LeVERB——潜在视觉-语言指令驱动的人形全身控制:快慢双系统下VLM感知环境和指令,VLA执行动作(完全基于合成数据进行训练)
LeVERB是首个基于视觉-语言潜在动作的人形机器人全身控制系统,由加州伯克利等机构联合研发。该系统采用分层架构:高级视觉-语言策略(系统2)解析多模态输入并生成潜在动作计划;低级反应式控制器(系统1)以50Hz频率执行全身动作。创新点包括:1)通过合成数据流程生成17.1小时真实感运动数据;2)残差条件变分自编码器实现语义对齐;3)判别器消除模态差异。实验表明LeVERB能完成"走到桌
前言
我在《一文通透ViT——把图片划分成一个个patch块后再做注意力计算,打破CNN在CV领域的统治地位(含Swin Transformer的详解)》的开头有说到,“长沙分部很快 要折腾两个新的具身项目了,到时候就是第二轮、第三轮的突飞猛进,至于第一轮突飞猛进是今25年6.4-7.19日 ”
那第二轮将开始于什么时候呢?很快了,因为自从7月份基于客户提供的G1完成一舞蹈的交付后,8月下旬已连签两个合同(一个机械臂、一个人形),客户们将在9月初 把机器寄到长沙分部
当然,过去的一个多月,长沙分部一天也没闲着,包括我个人在过去的一个多月先后解读了
- NaVid、LOVON、Manual2Skill、TrackVLA(智能跟随)
- VideoMimic、Grounded SAM
- ForceVLA、Galaxea G0、EgoVLA、Qwen3、Tactile-VLA、MP3D、CorrectNav、NavA3
- ViT、图文对比学习CLIP等、GSPO
可以看到,过去一个多月这17篇解读中,有4篇是跟导航相关的,原因很简单:今年以来签的订单中,有好几个都跟导航有关,其次是语音交互
而语音交互的重要性则越来越高,毕竟人形在替人类干活的过程中,不可避免的会常常涉及到和人类的交流
而本文要解读的LeVERB便是基于潜在视觉-语言指令的人形机器人全身控制
- 当我看到LeVERB的时候,第一反应想到的是Helix (其次则是GR00T)
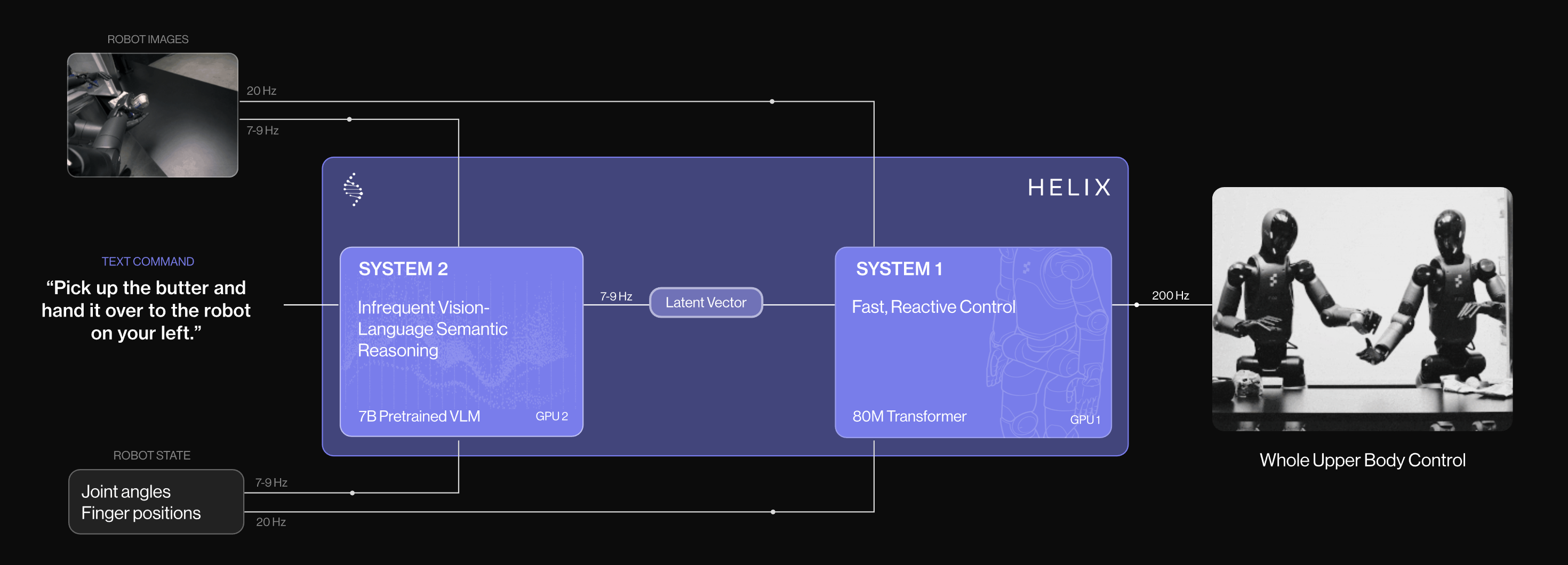
- 但本文要介绍的LeVERB,其模型结构则比Helix要复杂些
其在结构上,与《Hi Robot——大脑加强版的π0:基于「VLM的高层推理+ VLA低层任务执行」的复杂指令跟随及交互式反馈》更像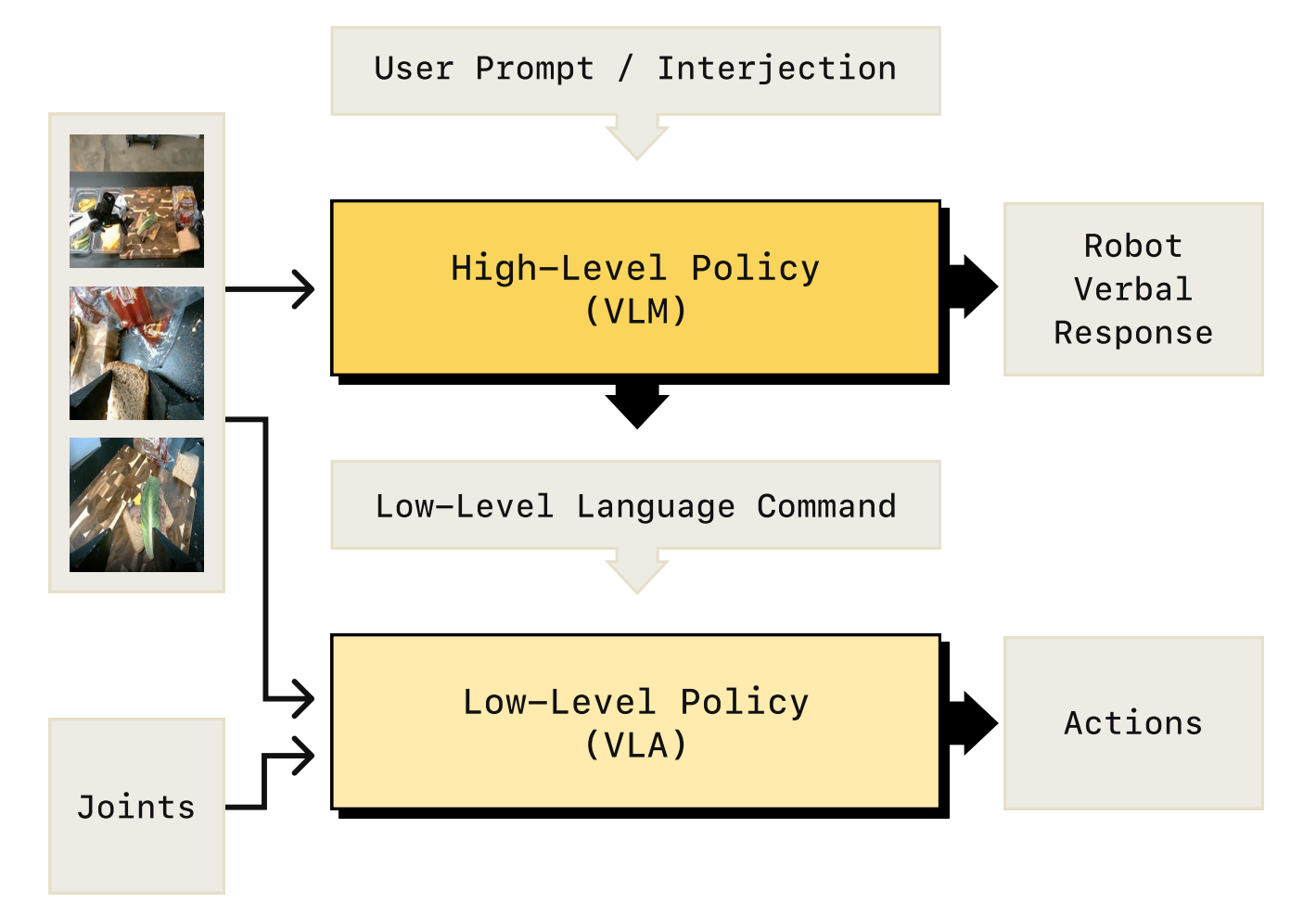
