
Qwen3-VL-4B-Instruct多模态编程实战:从图像生成Draw.io/HTML/CSS/JS的完整指南
Qwen3-VL-4B-Instruct多模态编程实战:从图像生成Draw.io/HTML/CSS/JS的完整指南
【免费下载链接】Qwen3-VL-4B-Instruct  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Instruct
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Instruct
在人工智能快速发展的今天,Qwen3-VL-4B-Instruct作为阿里通义千问系列中最强大的视觉语言模型,为开发者提供了革命性的多模态编程能力。这款先进的AI模型能够从图像直接生成Draw.io图表、HTML代码、CSS样式和JavaScript脚本,彻底改变了传统编程工作流程。本文将为您详细介绍如何快速上手这个强大的视觉编码工具,让您体验从图像到代码的智能转换。
🚀 为什么选择Qwen3-VL-4B-Instruct?
Qwen3-VL-4B-Instruct不仅仅是另一个视觉语言模型,它是一个视觉编码增强的AI助手。想象一下,您只需要上传一张网页截图,模型就能自动生成对应的HTML结构;或者您绘制了一个简单的界面草图,模型就能将其转换为可运行的代码。这就是Qwen3-VL-4B-Instruct带给开发者的超能力!
🌟 核心功能亮点
- 视觉编码增强:从图像/视频生成Draw.io/HTML/CSS/JS
- 视觉代理能力:操作PC/移动端GUI界面,识别元素、理解功能、调用工具、完成任务
- 高级空间感知:判断物体位置、视角和遮挡关系
- 长上下文支持:原生256K上下文,可扩展至1M
- 多模态推理:在STEM/数学领域表现优异,提供因果分析和逻辑推理
📊 模型架构与性能
Qwen3-VL-4B-Instruct采用了创新的Interleaved-MRoPE架构,通过全频率分配的时间、宽度和高度位置嵌入,增强了长序列视频推理能力。DeepStack技术融合多级ViT特征,捕捉细粒度细节并锐化图像-文本对齐。

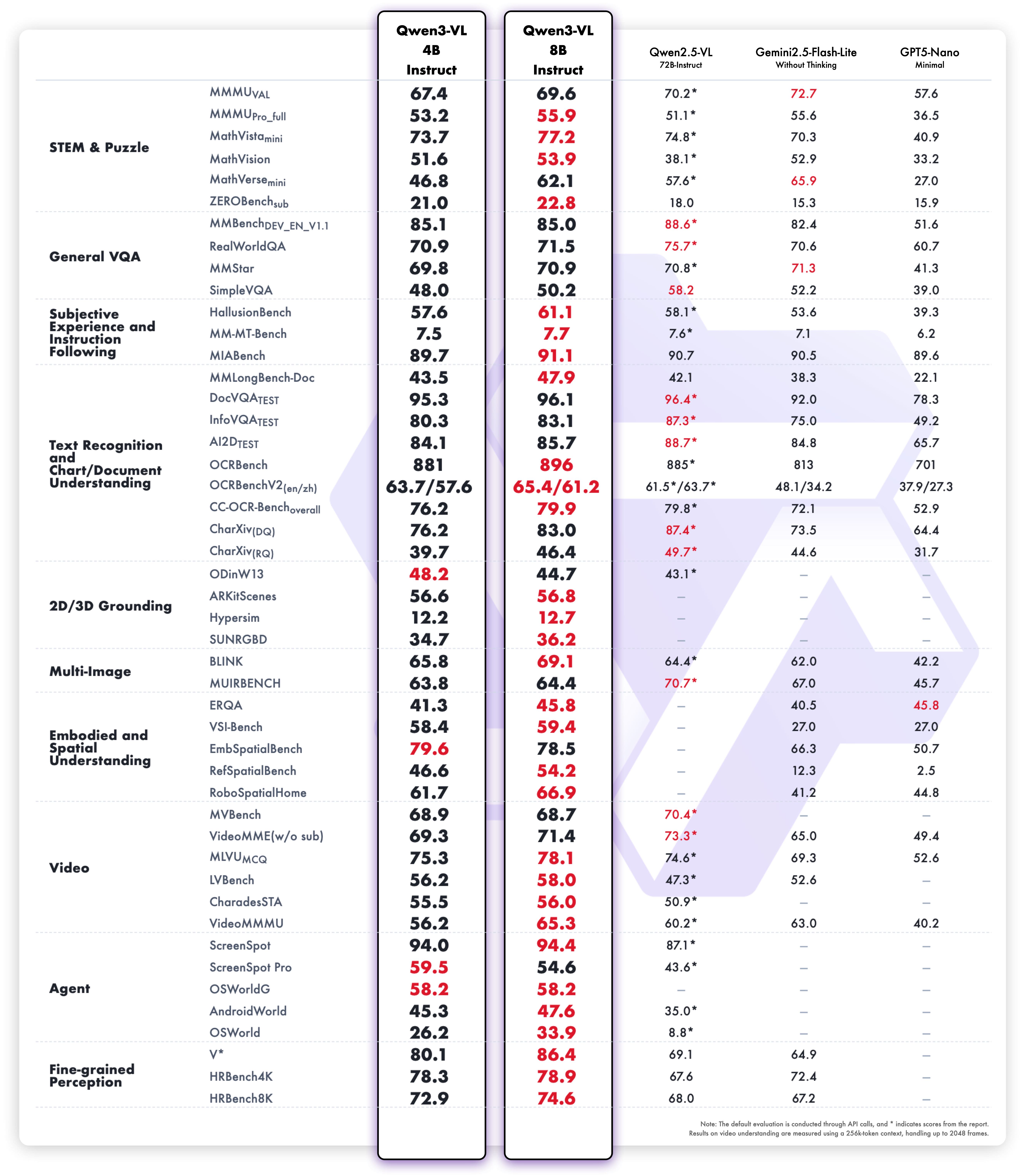
多模态性能表现
🔧 快速安装与配置
环境准备
首先确保您的Python环境已就绪,然后安装最新版本的transformers库:
pip install git+https://github.com/huggingface/transformers
模型加载
Qwen3-VL-4B-Instruct模型文件位于当前仓库,包含以下关键文件:
model.safetensors.index.json- 模型索引文件model-00001-of-00002.safetensors- 模型权重文件(部分1)model-00002-of-00002.safetensors- 模型权重文件(部分2)config.json- 模型配置文件tokenizer.json- 分词器配置
🎯 从图像生成代码实战
步骤1:基础图像描述
让我们从最简单的开始——让模型描述一张图片:
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
# 加载模型
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-4B-Instruct",
dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-4B-Instruct")
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "your_image_path.jpg"},
{"type": "text", "text": "描述这张图片中的界面布局。"},
],
}
]
步骤2:生成HTML代码
现在尝试从界面截图生成HTML结构:
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "website_screenshot.jpg"},
{"type": "text", "text": "根据这张网页截图,生成对应的HTML结构代码。"},
],
}
]
步骤3:生成CSS样式
让模型分析设计风格并生成匹配的CSS:
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "ui_design.jpg"},
{"type": "text", "text": "分析这个UI设计,生成对应的CSS样式代码。"},
],
}
]
📝 配置文件详解
了解模型配置对于优化性能至关重要。主要配置文件包括:
- config.json - 模型架构配置
