
我们把 Hermes Agent 的记忆系统拆开看了:AI Agent 到底该怎么“记住”事情?
仓库地址:https://github.com/breath57/how-ai-agents-remember
如果你想系统理解 AI Agent 的“记忆”到底是怎么实现的,这个仓库值得收藏。
How AI Agents Remember 不是泛泛而谈的 AI Agent 综述,而是逐行阅读 5 个开源 Agent Bot 项目的记忆相关源码,把它们的架构、数据模型、检索管线、上下文注入、生命周期管理和复刻方案整理成一套可读、可比较、可落地的技术文档。
目前仓库已经覆盖 5 个项目:OpenClaw、Hermes Agent、nanobot、NullClaw、OpenFang。
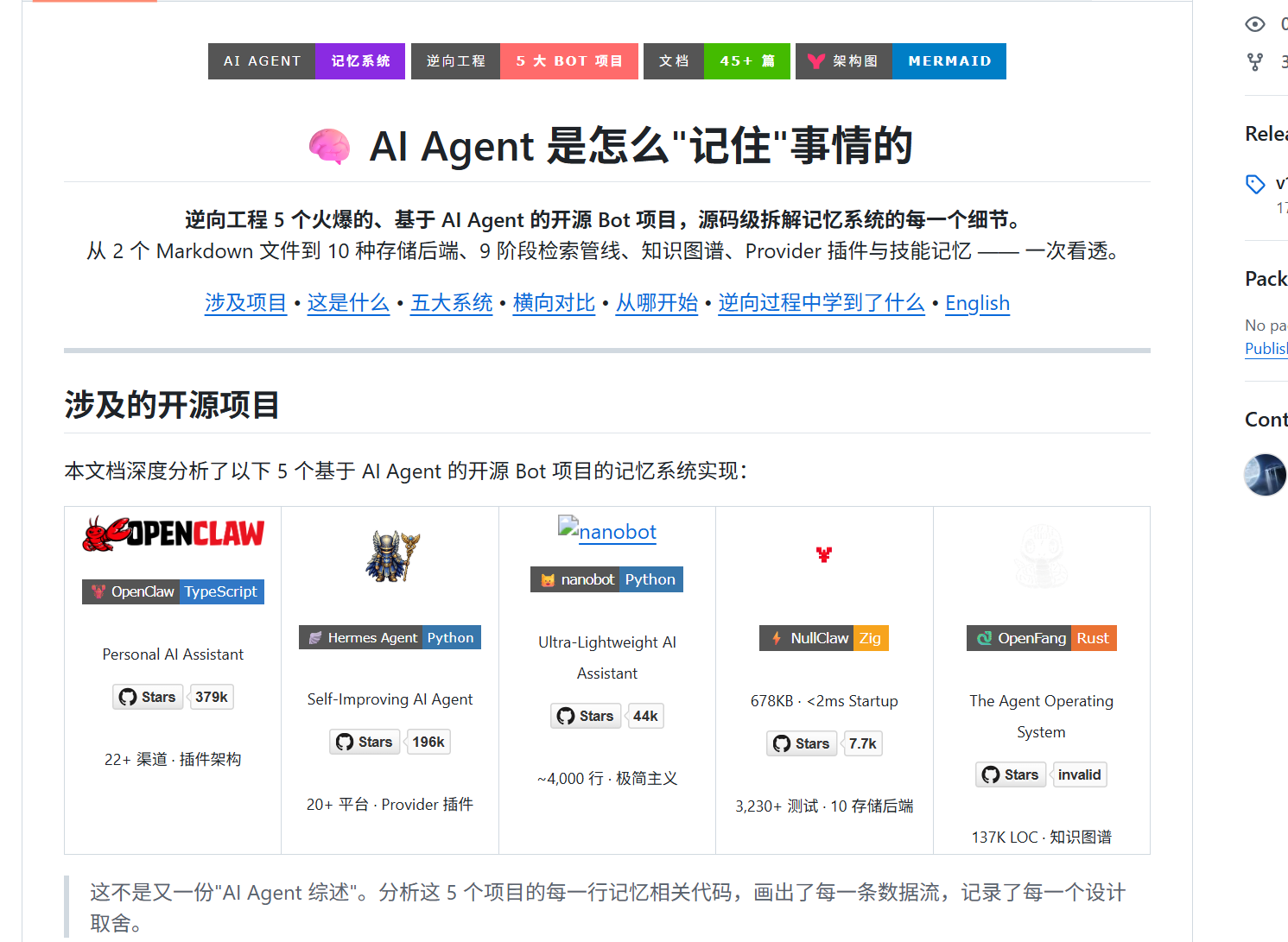
这次更新的重点,是新增了对 Hermes Agent 的完整拆解。但这篇文章不是只介绍 Hermes,而是想借 Hermes 这个最有代表性的案例,把整个仓库想解决的问题讲清楚:AI Agent 到底应该如何长期、可靠、可控地“记住”事情?
