JVM调优案例
一家制造工厂的 MES(制造执行系统) 需要定期(如每月)为管理层生成生产报表。该系统已稳定运行数年。最近,每当财务部门在月初执行“月度生产报告导出”功能时,系统就会无响应,随后日志中出现 java.lang.OutOfMemoryError: Java heap space错误,导致需要重启应用。
1. 问题现象 (The Symptom)
操作:用户在 Web 界面上点击“导出月度生产数据(Excel)”。
现象:界面卡住几分钟后,提示“服务器内部错误”。
日志:应用日志中出现 OutOfMemoryError,GC 日志显示在错误发生前进行了多次连续的 Full GC,但几乎无法回收内存(“GC overhead limit exceeded” 也可能出现)。
特点:问题只在执行特定操作时出现,且每月只出现一次。系统其他功能正常。
2. 根本原因分析 (Root Cause Analysis)
第一步:获取堆转储(Heap Dump)
由于问题可复现,在导出操作时使用 jmap或配置 -XX:+HeapDumpOnOutOfMemoryError生成堆转储文件(heapdump.hprof)。
第二步:使用 MAT 分析
打开堆转储文件后,MAT 的 Leak Suspects Report 直接指向问题:
1.一个 java.lang.Object[]数组占据了约 90% 的堆内存。
2.点击详情查看,发现这个数组被一个 ArrayList所持有。
3.查看这个 ArrayList的引用链,最终定位到是一个 XSSFWorkbook 对象。
结论:内存被 Apache POI 库中用于生成 Excel 的 XSSFWorkbook对象完全占满。
第三步:代码溯源
检查导出功能的代码,发现如下问题:
// 伪代码:有问题的报表导出逻辑
@PostMapping("/export/monthlyReport")
public void exportMonthlyReport(HttpServletResponse response) {
// 1. 从数据库查询出整整一个月的历史生产数据(数十万条记录)
List<ProductionRecord> allRecords = productionDAO.findAllByMonth(month);
// 2. 在内存中创建一个Excel工作簿
XSSFWorkbook workbook = new XSSFWorkbook();
// 3. 遍历所有数据,逐个创建Row和Cell,并写入workbook
for (ProductionRecord record : allRecords) {
XSSFRow row = sheet.createRow();
row.createCell(0).setCellValue(record.getDate());
row.createCell(1).setCellValue(record.getProductId());
row.createCell(2).setCellValue(record.getQuantity());
// ... 可能多达20列
}
// 4. 将workbook写入response输出流
workbook.write(response.getOutputStream());
}
致命问题分析:
1.数据量巨大:一个月的历史生产数据可能达到 几十万甚至上百万条。
2.Apache POI 的模型开销:XSSFWorkbook(用于处理 .xlsx)会将所有工作表、行、单元格的对象模型完全保存在内存中。每个单元格都是一个 Java 对象。创建 100w 个单元格,就需要在内存中创建 100w 个对象。这对于 JVM 堆内存来说是极其沉重的负担。
3.一次性加载:代码将所有数据一次性从数据库查出,并在内存中一次性构建整个 Excel 模型,导致内存使用量呈爆炸式增长,直接撑爆堆内存。
3. 解决方案 (The Solution)
方案一:优化代码(采用流式处理)
这是最根本的解决方案。使用 Apache POI 提供的 SXSSFWorkbook 替代 XSSFWorkbook。
SXSSFWorkbook 采用“流式”处理模式,它只在内存中保留一定数量的行(如 100 行),当行数超过阈值时,将最早的行刷新到磁盘临时文件中。这样可以极大幅度地降低内存消耗。
// 优化后的伪代码
@PostMapping("/export/monthlyReport")
public void exportMonthlyReport(HttpServletResponse response) {
// 1. 采用SXSSFWorkbook,并设置一个在内存中保留的行数(例如100行)
SXSSFWorkbook workbook = new SXSSFWorkbook(100);
// 2. 使用数据库分页查询,而不是一次性加载所有数据
int pageSize = 1000;
int pageNumber = 0;
Page<ProductionRecord> page;
do {
page = productionDAO.findAllByMonth(month, PageRequest.of(pageNumber, pageSize));
