大模型相关知识
大模型(Large Model / Foundation Model)
一句话定义
参数规模巨大、在海量无标注 / 弱标注数据上自监督预训练、能直接适配大量下游任务的通用人工智能模型。
一、大模型的 3 个核心特点(面试必背)
-
参数规模极大
- 通常亿级、十亿、百亿、千亿参数
- 参数越多,模型记忆能力、理解能力、泛化能力越强
-
数据量极大 + 自监督学习
- 用海量文本、图像、语音等无标注数据训练
- 不靠人工打标签,自己从数据里学规律
- 学到语言规律、世界知识、逻辑、常识
-
通用性极强(一模型多用)
- 不用为每个任务单独训练
- 能做:对话、翻译、写代码、总结、推理、创作、画图…
- 给个 ** 提示(Prompt)** 就能直接用
二、大模型和传统小模型的区别(高频对比)
| 传统小模型 | 大模型 | |
|---|---|---|
| 数据 | 少量标注数据 | 海量无标注数据 |
| 训练 | 监督学习,任务专用 | 自监督预训练 |
| 能力 | 单一任务(分类、识别) | 通用能力,零样本 / 少样本 |
| 用法 | 训练→部署 | 预训练→微调→提示词 |
| 代表 | CNN、SVM、小 Transformer | GPT、文心一言、Llama |
一句话记:小模型是 “专科生”,大模型是 “全才通才”。
三、大模型的关键技术(复试加分)
-
Transformer 架构大模型的基础骨架,靠自注意力机制建模长距离依赖。
-
自监督预训练
- 给一句话遮一部分,让模型猜
- 预测下一个词(GPT 模式)不用人工标签,就能学到语言和知识。
-
上下文学习(In-Context Learning)给几个例子,不用训练、不用改参数,直接学会新任务。
-
指令微调(Instruction Tuning)用各种任务指令再训练一遍,让模型听懂人话。
