
OpenClaw(ClawdBot) 实战指南:如何在 AMD开发者云上用 vLLM 免费部署你的专属 Agent
OpenClaw(ClawdBot) 实战指南:如何在 AMD开发者云上用 vLLM 免费部署你的专属 Agent
原文作者:Mahdi Ghodsi

过去一周,OpenClaw(之前叫 ClawdBot 和 MoltBot)的活跃度明显提升。很多用户在展示自己的项目,也在分享如何把它当作个人助理来用。与此同时,围绕成本和安全性的讨论也越来越多。
本文将带你实操:如何在AMD Developer Cloud 上,借助企业级数据中心 GPU,AMD GPU(单卡 192GB 显存),免费运行一个强大的开源大模型,让你摆脱消费级 GPU 的限制。

通过AMD AI 开发者计划获取免费云资源
加入AMD AI 开发者计划 [1] 后,你可以获得:
- 50小时开发者云GPU算力(单卡)免费额度,足够你完成模型验证和一次完整项目跑通。
- 如果你能做出有价值的应用并公开分享项目,还可以申请额外额度。
- 另外还包含:
- 一个月 DeepLearning.AI Premium 会员
- 有机会定期参与每月 AMD 硬件抽奖
- AMD 训练课程的免费访问权限
快速上手流程概览
Step 1:注册 AMD AI 开发者计划
访问AMD AI 开发者计划页面[1],完成注册和加入:
- 已有 AMD 账号:直接登录后,加入该 Program 即可。
- 新用户:在登录页选择 “Create an account”,创建 AMD 账号后同步加入计划。
Step 2:激活云端额度
加入开发者计划后,进入成员站点(member-site),可以看到你的免费额度激活码,按页面提示进行激活。
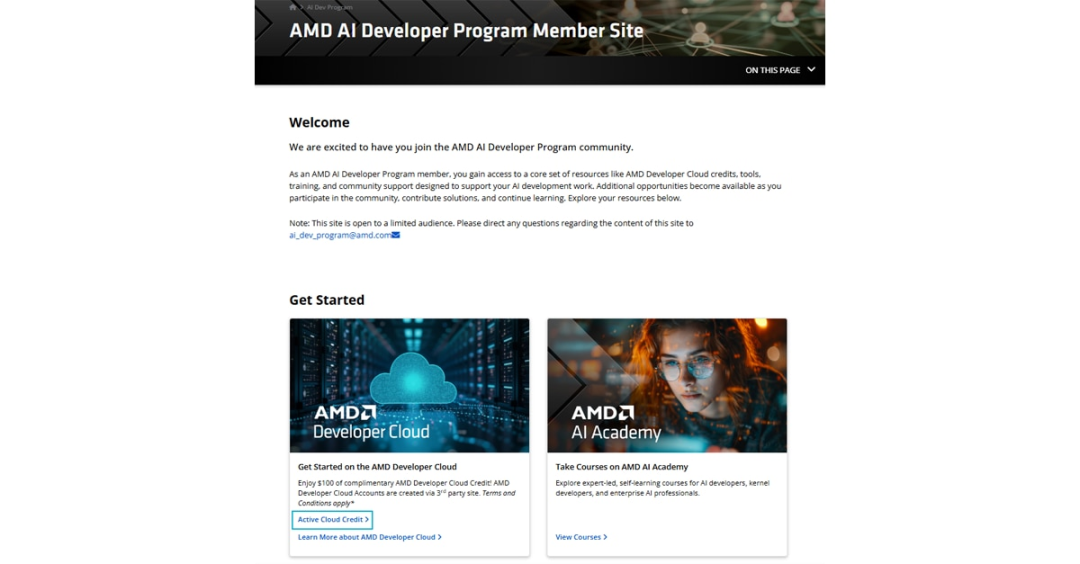
Figure 1: AMD AI 开发者计划成员站点首页示例
