
Claude Code 浏览器搭子来了!这个 5k Star 神器让 CC 直接用你的真实 Chrome 拿数据
👉 这是一个或许对你有用的社群
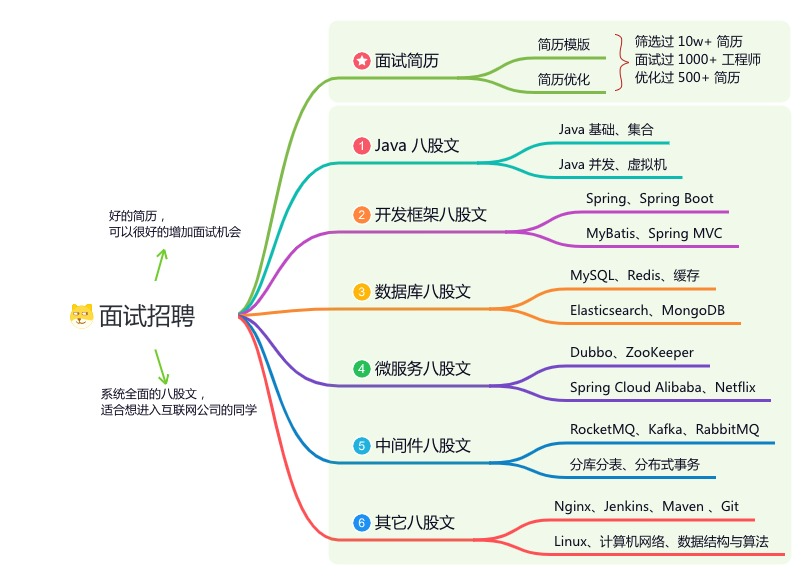
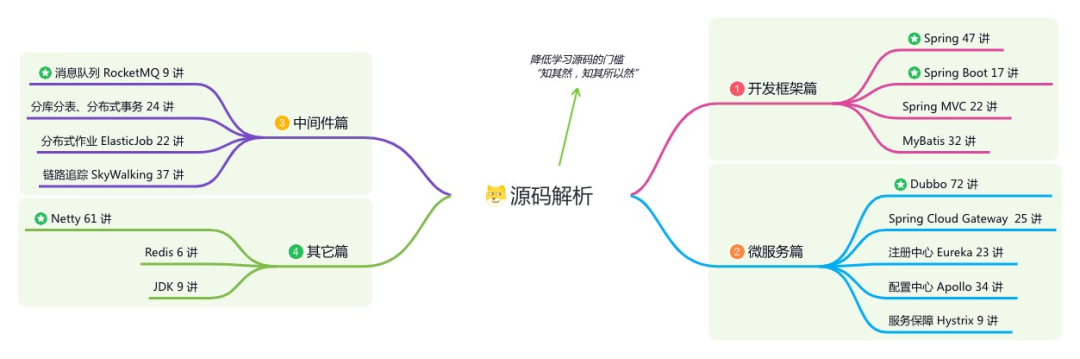
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
-
《项目实战(视频)》:从书中学,往事中“练”
-
《互联网高频面试题》:面朝简历学习,春暖花开
-
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
-
《精进 Java 学习指南》:系统学习,互联网主流技术栈
-
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
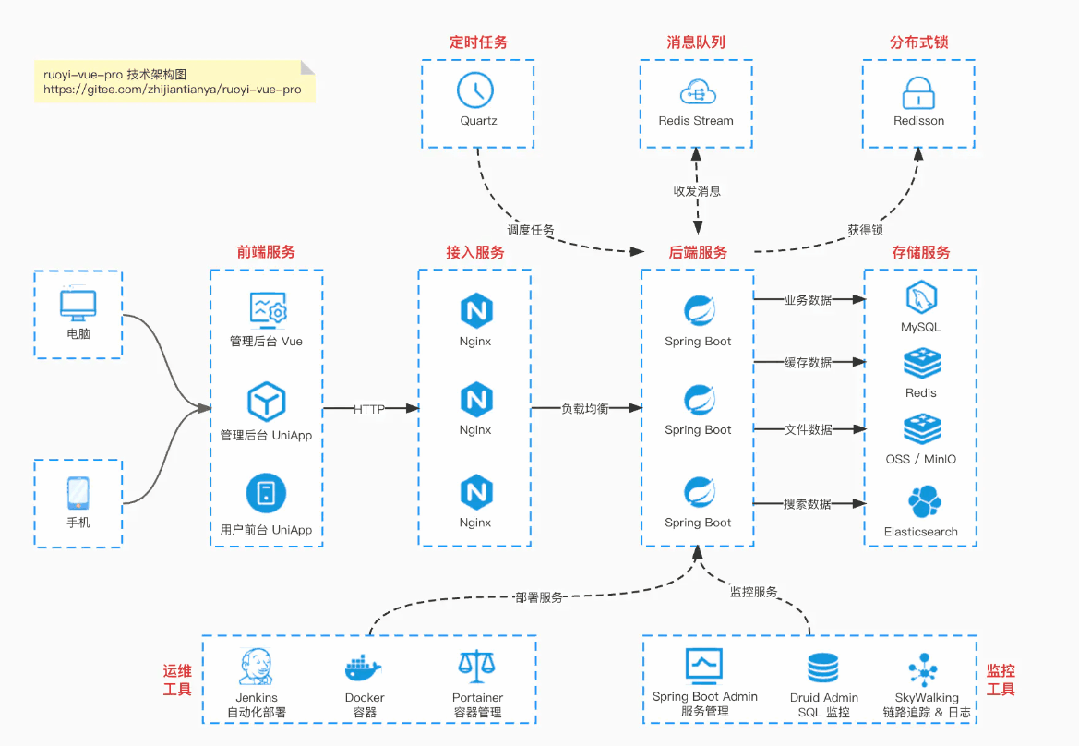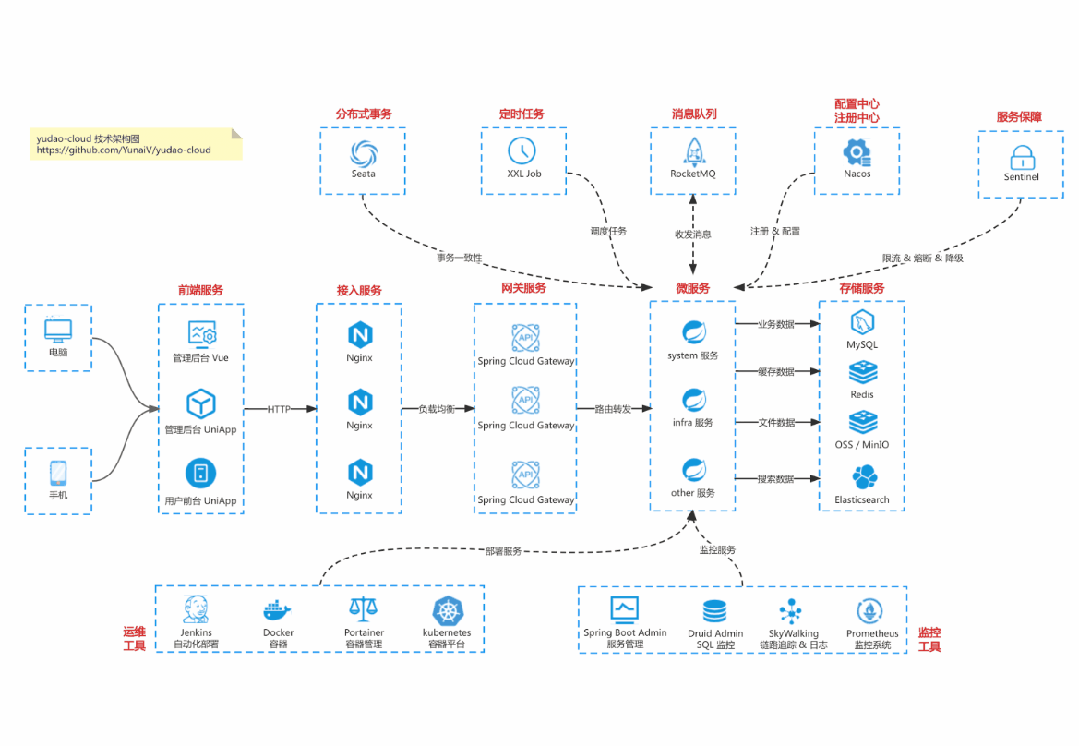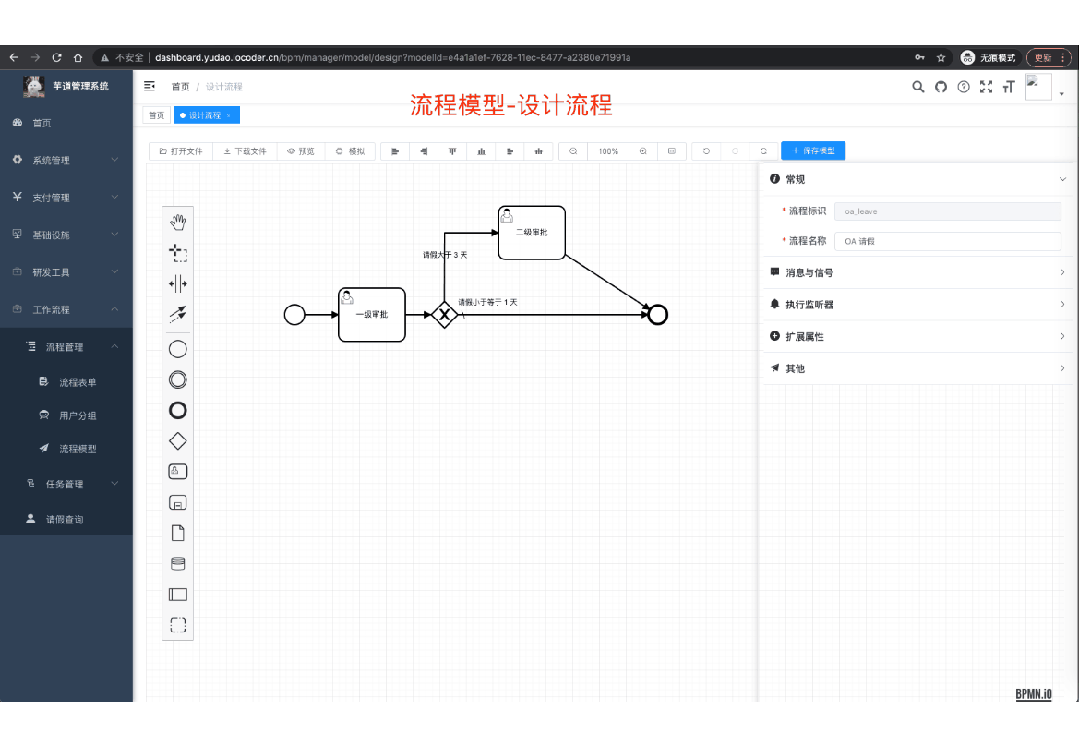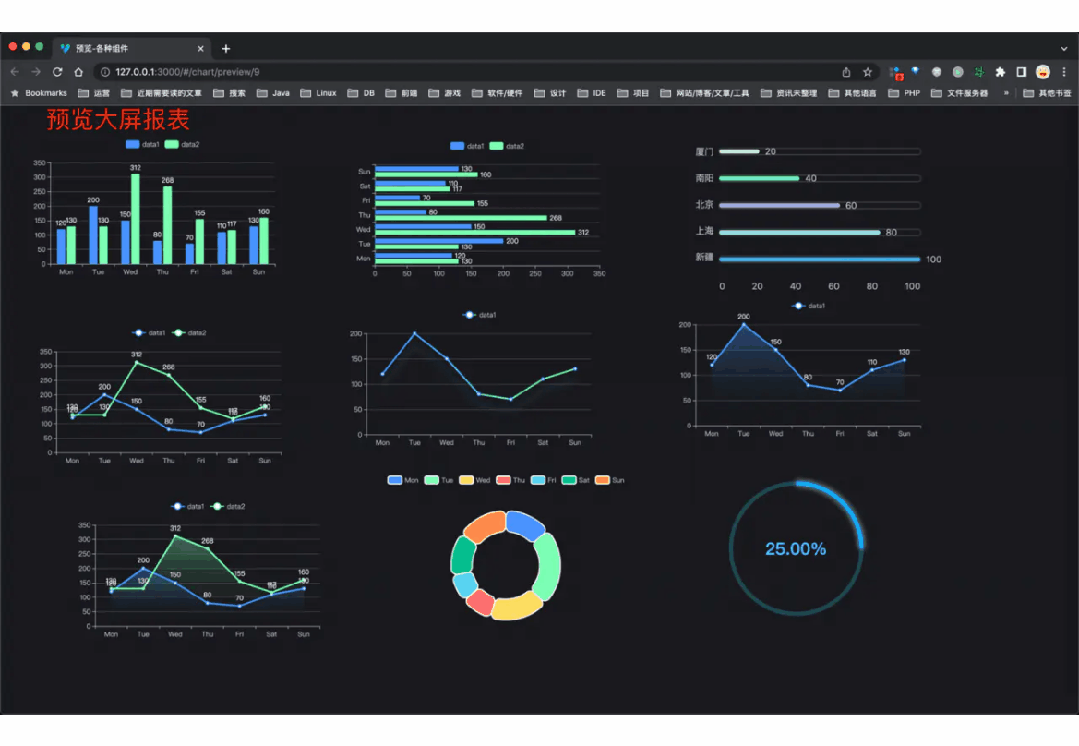
国产Star破10w的开源项目,前端包括管理后台、微信小程序,后端支持单体、微服务架构
RBAC权限、数据权限、SaaS多租户、商城、支付、工作流、大屏报表、ERP、CRM、AI大模型、IoT物联网等功能:
多模块:https://gitee.com/zhijiantianya/ruoyi-vue-pro
微服务:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK17/21+SpringBoot3、JDK8/11+Spring Boot2双版本

让 AI 联网拿数据:每个研发都翻过的车
最近用 Claude Code 做一个调研——让它帮我对比几个框架在 GitHub 上的 Issue 趋势 + Stack Overflow 的讨论热度。
结果直接卡死 :
-
❌ GitHub REST API 有频率限制 ——一天能打的接口数有上限;
