从零开始之Qwen3微调及部署
摘要 本文详细介绍了在阿里魔搭社区和AutoDL平台上微调Qwen3语言模型的方法。主要内容包括:注册训练可视化工具SwanLab、医疗数据集预处理、两种平台的具体操作流程(实例创建、数据准备、参数配置等),以及使用ms-swift框架进行模型微调的完整步骤。文章提供了关键参数说明和平台链接,帮助开发者快速实现Qwen3模型的定制化训练。
从零开始之Qwen3微调及部署
前言
Qwen3是阿里云通义千问团队于2025年4月29日发布的最新大型语言模型系列,包含2个MoE模型和6个Dense模型。其基于广泛的训练,在推理、指令跟随、Agent 能力和多语言支持方面取得了突破性的进展。当我们需要针对模型的特定的能力进行增强时,需要对Qwen3的模型进行微调。本文将分别介绍两种线上微调的方案,分别为在阿里的魔搭社区平台 和 AutoDL 平台上微调。微调框架采用的是阿里的 ms-swift
一、工具列表
- 魔搭社区平台
- AutoDL
- ms-swift
- 微调数据集(精致的医疗r1数据)
- 训练过程可视化平台 SwanLab
二、注册SwanLab
SwanLab 是一款开源、轻量的 AI 模型训练跟踪与可视化工具,提供了一个跟踪、记录、比较、和协作实验的平台。SwanLab传送门。注册后,将API KEY记录下,用于后续微调时的监控。API KEY的获取方式如下图所示。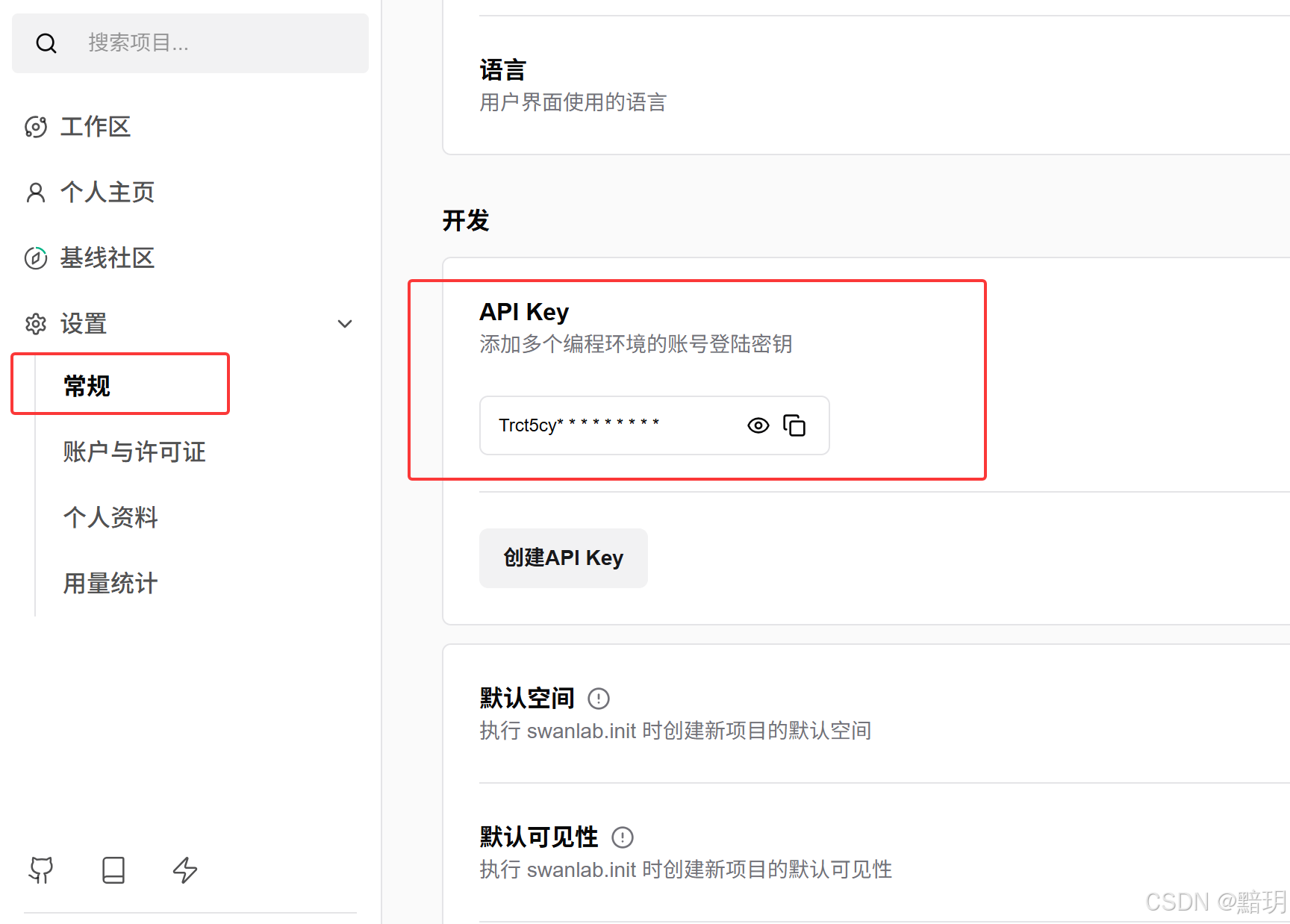
三、微调数据集预处理
1. 下载微调数据集
本文采用的微调数据集为精致的医疗r1数据,医疗r1数据传送门
2. 数据预处理
2.1. 微调数据格式
Qwen3具有思考模式。其微调需要的数据格式可参考 ms-swift 官方数据格式,微调数据格式传送门 ,Qwen3微调数据格式传送门
# 通用格式
{"messages": [
{"role": "system", "content": "<system-prompt>"},
{"role": "user", "content": "<query1>"},
{"role": "assistant", "content": "<response1>"}
]}
# 带think的格式
{"messages": [
{"role": "user", "content": "Where is the capital of Zhejiang?"},
