
【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 --- (5)--- 异步处理
0x00 概要
本系列的目的是:借着对 OpenClaw-RL 源码的学习,来梳理强化学习的一些相关概念和思想。所以,会有一些基础知识、扩展和发散,OpenClaw-RL 只是一个切入点。而且,因为整篇系列是一个整体,所以有些概念的解读/学习会在不同的文章中出现,还请大家谅解。
OpenClaw-RL 是一个用于在线强化学习(Online RL)的框架,专门针对智能体工具使用场景。它通过从环境反馈中提取过程奖励信号来训练语言模型,支持三种主要模式:
- openclaw-rl:基于二元奖励的强化学习(Binary RL / GRPO)
- openclaw-opd:基于后见之明提示的在线策略蒸馏(On-Policy Distillation, OPD)
- openclaw-combine:联合方法,在同一 PPO 更新中同时利用 RL reward 和 OPD teacher signal
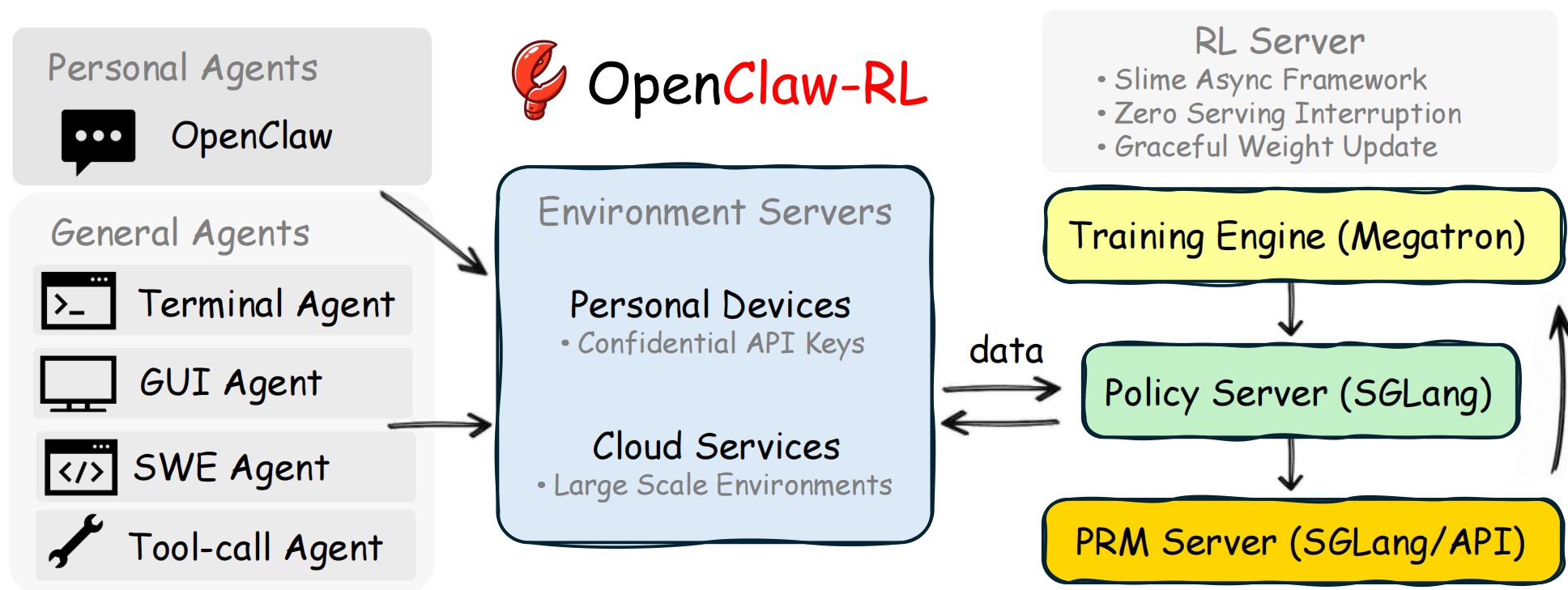
0x01 异步架构
OpenClaw-RL 的系统设计是四个异步解耦的循环——policy serving、environment hosting、reward judging、policy training 同时运行、互不阻塞,因此模型可以一边持续服务,一边从刚刚发生的真实交互中在线学习。
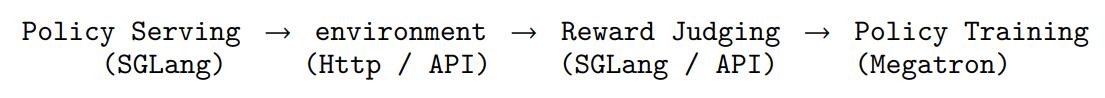
这四个组件以零协调开销异步运行:模型服务用户请求的同时,PRM正在评判上一轮交互,训练器同步更新策略------ 三者互不等待。这一设计使得从实时、异构的交互流中进行连续训练成为可行,无需任何流被暂停或批处理来配合其他组件。
在这种模块化设计中,各组件既保持功能独立性又实现数据互通。即,其总体是异步进行的,具体如下:
时间轴 (完全异步, 各组件不相互阻塞):
----------------------------- Policy Serving ---------------------------------
SGLang: 服务用户 ─────────────────── 暂停(503) ─ 加载新权重 ─ 服务用户 ──►
Proxy: 采集数据 ─────────────────── 暂停 ─────── 恢复 ───── 采集数据 ──►
----------------------------- Reward Judging ---------------------------------
PRM: 评分 ───── 评分 ───── 评分 ─────────────────────── 评分 ───── 评分 ──►
----------------------------- Policy Training---------------------------------
