【论文阅读】π∗ 0.6: a VLA That Learns From Experience
人类纠正机器的操作,机器不仅学习到正确的操作,还能通过value head判断之前哪里做的不好,导致了人类干预,从而避免再次出现该问题。注意:训练被分成了2个阶段,第一阶段训练value network,下一阶段训练policy network。,机器没做好的地方,人类给出打分,但是并没有干预其action。打分通过reward,使得机器意识到哪些动作是不好的,从而进行纠正。,针对机器探索到的分布
【论文阅读】π∗ 0.6: a VLA That Learns From Experience
1 论文信息
2 任务背景
2.1 核心贡献—Recap
这篇文章提出了一套训练方法(RL with Experience and Corrections via Advantage-conditioned Policies)
这套方法主要包含3个重点:
- 真机强化学习(RL with Experience)
- 专家干预(Corrections)
- 优势条件化(Advantage-conditioned)
2.2 专家干预的发展脉络
2010-2020:DAgger,针对机器探索到的分布外场景,人类进行干预,得到新的数据集。这部分数据用于模仿学习,而不是强化学习。
2022-2025:RLHF人类反馈强化学习,机器没做好的地方,人类给出打分,但是并没有干预其action。打分通过reward,使得机器意识到哪些动作是不好的,从而进行纠正。
pi*0.6:Recap,人类纠正机器的操作,机器不仅学习到正确的操作,还能通过value head判断之前哪里做的不好,导致了人类干预,从而避免再次出现该问题。
2.3 模型说明
pi0.5 + larger backbone and more diverse conditioning = pi0.6
pi0.6 + RL = pi*0.6
3 前置知识
3.1 知识隔离 Knowledge Insulation
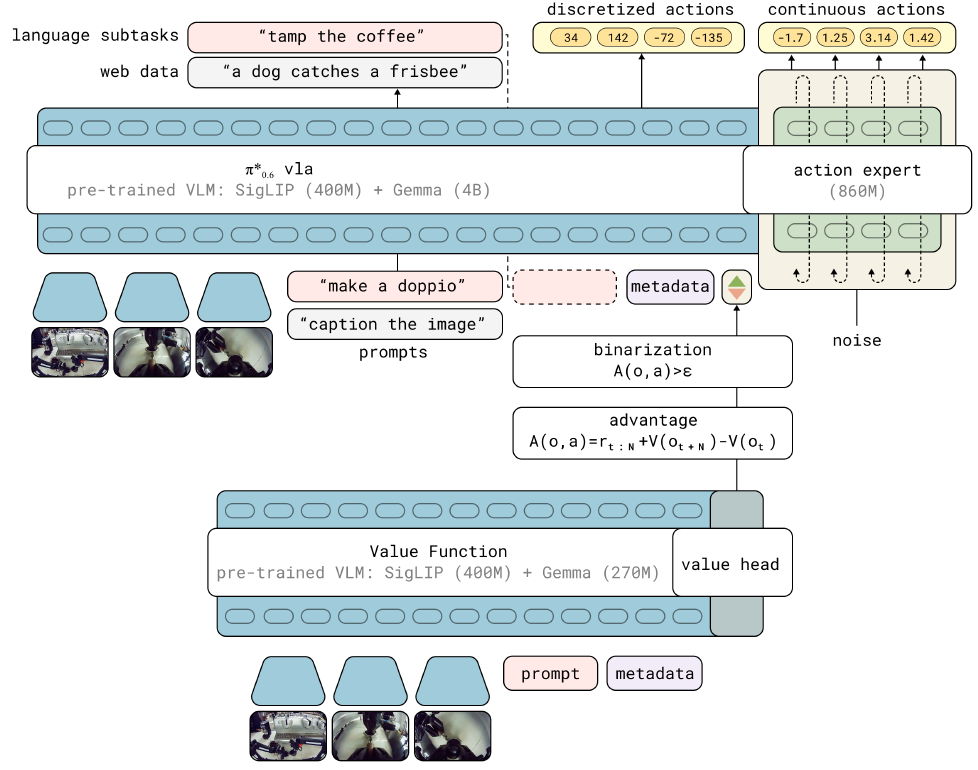
问题背景:VLM增加action expert之后,action export的权重是随机初始化的,对其进行训练时,梯度会反传到VLM主干上,导致VLM性能下滑,甚至听不懂prompt。但是如果不反传,预训练的VLM也不足以解决复杂的机械臂操作问题。
解决方案:
- 核心原理:梯度停止。VLM和action expert的梯度断开。VLM只依靠离散的动作tokens进行更新。
- 实现方式:VLM自回归离散动作,Action export(FM)输出连续轨迹。离散动作的自回归是VLM熟悉的方式,VLM 主干只用离散动作 token 的梯度来更新,离散动作的监督信号是真值的离散化信息。VLM 嵌入可以给动作专家,但连续动作专家的梯度只更新自己的参数。
- Key insight:next token prediction是保证VLM语义理解能力不退化的原因。
参考论文:《Knowledge insulation vision-language models: Train Fast, Run Fast, and Generalize Better》
3.2 无分类器的引导 Classifier-free guidance
4 具体做法
3.1 Pipeline
下述步骤循环往复:
- 收集数据。这一步用到了dataset aggregation,每次迭代都会增加新数据,包含专家接管数据。
- 训练Value function。它是一个VLM,由SigLIP(400M)+Gemma(270M)构成。其中,sigLIP (Sigmoid Loss for Language-Image Pre-training) 是 Google 的语言-视觉模型,输入语言和图像,计算其高维表征,输出相似度分数,可以提升语言与图像的对齐能力。
- 训练VLA。它是一个VLM+action expert。其中VLM有SigLIP(400M)+Gemma(4B)构成。
注意:训练被分成了2个阶段,第一阶段训练value network,下一阶段训练policy network。这在之前已经有类似的工作。
3.1 数据
数据主要分为3类:
- 演示数据
- 真机实操数据
- 专家纠正数据
疑问
pi*0.6只用了强化学习,没有使用模仿学习吗?demonstrations怎么使用?

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)