-
❌ Stack Overflow API 要申请 key ——填表 → 等审核 → 几天才下来;
-
❌ 知乎 / 小红书 / 微博 / B 站 ——根本没有公开 API 。
最后只剩两条路 ——要么手动搜手动复制粘贴丢给 Agent;要么让 Agent 自己去抓网页 HTML 再自己解析——慢、乱、动不动被反爬 。
这事不只你遇到 ——身边用 Cursor / Claude Code / OpenClaw 做 Agent 的朋友 90% 都吐过同一个槽:
让 AI 联网拿数据,比想象中难多了 。
直到我装了 bb-browser ——这个 5k Star、最新版 v0.11.5(2026-05-07)的开源神器——终于把这个口子堵上。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
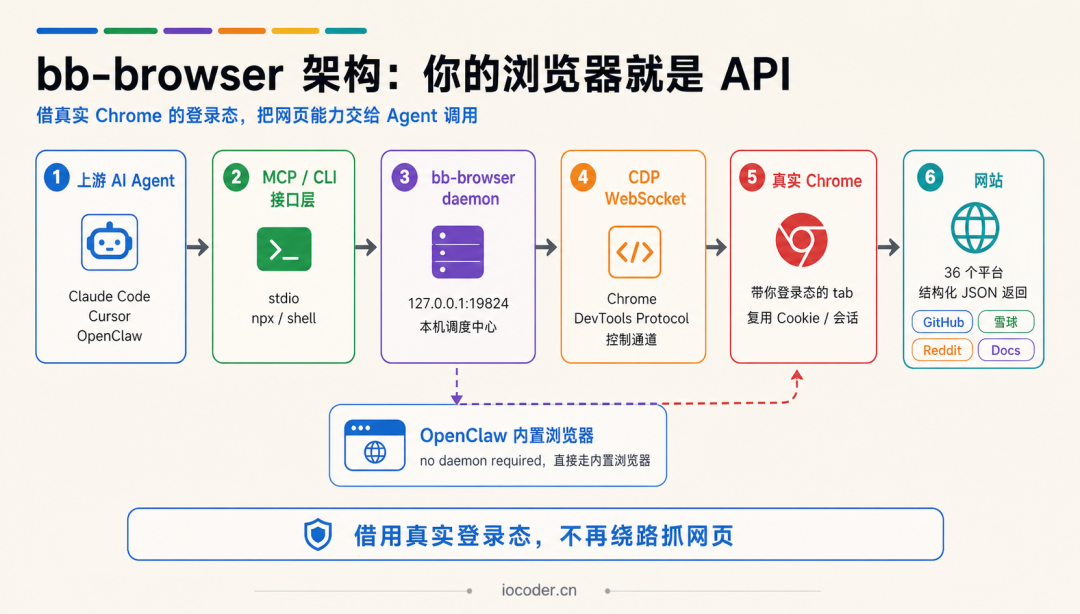
bb-browser 是什么:你的浏览器就是 API
bb-browser(全名 BadBoy Browser )的设计哲学是 README 里那句话:
"Your browser is the API. CLI + MCP server for AI agents to control Chrome with your login state."
(你的浏览器就是 API ——CLI + MCP 服务,让 AI Agent 用你的登录态操控 Chrome。)
没有比这更直白的定位 ——它让 AI Agent 直接使用你已经登录的 Chrome 浏览器 ——把各种网站当 API 用——不要 API Key、不要爬虫、不要模拟登录 。
目前覆盖 36 个平台、103 条命令 ,全部走你浏览器自己的登录态 。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
它和 Playwright / 爬虫库差在哪:登录态是分水岭
做过爬虫或者浏览器自动化的研发都懂——这块有几个老大难问题 :
|
方案 |
浏览器 |
登录态 |
反爬检测 |
|---|---|---|---|
| Playwright / Selenium | 无头浏览器