Megatron: ─ 等待数据 ───────────── 训练 ─ 同步 ─ 等待数据 ─── 训练 ─────────►
系统通过完全异步的设计实现四大核心优势:
- 服务连续性保障:策略服务与训练过程解耦,确保7×24小时无中断服务。通过双缓冲机制实现模型热切换,权重更新期间仍可维持原有策略响应。
- 实时学习能力:环境反馈与评估结果通过消息队列实时传输,训练模块可立即消化最新交互数据。系统支持每秒百次级的模型参数更新,实现真正意义上的在线学习。
- 长周期任务处理:针对软件工程等复杂任务,采用异步环境管理策略。不同任务轨迹可独立推进,通过工作流引擎协调依赖关系,有效缓解长尾延迟问题。
- 个性化适应机制:通过会话感知技术区分训练轮次与转发轮次,在保证用户体验的同时积累个性化数据。系统动态调整探索-利用平衡参数,实现用户偏好与模型能力的协同进化。
0x02 训推分离
因为异步架构和训推分离是一体两面,所以我们先介绍训推分离。
同步RL的理想情形(无漂移)是on-policy,即:
时刻 t:
1. rollout:使用π_t生成N条样本
2. update: 用这N条样本更新 → 得到π_{t+1}
3. rollout:使用π_{t+1}生成下一批...
即,Policy π_θ → 生成轨迹 → 立刻更新T_θ → 重复
每批训练数据100%来自当前policy → 完全on-policy,即生成数据时的 policy = 更新时的 policy = on-policy → 理论保证:importance weight = 1,无需修正。
ratio = π_{t+1}(a|s)/π_t(a|s) = 1(刚更新一步,变化很小)
然而,实际上这是理想情况。
2.1 为什么训练和推理通常分离?
2.1.1 内存布局根本冲突
训练和推理同时在同一块 GPU 上高效运行,物理上就冲突——KV cache 和优化器状态争同一显存。
| 训练引擎(FSDP/Megatron) | 推理引擎(vLLM/SGLang) |
|---|---|
| 显存用途:参数 + 梯度 + 优化器状态(约 4x 参数大小) | KV Cache(约 2x 参数大小) |
| 分片方式:ZeRO 参数分片(跨 GPU 不连续) | 每卡完整参数(连续 + 量化) |
| Attention:PyTorch Flash Attention | PagedAttention |
| 批处理:固定 batch(padding 对齐) | Continuous batching(动态) |
由于前向传播占用的显存小于反向传播,所以一般一个 step会首先 rollout 大量的轨迹,然后分批次进行梯度优化。
2.1.2 计算特性完全相反
- 训练:计算密集(矩阵乘法,GPU利用率高),延迟不敏感
- 推理:内存带宽密集(每token读权重),延迟极敏感
混合运行会让两者都变慢。
2.1.3 RL特有的权重同步问题
推理(rollout) → 收集数据 → 训练(更新权重) → 推理用新权重 → ...
