
python爬虫4K高清美女壁纸
·
简介:
- 一次爬取20张图片,可以更改这段代码的数值,改变下载图片数量:if success_count >= 20:
- 图片存放到D:\pachong1,可以更改这段代码的值修改存放地址:SAVE_DIR = r"D:\pachong1"
- 需要安装对应的库,使用:pip install 库名来安装需要的库
代码:
"""
AURA 壁纸爬虫 - 摄影美女专题
爬取 https://gallery.wallaura.cn/?t=摄影美女 上的图片
保存到 D:\pachong1,爬取20张 真图(跳过占位图<100KB)
"""
import os
import time
import json
import hashlib
import base64
import requests
from Crypto.Cipher import AES
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
SAVE_DIR = r"D:\pachong1"
os.makedirs(SAVE_DIR, exist_ok=True)
def encrypt_md5(text):
return hashlib.md5(text.encode()).hexdigest()
def decrypt_aes(cipher_text, key):
if not cipher_text or not key:
return ""
key = (key * 16)[-16:]
md5_key = encrypt_md5(key)
iv = md5_key[8:24]
try:
raw = bytes.fromhex(cipher_text)
b64_data = base64.b64encode(raw).decode()
except:
return cipher_text
try:
cipher = AES.new(key.encode('utf-8'), AES.MODE_CBC, iv.encode('utf-8'))
decrypted = cipher.decrypt(base64.b64decode(b64_data))
return decrypted.rstrip(b'\x00').decode('utf-8')
except:
return cipher_text
def decrypt_url(img_url, provider):
if not img_url or not provider:
return ""
parts = img_url.split("?")
path_parts = parts[0].split("/")
filename = path_parts[-1]
name_parts = filename.split(".")
if len(name_parts[0]) < 32:
return img_url
encrypted = name_parts[0][:32]
remaining = name_parts[0][32:]
decrypted = decrypt_aes(encrypted, provider)
name_parts[0] = decrypted + remaining
path_parts[-1] = ".".join(name_parts)
parts[0] = "/".join(path_parts)
return "?".join(parts)
def try_download(img_url, save_path, index):
"""尝试下载,如果是占位图(<100KB)返回False"""
headers_list = [
{
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": "https://gallery.wallaura.cn/",
},
{
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
},
]
for attempt, headers in enumerate(headers_list):
try:
resp = requests.get(img_url, headers=headers, timeout=30)
if resp.status_code == 200:
size_kb = len(resp.content) / 1024
if size_kb < 100:
print(f" [占位图 {size_kb:.1f}KB] 跳过")
return False
with open(save_path, "wb") as f:
f.write(resp.content)
print(f" [OK] 第{index}张 ({size_kb:.1f} KB)")
return True
except Exception as e:
print(f" 尝试{attempt+1}异常: {e}")
time.sleep(0.5)
return False
def main():
print("=" * 60)
print("AURA 壁纸爬虫 - 摄影美女专题 (只下真图)")
print("=" * 60)
chrome_options = Options()
chrome_options.add_argument('--headless=new')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--window-size=1920,1080')
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
driver = webdriver.Chrome(options=chrome_options)
try:
print("\n[1/2] 正在获取图片数据...")
driver.get("https://gallery.wallaura.cn/?t=%E6%91%84%E5%BD%B1%E7%BE%8E%E5%A5%B3")
time.sleep(6)
data_json = driver.execute_script("""
if (typeof DATA_CACHE !== 'undefined' && DATA_CACHE.length > 0) {
var items = [];
for (var i = 0; i < DATA_CACHE.length; i++) {
var item = DATA_CACHE[i];
if (!item.rawprovider || !item.rawid) continue;
var imgurl = item.imgurl || item.thumburl || '';
if (!imgurl) continue;
var decrypted = imgurl;
try { decrypted = decryptUrl(imgurl, item.rawprovider); } catch(e) {}
items.push({
provider: item.rawprovider,
rawid: item.rawid,
url: decrypted
});
}
return JSON.stringify(items);
}
return '[]';
""")
items = json.loads(data_json)
print(f"获取到 {len(items)} 张图片")
if not items:
print("没有获取到图片!")
return
print(f"\n[2/2] 开始下载,跳过占位图(<100KB)直到凑满20张...")