(隔离环境) |
❌ 没有,要重新登录 |
⚠️ 容易识别 |
| Python requests / 爬虫库 | 没有浏览器 |
❌ 偷 Cookie |
⚠️ 猫鼠游戏 |
| bb-browser | 你的真实 Chrome |
✅ 已经在了 |
✅ 无法检测——它就是用户 |
bb-browser 的思路完全反过来 ——不让网站适配机器,而是让机器用人的界面 。
具体怎么做:
-
bb-browser 本地 daemon 起在
127.0.0.1:19824,通过 CDP(Chrome DevTools Protocol)WebSocket 直连你正在跑的 Chrome; -
在你的浏览器 tab 里执行
eval,用你的 Cookie 直接调fetch(); -
或者注入页面的 webpack 模块 调用网站自己的内部方法。
网站看到的是什么?是一个正常登录的用户在正常操作 ——因为,就是你 。
详细对比表 :
|
对比项 |
Playwright / Selenium |
爬虫库 |
bb-browser |
|---|---|---|---|
|
浏览器 |
无头、隔离环境 |
无浏览器 |
你的真实 Chrome |
|
登录态 |
没有,要重新登录 |
偷 Cookie |
已经在了 |
|
反爬检测 |
容易被识别 |
猫鼠游戏 |
无法检测,它就是用户 |
|
复杂鉴权(CSRF / OAuth) |
无法复制 |
需要逆向 |
页面自己处理 |
|
致命短板 |
维护脆弱 |
反爬就崩 |
必须依赖 Chrome 一直跑 |
覆盖范围:36 个平台、103 条命令
直接看 README,这是目前社区维护的覆盖范围 ——常用的基本都在:
|
类别 |
平台 |
可用命令 |
|---|---|---|
| 搜索 |
Google / 百度 / Bing / DuckDuckGo / 搜狗微信 |
search |
| 社交 |
Twitter/X / Reddit / 微博 / 小红书 / 即刻 / LinkedIn / 虎扑 |
search
/ |
| 新闻 |
BBC / Reuters / 36氪 / 头条 / 东方财富 |
headlines
/ |
| 技术 |