如果训练和推理在同一进程,参数更新期间无法同时做推理。虽然可以用xccl广播把新权重从Megatron传到 SGLang,但是,这本身就是跨引擎同步,不是同框架内的操作。
比如:
GPU 0-3(Megatron)更新后 → 同步到GPU 4-5(SGLang)
同步期间(几十秒到几分钟): → 在途的rollout用的是旧weights → 同步完成前所有新对话都是off-policy
2.1.4 工程复杂度爆炸
维护一个同时优化 FlashAttention、PagedAttention、ZeRO-3、梯度 checkpoint 的框架,代码复杂度是各自独立的 5-10 倍。因此,主要框架选择了各自专精:
| 框架 | 策略 |
|---|---|
| OpenRLHF | 彻底分离:Actor(vLLM) + Trainer(DeepSpeed) |
| VeRL | "混合引擎"(同卡串行切换,不是真并行) |
| AReaL | 异步解耦:SGLang 推理 + FSDP 训练,用 xccl 同步权重 |
| TRL | 简单 PPO,训练和推理共用 HF 权重(效率最低) |
2.1.5 小结
因此,在第 2 个批次及以后,所优化的轨迹都不是那个 model 自己生成的,而是上一个 step 的 model 生成的,这就引入了 off-policy。另外,在 partial rollout 中,一条轨迹可能来自不同的 model,就更加加剧了这个问题。
2.2 Agentic RL的三个分布
在Agentic RL中,有三个分布:
π_rollout:采样时的策略分布(策略模型产生训练数据的policy)π_learner:更新时见到的样本分布(learner实际梯度计算用的数据)π_deploy:最终部署时系统实际执行的策略分布(真实环境下policy的行为)
一致的理想情形:完全on-policy + 训练分布 = 部署分布。然而,这三个分布几乎不可能天然一致。
三层分歧的汇总如下:
生成数据 处理数据 真实服务
π_rollout ────► π_learner ────► π_deploy
↑ ↑ ↑
异步更新Gap Filter + Buffer Gap 探索/利用+分布漂移Gap
k步policy差异 训练分布被人为塑造 用户分布随时间变化
PPO clip约束 ?(通常无显式约束) 通常完全不处理
以下,我们会结合OpenClaw-RL 逐层分析为何这几乎不可能。
2.2.1 第一层分歧
第一层分歧:π_rollout ≠ π_learner(Off-Policy Gap)
原因A:异步更新(权重同步延迟)
时刻t: rollout生成样本(s_0,a_0,...,s_T)使用`π_θ_t`
时刻t+k:learner处理这批样本,更新π_θ_{t+k}
π_θ_{t+k} ≠ π_θ_t(中间已经k步更新了)
importance ratio = π_{t+k}(a|s)/π_t(a|s) ≠ 1
在单轮RL里:
- k很小(一次更新周期)。
在Agentic RL里:
- 一个episode跑T=20步,在此期间其他worker可能更新了policy
- step 1的数据用的是
π_t,step 20的数据已经是π_{t+20}的环境下生成的
比如(Weight Sync 窗口):
-
权重同步期间(503 阻断了新的 rollout): → 但已在队列里的样本是同步之前生成的
-
同步完成后(SGLang 有了新的权重):
→ learner 还在处理同步前的旧样本 → 旧样本的 rollout_log_probs 来自"旧权重的 SGLang"
→ 当前 policy 是"新权重的 Megatron" → ratio 在 weight sync 边界处跳跃
ratio 时间线(示意):
-------------------------[weight sync]-------------------
ratio: 1.0, 1.1, 0.9, 1.2, ... | 1.8, 1.5, 2.1, ...
