
深入理解向量数据库:原理、应用与选型指南
·

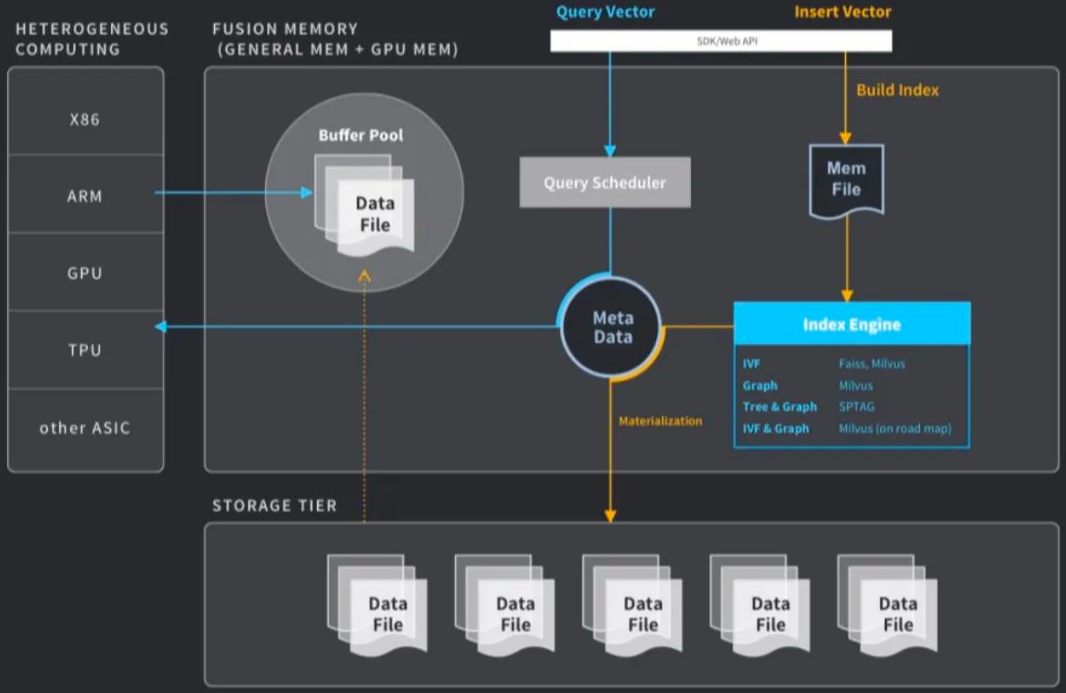
认识向量数据库
1. 什么是向量数据库
向量数据库是专门用于存储和查询向量数据的数据库系统。它能够高效处理由深度学习模型生成的embedding向量,这些向量通常以一维浮点数数组的形式表示对象在多维空间中的特征。
2. 常见的向量数据类型
- 图像向量:通过CNN等模型提取的视觉特征
- 文本向量:由BERT等模型生成的语义表示
- 音频向量:从声波信号中提取的声学特征
3. 核心优势
与传统数据库相比,向量数据库具备以下特点:
- 支持海量高维数据存储
- 提供近似最近邻(ANN)搜索能力
- 擅长处理非结构化数据
- 查询效率是传统方案的10倍以上
工作原理详解
1. 相似性度量方法
欧氏距离
计算向量间的直线距离,适用于需要考虑向量长度的场景。
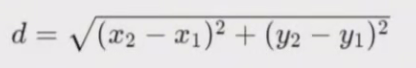
余弦相似度
衡量向量方向一致性,对文本等语义搜索特别有效。
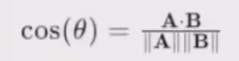
2. 索引构建技术
聚类索引(IVF)
通过K-means将数据分簇,搜索时只在最近簇内查询:
- 初始化K个质心
- 分配向量到最近质心
- 重新计算质心位置
- 迭代优化