GitHub / StackOverflow / HackerNews / CSDN / 博客园 / V2EX / arXiv / npm / PyPI |
search
/ |
| 视频 |
YouTube / B站 |
search
/ |
| 影音 |
豆瓣 / IMDb / 起点中文网 |
movie
/ |
| 财经 |
雪球 / 东方财富 / Yahoo Finance |
stock
/ |
| 求职 |
BOSS直聘 / LinkedIn |
search
/ |
| 百科 |
Wikipedia / 知乎 / Open Library |
search
/ |
| 购物 |
什么值得买 |
search |
| 工具 |
有道翻译 / GSMArena / Product Hunt / 携程 |
translate
/ |
每个命令背后是一个独立的 JS 文件——配套仓库叫 bb-sites,社区驱动维护 。新增一个网站 = 加一个 JS 文件 ——门槛极低。
3 种接入路径:CLI / MCP / OpenClaw
按你用的工具挑一条——没有任何一条需要装 Chrome 扩展 ,daemon 自己走 CDP 直连本机 Chrome。
路径 A:CLI 基础包(最快上手)
npm install -g bb-browser
bb-browser site update # 拉社区适配器装完直接跑 :
bb-browser site zhihu/hot # 知乎热榜
bb-browser site github/repo epiral/bb-browser # 某个 GitHub repo 信息
bb-browser site boss/search "AI engineer" # 搜职位
bb-browser site youtube/transcript VIDEO_ID # YouTube 字幕全文路径 B:MCP(Claude Code / Cursor 接入)
mcp.json 加一段就行:
{
"mcpServers": {
"bb-browser": {
"command": "npx",
"args": ["-y", "bb-browser", "--mcp"]
