
(二十八)pom.xml文件-【坐标】+【引用jar包】+【大厂 Java 架构师视角】
pom.xml 四大核心功能 + 具体做法
1. 引入依赖
作用:导入项目所需第三方 jar 包做法:在<dependencies>标签内写依赖坐标,Maven 自动从仓库下载
xml
<dependencies>
<dependency>
<groupId>依赖组名</groupId>
<artifactId>依赖项目名</artifactId>
<version>版本号</version>
</dependency>
</dependencies>
2. 编译代码
作用:java 源码转为 class 字节码文件做法:配置 maven 编译插件,指定 JDK 版本,执行编译命令
xml
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
命令:mvn compile
3. 执行测试
作用:运行单元测试代码校验功能做法:引入测试依赖,编写测试类,直接执行测试命令引入测试依赖:
xml
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
命令:mvn test
4. 打包运行
作用:整合所有文件打成压缩包,可直接部署启动做法:指定打包格式,配置打包插件,执行打包命令
xml
<packaging>jar</packaging>
命令:mvn package运行项目:mvn run
我们编写的所有配置都会放到pom.xml文件中这个project(普肉J克特)当中。
先是modelversion这个可以无视,这个是maven版本相关的信息,当他不存在,但不要改动它
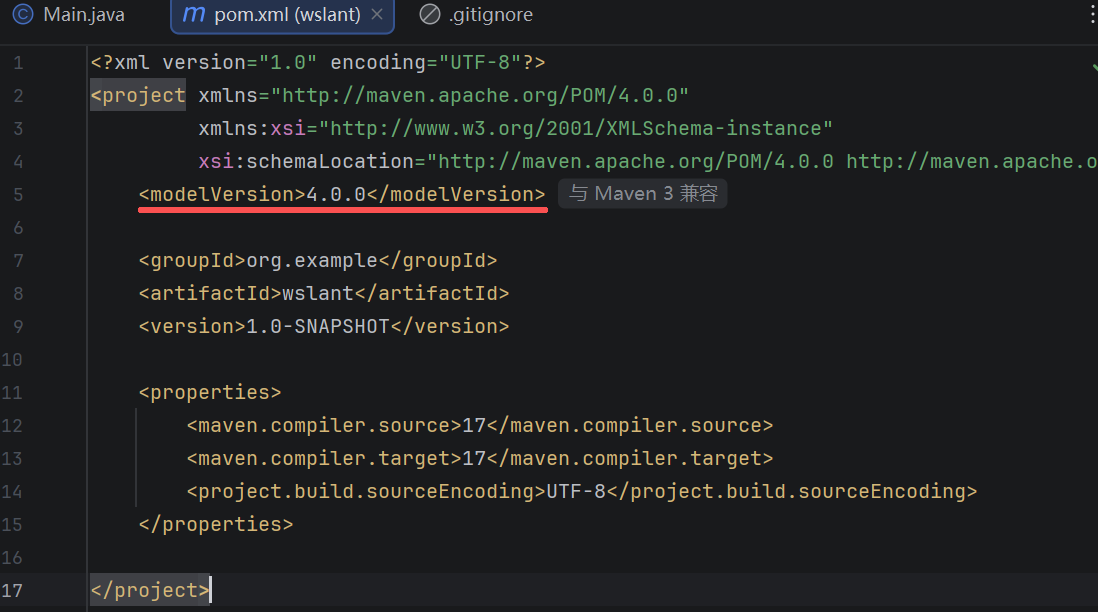
---【定位】---信息3兄弟----唯一依赖
祖贵滴(groupId)
阿 te 法克特(artifactId)
威森(version)
Maven 的三大坐标是它的核心灵魂,作用只有一个:在全世界的 Maven 仓库里,精准、唯一地定位到一个 jar 包 / 项目,就像快递地址一样,缺一不可。
作用:通过这3兄弟,找到jar包所在的位置
他们怎么找jar包?
他们到本地仓库找根据一以下坐标找
<groupId>org.example</groupId> <artifactId>wslant</artifactId> <version>1.0-SNAPSHOT</version>
本地仓库没有jar包,找不到,就去我们配置的镜像去找,去远程镜像地址找
