
如何在亚马逊 SageMaker 进行 Stable Diffusion 模型在线服务部署
前言 - 浅谈 AIGC

AIGC - 引领人工智能走向春天
随着人工智能技术的发展与完善,AI Generated Content (AIGC,人工智能自动生成内容) 在内容的创作上为人们的工作和生活带来前所未有的帮助,具体表现在能够帮助人类提高内容生产的效率,丰富内容生产的多样性、提供更加动态且可交互的内容。AIGC 相关技术可以在创意、表现力、迭代、传播、个性化等方面,充分发挥技术优势,打造新的数字内容生成与交互形态。在这两年AIGC在AI作画、AI 作曲、AI 作诗、AI写作、AI视频生成、 AI语音合成等领域持续大放异彩;尤其是近段时间火遍全网的AI绘画,作为用户的我们只要简单输入几个关键词几秒钟之内一幅画作就能诞生。
春天里盛开的 AI 绘画
最近以AIGC带来巨大生产力提升的时尚宠儿不断进化升级,争相亮相。我们迎来ChatGPT 系列技术带给我们一波又一波的AI盛宴,而在计算机视觉领域,AI 绘画近两年正在逐渐走向图像生成舞台的中央。

文本生成图像(AI 绘画)是根据文本生成图像的的新型生产方式,相比于人类创作者,文本生成图像展现出了创作成本低、速度快且易于批量化生产的优势。
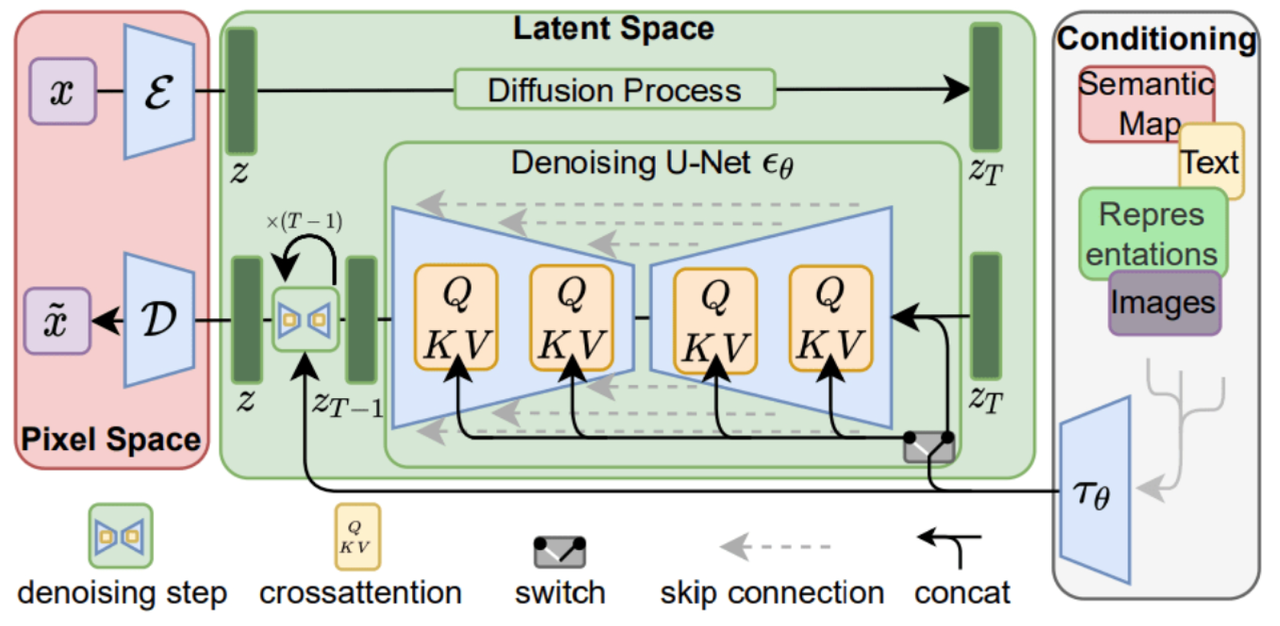
AI 绘画之Stable Diffusion 2.0 登场
近一年来,AI绘画领域迅猛发展,国内外科技巨头和初创企业争相涌入,出现了不少文本生成图像的技术产品。这些产品背后主要使用基于扩散生成算法的 dall-e-2 和 stable diffusion 等模型。
2022年 Stable Diffusion 2.0 版本的发布,再次点燃了无数创作者使用AI文本图像生成技术来生成高质量创意图像的热情 ,如下图所示,Stable Diffusion相关代码仓库,gitHub star 数量正在飞速增长:

