
TR-C | 同济&新国立:基于多智能体强化学习的大规模计划运营车辆准点性导向交通信号控制
基准方法包括:固定配时(FT)、最大压力(MP)、主动公交优先(ATSP)、仅考虑效率的PressLight(PL)、仅使用SV信息(Only‑SV)、固定SV观测维度(Fixed‑SV)仿真在网格网络和真实路网(中国钦州)中进行,结果表明:与多种基准方法(固定配时、最大压力控制、传统公交优先等)相比,本方法显著提升了SV的准点率(在60秒延误内到达的比例超过78%),同时。,使每个交叉口智能体能

由于微信推送机制改版,是不是经常看不到论文推送啦?
如果你也在做交通+机器学习相关研究,别再让优质论文分享从指尖溜走了。
👉给「交通遇上机器学习」点个⭐️星标
第一时间获取最新论文解读、前沿方向,不再错过任何一次灵感碰撞。
把时间留给真正有价值的内容,我们帮你筛选好。

导读
提升准点到达率是公共交通、货运及预约出行等计划车辆(SVs)运营的核心诉求。然而,现有信号优先控制多面向少量公交车,难以应对大规模、多线路、动态到达的SVs优先请求冲突。本文提出一种基于多智能体强化学习(MARL)的信号控制框架,创新性地引入基于剩余距离的优先级分配机制和Transformer特征提取器,使每个交叉口智能体能够实时处理可变维度的SV观测信息,并在兼顾整体交通效率的前提下,为临近目的地的SV提供更精准的优先权。仿真表明,该方法在大规模SV场景下显著改善了准点率,同时甚至降低了普通车辆的平均延误。


1
基本信息
标题:Schedule adherence oriented traffic signal control for large-scale scheduled vehicle operations: A multi-agent reinforcement learning approach
期刊:Transportation Research Part C
作者:Jichen Zhu, Qiqing Wang, Kaidi Yang, Xiaoguang Yang
单位:同济大学、新加坡国立大学
