
【来也Uibot导入Python程序作为命令库使用,以PlayWright为例】
文章目录
环境
uibot运行环境:
- Creator CommunityV1.2.1 或 Creator CommunityV1.2.2
python代码编写环境:
- python3.12
- 本地通过pip或conda安装playwright库
一、使用步骤
1.通过控制台cmd命令,以调试模式启动谷歌chrome
这里使用playwright直接连接已经打开的浏览器标签页。
注意:将chrome.exe的路径改成你的实际路径,命令需要带上最外层的引号,这里使用的端口为9222,可以自行修改。
"C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe" --remote-debugging-port=9222 --user-data-dir="C:\\temp\\chrome-debug-profile"
2.编写py文件,引入PlayWright库,连接到浏览器的指定标签页
这里以百度搜索页面为例:
1.首先在通过cmd启动的chrome地址栏输入https://www.baidu.com/进入到百度首页。
2.编写一个python函数,目标:
(1).接收uibot传入的字符串。
(2).连接到https://www.baidu.com/标签页。
(3).在百度的标签页F12开发者界面的控制台上输出传入的字符串。
python代码如下:
注意代码中的端口号必须与第一步中的端口号一致,这里为9222。
可以自行添加main函数测试python命令,这里不做演示。
from playwright.sync_api import sync_playwright
def console_input(input_str: str):
# 解析命令行参数
print(f"参数设置:")
print(f" 匹配值: {input_str}")
with sync_playwright() as p:
# 连接到已运行的 Chrome
try:
print("正在连接到已运行的 Chrome 浏览器...")
# 端口号改成自己的
browser = p.chromium.connect_over_cdp("http://localhost:9222")
print("成功连接到 Chrome 浏览器")
except Exception as e:
print(f"连接失败: {e}")
print("请确保 Chrome 已以调试模式启动")
return
context = browser.contexts[0]
# ---------- 获取目标标签页 ----------
target_url = "https://www.baidu.com/" # 改成实际的地址和标签页title
target_title = "百度一下,你就知道"
pages = context.pages
print(f"共找到 {len(pages)} 个标签页")
for i, page in enumerate(pages):
current_url = page.url
current_title = page.title()
print(f" 标签页 {i}: URL={current_url}, Title={current_title[:50]}")
page = None
# 方法1: 精确匹配 URL
for p in pages:
if p.url == target_url:
page = p
print(f"通过精确 URL 匹配找到目标标签页")
break
# 方法2: URL 包含匹配
if page is None:
for p in pages:
if target_url in p.url:
page = p
print(f"通过 URL 包含匹配找到目标标签页: {p.url}")
break
# 方法3: title 匹配
if page is None:
for p in pages:
if target_title in p.title():
page = p
print(f"通过 title 匹配找到目标标签页: {p.title()}")
break
# 方法4: 返回最后一个新打开的标签页
if page is None and len(pages) >= 2:
page = pages[-1]
print(f"未通过条件匹配,返回最后一个标签页(索引 {len(pages) - 1})")
if page is None:
print("未找到目标标签页,退出")
return
# 将目标页面置前
page.bring_to_front()
print(f"已切换到目标页面: {page.url}")
# ---------- 获取 placeholder 属性值 ----------
try:
# 等待页面加载完成
print("等待页面加载...")