{"role": "assistant", "content": "<think>\n...\n</think>\n\nThe capital of Zhejiang is Hangzhou."}
]}
# 不带think的格式
{"messages": [
{"role": "user", "content": "Where is the capital of Zhejiang?"},
{"role": "assistant", "content": "<think>\n\n</think>\n\nThe capital of Zhejiang is Hangzhou."}
]}
{"messages": [
{"role": "user", "content": "Where is the capital of Zhejiang? /no_think"},
{"role": "assistant", "content": "<think>\n\n</think>\n\nThe capital of Zhejiang is Hangzhou."}
]}
2.2. 微调数据处理
可参考项目ms-swift微调Qwen3完成医疗问答任务中的处理数据的代码,将数据处理成 2.1. 中的数据结构即可。ms-swift微调Qwen3完成医疗问答任务传送门
四、魔搭社区平台微调流程
魔搭社区平台是阿里达摩院于近一年刚上线的一款开源模型平台,里面提供了很多的热门模型供使用体验,而且与阿里云服务进行联动,让开发者免除了额外的部署成本,实现了模型推理与调优的极速体验。
1. 登录魔搭社区
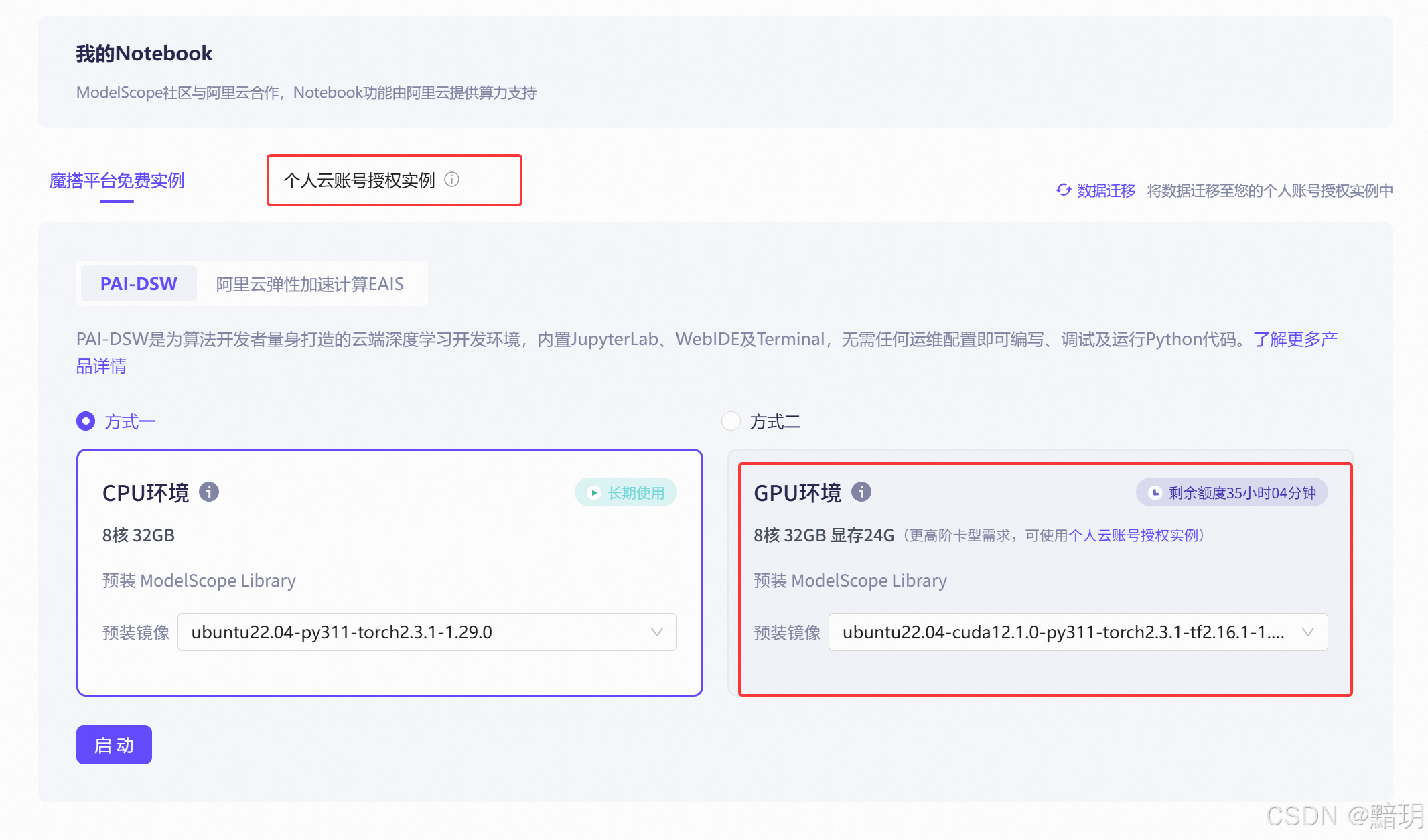
进入魔搭社区的官网,魔搭社区传送门。进入后,点击左侧菜单栏中的【我的Notebook】。如下图所示。可选择【魔搭平台免费实例】中的GPU环境或【个人云账号授权实例】,对于新人【魔搭平台免费实例】有对应的免费额度,【个人云账号授权实例】也有连续3个月的免费定额。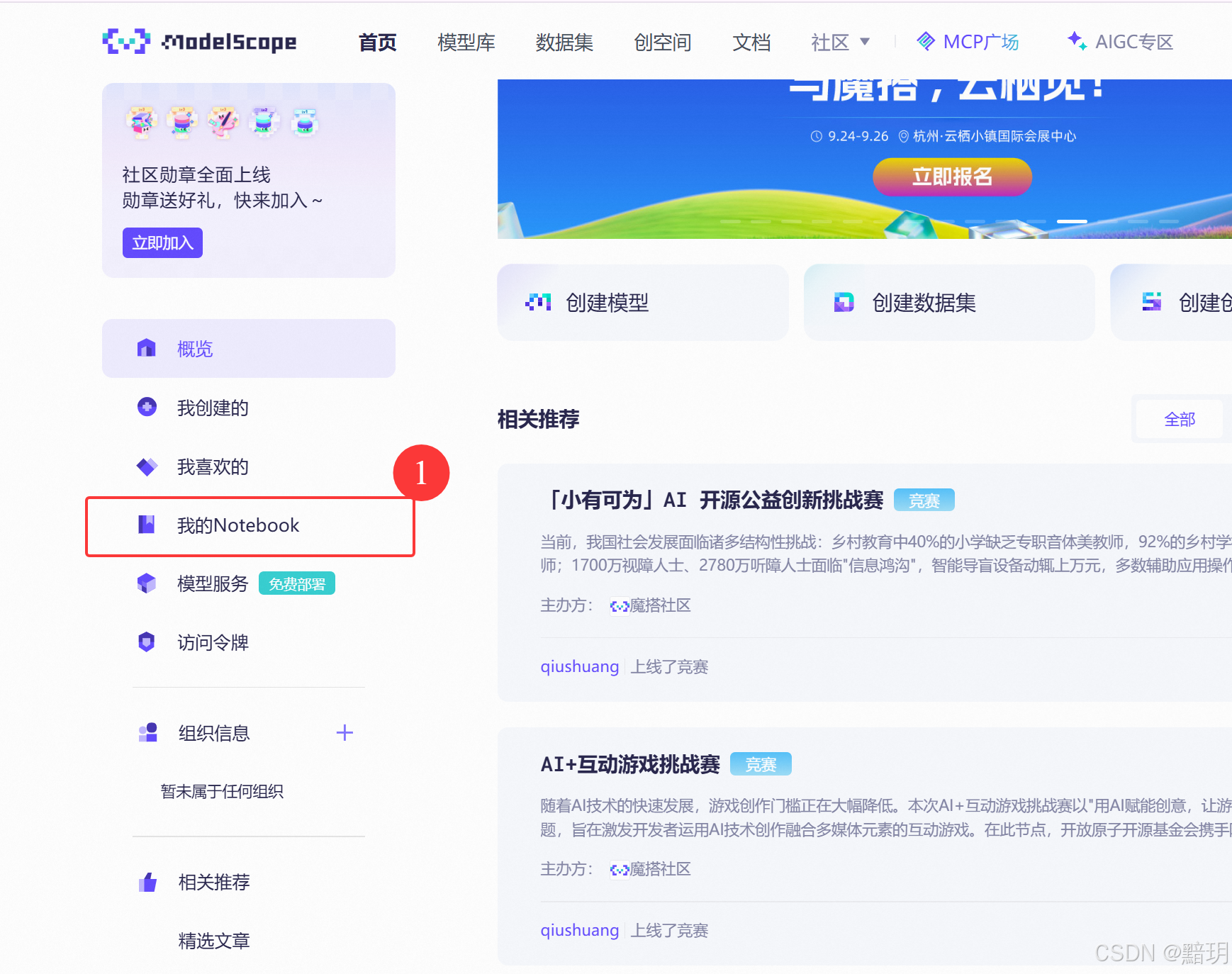
2. 创建实例
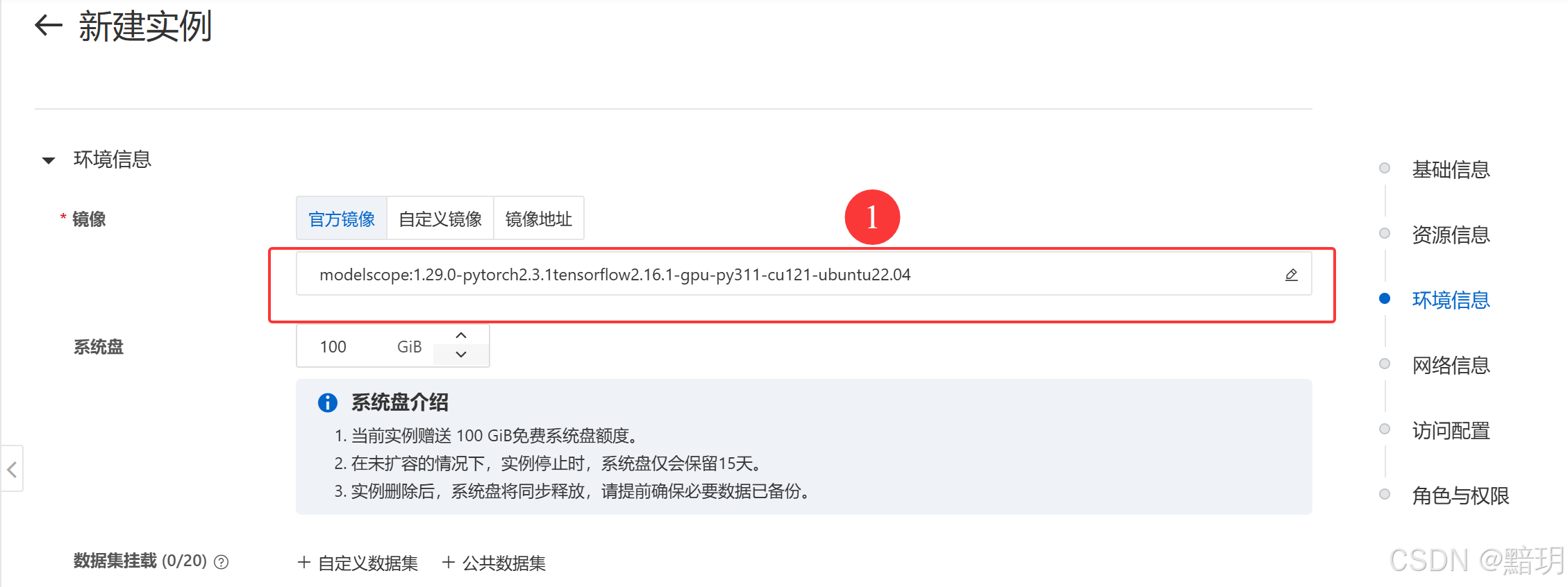