在AMD Developer Cloud 上创建AMD GPU Droplet
Step 3:创建 GPU Droplet
激活额度后,会进入Create a GPU Droplet 页面,你可以在顶部看到当前可用的积分(Credit)。
按如下配置创建Droplet:
1. 选择硬件:选择单卡实例。
2. 选择镜像(Image):选择ROCm Software镜像。
3. 配置访问方式:在页面相应区域添加你的 SSH 公钥(页面会提供生成 SSH key 的说明)。
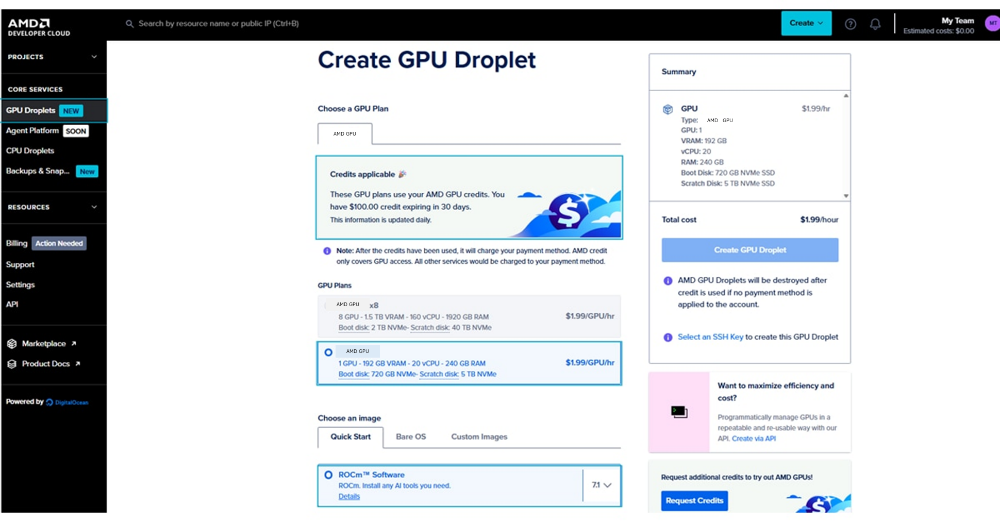
Figure 2: 在 AMD Developer Cloud 中创建GPU Droplet
Droplet 创建完成后,你可以:从本地终端通过 SSH 登录,或在控制台 UI 中点击Web Console按钮进入。
SSH 方式示例:
ssh root@<YOUR_DROPLET_IP>
使用vLLM 在AMD GPU上运行大模型
我们将使用vLLM 这个目前非常流行的LLM 推理框架来运行模型。下面的所有步骤,都需要在你上一节已经创建好的 Droplet 上完成。
Step 1:环境准备
示例使用Python虚拟环境 + pip搭建环境:
apt install python3.12-venvpython3 -m venv .venvsource .venv/bin/activate
然后安装ROCm 优化版本 vLLM:
pip install vllm==0.15.0+rocm700 --extra-index-url https://wheels.vllm.ai/rocm/0.15.0/rocm700
Step 2:开放端口并启动 vLLM
本例将通过vLLM 从 Hugging Face 拉取并部署一个适配 MiniMax-M2.1 的 pruned 模型。