如果你正在做 AI Agent,很可能已经遇到过这个问题:
Agent 能回答当前这一轮对话,不难。
但它怎么记住用户是谁?怎么记住长期偏好?怎么搜索历史会话?怎么在不破坏 prompt cache 的情况下,把“记忆”安全地塞回上下文?
这就是这个仓库想回答的问题。
不同项目给出了完全不同的答案:有的用 Markdown 做唯一真相源,有的做多阶段检索管线,有的把知识图谱塞进统一 SQLite 底座,有的把记忆拆成 Provider、会话搜索、上下文压缩和 Skills。把它们放在一起看,比单看某一个框架更容易理解 Agent 记忆系统的真实设计空间。
为什么重点看 Hermes Agent?
Hermes Agent 很有代表性。
它不是简单地把几条用户偏好写进 MEMORY.md,也不是把所有历史都粗暴塞进 prompt。它的记忆系统更像一个分层的生产级 Agent 记忆架构:
MEMORY.md/USER.md保存少量必须常驻 prompt 的事实。state.db保存完整会话历史,并通过 SQLite FTS5 做按需搜索。- Memory Provider 插件负责外部语义记忆、用户模型或知识图谱。
- ContextEngine 管理上下文压缩和 session split。
- Skills 承担程序性记忆,把复杂流程从事实记忆里拆出去。
- 外部 recall 不直接污染 system prompt,而是 fenced 后注入当前 user message 的 API copy。
最后这一点尤其关键。
很多 Agent 项目一开始都会把“记忆”理解成“往 prompt 里塞更多东西”。但 Hermes Agent 的设计提醒我们:生产级记忆系统首先是缓存边界设计。
什么内容应该常驻 system prompt?什么内容应该只在需要时搜索?什么内容应该只在当前 API 调用里临时注入?如果这些边界不清楚,记忆越多,Agent 反而越不稳定、越慢、越贵,也越容易被历史噪音污染。
Hermes Agent 的核心洞察:记忆不是一个数据库,而是五条记忆平面
在这次分析里,我们把 Hermes Agent 的记忆系统拆成了五条平面:
- 内置事实记忆:
MEMORY.md/USER.md - 会话搜索记忆:
state.db+ FTS5 +session_search - 外部 Provider 记忆:Honcho / Mem0 / Hindsight 等插件
- 上下文压缩记忆:ContextEngine + compressor + session lineage
- 程序性记忆:Skills + slash command + curator
这五条平面解决的是不同问题。
事实记忆解决“用户是谁、长期偏好是什么”。
会话搜索解决“过去某次对话里说过什么”。
Provider 记忆解决“语义相似、用户画像、知识图谱、长期关系建模”。
上下文压缩解决“上下文窗口满了以后怎么不断线”。
Skills 解决“复杂流程和操作套路不应该写进事实记忆”。
这比“加一个 memory table”要复杂,但也更接近真正能跑起来的 Agent 产品。
这次 Hermes Agent 文档具体写了什么?
