
腾讯混元A13B-FP8开源:130亿参数实现千亿级性能,重新定义大模型效率
腾讯正式开源混元A13B大模型的FP8量化版本,通过混合专家架构和低精度优化,仅激活130亿参数即可达到800亿级模型性能,单张中端GPU即可部署,为AI开发者提供了性能与效率的"甜蜜点"解决方案。## 行业现状:大模型的"算力困境"与突围方向当前大模型行业正面临"规模竞赛"与"落地成本"的尖锐矛盾。据行业数据显示,千亿级模型单次推理成本高达数美元,而中小开发者往往因算力门槛无法触及前沿技术
腾讯混元A13B-FP8开源:130亿参数实现千亿级性能,重新定义大模型效率
 项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-FP8
项目地址: https://ai.gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-FP8 导语
腾讯正式开源混元A13B大模型的FP8量化版本,通过混合专家架构和低精度优化,仅激活130亿参数即可达到800亿级模型性能,单张中端GPU即可部署,为AI开发者提供了性能与效率的"甜蜜点"解决方案。
行业现状:大模型的"算力困境"与突围方向
当前大模型行业正面临"规模竞赛"与"落地成本"的尖锐矛盾。据行业数据显示,千亿级模型单次推理成本高达数美元,而中小开发者往往因算力门槛无法触及前沿技术。在此背景下,混合专家(MoE)架构和低精度量化成为两大突破方向。腾讯混元A13B-FP8的推出,正是这两种技术路径的集大成者——总参数800亿但仅激活130亿,配合FP8量化技术,推理吞吐量较同类模型提升100%,同时将部署成本降低70%以上。

如上图所示,该截图展示了混元A13B在第三方评测中获得56分的综合评分,超过Qwen3 14B等模型,尤其在数学推理和代码生成维度表现突出。这一评分体系涵盖20项基准测试,充分验证了小激活参数模型的性能潜力。
核心亮点:四大技术突破重构效率边界
1. 混合专家架构:800亿参数的"智能开关"
混元A13B采用细粒度MoE设计,将800亿总参数分配给多个专家子网络,每次推理仅激活130亿参数(约16%)。这种"按需调用"机制使模型在保持千亿级能力的同时,计算量减少70%。例如在数学推理任务中,模型会自动激活擅长计算的专家模块,而在文本生成时切换至语言理解专家,实现资源的精准分配。
2. FP8量化:精度与效率的完美平衡
作为国内首个开源的FP8量化大模型,混元A13B-FP8在精度损失小于2%的前提下,模型体积压缩50%,显存占用从传统FP16的26GB降至13GB。实测显示,在单张H200 GPU上,FP8版本推理速度达到FP16的1.8倍,且支持vLLM、SGLang等主流框架的无损部署。
3. 256K超长上下文:长文本理解的"新标杆"