}
}
}路径 C:OpenClaw 内置浏览器(最省事)
官方原话 :*"bb-browser runs directly through OpenClaw's built-in browser — no Chrome extension or daemon required"*——不装扩展也不开 daemon :
bb-browser site reddit/hot --openclaw
bb-browser site xueqiu/hot-stock 5 --openclaw --jq '.items[] | {name, changePercent}'进阶补充:本机要直连真实 Chrome 的话 ,CDP 通道由 bb-browser daemon 自动建立——不用你额外配置;如果你想看 daemon 干了啥,去
127.0.0.1:19824翻日志即可。
所有命令输出都是结构化 JSON ——支持 --json + --jq 内联过滤:
# 雪球实时涨跌幅前 5
bb-browser site xueqiu/hot-stock 5 --jq '.items[] | {name, changePercent}'
# {"name":"云天化","changePercent":"2.08%"}
# {"name":"东芯股份","changePercent":"-7.60%"}结果干净的 JSON——传给后续 Agent 或脚本极方便 。
接进后能干啥:4 个研发高频用例
走完上面任意一条路径接进 Claude Code / Cursor / OpenClaw 后,Agent 自己就能拉数据 :
|
场景 |
跟 Agent 这么说 |
|---|---|
|
调研某个 GitHub 项目 |
"帮我拉 epiral/bb-browser 这个仓库最近 10 个 issue、按热度排 " |
|
arXiv 搜论文 |
"搜 'token reduction LLM' 这两年发的 paper " |
|
看 Twitter 话题 |
"Twitter 上 'Claude Code' 这话题最近一周的热门讨论 " |
|
比对职位 |
"BOSS 上 'Java 后端 北京' 30 个岗位、按薪资排序 " |
