
一天搞定Skills:从零到实战的极速通关
随着 AI 大模型的爆火,我们迎来了人工智能的黄金时代,但许多人在最初的兴奋过后,逐渐陷入了“提示词(Prompt)疲劳”。为了从大模型那里榨取完美的回复,用户不得不绞尽脑汁地编写冗长复杂的提示词,且每次开启新对话都要重新“培训”一遍这个聪明却健忘的助手,不仅效率低下,输出结果也常常缺乏稳定性。为了打破这一瓶颈,Agent Skills应运而生。它相当于给 AI 装上了标准化的“职业技能”,如果说大模型是 AI 的“大脑”,那么 Skills 就是 AI 的“手脚”与“经验库”,将那些复杂的提示词、执行流程与校验规则封装成可复用的模块,成为将抽象目标转化为具体行动的核心支撑。
一、Agent Skills 是什么?
Agent Skills 是由 Anthropic 于 2025 年确立的一套开放式 AI 智能体构建标准,其核心思想是将完成特定任务所需的知识、工具和执行逻辑,封装为模块化、可复用的"技能包",让 AI Agent 能够像人类拥有专业技能一样,在需要时动态加载并执行特定任务。
二、为什么需要Skills?
在传统的大模型应用中,开发者主要依赖冗长的 System Prompt 来指导模型行为。但随着企业级应用越来越复杂,这种方式面临两大瓶颈:
- 上下文污染:所有规则一次性塞入 Prompt,导致模型注意力分散,产生"指令漂移"。
- 复用性极差:业务逻辑被硬编码在对话历史中,难以跨项目、跨团队迁移。
Agent Skills 的出现,正是为了解决这些问题——它把 AI Agent 的"岗位 SOP(标准作业程序)"从 Prompt 中剥离出来,变成独立、可版本控制、可移植的技能模块。
三、Skills不同级别与优先级
目前各大厂商的 Agent Skills 在实现上各有差异。以 Claude Code 为例,Skills 根据所属级别的不同,拥有不同的作用域和优先级。
|
级别 |
存放目录(推荐) |
作用域 |
共享方式 |
优先级(越高越优先) |
|---|---|---|---|---|
|
企业技能 |
企业统一注册表/托管路径(如 |
组织内所有用户/项目 |
管理员统一配置,版本管理 |
最高(作为强制基线,不能被下级覆盖) |
|
个人技能 |
|
当前用户的所有项目 |
仅个人可见,不提交 Git |
次高(可覆盖项目和插件,但不能覆盖企业) |
|
项目技能 |
|
仅当前项目 |
通过 Git 提交,团队共享 |
中等(可覆盖插件,但不能覆盖企业和个人) |
|
插件技能 |
|
启用该插件的所有项目 |
随插件分发,无需手动安装 |
最低(作为能力补充,可被所有上级覆盖) |
当多个级别的技能存在冲突时,通常遵循优先级规则:Enterprise > Personal > Project > Plugin。
四、Skills的核心构成
一个完整的 Skill 通常包含以下要素:
- 触发条件:什么样的用户指令会激活这个 Skill
- 执行逻辑:具体的操作步骤和工具调用链
- 输入输出规范:需要什么输入,产出什么结果
- 错误处理:执行失败时的回退方案
从技术架构上看,一个标准的 Skill 是一个目录结构,包含:
my-skill-name/
├── SKILL.md ← 说明书(元数据+执行指令,用Markdown写)
├── scripts/ ← 可执行的脚本(.py / .sh 等),可选
├── references/ ← 参考资料(模板、API文档、规范文件等),可选
├── assets/ ← 静态资源(图片、字体、样例数据、模板文件等),可选
