
大模型-多模态-【篇一:扩散模型】
本文系统介绍了扩散模型的核心内容与发展脉络。在基本原理部分,详细阐释了DDPM模型的前向/反向扩散过程、噪声预测优化目标及其与VAE的关联。发展历程方面,梳理了从基础模型到多模态生成的技术演进,包括采样加速、CLIP引导等关键突破。应用领域覆盖计算机视觉、时序预测、NLP及科学计算等多个场景。实战环节提供从零构建MNIST扩散模型、Diffusers库实现、图像生成优化等具体指导,特别介绍了Sta
优质文档
具体内容
如下是对于扩散模型的详细介绍:
一、基本原理介绍
内容:
-
介绍了DDPM:扩散过程:前向过程(给数据添加噪声的过程)、反向过程(将数据去噪声化的过程)
-
优化目标:预测的是噪声残差,即要求后向过程中预测的噪声分布与前向过程中噪声分布的“距离”最小。对应的损失函数是MSE
-
给出了主要的公式推导
-
和VAE的关系:扩散模型其实是一种包含T个隐变量的模型,因此可以看成更深层次的VAE ,而VAE的损失函数可以使用变分推断来得到变分下界(variational lower bound)
二、扩散模型的发展
内容:
-
介绍扩散模型的发展过程
-
开始扩散:基础扩散模型的提出与改进;
-
加速生成:采样器;
-
刷新纪录:基于显式分类器引导的扩散模型;
-
引爆网络:基于CLIP ( Contrastive Language – Image Pretraining ,对比语言﹣图像预处理)的多模态图像生成;
-
再次"出图":大模型的"再学习"方法﹣DreamBooth、LoRA和ControlNet;
-
开启 AI 作画时代:众多商业公司提出成熟的图像生成解决方案。
-
三、扩散模型的应用
内容:
-
介绍了扩散模型在如下场景的应用
-
计算机视觉:图像分割和目标检测;图像超分钟率(将低分辨率图像重建为高分辨率图像);图像修复、翻译和编辑
-
时序数据预测:TimeGrad是首个在多元概率时序数据预测任务中加入扩散思想的自回归模型
-
自然语言处理:Diffusion-LM是首个将扩散模型应用到自然语言领域的扩散语言模型,后续有很多基于Diffusion-LM的应用。不过在NLP领域,主流还是GPT
-
基于文本的多模态:文本生成图像(如DALLE、Imagen、Stable Diffision)、文本生成视频(Meta AI的Make-A-Video,ControlNet Video)、文本生成3D(如点云等)
-
AI基础科学:蛋白质结构生成、材料结构生成
四、从零构建扩散模型
内容:
-
以MNIST数据集为例,从零构建扩散模型
-
环境配置
-
加载数据集
-
退化过程(向数据中添加噪声)
-
构建一个简单的UNet模型
-
训练扩散模型
-
采样过程分析:对于噪声量较低的输入,模型的预测效果是很不错的,当amount=1时,模型的输出接近整个数据集的均值
-
-
UNet模型
-
给出了BasicUNet的具体实现
-
结构图如下
-
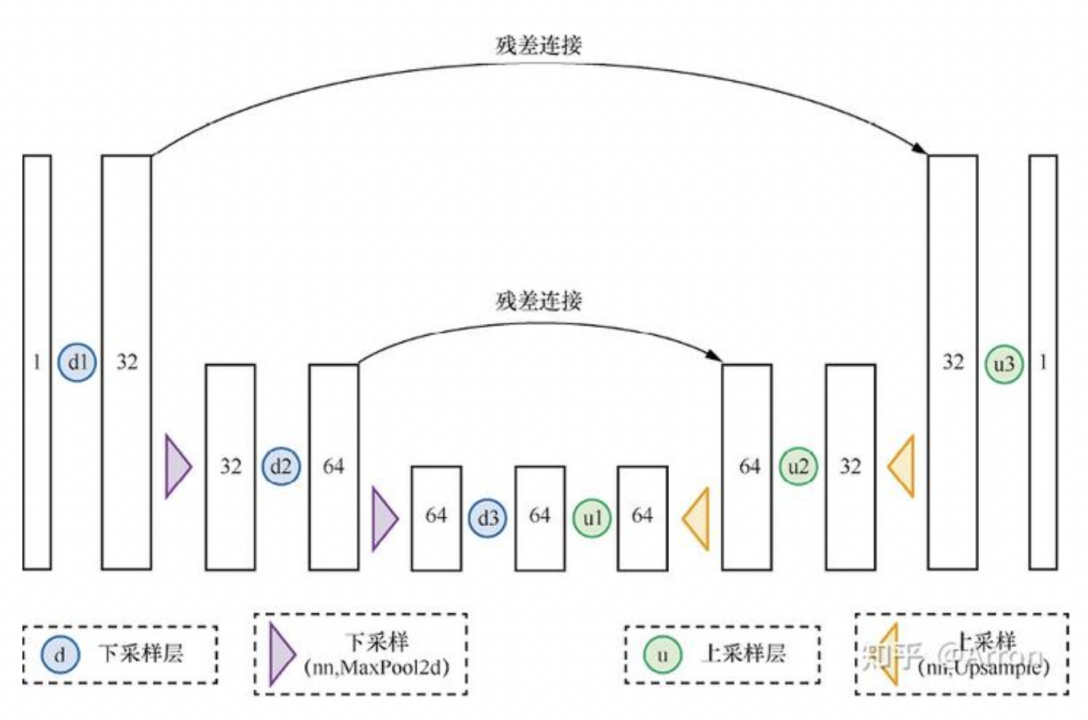
五、采样过程