这些以前要么靠 API key、要么靠手动复制粘贴——现在 Agent 自己搞定 。
10 分钟把任何网站 CLI 化:3 级复杂度
这功能我觉得最有意思——而且项目组测试过 :
跟 Agent 说「帮我把 XX 网站 CLI 化」 ,它会自己读项目里的 guide → 用
network --with-body抓包逆向 → 写 adapter → 测试 → 提 PR 到社区仓库 。全程不用你盯着 。
项目把 adapter 复杂度分 3 级:
|
层级 |
认证方式 |
代表网站 |
耗时 |
|---|---|---|---|
| Tier 1 |
Cookie(直接 fetch) |
Reddit / GitHub / V2EX |
约 1 分钟 |
| Tier 2 |
Bearer + CSRF token |
Twitter / 知乎 |
约 3 分钟 |
| Tier 3 |
Webpack 注入 / Pinia store |
Twitter 搜索 / 小红书 |
约 10 分钟 |
项目组实测的数据 :20 个 AI Agent 并发运行 ——每个独立逆向一个网站、产出可用的 adapter——把一个新网站纳入 Agent 可访问范围的成本已经压得极低了 。
用之前要清楚的 3 件事
按踩到概率从高到低排:
边界 1(最常见):Chrome 必须保持运行
bb-browser 依赖你的 Chrome 一直开着 ——浏览器关了 / 网络切了——Daemon 立马断 。
修法 :① 笔记本上把 Chrome 设成开机启动 + 至少留一个标签页;② 重要任务跑完前别关 Chrome ——这条很反直觉但很重要。
边界 2(常见):本质是在你浏览器里执行代码
安全提醒——这是 README 都强调的 :bb-browser 的工作原理就是在你的浏览器 tab 里 eval 代码 + 注入 webpack ——接入第三方 Agent 时要评估信任边界 。
修法 :① 优先接你信任的 Agent(Claude Code / Cursor / OpenClaw);② 别给来路不明的 Agent 配 bb-browser 的 MCP;③ 重要账号用单独的 Chrome Profile 跑——和日常账号隔离。