↑ sync 后 ratio 突然变大
原因B:队列/Buffer的时间延迟
OpenClaw具体情况:
- 轮次N的response进入queue → 等待PRM打分(异步)
- 在此期间,其他样本继续训练 → policy继续更新
- PRM打完分,样本进入训练 → 这时policy已经是
π_{N+k} - policy用
π_{N+k}在π_N生成的数据上更新 → off-policy
即,系统架构决定了异步性:
rollout worker ────► buffer/queue ────► learner
(连续产生数据) (样本等待处理) (继续更新policy)
样本在buffer里等待期间:
- learner继续更新policy
- policy从
π_t变成了π_{t+k}
当样本被learner取出时:
- 样本的log_prob是
π_t计算的 - gradient更新的是
π_{t+k} ratio=π_{t+k}(a|s)/π_t(a|s)← 不再 ≈ 1
即使在“同步“系统里:
- rollout进入queue → 等待learner → 处理时policy已更新
- queue depth x 更新频率 = staleness
原因C: Filtering改变分布
OPD只保留hint-accepted的样本:
- → learner看到的分布 = “模型回复较差、有改进空间的那些turn"
- ⇆ rollout原始分布(所有turn)
Binary RL的at-least-one:
- → 强制把某些score = 0的样本变成mask = 1
- → learner见到的有效样本分布被人为调整
原因D:PRM打分的异步延迟
Turn 产生 → _fire_prm_scoring(异步发出 3 个 judge 请求)
↓ 等待 5-30 秒(judge LLM 推理时间)
↓ 期间:其他 turn 继续进入 learner
PRM 返回 → 样本进入队列 → 被 learner 处理
样本的 rollout_log_probs 是 5-30 秒前的 policy 计算的,policy 在这 5-30 秒内可能已经更新了若干步
原因E:多步 Episode 的时间跨度
假设每步 2 秒,T=20 步的 episode:
step 1 生成于 t=0, rollout_lp 来自 π_{t=0}
step 20 生成于 t=40s
这 40 秒内如果 learner 更新了 k 步: step 1 的样本被 π_{t=0+40s+training_time} 处理,π 已经变了很多
漂移量 ≈ f(episode_length × step_time × learner_speed)
原因F: 轨迹时长不均
还有一种情况是 轨迹时长不均,比如:Task A: 2秒 Task B:30分钟 Task C:10秒。
如果等所有任务完成再更新: → Task A在 policy v1 时生成,等待时变成 stale → 等 Task B完成,TaskA已经是30分钟前的数据 → 如果不等Task B,则TaskB贡献的梯度在下一轮更新才进来
2.2.2 第二层分歧
第二层分歧:π_rollout ⇆ π_deploy(协变量偏移)
原因A:探索 vs 利用的采样差异
rollout(训练时):
- temperature = T_high,随机采样 → 生成多样化的响应,探索更广的路径 → 分布更宽、更均匀
deploy(部署时):
-
temperature = T_low(或top-p),更确定性 → 给用户最好的那条路径 → 分布更尖锐、集中在高概率区域
-
D_KL(π_deploy || π_rollout)>0:用高temperature的数据训练,要使用 low temperature的推理 → 分布不一致
原因B:用户行为随时间变化
训练数据收集时:用户问A类问题。
三个月后部署:用户问B类问题(新需求、新话题、模型能力提升导致用户问更难的)
π_rollout在旧的状态分布D_old上采样π_deploy面对新的状态分布D_new
- D_new ⇆ D_old → 分布偏移
原因C:Agentic特有的状态分布循环依赖
π_t 决定采样哪些trajectories → trajectories决定遇到哪些states → states的分布影响下一步的 action distribution → action distribution又影响π_{t+1}的训练方向
这是一个循环:
state_distribution = f(policy)
policy=f(state_distribution)
当policy更新后,状态分布也会变化 → rollout时的状态分布和deploy时的状态分布持续偏移 → 单轮RL没有这个问题(状态=用户的prompt,不依赖policy)
2.2.3 第三层分歧
第三层分歧:π_learner ⇆ π_deploy(优化目标错位)
- π_learner优化的是:reward信号所定义的"好“
- π_deploy面对的是:真实用户的"有用“
当reward真实用户价值时:模型学会了“让judge打高分的技巧“,而不是“真正帮助用户的能力“
具体来说,以下二者不同:
- learner分布 = “被judge filter后的数据"(有偏)
- deploy分布 = “所有真实用户请求"(无偏)
2.2.4 拓展
漂移的数学影响