与 Stable Diffusion 上一个版本相比,Stable Diffusion 2.0 取得了更加优异的图像生成效果,具体表现如下:
- 通过在模型体系结构中引入交叉注意力层,将扩散模型转化为强大而灵活的生成器,用于文本或边界框等一般条件输入,并以卷积方式实现高分辨率图像生成;
- 基于 latent diffusion models(LDM)在图像修复和类条件图像合成方面获得了目前最优的分数;
- 在多项任务上都取得了非常有竞争力的表现,包括无条件图像生成、文本到图像合成和超分辨率;
- 同时与 pixel-based 扩散模型方法相比显著降低了计算要求,使得它的推理速度大大提升。
人人都有机会成为前沿的技术探索者
Stable Diffusion 2.0 和 chatGPT 等系列模型在计算机视觉和自然语言处理两大AI应用领域的优异表现, 引起学术界和工业界的极大轰动,人工智能事业发展似乎迎来了又一个春天。
众所周知,随着 AI 任务复杂性和应用范围增加,高精度大规模不断涌现,AI模型的训练和推理对算力的要求越来越高,对于中小企业和个人开发者而言,如果想训练或者部署稍微大的AI模型就不得不面对购买大量算力资源高投入的风险,而具备高算力资源的企业则能够有机会把握住各种神奇AIGC技术全面开花落地的历史机遇。
我们普通的创业者和开发者,有没有机会去训练和部署我们所看好领域的AIGC模型呢,答案是肯定的,在当下这个云服务时代,人人都有机会成为前沿的技术探索者。
最近受邀参加了亚马逊云科技 『云上探索实验室』实践云上技术的系列活动,通过Amazon SageMaker 平台快速完成 AIGC模型推理服务在线web部署,带给我很多启发和惊喜,原来在云端进行AI模型推理部署可以如此简洁,优雅、流畅。在参加这次活动实践的过程中,我也学到了很多有益的知识和技能, 接下来的博文就会以我的一次AIGC模型(Stable Diffusion 2.0 )web服务部署之旅带大家一起体验如何在云端去落地AI模型服务:
基于Amazon SageMaker进行Stable Diffusion 模型部署
认识 Amazon SageMaker
Amazon SageMaker 是一项完全托管的机器学习服务:借助SageMaker的多种功能,数据科学家和开发人员可以快速轻松地构建和训练机器学习模型,然后直接部署至生产环境就绪的托管环境。SageMaker涵盖了ML 的整个工作流,可以标记和准备数据、选择算法、训练模型、调整和优化模型以便部署、预测和执行操作。
经过过去一周多的学习和实践体验,我发现这个平台简直就是为我们这些创业者和个人开发者量身打造的AI服务落地利器。许多AI工程项目,我们只需去构造好自己的训练集和测试集,其余的模型训练、推理、部署,Amazon SageMaker 都能够帮我们轻松完成。
本次博文所分享的 Stable Diffusion 2.0,通过参考官方提供的技术文档,只用了 20分钟左右的时间,我就在Amazon SageMaker 上成功搭建了一套流畅的AI绘画在线服务,接下来,让我们一起揭秘。
借助 Amazon SageMaker 进行环境搭建和模型推理
1. 创建 jupyter notebook 运行环境
在搜索框中搜索 SageMaker ,如下图所示

这里我们创建一个笔记本编程实例

我这里选择的配置如下:

选择角色,其他的默认即可

大概5分钟左右,实例就创建成功啦

上传刚刚下载的代码

直接打开这个代码

选择合适的conda环境

2. 一键运行所有代码
这里我们直接一键运行运行所有代码即可,代码执行过程中会依次完成 Stable Diffusion 模型相关类和函数的代码定义、推理测试,并打包代码和模型,然后部署模型至Sagemaker 推理终端节点 (PS:这里的所有代码运行完毕大概需要5到10分钟左右)

关键代码分析如下
1. 环境准备,代码模型下载
检查当前 pyTorch 版本
!nvcc --version
!pip list | grep torch
安装 Stable Diffusion 代码运行额外需要的依赖库,这网速飞快
!sudo yum -y install pigz
!pip install -U pip
!pip install -U transformers==4.26.1 diffusers==0.13.1 ftfy accelerate
!pip install -U torch==1.13.1+cu117 -f https://download.pytorch.org/whl/torch_stable.html
!pip install -U sagemaker
!pip list | grep torch
下载代码和模型文件,这里直接下载Hugging Face提供的代码和模型即可