边界 3(少见但破坏力大):远程调用要小心
Daemon 默认绑 127.0.0.1:19824——可以改成监听 0.0.0.0 ,配 Tailscale / ZeroTier 远程调用自己的浏览器。这个玩法很爽——但要意识到把"浏览器执行权"暴露给了网络 。
修法 :远程访问只走 Tailscale / ZeroTier 这种私有网络 ——别裸奔在公网 。
我的判断
AI Agent 落地最大的卡点之一就是「信息获取」 ——Agent 能写代码、能跑命令、但它看不到互联网上正在发生的事情、或者看到的太滞后、太残缺 。
没有 bb-browser 的时候 :AI Agent 的世界 = 文件 + 终端 + 少数有 API key 的服务;有了 bb-browser 之后 :多了整个互联网 。
bb-browser 走的这条路,我觉得挺对的 ——不和网站讲条件,直接借用用户自己的登录状态 。这个设计哲学简单粗暴,但有效 。
适合用的几种情况 :
-
用 Claude Code / Cursor / OpenClaw 做调研、信息收集;
-
想让 Agent 同时拉国内外多个平台 的数据(GitHub + 知乎 + B 站 + V2EX);
-
习惯每天看 5 个 App 凑信息 ——bb-browser 让 Agent 替你做这件事。
不太适合 :
-
重型生产环境的爬虫——这不是它的目标;
-
不想保持 Chrome 一直开——bb-browser 没法用。
最后说一句 :bb-browser 这种"借用人的登录态"思路,未来一年应该会成为 AI Agent 的标配工具组件 ——比 SerpAPI / Tavily 这种付费搜索 API 更通用、比无头浏览器更稳定 ——这条路对了 。

仓库:https://github.com/epiral/bb-browser
适配器仓库:https://github.com/epiral/bb-sites
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)更多推荐



 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)