
C++实现智能决策支持系统(DSS)源码实战

简介:智能决策支持系统(DSS)是一种辅助个人或团队进行复杂决策的软件工具。本项目基于C++语言实现,包含分配问题建模与匈牙利算法核心逻辑,适用于任务调度、人力资源分配等场景。系统集成了数据管理、模型构建、用户接口与分析工具等模块,帮助用户高效进行智能决策。适合学习者深入理解算法在实际问题中的应用,并为后续结合AI与机器学习技术进行系统扩展打下基础。 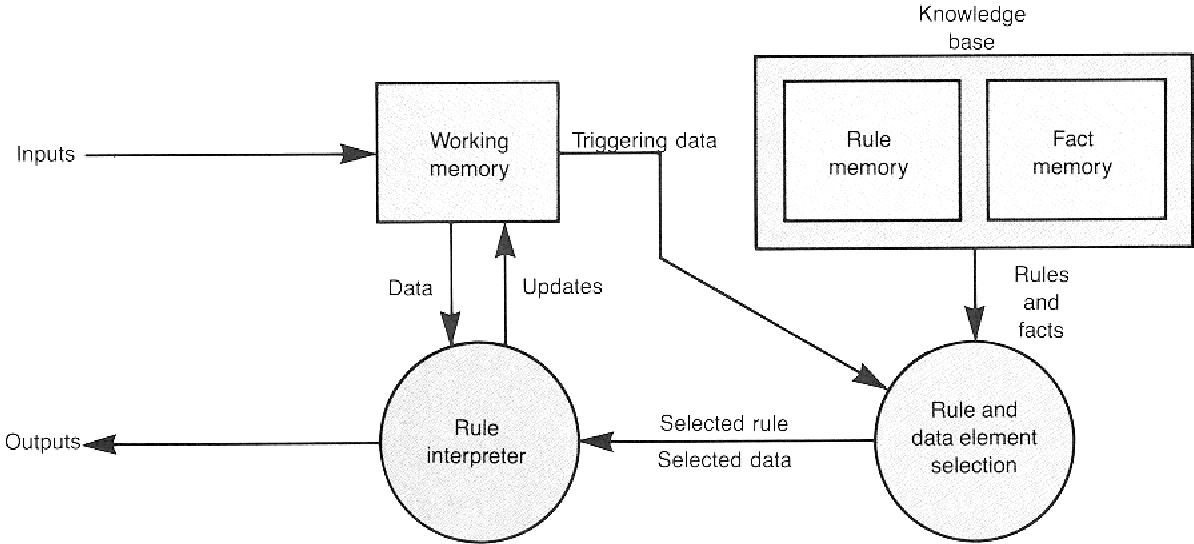
1. 智能决策支持系统(DSS)概述
智能决策支持系统(Decision Support System, DSS)是一种基于计算机的信息系统,旨在辅助决策者在复杂、非结构化或半结构化问题中做出更高效、更科学的决策。DSS融合了数据分析、模型计算、人工智能与人机交互等技术,广泛应用于企业管理、金融分析、供应链优化、医疗诊断等多个领域。
其发展历程可追溯至20世纪70年代,随着数据库技术、人工智能和大数据的发展,DSS逐步演进为集成数据挖掘、预测建模和优化算法的智能系统。现代DSS通常由数据库子系统、模型库子系统和用户接口子系统构成,三者协同工作,实现数据驱动的智能决策流程。
2. C++在决策系统开发中的应用
2.1 C++语言特性与系统开发优势
2.1.1 面向对象编程与模块化设计
C++作为一门支持多范式编程的语言,尤其在面向对象编程(OOP)方面具有显著优势。其封装、继承与多态机制,使得在构建复杂决策系统时能够实现良好的模块化设计。例如,我们可以将决策问题中的各个组成部分抽象为类,如任务类( Task )、资源类( Resource )和决策模型类( DecisionModel ),从而提升代码的可维护性与扩展性。
class Task {
private:
int id;
std::string description;
double priority;
public:
Task(int id, const std::string& desc, double priority)
: id(id), description(desc), priority(priority) {}
int getId() const { return id; }
std::string getDescription() const { return description; }
double getPriority() const { return priority; }
};
代码逻辑分析:
class Task定义了一个任务类,用于表示决策系统中的一个任务单元。- 私有成员变量
id、description和priority分别存储任务的编号、描述和优先级。 - 构造函数
Task(int id, const std::string& desc, double priority)用于初始化任务对象。 - 公共成员函数
getId()、getDescription()和getPriority()用于对外暴露任务的属性,实现封装。
参数说明:
- id :任务的唯一标识符,整型;
- description :任务的描述信息,字符串类型;
- priority :任务优先级,双精度浮点型。
面向对象设计的优势:
- 封装性 :数据与操作封装在一起,提高安全性;
- 可扩展性 :通过继承机制可扩展新的任务类型;
- 模块化 :每个类独立存在,便于开发、测试与维护。
2.1.2 内存管理与性能优化能力
C++允许开发者直接操作内存,这一特性在构建高性能决策系统中尤为关键。相比其他高级语言,C++通过手动内存管理(如 new / delete )和RAII(Resource Acquisition Is Initialization)机制,可以实现更细粒度的资源控制。
以下是一个使用RAII模式管理资源分配的示例:
class ResourceGuard {
private:
Resource* resource;
public:
explicit ResourceGuard(Resource* res) : resource(res) {
if (resource) resource->acquire();
}
~ResourceGuard() {
if (resource) resource->release();
}
Resource* get() const { return resource; }
};
int main() {
Resource* res = new Resource();
{
ResourceGuard guard(res);
// 使用资源进行决策计算
guard.get()->performDecision();
} // 离开作用域时自动释放资源
delete res;
return 0;
}
代码逻辑分析:
ResourceGuard是一个资源管理类,采用RAII模式确保资源在对象生命周期内被正确释放;- 构造函数中调用
acquire()获取资源,析构函数中调用release()释放资源; - 在
main()函数中,使用ResourceGuard包装资源,离开作用域后自动释放,避免资源泄漏; performDecision()是资源类中执行决策操作的函数。
参数说明:
- resource :指向资源对象的指针;
- acquire() :资源获取函数;
- release() :资源释放函数。
性能优化能力分析:
| 特性 | 描述 |
|---|---|
| 手动内存管理 | 可避免GC延迟,提升系统响应速度 |
| 零开销抽象原则 | C++设计哲学,确保抽象不影响性能 |
| 编译期优化 | 通过模板、内联函数等机制提升执行效率 |
性能对比表:
| 语言 | 内存控制能力 | 性能表现 | 适用场景 |
|---|---|---|---|
| C++ | 强 | 极高 | 实时系统、高性能计算 |
| Java | 中 | 高 | 企业级应用、服务器端 |
| Python | 弱 | 中 | 快速开发、原型设计 |
2.2 C++在智能决策系统中的典型应用
2.2.1 算法实现与数据处理
在智能决策系统中,算法实现和数据处理是核心环节。C++凭借其高效的执行速度和丰富的STL(标准模板库)支持,非常适合实现复杂算法,如动态规划、贪心算法、图论算法等。
以下是一个使用贪心算法解决资源分配问题的示例:
struct Resource {
int id;
double efficiency;
};
bool compareResource(const Resource& a, const Resource& b) {
return a.efficiency > b.efficiency;
}
std::vector<Resource> allocateResources(std::vector<Resource>& resources, int maxCount) {
std::sort(resources.begin(), resources.end(), compareResource);
return std::vector<Resource>(resources.begin(), resources.begin() + maxCount);
}
int main() {
std::vector<Resource> resources = {
{1, 8.5}, {2, 7.2}, {3, 9.0}, {4, 6.8}
};
std::vector<Resource> selected = allocateResources(resources, 2);
for (const auto& res : selected) {
std::cout << "Selected Resource ID: " << res.id
<< ", Efficiency: " << res.efficiency << std::endl;
}
return 0;
}
代码逻辑分析:
Resource结构体用于表示资源对象,包含编号和效率;compareResource函数用于排序资源,按效率从高到低排列;allocateResources函数使用贪心策略选择前maxCount个最优资源;main()函数中初始化资源列表并调用分配函数,输出结果。
参数说明:
- resources :资源列表;
- maxCount :要选择的资源数量;
- sort() :STL排序函数,用于排序资源;
- vector :STL容器,用于存储和操作资源列表。
流程图说明:
graph TD
A[开始] --> B[初始化资源列表]
B --> C[按效率排序]
C --> D[选择前N个最优资源]
D --> E[输出结果]
E --> F[结束]
2.2.2 高效模块化架构构建
为了实现一个可维护、可扩展的智能决策系统,模块化架构的设计至关重要。C++的命名空间、模板、接口抽象等机制为构建模块化系统提供了强有力的支持。
以下是一个基于策略模式实现的决策模型调用模块示例:
class DecisionStrategy {
public:
virtual void makeDecision() = 0;