page.wait_for_load_state("networkidle", timeout=10000)
page.wait_for_timeout(1000) # 额外等待确保元素渲染
page.evaluate(f'console.log("{input_str}")')
print(f"已在控制台输出: {input_str}")
except Exception as e:
import traceback
traceback.print_exc()
3.将python文件导入到uibot命令库当中,测试效果
1.右键py文件,将py文件压缩成ZIP类型的压缩包(不需要放入文件夹中!!!),这里我的文件是test.zip。
2.进入到Creator命令库管理界面,按照如下步骤添加命令: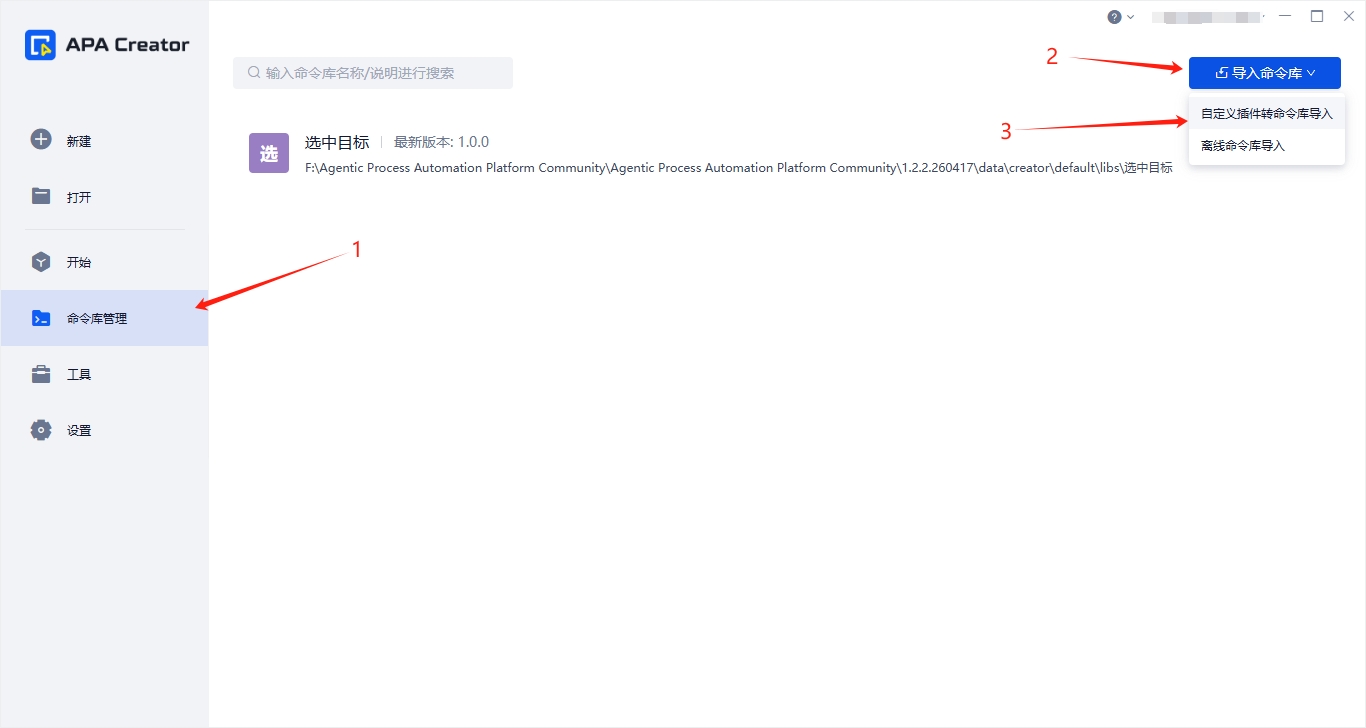
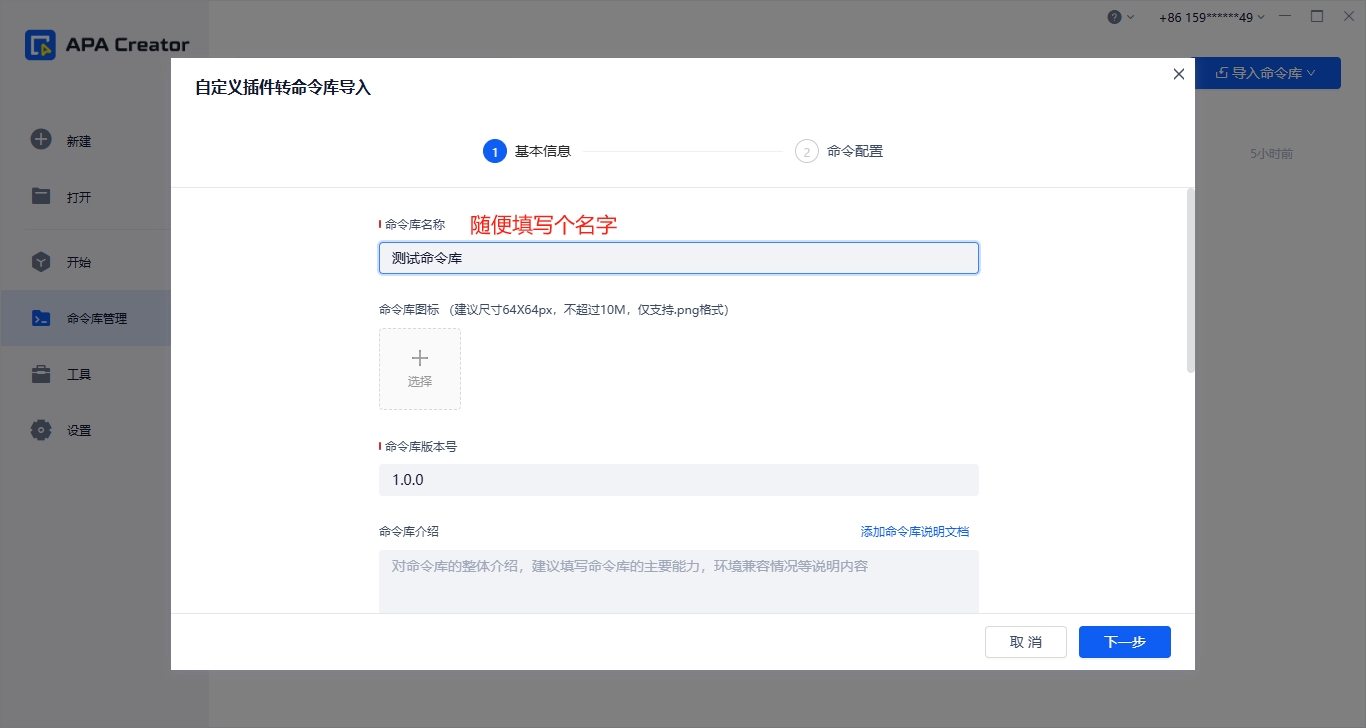
下拉滚动条到界面底部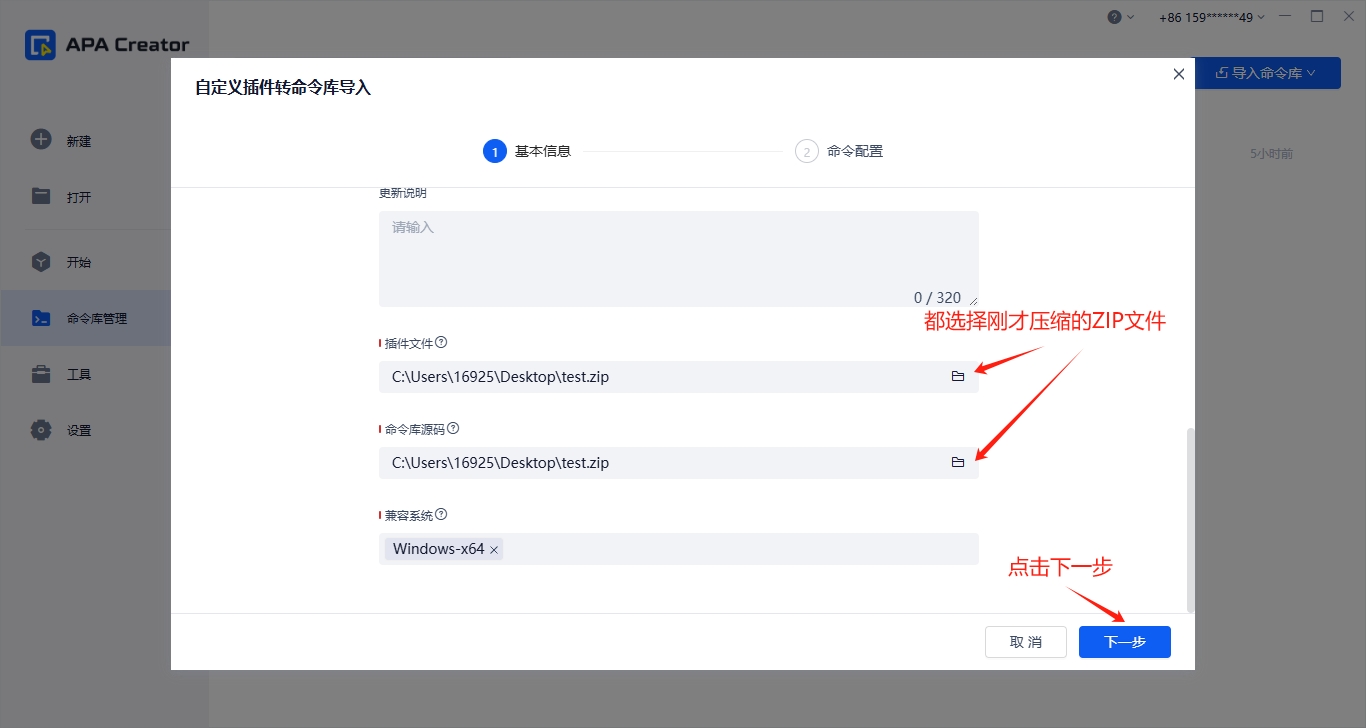