第一部分 LeVERB
1.1 引言、相关工作、LeVERB 数据集与基准测试
1.1.1 引言
如原论文所说,人类既能快速思考,也能慢速思考。视觉和语言最终在大脑皮层中处理,使人类具备高级推理能力和长时规划能力;而由脊髓反射和皮层下运动回路介导的感知-运动反应,则支持快速、反应性的控制[18]
这种双重处理架构使人类能够执行复杂的运动技能,并适应不断变化的环境
为了实现类似的人体整体能力,具备与人类运动控制复杂性相当的人形机器人同样需要集成一种分层架构,将来自本体感觉反馈的高频控制与基于丰富视觉和语言输入的低频规划及语义推理相结合
以往基于VLA的WBC相关研究通常依赖于显式、低维的动作“词汇”,如基础速度、末端执行器位姿等,将其作为VLA模型与低层控制器之间的接口[9,11]。在这种框架下,低层控制通常仅能执行少量原子技能,并被设计为能够对细粒度的高层命令做出快速响应
然而,这类接口限制了表达能力,使得集成复杂的全身运动和场景交互变得困难。为了充分释放人形机器人全身能力,需要:
- 一种学习得到的“潜在词汇”,其表达能力足以覆盖全身运动,并能够捕捉视觉和语言输入中编码的语义
- 并将其与(2) 一个多功能的WBC层结合,该层能够动态地将这一词汇转化为人形机器人可行的动作,并能够零样本迁移到真实世界
为弥合这一差距,来自1 University of California Berkeley、2 Norwegian University of Science and Technology、3 Simon Fraser University、4 Carnegie Mellon University的研究者提出了LeVERB(Latent Vision-Language Encoded Robotic Behavior,潜在视觉-语言编码机器人行为),这是首个用于人形机器人全身控制的视觉-语言潜在动作模型
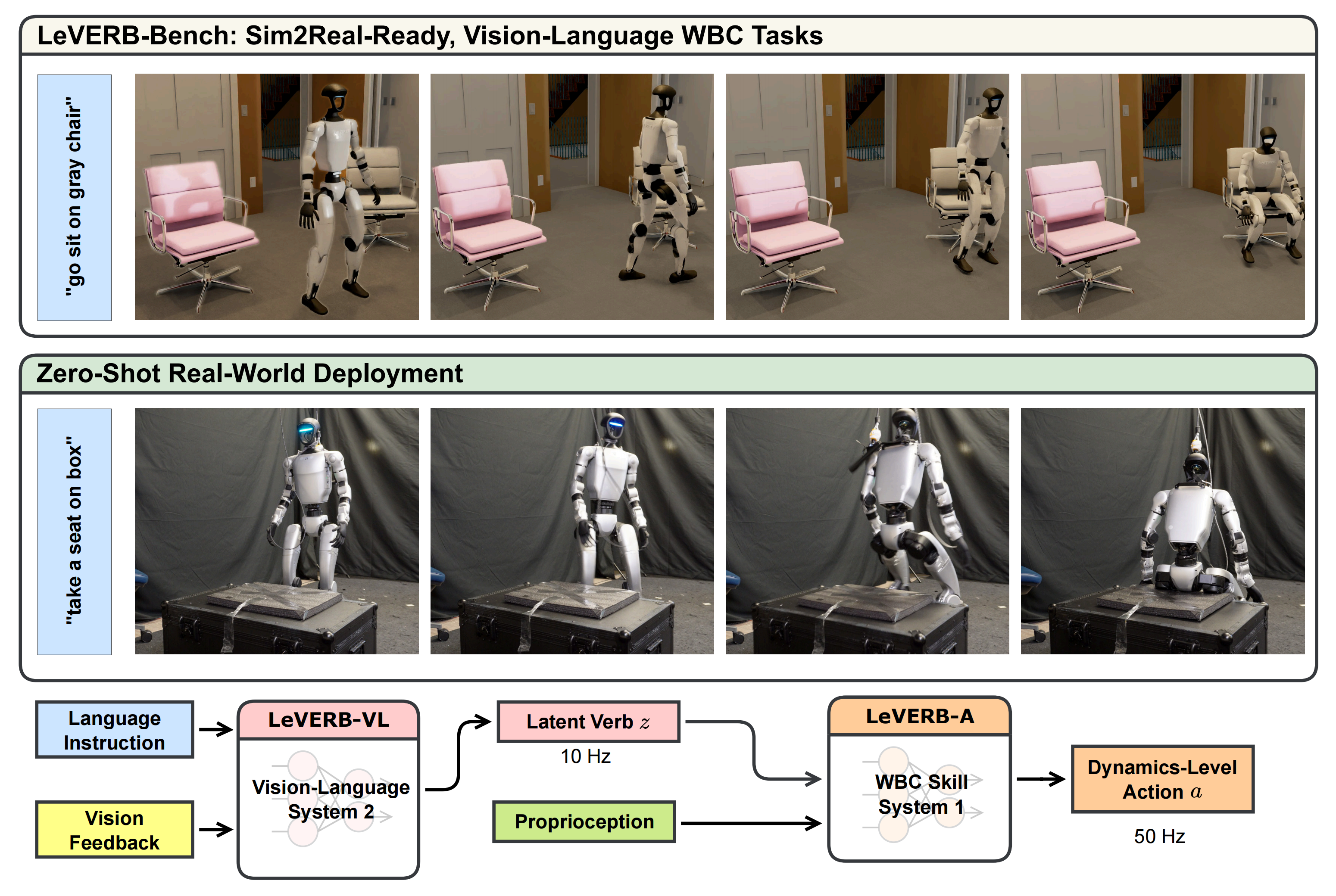
- 其paper地址为:LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
其作者为:
Haoru Xue 1∗、Xiaoyu Huang 1∗、Dantong Niu 1∗、Qiayuan Liao 1∗
Thomas Kragerud 2、Jan Tommy Gravdahl 2、Xue Bin Peng 3、Guanya Shi 4
