
让GPU更轻盈 让推理更流畅|焱融YRCache双异步技术激活AI新价值
近日,国内首创的大模型推理加速技术——焱融 YRCache,发布了最新的实测数据。基于异步卸载与异步加载两大核心创新,不仅释放 GPU 显存、降低推理成本、提升资源利用率,还大幅提升推理效率,轻松支持 32K、128K 及更长上下文的流畅处理,并实现跨节点缓存共享,为用户带来高性能、低成本的大模型推理体验和显著业务价值。
近日,国内首创的大模型推理加速技术——焱融 YRCache,发布了最新的实测数据。基于异步卸载与异步加载两大核心创新,不仅释放 GPU 显存、降低推理成本、提升资源利用率,还大幅提升推理效率,轻松支持 32K、128K 及更长上下文的流畅处理,并实现跨节点缓存共享,为用户带来高性能、低成本的大模型推理体验和显著业务价值。
当前,随着大模型应用的不断深入,推理性能的提升已成为业界关注焦点。在众多优化手段中,KVCache(键值缓存)技术尤为关键。但随着长上下文长度的不断增加,KVCache 数据量急剧膨胀,迅速占满有限 GPU 显存,拖慢推理效率,并推高推理成本。将 KVCache 数据卸载到外部存储,成为打破这道“显存墙”的一种重要方式。
然而,这种方式也面临两大挑战:
一是如何在不影响正在进行的推理任务的情况下,将 KVCache 卸载至外部存储;
二是在需要重新使用这些数据时,如何实现快速加载,以保障推理性能。
作为专业的 AI 存储厂商,焱融科技推出的国内首个推理加速方案——YRCache,正是为解决上述难题而设计。YRCache 将 KVCache 无缝扩展至焱融高性能分布式文件存储系统 YRCloudFile,并确保在需要时能快速将数据重新加载至 GPU 显存。这不仅显著降低了 GPU 显存占用,释放出更多宝贵的计算资源,降低推理成本,还能支持更高的并发用户数和更长的上下文长度,保障 32K、128K 以及更长上下文的高效推理与流畅用户体验。其中,KVCache 的异步卸载与异步加载是 YRCache 实现高效推理的两项重要优化技术。