【魔搭平台免费实例】中创建GPU实例,直接选择镜像即可,本文使用的镜像为【modelscope:1.29.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04】,【个人云账号授权实例】页面中点击【创建实例】后,进入【创建实例】页面。其中资源规格选择的是【NVIDIA A10】,镜像版本选择的是【modelscope:1.29.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04】。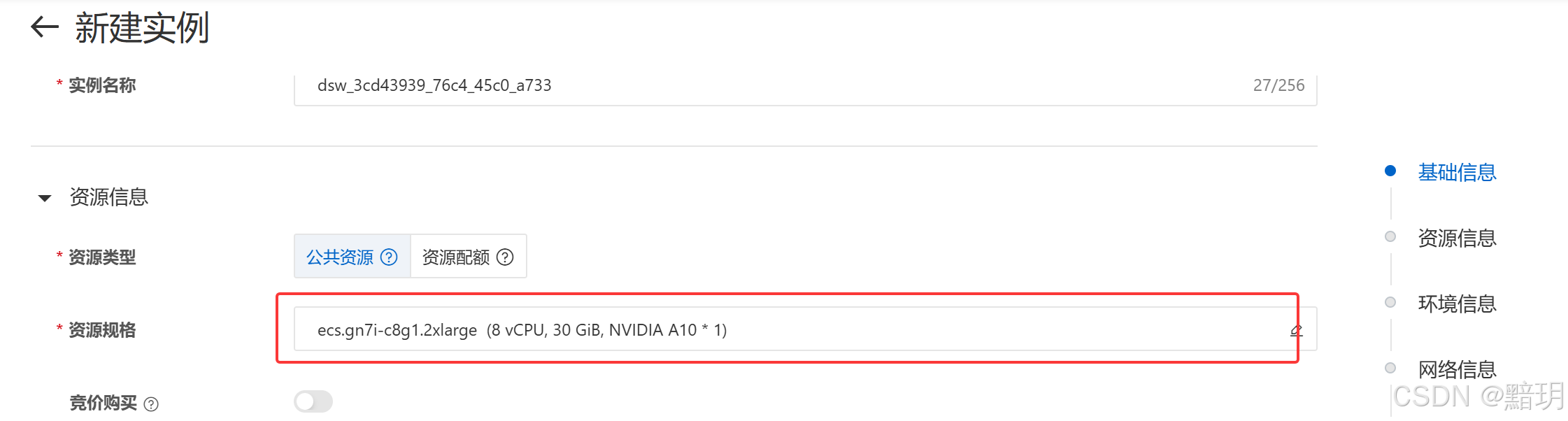
3. 启动实例
实例创建完成后,在实例列表界面直接点击【启动】即可。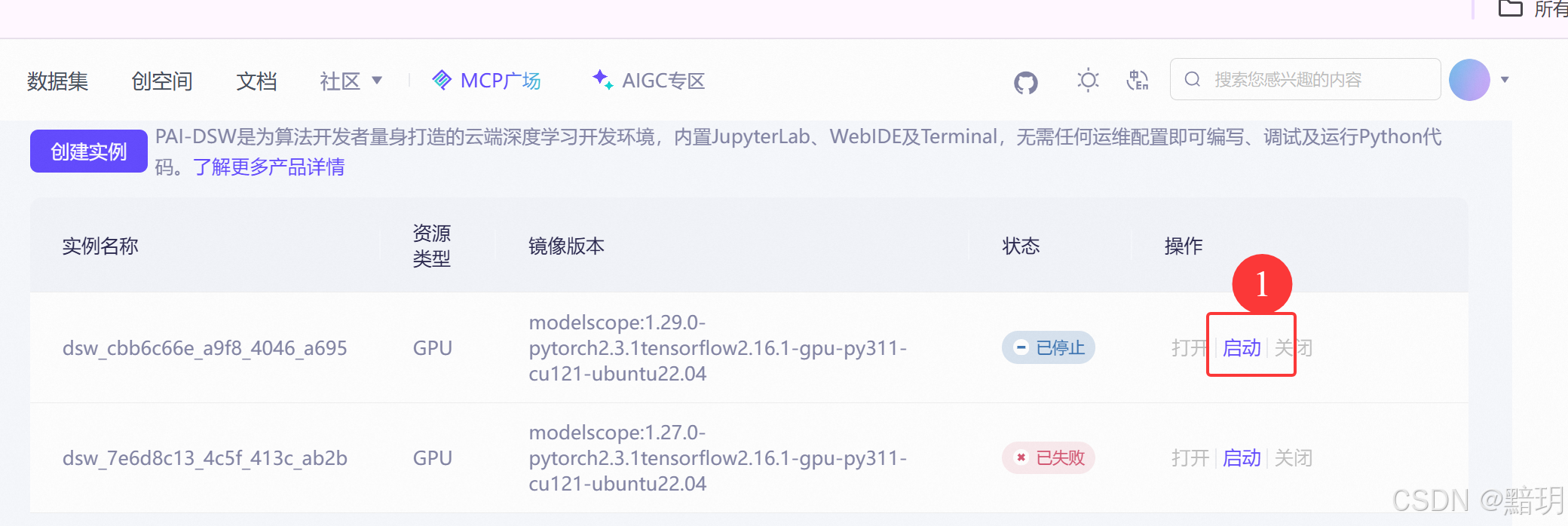
4. 放置数据
通过上传的方式,将步骤【微调数据集预处理】中处理后的微调数据和验证数据存放在/data路径下,分别命名为 【traindata.jsonl】和【valdata.jsonl】,并在根目录下创建一个train.sh文件,文件内容如下所示。其中的主要参数说明:
- model:微调的基础模型
- train_type:为微调的方式
- dataset:微调的数据集
- val_dataset:微调的验证数据集
- bnb_4bit_compute_dtype,bnb_4bit_quant_type,bnb_4bit_use_double_quant,quant_method,quant_bits 为量化相关配置
- num_train_epochs:训练轮数
- loss_scale:在训练期间,指定 –loss_scale ignore_empty_think,以忽略对 <think>\n\n</think>\n\n 的损失计算,当微调数据中有不含思维链的数据时采用
- model_author,model_name,report_to,swanlab_project 为将微调过程上传到Swanlab平台方便进行监控
- 其余参数详解可参考官方参数文档,官方命令行参数详解传送门
# 24GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen3-8B \
--train_type lora \
--dataset ./data/traindata.jsonl \
--val_dataset ./data/valdata.jsonl \
--torch_dtype bfloat16 \
--bnb_4bit_compute_dtype bfloat16 \