内容:将预测的方向进行多次迭代,即多次扩散,效果越来越好
六、Diffusers DDPM初探
内容:
-
基于开源库Diffusers实现DDPM模型,在Diffusers库中DDPM模型的实现库是UNet2DModel。
-
论文名称:《Denoising Diffusion Probabilistic Models》
-
预测目标:拟合每个时间步的采样噪声
-
实现
-
UNet2DModel模型比之前介绍的BasicUNet模型有一些改进,具体如下:
-
退化过程的处理方式不同,UNet2DModel通过调节时间步来调节噪声量,t作为一个额外参数被传入前向过程;
-
UNet2DModel有更多的采样策略可供选择。
-
训练目标不同,UNet2DModel旨在预测不带缩放系数的噪声(也就是单位正太分布的噪声)而不是”去噪“的图像。
-
七、Diffusers蝴蝶图像生成实战
参考:扩散模型实战(七):Diffusers蝴蝶图像生成实战
内容:基于DreamBooth实现Stable Diffusion微调,给出了具体的实现代码
开源库Diffusers可以通过DDPMScheduler调度器控制采样
八、微调扩散模型
相比(七),改变点在于更改了调度器(改为DDIMScheduler)的实现。DDIMScheduler:通过更少的迭代周期来产生很好的采样样本,相比DDPMScheduler更快
训练技巧:
-
设置合适的batch_size,在不超过GPU显存的前提下,尽量大一些,这样可以提高GPU计算效果;如果特别小,可以采用梯度累积的方式来更新模型参数,达到和大batch_size类似的效果,也就是多运行几次loss.backward(),再调用optimizer.step()和optimizer.zero_grad();
-
训练过程中,要时不时生成一些图像样本来观察模型性能;
-
训练过程中,可以把损失值、生成的图像样本等信息记录在日志中,可以使用Weights and Biases、TensorBoard等工具
九、使用CLIP模型引导和控制扩散模型
参考:扩散模型实战(九):使用CLIP模型引导和控制扩散模型
介绍使用CLIP控制图像生成的基本流程,具体如下:
-
使用CLIP模型对Prompt表示为512embedding向量;
-
在扩散模型的生成过程中需要多次执行如下步骤:
-
-
生成多个“去噪”图像;
-
对生成的每个“去噪”图像用CLIP模型进行embedding,并对Prompt embedding和图像的embedding进行对比;
-
计算Prompt和“去噪”后图像的梯度,使用这个梯度先更新输入图像X,然后再使用调度器更新X
-
十、Stable Diffusion文本条件生成图像大模型
参考:扩散模型实战(十):Stable Diffusion文本条件生成图像大模型
内容:
-
根据prompt生成图片
-
使用DreamBooth实现Stable Diffusion微调
十一、剖析Stable Diffusion Pipeline各个组件