└── templates/ ← 输出模板(报告、邮件、代码骨架等生成物模板),可选
五、Skills 的加载机制(三层架构)
Skills 的加载并非一次性将所有内容塞入上下文,而是采用 分层按需加载 策略,兼顾轻量与精准:
第一层:元数据层--始终加载
加载时机:Agent 启动或工作区初始化时,立即扫描并加载所有可用 Skill 的元数据。
加载内容:每个 SKILL.md头部元数据
特点:
-
体积极小(通常 < 1KB),常驻 Agent 的工作内存,不占用太多 Token 预算。
-
用于构建 Skill 索引表,让 Agent 知道“我有哪些技能可用”、“它们叫什么”、“何时触发”。
-
支持快速匹配:用户输入
/release-check或意图命中时,Agent 能立即定位到对应 Skill。
第二层:指令层--按需触发
加载时机:只有当用户的请求或上下文 匹配到某个 Skill 的触发器(命令、意图关键词、文件模式等)时,才加载该 Skill 的完整指令正文。
加载内容:SKILL.md中除元数据外的所有 Markdown 正文,包括:
-
Workflow / Steps:执行步骤、判断条件、分支逻辑
-
Rules / Constraints:输出格式要求、质量标准、禁忌事项
-
Examples:输入输出示例(帮助模型理解期望行为)
特点:
-
懒加载:未被触发的 Skill 的指令正文永远不会进入上下文,大幅节省 Token。
-
一次通常只激活 1~3 个 Skill(可配置),避免上下文膨胀。
-
加载完成后,Agent 获得完整的“操作手册”,开始执行任务。
第三层:资源、模板与脚本--只有引用部分被读取
加载时机:在指令执行过程中,当 Agent 需要具体的数据、输出模板或执行自动化操作时,才按需读取 references/、assets/、templates/、scripts/中的文件。
加载内容(仅限被引用的部分):
|
目录 |
读取方式 |
示例 |
|---|---|---|
|
|
作为上下文片段注入(文本型) |
读取 |
|
|
作为附件/文件路径传递(二进制或文件) |
读取 |
|
|
作为输出模板读取,填充变量后生成最终产物 |
读取 |
|
|
在沙箱中执行(不注入上下文) |
执行 |
三层加载的总览图
┌───────────────────────────────────────────┐
│ Agent 启动 │
├────────────────────────────────────── ────┤
│ 第一层:元数据层(始终加载) │
│ - 扫描所有 skill 目录 │
│ - 加载 YAML Frontmatter │
│ - 建立 Skill 索引表 │
├───────────────────────────────────────────┤
│ 等待用户输入 / 事件触发 │
├───────────────────────────────────────────┤
│ 第二层:指令层(按需触发) │
│ - 匹配到触发器(命令/意图) │
│ - 加载对应 SKILL.md 正文(Workflow/Rules) │
│ - Agent 获得完整执行指引 │
├────────────────────────── ────────────────┤
│ 第三层:资源、模板与脚本(引用时读取) │
│ - 按步骤需要,读取 references/ 文本片段 │
│ - 按步骤需要,传递 assets/ 文件路径 │
│ - 按步骤需要,读取 templates/ 模板并填充 │