Trevor Darrell 1、Koushil Screenath 1、Shankar Sastry 1 - 其项目地址为:ember-lab-berkeley.github.io/LeVERB-Website
具体而言,LeVERB包括
- 一个高级视觉-语言策略(系统2),用于解析视觉-语言输入
为了解决机器人专用视觉数据稀缺的问题,作者开发了一条数据合成流程,收集多样化的人体动作,并将其重新定向到人形机器人上,然后在随机化场景中进行真实感渲染
随后,利用视觉语言模型(VLM)对一组语义相似的语言指令进行标注。这使得高级视觉-语言动作模型能够直接在配对的、机器人专用的视频和语言数据上进行训练 - 以及一个低级反应式控制器(系统1),用于执行全身动作
且为了从视觉-语言输入中学习结构化的潜在空间,作者提出了一种基于CVAE的高层VLA模块架构。这一结构化潜在空间对于学习统一的视觉-语言-动作分布至关重要,它能够准确对齐感知与动作,同时缓解过拟合问题
且为降低并行仿真训练中写实渲染的成本,作者将学习过程解耦
- 首先,通过运动学重建训练视觉-语言组件,实现视觉与动作语义的对齐
- 随后,冻结其潜在空间,并训练一个独立的动作模块,该模块从中采样以学习仅基于本体感觉的控制器,专注于掌握机器人动力学
LeVERB 完全基于合成数据进行训练,实现了灵活、可由指令驱动的人形机器人行为。它能够根据状态空间目标(例如“向左转”、“直行”)和视觉目标(例如“走到前面的桌子旁”、“坐在绿色椅子上”)执行指令
在推理阶段,视觉-语言模块(系统2)将视觉和语言输入编码为潜在的行动计划,随后由低层控制器(系统1)解码为可在机器人上执行的运动指令
1.1.2 相关工作
第一,对于仿人全身控制
基于物理的动画在类人全身控制方面的最新进展取得了显著成果,主要通过动作跟踪方法[37,38,29],即强化学习(RL)策略模仿来自人体动作捕捉(MoCap)数据的参考动作
- 在此基础上,诸如PULSE [30] 和 MaskedMimic [46] 等方法,通过条件变分自编码器(Conditional VAE)或基于语言和物体交互条件的Transformer,学习可由高层输入控制的潜在策略
TokenHSI [36] 进一步支持组合式的物体交互
