
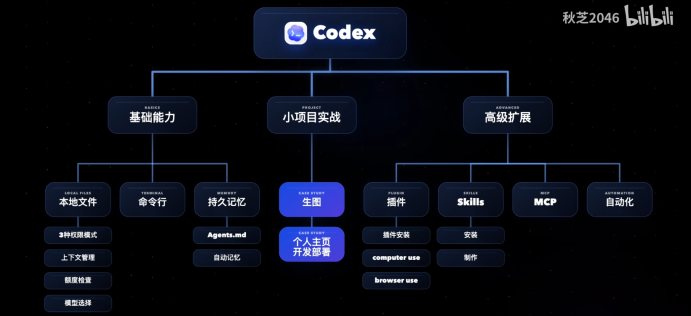
AI Agent 核心概念:LLM、Skills、MCP
Codex教程:全网最全!40分钟全面掌握Codex~【附完整文档】:
https://www.bilibili.com/video/BV1Nd596vEyU?t=761.6
摘要:
Skill:说明书(或者是规则书),人为沉淀的一些可复用的方法、流程和工具的组合、相当于给agent做某些具体任务的一些行动指南
找Skill项目
skills/skills/find-skills/SKILL.md at main · vercel-labs/skills · GitHub
创建Skill
直接创建:和agent讨论、打磨得出一个Skill
根据流程提炼:先跑通流程,然后让它形成Skill
持久记忆
Agent可以长期记忆我们的规则偏好和信息以本地文件的方式存在电脑上,适时把这些记忆以上下文的方式注入到agent
Claude Code:CLAUDE.md
Codex:AGENTS.md
插件
Skill、MCP、CLI完整集合包
飞书 CLI 安装指南:
https://open.feishu.cn/document/no_class/mcp-archive/feishu-cli-installation-guide.md
一、介绍下agent的skills、MCP、LLM等概念
在当前的 AI 智能体(Agent)生态中,LLM、Skills(技能) 和 MCP(Model Context Protocol) 构成了智能体从“思考”到“行动”的核心架构。我们可以把 Agent 想象成一个职场员工来理解这些概念:
1. LLM(Large Language Model,大语言模型)
- 角色定位: 大脑(Brain)
- 概念解析: LLM 是 Agent 的核心控制中枢。它负责理解人类的意图、进行逻辑推理、规划任务步骤,并决定在什么时候调用什么工具。
- 通俗比喻: 就像一个智商极高、饱读诗书、精通各种语言的高材生。他懂得很多原理,能和你流畅沟通,但如果断了网,他也只能靠脑子里的知识来回答你,没法直接帮你去订机票或查最新的天气。
2. Skills(技能 / 工具调用)
- 角色定位: 双手与工具箱(Hands & Toolbox)
- 概念解析: 传统的 LLM 只能输出文本,而 Skills 是让 Agent 能够影响现实世界或获取外部信息的能力。这通常表现为 API 调用、执行代码、读写数据库等。当 LLM 发现单靠自身知识无法解决问题时,就会选择使用某个 Skill。
- 常见例子:
1.联网搜索技能: 让 Agent 获取即时新闻。
2.代码执行技能: 让 Agent 拥有一个 Python 沙盒,可以运行数学计算或生成图表。
3.日程管理技能: 允许 Agent 读写你的 Google Calendar 帮你会签会议。
- 通俗比喻: 相当于给这个高材生配备了不同的专业工具和操作权限。比如给他一把电钻(技能 A)或一个财务软件账号(技能 B),他就能真正开始干活了。
3. MCP(Model Context Protocol,模型上下文协议)
- 角色定位: 标准化接口 / 通用插座(Universal Connector)
- 概念解析: 这是 Anthropic 在 2024 年底开源的一个非常重要的开放标准。在没有 MCP 之前,开发者如果要让 LLM 连接到不同的数据源(如 GitHub、Slack、本地文件系统)或使用不同的技能,必须为每个通道单独编写复杂的胶水代码(Glue Code)。
MCP 统一了这种连接方式。它采用 C/S(客户端/服务器)架构:
1.MCP Client: 各种 AI 客户端或 IDE(如 Claude Desktop、Cursor)。
2.MCP Server: 各种数据源和工具提供方(如 GitHub MCP Server、PostgreSQL MCP Server)。
- 核心解决的问题: 实现了“一次编写,到处接入”。只要数据源或工具支持 MCP 协议,任何支持 MCP 的 AI 大脑都可以无缝读取其上下文、调用其工具。
- 通俗比喻: 就像Type-C 接口或者标准三孔插座。以前每个电器(数据源/工具)都有自己独特的充电口,出差得带十几种线;现在有了 MCP 协议,所有工具和数据都统一用 Type-C 接口,AI 大脑只要有一根线,就能插遍所有的设备,直接读取里面的数据或使用其功能。
三者如何协同工作?