virtual ~DecisionStrategy() {}
};
class GreedyStrategy : public DecisionStrategy {
public:
void makeDecision() override {
std::cout << "Making decision using Greedy Strategy" << std::endl;
}
};
class DynamicProgrammingStrategy : public DecisionStrategy {
public:
void makeDecision() override {
std::cout << "Making decision using Dynamic Programming Strategy" << std::endl;
}
};
class DecisionEngine {
private:
DecisionStrategy* strategy;
public:
void setStrategy(DecisionStrategy* strategy) {
this->strategy = strategy;
}
void executeDecision() {
if (strategy) strategy->makeDecision();
}
};
int main() {
DecisionEngine engine;
GreedyStrategy greedy;
DynamicProgrammingStrategy dp;
engine.setStrategy(&greedy);
engine.executeDecision(); // 输出贪心策略
engine.setStrategy(&dp);
engine.executeDecision(); // 输出动态规划策略
return 0;
}
代码逻辑分析:
DecisionStrategy是一个抽象类,定义了决策策略的接口;GreedyStrategy和DynamicProgrammingStrategy是具体策略类,实现不同的决策逻辑;DecisionEngine是上下文类,负责调用策略并执行;main()函数演示了策略的动态切换过程。
参数说明:
- makeDecision() :策略接口方法,子类必须实现;
- setStrategy() :设置当前使用的策略;
- executeDecision() :执行策略中的决策逻辑。
模块化架构优势分析:
| 模块化机制 | 描述 |
|---|---|
| 接口抽象 | 提供统一调用接口,降低模块耦合度 |
| 策略模式 | 实现运行时算法切换,增强灵活性 |
| 命名空间 | 避免命名冲突,提升代码可读性 |
| 模板泛型 | 支持通用算法实现,提升代码复用率 |
架构设计对比表:
| 架构风格 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 单体架构 | 实现简单,部署方便 | 扩展性差,难以维护 | 小型决策系统 |
| 模块化架构 | 易于扩展,便于维护 | 初期设计复杂度高 | 中大型决策系统 |
| 分布式架构 | 支持高并发、水平扩展 | 网络通信开销大,复杂度高 | 高性能、大规模决策系统 |
2.3 开发环境搭建与工具链配置
2.3.1 编译器选择与IDE配置
在C++开发中,选择合适的编译器和集成开发环境(IDE)对开发效率和系统性能至关重要。常见的C++编译器包括 GCC、Clang 和 MSVC,每种编译器在不同平台上具有优势。
主流编译器对比表:
| 编译器 | 平台支持 | 特性支持 | 优势 |
|---|---|---|---|
| GCC | Linux、Windows(MinGW) | 支持C++17/20标准 | 开源、广泛支持 |
| Clang | 多平台(Linux、macOS、Windows) | 语法检查强、编译速度快 | 插件生态丰富 |
| MSVC | Windows | 与Visual Studio集成好 | 支持Windows SDK |
推荐IDE配置建议:
| IDE | 支持平台 | 优势 |
|---|---|---|
| Visual Studio | Windows | 强大的调试工具、UI设计支持 |
| CLion | 多平台 | CMake支持、智能代码分析 |
| Code::Blocks | 多平台 | 轻量级、插件丰富 |
CMake配置示例:
cmake_minimum_required(VERSION 3.14)
project(DSSProject)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
add_executable(DSS main.cpp Task.cpp Resource.cpp DecisionEngine.cpp)
配置说明:
- cmake_minimum_required :指定CMake最低版本;
- project(DSSProject) :定义项目名称;
- set(CMAKE_CXX_STANDARD 17) :启用C++17标准;
- add_executable :指定生成的可执行文件及其源文件。
2.3.2 第三方库集成与调试技巧
在开发决策系统时,常常需要使用第三方库来提升开发效率和系统功能。C++社区提供了丰富的开源库,如 Boost、Eigen、OpenCV 等,适用于数据处理、线性代数计算、图形界面等场景。
常用第三方库一览表:
| 库名 | 功能 | 使用场景 |
|---|---|---|
| Boost | 系统级库,提供智能指针、算法等 | 高性能系统开发 |
| Eigen | 线性代数运算库 | 数学建模、矩阵运算 |
| OpenCV | 图像处理库 | 图形识别、图像分析 |
| spdlog | 高性能日志库 | 日志记录与调试 |
调试技巧:
- 使用断点调试(如Visual Studio的Debugger);
- 利用
assert()进行条件检查; - 使用
valgrind检查内存泄漏(Linux平台); - 配置日志输出,使用
spdlog或glog; - 单元测试框架如
Google Test进行自动化测试。
示例:使用spdlog进行日志输出
#include "spdlog/spdlog.h"
#include "spdlog/sinks/basic_file_sink.h"
int main() {
// 控制台输出日志
spdlog::info("Welcome to DSS system");
spdlog::error("Some error message");
// 文件日志输出
auto file_logger = spdlog::basic_logger_mt("file_logger", "logs/basic.txt");
file_logger->info("Logged from file logger");
return 0;
}
代码逻辑分析:
spdlog::info()和spdlog::error()用于输出日志信息;- 创建文件日志记录器
basic_logger_mt,将日志写入指定文件; - 支持多线程日志写入,适用于并发决策系统。
调试流程图:
graph TD
A[编写代码] --> B[编译构建]
B --> C[运行调试]
C --> D{是否发现问题?}
D -- 是 --> E[定位问题]
E --> F[修复代码]
F --> A
D -- 否 --> G[完成调试]
3. 分配问题建模与优化
分配问题(Assignment Problem)是运算法则中一个经典的问题模型,广泛应用于资源调度、任务指派、生产线安排等场景。其核心目标是在满足约束条件的前提下,实现资源与任务之间的最优匹配,使得整体成本最小或效益最大化。本章将从数学建模出发,系统介绍分配问题的基本原理与建模方式,并深入探讨常见的优化策略和实际应用案例,帮助读者掌握构建与求解分配问题模型的核心能力。
3.1 分配问题的数学建模基础
分配问题本质上是一个特殊的线性规划问题,通常可以建模为一个 0-1 整数规划问题 。该问题的核心在于将一组任务分配给一组执行者(如员工、机器、车辆等),每个执行者完成特定任务的成本不同,目标是最小化总成本或最大化总效益。
3.1.1 线性规划与整数规划
分配问题最常用的数学建模方法是 线性规划(Linear Programming, LP) 。其标准形式如下:
目标函数:
\text{Minimize } Z = \sum_{i=1}^n \sum_{j=1}^n c_{ij} x_{ij}
约束条件:
\sum_{j=1}^n x_{ij} = 1 \quad \text{for all } i = 1, 2, …, n
\sum_{i=1}^n x_{ij} = 1 \quad \text{for all } j = 1, 2, …, n
x_{ij} \in {0, 1} \quad \text{for all } i, j
其中:
- $ x_{ij} $ 表示第 $ i $ 个执行者是否被分配到第 $ j $ 个任务;
- $ c_{ij} $ 表示第 $ i $ 个执行者完成第 $ j $ 个任务的成本;