然而,这些方法依赖于特权模拟状态(例如完整的物体姿态),这限制了其在现实世界中的应用,并忽略了视觉输入 - 相比之下,现实世界中的人形机器人系统避免使用潜变量条件的低层控制,而是预测诸如底座速度、朝向或全身关键帧等显式指令 [10,22,16,12,19]。这种模块化设计便于集成,但由于预测结果不可行,往往导致动作抖动或不自然
LangWBC [43] 引入了一种基于语言条件的CVAE用于全身控制,具备潜在结构,但缺乏视觉基础和高级推理能力,因此仅限于执行简单指令
————
其paper地址为:LangWBC: Language-directed Humanoid Whole-Body Control via End-to-end Learning
其项目地址为:langwbc.github.io
其GitHub地址为:github.com/YiyangShao2003/LangWBC
故,将视觉条件的潜变量策略融入人形机器人控制,仍然是一个关键挑战
第二,对于用于机器人学习的分层VLA
近年来,在操作领域的研究进展[17,4,49,53,20,45]表明,视觉-语言-动作(VLA)模型通过将视觉和语言输入与低层控制相结合,实现了对开放世界任务的泛化
然而,端到端模型由于VLA主干网络体积庞大,通常推理延迟较高,导致动作响应延迟或不连贯。对于需要高频、低延迟反馈以保证稳定性和灵活性的人形机器人全身控制来说,这一问题尤为突出
为了解决这一难题,近期研究[7,52,3,15,23]采用了分层的System-1-System-2架构
- 值得注意的是,AGIbot[7]证明使用潜在接口能够提升性能。对于如四足或人形机器人等动态系统,现有的真实世界方法通常依赖于高层与低层策略之间的显式接口
- 例如,Liu等人[27]在全身操作中采用末端执行器姿态和底座速度
- NaVILA[9]则预测方向和距离以进行速度控制
- Humanoid-VLA[11]预测全身姿态,具备较强表达能力,但需要针对具体任务进行调优
这些显式策略简化了模块化训练,但限制了对多样化全身技能(如坐姿交互等)的泛化能力。作者认为所知,尚无先前的研究在真实人形机器人上,通过分层潜变量架构实现视觉-语言驱动的全身控制——本工作正是旨在填补这一重要空白
第三,对于人形机器人的基准测试
演示数据是训练VLA模型的关键支撑,但为机器人控制收集此类数据并非易事。在操作领域,近期的研究通过使用遥操作[21,35,4]和专家策略蒸馏[33]的大规模数据收集流程来应对这一问题
- 相比之下,用于类人机器人视觉WBC的演示数据仍然稀缺。尽管近期在类人机器人遥操作方面取得了进展[19,16,50],但由于在实体机器人上收集全身动作的复杂性,大规模视觉演示尚未实现