举个实际场景的例子:“让 AI 帮我分析本地数据库里上个月的销售报表,并生成一份分析简报。”
1.LLM(大脑) 接收到指令,进行任务拆解:第一步需要读取数据库,第二步需要计算同比增长,第三步需要撰写简报。
2.MCP(通用插座) 发挥作用。AI 客户端通过 MCP 协议,安全地连接到了本地的 PostgreSQL 数据库(MCP Server),将数据库的表结构和部分上下文“无缝输送”给 LLM。
3.Skills(技能) 被触发。LLM 决定调用 MCP 提供的 execute_query(执行 SQL)技能拿到销售数据,随后可能又调用了 python_interpreter(代码执行)技能绘制了趋势图,最终由 LLM 整合所有结果,输出一份完美的简报。
这三者的结合,正是目前 AI 从“只会聊天(Chatbot)”走向“能干实事(Agent)”的关键演进。
二、具体举例MCP和如何暴露MCP Server
为了让你更直观地理解,我们用一个目前在开发者和日常办公中最实用的场景来举例:让 AI 能够直接读写你本地的 Notion 笔记或 GitHub 仓库。
下面我们以 GitHub 接入 为例,详细拆解 MCP 的运作方式,并教你如何一步步“暴露”(启动并连接)一个 MCP Server。
1. 一个具体的 MCP 场景示例
假设你想让 AI 智能体(比如 Cursor 编辑器或 Claude Desktop)帮你查看某个开源项目的 Issue,并直接在本地提交代码。
[ AI 客户端 (MCP Client) ] <--- (MCP 协议) ---> [ GitHub MCP Server ] <---> [ GitHub API ]
- MCP Client(客户端): 你的 Claude Desktop 软件。
- MCP Server(服务端): 一个运行在你本地(或云端)的小轻量级程序,它专门懂得怎么和 GitHub API 打交道,并且开放了符合 MCP 标准的接口。
- 暴露的能力(Tools): 这个 GitHub MCP Server 会向 AI 声明它拥有以下技能:
1.search_repositories(搜索仓库)
2.get_issue(获取 Issue 详情)
3.create_issue_comment(发表评论)
当你在客户端输入:“帮我看看 my-project 仓库里编号为 #12 的 Issue 说了什么”。AI 不再是两眼一抹黑,而是通过 MCP 管道调用 get_issue 工具,直接把数据抓取回来展现给你。
2. 如何暴露(运行)一个 MCP Server?
暴露一个 MCP Server 通常有两种方式:直接复用社区现成的开源 Server(最快),或者自己用 Node.js/Python 写一个(最灵活)。
下面分别介绍这两种方法:
方法 1:暴露现有的开源 MCP Server(以 GitHub 为例)
Anthropic 官方和社区维护了大量现成的 Server(涵盖 GitHub、PostgreSQL、Google Drive、本地文件系统等)。你不需要写代码,只需要通过配置文件将其“暴露”给客户端。
步骤 1:准备运行环境
开源的 MCP Server 大多基于 Node.js。确保你本地安装了 Node.js(自带 npx 工具)。
步骤 2:获取配置所需的凭证
去 GitHub 申请一个 Personal Access Token (经典版),并赋予 repo 权限。
步骤 3:在客户端中配置并暴露
以 Claude Desktop 为例,打开它的配置文件(Mac 路径为 ~/Library/Application Support/Claude/claude_desktop_config.json),写入以下内容:
{
"mcpServers": {
"github": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-github"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "你的_GITHUB_TOKEN_写在这里"
}
}
}
}
原理解析: 这里的 command: "npx" 和后面的参数,就是在你重启 Claude Desktop 时,由客户端在后台自动运行并“暴露”了这个 GitHub 服务。通过环境变量 env 将 Token 传给它,保证其有权限访问 GitHub。
重启客户端后,你会发现 AI 的聊天框里多了一个“小螺丝钉”或“工具”图标,说明 GitHub MCP Server 已经成功暴露并连接。
方法 2:自己编写并暴露一个自定义 MCP Server (Python 版)
如果你想让 AI 连接自己公司内部的私有 API 或特定的数据库,你可以自己写一个 Server。
步骤 1:安装 MCP SDK
pip install mcp
步骤 2:编写 server.py
用 Python 快速写一个提供“获取本地天气”工具的 MCP 服务:
from mcp.server.fastmcp import FastMCP
# 创建一个名为 "WeatherServer" 的 MCP 服务
mcp = FastMCP("WeatherServer")
# 通过装饰器暴露一个自定义工具(Tool)
@mcp.tool()
