
Karpathy 想要的那个 LLM Wiki 产品来了,装一个 Skill 就能用
安装完之后,在这些编程工具里同样能操作有道云笔记,打通"写代码 / 写文章"和"知识管理"两个场景,后面的实测部分会演示这个场景。直到最近我用上了有道云笔记的 youdaonote-llm-wiki skill,把自己在这个号上发表过的文章整进了一个知识库,才意识到那个产品方向真的有人在落地了。,里面是 Anthropic 在多篇文章里被提及的内容汇总:公司背景、Claude 系列产品的更新记录、

微信收藏夹里躺着 100 多篇技术文章,每一篇收的时候都觉得有用,但大多数的下场是再也找不到。
想引用某个观点,得在收藏夹里用关键词翻半天,十有八九翻不出来。更别说"把这些文章串起来看趋势"了。
收藏夹是仓库,但不是知识库。它收得越多,就越显得乱。
4 月初 Karpathy 那条推文提出了"LLM Wiki"的想法,我在之前的文章里有过介绍,这里不重复展开。Karpathy 把他的实现整理成了一份 idea file,末尾留了这么一句:
“"I think there is room for an incredible new product instead of a hacky collection of scripts."
他的意思是:这套思路值得有人做成一个真正的产品,而不是一堆脚本凑出来的临时方案。
当时社区跑出来的回应,大多是 MCP server 集成、语义搜索扩展、Git provenance 追踪之类的方案,仍然是极客向。普通人想跟着做,门槛挺高。