四、大模型能干嘛?
- 自然语言理解、生成、对话、总结
- 代码生成、数学推理
- 多模态:看图说话、文生图
- 作为基座,快速做各种 AI 应用
五、复试满分口述版(直接背)
“大模型是指参数规模巨大、基于 Transformer 架构、在海量无标注数据上通过自监督学习预训练出来的通用基础模型。它具有强泛化、强理解、强通用的特点,一个模型就能适配多种任务。和传统小模型相比,大模型不再需要大量标注数据和单独训练,通过提示词或少量微调就能使用,是当前人工智能的主流方向。”

MoE(混合专家模型):大模型的 “智能分工” 核心
MoE(Mixture of Experts,混合专家模型)是一种稀疏激活的大模型架构,核心是把大模型拆成多个 “专精领域” 的独立子网络(专家),再用一个 “调度器”(门控网络)按需分配任务,只激活最相关的少数专家,实现 “高总参数量、低实际计算量” 的高效推理。
一、核心组件(面试必背 3 要素)
| 组件 | 作用 | 通俗比喻 |
|---|---|---|
| 专家(Experts) | 多个独立的前馈网络(FFN),每个专家专精一类数据 / 任务,参数互不共享 | 专科医生,比如 “内科专家”“外科专家”,只处理自己擅长的病 |
| 门控网络(Gating/Router) | 接收输入特征,给每个专家打分,选 Top-K 个(通常 K=2)激活,是核心 “调度器” | 分诊台,根据病情分配给对应专科医生,不找全员 |
| 稀疏激活 | 每个输入只激活少数专家,未激活的专家 “休眠”,不耗算力 | 看病只找 2 个医生,其他医生休息,不参与无效计算 |
二、工作流程(一句话记:输入→门控选专家→专家并行算→结果加权合)
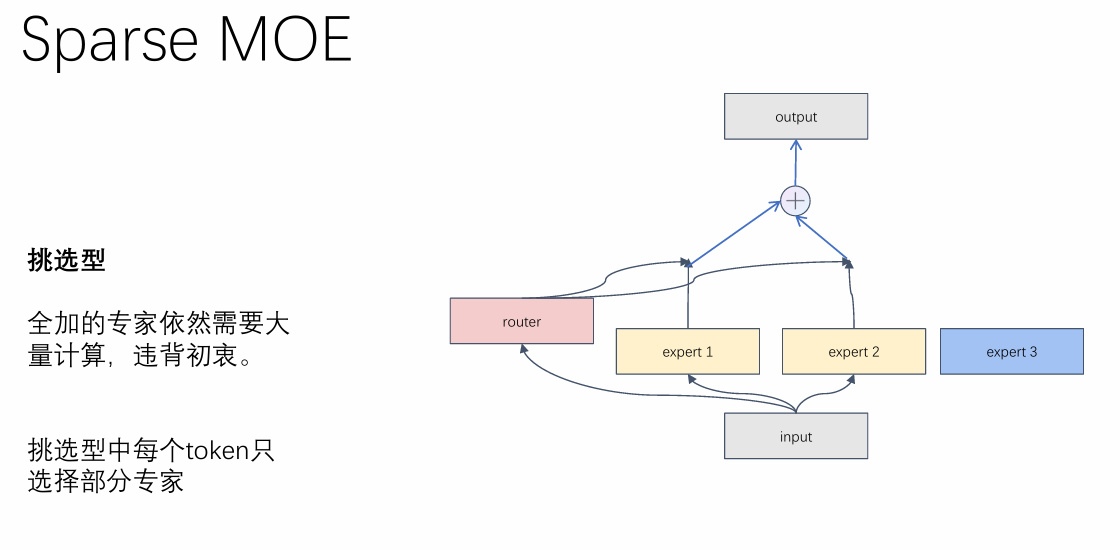