--bnb_4bit_quant_type nf4 \
--bnb_4bit_use_double_quant true \
--quant_method bnb \
--quant_bits 4 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-5 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 8192 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--loss_scale ignore_empty_think \
--model_author swift \
--model_name swift-test\
--report_to swanlab \
--swanlab_project swift-test
5. 开始微调
打开终端输入以下命令即可。首次微调时会提示你登录SwanLab,输入步骤二中获得的【API KEY】即可。
bash train.sh
五、AutoDL平台微调流程
AutoDL 是一个算力平台,可以在此平台上租用GPU服务。AutoDL官网传送门
1. 租用GPU实例
本文选择的GPU实例如下图所示,GPU选择的RTX 3090(24GB),镜像选择的是 PyTorch 2.5.1 Python 3.12(ubuntu22.04)CUDA 12.4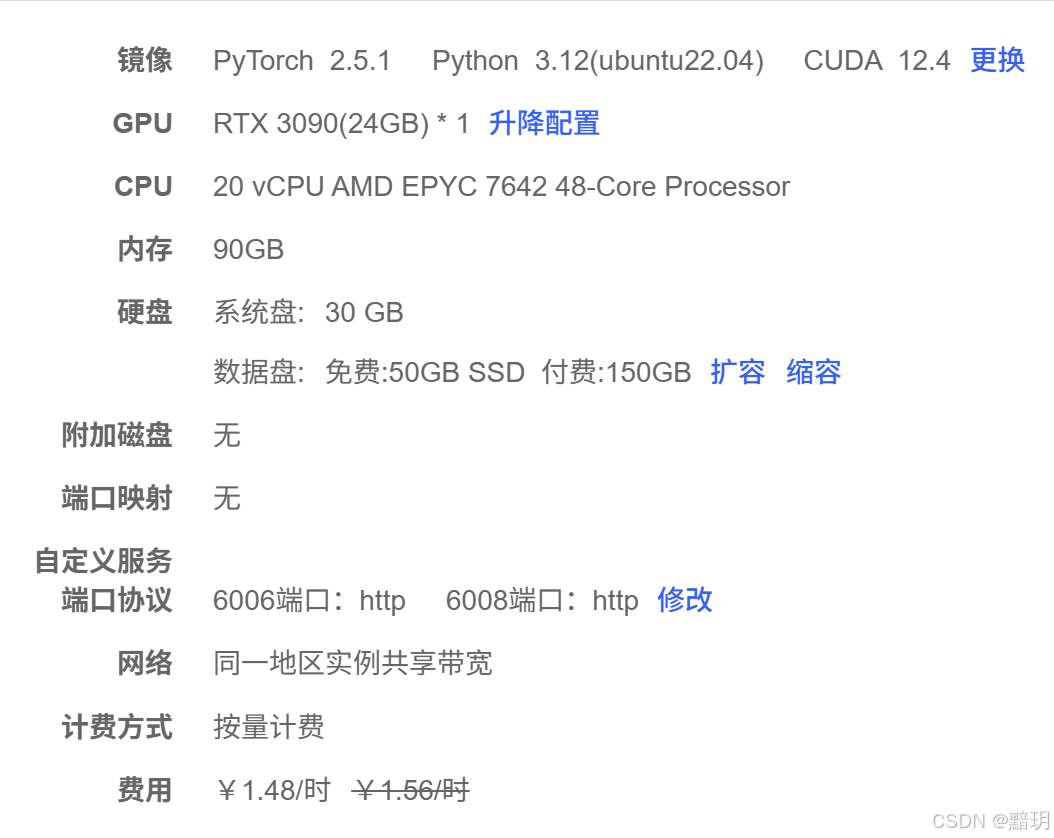
2. 安装环境
因为AutoDL不像魔搭社区一样提前内置环境,所以我们需要安装相应的环境并进行配置。
2.1. 安装 ms-swift
此安装为ms-swift训练框架所需,打开终端后输入如下命令安装
pip install ms-swift -U

2.2. 安装 swan-lab
此安装为swanLab监控所需,在终端中输入如下命令安装
pip install swanlab

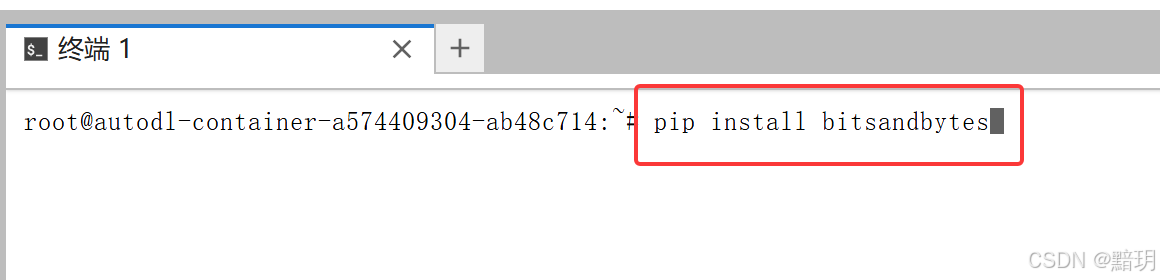
2.3. 安装 bitsandbytes
此安装为量化所需,在终端中输入如下命令安装
pip install bitsandbytes
2.4. 其他安装
如下不是必要安装,只是记录下安装时的问题。
pip install deepspeed # 多GPU训练
