
RAG技术进阶指南:向量检索与知识图谱的融合应用
·

RAG技术的工作原理与应用场景
检索增强生成(RAG)作为当前AI领域的热门技术,其核心在于将传统检索系统与大型语言模型相结合。整个过程可以概括为:先将文档分割为多个文本块,转换为向量形式存储;当用户提问时,系统会检索最相关的文本片段,并将其作为上下文与问题一起输入生成模型。
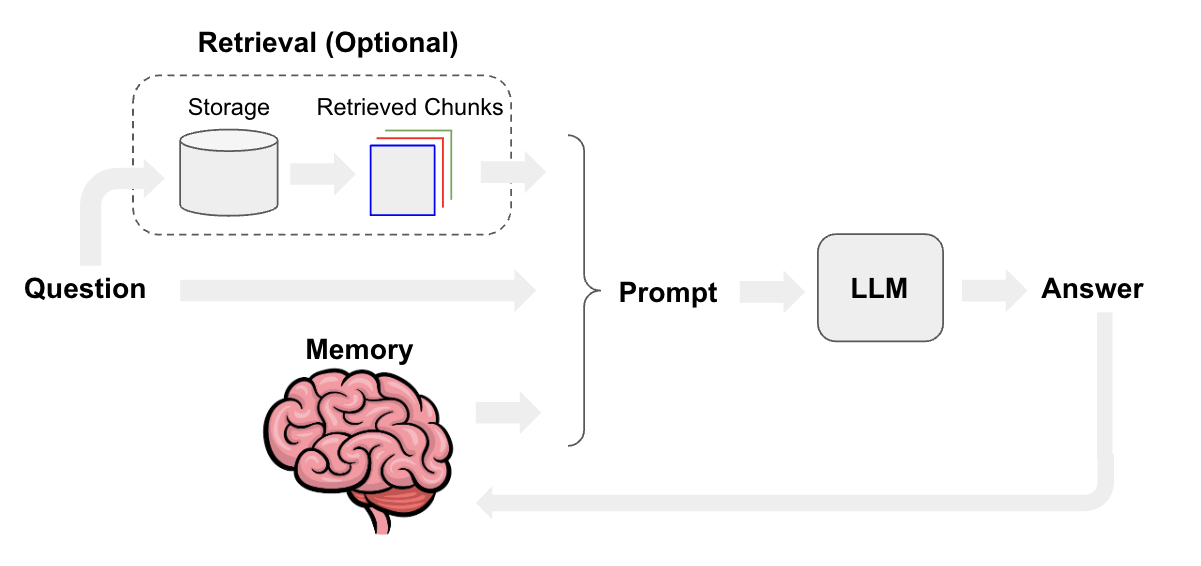
提升RAG效果的五大关键点
在实际应用中,我们可以通过以下方式显著提升RAG系统的性能:
- 文本分块优化:调整块大小和重叠区域,找到最适合特定数据的分割方式
- 多粒度检索:使用小尺寸块进行检索,大尺寸块提供上下文,获得更完整的背景信息
- 向量模型升级:采用高性能嵌入模型如BGE系列,有条件时可进行领域微调
- 结果重排序:先用向量模型召回大量候选,再用精排模型筛选最优结果
- 提示词工程:设计合理的提示模板,引导模型生成更准确、稳定的回答
RAG优化的两大方向
基础功能优化
这一层面的优化聚焦于RAG的核心流程,包括:
- 改进文本预处理方法
- 增强检索模块的准确性
- 优化生成环节的提示设计
系统架构优化
更深入的改进涉及整体架构的创新,比如:
- 结合知识图谱的结构化信息(KG RAG)
- 实现自我优化的检索机制(Self-RAG)
- 整合多模态数据的检索能力(多向量检索器)
这些进阶技术能够显著提升系统处理复杂查询的能力,特别是在需要跨文档推理或多源信息整合的场景中表现尤为突出。

音视频技术社区,一个全球开发者共同探讨、分享、学习音视频技术的平台,加入我们,与全球开发者一起创造更加优秀的音视频产品!
更多推荐
 0
0 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)