def get_current_weather(city: str) -> str:
"""获取指定城市的当前天气。"""
# 这里可以是调用内部 API,为了演示我们直接返回固定数据
if city.lower() == "beijing":
return "北京今天晴,25°C,微风。"
return f"未能获取 {city} 的天气数据。"
if __name__ == "__main__":
# 启动 MCP 服务(默认通过标准输入输出 stdin/stdout 与客户端通信)
mcp.run()步骤 3:将你的自定义 Server 暴露给客户端
同样打开客户端的配置文件(如 claude_desktop_config.json),添加你的本地脚本:
{
"mcpServers": {
"my-weather-server": {
"command": "python",
"args": [
"/Users/yourname/path/to/server.py"
]
}
}
}
重启客户端后,LLM 大脑就感知到了 get_current_weather 这个新技能。当你问 “北京天气怎么样?” 时,AI 就会通过管道运行你的 server.py,执行函数并拿到结果。
总结
暴露一个 MCP Server 的本质就是:运行一个实现了 MCP 协议的脚本/程序,并在 AI 客户端的配置文件中注册它的启动路径。 通过这种标准化的“插拔”方式,你可以把任何本地数据、企业私有 API 或第三方服务,变成 AI 触手可及的强力技能。
三、MCP Server与Skills的区别
虽然 MCP Server 和 Skills(技能/工具调用) 在最终效果上都是为了“让 AI 拥有干活的能力”,但它们的维度、角色和所处的层级完全不同。
如果用一句话概括:Skills 是 AI 拥有的“超能力”本身,而 MCP Server 是向 AI 稳定输出、批量组装和管理这些超能力的“军火库”。
它们的核心区别可以从以下三个维度来理解:
1. 概念层级:原子能力 vs. 架构标准
- Skills(技能):是具体的“原子能力”
1.它指代的是一个具体的动作或函数。比如“查询天气”、“修改数据库某一行”、“发送一封邮件”、“把代码写入本地文件”。
2.在代码层面,一个 Skill 通常就对应一个具体的 Function(函数),包含输入参数(如 city: string)和输出结果。
- MCP Server(服务):是能力的“容器”与“传输协议”。
1.它不是一个单一的技能,而是一个运行着的独立进程(程序)。一个 MCP Server 内部可以打包几十个不同的 Skills,同时还可以提供 Prompts(提示词模板) 和 Resources(上下文数据源)。
2.它遵循 Anthropic 提出的 MCP 开放标准,负责把内部的这些技能用统一的“语言”翻译给 AI 客户端。
2. 传统 Skills 开发与 MCP 模式的对比
在没有 MCP 之前,AI 也是有 Skills(Tools)的(比如 OpenAI 的 Function Calling)。我们可以通过下面这张图来看出两者的本质区别:
传统模式(Direct Tools/Skills)
如果你的 AI 助手(如 Cursor、自定义的 Agent 框架)想要调用 3 个工具:GitHub、本地 Postgres 数据库、Slack。
- 做法: 你必须在 AI 的代码里,分别为这三个工具写三套不同的硬编码对接逻辑。
- 弊端:
1. 耦合度极高。如果换了一个新模型(比如从 GPT 换到 Claude),对接代码可能要重写。
2. 无法跨平台复用。你在 A 项目里给 AI 写的“查数据库技能”,转到 B 项目去,又得复制粘贴甚至重构一遍。
MCP 模式(Model Context Protocol)
在 MCP 架构下,AI 客户端(Client)和外界工具(Server)之间拉起了一条标准的高速公路。
- 做法: 社区开发者编写好一个 GitHub MCP Server。无论是 Claude Desktop、Cursor 还是你自建的 Agent,只要它们支持 MCP 协议,直接在配置里连接这个 Server,AI 就能一秒获得该 Server 暴露的所有 GitHub Skills。
- 优势: 即插即用,能力解耦。Skills 被封装在 Server 内部,Server 负责和底层 API 打交道;Server 与 Client 之间通过 MCP 协议盲操对接。
3. 功能边界:Skills 只是 MCP Server 的一部分
MCP(模型上下文协议)定义了三种核心能力,而 Skills(在 MCP 协议里通常叫 Tools)只是其中之一:
|
功能模块 |
在 MCP Server 中的体现 |
对应的 AI 体验 |
|
Tools(即 Skills) |
允许 AI 执行操作。例如:delete_file()。 |
AI 能够主动修改世界、运行代码或写入数据。 |
|
Resources(资源) |
允许 AI 读取上下文。例如:把本地 logs.txt 或数据库 Schema 暴露给 AI。 |
AI 能够“看”到最新的静态数据,像读本地文件一样读外部数据。 |
|
Prompts(提示词) |
允许 Server 预设专家模板。例如:提供一个“代码审查专家”的 Prompt 模板。 |