│ - 按步骤需要,执行 scripts/ 脚本并获取结果 │
└────────────────────────── ────────────────┘
六、手把手写skill
一个最基本的skill目录最少包含一个SKILL.md,其他目录可以根据需要增加。
1. 技能目录——Skill顶层组织结构
技能目录名必须都用小写,只能包含小写字母,字符和连字符,长度限制在64字符内。
例如:analyze-logs
2. SKILL.md——技能说明书(核心文件)
一个 SKILL.md 应该包含YAML frontmatter(元数据/触发条件)和Markdown 正文(给 Agent 的执行说明书)。ps:早期可能包含YAML文件,随着Agent的发展,YAML文件废除,相应的内容放在了SKILL.md的开头。
元数据
Metadata(元数据)是必须用---包裹,在“---”之前不能有空格其他内容,必须包含name和description,也可以根据需求增加version等。
name:必须跟这个skill的技能目录名一致,例如文件夹名是“generate-test-case”,那这个name也必须是“generate-test-case”。
description:必填且少于1024字符。
name和description不宜过长,否则每次加载都会消耗不必要的token,且不利于记忆和匹配。
description中应包含触发条件,最好是高频词,比如:生成测试用例的skills应该有“生成测试用例”、“generate test cases”等。避免描述操作步骤,description只做两件事,一个声明这个skill是做什么的,在什么时候触发。
例如下面这个skill的元数据的示例:
--- name: analyze-logs description: 对应用日志(stdout、文件日志、结构化 JSON)进行分类分析,找出错误、堆栈跟踪和可能的根因。适用于用户粘贴或附上日志、要求分析/调试日志输出、从应用日志中排查崩溃或故障,或需要从日志文件生成结构化 HTML 报告时。支持通过 ADB 从 Android 设备采集 logcat/ANR/dropbox/bugreport,以及通过 libimobiledevice 采集 iOS 系统日志和崩溃日志。报告以独立的 .html 文件输出,包含可折叠的堆栈跟踪、彩色严重程度标签和响应式布局。 ---
Markdown指令主体
文件限制:文件内容不宜过长,控制在 500 行以内或按 token 估算大约 ≤ 5000 tokens。正文内容正文尽量清晰明确,只放"每次执行都要看的指令",其他资料拆到 references/ 里按需读,相关静态文件放在asset读取。
SKILL.md 在命中触发后会整体加载进 Agent 的上下文窗口——它跟对话历史、系统提示、其它技能元数据抢同一个有限的 token 预算。太长会稀释注意力、拖慢响应、甚至被挤掉关键信息。
一个SKILL.md一般会包含以下几个基本内容
1. 工作流/步骤——分步执行,清晰明确
工作流/步骤应该清晰明确,并且分步执行。指令明确防止AI自由发挥,结果偏离语义。分步执行可以避免AI一次加载太多内容造成结果模糊,或者执行时没有重点造成部分内容被忽略。
``` 任务进度: - [ ] 步骤 1:标准化格式(纯文本 vs JSON) - [ ] 步骤 2:查找故障信号 - [ ] 步骤 3:构建事件时间线 - [ ] 步骤 4:追溯根因 - [ ] 步骤 5:输出结构化报告 ```
2. 规则与约束 ——明确边界,防止越界