首先,开放8090 端口,以便外部请求可以访问你的模型服务:
ufw allow 8090
接下来,在Droplet 上执行下面这条命令,从 HuggingFace 拉取经过剪枝的 MiniMax-M2.1 模型。该模型采用 FP8、参数规模约 139B,在 AMD GPU 的 192GB 显存中可以比较从容地完整加载并运行。
注意:将命令中的 abc-123 替换为你自定义的、随机且安全的 API Key。
VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve cerebras/MiniMax-M2.1-REAP-139B-A10B \ --served-model-name MiniMax-M2.1 \ --api-key abc-123 \ --port 8090 \ --enable-auto-tool-choice \ --tool-call-parser minimax_m2 \ --trust-remote-code \ --reasoning-parser minimax_m2_append_think \ --max-model-len 194000 \ --gpu-memory-utilization 0.99
这条命令将会:下载模型权重,将权重加载到AMD GPU 上,启动一个 OpenAI API 兼容的推理端点。
启动完成后,模型会通过如下URL 提供服务:http://:8090/v1
将OpenClaw 接入你的 vLLM 模型
接下来,我们把本地/ 浏览器里的OpenClaw配置为使用你刚刚部署的 vLLM 模型。
Step 1:安装 OpenClaw
如果还没有安装OpenClaw,可以在 Mac / Linux 上执行:
curl -fsSL https://openclaw.ai/install.sh | bash