pip install liger-kernel # 节约显存资源
pip install flash-attn --no-build-isolation # packing需要
如果在安装【flash-attn】时遇到 Could not build wheels for flash-attn, which is required to install pyproject 问题,可参考此文章。flash-attn安装问题解决方案传送门
3. 上传微调数据
上传微调数据需要用ssh连接到AutoDL上的服务,本文采用的是 FinalShell,FinalShell下载官网,FinalShell连接AutoDL可参考文档 AutoDL用XShell传输文件帮助传送门。
3.1. 配置FinalShell
打开FinalShell后,点击如下按钮,新增连接。
- 名称:可随意
- 主机:复制AutoDL上的登录指令,如下图所示。复制出的内容类似如下文本,此时将 @ 后的内容复制到 【主机】即可。

ssh -p 19423 root@connect.nmb2.seetacloud.com
- 端口:将 ssh -p 后面的端口号复制上即可。即 19423
- 用户名:填入 @ 前的内容,即 root
- 密码:复制AutoDL上的密码即可,如下图所示。

填写完成后如下图所示。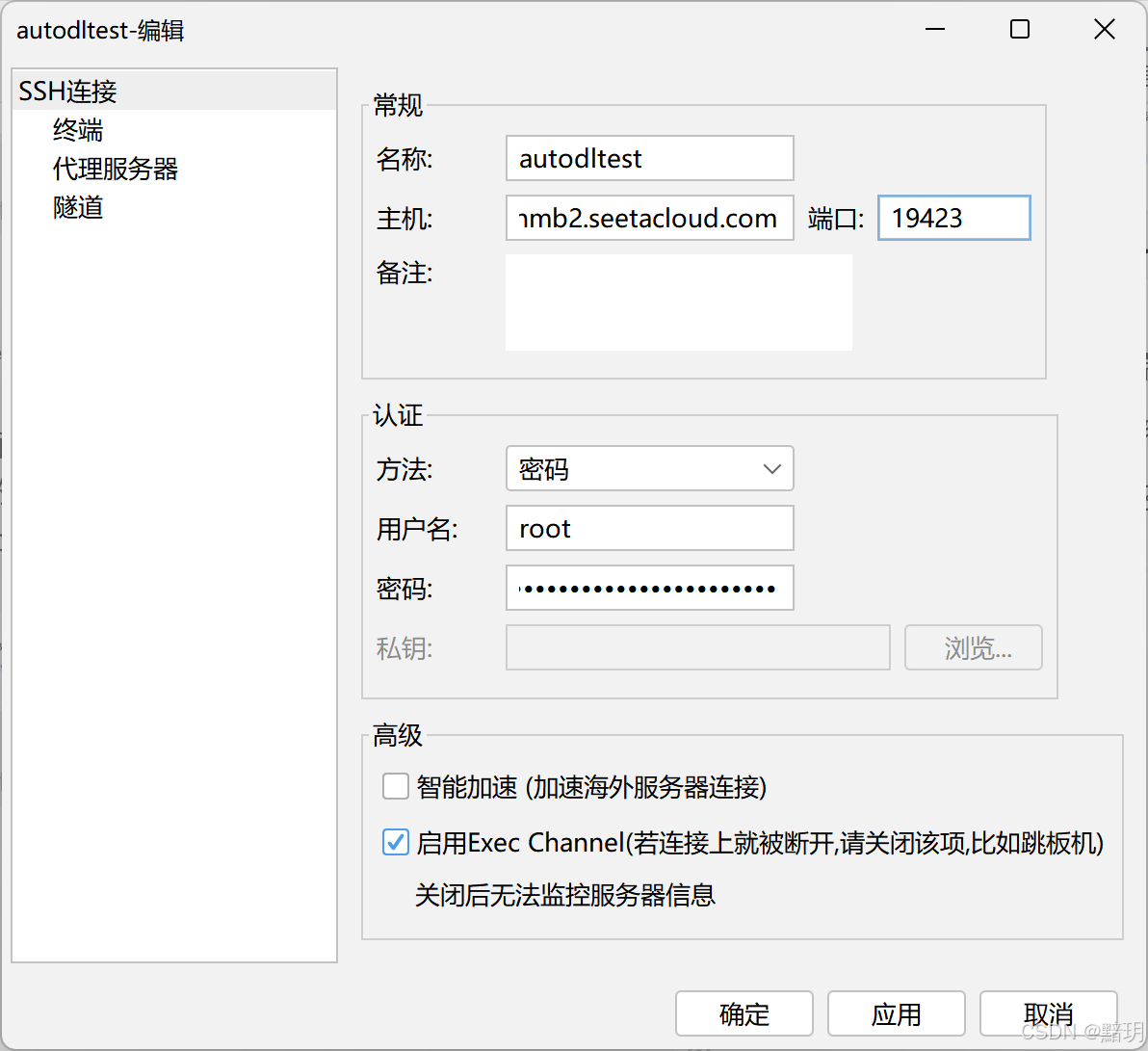
3.2. 上传微调数据
利用FinalShell 上传微调数据到AutoDL,如下图所示。请一定要上传数据到 autodl-tmp 文件夹下,这样重置系统时数据盘和文件存储中的数据不受影响。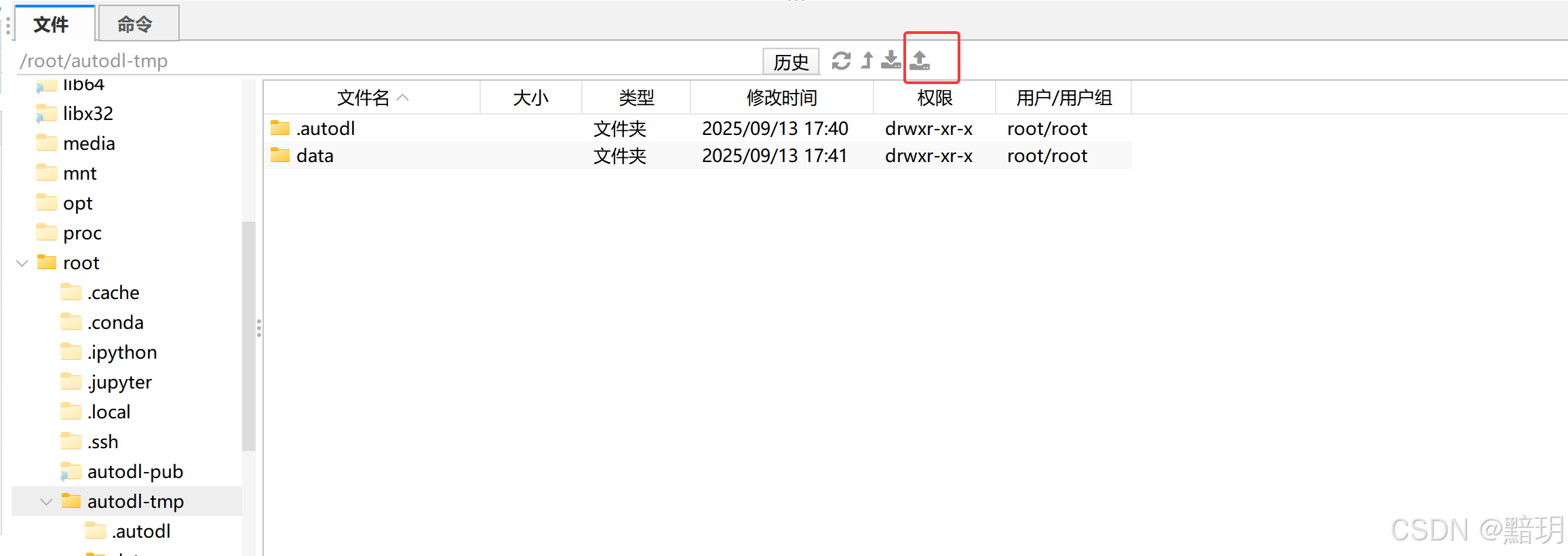
4. 开始微调
4.1. 创建train.sh文件
在 autodl-tmp 目录下创建 train.sh 文件,文件内容如下所示。其中的 export MODELSCOPE_CACHE=‘/root/autodl-tmp’ 部分为设置ms-swift将基础模型Qwen3-8B下载的路径,以防系统重置后重新下载,且放在autodl-tmp路径下占用的是数据盘,不占用系统盘。
export MODELSCOPE_CACHE='/root/autodl-tmp'