规则与约束定义了 AI 在执行任务时必须遵守的硬性边界,包括输出格式要求、质量标准、禁忌事项等。这些规则应当具体、可衡量、无歧义,避免使用“尽量”“通常”等模糊词汇。约束可以分为三类:
-
格式约束:输出的结构、字段顺序、数据类型、文件扩展名等。
-
质量约束:最小字数、必须包含的要素、不允许出现的错误类型等。
-
禁忌事项:禁止调用的 API、禁止删除的文件、禁止透露的信息等。
### 格式约束
- 输出必须为 Markdown 格式,文件名为 `weekly-report-YYYY-MM-DD.md`
- 顶部必须包含元数据块:`作者`、`日期`、`项目名称`
- 正文分为三个段落:`已完成事项`、`进行中事项`、`待解决问题`### 质量约束
- 每个事项条目必须包含:`任务名称`、`状态`(✅ 已完成 / 🔄 进行中 / ⏳ 待开始)、`备注`
- 总字数不少于 200 字,不多于 500 字
- 不允许出现“暂无”“无进展”等空泛描述;若无进展,应写明原因### 禁忌事项
- 不得访问项目根目录以外的文件系统
- 不得调用网络 API(除非在 SKILL.md 中显式声明)
- 不得将任何内部数据写入公共日志或标准输出
3. 示例规范——输入输出约束规范
示例规范,应该给出相应的正确示例规范对AI的输入输出加以约束规范。
好的示例:
任务:查询天气
输入:“城市:北京,时间:2026-6-6”
输出格式:北京,时间:2026-6-6,天气晴,气温:5-15摄氏度,穿衣建议:穿薄外套。
4. 引用与拓展——渐进式披露
因为SKILL.md长度的限制和保持文档清晰可读性,SKILL应只涵盖高层级的任务描述、目录索引、规则说明和执行流程,而其他的内容应该放在资源文件里面。引用外部层级深度不要超过一级,避免多层嵌套引用。而具体的细节内容(如完整的字段映射表、长篇示例、详细的技术规范)应存放在 references/、assets/、templates/等资源文件中,通过显式引用的方式按需加载。
核心原则
-
SKILL.md 保持“瘦身”:只写核心流程、关键规则和必要的约束,避免大段复制粘贴。
-
引用代替内嵌:凡是超过 10 行、或者属于“可替换/可版本化管理”的内容,都放到资源文件中,在
SKILL.md中用路径或文件名引用。 -
引用层级不超过一级:避免多层嵌套引用(例如
A.md引用B.md,B.md又引用C.md),这会增加加载器的复杂度和出错概率。建议只允许 Skill 主文件引用其同级目录下的资源文件,资源文件之间不再相互引用。
在 SKILL.md中,可以用以下方式引用外部资源:
## 附加资源
- 设备日志采集脚本:[scripts/collect_logs.py](scripts/collect_logs.py)
- HTML 报告模板:[references/template.html](references/template.html)
- 分类分析报告示例:[examples.md](examples.md)
至此,一个完整的 SKILL.md就完成了。它包含了两个核心部分:YAML Frontmatter(元数据层) 和 Markdown 正文(指令层)。元数据层为 Agent 提供了轻量索引所需的名称、版本、作用域、触发条件和依赖声明;指令层则在任务匹配后按需加载,详细描述了工作流程、规则约束、示例以及对外部资源的引用。整个文件遵循“瘦主体、按需引用”的原则,既保证了 Agent 的快速响应,又为复杂任务的精准执行提供了完整指引。整体结构如下:
---
name: release-check
description: 发布前检查清单(测试覆盖率/变更日志/权限)
---## 工作流程 / 执行步骤