去依次你找你自己配置好的网络镜像,比如阿里云,华为云去下载,下载到了
返回中央仓库,找不到会报错not f
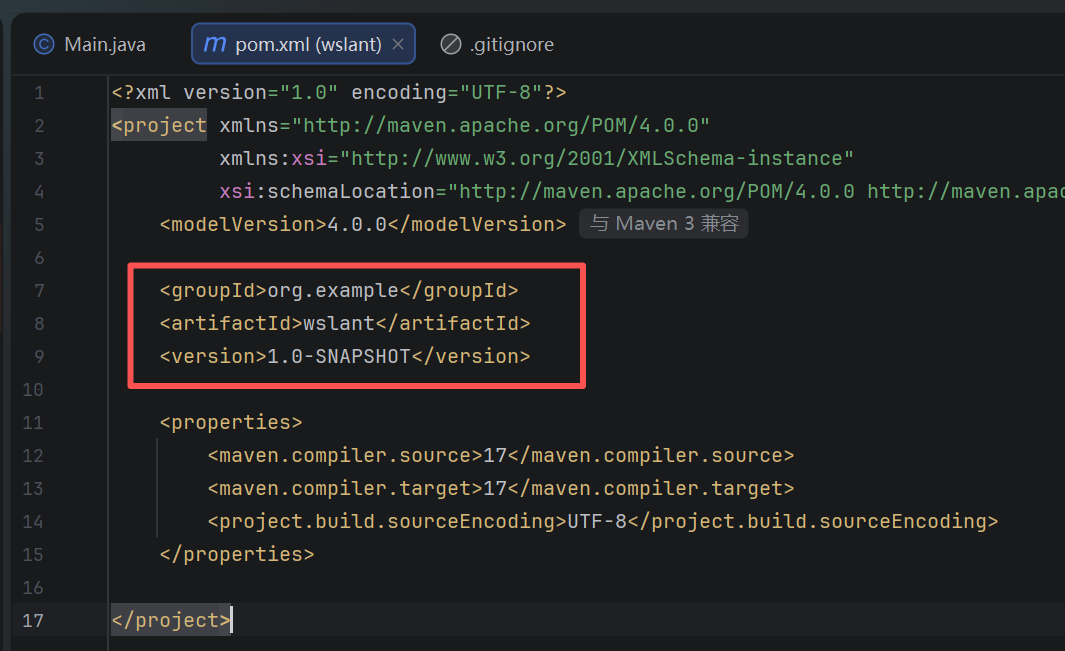
怎么样去配置本工程坐标信息
比如模块有3个,前台、后台、common(聚合maven项目)
我们开发的项目大部分是多个工程多个模块组成
比如:前台、后台、commn这个属于一个oa系统模块那么
就是OA(前台、后台、commn)这样写
这样配置的坐标信息就不一样
---【引用jar包】---
<dependencies>(大箱子)
<dependency>(小盒子)
<groupId></groupId>
<artifactId></artifactId>
<version></version>
</dependency>(小盒子)