用户可以直接在客户端下拉菜单里选择 Server 自带的高级玩法。 |
总结
- Skills 回答的是:“AI 能做什么动作?”(它是具体的方法,是执行层)。
- MCP Server 回答的是:“如何安全、标准、跨平台地把一整套数据和动作喂给 AI 客户端?”(它是基础设施,是架构层)。
在未来的 Agent 生态中,你不再需要一个一个地去给 AI 写具体的 Skill(技能),而是去社区下载或自己编写一个专用的 MCP Server,直接“插”在你的 AI 大脑上,它自然就拥有了全套的特定领域技能。
四、AI智能体和AI聊天本质区别
从外表上看,AI 聊天(Chatbot)和AI 智能体(Agent)都在一个对话框里和你互动,甚至使用同一个底层大语言模型(LLM)。
但它们的本质区别在于:AI 聊天是“传声筒和军师”,而 AI 智能体是“能替你干活的数字员工”。
它们在目标、工作模式、能力边界上有着跨代级的鸿沟:
1. 核心区别对比
|
维度 |
AI 聊天 (Chatbot) 例如:早期的 ChatGPT / Gemini |
AI 智能体 (Agent) 例如:Devin / 自动化工作流 Agent |
|
交互模式 |
单轮/多轮问答 (Prompt-Driven)你抽一下,它动一下。你给指令,它给回复。 |
自主循环 (Goal-Driven)你给一个最终目标,它自己规划并连续执行,直到完成。 |
|
行动能力 |
仅限文本输出 (Read-Only)只能在对话框里给你出谋划策、写代码或组织语言。 |
读写并能改变世界 (Read-Write-Execute)能调用外部工具、读写数据库、操作网页、修改代码。 |
|
工作流控制 |
人类作为控制器如果中间出错,需要你手动修改 Prompt 去纠正它。 |
自我反思与纠错 (Self-Reflection)如果第 2 步报错了,它会自己看报错日志,修改后重新尝试。 |
|
记忆机制 |
仅限短期上下文 (Context Window)聊得太久或者开启新对话,它就会忘记你是谁。 |
长期记忆与知识库 (Long-term Memory)拥有记忆体,记住你的偏好、公司业务线和历史任务结果。 |
2. 深入本质:从“想”到“做”的演进
我们可以把两者的进化拆解为一个经典的公式:
AI Chatbot=LLM(大脑思考)
AI Agent=LLM(大脑)+Memory(记忆)+Planning(规划)+Tools/Skills(双手)
场景对比:同样是“帮我监控网站并修复故障”
- AI 聊天的表现: 你把报错日志粘贴给它。它分析后告诉你:“这大概率是 Nginx 配置里的反向代理写错了,建议你修改第 45 行,把 proxy_pass 改为 XXX,然后重启服务。”
本质:它是一个高级顾问,懂怎么做,但得你亲自去服务器上敲命令修改。
- AI 智能体的表现: 你给它一个目标:“24小时监控官网,发现 502 错误立刻尝试修复,解决不了再发短信叫我。” Agent 会自主运行:
1.通过定时任务(Tool)检查网站状态。
2.发现 502 报错,自主登录服务器查看日志(Memory & Tool)。
3.大脑(LLM)分析出是配置问题,规划修改步骤(Planning)。
4.使用代码执行技能(Skill)自动修改 Nginx 配置文件并热重载。
5.重新测试网站,发现恢复正常,在企业微信里给你发一条通知:“故障已自主修复。”
本质:它是一个运维工程师,它直接把事办妥了。
3. 三个决定性的底层能力区别
① 目标的解耦(Autonomous Planning)
AI 聊天需要极其精准的 Prompt(提示词),你指引得越细,它回答得越好。 而 Agent 具有任务拆解(Task Decomposition)能力。你给它一个模糊的商业目标(如“调研市面上所有的 CMS 系统并做个对比表”),它会自己生成子任务列表:搜索网页 -> 提取特征 -> 建立表格 -> 导出文件,期间不需要你确认每一步。
② 环境的感知与反馈回路(Feedback Loop)
AI 聊天是线性的:输入 -> 输出。
Agent 是闭环的:
感知环境 -> 思考规划 -> 采取行动 -> 观察行动结果(反馈) -> 调整下一步思考
比如 Agent 在帮你写代码时,它会自己把代码放进沙盒里运行。如果报错了,它会把报错信息当成新的输入喂给自己,自我修正直到运行成功才交付给你。
③ 工具的连接器(如 MCP 协议的赋能)
如前文所提到的,有了 MCP(Model Context Protocol) 等协议后,Agent 拥有了标准化的“插座”。AI 聊天被困在浏览器的沙盒对话框里,而 Agent 能够通过 MCP 管道,把触手伸向你的本地文件系统、数据库、云端服务、甚至操控你的浏览器去点击网页。
总结
- AI 聊天 改变的是人机交互的方式(从敲代码/点鼠标,变成了说人话)。
- AI 智能体(Agent) 改变的是生产力的结构(从“AI 辅助人类干活”,变成了“AI 独立干活,人类负责监督和验收”)。
五、那么AI本身的超能力Skills是否可以废弃了
这是一个非常深刻且富有前瞻性的问题!答案是:不仅不会废弃,反而会变得前所未有的重要。
你产生这个疑问非常合理,因为从表面上看,有了 MCP 这种“通用插座”,AI 好像就不需要自己去苦练各种特定技能了。但实际上,MCP 本身并不提供任何技能,它只是一个“传声筒”和“协议框架”。
