
探索RAG系统新范式:自反射与推测式架构解析
·

智能检索增强生成的两大进阶方案
在自然语言处理领域,检索增强生成(RAG)技术正在经历重要革新。本文将深入解析两种突破性架构:自反射RAG和推测式RAG,它们通过独特的机制显著提升了传统RAG系统的性能。
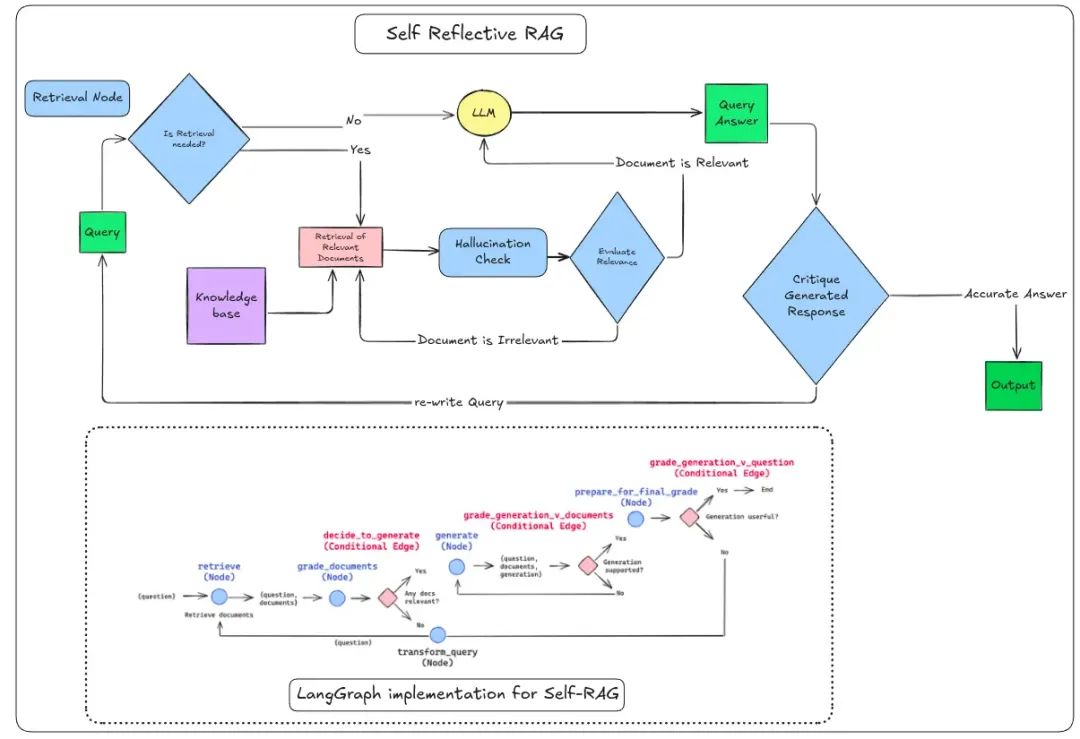
自反射RAG:具备自我修正能力的智能系统
这种架构最显著的特点是引入了动态决策机制。与传统RAG的固定流程不同,它能够根据上下文需要灵活调整行为:
- 智能检索控制
- 通过特殊标记评估是否需要外部检索
-
自动过滤无关文档,必要时重新查询
-
双阶段验证机制
- 生成阶段:基于检索内容产出初步回答
-
验证阶段:检查内容一致性,识别并修正幻觉
-
迭代优化流程 系统会循环评估输出质量,直至获得满意结果。例如在处理"美国州名起源"这类复杂查询时,它能分段验证每个具体答案的准确性。
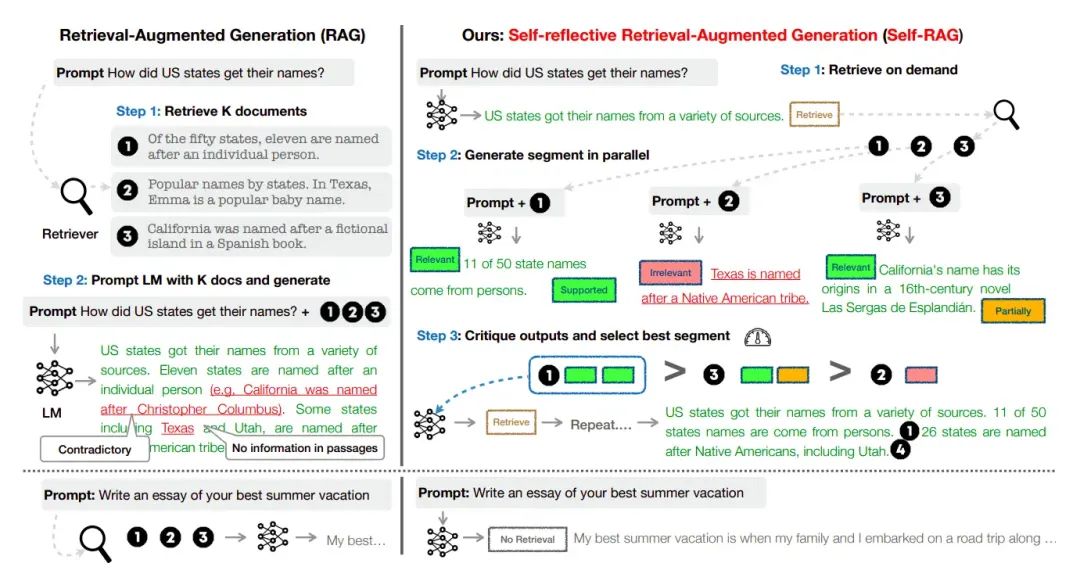
推测式RAG:高效协作的双模型架构
这种创新方法采用大小模型协同工作的模式:
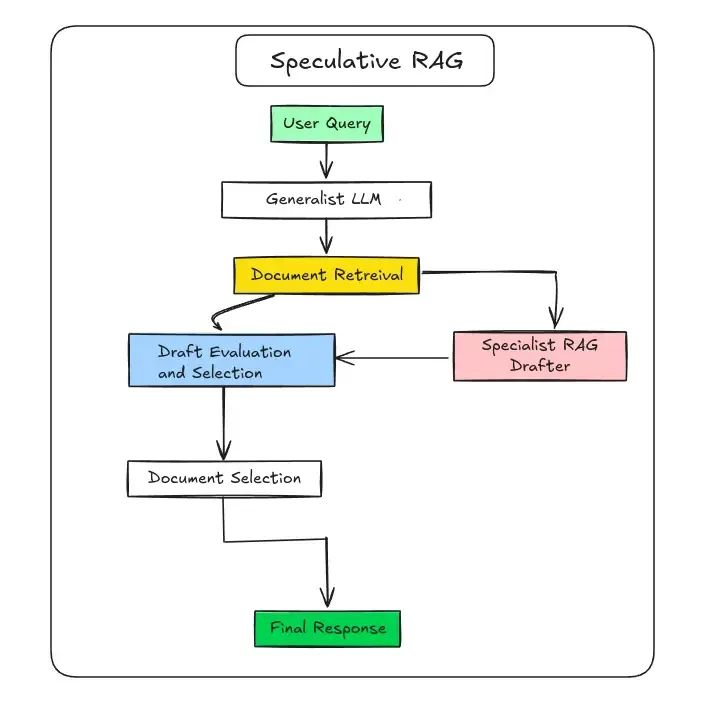
