激活。
-
卷积层用于对图像上的多个滤波器进行卷积,并产生多个特征图
-
没有使用任何形式的池化,而是使用步长为 2 的卷积层对特征图进行下采样。
-
它有助于防止通常归因于池化的低级特征的丢失。
4\。 YOLO 内部的不同层
- Tensorflow 中第 1 层到第 53 层的代码:考虑以下代码的 res_block() 方法
def res_block(inputs, filters):
shortcut = inputs
net = conv2d(inputs, filters * 1, 1)
net = conv2d(net, filters * 2, 3)
net = net + shortcut
return net
进入全屏模式 退出全屏模式
前两个带有 32 和 64 个过滤器的 conv2d 层
net = conv2d(inputs, 32, 3, strides=1)
net = conv2d(net, 64, 3, strides=2)
进入全屏模式 退出全屏模式
资源_block * 1
net = res_block(net, 32)
# Convolutional block with 128 filters
net = conv2d(net, 128, 3, strides=2)
进入全屏模式 退出全屏模式
资源_block * 2
for i in range(2):
net = res_block(net, 64)
# Convolutional layer with 256 filters
net = conv2d(net, 256, 3, strides=2)
进入全屏模式 退出全屏模式
res_block * 8
for i in range(8):
net = res_block(net, 128)
# Convolutional layer with 512 filters
route_1 = net
net = conv2d(net, 512, 3, strides=2)
进入全屏模式 退出全屏模式
res_block * 8
for i in range(8):
net = res_block(net, 256)
# Convolutional layer with 1024 filters
route_2 = net
net = conv2d(net, 1024, 3, strides=2)
进入全屏模式 退出全屏模式
资源_block * 4
for i in range(4):
net = res_block(net, 512)
route_3 = net
进入全屏模式 退出全屏模式
5\。模型推理的输入详细信息
输入预处理:
在将图像输入我们的模型之前,需要将图像大小调整为 416 x 416 像素,或者也可以在运行 python 文件时指定尺寸
输入尺寸:
该模型期望输入是具有 416 x 416 像素的正方形的彩色图像,或者也可以由用户指定。
6\。模型推理程序和输出的详细信息
1\。模型的输出
-
输出是边界框列表以及已识别的类。
-
每个边界框由 6 个数字表示 (pc, bx, by, bh, bw, c)。这里 c 是一个 80 维向量,相当于我们要预测的类的数量,每个边界框由 85 个数字表示。
2\。后处理输出
-
推理程序产生一个 numpy 数组列表,其形状显示为输出。这些数组预测边界框和类标签,但经过编码。
-
此外,我们将获取每个 numpy 数组并解码候选边界框和类别预测。如果有任何边界框不能自信地描述对象(类别概率小于阈值,0.3),我们将忽略它们。
-
这里最多可以在图像中考虑 200 个边界框。
-
我使用了correct_yolo_boxes() 函数来执行边界框坐标的平移,以便我们可以绘制原始图像并绘制边界框。
-
再次删除那些可能指向同一对象的候选边界框,我们将重叠量定义为非最大抑制阈值 u003d 0.45。
-
还需要将边界框的坐标重新调整为原始图像,并在每个边界框的顶部显示标签和分数。
-
在我们获得边界框以及输出图像中识别的类之前,需要执行所有这些后处理步骤。
3\。模型推理程序的输出
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--mDrjFtho--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/mp4bfay0kauseh5qi7ee.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--mDrjFtho--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/mp4bfay0kauseh5qi7ee.png)
[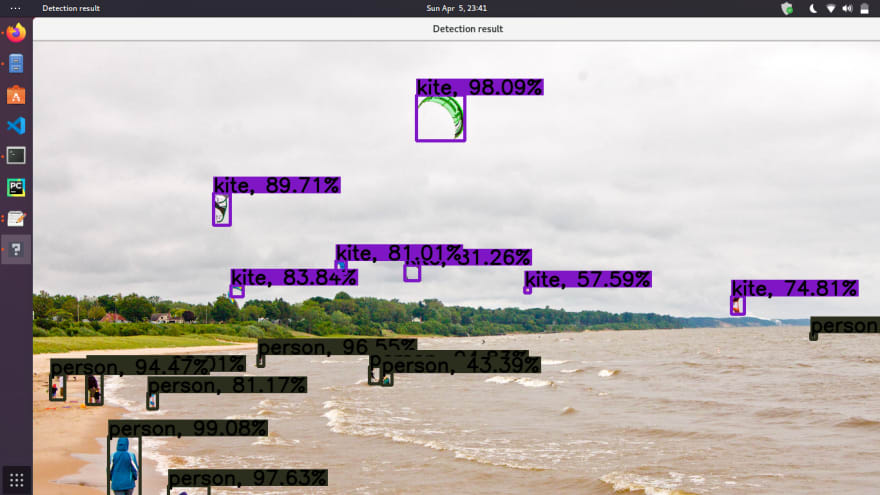 ](https://res.cloudinary.com/practicaldev/image/fetch/s--XCULNqEg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/mi03i6zfwe7v0o8xcpmq.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--XCULNqEg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/mi03i6zfwe7v0o8xcpmq.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--2oGiFDGS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/0334dn2man69a6am3caf.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--2oGiFDGS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to-uploads .s3.amazonaws.com/uploads/articles/0334dn2man69a6am3caf.png)
7\。 YOLOv3 的速度和准确性
-
模型速度(以 FPS 为单位) - 在 Pascal Titan X 上,它以 30 FPS 的速度处理图像。
-
模型精度(在测试数据集上) - 它在 VOC 测试集上的 mAP(平均精度)为 87.54%。
8\。运行模型
找到指向我的 Dockerfile 的链接:afrozchakure/yolov3-tensorflow
要在您的机器上使用 docker(应预先安装 docker)运行模型,请在终端中使用以下命令 :)
xhost +
sudo docker run --rm -ti --net=host --ipc=host -e DISPLAY=$DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix --env="QT_X11_NO_MITSHM=1" afrozchakure/yolov3-tensorflow
进入全屏模式 退出全屏模式
9\。从以下资源中了解有关 YOLOv3 工作原理的更多信息
参考链接 1
参考链接 2
如果你能走到这一步,那就太好了。干杯😇💖

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献35529条内容
已为社区贡献35529条内容

所有评论(0)