</dependencies>(大箱子)
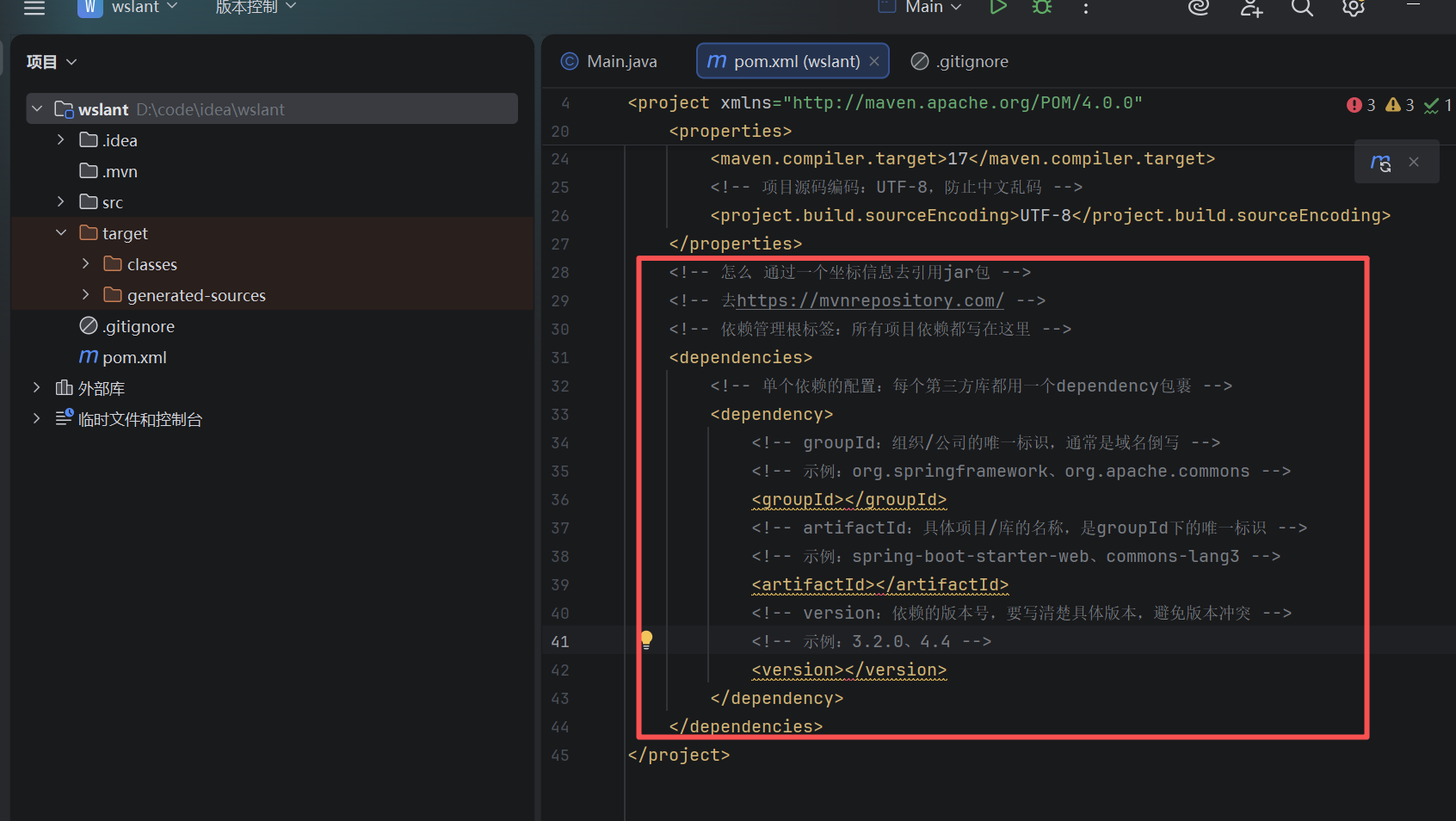
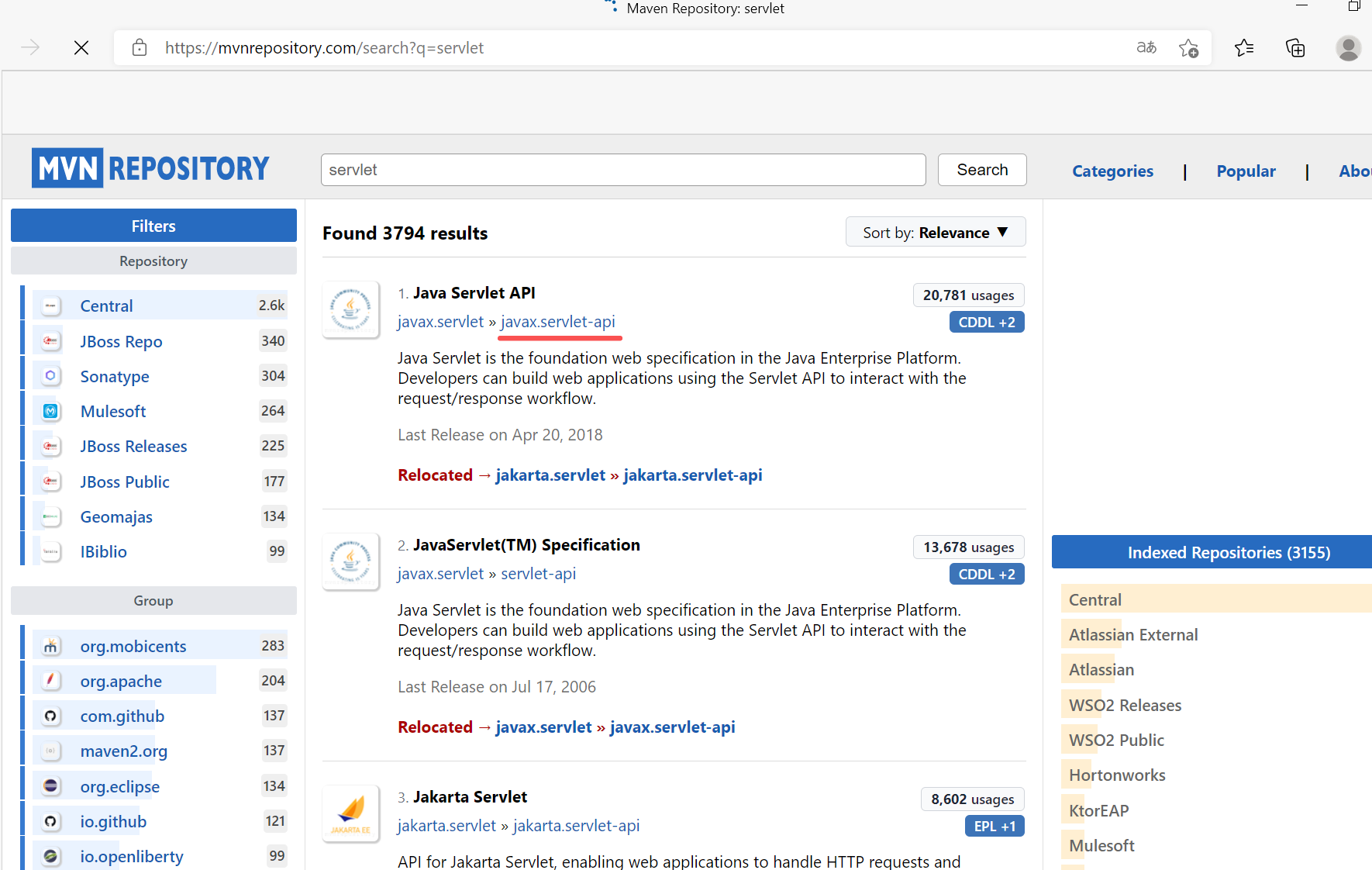
去下载一个依赖servlet.去:https://mvnrepository.com/
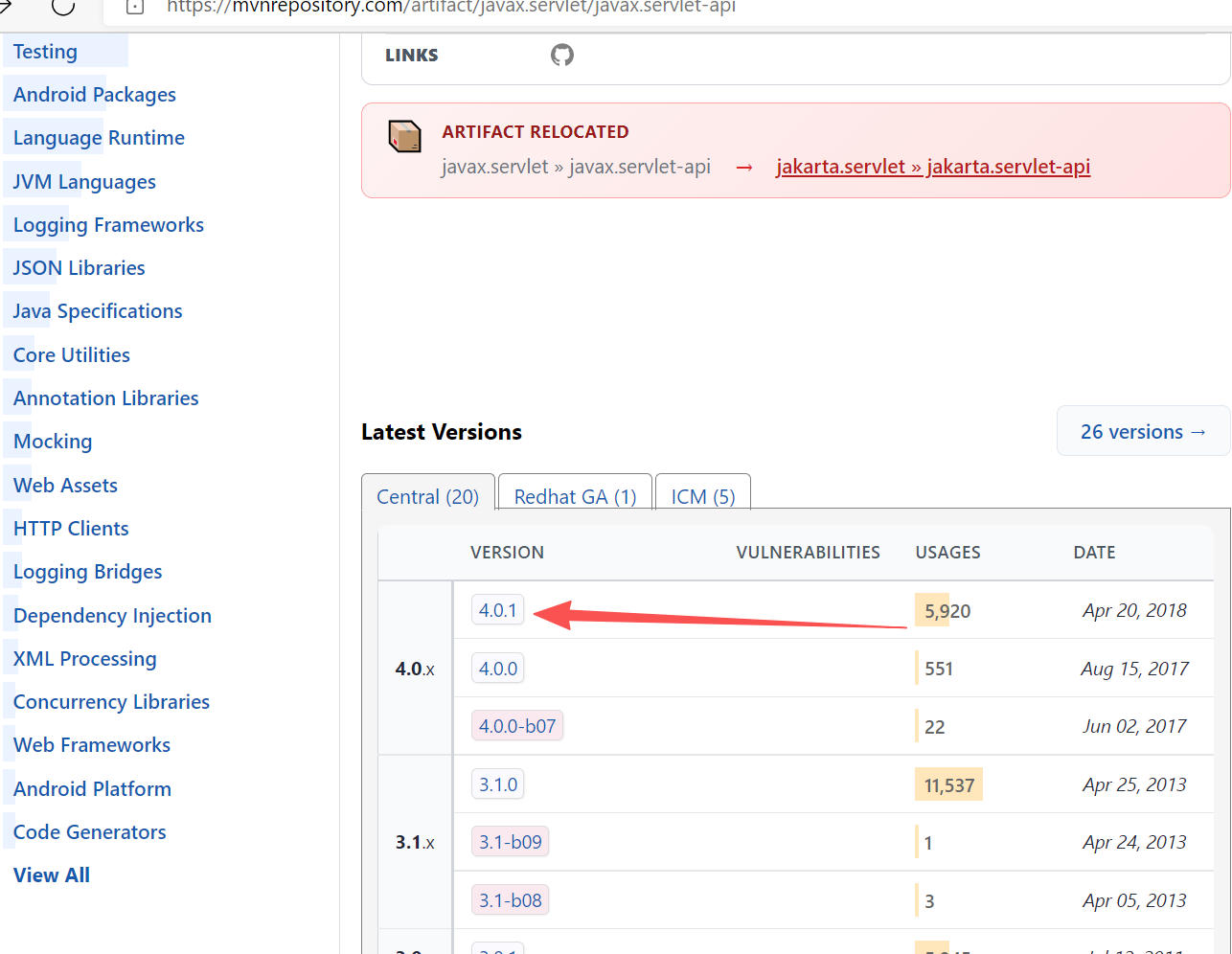
找到你想找的版本,比如我需要4.0.1版本
这就是他给到的配置项
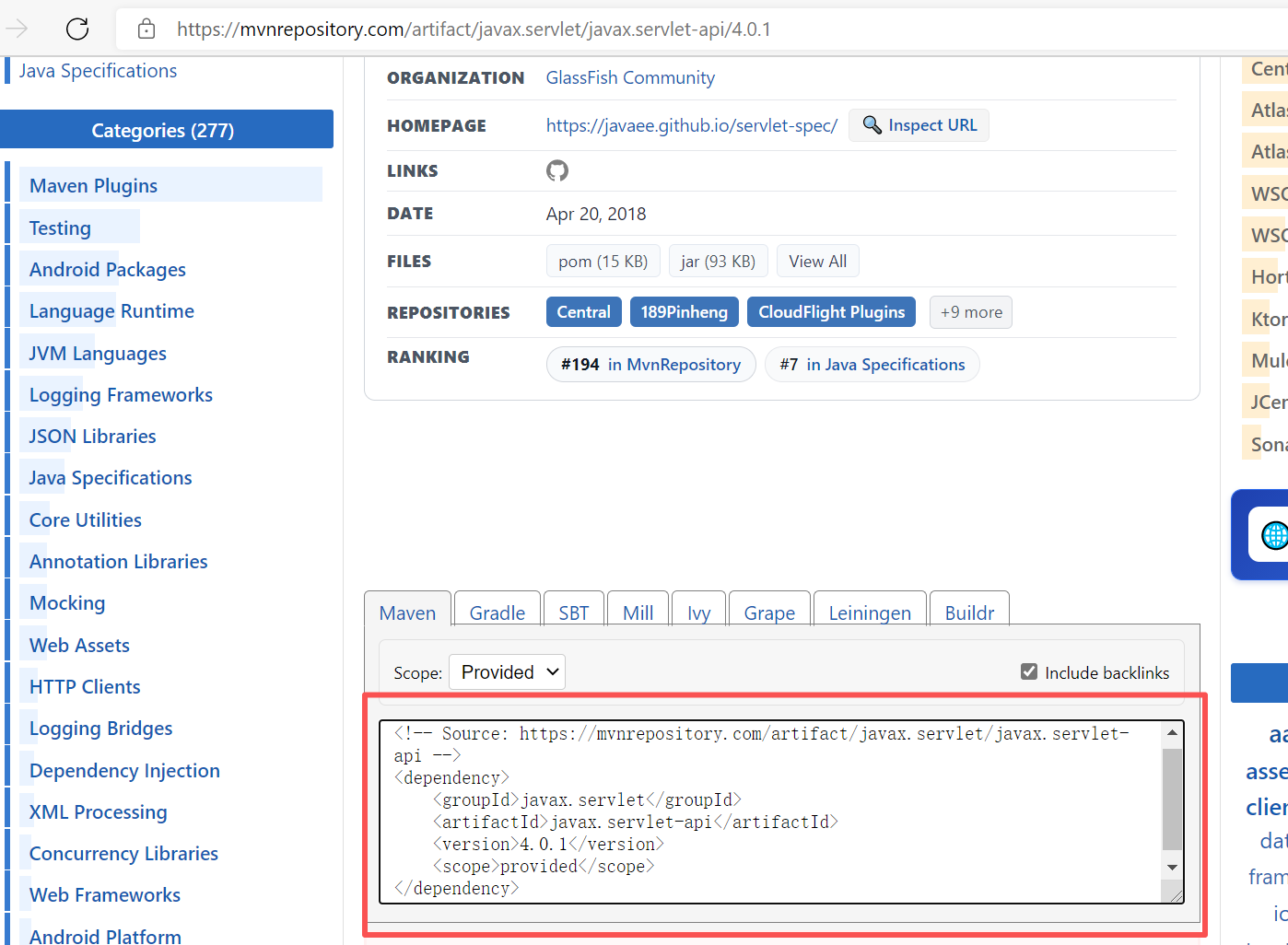
复制进去pom.xml文件里,就会生成一个servlet依赖
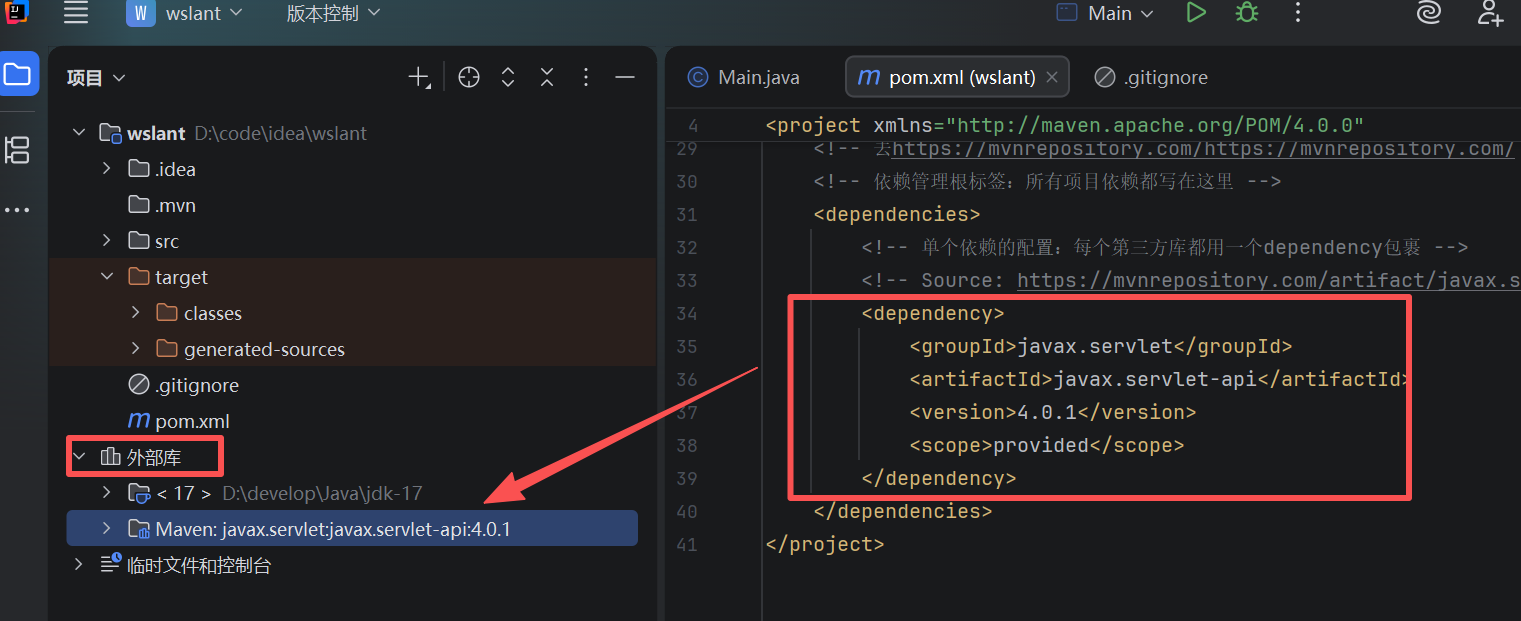
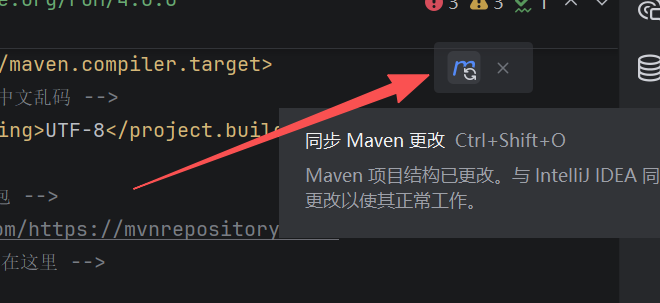
这里记得点刷新同步