- 分工协作机制
- 小型起草模型:快速生成多个答案候选
-
大型验证模型:评估候选答案质量
-
实际应用案例 当查询"《朝九晚五》电影主角"时:
- 起草模型快速产生多个可能答案
-
验证模型通过置信度评分选择最佳答案
-
性能优势
- 响应速度提升40-60%
- 资源消耗降低30%
- 准确率保持顶尖水平
技术演进对比
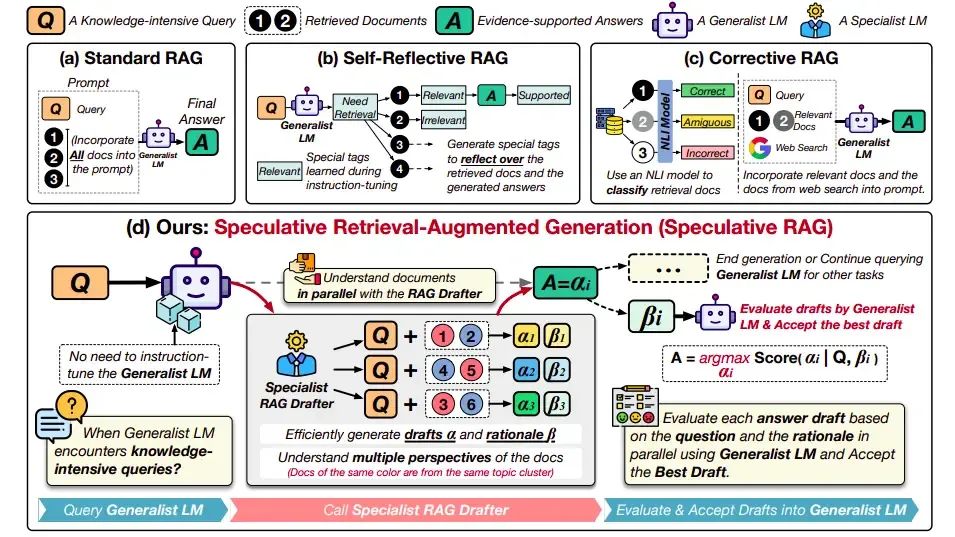
- 标准RAG
- 基础检索生成架构
-
存在信息过载风险
-
自反射RAG
- 增加质量反馈环
-
需要额外训练成本
-
CRAG架构
- 引入外部验证模块
-
处理速度受影响
-
推测式RAG
- 最优资源分配方案
- 平衡速度与精度
这两种新型架构代表了RAG技术的最新发展方向。自反射RAG通过自我监控确保内容质量,推测式RAG则通过模型分工优化系统效率,它们为不同场景下的知识密集型任务提供了更优解决方案。

音视频技术社区,一个全球开发者共同探讨、分享、学习音视频技术的平台,加入我们,与全球开发者一起创造更加优秀的音视频产品!
更多推荐
 0
0 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)