- 现有基准要么仅关注于行走[1],要么仅在状态空间中运行,而不涉及视觉效果[41,31],或采用非真实感渲染[28],导致了较大的仿真到现实差距
作者提出了首个同时提供真实感渲染和基于物理的全身动作仿真,并可直接迁移到真实硬件的基准和数据集
1.1.3 LeVERB 数据集与基准测试
由于目前尚无适用于基于视觉-语言的人形机器人WBC的数据集和基准,下面先介绍LeVERB-Bench,这是一个高效且可扩展的用于合成视觉-语言人形机器人WBC数据生成与闭环基准测试的流程
数据集可视化的概览如图2所示:LeVERB-Bench环境可视化。上排:数百种材质和物体随机化选项。中排:第一人称摄像头视角及随机化的第三人称摄像头视角。下排:多样化的任务类别
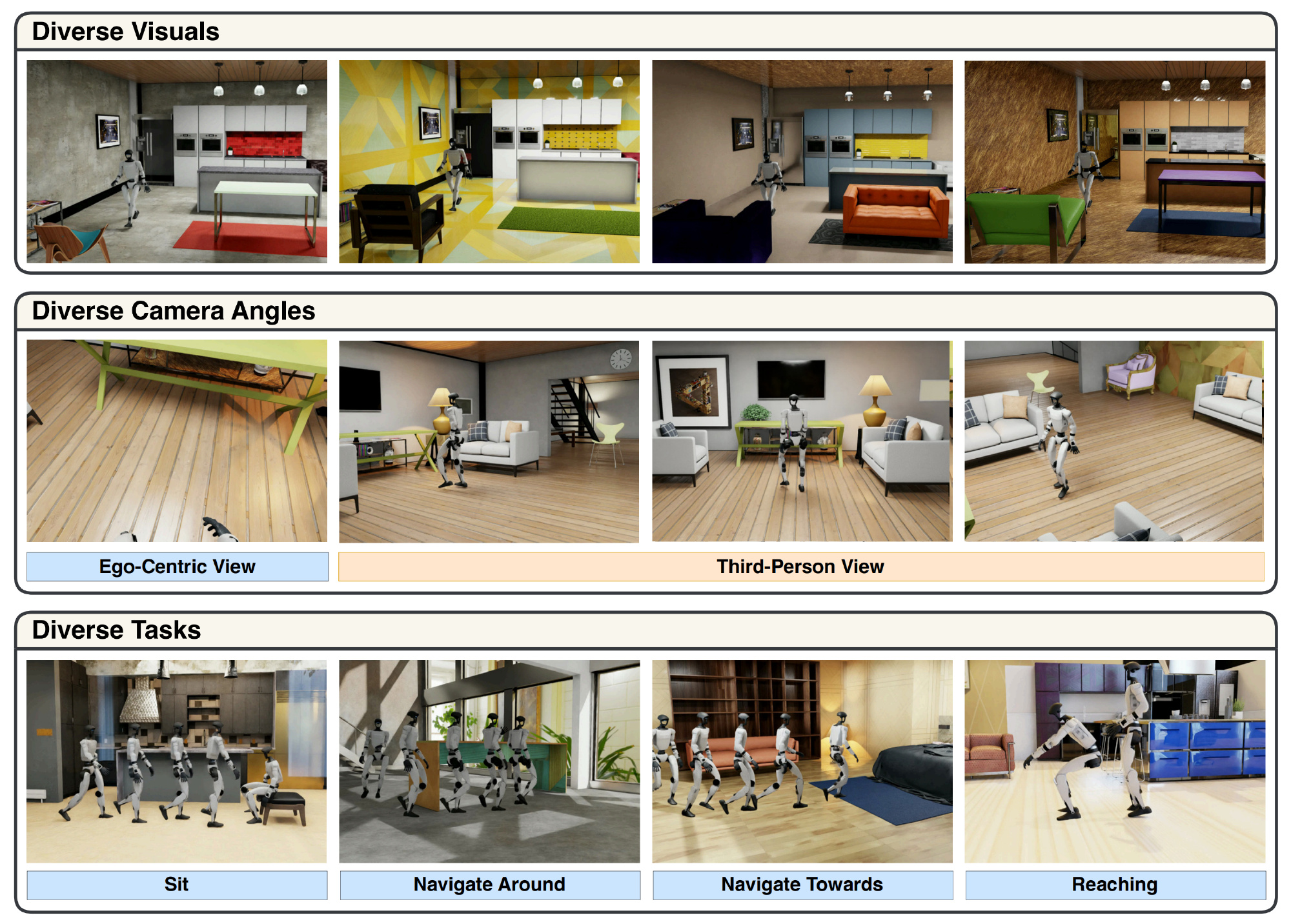
他们高效的合成数据生成流程的主要创新在于,在仿真环境中重放重定向的动作捕捉(MoCap)动作,从而收集具有照片级真实感的回放数据。这带来了三大优势:
- 无需在数据采集过程中依赖可靠的动态控制
- 仅用运动学姿态即可为视觉-语言理解提供足够的任务级语义信息
- 支持未来利用来自互联网视频等来源的重定向人形数据
尽管存在一些细微的伪影,但只采用运动学渲染并结合高质量的低层策略实现闭环控制,已足够满足需求。且他们在IsaacSim中使用光线追踪渲染来生成数据。这种方法能够更准确地模拟场景中的光照和阴影,从而缓解以往由于不真实光照带来的仿真到现实差距
为了利用少量运动学运动轨迹生成具有语言指令的多样化视觉场景,作者采用了程序化生成流程,对每次执行进行扩展和随机化
- 具体而言,作者对场景背景、物体属性、任务设置、摄像机视角进行随机化,并对执行过程进行镜像,以确保数据的多样性和语义丰富性
- 随后,通过人工或使用VLM[24]为其标注以第一人称视角的文本指令。详细的工作流程见附录A
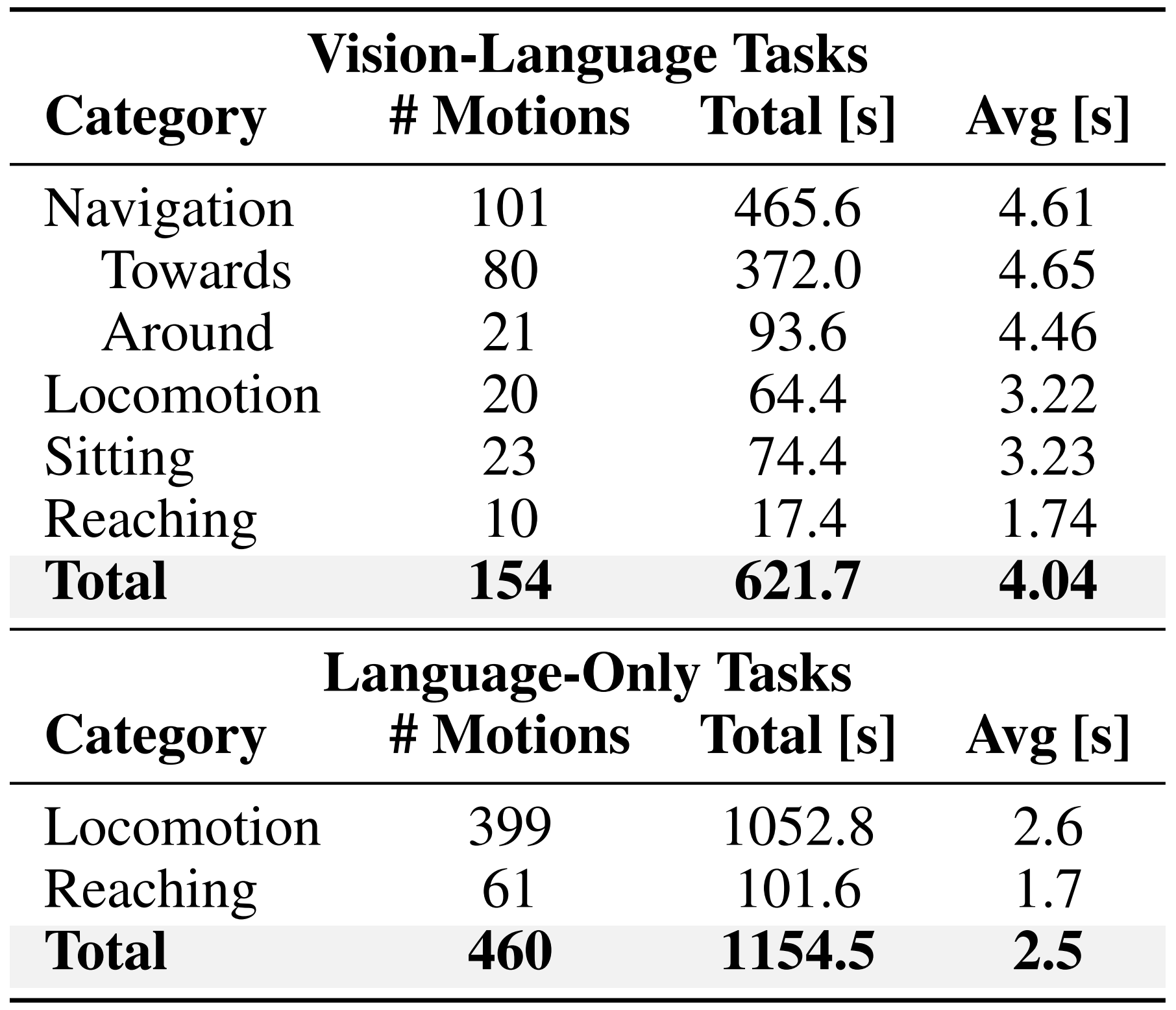
通过对154条轨迹各自随机化100次,作者共生成了17.1小时的高真实感运动回放。表1总结了其中不同任务的混合情况
- 每个演示包含图像
,一条文本指令
,以及机器人运动学状态
- 为了进一步提升数据多样性,作者使用视觉语言模型(VLM)对仅包含文本的动作对进行标注,而无需进行真实感渲染