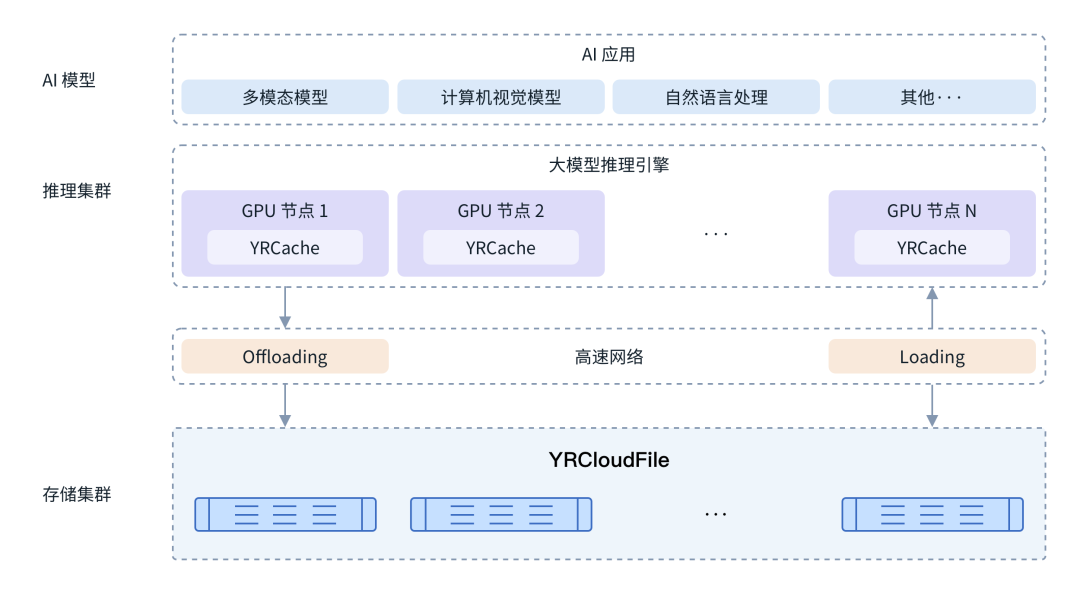
YRCache 方案架构图
让 GPU 更轻盈 让推理更流畅丨YRCache 两项关键技术的核心价值
KVCache 异步卸载:GPU 显存“瘦身术”
在大模型推理过程中,如果采用同步模式将 KV 缓存卸载到外部存储,数据需先从 GPU 显存传输到外部存储,在此期间 GPU 处于空闲状态,不仅增加了额外延时,还会削弱 KVCache 的性能收益。为此,YRCache 采用异步方式将 KV 键值缓存数据从 GPU 显存写入焱融高性能分布式文件存储系统 YRCloudFile。整个卸载过程在后台完成,无需中断正在进行的推理任务,最大限度降低了对推理性能的影响。
YRCache 异步卸载的显著优势:
-
提高 GPU 利用率:通过将非活跃或共享的 KV 缓存数据移出 GPU 显存,释放空间以处理新请求,可支持更多并发以及更长输入序列,避免显存溢出。
-
以存换算,加速推理:在多轮对话等存在上下文重叠的场景中,系统可直接从外部存储快速读取已计算的 KVCache 实现复用,避免重复计算,显著缩短首 Token 耗时(TTFT),提升响应速度。
-
多节点 KV Cache 共享,降低成本:随着多机多卡分布式推理成为大模型落地的核心基础设施,跨节点 KVCache 共享变得日益重要且复杂。YRCache 将 KV 缓存卸载至高性能存储集群,实现节点间的缓存共享,降低集群整体计算成本,支持更大规模 LLM 服务部署。
KVCache 异步加载:推理延迟“消除术”
若采用同步加载方式,每次从存储系统读取 KVCache 块时推理过程都需要暂停下来等待数据传输,会严重影响推理性能。YRCache 通过异步加载策略解决了这一问题。异步加载将数据传输(I/O)与计算(Compute)操作并行处理:当 GPU 执行当前 token 计算时,YRCache 系统提前将下一个请求所需的 token 加载至 GPU 显存。待计算任务完成后,所需的缓存数据已准备就绪,可直接使用,避免了等待时间。
YRCache 异步加载的显著优势:
-
避免计算阻塞,提高吞吐量:YRCache 异步加载完美解决了同步加载方式会造成的“后续计算流程阻塞,导致延迟增加”的问题,允许计算与数据传输并行,提高整体吞吐量。
-
支持动态调度:在流量动态变化时(如业务高峰时段),异步加载使系统能更灵活地调整 KVCache 的加载策略。如可根据实时负载动态决定是否提前加载或延迟加载 KVCache,适应不同业务需求,增强系统弹性和稳定性。
-
优化资源利用:通过异步方式重叠不同节点间的缓存传输,减少网络等待时间,充分利用带宽与计算资源,避免资源闲置。
-
隐藏延迟,保障用户体验:通过重叠 I/O 和计算,异步加载有效地隐藏了从存储加载数据的延迟,显著减少用户推理请求的等待时间,保障极低的响应延迟,提升用户使用体验。
为了更直观地展示异步卸载和异步加载技术能够带来的推理性能的提升,我们做了一系列测试。所有测试均是在相同的 NVIDIA L20 显卡配置下,选用 DeepSeek-R1-Distill-Qwen-32B 模型,对原生 vLLM 与 vLLM + YRCache 方案在多轮会话场景下的 TTFT 表现进行测试。
测试一:原生 vLLM vs YRCache(同步模式)
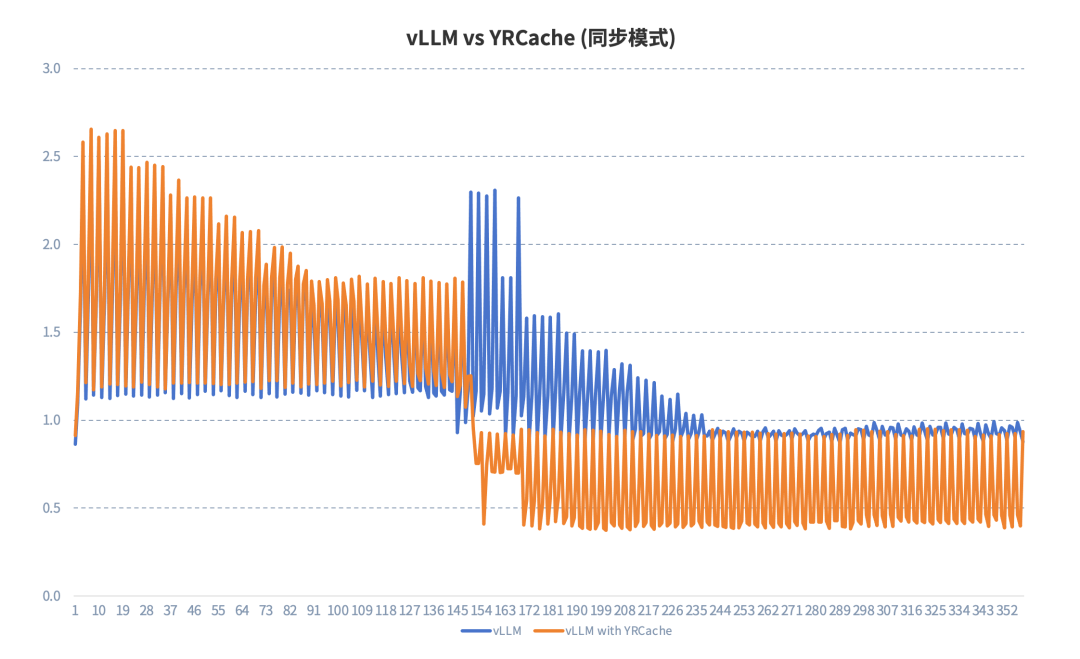
从上图中的测试结果可以看出,同步模式下,在会话较少缓存未命中时,由于卸载 KVCache 需要暂停当前推理任务,导致 TTFT 高于原生 vLLM;随着会话轮次的增加,当缓存开始命中后,使用 YRCache 方案相比原生 vLLM 的推理性能更加稳定,且有较大提升。
测试二:原生 vLLM vs YRCache (异步模式)
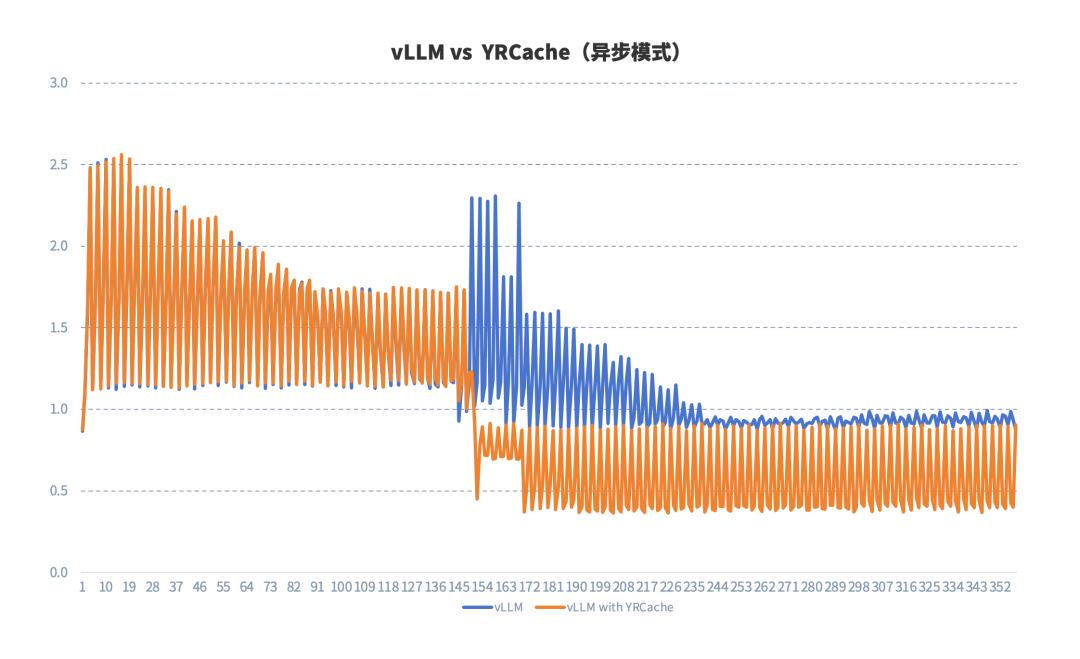
异步模式下,在会话较少缓存未命中时,YRCache 方案与原生 vLLM 性能一致,有效解决了同步模式对推理任务造成的负面影响;随着会话轮次的增加,当缓存开始命中后,使用 YRCache 方案相比原生 vLLM 的推理性能有着显著的提升。