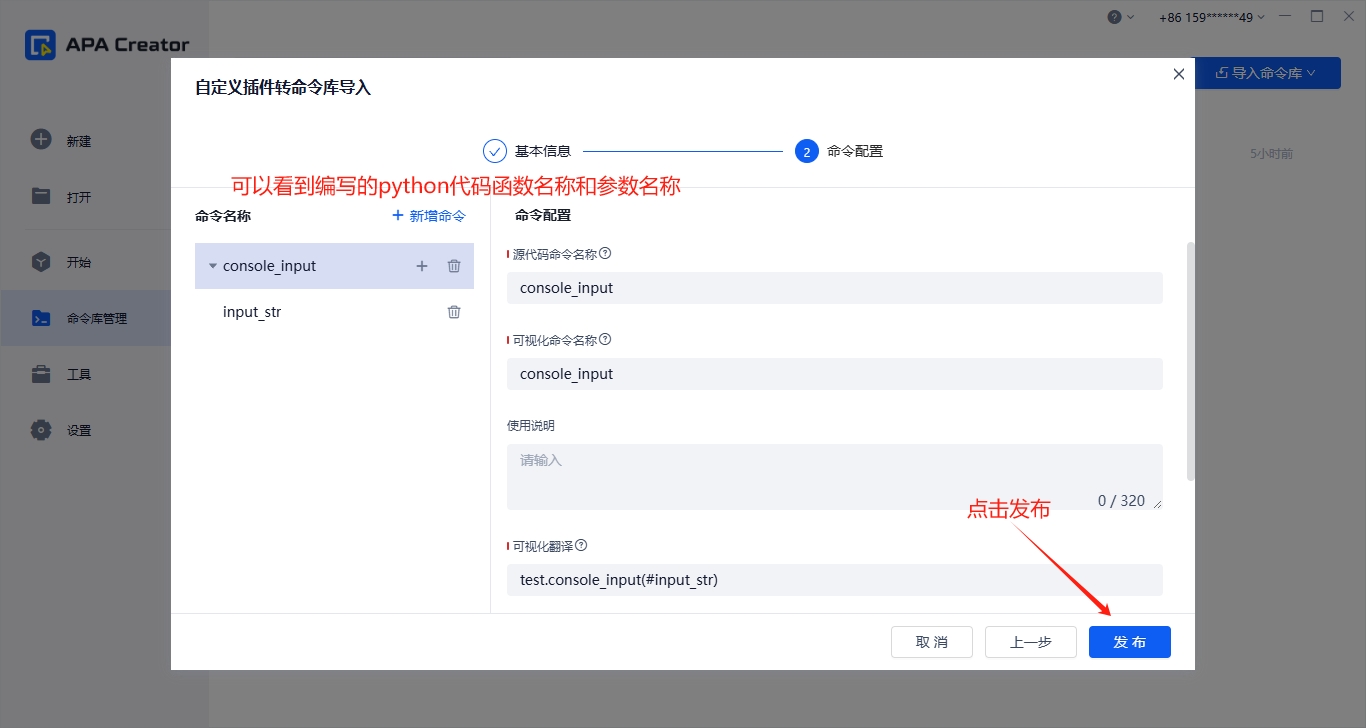
3.进入到流程命令块中,安装并调用命令: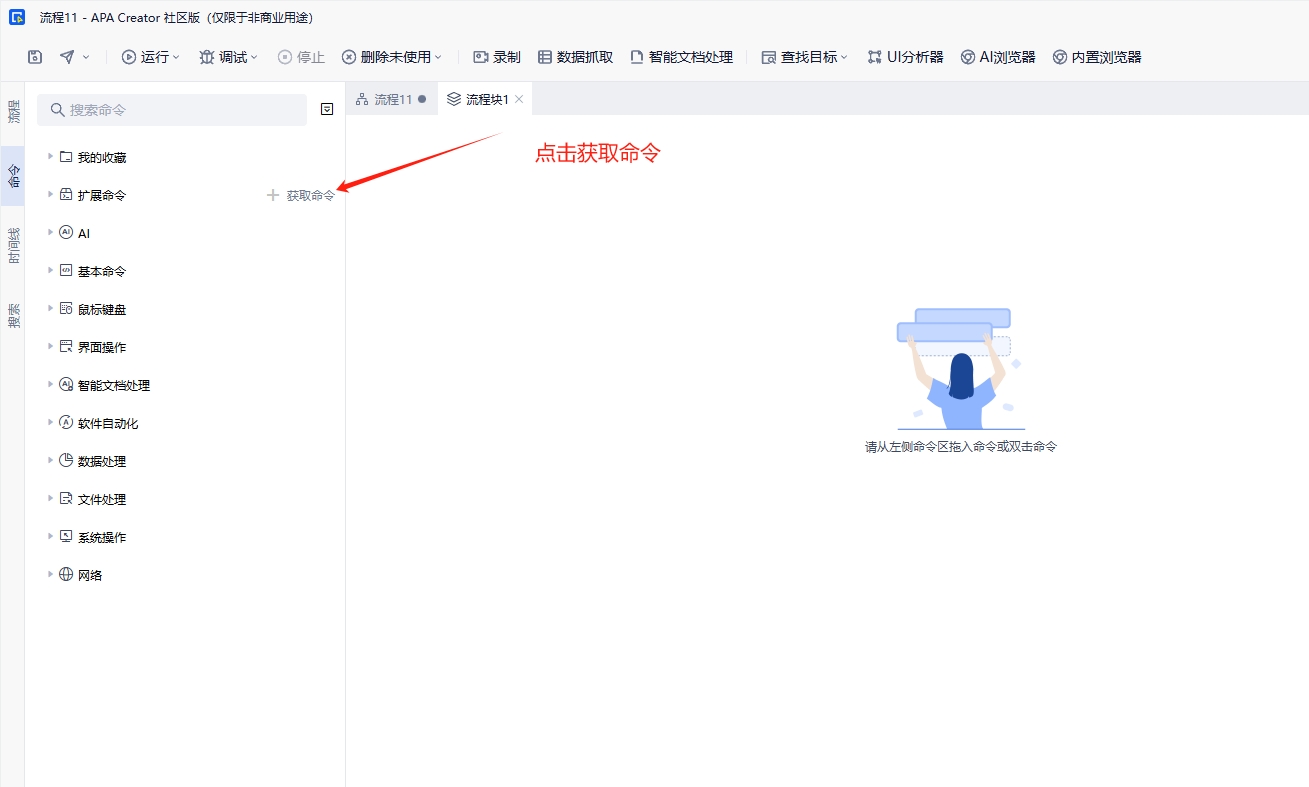
找到刚才创建的命令库,安装命令库