1. 检查测试覆盖率是否达到 80%
2. 验证变更日志是否存在且格式正确
3. 确认所有审批人已签署
4. 输出检查报告## 规则与约束
- 输出格式为 Markdown 表格
- 每项检查必须标注通过/失败/跳过
- 失败项必须附原因说明## 示例
输入:`/release-check`
输出:
| 检查项 | 状态 | 备注 |
|--------|------|------|
| 测试覆盖率 | ✅ 通过 | 85% |
| 变更日志 | ❌ 失败 | 缺少 v1.2.0 条目 |## 附加资源
- 测试覆盖率工具配置:参见 `references/coverage_config.json`
- 变更日志模板:参见 `templates/changelog_template.md`
3. scripts/—— 可执行脚本
定义:存放可直接由 Agent 沙箱环境执行的脚本文件,用于完成自动化操作(数据处理、API 调用、文件转换、环境检查等)。
典型内容:
-
Bash 脚本(
.sh) -
Python 脚本(
.py) -
其他脚本语言(如 Node.js
.js、Ruby.rb),取决于 Agent 的运行环境支持
限制与注意事项:
|
限制 |
说明 |
|---|---|
|
仅支持原生可执行脚本 |
目前仅 |
|
脚本必须具有可执行权限 |
Linux/macOS 环境下需确保 |
|
输出必须为 stdout |
Agent 通过捕获 stdout 获取脚本结果,因此关键信息应打印到标准输出,而非写入文件后另寻途径读取(除非在 SKILL.md 中约定文件路径)。 |
|
禁止副作用 |
脚本不应修改 Skill 目录之外的系统文件、环境变量或网络配置,除非在 SKILL.md 中显式声明并获得用户授权。 |
|
依赖声明 |
脚本所需的第三方库(如 Python 的 |
|
超时控制 |
脚本执行应有默认超时(如 30 秒),避免长时间挂起阻塞 Agent。超时值可在 |
4. templates/—— 输出模板
定义:存放 Skill 执行后生成最终产物时所依赖的空白模板文件。Agent 读取模板结构,填充数据后输出完整的文档、表格或演示文稿。
典型内容:
-
Word 文档模板(
.docx) -
Excel 表格模板(
.xlsx) -
PPT 演示文稿模板(
.pptx) -
纯文本/代码模板(
.md.jinja、.html.template、.py.template)
限制与注意事项:
|
限制 |
说明 |
|---|---|
|
模板应为“空白”或“占位符”形式 |
模板中应包含明确的占位符(如 |
|
格式兼容性 |
二进制模板( |
|
模板大小限制 |
单个模板文件建议不超过 5MB,过大的模板应拆分为多个子模板或存储在外部对象存储中,Skill 内仅保留路径引用。 |
|
占位符命名规范 |
占位符名称应与 |
|
模板版本管理 |
模板文件应随 Skill 一起纳入版本控制(如 Git),每次修改需同步更新 |
5. assets/—— 静态资源
定义:存放 Skill 在执行过程中需要用到的视觉素材、品牌元素、样例文件等静态资源。这些资源通常以文件路径形式传递给 Agent 或脚本,而非直接注入上下文。
典型内容:
-
企业 Logo 图片(
.png、.svg) -
专用字体文件(
.ttf、.otf) -
背景水印、信纸背景(
.png、.pdf) -
样例数据文件(
.csv、.json、.xml)—— 用于演示或测试 -
图标集、示意图(
.ico、.drawio)
限制与注意事项:
|