# 24GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen3-8B \
--train_type lora \
--dataset ./data/traindata.jsonl \
--val_dataset ./data/valdata.jsonl \
--torch_dtype bfloat16 \
--bnb_4bit_compute_dtype bfloat16 \
--bnb_4bit_quant_type nf4 \
--bnb_4bit_use_double_quant true \
--quant_method bnb \
--quant_bits 4 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-5 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 8192 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--loss_scale ignore_empty_think \
--model_author swift \
--model_name swift-test\
--report_to swanlab \
--swanlab_project swift-test
4.2. 执行train.sh
切换到autodl-tmp目录下后,执行train.sh即可。
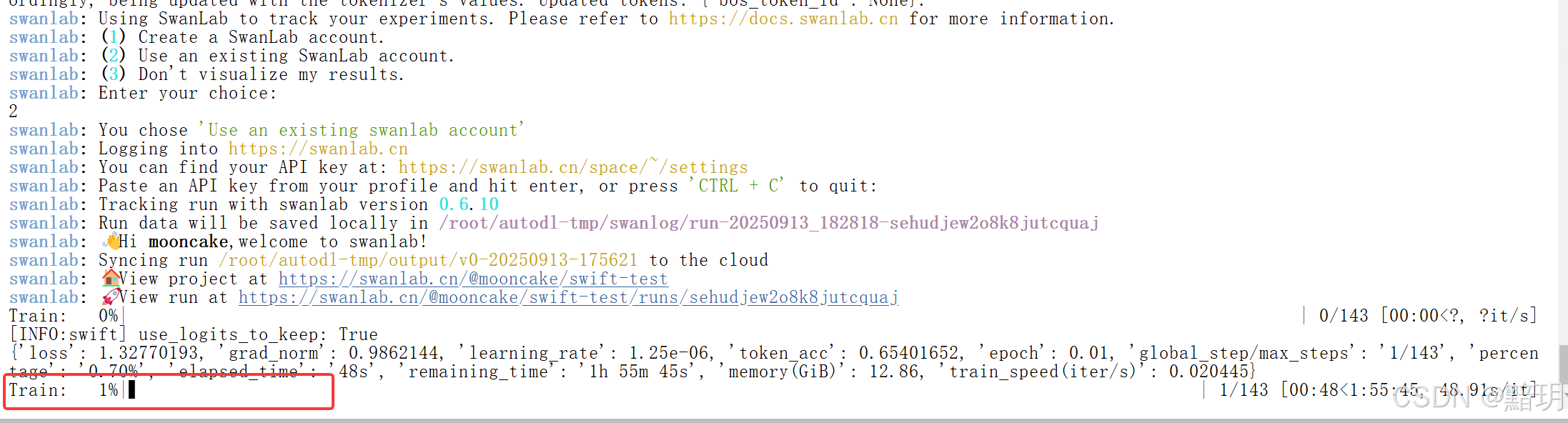
在train.sh运行过程中,如果是第一次运行,会要求你选择SwanLab账号,如下图所示。提示你是使用已有的,还是创建新的。本文采用已有的账号,因此输入2,回车确认。
然后提示你输入SwanLab上已有的API KEY,其API KEY的获取方法见步骤二。复制后单击鼠标右键选择【粘贴】即可粘贴好,然后回车确认。
显示下图的训练进度,即开始训练,等待训练完成即可。
5. 部署服务
完成微调后,即可进行部署。官方参考文档可参考 微调部署官方文档传送门 。
5.1. 安装VLLM
利用VLLM可以提升推理速度,通过如下命令安装即可。
pip install vllm -U
5.2. 创建推理脚本
本文在autodl-tmp的目录下创建deploy.sh文件,其内容如下所示。其中 adapters 参数对应为 lora 微调后生成的checkpoint的路径。