直到最近我用上了有道云笔记的 youdaonote-llm-wiki skill,把自己在这个号上发表过的文章整进了一个知识库,才意识到那个产品方向真的有人在落地了。这篇文章就是这次实测的全程记录。
LLM Wiki 解决的是什么问题
先把问题说清楚,再看产品做了什么。
传统 RAG 是按问检索。 你提问,系统就去你的资料堆里翻,把相关片段抓出来拼进上下文,再回答你。每次提问都从头检索,资料本身不会被整理,也不会互相建立连接。
LLM Wiki 的核心是"编译知识"。 素材进来一次,LLM 就处理一次:提取实体(公司、产品、人物),归纳概念,建立跨文档的引用关系,生成一套结构化的 Wiki 页面。之后提问,LLM 查的是自己整理好的 Wiki,不是原始文档堆。知识被"压缩"进了有组织的结构里,查起来既快又准。
Karpathy 把这个工作流拆成了四个操作:
-
Ingest(摄入):有新资料来,增量处理,更新相关 Wiki 页面,维护内部链接,不需要重建整个知识库
-
Query(查询):跨多个页面综合回答问题,带引用来源,两份资料有矛盾时自动标出
-
Archive(归档):有价值的查询结论存回知识库,越用越丰富
-
Lint(健康度审计):定期检查是否有过时内容、孤立页面、应建未建的连接
知识在这个模式下不是"记完就死",每次提问都在给知识库注入新的东西。
但 Karpathy 当时的实现是本地 Markdown 文件加上自己写的一堆脚本。他自己也承认是"hacky collection of scripts"。想跟着做,有开发能力的可以,非技术背景的人几乎进不来。
主角:有道云笔记 + youdaonote-llm-wiki skill
这套方案的两个核心:
-
有道云笔记:知识库的存储层,手机、桌面、网页、iPad 全端同步,Wiki 页面在所有设备上都能打开