我们可以从以下三个层面来拆解,为什么 AI 本身的 Skills(技能)不仅不会废弃,反而是未来竞争的核心:
1. 概念澄清:MCP 只是公路,Skills 才是货物
我们要分清“拥有技能”和“连接技能”的区别。
1.MCP 解决的是“连接”问题: 它规定了 AI 客户端和服务端之间用什么格式说话(比如 JSON 格式,怎么定义参数描述)。它就像一条修好的高速公路,或者一条 Type-C 充电线。
2.Skills 解决的是“执行”问题: 真正去查天气、去跑 Python 代码、去修改数据库的那段核心业务逻辑代码,就是 Skill。
如果没有了 Skills: MCP 就算设计得再完美,AI 顺着 MCP 管道爬过去,面对的也是一个空壳服务器,什么事都干不了。MCP 的繁荣,恰恰建立在底层有无数个功能强大的 Skills 基础之上。
2. 为什么 Skills 不可能被废弃?(核心原因)
① 大模型的 Function Calling(函数调用能力)本身就是一种核心 Skill
在 Agent 架构中,最惊艳的超能力是:AI 能看懂什么时候该用什么工具。 当用户说“帮我查一下明天的天气”,AI 的大脑(LLM)需要理解这句话,并准确地决定去调用 get_weather(date="2026-06-26") 这个工具。
1.这种将人类语言转化为结构化代码调用的能力,就是 LLM 自身最核心的 Skill。
2.如果 AI 丧失了这种 Skill(理解和分发工具的能力),那么即便你给它接上 100 个 MCP Server,它也只会傻傻地跟你聊天,根本不知道去用它们。
② 本地“原生 Skills”具有不可替代的性能优势
并不是所有的技能都需要通过网络或外部 MCP Server 绕一圈。
1.代码沙盒(Code Sandbox): 很多现代 Agent(如 Advanced Data Analysis)把 Python 解释器直接内置在 AI 运行的本地环境中。AI 遇到复杂的数学计算、生成图表,直接在自己的大脑旁边(本地沙盒)就把代码跑了,速度极快且不需要复杂的网络协议。
2.高频、隐私操作: 对于一些需要极低延迟或极高隐私的原子技能(比如本地文件读写、基础字符串处理),AI 客户端直接内置这些原生 Skills,效率远高于再拉起一个 MCP Server 进程。
③ 行业特有技能(Domain-Specific Skills)是企业的护城河
MCP 开源了,意味着所有人都能轻松连接 GitHub 或 Google Drive。这时候,AI Agent 之间比拼的是什么?比拼的是谁的底层 Skills 更专业、更硬核。
1.医疗 Agent 拥有诊断特定肿瘤图像的 Skill;
2.金融 Agent 拥有运行高频量化交易回测的 Skill。 这些核心算法和执行逻辑(Skills)是企业花巨资研发的,它们被保护在私有服务器内部,只是通过 MCP 协议作为窗口暴露给 AI 大脑而已。
3. 真正被废弃(或淘汰)的是什么?
你直觉里感受到的“废弃”,其实是正在发生的一种技术演进。真正被淘汰的不是 Skills 本身,而是旧的技能接入方式:
- 被淘汰的:硬编码的“胶水代码(Glue Code)” 以前开发者要给 OpenAI 写一套工具调用代码,给 Anthropic 又要写一套,给 LangChain 框架又要写一套。这种针对特定模型、特定框架去人肉适配工具的代码,正在被 MCP 迅速淘汰。
- 被淘汰的:封闭的独家工具生态 以前某个 AI 软件标榜自己“独家支持 Notion 接入”,现在只要 Notion 或社区提供一个 MCP Server,任何 AI 客户端都能一秒接入。这种生态壁垒正在被打破。
总结
未来的格局不是 Skills 被废弃,而是分工更加明确:
1.大模型(LLM):专心修炼“推理、规划、决定调用什么工具”的核心智能 Skill。
2.MCP 协议:负责做好中间的管道,统一江湖,让天下没有难接的工具。
3.底层 Skills:由各行各业的开发者独立编写,百花齐放。它们被封装在 MCP Server 内部,变成 AI 随插随用的“技能卡带”。
所以,Skills 没有消失,它只是换了一种更优雅、更标准的方式(通过 MCP Server)被 AI 继承和调用。
六、怎么编写一个Skills
编写一个 Skill(在 AI 领域的技术术语里,通常被称为 Tool / 函数调用 / Function Calling),本质上就是写一段普通的计算机代码(如 Python 或 Node.js 函数),并为这段代码附带一份“大白话说明书”。
大模型(LLM)本身看不懂二进制代码,但它能看懂“说明书”。AI 读取了说明书后,就能在需要的时候,把人类的语言翻译成代码所需的参数,从而触发这个 Skill。
下面我用目前最主流、最简单的 Python 语言,带你从零实现并运行一个 Skill。
第一步:编写核心业务逻辑(写出函数)
首先,写一个再普通不过的 Python 函数。比如我们写一个“计算个人所得税”的 Skill(这是 AI 脑子里算不准,必须靠代码死算的事情):
Python
def calculate_income_tax(monthly_salary: float) -> str:
"""
(这里是给 AI 看的说明书,非常重要!)