2. 在Notebook中配置并使用模型
直接调用 函数进行模型加载
import torch
import datetime
from diffusers import StableDiffusionPipeline
# Load stable diffusion
pipe = StableDiffusionPipeline.from_pretrained(SD_MODEL, torch_dtype=torch.float16)
在 Cuda 上进行模型的推理,这里 Stable Diffusion V2 能够支持生成的最大图像尺寸为 768 * 768
# move Model to the GPU
torch.cuda.empty_cache()
pipe = pipe.to("cuda")
# V1 Max-H:512,Max-W:512
# V2 Max-H:768,Max-W:768
print(datetime.datetime.now())
prompts =[
"Eiffel tower landing on the Mars",
"a photograph of an astronaut riding a horse,van Gogh style",
]
generated_images = pipe(
prompt=prompts,
height=512,
width=512,
num_images_per_prompt=1
).images # image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
print(f"Prompts: {prompts}\n")
print(datetime.datetime.now())
for image in generated_images:
display(image)
友情提示 :如果报错,遇到推理时 GPU 内存不够,则可以尝试以下三种方式进行解决
- 试一试生成分辨率小一点的图片
- 减少生成图片的数量
- 升级机型,选择更强的GPU服务器
3. 部署模型至Sagemaker 推理终端节点
我们这里直接使用 AWS 的 SageMaker Python 开发工具包部署模型刚刚已经验证能够运行成功的模型和打包好的代码。
- 编写初始化的Sagemaker代码用于部署推理终端节点
import sagemaker
import boto3
'''
# 创建 Session
'''
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
- 创建 inference.py 脚本,进行模型的加载和推理
%%writefile ./$SD_MODEL/code/inference.py
import base64
import torch
from io import BytesIO
from diffusers import StableDiffusionPipeline
'''
# 加载模型到CUDA
'''
def model_fn(model_dir):
# Load stable diffusion and move it to the GPU
pipe = StableDiffusionPipeline.from_pretrained(model_dir, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
return pipe
'''
# 推理方法
'''
def predict_fn(data, pipe):
# 解析参数 get prompt & parameters
prompt = data.pop("prompt", "")
# set valid HP for stable diffusion
height = data.pop("height", 512)
width = data.pop("width", 512)
num_inference_steps = data.pop("num_inference_steps", 50)
guidance_scale = data.pop("guidance_scale", 7.5)
num_images_per_prompt = data.pop("num_images_per_prompt", 1)
# 传入参数,调用推理 run generation with parameters
generated_images = pipe(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
num_images_per_prompt=num_images_per_prompt,
)["images"]
# create response
encoded_images = []
for image in generated_images:
buffered = BytesIO()
image.save(buffered, format="JPEG")
encoded_images.append(base64.b64encode(buffered.getvalue()).decode())
# create response
return {"generated_images": encoded_images}
在 Amazon Cloud9 创建前后端 Web 应用
AWS Cloud9 是一种基于云的集成开发环境 (IDE),只需要一个浏览器,即可编写、运行和调试代码。包括一个代码编辑器、调试程序和终端,并且预封装了适用于 JavaScript、Python、PHP 等常见编程语言的基本工具,无需安装文件或配置开发计算机,即可开始新的项目。
1. 创建云服务实例,并进行web环境安装
这里我试用了 Cloud9 云服务,在查找服务处搜索 Cloud9,并点击进入Cloud9服务面板即可

点击创建环境

我这里的设置如下

其他部分配置保持默认,在页面底部点击橙色的 Create 按钮创建环境。 环境的创建将花费1-2分钟的时间。

创建成功之后,点击 open 进入服务控制台

粘贴左侧的代码,复制到控制台bash窗口进行运行,会自动下载和解压代码
cd ~/environment
wget https://static.us-east-1.prod.workshops.aws/public/73ea3a9f-37c8-4d01-ae4e-07cf6313adac/static/code/SampleWebApp.zip
unzip SampleWebApp.zip
# 在 AWS Cloud9 上安装 Flask 和 boto3
pip3 install Flask
pip3 install boto3