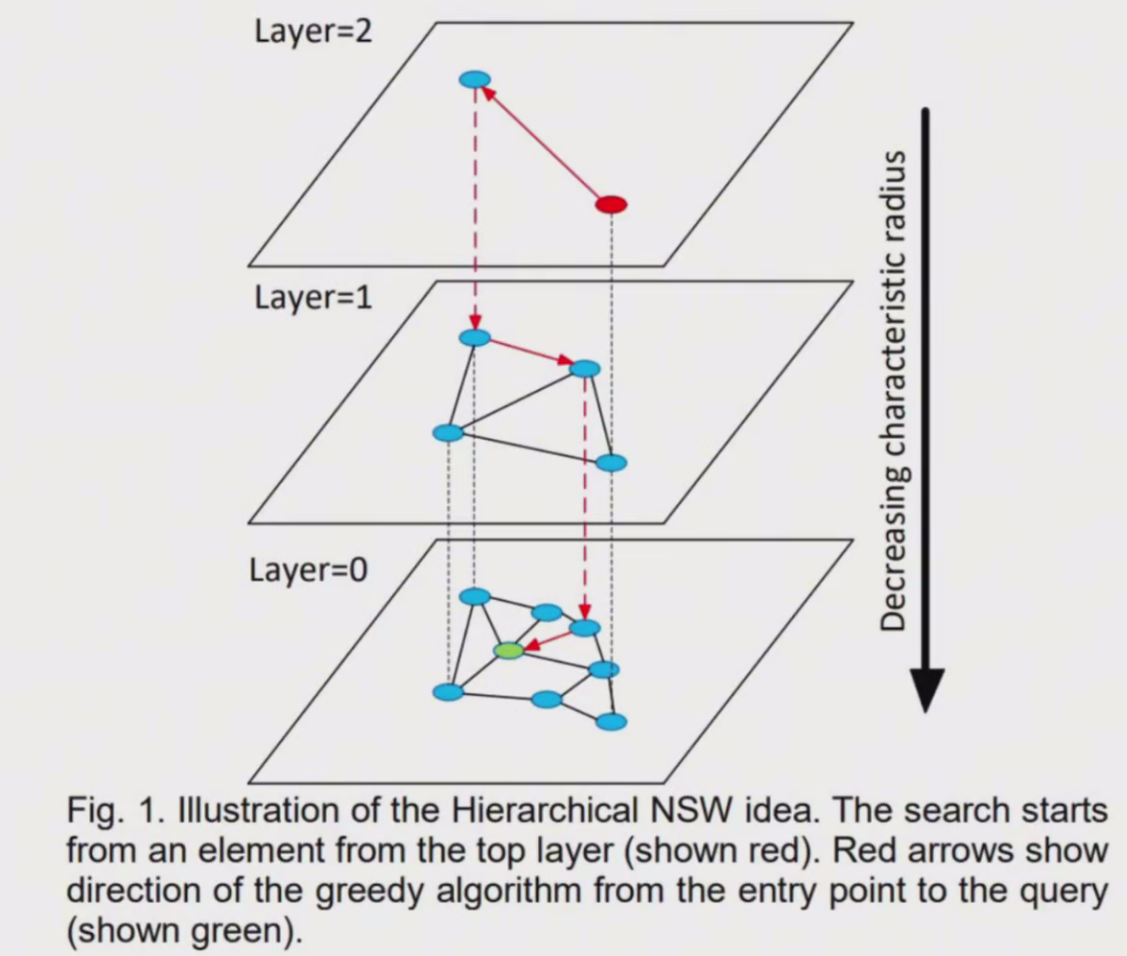
图结构索引(HNSW)
构建多层导航图实现高效搜索: - 高层:快速定位大致范围 - 低层:精确查找最近邻
乘积量化(PQ)
将高维向量分割压缩,大幅减少存储需求:
- 将128维向量分成8个16维子向量
- 对每个子向量聚类为256类
- 用8个8bit整数表示原始向量