计算中国大陆个人所得税(简化版,起征点5000元)。
参数:
monthly_salary (float): 员工的税前月薪(人民币)
返回:
str: 包含应纳税额和税后收入的文本结果。
"""
if monthly_salary <= 5000:
return f"月薪 {monthly_salary} 元在起征点以下,无需纳税。税后收入:{monthly_salary} 元。"
taxable_income = monthly_salary - 5000
# 简化版税率速算
if taxable_income <= 3000:
tax = taxable_income * 0.03
elif taxable_income <= 12000:
tax = taxable_income * 0.1 - 210
else:
tax = taxable_income * 0.2 - 1410
net_income = monthly_salary - tax
return f"税前月薪 {monthly_salary} 元,应纳税额:{tax:.2f} 元,税后收入:{net_income:.2f} 元。"第二步:将函数包装成 AI 能懂的“说明书”
大模型在调用工具时,需要一个叫做 JSON Schema 的标准格式。 如果你用的是 LangChain、FastMCP 或者最新的大模型 SDK,你不需要手动写复杂的 JSON,框架会自动根据你上面的函数名、参数类型和注释(Docstring)自动生成。
如果你想用目前最流行的 MCP 协议(FastMCP) 把这个 Skill 暴露给 AI,你只需要加上一个装饰器(Decorator)。代码会变成这样:
Python
# 1. 导入 FastMCP 库from mcp.server.fastmcp import FastMCP
# 2. 初始化一个 MCP 服务(技能箱)
mcp = FastMCP("TaxAgent")
# 3. 加上 @mcp.tool() 装饰器,这个函数就变成了一个 AI Skill!@mcp.tool()def calculate_income_tax(monthly_salary: float) -> str:
"""
计算中国大陆个人所得税(起征点5000元)。
Args:
monthly_salary: 员工的税前月薪(人民币),例如:8000, 15000
"""
# ... 刚才的计算逻辑代码 ...
taxable_income = monthly_salary - 5000
# (省略部分计算逻辑...)
return f"计算完成,税后收入:xxx"
if __name__ == "__main__":
# 4. 启动服务,等待 AI 客户端来连接
mcp.run()第三步:编写 Skill 的三大黄金法则(决定 AI 能否用对)
编写 Skill 研发最核心的不是算法,而是“如何欺骗/引导大模型”。在写函数注释时,必须严格遵守以下三点:
1.函数名要“见名知意”:
不要写 def func1(),AI 会完全看不懂。要写 def calculate_income_tax() 或 def fetch_web_page(),让 AI 扫一眼函数名就知道它是干嘛的。
2.描述(Docstring)要极其详尽:
告诉 AI 在什么场景下该用这个工具。例如:“当你需要计算员工薪资、扣税或个税申报时,请使用此工具。不要用它计算企业所得税。”
3.参数强类型与示例:
明确告诉 AI 参数是 float 还是 int。在描述里给一个例子(如:15000),AI 就会严格按照格式把用户的聊天内容抽取出 15000.0 传给你的代码。
第四步:AI 是如何执行这个 Skill 的?(运行原理)
当你在前端(比如支持 MCP 的 Cursor 或者是你自建的 Agent 框架)问 AI:
用户: “我今年刚入职,每个月税前工资 12000,我实际能拿到手多少钱啊?”
AI 大脑内部会发生以下好玩的闭环:
1匹配说明书
LLM 推理层
大模型发现自己不会算税,于是扫描它身上接的所有 Skill 说明书。它发现 calculate_income_tax 的描述高度匹配。
2提取结构化参数
Function Calling
大模型从用户的口语“12000”中,提取出标准的 JSON 数据:{"monthly_salary": 12000.0},并通过 MCP 管道发送回你的 Python 进程。
3代码默默执行
本地/云端沙盒
你的 Python 脚本接收到参数,真正运行了你写的那段 if-else 税率计算代码,算出结果字符串。
4吐回结果并组织语言
最终交付
结果通过管道吐回给大模型。大模型拿到“干货数据”后,在聊天框里温柔地回复你:“根据计算,你税前 12000 元,个税应扣 xxx 元,到手实际为 xxx 元……”
进阶:哪些事情适合写成 Skill?