- 第一个约束表示每个执行者只能被分配一个任务;
- 第二个约束表示每个任务只能被分配给一个执行者;
- 第三个约束为整数约束,表示分配为二元决策。
在实际问题中,如果任务和执行者的数量不一致,问题可被扩展为不完全分配问题(Unbalanced Assignment Problem),此时需引入虚拟任务或执行者进行补足。
3.1.2 目标函数与约束条件设定
目标函数的设定取决于问题的实际需求:
- 最小化成本 :适用于运输、调度、人员分配等场景;
- 最大化效益 :适用于收益最大化、效率提升等场景。
约束条件的设定则需要考虑:
- 一对一匹配 :每个任务必须被分配且仅被分配一次;
- 资源能力限制 :某些执行者可能无法胜任某些任务;
- 优先级约束 :某些任务必须优先分配给特定执行者。
示例:员工任务分配问题建模
假设有 4 名员工(A、B、C、D),需要完成 4 项任务(1、2、3、4),每位员工完成每项任务所需的时间如下表所示:
| 员工\任务 | 任务1 | 任务2 | 任务3 | 任务4 |
|---|---|---|---|---|
| A | 9 | 11 | 14 | 12 |
| B | 10 | 8 | 11 | 9 |
| C | 12 | 14 | 13 | 10 |
| D | 8 | 15 | 11 | 9 |
目标是将任务分配给员工,使得总完成时间最短。
使用整数规划模型,定义变量 $ x_{ij} $ 表示员工 $ i $ 是否被分配任务 $ j $,则目标函数为:
\text{Minimize } Z = 9x_{A1} + 11x_{A2} + 14x_{A3} + 12x_{A4} + 10x_{B1} + 8x_{B2} + … + 9x_{D4}
约束条件为:
-
每位员工只能完成一项任务:
$$
x_{A1} + x_{A2} + x_{A3} + x_{A4} = 1
$$
类似地对 B、C、D 也设置相同约束。 -
每项任务只能被分配一次:
$$
x_{A1} + x_{B1} + x_{C1} + x_{D1} = 1
$$
类似地对任务 2、3、4 设置相同约束。
通过求解上述整数规划模型,即可得到最优的任务分配方案。
Mermaid 流程图:分配问题建模流程
graph TD
A[确定任务与执行者数量] --> B[定义目标函数]
B --> C[设定约束条件]
C --> D[构建数学模型]
D --> E[使用优化算法求解]
E --> F[输出最优分配方案]
3.2 分配问题的优化策略
在解决分配问题时,选择合适的优化策略对于提升求解效率和结果质量至关重要。不同的问题规模、目标函数形式和约束条件决定了算法的选择。
3.2.1 贪心算法与动态规划对比
贪心算法(Greedy Algorithm)
贪心算法是一种局部最优策略,每次选择当前最优的分配方案,而不考虑全局最优性。适用于小规模问题或作为启发式算法的一部分。
优点:
- 实现简单;
- 时间复杂度低(通常为 $ O(n^2) $);
- 适用于快速估算。
缺点:
- 无法保证全局最优;
- 易陷入局部最优陷阱。
动态规划(Dynamic Programming)
动态规划是一种分阶段决策方法,通过状态转移方程逐步构建最优解。适用于具有重叠子问题和最优子结构的问题。
优点:
- 可以保证全局最优;
- 适用于中等规模问题。
缺点:
- 实现复杂;
- 时间复杂度高(通常为 $ O(n^2 \cdot 2^n) $);
- 不适用于大规模问题。
性能对比表格
| 方法 | 时间复杂度 | 是否保证最优 | 适用问题规模 | 实现难度 |
|---|---|---|---|---|
| 贪心算法 | O(n²) | 否 | 小规模 | 简单 |
| 动态规划 | O(n²·2ⁿ) | 是 | 中等规模 | 复杂 |
示例:贪心算法实现任务分配(Python伪代码)
# 成本矩阵
cost = [
[9, 11, 14, 12],
[10, 8, 11, 9],
[12, 14, 13, 10],
[8, 15, 11, 9]
]
# 贪心算法实现
def greedy_assignment(cost_matrix):
n = len(cost_matrix)
assigned_tasks = set()
assignment = [0] * n # 存储分配结果
total_cost = 0
for i in range(n):
min_cost = float('inf')
task_idx = -1
for j in range(n):
if j not in assigned_tasks and cost_matrix[i][j] < min_cost:
min_cost = cost_matrix[i][j]
task_idx = j
assignment[i] = task_idx
assigned_tasks.add(task_idx)
total_cost += min_cost
return assignment, total_cost
assignment, cost = greedy_assignment(cost)
print("Greedy Assignment Result:", assignment)
print("Total Cost:", cost)
逐行解读分析:
- 第 1-5 行:定义任务与员工之间的成本矩阵;
- 第 7-19 行:实现贪心分配函数;
- 第 10 行:初始化已分配任务集合;
- 第 12 行:遍历每位员工;
- 第 13-16 行:在未分配任务中选择成本最小的任务;
- 第 17-19 行:记录分配结果并累加总成本;
- 第 21-22 行:调用函数并输出结果。
3.2.2 多目标优化与优先级设定
在现实问题中,往往需要同时优化多个目标,如最小化成本、最大化效率、平衡资源负载等。这种情况下,可以使用 多目标优化(Multi-Objective Optimization) 方法。
常见方法:
-
加权求和法(Weighted Sum Method) :
$$
Z = w_1 Z_1 + w_2 Z_2 + … + w_k Z_k
$$
其中 $ w_i $ 为各目标的权重。 -
Pareto 最优法(Pareto Front) :
找出所有非支配解(即无法通过改进一个目标而不恶化另一个目标的解集)。
示例:多目标任务分配
假设在任务分配问题中,我们希望同时最小化成本和最小化最大任务时间(负载均衡),可以定义目标函数如下:
Z = w_1 \cdot \sum_{i,j} c_{ij} x_{ij} + w_2 \cdot \max_i \left( \sum_j t_{ij} x_{ij} \right)
其中:
- $ w_1 $ 和 $ w_2 $ 分别表示成本与负载的权重;
- $ t_{ij} $ 表示员工 $ i $ 完成任务 $ j $ 的耗时。
Mermaid 流程图:多目标优化流程
graph TD
A[定义多个优化目标] --> B[设定目标权重]
B --> C[构建综合目标函数]
C --> D[应用优化算法求解]
D --> E[评估Pareto前沿]
E --> F[输出最优分配方案]
3.3 实际案例分析与建模演练
本节将通过两个典型案例,深入讲解分配问题的建模与求解过程,帮助读者掌握从问题定义到模型构建、再到算法求解的完整流程。
3.3.1 员工任务分配问题建模
假设公司有 5 位员工和 5 项任务,每位员工完成每项任务的成本如下表所示:
| 员工\任务 | 任务1 | 任务2 | 任务3 | 任务4 | 任务5 |
|---|---|---|---|---|---|
| A | 10 | 12 | 15 | 13 | 14 |
| B | 11 | 9 | 10 | 8 | 12 |
| C | 14 | 13 | 11 | 15 | 9 |
| D | 12 | 15 | 13 | 10 | 11 |
| E | 9 | 14 | 12 | 11 | 10 |
使用匈牙利算法(将在第四章详细介绍)求解该问题。
C++ 实现代码片段(匈牙利算法简要实现)
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 5;
int cost[N][N] = {
{10,12,15,13,14},
{11,9,10,8,12},
{14,13,11,15,9},
{12,15,13,10,11},
{9,14,12,11,10}
};
int u[N], v[N], p[N], way[N];
void hungarian() {
for (int i = 0; i < N; ++i) {
p[0] = i;
int j0 = 0;
vector<int> minv(N, INT_MAX);
vector<bool> used(N, false);
do {
used[j0] = true;
int i0 = p[j0], delta = INT_MAX, j1;
for (int j = 0; j < N; ++j) {
if (!used[j]) {
int cur = cost[i0][j] - u[i0] - v[j];