关键词:Traffic signal control; Scheduled vehicles; Travel time reliability; Schedule adherence; Multi-agent reinforcement learning
发表时间:2026 年 5 月

2
研究动机
-
规模挑战:现有SV优先控制(如公交信号优先TSP)主要针对少量公交车,无法处理大规模、多线路、并发优先请求的场景(如数十辆网约车同时接近不同路口)。下图展示了这种多SV并存的复杂情况。
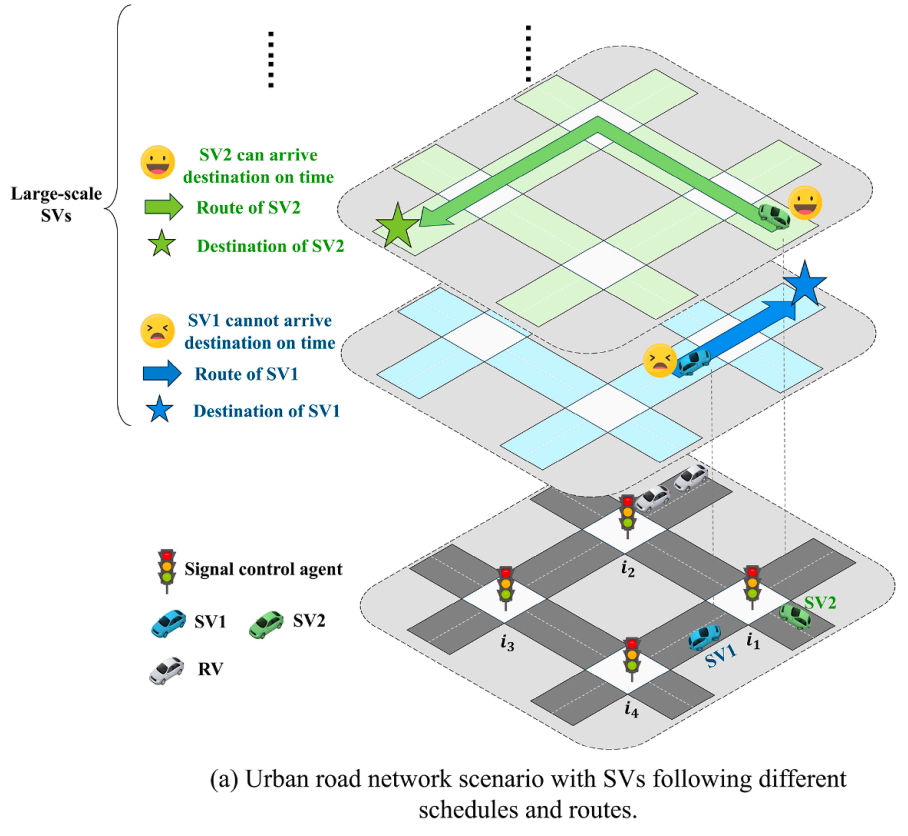
-
动态维度:SV数量随时间动态变化(到达、离去),传统的固定维度观测空间无法适应,导致信息丢失或模型失效。
-
优先级策略缺陷:多数方法无条件对所有延误SV给予优先,忽视了不同SV的剩余行程长度。远距离的SV即便被短暂延迟,下游仍有充足时间补偿;近距离的SV则几乎无补偿机会。不加区分地优先会造成绿灯资源浪费,损害整体通行效率。下图示意了这种需策略性分配优先的场景。
