
FFmpeg
FFmpeg
·
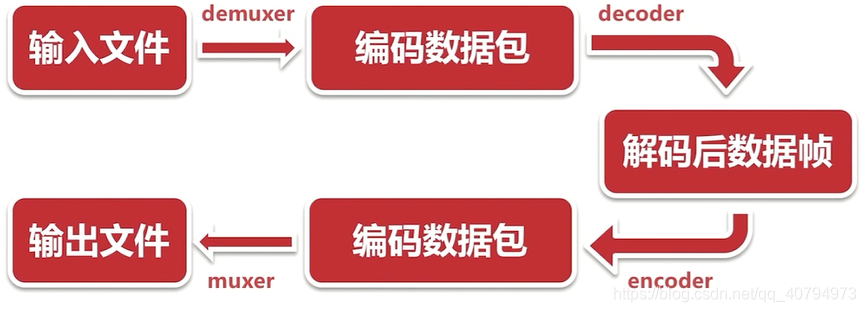
1 FFmpeg处理音视频流程

音视频技术社区,一个全球开发者共同探讨、分享、学习音视频技术的平台,加入我们,与全球开发者一起创造更加优秀的音视频产品!
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容
FFmpeg
音视频技术社区,一个全球开发者共同探讨、分享、学习音视频技术的平台,加入我们,与全球开发者一起创造更加优秀的音视频产品!
更多推荐
5 0
已为社区贡献1条内容

所有评论(0)