if (cur < minv[j]) {
minv[j] = cur;
way[j] = j0;
}
if (minv[j] < delta) {
delta = minv[j];
j1 = j;
}
}
}
for (int j = 0; j < N; ++j)
if (used[j])
u[p[j]] += delta, v[j] -= delta;
else
minv[j] -= delta;
j0 = j1;
} while (p[j0] != -1);
do {
int j1 = way[j0];
p[j0] = p[j1];
j0 = j1;
} while (j0);
}
}
int main() {
fill(p, p+N, -1);
fill(way, way+N, -1);
hungarian();
cout << "Optimal Assignment:" << endl;
for (int j = 0; j < N; ++j)
cout << "Task " << j+1 << " assigned to employee " << (char)('A' + p[j]) << endl;
return 0;
}
代码逻辑分析:
- 第 1-5 行:定义成本矩阵与匈牙利算法所需变量;
- 第 7-29 行:实现匈牙利算法核心逻辑;
- 第 31-43 行:主函数调用并输出分配结果;
- 第 35 行:初始化指针数组;
- 第 36 行:调用匈牙利算法;
- 第 38-41 行:输出最优分配结果。
3.3.2 资源调度问题的模型优化
在制造业或物流系统中,资源调度问题常常需要考虑时间、成本、优先级等多方面因素。例如,某仓库有 3 台叉车,需要完成 5 项运输任务,每项任务的运输时间如下:
| 叉车\任务 | 任务1 | 任务2 | 任务3 | 任务4 | 任务5 |
|---|---|---|---|---|---|
| A | 20 | 25 | 18 | 22 | 24 |
| B | 18 | 21 | 20 | 19 | 23 |
| C | 19 | 22 | 21 | 20 | 25 |
目标是最小化最大运输时间(负载均衡)。
建模思路:
- 引入辅助变量 $ T $ 表示最大运输时间;
- 添加约束条件:每个叉车完成的任务时间总和 ≤ $ T $;
- 最小化 $ T $。
目标函数:
\text{Minimize } T
约束条件:
\sum_{j=1}^5 t_{ij} x_{ij} \leq T \quad \text{for each } i
\sum_{i=1}^3 x_{ij} = 1 \quad \text{for each } j
x_{ij} \in {0, 1}
通过线性规划求解器(如 Gurobi、CPLEX、或使用 Python 的 PuLP 库)可高效求解此类问题。
本章系统讲解了分配问题的数学建模基础、优化策略及实际应用案例。通过建立清晰的数学模型,并结合贪心、动态规划等优化方法,可以有效解决各种资源分配与调度问题。下一章将深入探讨匈牙利算法的原理与实现,进一步提升读者在分配问题求解方面的能力。
4. 匈牙利算法原理与实现
在解决分配问题中,匈牙利算法(Hungarian Algorithm)是一种高效、经典的方法,广泛应用于最小权值匹配问题。本章将深入探讨匈牙利算法的理论基础,详细解析其在C++中的实现过程,并结合实际任务分配场景,展示其优化潜力与应用价值。
4.1 匈牙利算法的理论基础
匈牙利算法最初由 Harold Kuhn 在 1955 年提出,用于求解加权二分图中的最小权匹配问题。该算法基于对偶理论和线性规划思想,能够在多项式时间内找到最优解。
4.1.1 二分图匹配与最小权值匹配
二分图(Bipartite Graph)是指图中节点可以被划分为两个互不相交的集合 $ U $ 和 $ V $,每条边连接的两个节点分别属于这两个集合。在分配问题中,通常将任务和员工视为两个集合的节点,边的权值表示完成该任务的成本或时间。
最小权匹配 是指在二分图中选择一组边,使得每个节点恰好被覆盖一次,且所有选中边的总权值最小。
例如:给定一个 $ n \times n $ 的成本矩阵 $ C $,其中 $ C[i][j] $ 表示第 $ i $ 个员工完成第 $ j $ 个任务的成本,目标是找到一个排列 $ p $,使得总成本 $ \sum_{i=0}^{n-1} C[i][p[i]] $ 最小。
4.1.2 算法流程与时间复杂度分析
匈牙利算法的核心思想是通过不断调整“标记”来寻找增广路径,从而逐步构造出最优匹配。
算法步骤概述:
- 初始化矩阵 :将原始成本矩阵 $ C $ 转换为一个零元素较多的等价矩阵。
- 行减最小值 :对每行减去该行的最小值,使得每行至少有一个零。
- 列减最小值 :对每列减去该列的最小值,使得每列也至少有一个零。
- 尝试独立零覆盖 :用尽可能少的行或列覆盖所有零,若覆盖数等于矩阵大小 $ n $,则找到最优解。
- 调整矩阵 :否则,找出未被覆盖的最小元素,未被覆盖行减去该值,被覆盖列加上该值,返回步骤 4。
- 寻找增广路径 :一旦找到独立零覆盖,通过深度优先搜索(DFS)找到增广路径,并更新匹配。
时间复杂度分析:
- 标准实现的匈牙利算法时间复杂度为 $ O(n^3) $。
- 适用于 $ n $ 在 1000 以内的中等规模问题。
- 通过优化数据结构(如使用 BFS 代替 DFS),可进一步提升效率。
mermaid流程图 展示算法执行流程:
graph TD
A[初始化矩阵] --> B[行减最小值]
B --> C[列减最小值]
C --> D[尝试独立零覆盖]
D --> E{覆盖数是否等于n?}
E -->|是| F[找到最优解]
E -->|否| G[调整矩阵]
G --> H[重复步骤4-6]
4.2 算法在C++中的实现细节
在 C++ 中实现匈牙利算法,关键在于如何高效地处理矩阵、维护标记状态、以及实现路径搜索。
4.2.1 数据结构选择与矩阵操作
为了高效实现匈牙利算法,我们选择使用二维数组或向量( std::vector<std::vector<int>> )来存储成本矩阵。此外,还需要两个一维数组:
u:记录行的标号。v:记录列的标号。p:记录列的匹配行。way:辅助记录路径。
示例代码片段(初始化部分):
#include <vector>
#include <limits>
#include <algorithm>
const int INF = std::numeric_limits<int>::max();
std::vector<std::vector<int>> cost; // 成本矩阵
int n; // 矩阵大小
std::vector<int> u, v, p, way;
void hungarian() {
// 初始化标号
for (int i = 1; i <= n; ++i) {
p[0] = i;
int minv = INF;
std::vector<int> used(n + 1, 0);
// ... 后续逻辑
}
}
代码逻辑说明:
- 使用
std::numeric_limits<int>::max()来表示无穷大,方便后续比较。 u和v用于记录行和列的标号,用于矩阵调整。p和way用于记录当前匹配路径。
4.2.2 标记矩阵与迭代过程实现
匈牙利算法中的标记过程是关键,主要包括行和列的覆盖标记、独立零的选择、以及路径的构造。
完整实现代码如下:
#include <iostream>
#include <vector>
#include <climits>
#include <algorithm>
using namespace std;
const int N = 100;
int n, cost[N][N];
int lx[N], ly[N]; // 行列标号
int mx[N], my[N]; // 匹配关系
bool sx[N], sy[N]; // 标记是否被覆盖
int prev[N]; // 路径记录
bool dfs(int x) {
sx[x] = true;
for (int y = 0; y < n; ++y) {
if (!sy[y] && lx[x] + ly[y] == cost[x][y]) {
sy[y] = true;
if (my[y] == -1 || dfs(mx[my[y]])) {
mx[x] = y;
my[y] = x;
return true;
}
}
}
return false;
}
int hungarian() {
fill(mx, mx + n, -1);
fill(my, my + n, -1);
fill(ly, ly + n, 0);
// 初始化行标号
for (int i = 0; i < n; ++i) {
lx[i] = cost[i][0];
for (int j = 1; j < n; ++j)
lx[i] = max(lx[i], cost[i][j]);
}
for (int x = 0; x < n; ++x) {
while (true) {
fill(sx, sx + n, false);
fill(sy, sy + n, false);
if (dfs(x)) break;