success_count = 0
for i, item in enumerate(items):
if success_count >= 20:
break
print(f"\n--- [{success_count+1}/20] 第{i+1}/{len(items)}张 ---")
print(f" 来源: {item['provider']}, ID: {item['rawid']}")
print(f" URL: {item['url'][:100]}...")
url_path = item['url'].split("?")[0]
ext = os.path.splitext(url_path)[1] or ".jpg"
if len(ext) > 5:
ext = ".jpg"
file_name = f"aura_{item['provider']}_{item['rawid']}{ext}"
save_path = os.path.join(SAVE_DIR, file_name)
if try_download(item['url'], save_path, success_count + 1):
success_count += 1
time.sleep(0.3)
print("\n" + "=" * 60)
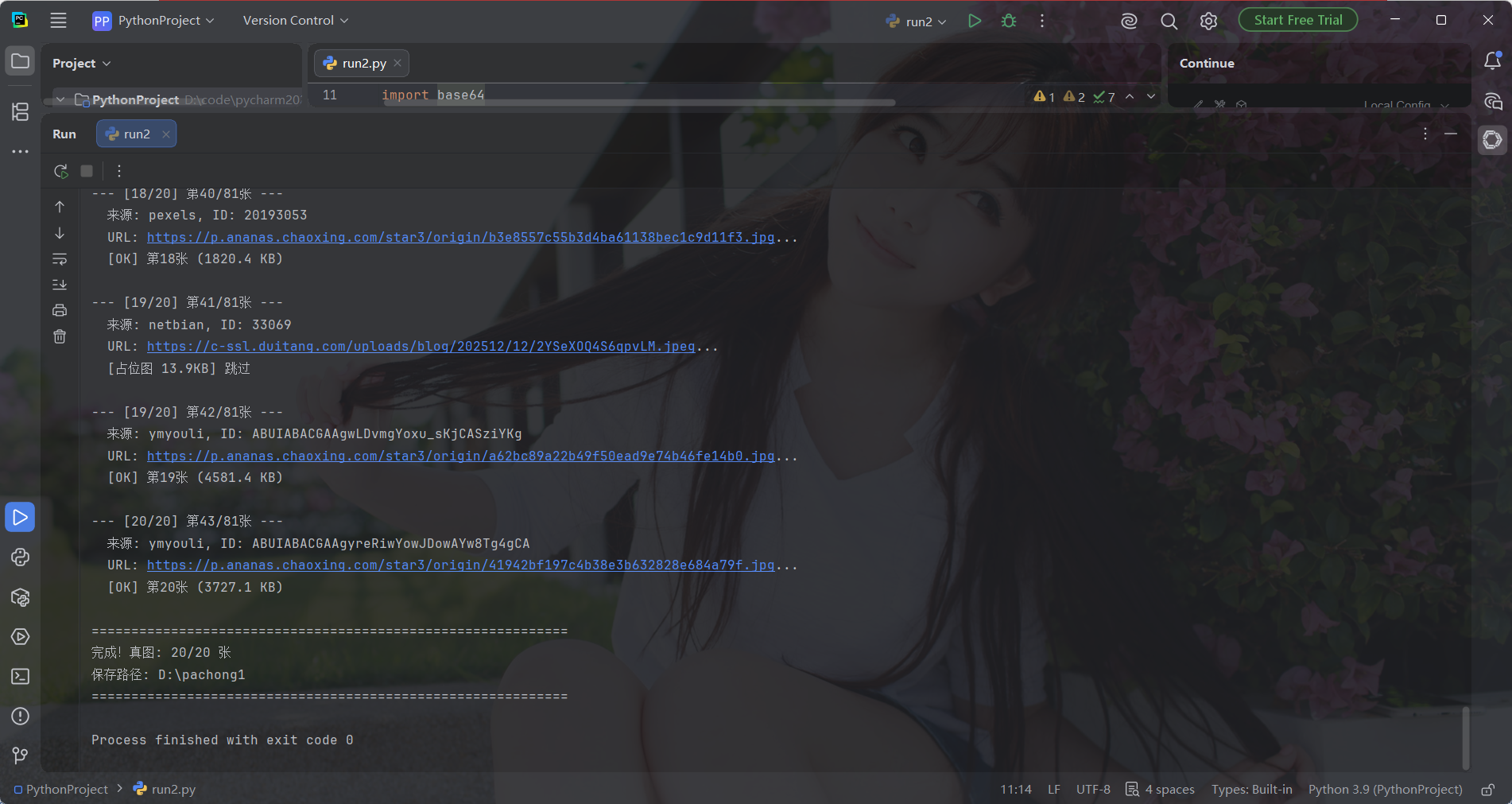
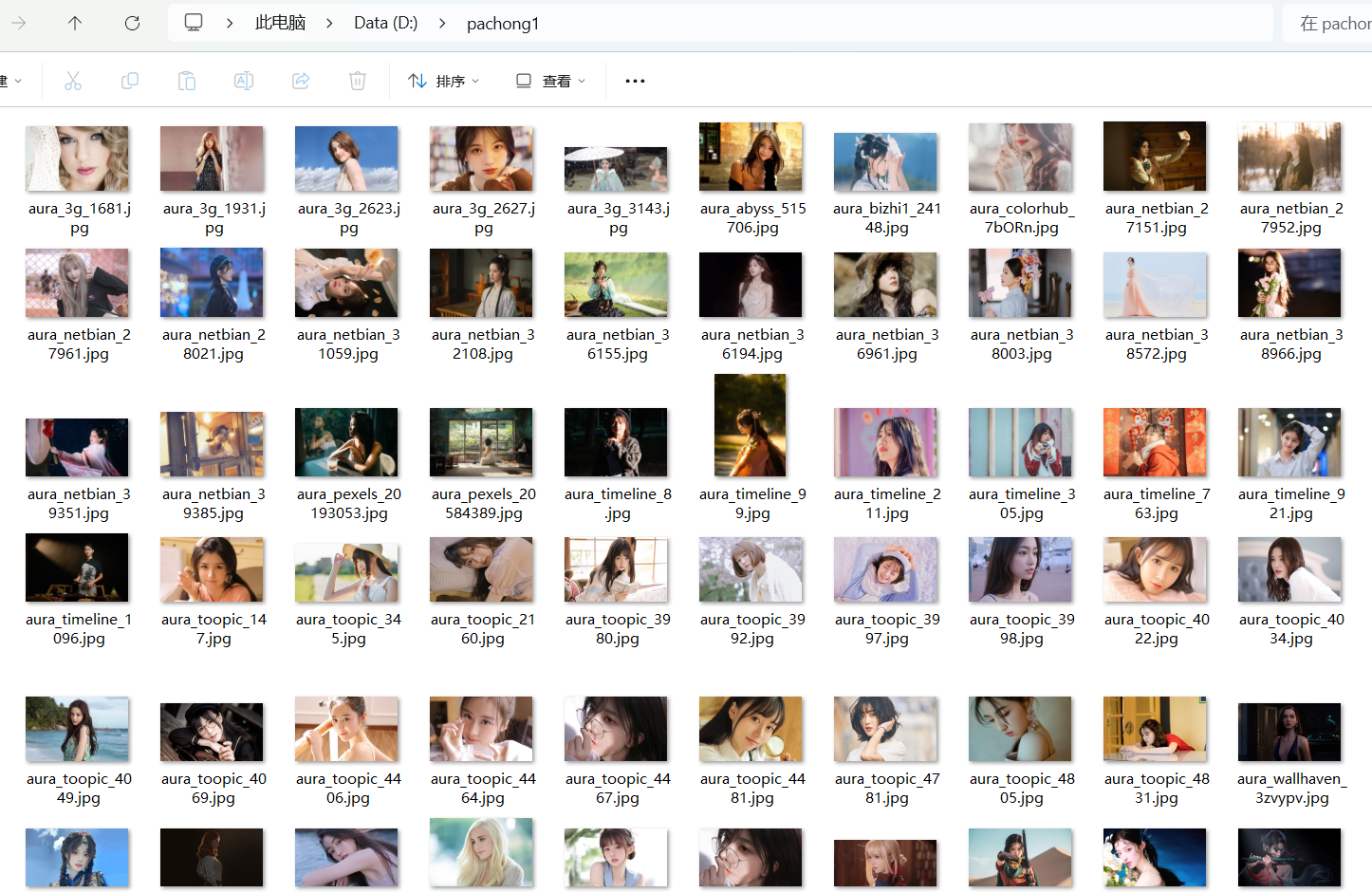
print(f"完成!真图: {success_count}/20 张")
print(f"保存路径: {SAVE_DIR}")
print("=" * 60)
finally:
driver.quit()
if __name__ == "__main__":
main()
运行结果截图:
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)