-
youdaonote-llm-wiki skill:把 LLM Wiki 方法论封装成即用插件,在支持的 AI 对话工具里一句话触发
youdaonote-llm-wiki skill 支持在 LobsterAI(有道龙虾)、OpenClaw、QClaw、WorkBuddy、EasyClaw 等主流龙虾 AI Agent 里运行,也支持 Cursor、Claude Code 等编程工具(后面会演示)。本文演示选的是有道龙虾,之前用过一段时间,操作也很顺手。
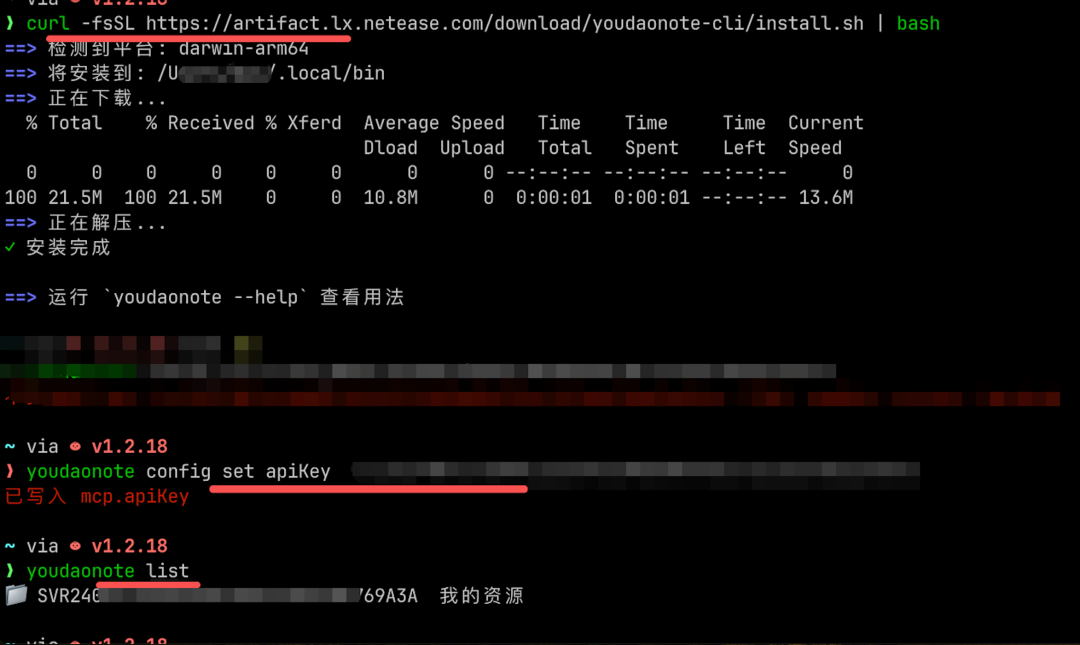
前置步骤:配置有道云笔记 CLI
youdaonote-llm-wiki skill 读写有道云笔记,底层依赖的是 YoudaoNote CLI。用 Skill 之前,需要在本机安装 CLI 并绑定账号 API Key,这是读写权限的基础层。
官方有完整的安装指南:https://note.youdao.com/help-center/cli-install-guide.html
macOS / Linux 照着跑一行安装脚本,Windows 手动下载可执行文件加进 PATH,之后在 MCP Console 里拿到 API Key 配置上。跑 youdaonote list 能看到你的笔记列表,说明配置完成。
Node.js 开发者对这种流程应该很熟悉,5 分钟以内。
在哪里找到这个 Skill
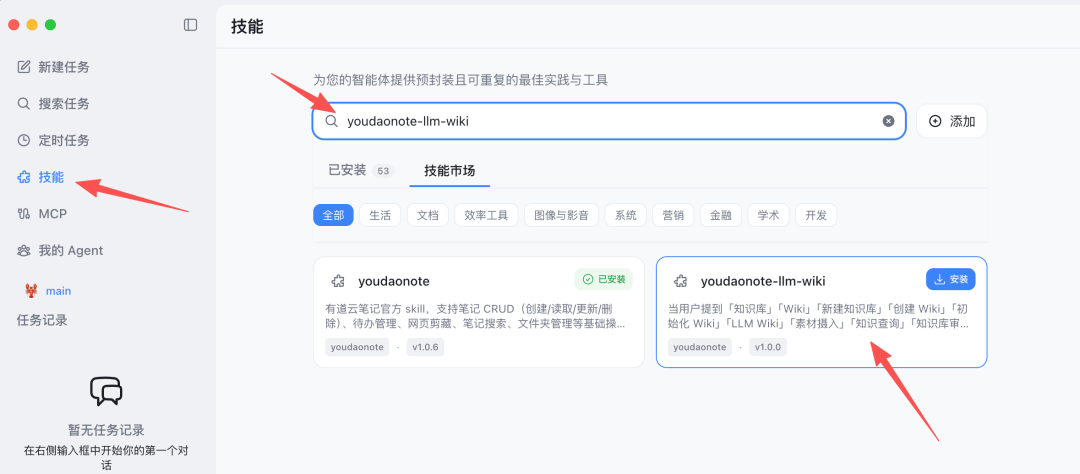
主路径走有道龙虾的技能市场:
-
官网下载安装有道龙虾客户端
-