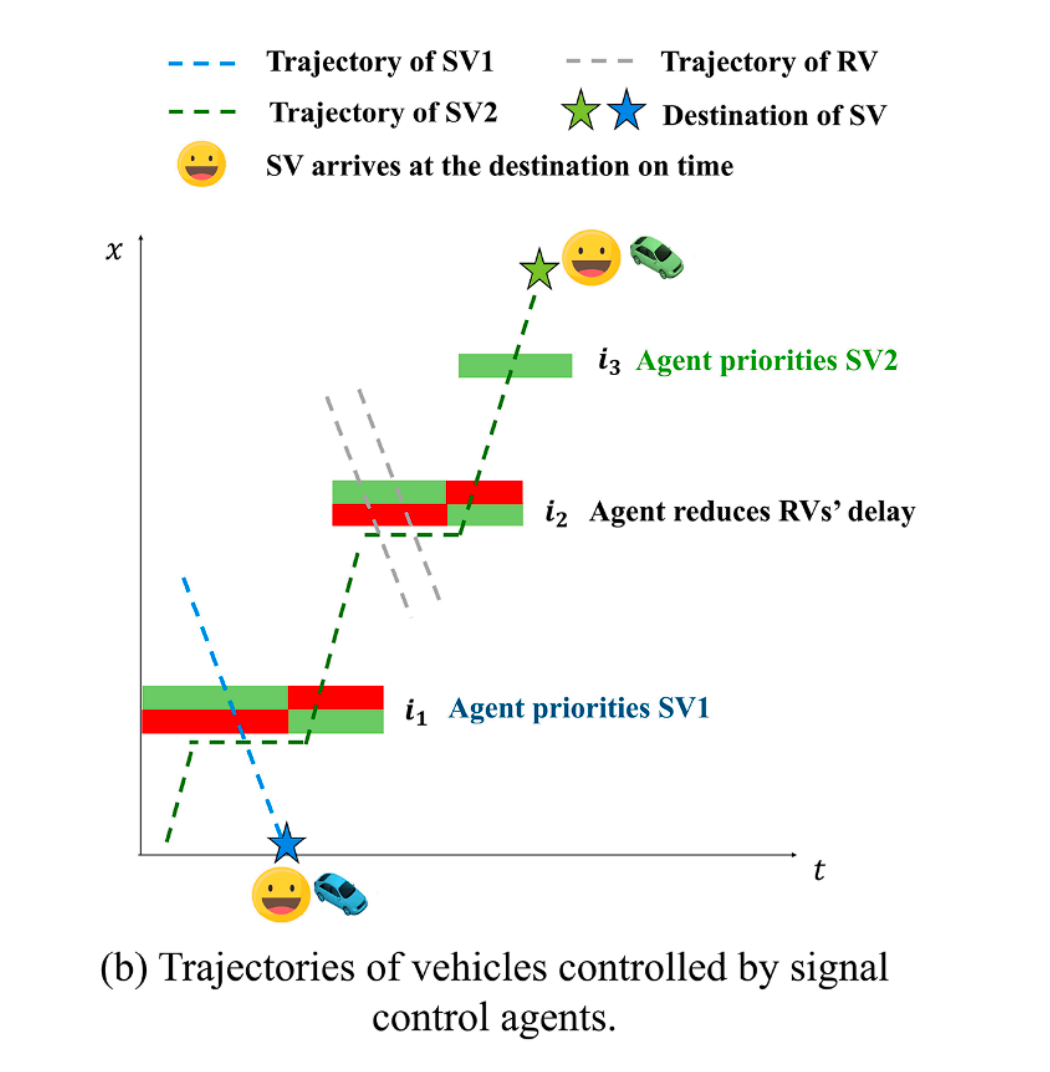
-
现有MARL局限:已有部分MARL信号控制考虑了SV,但要么假设固定数量SV,要么只关注少数高优先级车辆,且未将远期目的地信息纳入决策,无法实现前瞻性的协调。

3
核心创新点
1、方法创新:基于剩余距离的优先级分配机制
将SV的优先级定义为 Pro = SD / (RI+1),其中SD为当前时刻的时刻表偏差(即预计延误),RI为剩余交叉口数量。该机制使接近目的地的SV获得更高优先权,而远离目的地的SV可被暂时延迟,因为下游仍有补偿机会。这避免了传统方法对所有SV无条件优先导致的资源浪费。
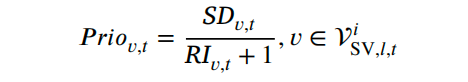
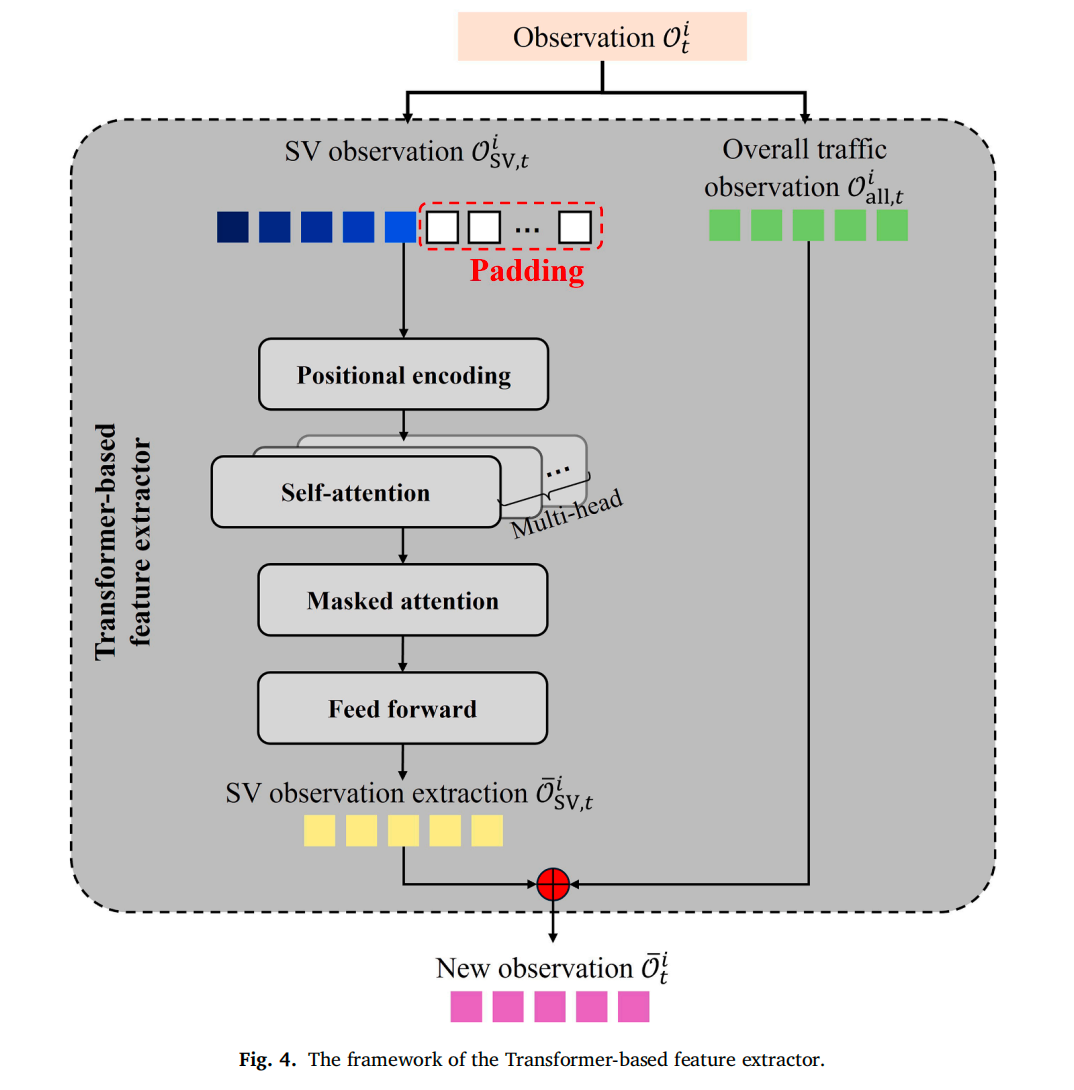
2、结构创新:Transformer特征提取器处理可变维度观测
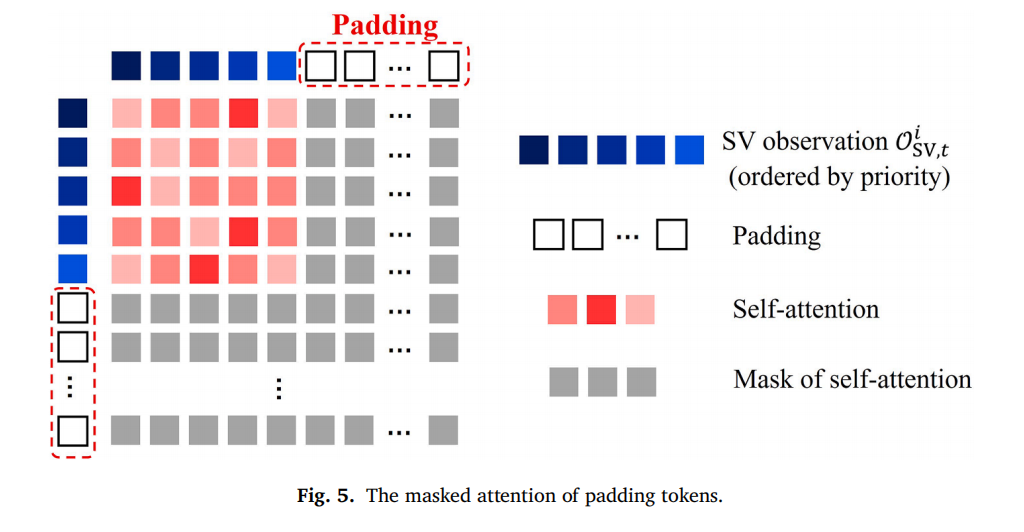