安装过程中会有一个提示:“How do you want to hatch your bot?”,此时选择:“Open the Web UI”,然后根据提示在浏览器中打开OpenClaw Web 应用。
Step 2:配置 Provider(模型服务提供方)
在OpenClaw Web UI 中,进入:Settings → Config。新增一个模型 Provider,填写如下字段:
-
Name:vllm
-
API:选择openai-completions
-
API Key:填写前面 vLLM 启动命令中配置的 key(示例为 abc-123)
-
Base URL:http://:8090/v1
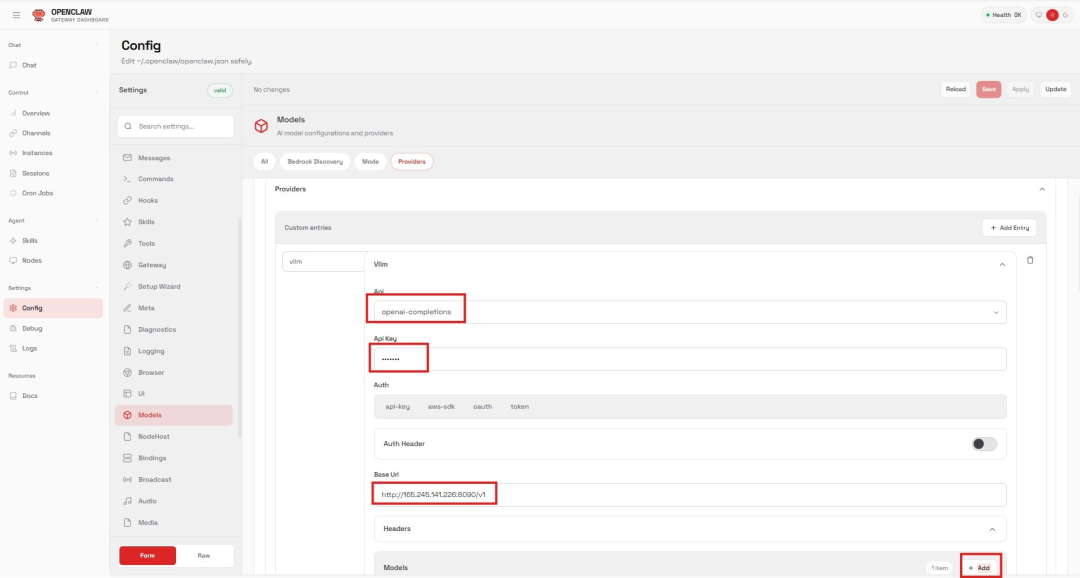
Figure 3: 在 OpenClaw 中配置 vLLM Provider
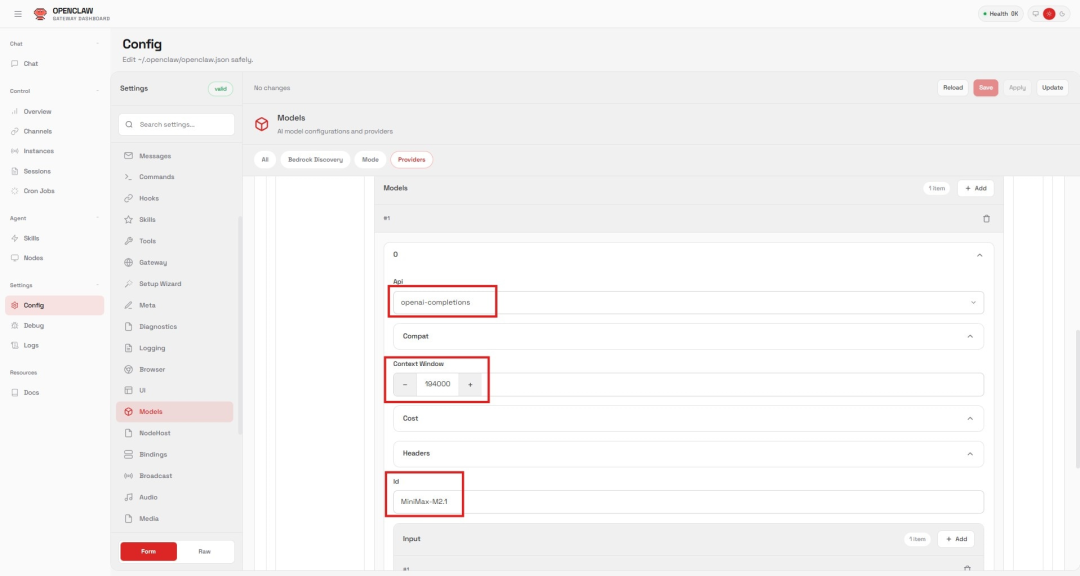
Figure 4:OpenClaw 中 MiniMax-M2.1 的模型定义
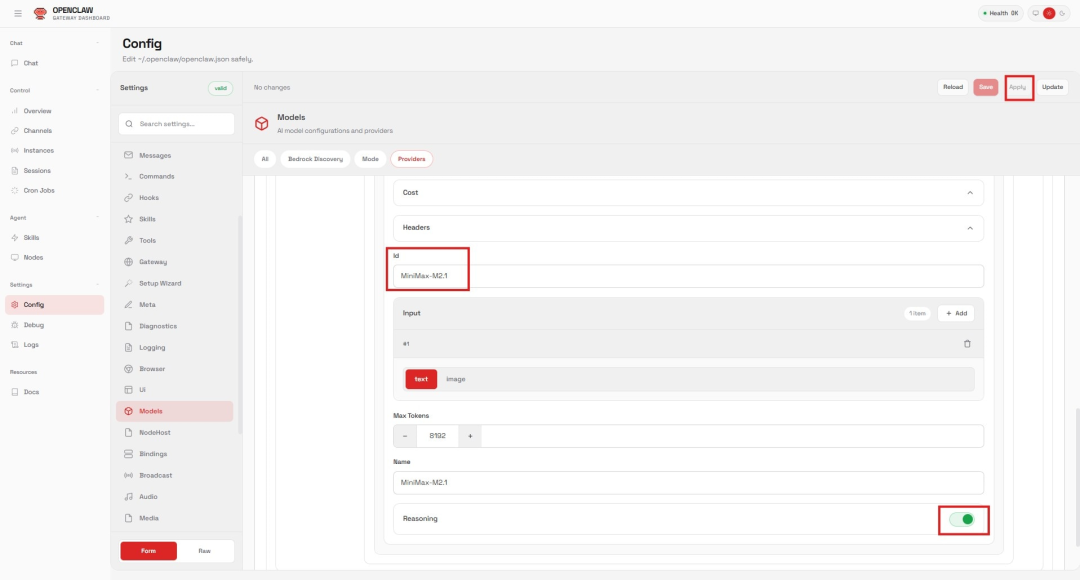
Figure 5:OpenClaw 中 MiniMax-M2.1 的模型 ID 与推理配置定义
Step 3:配置模型(Models)
接下来在OpenClaw 中定义具体模型信息:
1. 在 Models区域新增一条配置:
-
API:选择 openai-completions
-
Context Window:设置为 194000(需与max-model-len设置一致)
-
ID:设置为 MiniMax-M2.1(需与served-model-name设置一致)
2. 点击 Apply 保存。
Step 4:为 Agent 选择主模型
最后一步,将这个vLLM 模型绑定到你的主 Agent:
1. 进入 Agents 页面。