2. 运行启动web服务,输入想要生成的图像参数和提示词,调用推理服务
依赖的环境安装好之后,就可以运行这个服务代码

服务启动成功之后,访问 127.0.0.1:8080 即可访问本地服务;设定 width 和 Length 参数,以及想要生成的图片描述,然后点击提交

等待 几秒钟之后,就得到了上面输入的两个 提示词对应生成的图像,看得出来效果还是非常不错的;
- 经测试发现,即使每次输入的提示词是同一个,模型生成得到的输出也是不固定的
- 输入的提示词语越精准,生成的图像效果会容易越好
- 基于亚马逊SageMaker服务平台,如此快速(熟练之后,不到半个小时)就能搭建好一套AI模型的web端在线推理调用,果然好的技术就是第一生产力

3. 文本图像生成示例
这里提供3组文本图像生成的示例,方便各位同学参考:
| 提示词 | 生成图像示例1 | 生成图像示例2 |
|---|---|---|
A rabbit is piloting a spaceship |
 |
 |
Driverless car speeds through the desert |
 |
 |
A small cabin on top of a snowy mountain in the style of Disney, artstation |
 |
 |
4. Stable Diffusion 2.0 模型效果优缺点分析
目前业界已经有不少文本图像生成的服务和模型推出,Stable Diffusion 2.0 的图像生成效果,整体上我觉得相当惊艳,优点很明显:
- 能够直接支持 512x512像素和768x768像素的图像生成,生成图像的整体质量和局部细节都有显著提升,其次在超分辨率高阶Diffusion模型加持下,Stable Diffusion 2.0 可以进一步生成分辨率2K以上的高清图像。
- 对文本词汇的解析比较精准,推理速度相比之前版本有较大提升,整体来看非常高效、鲁棒,超越目前业界很多模型。
不足之处,Stable Diffusion 2.0 对于过短和过长的文本提示词生成的图像可能效果差异很大,这意味着有的时候,如果想要生成得到更加贴近我们预期的图像,需要对专业的文本提示词汇有所了解,使得输入的文本提示词更加精准和容易让模型理解。
亚马逊云科技之云上探索实验室
亚马逊云服务使用体验总结
通过此次深度参与亚马逊云科技之云上探索实验室活动并上手实践不同AI项目的云端服务部署,我进一步认识到 AWS(Amazon Web Services)的强大所在:
- 可扩展性:AWS允许用户根据业务需要轻松扩展服务器资源,能够帮助客户节省成本、提高效率;
- 可靠性:AWS 拥有持续领先的云服务基础设施,具有高度可靠的分布式架构,能够在全球业务范围内提供稳定可靠的服务;
- 安全性:AWS 提供各种安全功能和工具,有效帮助用户保护数据和应用程序;
- 灵活性:AWS 提供各种可定制的服务和功能,以满足用户的特定需求;
- 可信赖:AWS 在业界树立良好的企业形象和服务口碑,早已成为全球数百万企业和个人客户的云转型首选。
AWS 相比其他云服务厂商,还具备以下优点:
- 亚马逊云科技为 AWS 提供全球覆盖广泛、服务深入的云平台,已有超过 200 项功能齐全的服务可供使用;
- 提供有一套构建于 AWS 之上的按需付费的生产效率应用程序,使得团队用户能够快速、安全、经济高效地检查项目状态、进行内容协作,并实现实时通信;
- 提供最广泛、最深入的机器学习服务及配套的云基础设施和广泛验证的算法模型,从而使每位开发人员、数据科学家和专家从业者都能利用机器学习技术高效切入AI服务的落地和部署;
- 提供全方位的在线开发工具,用户能够更快、更高效地托管代码以及构建、测试和部署应用程序;
前沿技术有待大家一起去探索
这次有幸受邀参加亚马逊云科技【云上探索实验室】活动,跟着亚马逊云科技技术团队提供的系列非常详尽的 AI模型云上推理部署实战文档和视频教程一步步进行真实的云上服务部署操作,让我再次认识到AI在各个领域技术突破所带来的强大生产力,而通过借助 亚马逊 SageMaker 平台进行AI模型服务部署大大简化我们普通开发者进行AI模型部署服务的难度,使得对于中小企业和个人开发者而言,AI服务的快速落地也不再是一件难事。
通过使用 亚马逊 SageMaker 服务平台,我们只需要一个浏览器,即可编写、运行和调试各种代码,无需进行复杂的机器适配和环境搭建,能够快速完成AI模型的推理、测试、验证部署工作。
如果你也想亲身感受最新、最热门的亚马逊云科技开发者工具与服务,那么只需点击下方链接,即可跟着亚马逊云科技团队工程师一起对更多有趣的AI技术进行探索与实践,出击吧,AI 追梦人

率先完成学习打卡小伙伴,还有丰厚奖品可以领取哟

更多推荐


 634
634 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)