由于SV数量动态变化,常规固定输入维度的强化学习无法适用。本文采用Transformer编码器,通过padding(补零)和自注意力掩码机制,使模型能够处理任意数量的SV输入,并自动关注高优先级的SV。该模块与Actor‑Critic网络端到端联合训练。
3、奖励设计创新:距离加权的SV奖励
奖励函数中SV部分为 ∑ (SD_before - SD_after) / (RI+1)。分子反映当前信号决策对时刻表延误的边际改善;分母的1/(RI+1)确保越接近目的地的SV对奖励的贡献越大。该设计使智能体自动学会“上游适度延迟、下游优先保障”的策略,实现SV准点率与整体通行效率的帕累托改进。
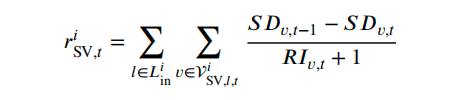

4
论文摘要
行程时间可靠性对于按照预定时刻表运行的计划车辆至关重要。随着网约车、配送卡车、预约出行等SVs在城市路网中日益普及,如何通过交通信号控制保障其准点率成为关键挑战。现有研究多集中于少数公交车的优先控制,难以应对大规模、动态到达且请求可能冲突的SV场景。本文提出一种多智能体强化学习框架,每个交叉口作为一个智能体,通过局部观测学习协调策略。我们设计了一个基于剩余距离的优先级指标,使接近目的地的SV获得更高优先权;并采用Transformer特征提取器处理可变长度的SV观测序列。仿真在网格网络和真实路网(中国钦州)中进行,结果表明:与多种基准方法(固定配时、最大压力控制、传统公交优先等)相比,本方法显著提升了SV的准点率(在60秒延误内到达的比例超过78%),同时降低了普通车辆的平均延误(在真实路网中降低16.2%)。敏感性分析验证了方法在SV渗透率、需求因子、需求不均衡程度及ETA预测噪声下的鲁棒性。

5
研究方法
POMDP建模
-
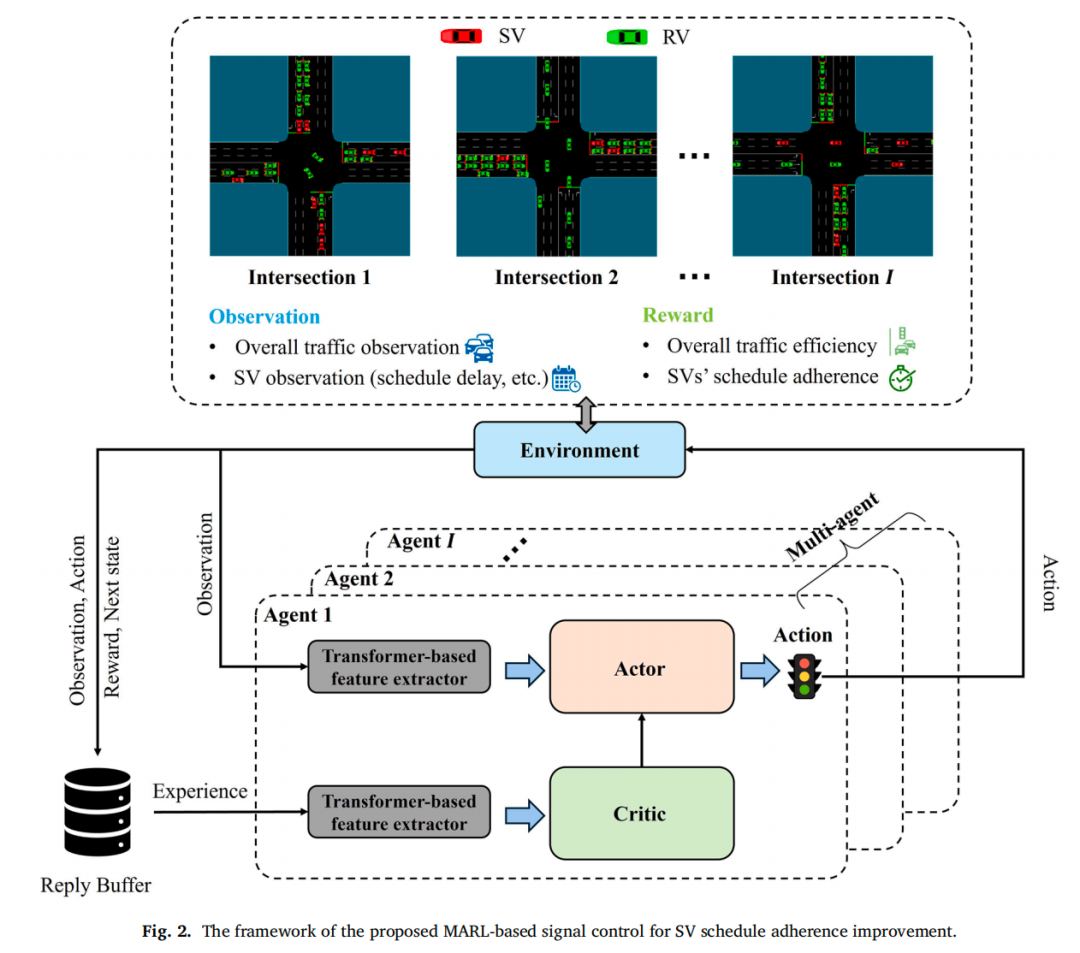
观测空间:每个智能体的观测包含两部分:① 整体交通观测(当前相位、各车道排队长度等);② SV观测(每条进口道上的SV列表,每个SV包含优先级Pro和到停车线距离x)。SV列表长度动态变化 → 引出Transformer。