实际应用场景
- 智能问答系统:实现基于语义的知识检索
- 推荐引擎:根据用户行为特征匹配相似商品
- 图像搜索:通过视觉特征查找相似图片
- 生物识别:快速比对海量人脸/声纹数据
- 金融风控:发现异常交易模式
主流技术选型
1. 专用向量数据库
| 特性 | Milvus | Weaviate | Qdrant | |------------|--------|----------|--------| | 分布式支持 | ✓ | ✓ | ✓ | | 过滤搜索 | ✓ | ✓ | ✓ | | 多模态支持 | ✓ | ✓ | ✗ |
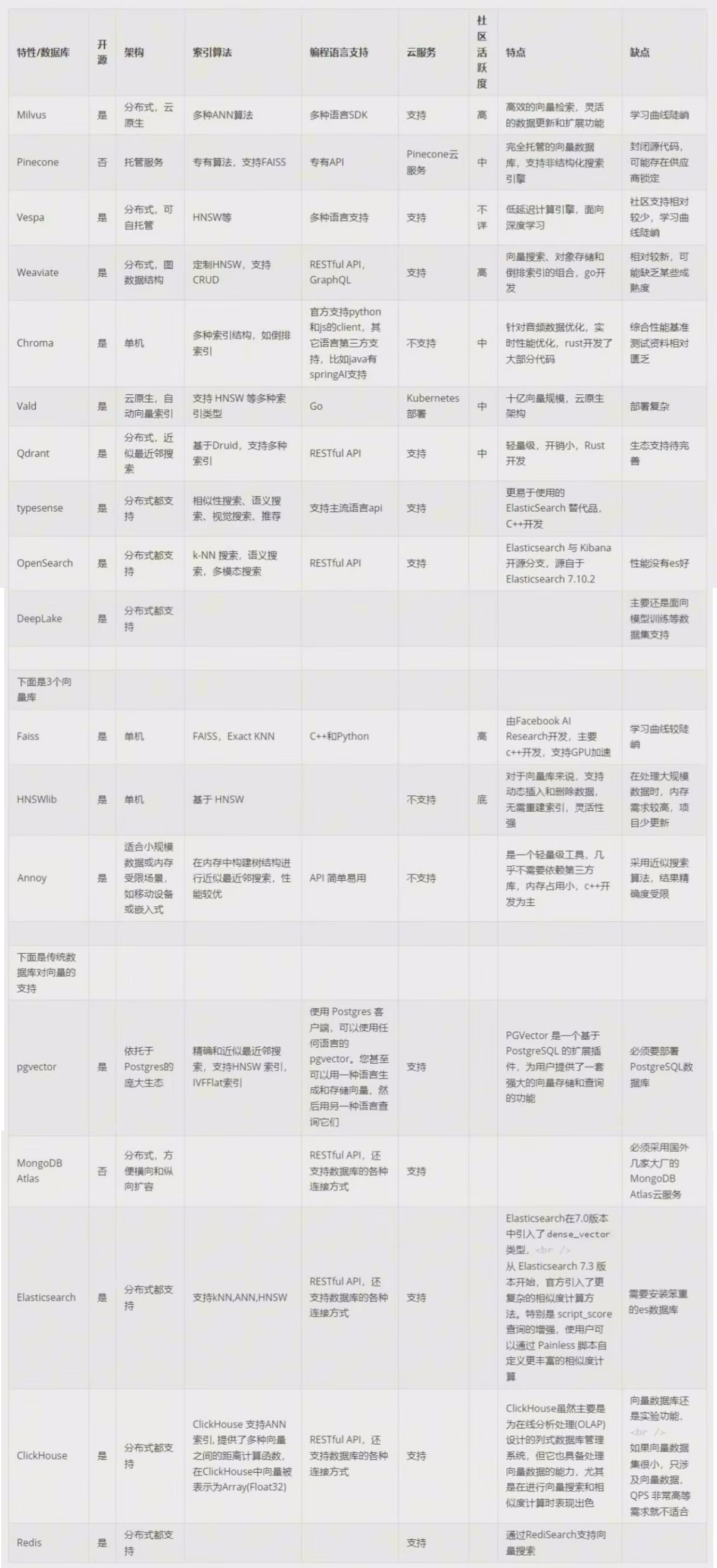
2. 传统数据库扩展方案
- PostgreSQL:通过pgvector插件支持
- Redis:使用RediSearch模块
- Elasticsearch:7.0+版本支持向量检索
实施建议
- 数据规模评估:小规模(<10万)可考虑传统数据库扩展
- 查询延迟要求:高并发场景选择分布式架构
- 功能完整性:企业级应用需关注ACL、监控等特性
- 开发生态:优先选择API文档完善、社区活跃的产品

音视频技术社区,一个全球开发者共同探讨、分享、学习音视频技术的平台,加入我们,与全球开发者一起创造更加优秀的音视频产品!
更多推荐
 0
0 0
0- 0



 已为社区贡献81条内容
已为社区贡献81条内容

所有评论(0)