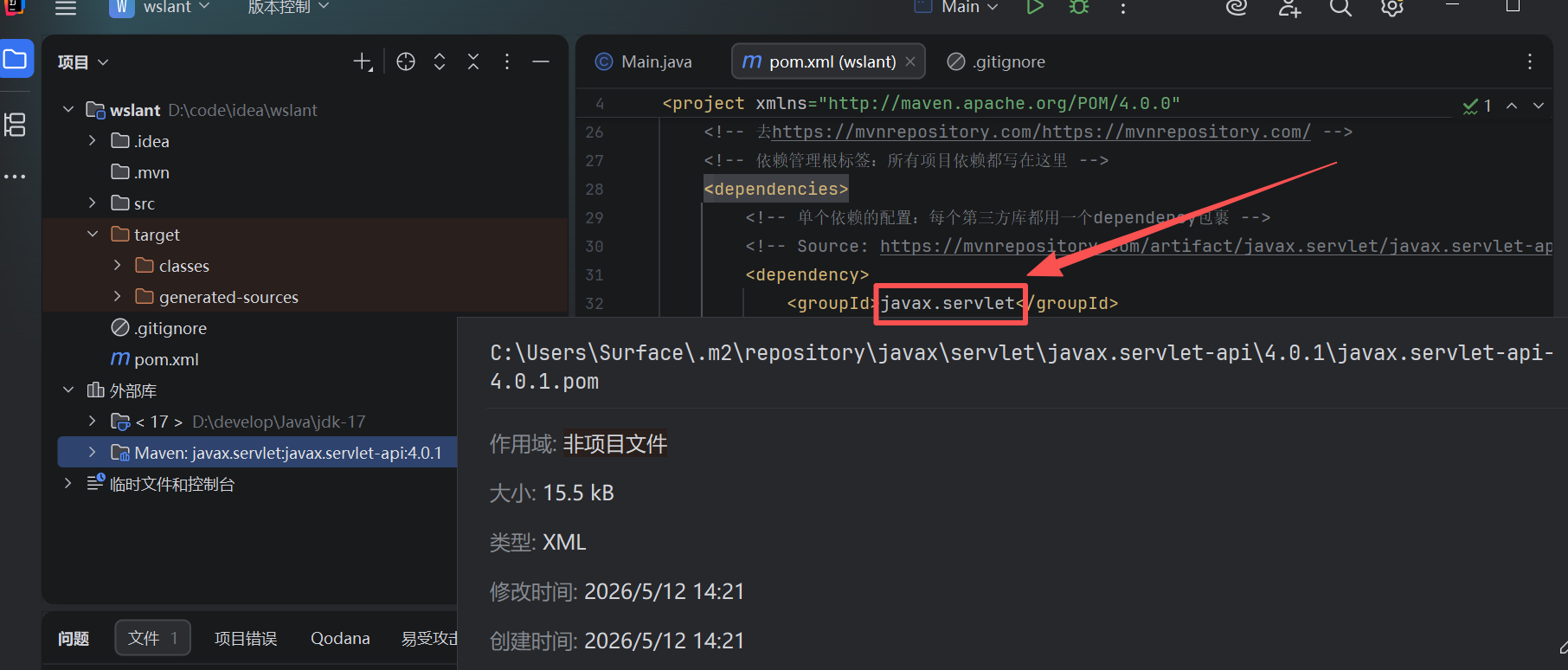
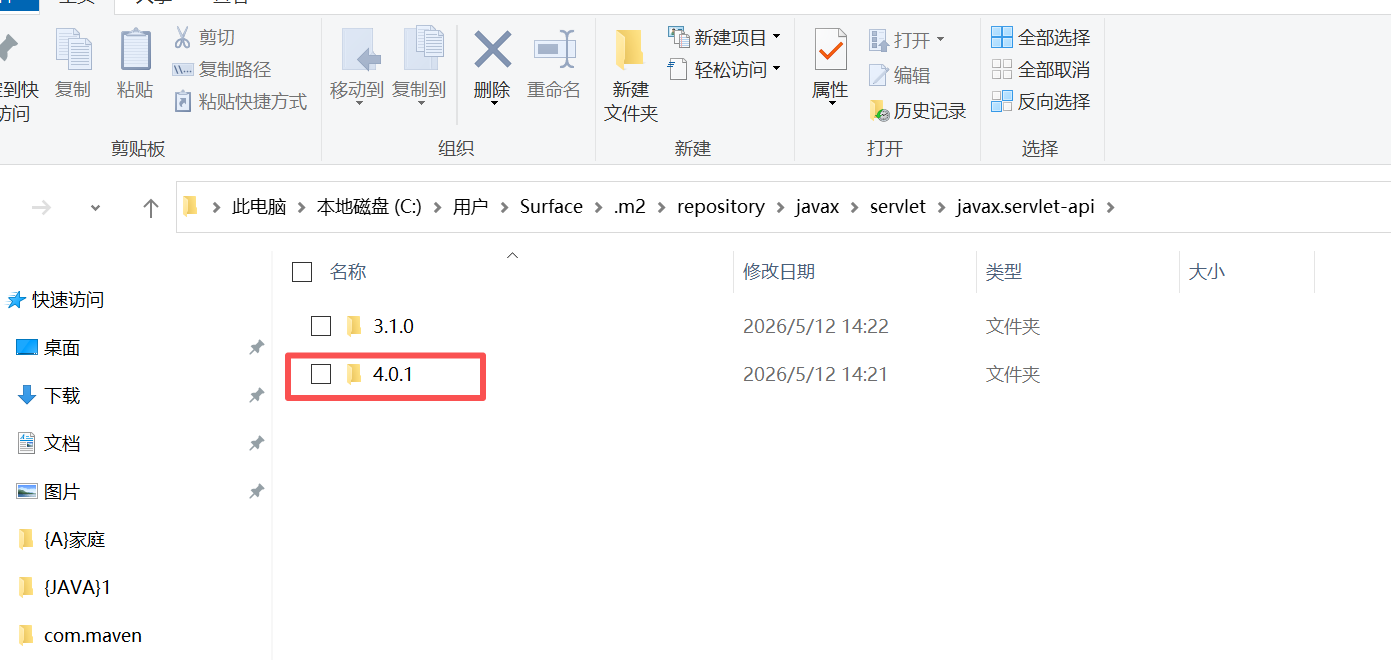
如何删除它,鼠标指上去他会告诉你地址,找到,并删除就行了。
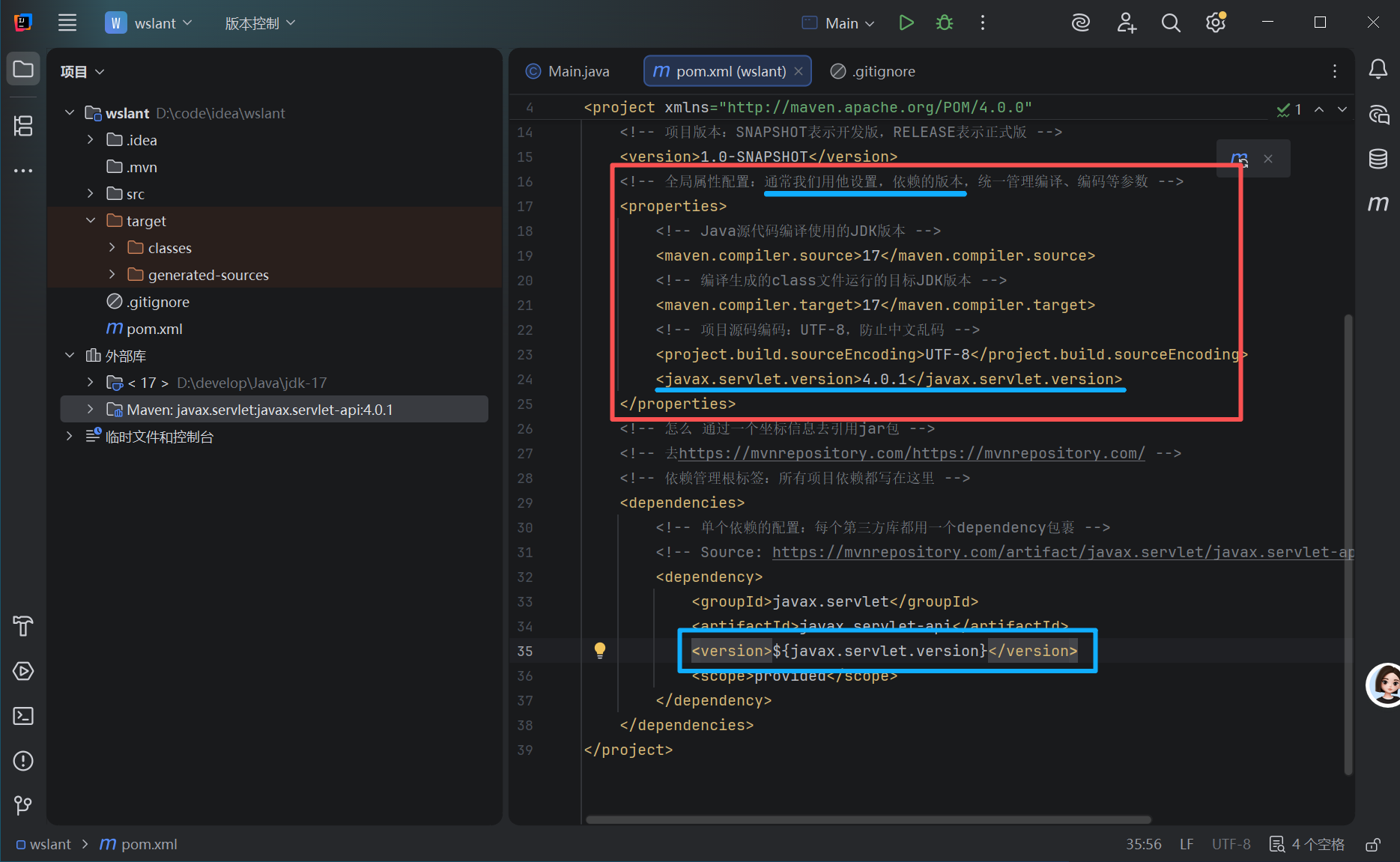
全局调整依赖的版本,加二条下面的命令,好处就是,版本号想变就直接变,再更新就是了。
这样做的目的:为了多个地方都可以调用一个地方的版本号
<javax.servlet.version>4.0.1</javax.servlet.version>
<version>${javax.servlet.version}</version>
大厂 Java 架构师视角:
Maven 项目生成后,标准落地步骤(纯实战流程)
我以阿里 / 京东 / 腾讯等大厂的标准开发规范,给你还原拿到需求 → 生成 Maven 项目后,架构师 / 资深开发第一时间会做的事,这是生产级项目的标准初始化流程,不是简单的写代码。
第一步:统一 Maven 基础配置(必须先做,否则项目无法协作)
生成好 Maven 骨架后,第一件事不是写业务代码,而是规范项目结构 + 锁定 Maven 配置,保证团队所有人环境一致。
1. 校验并修正 pom.xml 核心配置
|
xml |
2. 配置 Maven 私服 / 镜像(大厂必备)
修改 settings.xml,使用公司内部 Maven 私服,禁止直接拉公网依赖:
|
xml |
第二步:搭建标准项目目录结构(大厂分层架构)
Maven 默认结构太简单,生产项目必须按分层架构重建目录,这是架构师核心工作之一:
|
Plain Text |
为什么要做?