Hermes Agent 部分一共整理了 10 篇文档:
- 总览:五条记忆平面、模块关系和数据流。
- 内置记忆:
MEMORY.md/USER.md如何加载、冻结、写入和限制容量。 - Provider 插件:外部记忆插件接口、生命周期和注入方式。
- 会话搜索:
state.db、FTS5、跨 profile 会话读取和搜索工具。 - 上下文压缩:ContextEngine、session split、压缩边界和 lineage。
- 运行时流程:从启动到每一轮对话,记忆系统如何参与。
- 安全可靠性:注入防护、写入审批、漂移检测、异步隔离和 DB 自愈。
- 技能记忆:为什么 Skills 是程序性记忆,以及它如何避免污染事实记忆。
- 复刻指南:如果你用 Python / LangGraph 做 Agent,怎么复刻这套架构。
- 入口 README:快速索引和源码映射。
每篇都不是停留在概念层,而是尽量回答工程问题:数据放在哪里?什么时候读?什么时候写?失败怎么降级?prompt cache 怎么保护?上下文爆了怎么办?如果要自己实现,第一步应该做什么?
为什么这对 Agent 开发者有用?
因为“记忆”很容易被低估。
一个 demo 级 Agent 可以靠上下文窗口硬撑。
一个能长期使用的 Agent 必须处理这些问题:
- 用户长期事实和短期对话不能混在一起。
- 所有历史都塞 prompt 会破坏成本、延迟和稳定性。
- 语义记忆、会话搜索、技能流程其实是不同类型的记忆。
- 外部检索结果必须有边界,否则容易变成 prompt injection 的入口。
- 记忆写入需要审批、校验和可回滚设计。
- 上下文压缩不能破坏工具调用配对和会话连续性。
Hermes Agent 的价值在于,它把这些问题都放到了架构里处理,而不是靠一两个“memory tool”糊过去。
不只是 Hermes:5 个项目的横向对比
Hermes 是这次更新的重点,但仓库真正的价值在于横向对比。
除了 Hermes Agent,这个仓库还分析了另外 4 个项目:
- OpenClaw:插件架构、Markdown 真相源、SQLite / LanceDB / QMD 双引擎。
- nanobot:两个 Markdown 文件完成长期事实和事件日志,极简但优雅。
- NullClaw:Zig 实现的企业级记忆系统,10 种后端和 9 阶段检索管线。
- OpenFang:Rust Agent OS,用统一 SQLite 底座承载 KV、语义搜索、知识图谱和会话。
它们放在一起看,会更容易理解 Agent 记忆系统的设计空间:
- 想快速做原型,可以看 nanobot。
- 想做插件生态,可以看 OpenClaw。
- 想理解 prompt cache 约束下的混合记忆,可以看 Hermes Agent。
- 想研究复杂检索工程,可以看 NullClaw。
- 想看知识图谱和统一存储底座,可以看 OpenFang。
这也是为什么这个仓库不是“某个项目的源码笔记”,而是一份 Agent 记忆系统的工程地图。
你可以从某一个项目切入,也可以直接看根目录 README 的横向对比:
- 中文入口:https://github.com/breath57/how-ai-agents-remember/blob/main/README.md
- English entry: https://github.com/breath57/how-ai-agents-remember/blob/main/README.en.md
- Hermes Agent 专题:https://github.com/breath57/how-ai-agents-remember/blob/main/hermes-agent/README.md
如果你只读一篇,建议从 Hermes Agent 开始
Hermes Agent 不是最简单的方案,也不是最重的方案。
它真正值得看的是边界感:
- 小事实常驻 prompt。
- 大历史进入数据库。
- 语义记忆交给 Provider。
- 长上下文交给 ContextEngine。
- 复杂流程交给 Skills。
- recall 只在当前 API 调用里 fenced 注入。
这套拆分非常适合作为生产级个人 Agent 的参考架构。
如果你正在设计自己的 Agent 记忆系统,不妨从这里开始,也欢迎 star / fork / 提 issue 一起补充更多项目:
仓库地址:https://github.com/breath57/how-ai-agents-remember
Hermes Agent 分析入口:https://github.com/breath57/how-ai-agents-remember/blob/main/hermes-agent/README.md
看完以后,你可能会重新理解一句话:
Agent 的记忆系统,不是“把东西存下来”。
而是要在正确的时间,以正确的边界,把正确的记忆带回模型面前。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)