List<ProductionRecord> records = page.getContent();
// 3. 将这一页数据写入Excel
for (ProductionRecord record : records) {
// ... 创建行和单元格的逻辑
}
// 4. 重要:强制刷新当前数据到磁盘,清空内存中的行
sheet.flushRows();
pageNumber++;
} while (page.hasNext());
// 5. 写入响应流
workbook.write(response.getOutputStream());
// 6. 重要:清理临时文件
workbook.dispose();
}
方案二:调整 JVM 参数(临时缓解)
在代码优化上线前,作为临时方案,可以增加堆内存大小:
-Xms2g -Xmx4g # 将堆内存最大值从2G提高到4G
但这是一个治标不治本的方法:如果数据量持续增长,未来依然会 OOM。而且大内存会带来更长的 GC 停顿时间。
方案三:架构优化
异步导出:对于超大数据量的导出,不应是同步请求。可以改为用户提交导出任务后,系统在后台异步处理,生成文件后上传到 OSS 或文件服务器,再通知用户下载。
改变格式:对于极其大量的数据,考虑导出为 CSV格式而非 Excel,CSV 的内存开销极小。
总结与启示
这个传统行业的 OOM 案例非常经典,它告诉我们:
1.OOM 不总是高并发导致:单次操作的数据量过大同样致命,在数据处理、报表生成类功能中尤为常见。
2.第三方库是重灾区:像 Apache POI、PDF 生成工具、XML 解析器等第三方库,如果不了解其内存模型,很容易误用导致 OOM。
3.排查流程是关键:通过 MAT 分析 Heap Dump,迅速定位到占用内存最大的对象类型(XSSFWorkbook),从而直指问题核心。
4.解决方案重于参数调整:本例中,最有效的方案是改用流式 API(SXSSF)和分页查询,而不是简单地加大堆内存。这体现了从代码和架构层面根本解决问题的能力,而这正是面试官最希望看到的。
好的,我们举一个更简单、更清晰的例子:一个提供遥感影像查询和缩略图生成服务的Web应用。
场景描述
假设你有一个网站,用户输入影像编号和日期,系统会从数据库中查询到对应的遥感影像存储路径,然后从磁盘读取大型的TIFF影像文件,在内存中生成一个指定大小(如200x200像素)的缩略图,最后返回给用户。
•核心功能: 查询数据库 -> 读取大文件 -> 在内存中处理图像 -> 输出缩略图。
•技术栈: Spring Boot Web应用,使用Java内置的ImageIO库进行图像处理。
问题表现
随着用户访问量增加,你通过监控发现:
响应时间变长: 用户感觉页面加载图片越来越慢。
2.
CPU使用率过高: 服务器CPU持续在90%以上,但实际服务的用户数并不多。
3.
频繁的垃圾回收: GC日志显示每秒都在进行Young GC,而且每次GC后存活对象很多,内存压力大。
第一步:发现与监测 (How to Find?)
1.
查看GC日志 (-Xlog:gc*):
•发现: Eden区(年轻代)在以极快的速度被填满,导致几秒钟就触发一次Young GC。
•关键线索: GC后,老年代的使用量在稳步增长。这说明每次Young GC后,都有不少对象“存活”下来并被移到了老年代。
2.使用jstack分析CPU热点:
•在CPU高的时候,执行 jstack -l > stack.txt。
•发现: 很多线程都卡在 ImageIO.read(file) 这个方法上。这是一个强烈的信号,说明图像读取是瓶颈。
3.使用内存分析工具(如Eclipse MAT)分析堆转储 (jmap -dump:format=b,file=heap.hprof )):
•发现: 老年代里充满了大量的 byte[] 数组对象,这些数组非常大,每个都几MB甚至十几MB。追溯这些数组的引用链,发现它们都是由 BufferedImage 对象引用的。
第二步:根因分析 (Why?)
结合上面的监测信息,问题变得清晰:
•
罪魁祸首: ImageIO.read(file) 这个方法。
•
它做了什么: 为了读取一个巨大的TIFF文件(可能1GB),它会在内存中完全加载并解码整个图像,生成一个完整的 BufferedImage 对象及其背后的像素数据数组(byte[])。
•
为什么这很糟糕:
1.创建大对象: 一个1GB的影像文件解码后,可能会在堆里生成一个几百MB的 BufferedImage 和 byte[]。这种大对象直接分配在老年代(或者对于G1 GC,是Humongous区),分配和回收效率都很低。
2.CPU密集型: 解码整个大文件是一个非常消耗CPU的计算过程。
3.资源浪费: 用户只需要一个200x200的缩略图,但你却为每个请求都加载了整个1GB的影像!这就像为了喝一杯牛奶而养了一头奶牛。
结论:
每次请求都触发一次完整的、昂贵的大文件解码操作,创建巨大的临时对象,迅速撑满内存导致频繁GC,解码过程又吃光了CPU。这就是响应慢、CPU高、GC频繁的三重问题的共同根源。
第三步:解决与调优 (How to Fix?)