打开龙虾,进入【技能市场】
-
搜索框里输入
youdaonote-llm-wiki -
找到 Skill 卡片,一键安装
-
在对话框里说"帮我创建知识库"即可触发
除了龙虾之外,youdaonote skill 还支持直接安装到 Codex、Claude Code、Cursor 等 40+ AI 编程工具里。安装完之后,在这些编程工具里同样能操作有道云笔记,打通"写代码 / 写文章"和"知识管理"两个场景,后面的实测部分会演示这个场景。
Skill 自动建出什么
对话里说"帮我创建一个知识库",Agent 会在有道云笔记里自动建出:
-
一个根文件夹(知识库名)
-
五个子目录:
raw/(原始素材)、entities/(人物 / 组织 / 产品)、concepts/(概念)、comparisons/(对比页)、queries/(查询历史) -
三个系统笔记:
schema.md(结构定义)、index.md(索引)、log.md(变更日志)
这套结构是 Karpathy 在 Gist 里描述的架构,Skill 帮你完全自动建好,不需要自己维护目录。
多库管理也支持:按主题建多个独立库,一句话切换,全部登记在全局注册表里由 Agent 自动维护。
四个核心操作的产品化
-
Ingest:扔一篇文章、一个链接或一整个本地文件夹,Agent 抓内容、抽实体、建概念、连引用,全自动,每次都是增量,不重建全库
-
Query:跨多个页面综合回答问题,带来源引用,遇到矛盾用 ⚠️ 标记
-
Archive:有价值的对话结论一句话存回知识库
-
Lint:定期审计健康度,找过时信息、孤立页面、应建未建的连接
实测:把发表过的文章整合成「公众号知识库」