统一结构 = 团队协作无成本 = 新人快速上手 = 运维 / 测试易理解。
第三步:引入核心基础依赖(只加必要的,拒绝臃肿)
架构师会最小化依赖原则,只引入项目必需的核心 Starter:
SpringBoot 项目必选依赖
|
xml |
架构师原则: 不用的依赖绝对不加,避免依赖冲突、包过大、启动慢。
第四步:搭建项目基础能力骨架(通用能力,所有业务都要用)
这是最关键的一步,写完这些,业务代码才能快速开发:
- 统一返回结果封装
Result<T> + 响应码枚举,所有接口统一格式。
- 全局异常处理器
@RestControllerAdvice 捕获所有异常,统一返回错误信息。
- 统一日志规范
配置 logback/log4j2,按环境区分日志级别。
- 跨域配置 CORS
前端联调必备。
- 接口文档(Swagger/Knife4j)
自动生成 API 文档,测试 / 前端直接用。
- 环境配置拆分
application.yml
application-dev.yml(开发)
application-test.yml(测试)
application-prod.yml(生产)
第五步:做基础可运行验证(冒烟测试)
- 写一个 HealthController 健康检查接口
- 启动项目,访问接口,确保:
- 项目正常启动
- 统一返回体生效
- 全局异常生效
- 日志正常打印
- 执行 mvn clean package,确保打包无报错
第六步:代码规范 + Git 初始化(协作准备)
- 引入 阿里编码规范插件
- 配置 .gitignore(排除 idea、target、日志等)
- 初始化 Git 仓库,提交第一个版本:feat: 项目初始化
- 编写 README.md(项目说明、启动方式、环境配置)
第七步:对接需求,拆分模块
基础骨架搭好后,才开始真正的需求开发:
- 梳理需求 → 拆分接口
- 设计数据库表
- 定义 VO/DTO/Entity
- 开发 Controller → Service → Dao 分层代码
架构师总结:核心逻辑
生成 Maven 项目 ≠ 开始写业务代码
正确顺序(大厂标准):
- 统一 Maven 配置
- 标准分层目录
- 核心基础依赖
- 通用能力封装(统一返回、异常、日志、文档)
- 基础验证
- 代码规范 + Git
- 业务开发
这套流程能保证:项目可维护、可扩展、无坑、团队协作高效。
总结
- Maven 项目生成后第一步永远是规范配置和结构,不是写业务;
- 必须先搭建统一返回、全局异常、日志、接口文档等基础能力;
- 遵循最小依赖、分层架构、环境隔离三大架构原则;
- 基础骨架跑通后,再进入需求开发环节。
可以直接让AI给你生成一份可直接使用的生产级 pom.xml + 通用基础代码包(统一返回、全局异常、接口文档、日志配置),你拿到就能直接开发业务。
如何锚定pom.xml 需配置哪些依赖?
作为大厂 Java 架构师,判断 pom.xml 需配置哪些依赖,核心是「需求驱动 + 架构规范 + 经验沉淀」,绝非凭感觉添加,全程遵循「最小必要、版本可控、无冲突」三大原则,具体判断逻辑分 5 步(纯生产实战,无多余理论):
1. 先锚定「项目核心框架」(基础依赖,必选)
首先明确项目的核心技术栈,这是依赖选择的前提,架构师会根据需求和公司技术规范,确定核心框架,进而锁定基础依赖:
- 若为 SpringBoot 单体项目:必加
spring-boot-starter-web(web 核心)、spring-boot-starter-test(测试),这是基础骨架,所有 web 项目都离不开; - 若为微服务项目:在单体基础上,需加 Spring Cloud 相关依赖(如 nacos、feign、gateway),且必须通过
dependencyManagement统一版本(避免微服务间依赖冲突); - 若为非 web 项目(如定时任务、工具类项目):无需加 web 依赖,仅保留核心框架和必要工具依赖即可。
2. 按「业务需求」拆解依赖(按需添加,不冗余)
架构师会把需求拆解为具体的技术场景,每个场景对应明确的依赖,拒绝 “堆砌依赖”:
- 需操作数据库:加 MyBatis 相关(
mybatis-spring-boot-starter)或 JPA(spring-boot-starter-data-jpa),搭配数据库驱动(MySQL 则加mysql-connector-java); - 需缓存:加 Redis 依赖(
spring-boot-starter-data-redis),搭配连接池(如 lettuce); - 需接口文档:加 Knife4j/Swagger(
knife4j-spring-boot-starter,大厂首选,比原生 Swagger 更友好); - 需处理 JSON:无需额外加 Jackson(SpringBoot 默认集成),避免重复引入;
- 需工具类:加 Hutool(
hutool-all),大厂标配,替代自研工具类,减少重复开发。
3. 遵循「公司架构规范」(统一标准,避免混乱)
大厂都有成熟的技术规范和依赖版本库,架构师不会随意选择依赖,必须对齐规范:
- 版本统一:公司会维护「依赖版本清单」(如 SpringBoot 固定 2.7.x/3.1.x,Hutool 固定 5.8.x),所有项目统一使用,避免版本碎片化;
- 依赖选型:禁止使用小众、无维护、有安全漏洞的依赖(如避免使用过时的 Commons Lang 2,改用 Lang 3 或 Hutool);
- 私服限制:只能从公司 Maven 私服拉取依赖,公网依赖需提前报备,防止安全风险和依赖拉取失败。
4. 规避「依赖冲突」(架构师核心考量)
这是判断依赖的关键,架构师会通过经验和工具,提前避免冲突:
- 优先使用 SpringBoot Starter:Starter 已帮我们整合好了相关依赖(如
spring-boot-starter-web包含 tomcat、spring-web、spring-webmvc),无需手动添加子依赖,减少冲突; - 用 dependencyManagement 锁定版本:只声明依赖版本,不实际引入,子模块按需引入时,自动使用统一版本;
- 排查冲突:通过
mvn dependency:tree命令查看依赖树,排除冲突依赖(如排除某个依赖自带的 commons-logging,避免与 logback 冲突)。
5. 结合「经验沉淀」(避坑关键)
资深架构师会根据过往项目经验,规避 “踩过的坑”,优化依赖选择:
- 避免引入冗余依赖:如引入
spring-boot-starter-web后,无需再单独引入 tomcat 依赖,否则会造成冲突; - 优先选择轻量依赖:如工具类用 Hutool(单包,无多余依赖),而非引入多个零散工具包;
- 考虑可维护性:选择社区活跃、更新频繁的依赖(如 Knife4j 替代 Swagger2,解决 Swagger2 的兼容性问题)。
核心总结
架构师选择依赖的逻辑:「先定框架→再按需求拆场景→对齐公司规范→规避冲突→结合经验优化」,核心是 “用最少的依赖,满足所有技术需求”,既保证项目稳定,又降低维护成本。
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)