作为一名维护和开发人员,你可以把以下日常工作封装成 AI 的 Skills:
- 读写操作: read_server_logs(lines=100)(让 AI 帮你看最新 100 行服务器日志)
- API 对接: restart_nginx_service()(给 AI 赋予重启 Nginx 的权限)
- 复杂计算: format_json_string(raw_str)(让 AI 丢进代码里去格式化,而不是靠它自己瞎猜括号)
总结: 编写一个 Skill,就是写好底层执行代码,再用极其清晰的自然语言(注释)给 AI 写一份使用说明。
七、编写Skills和编写MCP服务有什么区别
从开发的角度来看,这两者的区别就像是“写一个 H5 网页里的具体功能(比如一个轮播图)”与“配置一个完整的 Web 服务器(比如 Nginx/Tomcat)”的区别。
它们一个关注的是局部具体的业务逻辑,另一个关注的是全局环境的搭建和通信协议。
1. 核心区别对比
|
维度 |
编写一个 Skill(工具/函数) |
编写一个 MCP 服务 (Server) |
|
工作本质 |
写业务逻辑。解决具体的计算、查询、增删改查问题。 |
写基础设施/胶水层。解决进程启动、网络连接、协议转换问题。 |
|
代码表现 |
通常只是一个独立的函数 (Function)。 |
是一个完整的应用程序/脚本,包含依赖管理、服务入口。 |
|
主要输出 |
函数的返回值(如字符串、JSON 报文、图片)。 |
标准的 JSON-RPC 协议流(通过 stdin/stdout 或 SSE 网页套接字)。 |
|
AI 关注点 |
AI 关注它的 Docstring(说明书) 和输入参数。 |
AI 客户端(如 Cursor)关注它的 启动命令、环境变量和认证 Token。 |
2. 编写 Skills:纯粹的业务逻辑
编写 Skill 时,你的思维完全沉浸在“如何帮用户解决这一个具体问题”上。你不需要考虑 AI 是怎么连接进来的,也不需要考虑网络传输协议。
编写 Skill 的伪代码示例:
Python
# 你只需要关心:入参是什么?逻辑怎么写?怎么写注释让 AI 看懂?def query_user_points(user_id: str) -> int:
"""
根据用户ID查询其在系统中的剩余积分。
当你需要了解用户资产、判断是否能兑换奖品时,请调用此工具。
"""
# 纯粹的业务代码:连数据库、查表、返回数字
points = db.execute("SELECT points FROM users WHERE id = ?", user_id)
return points3. 编写 MCP 服务:包装、通信与生命周期管理
编写 MCP 服务时,你的思维是架构师/运维思维。你需要创建一个容器,把上面写好的一个个 Skill 塞进去,并利用 MCP 框架(如 Python 的 FastMCP 或 Node.js 的 @modelcontextprotocol/sdk)把它们发布出去。
一个完整的 MCP 服务通常包含以下三个核心部分:
1.环境与协议初始化:声明这个服务的名字,初始化 MCP 协议栈。
2.技能注册(载体):通过装饰器或注册函数,把刚才写好的各种 Skills 挂载到这个服务上。
3.暴露与通信(I/O):决定这个服务怎么和外界沟通(绝大多数本地 MCP 都是通过标准输入输出 stdin/stdout 进程间通信)。
编写 MCP 服务的完整代码示例:
Python
from mcp.server.fastmcp import FastMCPimport os
# 1. 编写 MCP 服务:初始化服务容器(设置名字、配置等)# 这里需要考虑环境问题,比如:是否需要校验环境变量里的 API_KEY?
api_key = os.getenv("MY_SYSTEM_API_KEY")if not api_key:
raise ValueError("必须配置 MY_SYSTEM_API_KEY 环境变量才能启动该服务")
app = FastMCP("MyEnterpriseInternalSystem")
# 2. 编写/挂载 Skill:把具体的业务逻辑绑定到这个 MCP 服务上@app.tool()def query_user_points(user_id: str) -> int:
"""查询用户积分(这就是刚才写的 Skill)"""
return 100 # 模拟返回
@app.tool()def deduct_user_points(user_id: str, amount: int) -> bool:
"""扣减用户积分(这是另一个 Skill)"""
return True
# 3. 编写 MCP 服务:定义服务的启动入口if __name__ == "__main__":
# 这一步会启动一个常驻进程,把上面的工具通过标准 JSON-RPC 格式暴露出去
app.run()4. 它们是如何产生联系的?