总体上,作者通过增加2.7小时仅含语言的数据,扩展了视觉-语言数据集,涵盖了500条多样化的轨迹。且为了解决缺乏视觉输入的问题,作者在文本中注入空间提示(例如“左侧的红色椅子”),以保留消歧义的上下文信息
1.2 双重处理下的人形控制
本系统的数据收集与训练流程细节如下
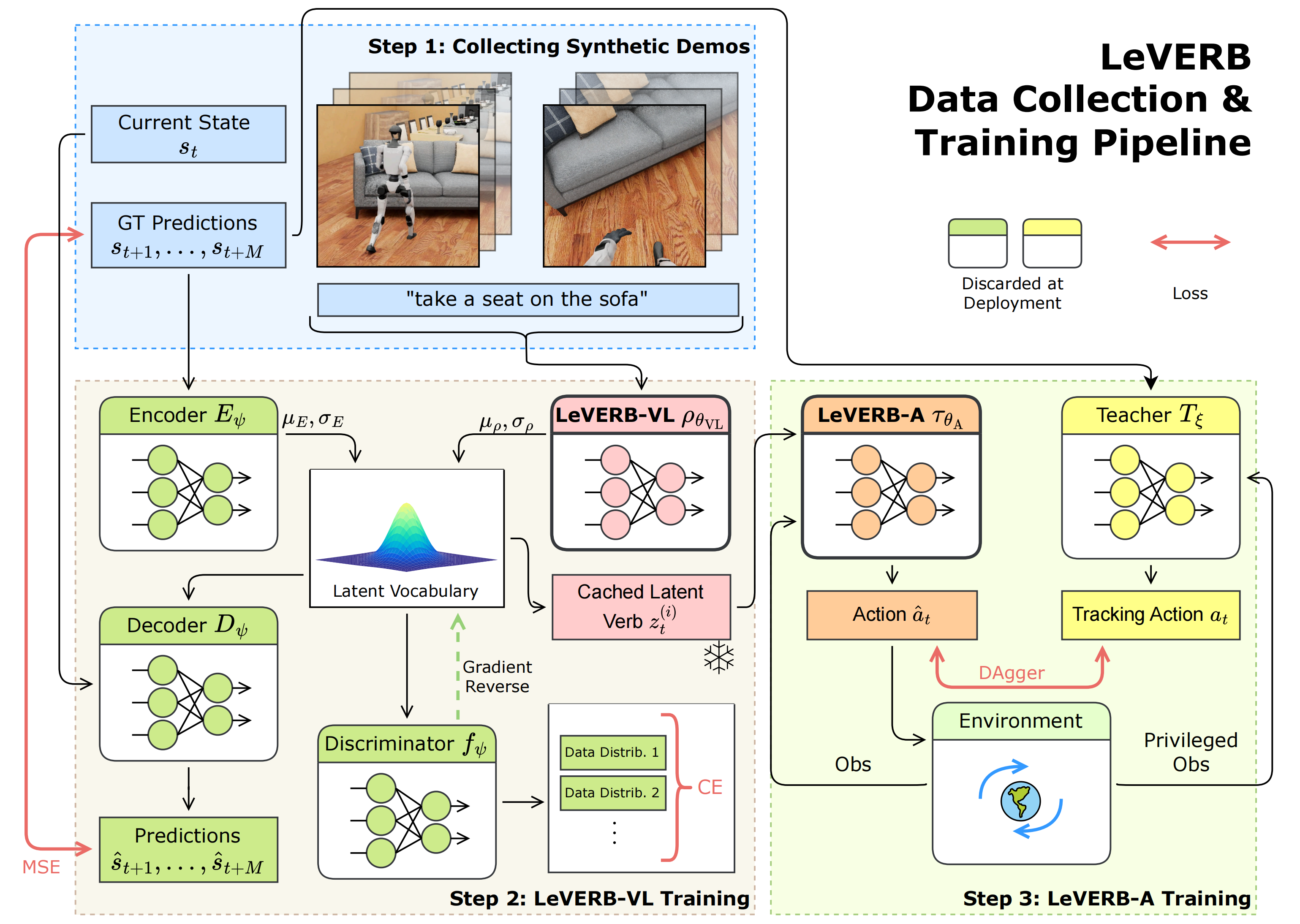
- 步骤1:在IsaacSim中收集一个合成的、逼真的动作重定向数据集,并用文本指令进行标注
- 步骤2:通过运动轨迹重建任务训练LeVERB-VL,获得一个正则化的潜在动词词汇表,并为数据集中每一次rollout缓存对应的潜在动词
- 步骤3:使用
来对 LeVERB-A 进行条件化。它是通过 DAgger 方法从教师跟踪策略
蒸馏得到的,该策略接收与潜在动词意图相对应的未来参考指令
1.2.0 总体模型层次结构:解耦视觉-语言与动作
将基于视觉-语言的 WBC 策略表述为
- 其中
是动力学层级的动作
是观测值
其中表示本体感受传感器读数,
表示来自第一人称视角和随机第三人称摄像头的视觉输入,以及文本指令
形式上,他们的分层system-1-system-2策略在推理时被表述为
其中,
表示高级系统2,用于处理视觉-语言指令和闭环视觉反馈,作者称之为LeVERB-VL,而
表示低级系统1 动作策略,作者称之为LeVERB-A。
和
是对应于这两个模型的策略参数
一个潜在向量作为LeVERB-VL到LeVERB-A之间的单向接口,并且是LeVERB-VL训练的核心
直观来看,的潜在空间是一种描述性词汇,用于编码复杂的全身运动目标,而
则是从该词汇中采样得到的潜在变量。LeVERB-VL以10 Hz运行,而LeVERB-A以50 Hz输出关节位置动作
这种将视觉-语言与动力学层级动作信息解耦的方法,使得两个系统可以分别训练,从而避免了端到端方法中对图形渲染所需的大量计算
1.2.1 LeVERB-VL 训练:视觉-语言-动作语义对齐
LeVERB-VL 的目标是将视觉和语言输入映射到一个平滑且正则化的运动控制潜在词汇空间
- 为此,作者采用残差条件变分自编码器(residual CVAE),其中仅包含视觉-语言输入的 VLA 先验的潜变量与特权轨迹编码器结合,形成一个残差潜在空间
- 这种方式促使 VLA 专注于语义推理,同时将运动相关的细节交由轨迹编码器处理。组合后的潜变量用于采样,并为解码器提供条件,以根据当前状态 st 预测未来姿态 ˆst+1, ...,ˆst+M