- generation_config.json - 生成参数配置
- preprocessor_config.json - 预处理配置
- chat_template.json - 对话模板配置
关键配置参数
在config.json中,您会注意到这些重要参数:
max_position_embeddings: 262144- 支持超长上下文hidden_size: 2560- 隐藏层维度num_hidden_layers: 36- 隐藏层数量num_attention_heads: 32- 注意力头数量
🎨 视觉编码应用场景
场景1:UI设计转代码
上传设计稿或原型图,Qwen3-VL-4B-Instruct能够:
- 识别界面元素和布局结构
- 生成语义化的HTML标签
- 创建响应式CSS样式
- 添加必要的JavaScript交互
场景2:图表生成
从数据可视化图像生成Draw.io图表代码:
- 识别图表类型(柱状图、折线图、饼图等)
- 提取数据关系和趋势
- 生成可编辑的Draw.io XML
场景3:代码重构
分析现有界面截图,提出代码优化建议:
- 识别冗余的CSS选择器
- 建议HTML语义化改进
- 推荐性能优化方案
⚡ 性能优化技巧
启用Flash Attention 2
为了获得更好的加速和内存节省,特别是在多图像和视频场景中,建议启用flash_attention_2:
model = Qwen3VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-4B-Instruct",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
)
生成参数调优
根据不同的任务类型调整生成参数:
视觉语言任务参数:
top_p=0.8
top_k=20
temperature=0.7
repetition_penalty=1.0
presence_penalty=1.5
out_seq_length=16384
纯文本任务参数:
top_p=1.0
top_k=40
repetition_penalty=1.0
presence_penalty=2.0
temperature=1.0
out_seq_length=32768
🔍 高级功能探索
1. 多图像处理
Qwen3-VL-4B-Instruct支持同时处理多个图像输入,这对于对比分析或序列理解特别有用。
2. 视频理解
模型具备强大的视频理解能力,能够:
- 分析视频中的动态变化
- 理解时间序列关系
- 提取关键帧信息
3. 空间推理
模型能够判断物体之间的空间关系,包括:
- 相对位置(前后、左右、上下)
- 遮挡关系
- 视角变换
🛠️ 故障排除与常见问题
问题1:内存不足
解决方案:
- 使用
device_map="auto"自动分配设备 - 启用混合精度
dtype="auto" - 考虑使用模型量化
问题2:生成质量不佳
解决方案:
- 调整temperature参数(降低以获得更确定性输出)
- 优化prompt设计,提供更明确的指令
- 检查输入图像质量和分辨率
问题3:处理速度慢
解决方案:
- 确保启用flash_attention_2
- 使用GPU加速
- 批量处理多个请求
📈 最佳实践建议
1. Prompt工程技巧
- 明确指定输出格式:要求模型以特定格式(如HTML、CSS、JSON)输出
- 提供上下文信息:说明图像的用途和期望的输出类型
- 分步指导:复杂任务分解为多个简单步骤
2. 图像预处理
- 确保图像清晰度高
- 适当调整图像尺寸
- 考虑去除不必要的背景干扰
3. 结果验证
- 始终验证生成的代码语法正确性
- 测试生成代码的实际运行效果
- 对比原始图像与生成结果的匹配度
🎯 总结与展望
Qwen3-VL-4B-Instruct作为一款先进的视觉语言模型,为开发者提供了前所未有的从图像到代码的转换能力。无论是快速原型开发、代码重构还是设计实现,这个工具都能显著提升工作效率。
随着多模态AI技术的不断发展,我们期待看到更多创新应用场景的出现。从简单的界面生成到复杂的系统设计,Qwen3-VL-4B-Instruct正在重新定义编程工作的边界。
立即开始您的视觉编码之旅,体验AI辅助编程带来的效率革命!🚀
提示:本文基于Qwen3-VL-4B-Instruct模型编写,所有代码示例仅供参考,实际使用时请根据具体需求进行调整。
【免费下载链接】Qwen3-VL-4B-Instruct 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-4B-Instruct
更多推荐



 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)