参考:扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
内容:
-
Stable Diffusion Pipeline要比之前介绍的DDPMPipeline复杂一些,除了UNet和调度器还有其他组件,具体给出VAE、分词器tokenizer、文本编码器text_encoder、UNet、调度器Scheduler的具体实现
-
给出了整个pipeline的具体实现
-
给出了其它pipeline的具体实现:图片到图片风格迁移Img2Img,图片修复Inpainting以及图片深度Depth2Image模型
十二、使用调度器DDIM反转来优化图像编辑
参考:扩散模型实战(十二):使用调度器DDIM反转来优化图像编辑
内容:给出了基于prompt和DDIM实现反转优化图像的具体实现
十三、ControlNet结构以及训练过程
参考:扩散模型实战(十三):ControlNet结构以及训练过程
内容:
-
ControlNet提出背景:解决难以用prompt来指导Stable Diffusion模型,比如人物四肢的角度、背景中物体的位置、每一缕光线的角度的情况
-
ControlNet是一种能够嵌入任意已经训练好的扩散模型,并通过图像Prompt来引入图像特征更加精细的控制扩散模型的生成过程
-
文中给出了一些ControlNet的实例
十四、扩散模型生成音频
内容:给出了基于扩散模型生成音频的代码实现
结尾
亲爱的读者朋友:感谢您在繁忙中驻足阅读本期内容!您的到来是对我们最大的支持❤️
正如古语所言:"当局者迷,旁观者清"。您独到的见解与客观评价,恰似一盏明灯💡,能帮助我们照亮内容盲区,让未来的创作更加贴近您的需求。
若此文给您带来启发或收获,不妨通过以下方式为彼此搭建一座桥梁: ✨ 点击右上角【点赞】图标,让好内容被更多人看见 ✨ 滑动屏幕【收藏】本篇,便于随时查阅回味 ✨ 在评论区留下您的真知灼见,让我们共同碰撞思维的火花
我始终秉持匠心精神,以键盘为犁铧深耕知识沃土💻,用每一次敲击传递专业价值,不断优化内容呈现形式,力求为您打造沉浸式的阅读盛宴📚。
有任何疑问或建议?评论区就是我们的连心桥!您的每一条留言我都将认真研读,并在24小时内回复解答📝。
愿我们携手同行,在知识的雨林中茁壮成长🌳,共享思想绽放的甘甜果实。下期相遇时,期待看到您智慧的评论与闪亮的点赞身影✨!
万分感谢🙏🙏您的点赞👍👍、收藏⭐🌟、评论💬🗯️、关注❤️💚~
自我介绍:一线互联网大厂资深算法研发(工作6年+),4年以上招聘面试官经验(一二面面试官,面试候选人400+),深谙岗位专业知识、技能雷达图,已累计辅导15+求职者顺利入职大中型互联网公司。熟练掌握大模型、NLP、搜索、推荐、数据挖掘算法和优化,提供面试辅导、专业知识入门到进阶辅导等定制化需求等服务,助力您顺利完成学习和求职之旅(有需要者可私信联系)
友友们,自己的知乎账号为“快乐星球”,定期更新技术文章,敬请关注!
更多推荐
 25
25 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)