- 代码优化(治本之策)
目标: 避免读取和解码整个大文件。
方案: 使用支持随机访问或区域读取的专业影像库来代替 ImageIO。
•例如,使用GDAL库(通过JNI)或GeoTools库:
// 伪代码示例
public BufferedImage generateThumbnail(String filePath, int width, int height) {
// 1. 打开文件,但此时并不读取像素数据
Dataset dataset = GDAL.Open(filePath, ...);
// 2. 直接读取你关心的区域(ROI)并缩放到目标大小
// 这里只会解码所需的一小块数据,而不是整个文件!
BufferedImage thumbnail = dataset.ReadAsArray(... /*指定读取范围*/, width, height);
dataset.close();
return thumbnail;
}
•
效果:
•
内存使用: 从每次请求几百MB降到几百KB。彻底解决了大对象和内存压力问题。
•
CPU使用: 只解码一小块区域,CPU计算量下降几个数量级。
•
响应时间: 速度极大提升。
2. JVM调优(辅助手段)
在代码优化之后,GC压力已经大幅减轻。此时可以进行一些常规优化:
•
切换GC器: 从默认的Parallel GC切换到G1 GC (-XX:+UseG1GC),并设置最大停顿目标 (-XX:MaxGCPauseMillis=100),让应用更平滑。
•
增加堆内存: 如果处理并发请求很多,可以适当增加总堆大小 (-Xms4g -Xmx4g),为新的、更高效的程序提供充足空间。
•
添加缓存: 对于热门影像的缩略图,直接在内存或Redis中缓存生成好的结果,避免重复处理。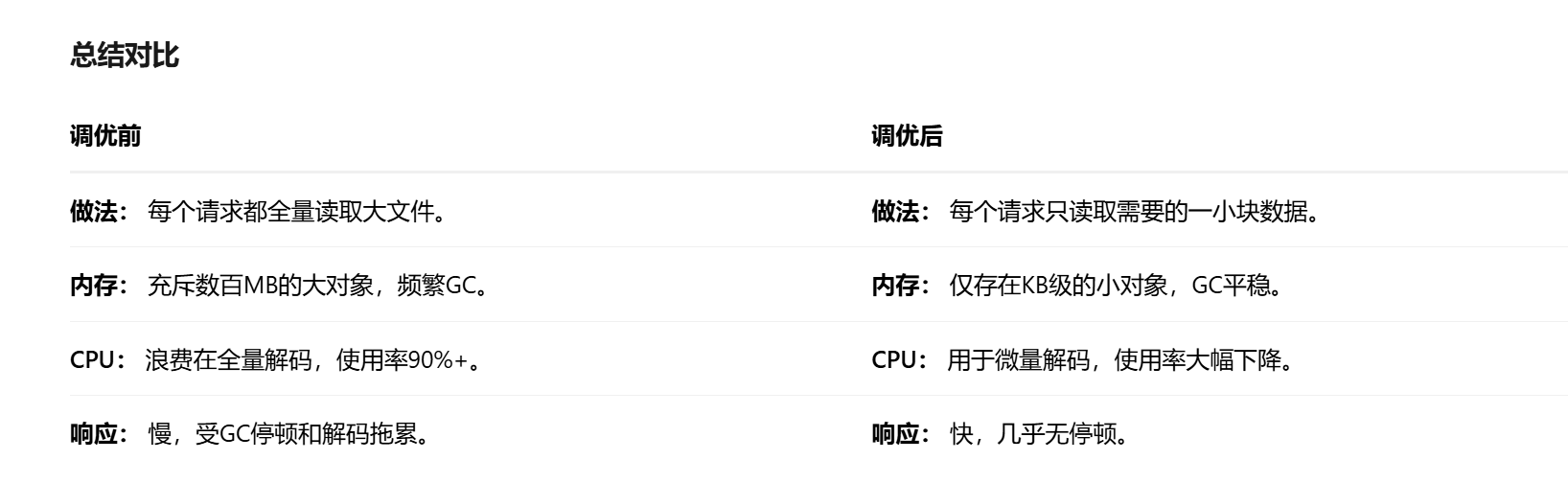
这个例子清晰地展示了:绝大多数Java性能问题,首先应从代码和算法层面寻找优化点,而不是盲目调整JVM参数。JVM调优是“治标”,而代码优化才是“治本”。监测工具(GC日志、jstack、MAT)是帮你找到“本”在哪里的眼睛。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)