-
动作空间:每个交叉口有4个相位(东西直行、东西左转、南北直行、南北左转)。智能体可保持当前相位(延长Δt)或切换到另一相位(插入3秒黄灯),受最小/最大绿灯时间约束。
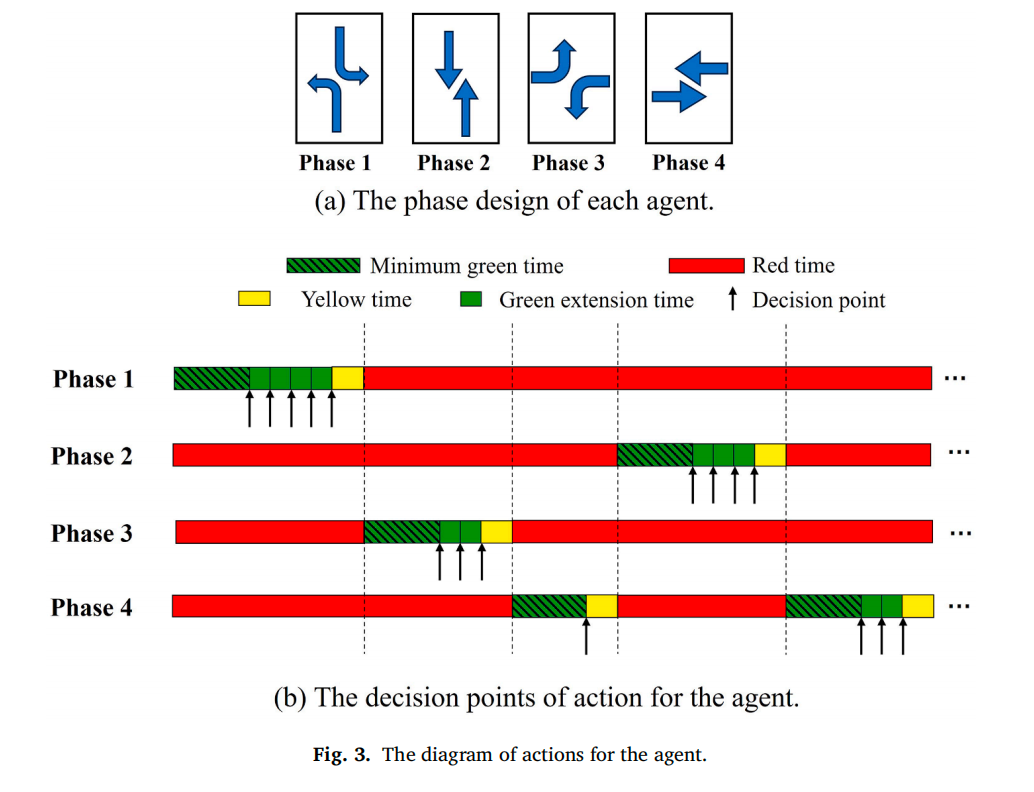
-
奖励函数:总奖励 = ω * 整体交通奖励 + (1-ω) * SV奖励。整体交通奖励采用压力(Pressure)定义(Eq. 3-4),促使各车道负载均衡。SV奖励如创新点3所述,强调边际改善和距离加权。
Transformer特征提取器
-
将所有进口道的SV列表拼接后,补零至固定最大长度,并添加位置编码。
-
通过多头自注意力计算,其中掩码(M_pad)确保补零位置不参与注意力计算。
-
输出固定维度的SV特征表示,与整体交通观测拼接后送入Actor‑Critic网络。
端到端学习框架
-
采用Soft Actor‑Critic (SAC) 算法,因其在处理连续/离散混合动作及探索‑利用平衡方面表现优异。
-