PPO clip假设:ratio∈[1-e,1+e]
-
正常情况:
ratio ≈ 1 → 梯度完整保留 -
漂移情况:
ratio=2.5(新policy更倾向于这个action) → min(2.5*A,1.28*A)=1.28*A → 被clip,损失了49%的梯度信号 ratio=0.3(新policy不太倾向于这个action) → min(0.3*A,0.8*A)=0.3*A → 低梯度,但方向可能是错的
漂移越大 → 被clip的样本越多 → 有效梯度越弱 → 需要更多样本才能达到同样的学习效果。
为什么在AgenticRL中比单轮RL更严重
单轮RL:每条样本 = 1个动作 → 更新 → 立即部署。三个分布分歧最小
AgenticRL:每个 episode=T个动作,T步期间policy可能更新多次(gap ∝ T),环境响应policy 的状态分布循环依赖 → 三个分布分歧随episode长度放大
漂移的不均匀性是最大问题
同一个训练batch里:
- 样本A:5分钟前生成,ratio=1.1 (新鲜,漂移小)
- 样本B:30分钟前生成,ratio=3.2 (陈旧,漂移大,被clip)
- 样本C:2分钟前生成,ratio=0.95 (非常新鲜)
问题:不同样本的漂移程度不同 → 每个样本对梯度的贡献比例不同 → 批次内的有效学习率实际上是不均匀的 → 训练方差增大,不稳定
2.2.5 小结
三个分布不一致是 Agentic RL 的结构性问题,而非工程缺陷:
- 异步训练把 rollout 和 learner 分开,filter 和 buffer 进一步改变 learner 分布,探索/利用差异和用户行为漂移让 deploy 分布独立演化。
- 单轮 RL 中这些分歧很小;但是,Agentic RL 中,它们随 episode 长度放大,成为训练不稳定的核心来源。PPO clip 只约束了 rollout-learner 的第一层分歧,后两层几乎没有系统性防护。
2.3 OpenClaw-RL 如何处理三层分布分歧
2.3.1 第一层
π_rollout ≠ π_learner(Off-Policy Gap)
处理机制 1: Weight Sync 期间的 503 Pause
在 503 pause 期间,权重同步时暂停 rollout,防止产生更多 off-policy 数据。
# openclaw_api_server.py
# 权重同步时暂停 rollout,防止产生更多 off-policy 数据
if not self.submission_enabled.is_set():
raise HTTPException(status_code=503, detail="submission paused for weight update")
虽然做了处理,但是并不能完全消除问题,比如,在 Megatron更新完权重 → 同步到SGLang(几十秒到几分钟)这期间:
- √ rollout被503阻断 → 不产生新的off-policy数据 → 减少了weight sync边界的大规模漂移
- ✗同步完成前已在队列里的样本 → 仍然off-policy(无法消除)
- ✗样本没有staleness字段(不知道等待了多久)
- ✗没有importance weighting(所有样本等权,不管新旧)
- ✗没有自动丢弃“太旧“的样本(ARLArena的OPSM思路)
- ✗weight sync边界的ratio跳跃没有特殊处理
处理机制2:PPO Clip(隐式IS修正)
# ppo_utils.py (slime/utils/ppo_utils.py:125-148)
ratio = (-ppo_kl).exp() # ppo_kl 是负的 log-ratio,取负再 exp 得到 π_θ/π_old
pg_loss = -torch.maximum( # 注意是 torch.maximum(非 torch.min),因为前有负号
ratio * advantages,
torch.clamp(ratio, 1 - eps_clip, 1 + eps_clip_high) * advantages
)
- eps_clip / eps_clip_high: 分别控制下/上裁剪阈值,允许非对称 clip(典型值 0.2 / 0.28)
- 超出 [1-eps_clip, 1+eps_clip_high] 范围的 ratio 被截断 → 防止极端 off-policy 样本主导梯度
处理机制3:监控指标
train_rollout_logprob_abs_diff 会监控漂移量
#Slime 内置
train_rollout_logprob_abs_diff #实时监控 rollout-learner gap
#如果这个值快速上升,说明off-policy问题加重
2.3.2 第二层
第二层:π_rollout ≠ π_deploy(协变量偏移)
OpenClaw的根本优势:在线学习使这层分歧几乎消失
离线RLHF(InstructGPT)
数据收集 → RM训练 → PPO训练 → 部署
↑ ↑
这是几周前用户的行为分布 这是现在用户的行为分布
二者已经不同
OpenClaw
用户 → 直接与SGLang交互 → 数据同时用于训练
↑ ↑
rollout分布 = 部署分布(同一个系统!)
小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)