
探索向量数据库ChromaDB的工作原理与应用
·

最近在研究人工智能领域时,接触到了向量数据库这个有趣的概念。作为一个技术爱好者,我想分享下自己的学习心得。
1. 理解向量与文本向量
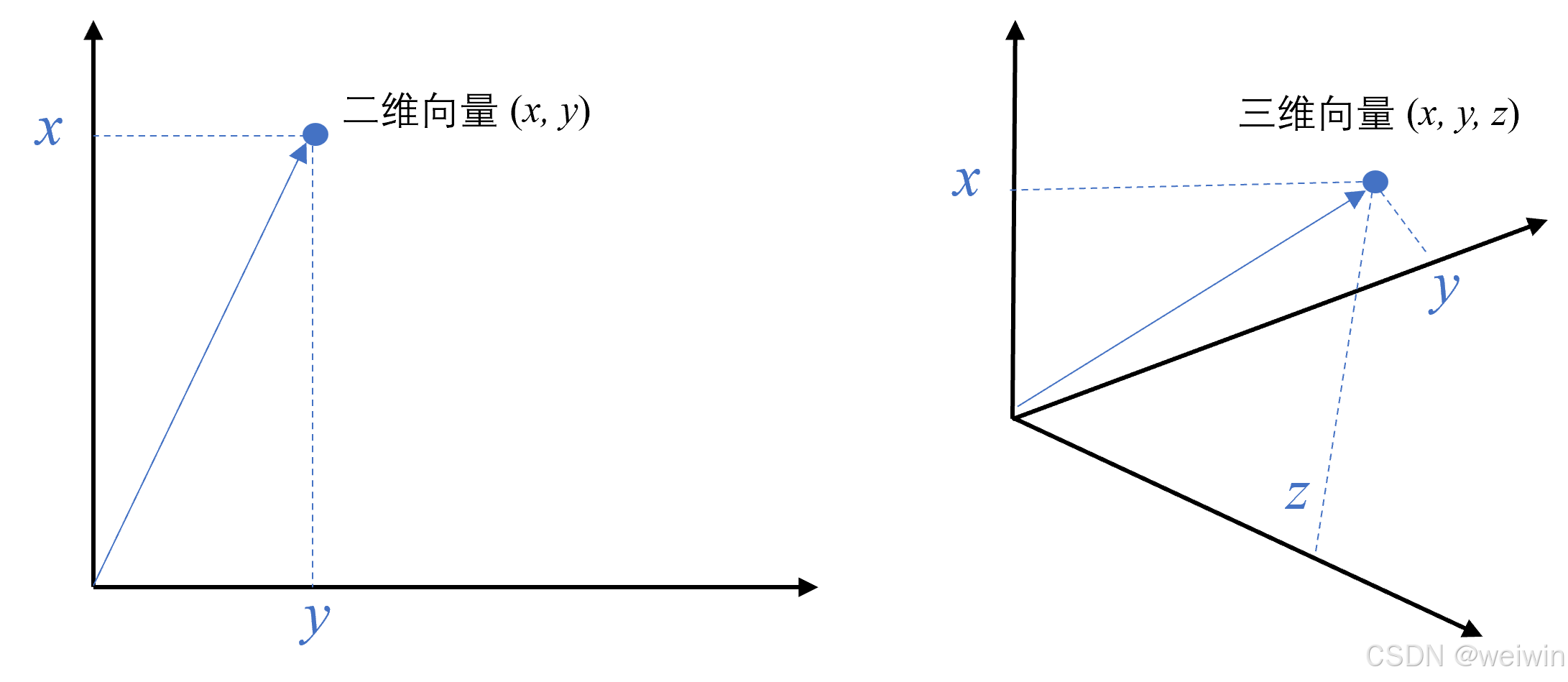
在数学中,向量不仅表示大小还包含方向。比如在二维空间里,(3,4)就是从原点指向(3,4)点的箭头。扩展到N维空间,我们就能用(x1,x2,...,xN)来表示更复杂的向量。
文本向量则是将文字转化为一组数字的神奇方式。比如把句子"我爱编程"转换成[0.1, 0.5, -0.3,...]这样的数值序列。通过计算这些数值序列之间的距离,我们就能判断两段文字的相似程度。
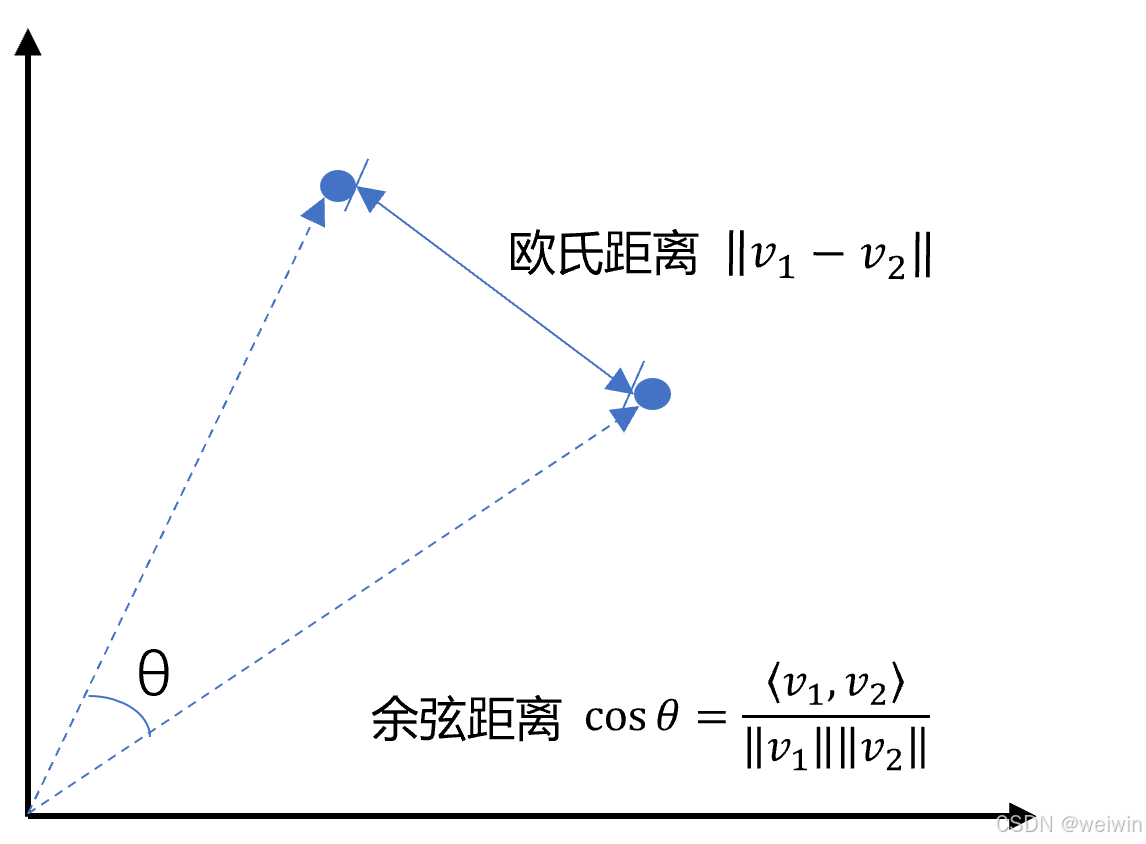
常用的计算方法有:
- 余弦相似度(值越大越相似)
- 欧氏距离(值越小越相似)
2. 向量数据库的特点
这类数据库专门用来存储和查询向量数据,主要特点包括:
- 存储高维向量及其元数据
- 建立高效索引加速搜索