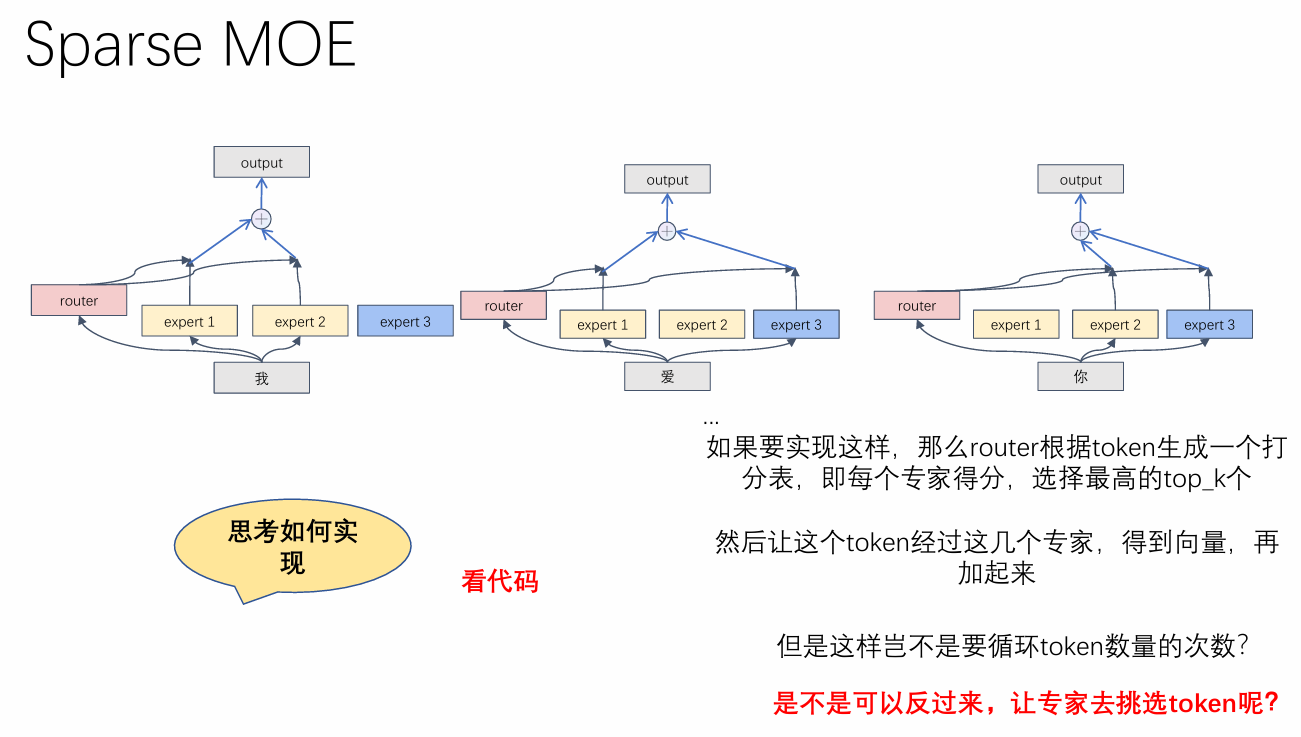
- 输入数据(如 token)进入门控网络,门控计算每个专家的适配度分数;
- 选择分数最高的 K 个专家(比如 Top-2)激活,被激活的专家并行处理输入;
- 各专家输出结果,按门控分数加权求和,得到最终输出;
- 未选中的专家全程不参与计算,大幅节省算力。
三、和传统稠密模型的核心区别
| 对比维度 | 传统稠密模型 | MoE 混合专家模型 |
|---|---|---|
| 激活方式 | 全量激活,所有参数参与计算 | 稀疏激活,仅激活 Top-K 专家 |
| 总参数量 | 参数量越大,计算量越高(线性增长) | 总参数量可扩展至万亿级,计算量不随参数翻倍 |
| 效率成本 | 模型越大越慢、越贵,算力浪费严重 | 高参数 + 低计算,训练 / 推理速度更快、成本更低 |
| 典型案例 | LLaMA-1/2、GPT-3(早期版本) | Mixtral-8x7B、GPT-4(部分模块)、Switch Transformer |
四、核心优势(复试 / 面试加分点)
- 高效扩展:轻松搭建万亿参数模型,不用像稠密模型那样 “堆参数 = 堆算力”;
- 降本提速:单条输入只算少数专家,推理速度、吞吐量提升,成本降低 50% 以上;
- 专业分工:专家可专精不同领域(如代码、数学、对话),整体能力更均衡;
- 灵活适配:支持共享专家(处理通用数据)+ 专属专家(处理细分数据),实用性强。
五、复试 / 面试口述版(直接背)