export MODELSCOPE_CACHE='/root/autodl-tmp'
CUDA_VISIBLE_DEVICES=0 \
swift deploy \
--adapters ./output/v0-20250913-175621/checkpoint-450 \
--infer_backend vllm \
--temperature 0 \
--max_new_tokens 8192 \
--max_model_len 24576
--served_model_name 'swift-test'
5.3. 开始部署
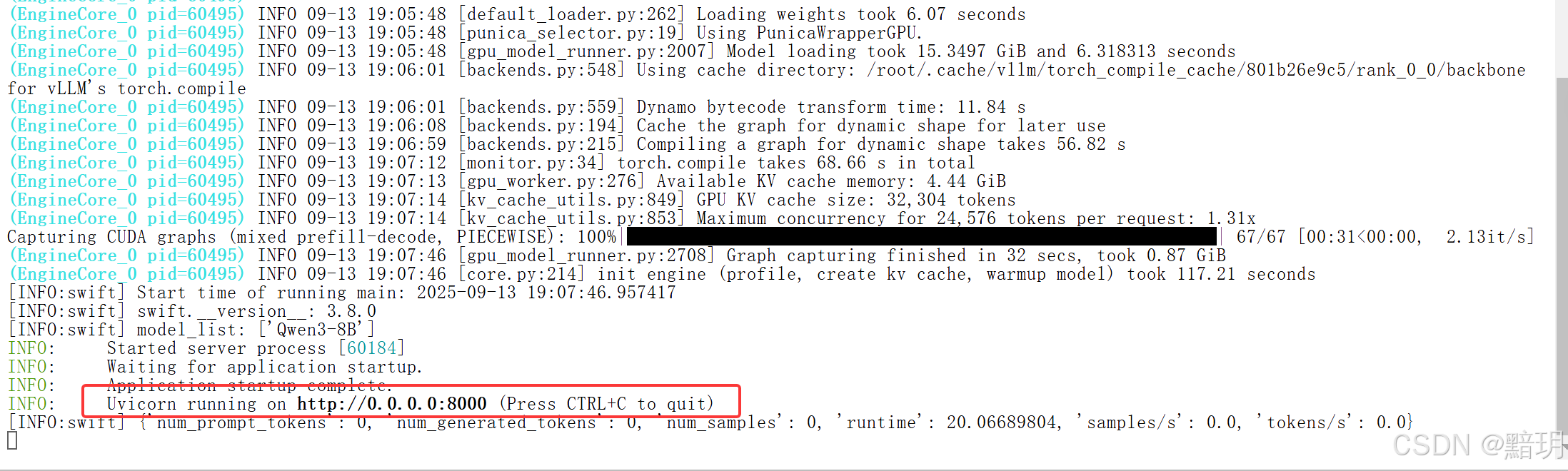
在终端中输入如下命令运行即可。
bash deploy.sh

部署成功后如下图所示。
5.4. 配置代理
5.4.1. 下载代理软件
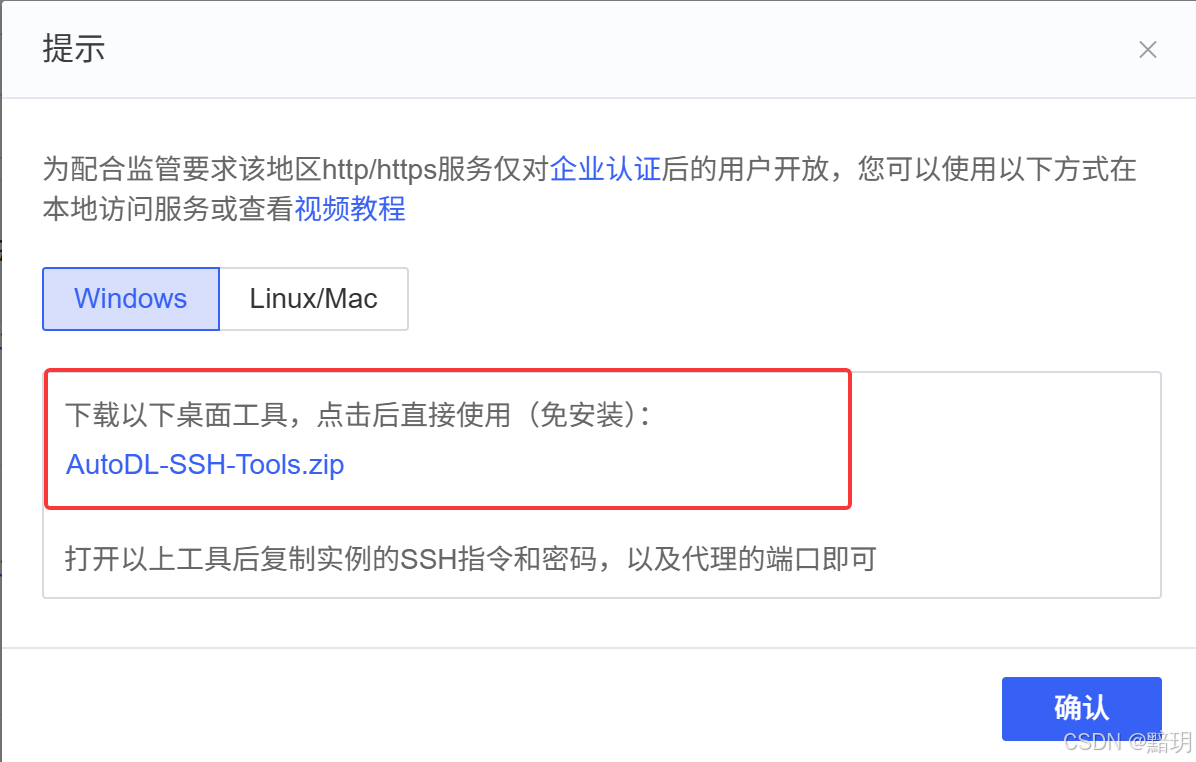
我们不能直接访问AutoDL上的服务,需要设置代理。点击实例上的【自定义服务】按钮,并下载对应的软件。
5.4.2. 配置代理软件
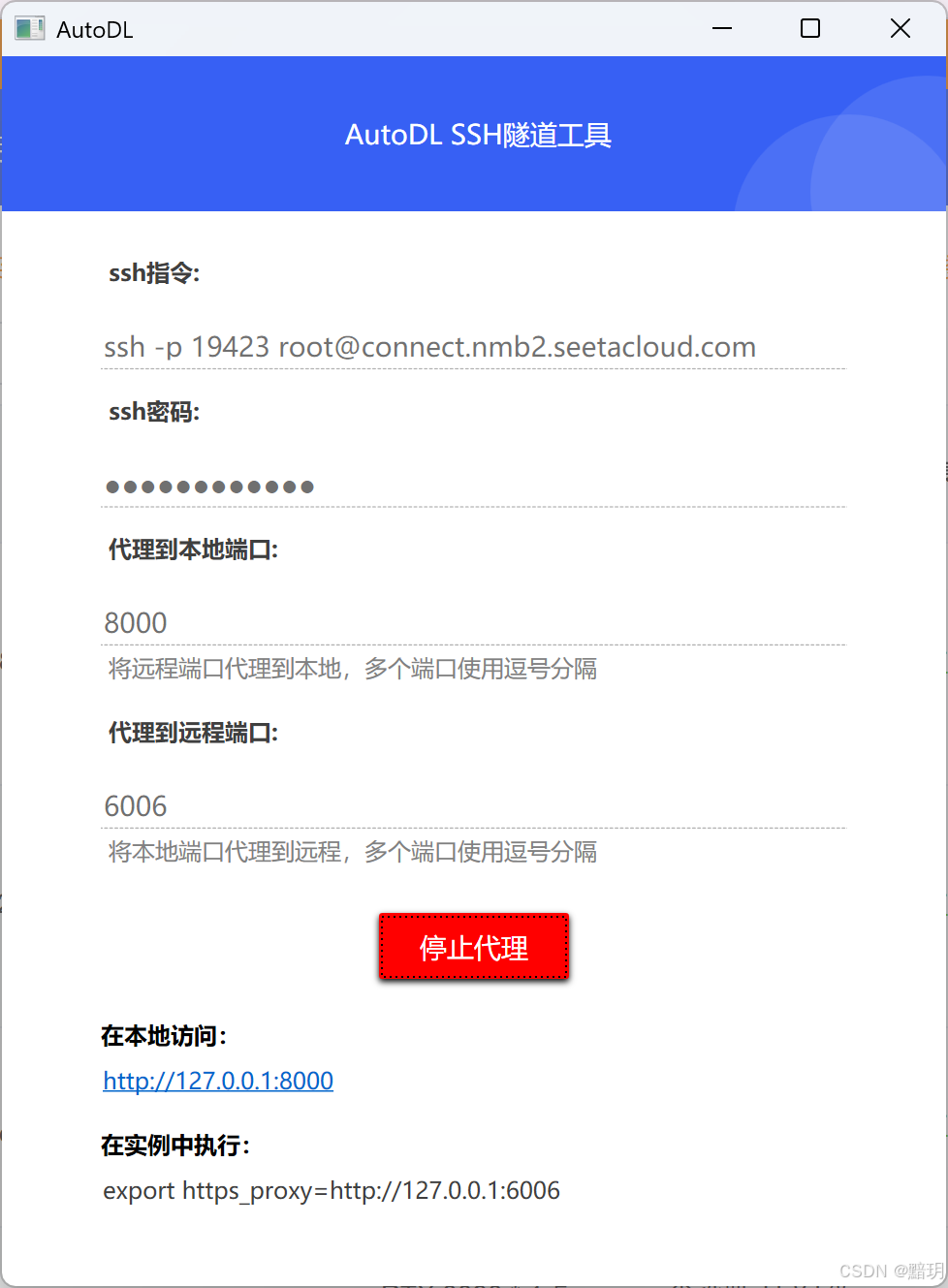
软件运行后如下图所示,其指令和密码见实例上对应指令和密码,复制即可。代理到本地端口根据服务部署成功后显示的端口号设置,本文设置为:8000,代理到远程端口,可随意设置本地未使用的端口,本文设为:6006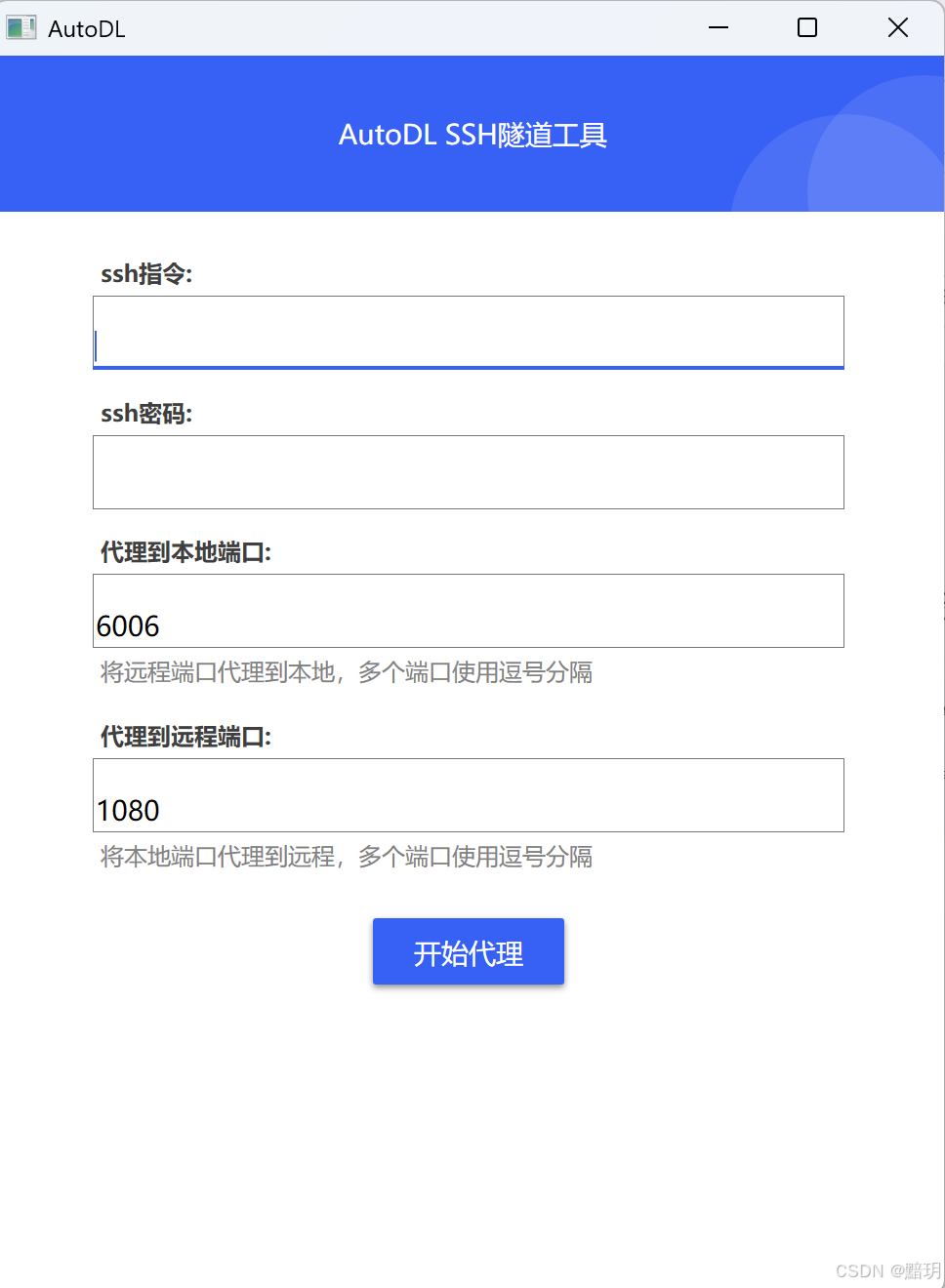

配置完成图如下所示。
5.5. 代码调用服务
本文采用的代码调用服务的方式为Open AI的方式。Python代码如下所示。
from openai import OpenAI
client = OpenAI(
api_key='EMPTY',
base_url=f'http://127.0.0.1:8000/v1',
)
models = [model.id for model in client.models.list().data]
print(f'models: {models}')
query = 'who are you?'
messages = [{'role': 'user', 'content': query}]
resp = client.chat.completions.create(model=models[1], messages=messages, max_tokens=512, temperature=0)
query = messages[0]['content']
response = resp.choices[0].message.content
print(f'query: {query}')
print(f'response: {response}')
gen = client.chat.completions.create(model=models[2], messages=messages, stream=True, temperature=0)
print(f'query: {query}\nresponse: ', end='')
for chunk in gen:
if chunk is None:
continue
print(chunk.choices[0].delta.content, end='', flush=True)
print()
"""
models: ['Qwen3-8B']
query: who are you?
response: I am an artificial intelligence model named swift-robot, developed by swift. I can answer your questions, provide information, and engage in conversation. If you have any inquiries or need assistance, feel free to ask me at any time.
query: who are you?
response: I am an artificial intelligence model named Xiao Huang, developed by ModelScope. I can answer your questions, provide information, and engage in conversation. If you have any inquiries or need assistance, feel free to ask me at any time.
"""

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)