- 支持快速相似性查询
3. ChromaDB实践
Chroma是当前流行的开源向量数据库,它的主要功能有:
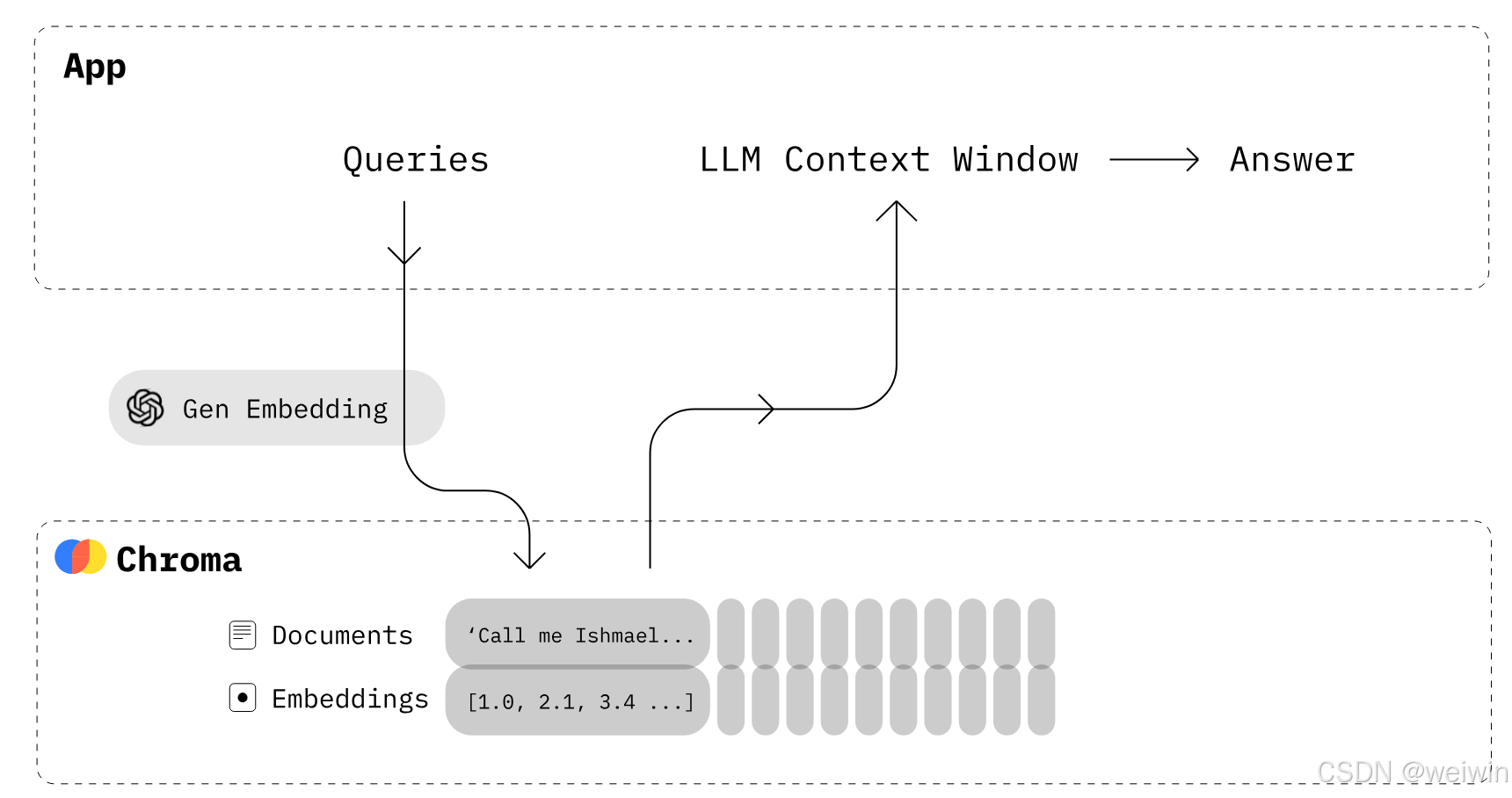
- 默认使用欧氏距离(L2)计算相似度
- 支持修改为余弦相似度等计算方式
- 提供简单易用的Python接口
安装和使用都很简单:
pip install chromadb
pip install sentence_transformers以下是基本使用示例:
import chromadb
from chromadb import Settings
class VectorDBHelper:
def __init__(self, collection_name, embedding_fn):
client = chromadb.Client(Settings(allow_reset=True))
client.reset()
self.collection = client.get_or_create_collection(name=collection_name)
self.embedding_fn = embedding_fn
def add_data(self, documents):
self.collection.add(
embeddings=self.embedding_fn(documents),
documents=documents,
ids=[f"id{i}" for i in range(len(documents))]
)
def search(self, query, top_n=3):
return self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)通过这样的工具,我们可以轻松构建各种语义搜索应用,为AI项目提供强大的数据支持。

音视频技术社区,一个全球开发者共同探讨、分享、学习音视频技术的平台,加入我们,与全球开发者一起创造更加优秀的音视频产品!
更多推荐
 0
0 0
0- 0



 已为社区贡献81条内容
已为社区贡献81条内容

所有评论(0)