限制 |
说明 |
|---|---|
|
仅作为引用素材,不直接进入 LLM 上下文 |
Assets 文件通常不直接喂给大模型,而是通过路径传递给脚本或输出模板。Agent 在处理时只读取文件元数据(如尺寸、格式)或将其作为附件附加到输出中。 |
|
文件格式需通用 |
优先使用开放标准格式(PNG、SVG、TTF、CSV、JSON),避免专有格式(如 PSD、AI)导致兼容性问题。 |
|
文件大小控制 |
单个资源文件建议不超过 10MB。大型图片或字体应压缩后再存放。若文件过大,应存储在外部 CDN,Skill 内仅保留 URL 引用。 |
|
版权与许可 |
使用的字体、图片必须具有合法授权或属于开源/免版权范畴,避免法律风险。建议在 |
|
路径引用一致性 |
在 |
6. references/—— 参考资料
定义:存放 Skill 在执行过程中需要参考的结构化知识或技术文档。这些内容通常以文本片段的形式注入到 Agent 的上下文中,帮助模型理解业务规则、字段含义或接口规范。
典型内容:
-
错误代码列表(
.md、.json、.csv) -
API 接口字典(
.yaml、.json、.md) -
合规手册、政策条文(
.md、.txt) -
数据库 Schema、字段映射表(
.sql、.json、.xlsx) -
业务规则说明、计算逻辑公式(
.md)
限制与注意事项:
|
限制 |
说明 |
|---|---|
|
内容应结构化、可检索 |
参考资料应尽量以结构化格式(JSON、YAML、CSV)或清晰分段 Markdown 呈现,便于 Agent 按需提取,而非大段无序文字。 |
|
文件大小建议 ≤ 50KB |
过大的参考文件会增加 Token 消耗。若超过 50KB,应考虑拆分或仅保留摘要,完整内容存储在外部知识库中,通过 MCP 工具查询。 |
|
避免敏感信息 |
参考资料中不应包含密码、密钥、个人隐私等敏感数据。如有必要,应使用占位符(如 |
|
版本对齐 |
参考资料应与 Skill 的版本同步更新。建议在文件名中包含版本号(如 |
|
引用深度不超过一级 |
参考资料文件本身不应再引用其他文件(避免递归引用),确保加载链路清晰可控。 |
总结:四类目录的分工与边界速查
|
目录 |
核心用途 |
是否进入 LLM 上下文 |
典型文件大小 |
版本管理方式 |
|---|---|---|---|---|
|
|
执行自动化操作 |
否(仅结果回流) |
小(<1MB) |
随 Skill Git 管理 |
|
|
输出产物的骨架 |
是(模板结构) |
中(<5MB) |
随 Skill Git 管理 |
|
|
视觉素材/样例数据 |
否(仅路径引用) |
中(<10MB) |
随 Skill Git 管理 |
|
|
知识参考/规则文档 |
是(文本片段注入) |
小(<50KB) |
随 Skill Git 管理 + 版本号 |
日志分析Skill
写了个日志分析 Skill ,已开源至 GitHub仓库,支持自动识别日志格式、匹配已知错误模式、生成带时间线与根因推断的分析报告。欢迎大家下载体验,也欢迎在仓库中留言反馈使用中遇到的问题或功能建议。
地址: GitHub - AlyboHuang/skills · GitHub
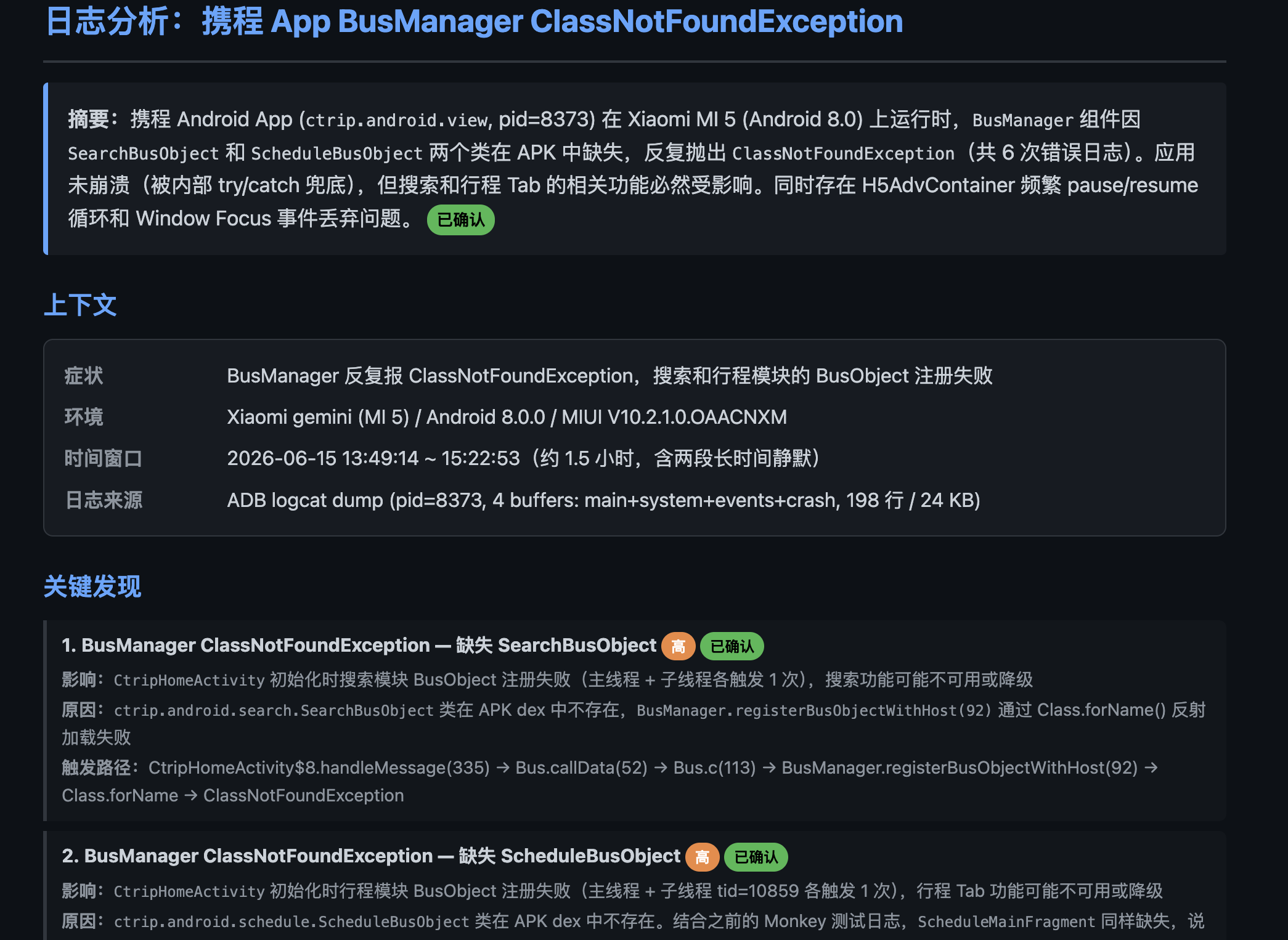
该 Skill 支持自动从手机导入日志文件进行分析,也支持直接粘贴日志内容或上传日志文件。示例如下:

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)