下面是完整的实测过程。素材是我在这个号上发表过的一批技术资讯类文章,存成 Markdown 格式放在本地文件夹里,主题围绕 AI 编程工具、Node.js 生态和前端工具链。
一句话建库,自动开始 ingest
打开龙虾,对话框里输入:
“"我在 Nodejs技术栈 发表了不少技术资讯文章,已经存成 Markdown,文件都在桌面的 /Users/xxxxx/Desktop/llm-wiki-demo/notes/ 目录下。帮我创建一个知识库,库名就叫「公众号知识库」,主题是把这些文章沉淀成结构化知识。"
Agent 读取目录之后,先给了一个建议:用英文库名 wechat-article-wiki,英文名更稳定。接受即可。
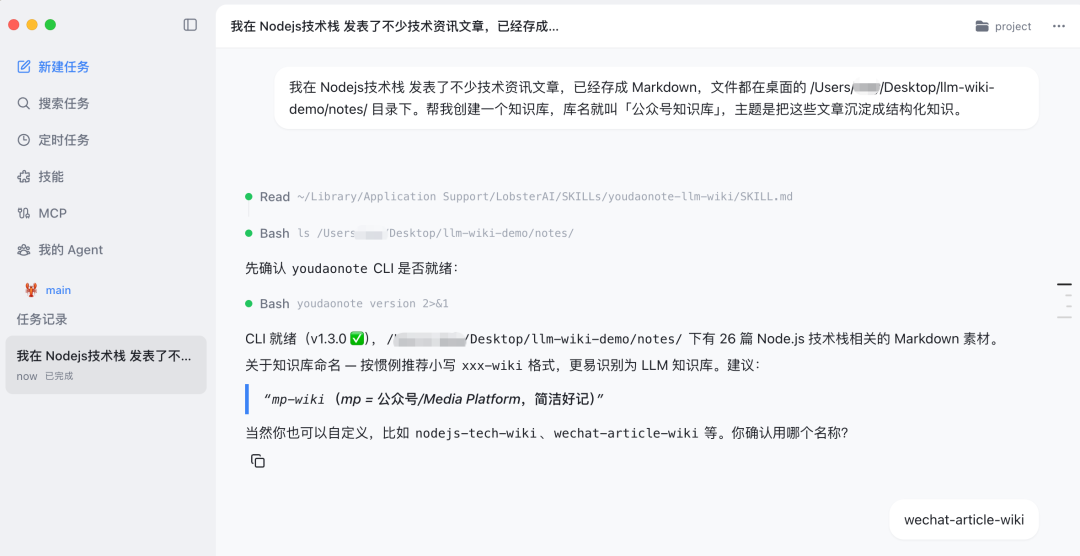
确认之后,Agent 直接开始 ingest,不需要再发第二条指令。26 篇文章自动处理,entities 和 concepts 页面陆续出现。

等 Agent 处理完,切到有道云笔记,wechat-article-wiki 文件夹已经建好了,五个子目录、三个系统笔记全在。
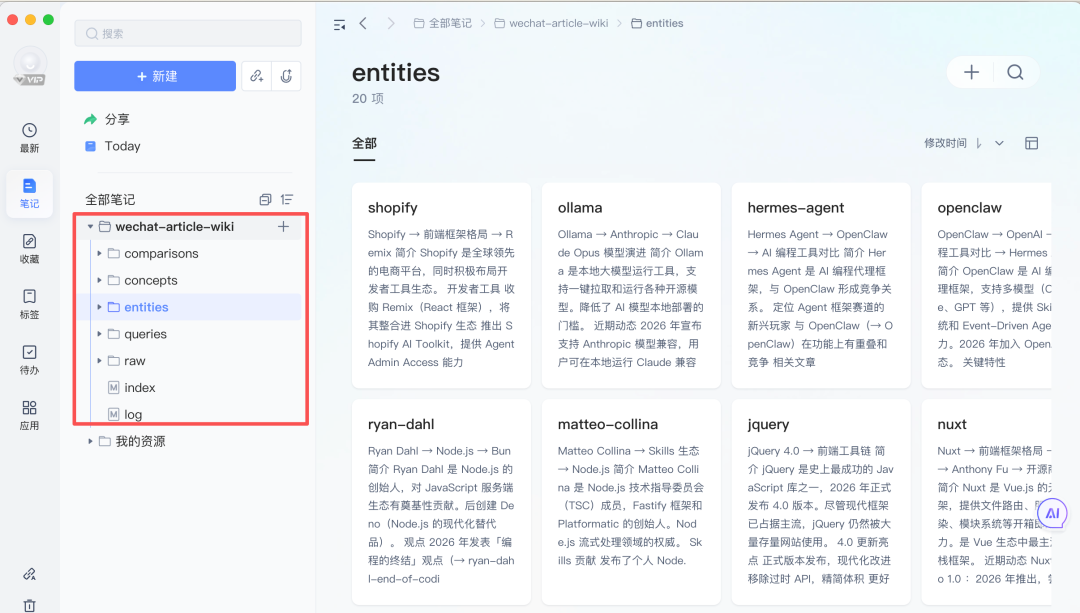
看自动建出来的东西(这是最有冲击感的一幕)
打开 entities/companies/anthropic.md,里面是 Anthropic 在多篇文章里被提及的内容汇总:公司背景、Claude 系列产品的更新记录、相关事件引用,不同文章里的信息整合在同一个页面,还有反向链接标注每条内容来自哪篇原文。
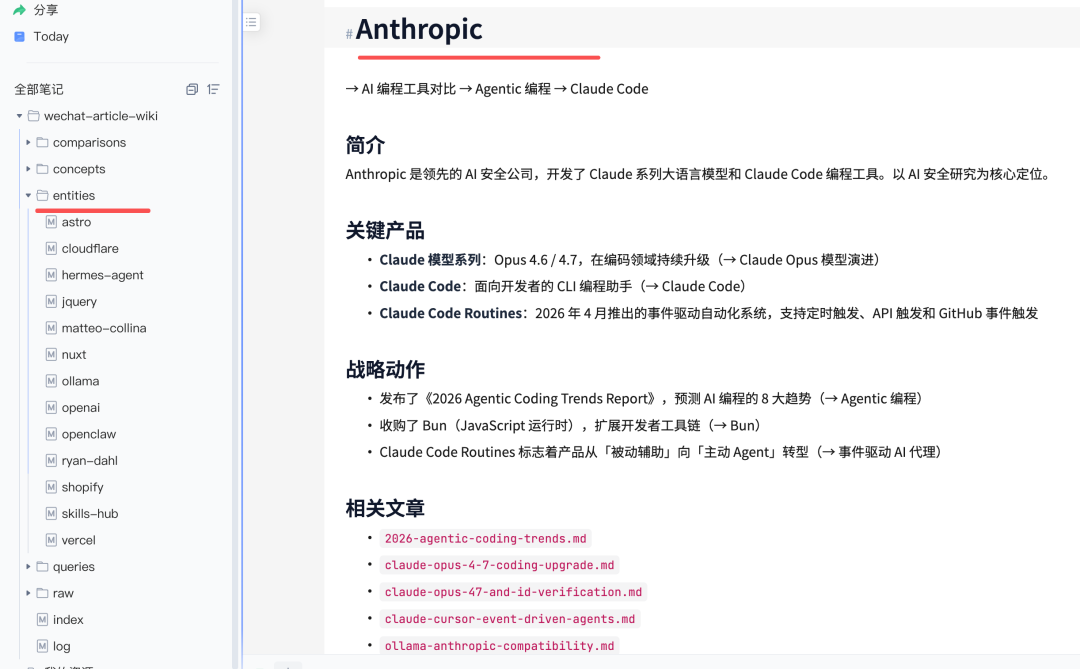