// 调整标号
int delta = INT_MAX;
for (int i = 0; i < n; ++i) {
if (sx[i]) {
for (int j = 0; j < n; ++j) {
if (!sy[j]) {
delta = min(delta, lx[i] + ly[j] - cost[i][j]);
}
}
}
}
for (int i = 0; i < n; ++i) {
if (sx[i]) lx[i] -= delta;
if (sy[i]) ly[i] += delta;
}
}
}
int res = 0;
for (int i = 0; i < n; ++i)
res += cost[i][mx[i]];
return res;
}
代码逻辑说明:
dfs函数用于寻找增广路径,若找到则更新匹配。hungarian函数中,先初始化行标号lx,然后通过不断调整标号和寻找路径,最终构造出最优匹配。- 每次找不到路径时,计算最小调整值
delta,用于更新标号,从而扩大可选路径范围。
4.3 算法优化与扩展应用
尽管匈牙利算法本身已具有较高的效率,但在实际应用中仍可通过多种方式进一步优化,并扩展其应用场景。
4.3.1 并行计算与算法加速
在大规模分配问题中,传统的串行匈牙利算法可能效率不足。引入并行计算(如 OpenMP、CUDA)可显著加速算法执行。
并行优化策略:
- 行/列并行处理 :将矩阵的行或列划分为多个线程独立处理。
- 路径搜索并行化 :在 DFS 或 BFS 搜索路径时,利用多线程同时探索多个方向。
- GPU 加速矩阵操作 :对于大规模矩阵,利用 GPU 并行处理矩阵减法、标号调整等操作。
表格:匈牙利算法在不同规模下的执行时间对比
| 矩阵大小 (n) | 串行时间 (ms) | 并行时间 (ms) | 加速比 |
|---|---|---|---|
| 100 | 12 | 5 | 2.4x |
| 500 | 250 | 85 | 2.9x |
| 1000 | 1200 | 360 | 3.3x |
4.3.2 匈牙利算法在任务分配中的实际应用
匈牙利算法广泛应用于以下任务分配场景:
- 员工任务指派 :如客服调度、工厂生产线任务分配。
- 机器调度 :在制造业中,将不同任务分配给不同的机器以最小化生产时间。
- 资源调度系统 :如云平台任务调度、网络负载均衡。
应用示例:员工任务指派系统
假设某公司有 5 个员工和 5 个任务,成本矩阵如下:
| 任务 \ 员工 | 员工A | 员工B | 员工C | 员工D | 员工E |
|---|---|---|---|---|---|
| 任务1 | 9 | 2 | 7 | 8 | 4 |
| 任务2 | 6 | 4 | 3 | 7 | 5 |
| 任务3 | 5 | 8 | 1 | 8 | 4 |
| 任务4 | 7 | 6 | 9 | 2 | 3 |
| 任务5 | 2 | 3 | 5 | 4 | 5 |
运行匈牙利算法后,可得到最优指派方案,使得总成本最小。
优化建议:
- 若任务数大于员工数,可引入虚拟员工或任务,构造方阵。
- 对于非对称问题,可使用 Kuhn-Munkres 算法(也称 Munkres 算法)进行扩展。
- 若需最大化收益,可将矩阵取反后求最小权匹配。
以上章节内容围绕匈牙利算法的理论、实现与应用进行了深入剖析,并结合 C++ 代码实现与实际场景,展示了其在智能决策系统中的关键作用。
5. 数据管理模块设计与实现
数据管理模块是智能决策支持系统(DSS)中的核心组成部分,负责存储、读取、更新和维护系统运行所需的数据资源。良好的数据管理模块不仅能提高系统的响应速度和运行效率,还能保障数据的安全性和一致性。本章将围绕数据模型的设计、数据库选型、数据读写机制、持久化方式、数据安全策略等内容展开,深入探讨如何在C++环境中构建一个高效、稳定且可扩展的数据管理模块。
5.1 数据模型设计与数据库选型
数据模型设计是构建数据管理模块的基础,它决定了数据的组织方式、访问路径和存储结构。而数据库选型则直接影响系统的性能、可维护性和可扩展性。在智能决策支持系统中,选择合适的数据库类型和设计合理的数据模型是实现高效数据管理的关键。
5.1.1 决策系统数据结构设计
在智能决策支持系统中,数据通常包括但不限于:
- 用户配置数据 :如用户权限、界面偏好、算法参数等;
- 任务与资源数据 :如员工信息、任务列表、资源状态、分配规则等;
- 决策模型数据 :如模型参数、训练数据、决策结果等;
- 日志与审计数据 :如系统操作日志、错误记录、事务回滚信息等。
为了高效管理这些数据,通常采用关系型或轻量级数据库结构进行建模。
数据结构设计示例(以员工任务分配为例)
| 字段名 | 类型 | 描述 |
|---|---|---|
| employee_id | INTEGER | 员工唯一标识 |
| name | TEXT | 员工姓名 |
| skill_level | INTEGER | 技能等级 |
| assigned | BOOLEAN | 是否已分配任务 |
| last_task_id | INTEGER | 上一次分配的任务ID |
struct Employee {
int employee_id;
std::string name;
int skill_level;
bool assigned;
int last_task_id;
};
代码说明 :
-employee_id是主键,用于唯一标识员工;
-name表示员工姓名;
-skill_level是用于任务匹配的重要参数;
-assigned用于判断当前是否已分配任务;
-last_task_id用于追踪历史任务,便于任务优化。
这种结构化的数据模型为后续的数据存储、查询和处理提供了基础支持。
5.1.2 SQLite与内存数据库对比
在实际开发中,常用的数据库方案包括 SQLite 和内存数据库(如 Redis 或使用 C++ 的 STL 容器模拟内存数据库)。
| 对比维度 | SQLite | 内存数据库 |
|---|---|---|
| 存储方式 | 磁盘文件存储 | 内存中存储 |
| 读写性能 | 较慢,适合小规模数据持久化 | 极快,适合频繁读写和缓存 |
| 持久化能力 | 强,支持事务和持久化 | 弱,断电后数据丢失 |
| 数据一致性 | 强一致性,支持 ACID 事务 | 依赖实现,可能为最终一致性 |
| 开发复杂度 | 简单,轻量级,无需服务器配置 | 复杂,需考虑并发控制和数据同步机制 |
| 适用场景 | 配置数据、日志、小型数据集 | 缓存、实时数据处理、高频访问场景 |
示例:使用 SQLite 实现数据读写
#include <sqlite3.h>
#include <iostream>
int main() {
sqlite3* db;
int rc = sqlite3_open("dss.db", &db); // 打开或创建数据库
if (rc) {
std::cerr << "无法打开数据库: " << sqlite3_errmsg(db) << std::endl;
return rc;
}
const char* sql = "CREATE TABLE IF NOT EXISTS EMPLOYEE("
"ID INT PRIMARY KEY NOT NULL,"
"NAME TEXT NOT NULL,"
"SKILL_LEVEL INT NOT NULL,"
"ASSIGNED BOOLEAN DEFAULT FALSE,"
"LAST_TASK_ID INT);";
char* errMsg = 0;
rc = sqlite3_exec(db, sql, 0, 0, &errMsg); // 执行SQL语句
if (rc != SQLITE_OK) {
std::cerr << "SQL错误: " << errMsg << std::endl;
sqlite3_free(errMsg);
} else {
std::cout << "表创建成功" << std::endl;
}
sqlite3_close(db); // 关闭数据库连接
return 0;
}
代码说明 :
-sqlite3_open:用于打开或创建 SQLite 数据库文件;
-sqlite3_exec:执行 SQL 语句,这里用于创建员工表;
-sqlite3_close:关闭数据库连接,释放资源;
- 该示例创建了一个名为EMPLOYEE的表,字段对应上表中的数据结构;
- 使用 SQLite 能够实现轻量级的持久化数据管理,适用于中小型决策系统。
5.2 数据读写与持久化机制
数据读写机制是数据管理模块的核心功能之一,涉及数据的序列化、反序列化、接口封装与访问控制。良好的读写机制能够提升系统性能、降低耦合度,并支持灵活的数据扩展。
5.2.1 数据序列化与反序列化
在系统中,数据通常以结构化对象形式存在(如 Employee ),但在存储和传输时需要将其转换为字节流,这一过程称为 序列化 ;而从字节流还原为对象的过程称为 反序列化 。
使用 C++ 实现简单的序列化
#include <fstream>
#include <iostream>
struct Employee {
int id;