- 最后,引入判别器,将来自不同来源的数据对齐到统一的潜在空间中
第一,LeVERB-VL ρθVL。VLA 先验由三个模块组成:视觉编码器、文本编码器和一个标准的Transformer [47] 主干网络
- 对于视觉编码器,作者采用了SigLiP [51, 2] 的视觉组件。由于视觉编码器和文本编码器经过对比预训练,得到的嵌入在语义上是对齐的,这有助于实现高效的多模态融合
在训练过程中,来自两个视角的图像:第一人称视角(头戴式)和第三人称视角,分别由冻结的ViT-B/16 SigLiP 视觉编码器独立处理
最终的图像token 通过注意力池化,分别生成图像token和
。视觉编码器在WebLI [8] 上进行了预训练,并在整个训练过程中保持冻结
- 文本编码器同样来自SigLiP 模型,将文本指令转换为语言token
。这些token 被拼接,形成Transformer 主干网络的输入序列:
其中,t 表示当前时间步;且仅使用当前帧的观测数据,不包含任何时间历史,以降低过拟合的风险[25,32]
序列随后被送入Transformer 和后续的MLP 头部,以预测观测分布,该分布由均值
和方差
参数化
- 作者在附录B 中对主干Transformer 模型的规模进行了消融分析
第二,运动学编码器Eψ
由于LeVERB-VL仅能观测当前的视觉-语言输入,作者引入了一个运动学编码器,用于捕捉来自未来状态的额外信息。该编码器是一个多层感知机MLP,它将展平后的真实未来状态作为输入,并预测潜在分布的均值
和方差
第三,残差潜在空间
受运动生成方法[26]的启发,作者将潜在分布构建为,其中均值为动作编码器与LeVERB-VL 的残差连接
。方差直接取自动作编码器:
这种设置允许编码器提供额外的细粒度信息以辅助重建,使VLA 能够更多地关注语义。在该后验分布上施加KL 损失,以确保编码器仅捕获那些无法从视觉-语言输入中推断的信息
且在训练过程中,应用标准的重参数化技巧对进行采样,其中
第四,运动学解码器Dψ
从后验分布中采样得到的潜变量 和当前状态
被输入到该MLP 中,以重建未来状态
第五,判别器
为了利用LeVERB-Bench 中的视觉-语言和仅语言轨迹,作者在System 2 训练期间混合这两种数据来源,通过向LeVERB-VL 输入白噪声图像来处理” 盲” 轨迹。然而,这会在” 盲” 与” 非盲” 输入的潜在嵌入之间引入分布偏移,从而影响泛化能力