打开 concepts/skills.md,这是被引用次数最多的概念之一。页面里列出了多位开发者和多个框架各自发布 Skills 时的核心动作,每条引用标明来自哪篇文章。
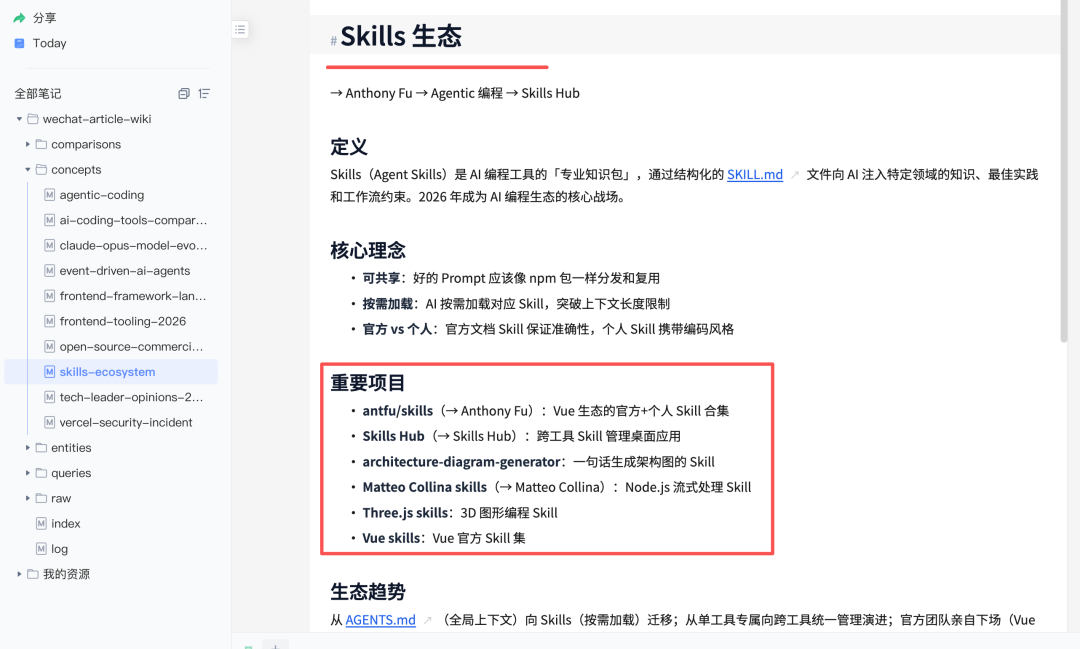
一个文件夹的文章,经过 Agent 处理之后,变成了一张相互连通的知识网。这是整个工具最有价值的地方:不是"存了多少",是"建立了多少连接"。
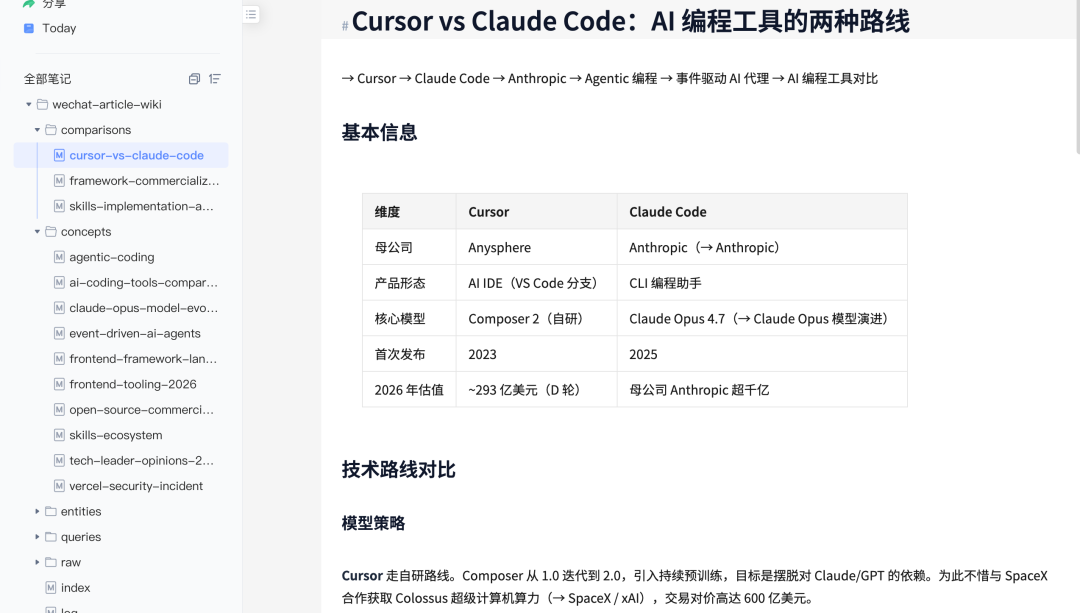
comparisons/ 目录初始是空的,需要手动触发一句指令。说"帮我生成这批文章里 AI 编程工具之间的对比页"之后,有道云笔记里立刻出现了对应内容,实测生成了 Claude Code vs Cursor 的横向对比页。

跨页综合查询
知识库建完之后,可以用它来回答跨多篇文章的问题。我问的是:
“"在 wechat-article-wiki 里,帮我综合一下:基于这批文章,2026 年 AI 编程工具领域有哪些关键趋势?请基于知识库里的内容回答,并标明引用来源。"
Agent 从 index.md 定位相关页面,跨 concepts、entities、comparisons 综合生成回答,每个观点标了来自哪个 Wiki 页面,两份资料有矛盾的地方用 ⚠️ 标出。

这种回答不是随口说的,是有出处的。之后一句话把结论存进 queries/:
“"把刚才这个回答存到 wechat-article-wiki 的 queries/ 里。"
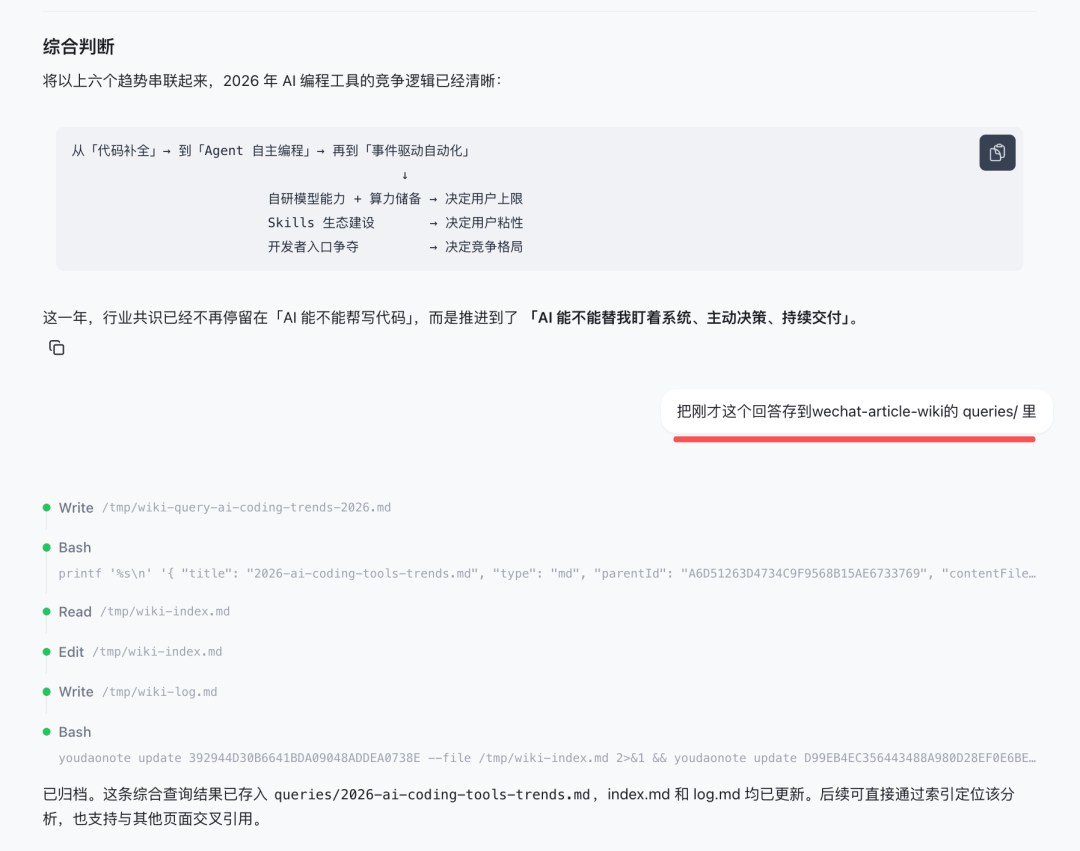
每次有价值的查询归档一次,知识库越问越丰富。Karpathy 说的"知识复利"就是这么滚起来的。