2. 将该 Agent 的 Primary Model设置为:vllm/MiniMax-M2.1(这个字符串由前面配置的Provider Name (vllm)和 Model ID (MiniMax-M2.1) 组合而成。
3. 点击Apply保存。
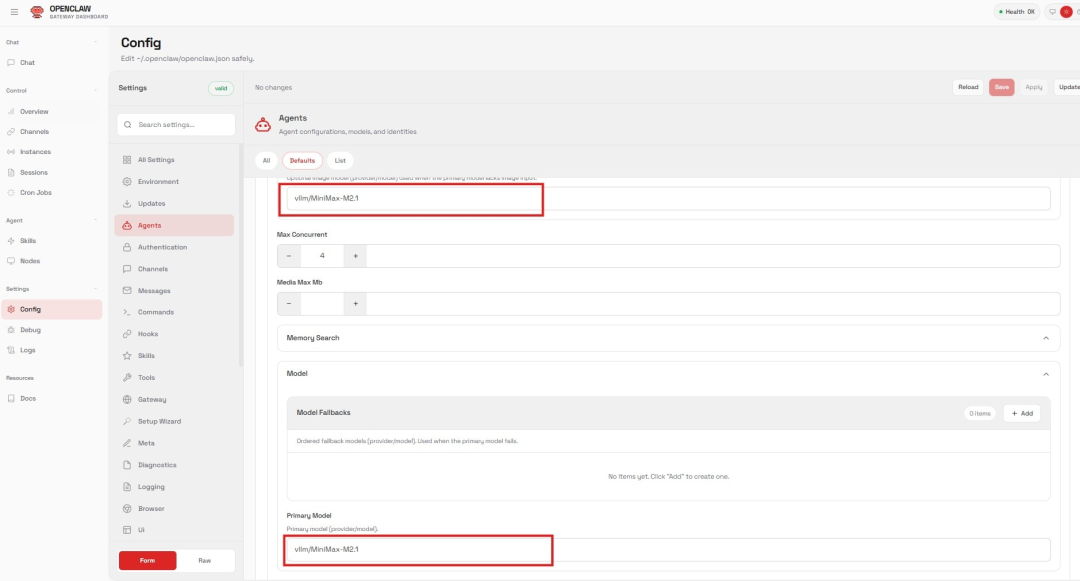
Figure 6: 在 OpenClaw 中为 Agent 选择 Primary Model
总结与下一步建议
至此,你已经完成了:
- 在 AMD Developer Cloud 上开通 AMD GPU 实例并激活免费额度;
- 使用 ROCm 优化 vLLM 在 AMD GPU上部署 MiniMax-M2.1-REAP-139B-A10B 模型;
- 将 OpenClaw 连接到这个 OpenAI 兼容的本地 / 远程模型服务端点。
现在,你可以在浏览器中,与运行在企业级GPU 上的 Agent 进行高上下文、高吞吐量的对话。
同样的流程也可以扩展到Hugging Face 上其他开源模型。
如果你在AMD 开发者云上做出有代表性的 Demo 或应用,不妨:
- 在社区、GitHub 或社交平台分享你的项目;
- 申请额外的免费 GPU 额度,持续优化和扩展你的智能体能力。
参考链接
[1] AMD AI 开发者计划(加入以获取免费额度等福利):
https://www.amd.com/en/developer/ai-dev-program.html?utm_source=referral&utm_medium=social&utm_campaign=mahdi-ghodsi&utm_content=adp-aig

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 4
4 0
0- 0


 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)