“MoE(混合专家模型)是一种稀疏激活的大模型架构,核心是将传统单一生成的稠密网络,拆分为多个独立的‘专家子网络’和一个‘门控调度网络’。每个专家专精一类任务或数据模式,门控网络根据输入特征动态选择 Top-K 个专家激活,仅让少数专家参与计算。它的关键是稀疏激活,在保持总参数量巨大的同时,大幅降低单条样本的推理计算量,兼顾模型容量和效率。相比传统稠密模型,MoE 能以更低成本实现万亿参数级模型,是当前大模型轻量化、高性能扩展的主流技术,典型代表有 Mixtral-8x7B、Switch Transformer 等。”
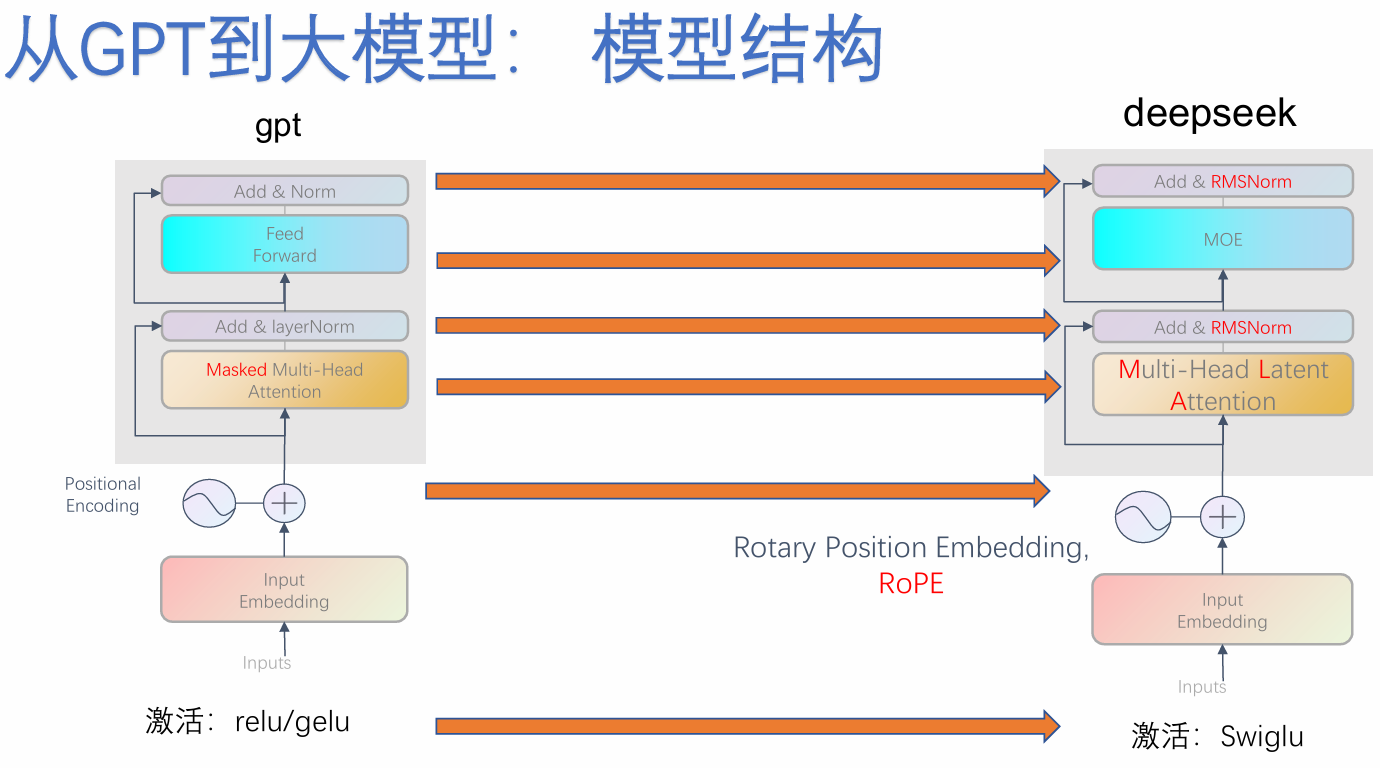
一、GPT 是什么?
GPT 全称:Generative Pre-trained Transformer生成式预训练 Transformer 模型
它有三个特点:
- 基于 Transformer 架构
- 只用 Decoder 结构(自回归)
- 从左到右预测下一个词来生成文本
二、为什么说 GPT 是大模型?
因为它满足大模型的所有条件:
- 参数巨大(从 GPT-1 亿 → GPT-3 1750 亿 → GPT-4 更大)
- 海量无标注数据预训练
- 通用能力极强
- 能做上下文学习、零样本 / 少样本学习
所以:GPT 是目前世界上最典型、最成功的大模型。
三、大模型 ≠ 只有 GPT
大模型是一个大类,包括:
- GPT 系列(OpenAI)
- Llama 系列(Meta)
- 文心一言、通义千问、混元、星火
- Claude、Gemini
它们都是大模型,只是架构、训练方式不一样。
四、超简面试口述版(直接背)
“GPT 是 OpenAI 提出的生成式预训练 Transformer 模型,是目前最典型、最成功的大模型之一。它通过自回归预测下一个词的方式预训练,具备强大的通用理解、生成和推理能力。大模型是一个更广泛的概念,GPT 只是其中最具代表性的一类。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)