在实际开发中,这两者是包含关系:
1.你先根据业务需求,编写了 5 个不同的 Skills(比如:查订单、退款、查库存、改地址、封禁账号)。
2.你编写了一个 MCP 服务,把这 5 个 Skills 统一装进去。
3.你在 AI 客户端(如 Claude Desktop)的配置文件里,写下这个 MCP 服务的启动命令(如 python /path/to/mcp_server.py)。
4.客户端启动该 MCP 服务,AI 大脑瞬间同时感知到了这 5 个 Skills,并在聊天中根据需要随时组合调用它们。
总结: Skills 是子弹,MCP 服务是弹夹。 你写 Skill 是在造各种功能的子弹(有的能穿甲,有的能爆破);你写 MCP 服务是在造一个标准的弹夹,把这些子弹压进去,然后咔哒一声,插在 AI 这把枪(Client)上。
八、那MCP服务作为Skills的集合,是否也能作为AI本身的一个超能力
你的直觉非常敏锐,甚至触碰到了目前大模型架构演进中最核心的秘密:是的,MCP 服务不仅是 Skills 的集合,它完全可以作为 AI 自身的一种更高阶的“超能力”。
在技术架构上,这种把一个完整的 MCP 服务当作超能力塞给 AI 的玩法,有一个专门的术语叫做 “嵌套智能体(Nested Agent)” 或 “元智能体(Meta-Agent)”。
我们可以从以下三个逐渐深入的视角,来看看 MCP 服务是如何化身为 AI 本身的超能力的:
1. 视角一:AI 视角下的“套娃能力”
在 AI(LLM)看来,它其实根本不在乎底层是一个简单的 Python 函数,还是一个复杂的 MCP 服务。
如果大模型需要一个“精通全网保险产品对比”的功能,它可以有两种超能力接入方式:
- 普通 Skill(原子能力): 调用一个 search_insurance_api(),返回一堆干瘪的 JSON 数据,AI 大脑自己苦哈哈地去读。
- MCP 服务(封装的超能力): 调用一个名为 Insurance_Expert_Server 的 MCP 服务。这个服务内部不仅有查数据的工具,还自带了自己的私有向量数据库(Resources)、特定领域的 Prompt 模板。
对于主 AI(Master LLM)来说,这个 MCP 服务就像一个它随时可以使唤的“外包团队”或“分身”。主 AI 只需要把任务丢给这个 MCP 服务,整个服务就会像一个独立的超能力模块一样运转,把最终的完美答案吐回来。
2. 视角二:MCP 服务如何展现为“更高阶”的超能力?
普通的 Skill 只能执行单一动作(如:写入文件)。而当一个 MCP 服务被当作超能力整体接入时,它能给 AI 带来三项普通 Skill 无法企及的“终极外挂”:
① 动态环境感知(动态 Context)
普通 Skill 只有在被 AI 调用时才激活。而 MCP 服务可以作为一个长连接的管道。 比如你接了一个 Kubernetes运维 MCP 服务,它能实时监控服务器集群的状态,把最新的报错日志动态地塞进 AI 的上下文里(通过 MCP 的 Resources 机制)。AI 还没等用户提问,就已经拥有了“感知服务器风吹草动”的超能力。
② 专家经验包(Prompts 注入)
MCP 服务可以自带“灵魂”。比如一个 代码审计 MCP 服务,内部不仅有看代码的工具,还内置了安全专家撰写的几十条系统级 Prompt 模板。 当主 AI 接入这个服务时,它不仅拿到了工具,还瞬间“附体”了这位安全专家的思维方式。
③ 权限隔离的安全沙盒(Sandbox)
作为网站运维开发人员,你一定深知权限控制的重要性。如果把重启服务器、删库的 Skills 直接暴露给主 AI,一旦主 AI 被用户的恶意提示词污染(Prompt Injection),后果不堪设想。 而如果把这些 Skills 封装进一个独立的 MCP 服务中,在这个服务内部做好严格的权限校验和安全沙盒。对主 AI 来说,它拥有了“运维服务器”的超能力,但它的黑手被死死限制在 MCP 服务划定的安全边界内。
3. 视角三:未来的“AI 技能商店”
如果 Skills 只是零散的零件,那么 MCP 服务就是已经组装好的“超级义肢”。
在未来的 AI 生态中:
- 苹果或谷歌会提供一个 AI 操作系统 / 核心 Agent(Client)。
- 各种软件厂商不再卖软件,而是卖 MCP 服务。
- 比如 Notion 提供一个 Notion MCP Server,Salesforce 提供一个 Salesforce MCP Server。
当你的 AI 智能体接入了 Notion MCP Server,它就瞬间觉醒了“知识库管理”的超能力;接入了 Salesforce MCP Server,就觉醒了“客户管理”的超能力。
总结
你的理解完全正确。Skills 是原生的、单一的超能力;而 MCP 服务是模块化的、生态化的“超级技能包”。
它让 AI 摆脱了“每个技能都要人肉手写”的原始阶段,实现了“超能力的批发和即插即用”。这也正是为什么整个大模型行业(特别是 Anthropic、Cursor 等先锋)对 MCP 协议如此兴奋的根本原因。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)