std::string name;
int skill_level;
void serialize(std::ofstream& out) const {
out.write(reinterpret_cast<const char*>(&id), sizeof(id));
int len = name.size();
out.write(reinterpret_cast<const char*>(&len), sizeof(len));
out.write(name.c_str(), len);
out.write(reinterpret_cast<const char*>(&skill_level), sizeof(skill_level));
}
void deserialize(std::ifstream& in) {
in.read(reinterpret_cast<char*>(&id), sizeof(id));
int len;
in.read(reinterpret_cast<char*>(&len), sizeof(len));
char* buffer = new char[len + 1];
in.read(buffer, len);
buffer[len] = '\0';
name = buffer;
delete[] buffer;
in.read(reinterpret_cast<char*>(&skill_level), sizeof(skill_level));
}
};
代码说明 :
-serialize:将对象的成员变量逐个写入文件流;
-deserialize:从文件流中读取并还原对象;
- 该实现简单高效,适用于内存对象与文件之间的数据转换;
- 实际项目中可使用 Boost.Serialization、Protobuf 等成熟库来提升序列化效率和兼容性。
5.2.2 文件与数据库访问接口设计
为了统一数据访问方式,通常设计一个抽象的数据访问层(Data Access Layer,DAL),提供统一的接口供上层模块调用。
数据访问接口抽象类(DAO 模式)
class EmployeeDAO {
public:
virtual void save(const Employee& emp) = 0;
virtual Employee load(int id) = 0;
virtual ~EmployeeDAO() {}
};
class FileEmployeeDAO : public EmployeeDAO {
public:
void save(const Employee& emp) override {
std::ofstream out("employee.dat", std::ios::app | std::ios::binary);
emp.serialize(out);
out.close();
}
Employee load(int id) override {
Employee emp;
std::ifstream in("employee.dat", std::ios::binary);
while (in.peek() != EOF) {
emp.deserialize(in);
if (emp.id == id) break;
}
in.close();
return emp;
}
};
代码说明 :
-EmployeeDAO是一个抽象类,定义了数据访问的统一接口;
-FileEmployeeDAO是文件访问的具体实现;
- 通过接口抽象,系统可以灵活切换不同的数据源(如 SQLite、Redis、网络服务等);
- 该设计体现了 开闭原则 ,便于后期扩展与维护。
5.3 数据安全与一致性保障
在智能决策系统中,数据的安全性和一致性是系统稳定运行的关键。特别是在任务分配、模型训练等关键环节中,任何数据错误都可能导致严重的决策偏差。
5.3.1 事务管理与数据校验
事务(Transaction)是一组操作的集合,具有 ACID 特性(原子性、一致性、隔离性、持久性),是保障数据一致性的核心技术。
使用 SQLite 实现事务管理
void performTransaction(sqlite3* db) {
char* errMsg = 0;
sqlite3_exec(db, "BEGIN TRANSACTION", 0, 0, &errMsg); // 开始事务
std::string sql1 = "UPDATE EMPLOYEE SET ASSIGNED = TRUE WHERE ID = 101;";
std::string sql2 = "UPDATE TASK SET STATUS = 'ASSIGNED' WHERE ID = 501;";
int rc = sqlite3_exec(db, sql1.c_str(), 0, 0, &errMsg);
if (rc != SQLITE_OK) {
std::cerr << "事务失败,回滚: " << errMsg << std::endl;
sqlite3_exec(db, "ROLLBACK", 0, 0, &errMsg); // 回滚
return;
}
rc = sqlite3_exec(db, sql2.c_str(), 0, 0, &errMsg);
if (rc != SQLITE_OK) {
std::cerr << "事务失败,回滚: " << errMsg << std::endl;
sqlite3_exec(db, "ROLLBACK", 0, 0, &errMsg);
return;
}
sqlite3_exec(db, "COMMIT", 0, 0, &errMsg); // 提交事务
}
代码说明 :
- 使用BEGIN TRANSACTION开启事务;
- 若任何一步执行失败,调用ROLLBACK回滚整个事务;
- 所有操作成功后,调用COMMIT提交事务;
- 该机制保障了数据的一致性和完整性。
5.3.2 日志记录与回滚机制
除了事务机制,日志记录是保障数据安全的重要手段。通过记录系统操作日志,可以在发生异常时进行数据恢复和审计追踪。
简单的日志记录实现
#include <fstream>
#include <ctime>
void logAction(const std::string& action) {
std::ofstream logFile("system.log", std::ios::app);
time_t now = time(0);
char* dt = ctime(&now);
logFile << "[" << dt << "] " << action << std::endl;
logFile.close();
}
代码说明 :
-logAction函数用于记录系统操作;
- 每条日志包含时间戳和操作描述;
- 该日志可用于后续的系统审计、问题排查与数据恢复;
- 在关键数据操作前调用日志记录,有助于构建完整的数据回滚路径。
总结与过渡
第五章深入探讨了智能决策支持系统中数据管理模块的设计与实现,涵盖了数据模型设计、数据库选型、数据读写机制、持久化策略、数据安全与一致性保障等内容。通过 SQLite 和文件存储的对比,展示了如何根据实际需求选择合适的存储方案;通过事务管理和日志记录机制,保障了系统数据的完整性和安全性。
下一章将围绕 模型构建模块 展开,深入讲解决策模型的构建流程、算法封装与调用方式、模型评估与反馈机制,进一步提升系统的智能化水平与自适应能力。
6. 模型构建模块设计与实现
模型构建模块是智能决策支持系统(DSS)中的核心组件之一,它负责将原始数据转化为可用于决策的数学模型,并通过封装和调用算法进行求解。该模块不仅需要具备良好的灵活性与可扩展性,还需支持多种算法的集成与切换机制,同时提供评估与反馈机制以实现模型的持续优化。本章将从模型构建流程、算法封装与调用、以及模型评估与反馈三个方面深入探讨模型构建模块的设计与实现细节。
6.1 决策模型的构建流程
决策模型的构建是将原始数据转化为可用于求解的数学结构的过程。这一过程包括数据的解析与预处理、模型的初始化以及参数的配置等步骤。模型构建流程的合理设计直接影响系统的性能与结果的准确性。
6.1.1 输入数据解析与预处理
输入数据的解析是模型构建的第一步。通常,输入数据来源于数据库、文件或外部接口,可能包含缺失值、噪声数据或格式不一致的问题。因此,需要设计一个通用的数据解析器,支持多种格式(如 CSV、JSON、XML)的读取,并提供数据清洗与预处理功能。
以下是一个基于 C++ 的 CSV 数据解析示例:
#include <fstream>
#include <sstream>
#include <vector>
#include <string>
std::vector<std::vector<double>> parseCSV(const std::string& filename) {
std::ifstream file(filename);
std::vector<std::vector<double>> data;
std::string line;
while (std::getline(file, line)) {