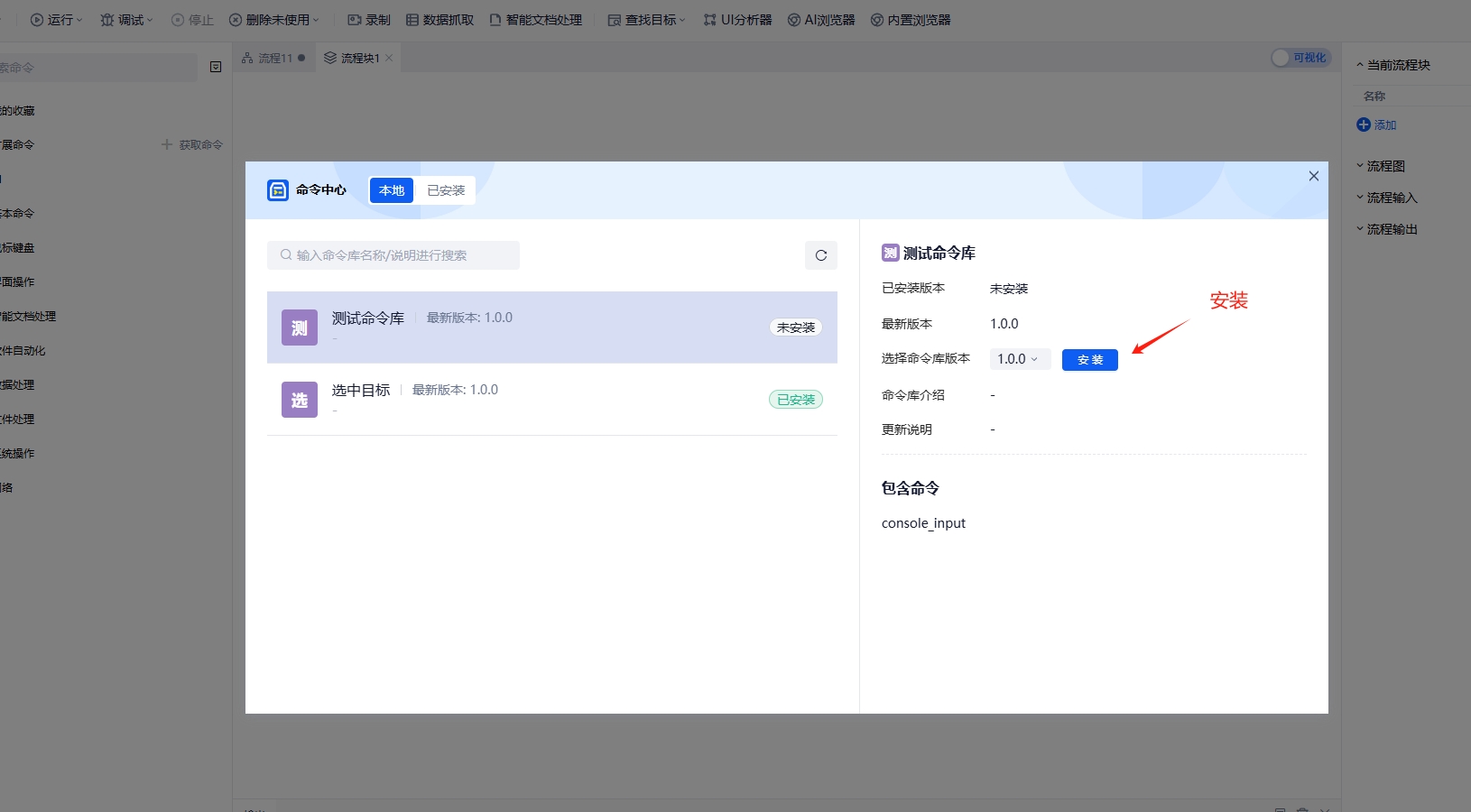
提示安装完成后,在扩展命令中找到命令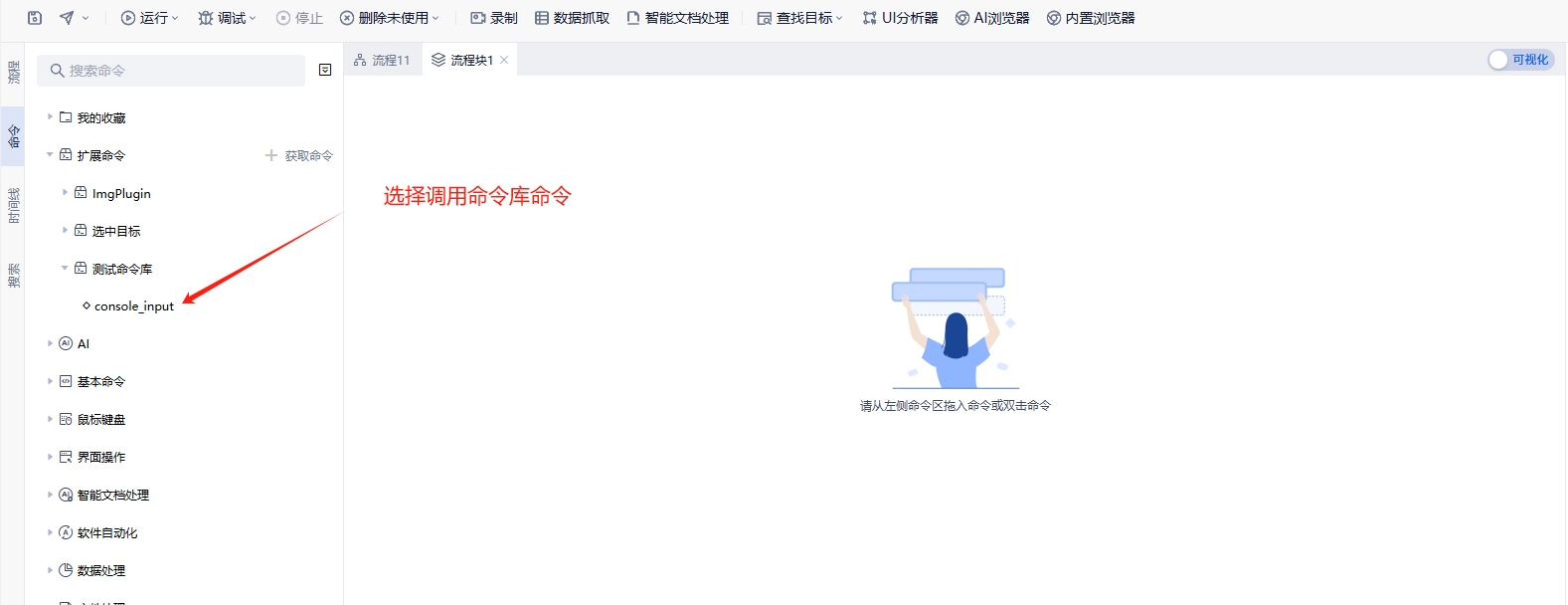
输入参数,运行
注意:确保通过命令行启动的chrome已经打开了https://www.baidu.com/百度页面