测试三:YRCache 同步模式 vs 异步模式
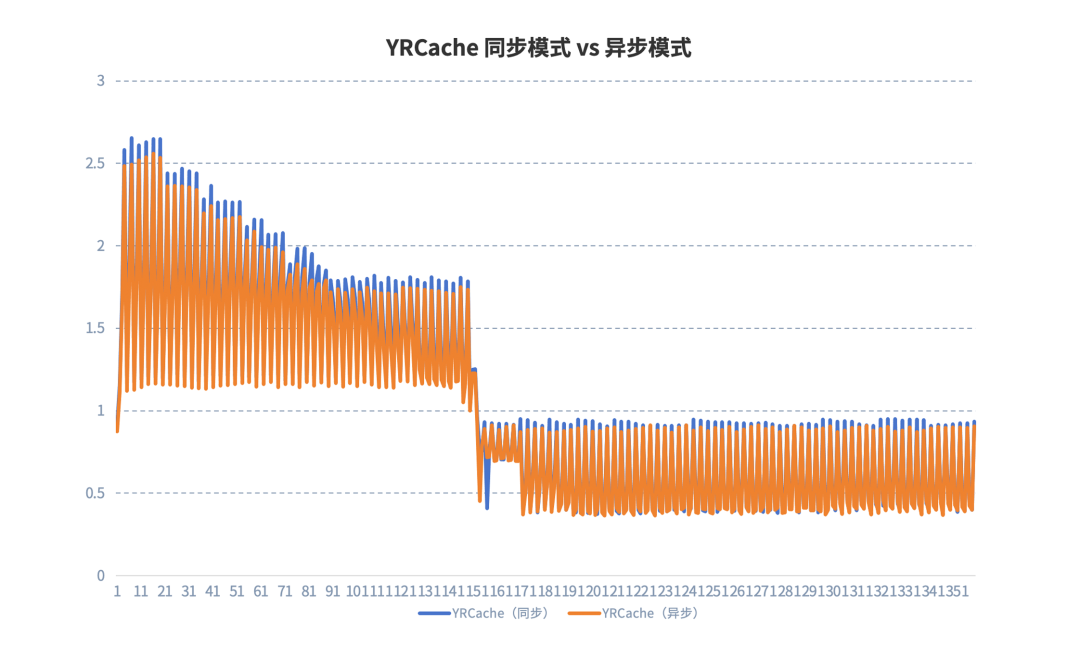
从 YRCache 同步模式和异步模式下的对比测试结果来看,不论是在缓存未命中,还是缓存命中时,异步加载和异步卸载技术方案下的推理性能均明显提升。
从这一系列测试的结果可以看出,当对话轮次增加,上下文重叠增加,缓存命中时,不论是同步模式还是异步模式,将 KVCache 卸载至外部高性能存储的 YRCache 方案均可以明显提升推理效率。而在异步加载和异步卸载技术的加持下,YRCache 方案避免了同步模式下的负面影响,在推理全流程中均能够更为显著地降低推理延迟,提升推理性能。
业务增长新引擎:YRCache 以推理性能撬动业务价值
焱融 YRCache 推理加速方案将昂贵的 GPU 显存与可扩展的高性能存储资源结合,实现 KVCache 的智能分级缓存,为不断增长的缓存数据提供大容量、易扩展的存储空间,同时确保其的快速读写,可将推理效率提升 65%,打造极致的“以存代算”高效率、低成本优势。对于用户而言,使用 YRCache 意味着:
-
数十页、上百页的文档分析不再需要漫长的等待,推理速度数倍提升。
-
长达数十轮乃至上百轮的对话,仍能够保持极低的响应延迟,用户体验流畅自然。
-
处理超长专业文献的 AI Agent 可实现秒级响应,将 AI 转化为生产力。
-
相同 GPU 资源支撑 2 倍以上用户并发,有效下降单位推理成本,提升用户满意度,用户规模增长,助力企业实现业务收入同步增长。
随着多模态模型和超长上下文窗口逐渐成为常态,对高效缓存管理的需求将愈发迫切。焱融 YRCache 方案不仅解决了当前的显存瓶颈,也为未来更复杂、更庞大的 AI 推理应用奠定了坚实基础。商业追求更低的成本、更高的效率和更好的用户体验。我们期待助力所有企业实现低成本、高效率的大模型应用部署,而 YRCache 正是推动这一变革的关键基石。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)