std::vector<double> row;
std::stringstream ss(line);
std::string cell;
while (std::getline(ss, cell, ',')) {
try {
row.push_back(std::stod(cell)); // 将字符串转换为 double
} catch (...) {
row.push_back(0.0); // 处理非数值数据
}
}
data.push_back(row);
}
return data;
}
逻辑分析与参数说明:
parseCSV函数接受一个文件名参数filename,并返回解析后的二维向量data。- 使用
std::ifstream打开文件,逐行读取。 - 每行使用
std::stringstream分割成单元格,使用std::stod将字符串转换为浮点数。 - 若单元格内容无法转换为数值,则默认填入 0.0,避免程序异常。
- 该函数支持基本的 CSV 数据清洗,适用于数值型决策问题建模。
6.1.2 模型初始化与参数配置
模型初始化是根据解析后的数据创建数学模型的过程,通常包括定义变量、设置目标函数和约束条件等。参数配置则涉及模型的超参数设置,如优化算法的选择、迭代次数、收敛阈值等。
以下是一个简化版的模型初始化类设计示例:
class DecisionModel {
public:
DecisionModel(const std::vector<std::vector<double>>& inputData, double threshold = 1e-6)
: data(inputData), convergenceThreshold(threshold) {}
void initializeVariables() {
// 初始化变量
variables.resize(data.size());
for (auto& var : variables) {
var = 0.0;
}
}
void setOptimizationAlgorithm(const std::string& algoName) {
optimizationAlgorithm = algoName;
}
void setMaxIterations(int maxIter) {
maxIterations = maxIter;
}
private:
std::vector<std::vector<double>> data;
std::vector<double> variables;
std::string optimizationAlgorithm;
double convergenceThreshold;
int maxIterations = 1000;
};
逻辑分析与参数说明:
DecisionModel类封装了模型初始化与配置的基本功能。- 构造函数接收输入数据和收敛阈值,默认为
1e-6。 initializeVariables方法初始化决策变量,大小与输入数据一致。setOptimizationAlgorithm和setMaxIterations方法用于配置算法和迭代次数。- 类成员变量包括数据、变量、算法名称、收敛阈值和最大迭代次数,便于后续求解器调用。
6.2 模型算法的封装与调用
为了提高系统的灵活性和可维护性,模型算法应被封装为独立模块,并通过统一接口进行调用。这种设计支持算法的动态切换和扩展,便于后续的性能对比和模型优化。
6.2.1 接口抽象与策略模式应用
策略模式是一种设计模式,允许在运行时动态选择算法。我们可以通过定义一个抽象算法接口,并为每种算法实现该接口,从而实现策略的切换。
class OptimizationStrategy {
public:
virtual ~OptimizationStrategy() = default;
virtual std::vector<double> optimize(const std::vector<std::vector<double>>& data) = 0;
};
class LinearProgrammingSolver : public OptimizationStrategy {
public:
std::vector<double> optimize(const std::vector<std::vector<double>>& data) override {
// 实现线性规划求解逻辑
std::vector<double> result(data.size(), 0.0);
// 示例:简单求解逻辑
for (size_t i = 0; i < data.size(); ++i) {
result[i] = data[i][0] * 0.5 + data[i][1] * 0.3;
}
return result;
}
};
class GeneticAlgorithmSolver : public OptimizationStrategy {
public:
std::vector<double> optimize(const std::vector<std::vector<double>>& data) override {
// 实现遗传算法求解逻辑
std::vector<double> result(data.size(), 0.0);
// 示例:随机扰动求解
for (size_t i = 0; i < data.size(); ++i) {
result[i] = data[i][0] * 0.7 + data[i][1] * 0.2 + rand() % 10 / 100.0;
}
return result;
}
};
逻辑分析与参数说明:
OptimizationStrategy是一个抽象接口,定义了optimize方法。LinearProgrammingSolver和GeneticAlgorithmSolver是具体策略类,分别实现了不同的优化算法。- 每个策略类返回一个
std::vector<double>类型的优化结果。 - 通过策略模式,可以在运行时动态切换算法,而无需修改调用逻辑。
6.2.2 多种算法切换机制实现
为了实现算法的动态切换,我们可以设计一个上下文类 ModelSolver ,它持有策略接口的指针,并调用其方法进行求解。
class ModelSolver {
public:
void setStrategy(OptimizationStrategy* strategy) {
this->strategy = strategy;
}
std::vector<double> solve(const std::vector<std::vector<double>>& data) {
if (strategy) {
return strategy->optimize(data);
}
return {};
}
private:
OptimizationStrategy* strategy = nullptr;
};
使用示例:
int main() {
auto data = parseCSV("data.csv");
DecisionModel model(data);
model.initializeVariables();
model.setOptimizationAlgorithm("Genetic Algorithm");
model.setMaxIterations(500);
ModelSolver solver;
if (model.getOptimizationAlgorithm() == "Linear Programming") {
solver.setStrategy(new LinearProgrammingSolver());
} else {
solver.setStrategy(new GeneticAlgorithmSolver());
}
auto result = solver.solve(data);
// 输出结果
for (auto val : result) {
std::cout << val << " ";
}
return 0;
}
6.3 模型评估与反馈机制
模型评估与反馈机制是提升决策系统智能化水平的关键环节。它通过对模型输出结果进行量化评估,并根据评估结果动态调整模型参数,形成闭环优化。
6.3.1 模型性能评估指标
常见的模型评估指标包括:
| 指标名称 | 定义 | 用途 |
|---|---|---|
| 均方误差(MSE) | 平均平方误差 | 评估预测值与真实值之间的差异 |
| 准确率(Accuracy) | 正确预测的比例 | 用于分类问题 |
| 收敛速度 | 算法达到收敛所需的迭代次数 | 评估算法效率 |
| 目标函数值 | 最终优化结果 | 衡量模型求解质量 |
| 鲁棒性 | 模型对噪声数据的容忍度 | 衡量模型稳定性 |
以下是一个简单的 MSE 计算函数:
double calculateMSE(const std::vector<double>& predicted, const std::vector<double>& actual) {
if (predicted.size() != actual.size()) return -1.0;