为了对齐潜在空间并鼓励共享表征,作者引入了受[34] 启发的判别器,该判别器以潜在变量 为输入,并预测实际图像是否存在
且在训练过程中应用梯度反转层GRL[13],使对抗性学习促使LeVERB-VL 生成与模态无关的潜在表示,无论图像是否可用
第六,训练目标
最终训练目标由三个部分组成:轨迹重建、分布对齐和对抗分类。完整的目标函数为
这里,是动作条件后验分布,
是来自LeVERB-VL 的观测条件先验分布。作者在附录B 中包含了数据混合策略、数据处理流程、超参数选择和训练方案
1.2.2 LeVERB-A 训练:通过学习的潜在分布蒸馏动作
在训练 LeVERB-VL 后,作者冻结其潜在空间,并通过首先学习与视觉-语言无关的教师模型,然后对基于transformer的学生策略进行蒸馏(该策略以 LeVERB-VL 的潜在分布为条件),来训练 LeVERB-A
- 训练教师
首先,训练视觉-语言无关的教师策略,能够准确跟踪来自LeVERB-Bench 的不同类别的重定向运动学轨迹。该策略接收特权本体感受观测和参考动作作为指令,并输出专家动作at
且使用近端策略优化(Proximal Policy Optimization,PPO)[40] 训练教师,并应用领域随机化以实现零样本仿真到现实的迁移,同时采用提前终止以辅助训练。教师策略的全部细节见附录D - LeVERB-A
接下来,从多个教师策略中提炼高质量的动作,将其整合到一个统一的学生策略中,该学生策略以LeVERB-VL 生成的潜在指令为条件
在每个回合开始时,作者从 LeVERB-VL 的训练集中采样一个运动轨迹,并提取潜在分布的均值和方差(和
)
随机选择一个时间步作为该回合的起始点。每隔 H 步,与 System 1-2 的重采样间隔一致,作者从预测分布中采样一个潜在编码
,并将其保持不变,直到下次重采样
需要注意的是,作者是从潜在分布中采样,而不是直接使用均值
LeVERB-A 使用一个Transformer,将观测值和潜在编码
作为独立的token 输入。其通过DAgger [39] 方法进行训练,采用Huber 损失函数对比教师的动作
,这种方式对异常值具有更好的鲁棒性
且每个回合在参考轨迹结束时终止,提前终止的标准与教师训练中所用标准一致,以确保教师保持在其训练分布内。在部署时,LeVERB-A 以LeVERB-VL预测的均值 为条件。更多细节见附录E
// 待更

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)