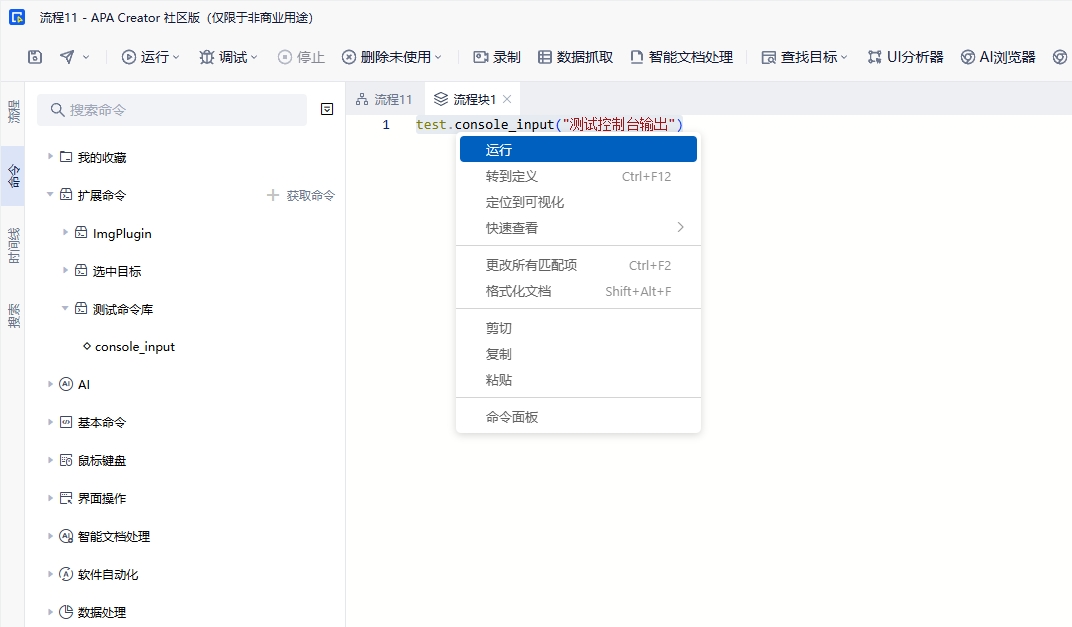
查看结果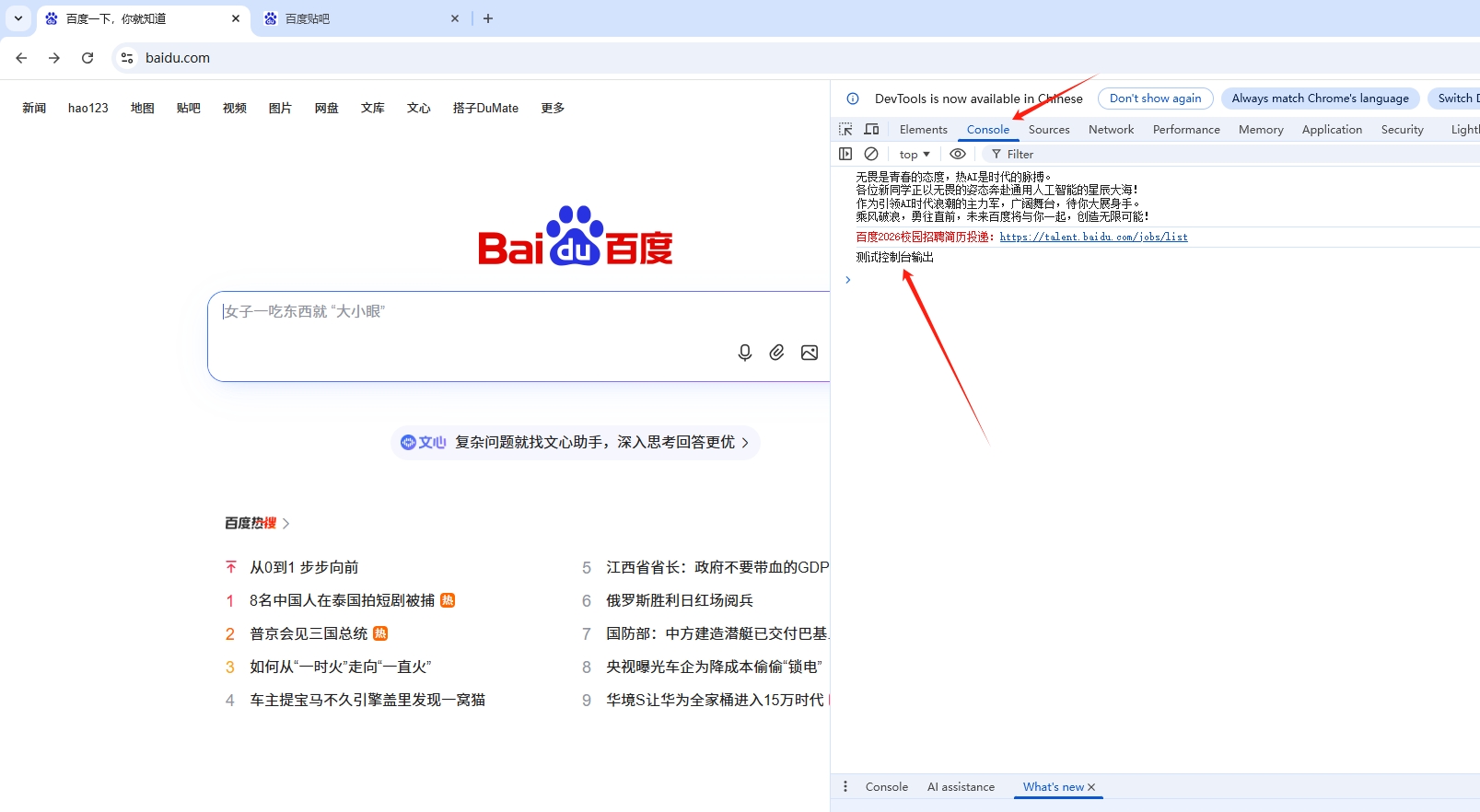
二、注意点
1.Creator CommunityV1.2.1以后内置了python和PlayWright库,运行环境中不需要自行添加了。
2.目前只支持传入字符串类型的参数,如需传入数组可以通过特殊符号拼接然后在python中分割成数组或者直接传入json字符串到python中解析。
3.支持通过“=”接收python返回的字符串类型返回值。
欢迎指正!
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)