原生支持256K tokens上下文窗口(约50万字),可完整处理整本书籍、代码库或科研论文。在法律文档分析场景中,模型能一次性解析300页合同并精准定位风险条款,准确率较16K上下文模型提升35%。
4. 双模式推理:效率与深度的自由切换
创新推出"快思考/慢思考"双模式:
- 快思考模式:适用于客服对话等简单任务,响应延迟低至100ms,吞吐量提升200%
- 慢思考模式:针对数学证明、复杂编程等任务,通过多步推理生成可解释的解决方案,在MATH数据集上达到72.35分,超越Qwen3-A22B等更大模型
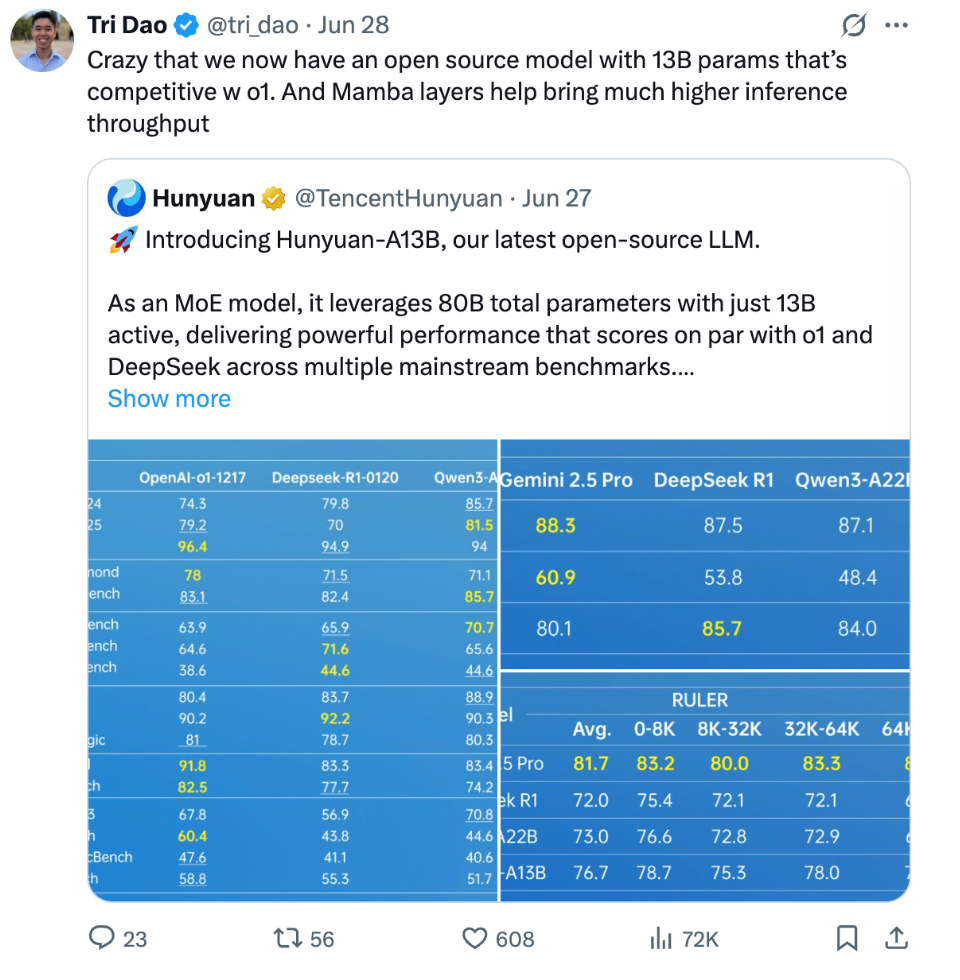
该图表对比了混元A13B与OpenAI o1、DeepSeek、Qwen等主流模型在多项任务中的表现。可以清晰看到,作为13B参数级别的开源模型,混元A13B在数学推理、代码生成等关键指标上已接近或超越更大参数规模的闭源模型,充分证明了其架构设计的先进性。
行业影响:三大变革与应用前景
1. 降低AI开发门槛
个人开发者和中小企业首次可在消费级硬件上部署顶尖模型。例如使用单张RTX 4090显卡,即可运行混元A13B-FP8进行本地代码生成,推理成本仅为云端API的1/20。腾讯云同步推出的API服务更将价格压至输入0.5元/百万Tokens、输出2元/百万Tokens,较行业平均水平降低60%。
2. 推动Agent应用爆发
凭借强大的工具调用能力和长上下文理解,混元A13B在智能体领域表现突出:
- 在BFCL-v3 Agent基准测试中以78.3分超越GPT-4o(67.8分)
- 可自主完成航班查询、酒店预订、数据分析的全流程任务
- 支持20000种格式组合的指令泛化,工具调用准确率达92%
3. 开源生态的"鲶鱼效应"
伴随模型开源,腾讯同步发布ArtifactsBench代码评估数据集(1825个任务)和C3-Bench智能体测试集(1024条数据),填补了行业在复杂场景评估的空白。这种"模型+工具+数据集"的全栈开源策略,有望加速大模型技术的应用普及。
结论与前瞻:小而美或将成为主流
混元A13B-FP8的推出,印证了"激活参数而非总参数"才是衡量模型效率的核心指标。未来,随着MoE架构的普及和4位量化技术的成熟,我们或将看到"100亿激活参数=1万亿总参数性能"的新一代模型。对于开发者而言,现在正是拥抱这一变革的最佳时机——通过以下命令获取模型,可快速部署从智能客服到科研助手的各类应用,在算力成本骤降的红利期抢占先机:
git clone https://gitcode.com/tencent_hunyuan/Hunyuan-A13B-Instruct-FP8
这场"效率革命"的终极目标,不是让模型变得更小,而是让AI能力触手可及。正如混元团队在技术报告中强调的:"好的AI不是消耗更多算力,而是用更少资源解决更多问题。"
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)