在 AI 编程工具里同步新文章
这是我觉得整个方案里最顺手的一个环节。
youdaonote skill 不只能装在龙虾里,还支持直接安装到 Codex、Claude Code、Cursor 等 40+ AI 编程工具。安装方式:下载 skill 到本地,用 npx skills add 安装,或者通过 skills-hub 这类 GUI 工具管理(skills-hub 是我自己开发的 skill 管理工具,一次安装覆盖多个 AI 编程工具)。官方的安装指南在这里:https://note.youdao.com/help-center/skill-install-guide.html
我用 skills-hub 把 youdaonote skill 装好,重启 Codex 之后就能直接用。
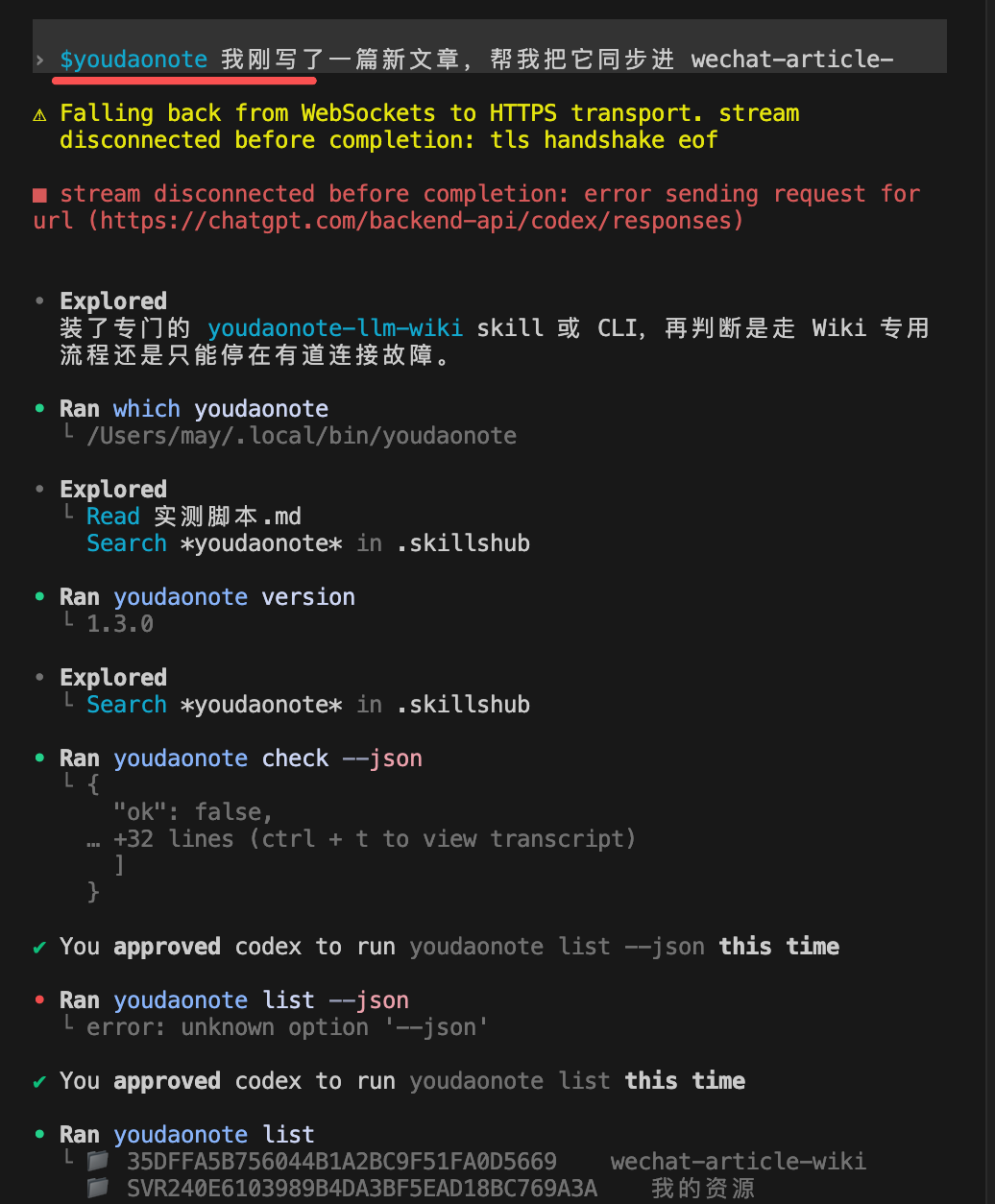
写完一篇新文章,不需要切到龙虾,直接在 Codex 对话里说"把这篇新文章同步进 wechat-article-wiki",有道云笔记里立刻出现对应更新。
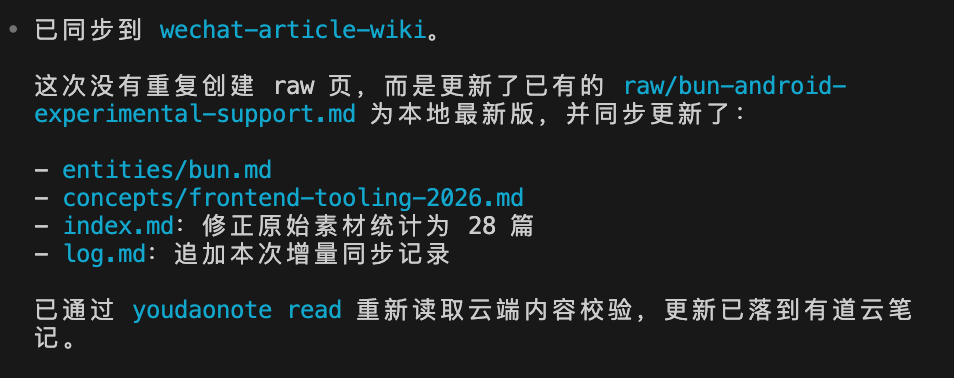

写完文章,在编程工具里一句话同步,知识库跟着输出一起成长,全程不需要切换应用。
和 Karpathy 原方案的差异
两套方案的思路完全一致,区别在落地层面。
|
维度 |
Karpathy 原方案 |
youdaonote-llm-wiki 方案 |
|---|---|---|
|
存储位置 |
本地 Markdown 文件 |
云端笔记,多端同步 |
|
查看方式 |
本地编辑器 |