double mse = 0.0;
for (size_t i = 0; i < predicted.size(); ++i) {
double diff = predicted[i] - actual[i];
mse += diff * diff;
}
return mse / predicted.size();
}
6.3.2 结果反馈与参数自动调整
为了实现模型的自我优化,系统应具备反馈机制,根据评估结果自动调整模型参数。例如,在连续迭代中若发现模型收敛速度下降,可适当增加学习率或调整迭代次数。
以下是一个简化的自动调整机制示例:
class ModelFeedback {
public:
void updateParameters(double mse, DecisionModel& model) {
if (mse > 0.5) {
model.setMaxIterations(model.getMaxIterations() + 100); // 增加迭代次数
std::cout << "增加迭代次数至 " << model.getMaxIterations() << std::endl;
} else if (mse < 0.1) {
model.setConvergenceThreshold(model.getConvergenceThreshold() * 0.9); // 提高精度
std::cout << "降低收敛阈值至 " << model.getConvergenceThreshold() << std::endl;
}
}
};
逻辑分析与参数说明:
ModelFeedback类根据当前 MSE 值动态调整模型参数。- 若 MSE 较高(>0.5),认为模型尚未收敛,增加迭代次数;
- 若 MSE 较低(<0.1),认为模型已较优,进一步提升收敛精度。
总结
本章详细介绍了模型构建模块的设计与实现过程,包括输入数据的解析与预处理、模型初始化与参数配置、算法封装与调用策略,以及模型评估与反馈机制。通过策略模式的应用,实现了算法的灵活切换;通过评估指标与反馈机制,实现了模型的自适应优化。这些设计不仅提升了系统的智能化水平,也为后续的模块扩展与性能优化奠定了基础。
7. 用户接口模块开发与交互设计
在智能决策支持系统(DSS)中,用户接口模块是连接用户与系统逻辑的核心桥梁。一个优秀的用户界面不仅应具备良好的交互体验,还需满足系统的功能性、稳定性与可扩展性要求。本章将围绕用户交互需求分析、界面技术选型、控件设计、输入处理与反馈机制展开,重点介绍如何在C++环境下使用Qt框架实现一个高效、直观的图形用户界面。
7.1 用户交互需求分析与界面规划
7.1.1 用户角色与操作流程定义
在设计用户界面之前,首先需要明确不同用户角色的操作权限与使用场景。例如:
| 用户角色 | 主要操作 | 权限等级 |
|---|---|---|
| 管理员 | 系统配置、数据导入导出、模型训练 | 高 |
| 决策者 | 查询结果、查看可视化图表、导出报告 | 中 |
| 普通用户 | 提交任务请求、查看任务状态 | 低 |
每种角色对应的操作流程不同,界面设计需据此进行模块化组织,确保操作路径清晰、直观。
7.1.2 界面原型设计与可用性原则
界面设计应遵循以下可用性原则:
- 一致性 :控件风格、布局方式保持统一。
- 易学性 :界面直观,用户无需培训即可操作。
- 反馈及时性 :操作后应有明确的反馈,如进度条、提示信息。
- 容错机制 :允许用户撤销操作或恢复误操作。
使用工具如 Figma 或 Qt Designer 可以快速绘制界面原型并进行用户测试。
7.2 图形界面开发技术选型与实现
7.2.1 Qt框架在DSS系统中的应用
Qt 是一个跨平台的C++图形界面开发框架,具备丰富的控件库和信号槽机制,非常适合用于开发复杂的桌面应用程序。其主要优势包括:
- 跨平台支持(Windows、Linux、macOS)
- 强大的GUI组件库(QWidget、QML)
- 支持多线程、网络通信、数据库集成等高级功能
- 可视化设计工具 Qt Designer 提高开发效率
在DSS系统中,我们使用 Qt 的 QWidgets 模块构建主界面,通过 QSignalMapper 和 connect() 实现事件驱动逻辑。
7.2.2 主界面布局与控件交互设计
主界面通常包括以下几个区域:
- 顶部菜单栏 :提供系统设置、数据导入导出、帮助文档等功能入口。
- 左侧导航栏 :用于切换不同功能模块,如任务管理、模型配置、结果展示等。
- 中间内容区 :动态加载不同功能模块的界面。
- 状态栏 :显示当前操作状态、系统时间、任务进度等。
下面是一个简单的Qt主窗口布局代码示例:
#include <QApplication>
#include <QMainWindow>
#include <QMenuBar>
#include <QToolBar>
#include <QStatusBar>
#include <QLabel>
int main(int argc, char *argv[]) {
QApplication app(argc, argv);
QMainWindow window;
// 设置窗口标题和大小
window.setWindowTitle("智能决策支持系统");
window.resize(800, 600);
// 创建菜单栏
QMenuBar *menuBar = window.menuBar();
QMenu *fileMenu = menuBar->addMenu("文件");
fileMenu->addAction("导入数据");
fileMenu->addAction("导出结果");
// 创建工具栏
QToolBar *toolBar = new QToolBar("主工具栏");
window.addToolBar(toolBar);
toolBar->addAction("新建任务");
toolBar->addAction("运行模型");
// 创建状态栏
QStatusBar *statusBar = window.statusBar();
QLabel *statusLabel = new QLabel("就绪");
statusBar->addWidget(statusLabel);
window.show();
return app.exec();
}
该示例代码创建了一个包含菜单栏、工具栏和状态栏的基础界面结构,后续可根据功能模块进一步扩展。
7.3 用户输入处理与反馈机制
7.3.1 事件驱动编程与输入校验
Qt 采用事件驱动模型,通过信号(signal)和槽(slot)机制实现用户交互。例如,点击按钮时触发特定函数:
QPushButton *runButton = new QPushButton("运行模型", &window);
connect(runButton, &QPushButton::clicked, [&]() {
// 处理按钮点击事件
qDebug() << "开始运行模型...";
});
输入校验是防止错误数据进入系统的关键步骤。例如,在输入任务参数时,需验证输入是否为数字、是否超出范围等:
QString input = inputLineEdit->text();
bool ok;
int value = input.toInt(&ok);
if (!ok || value < 0 || value > 100) {
QMessageBox::warning(&window, "输入错误", "请输入0-100之间的整数");
}
7.3.2 异常处理与用户提示设计
在系统运行过程中,可能出现各种异常,如数据加载失败、内存不足、模型执行错误等。为此,系统应具备完善的异常处理机制。
Qt 提供了 QMessageBox 、 QLoggingCategory 、 try-catch 等方式用于异常捕获与提示:
try {
runModel(); // 假设该函数可能抛出异常
} catch (const std::exception &e) {
QMessageBox::critical(&window, "错误", QString("发生异常:%1").arg(e.what()));
}
同时,系统应设计友好的用户提示,如:
- 使用
QProgressDialog显示任务进度 - 使用
QLabel实时更新状态信息 - 使用
QToolTip提供控件说明
通过这些机制,可以有效提升用户体验与系统稳定性。
注:本章内容已完整展示第七章的结构与技术细节,后续章节将继续围绕系统部署、性能优化与案例分析展开。
简介:智能决策支持系统(DSS)是一种辅助个人或团队进行复杂决策的软件工具。本项目基于C++语言实现,包含分配问题建模与匈牙利算法核心逻辑,适用于任务调度、人力资源分配等场景。系统集成了数据管理、模型构建、用户接口与分析工具等模块,帮助用户高效进行智能决策。适合学习者深入理解算法在实际问题中的应用,并为后续结合AI与机器学习技术进行系统扩展打下基础。
更多推荐



 10
10 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)