手机 / 桌面 / 网页 / iPad 任意端 |
|
搭建成本 |
自己写脚本、配置提示词 |
装 Skill,对话即用 |
|
维护方 |
自己维护脚本和提示词版本 |
Skill 迭代升级,跟着用就行 |
|
适合人群 |
有动手能力的极客 |
任何想做知识沉淀的人 |
值得说清楚:Karpathy 的方案没有问题,它是为有能力自己搭系统的人设计的,极客向本来就是它的定位。youdaonote-llm-wiki 做的不是"比他更好",而是把同样的方法论转化成了不需要写代码就能用的形式。
Karpathy 那句话说的是"需要一个真正的产品",有道团队做的正是这件事。
这套方法谁能用上
覆盖的场景比我想象的要广:
-
有公众号或博客,想把写过的文章沉淀成可检索、可综合的知识库的人
-
收藏夹里躺着几百篇技术文章、总想"以后系统整理"但一直没整理的人
-
持续跟踪某个技术方向(AI 编程工具、Node.js 生态、前端工程化)的开发者
-
在学某个新框架,想边看边做结构化笔记的人
核心判断是:只要你有持续产出或持续收集的资料,而且想对这些资料做汇总、对比、趋势分析,这套方案就值得试。
Karpathy 说他最近的工作时间,大部分从"操纵代码"转向了"操纵知识"。当 Agent 足够强、产品打磨足够细,知识工作的关键就不再是"会不会整理",而是"会不会问、会不会追问"。
你的收藏夹,可以从"以后再看"变成"以后能用上"。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 7
7 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)