Transformer提取器的参数与Actor/Critic网络的参数联合优化,目标是最小化SV时刻表延误并降低整体拥堵。
-
每个智能体独立训练(分散式学习),但通过压力奖励隐含地实现了邻近交叉口的协调。


6
实验结果
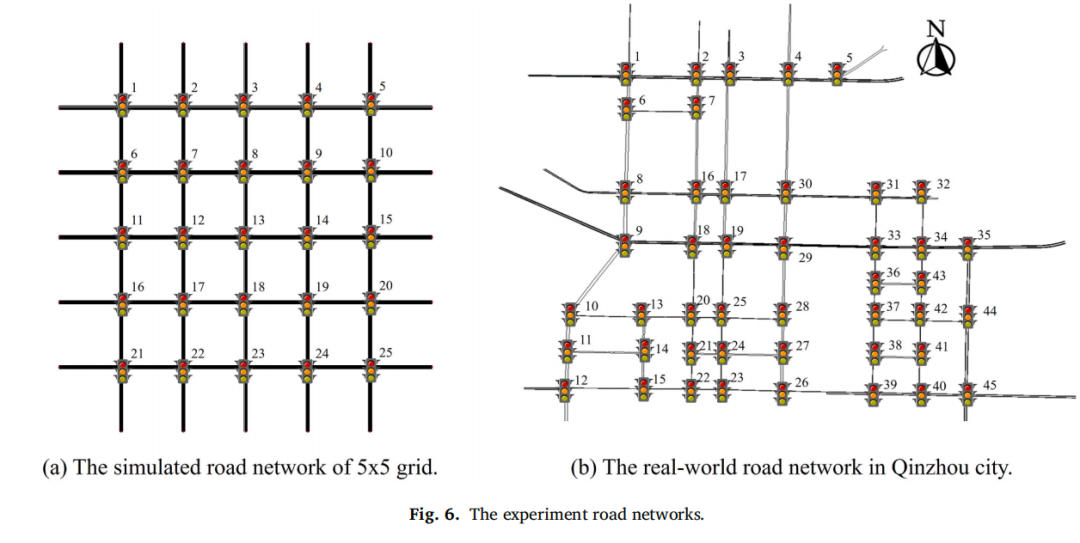
实验设置
使用SUMO仿真。网络①为5×5网格网络(图6a),网络②为中国钦州市真实路网(图6b,45个信号交叉口)。SV的预定到达时间基于最大压力控制下的平均行程时间加上随机扰动([-180s, 60s])生成,使大多数SV初始即晚点。基准方法包括:固定配时(FT)、最大压力(MP)、主动公交优先(ATSP)、仅考虑效率的PressLight(PL)、仅使用SV信息(Only‑SV)、固定SV观测维度(Fixed‑SV)
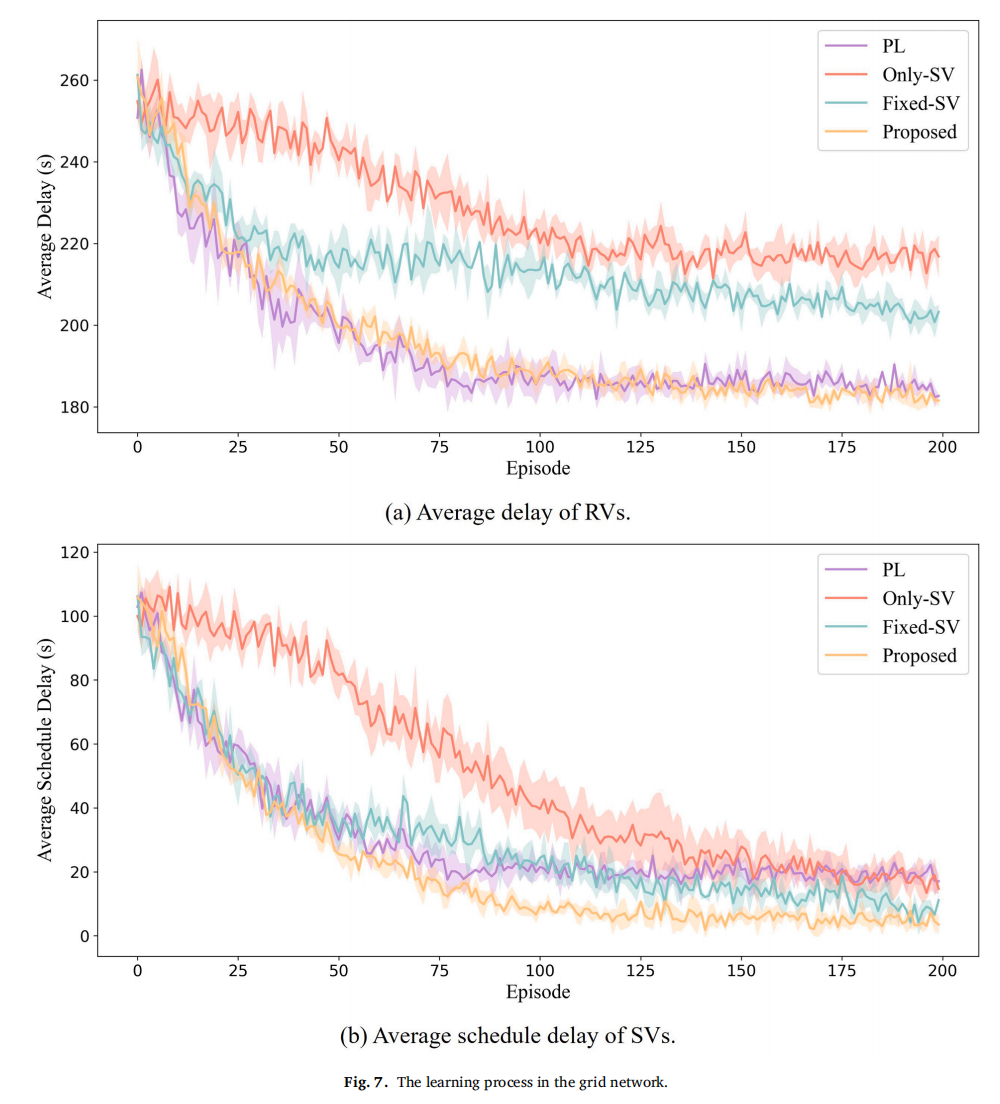
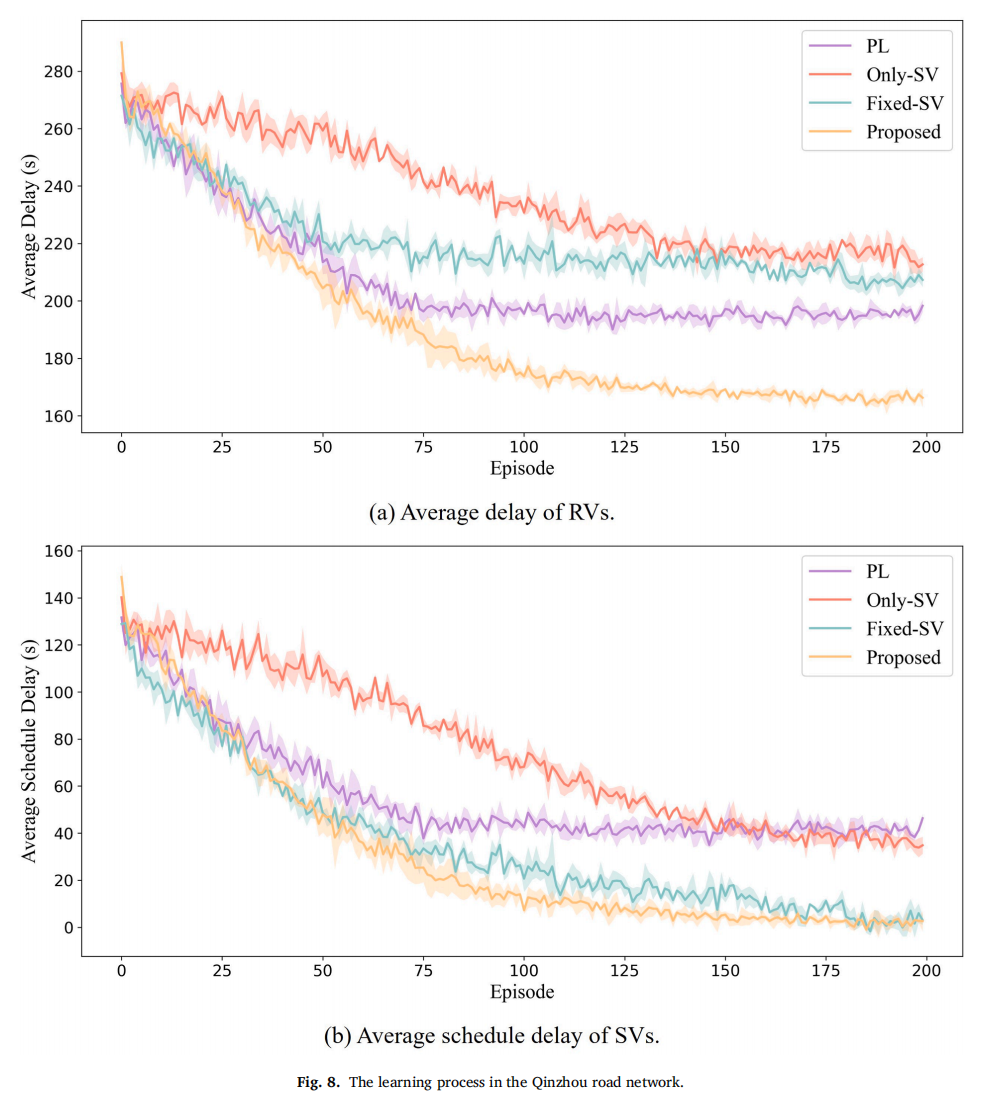
训练过程
在网格网络和钦州路网中,本方法收敛速度与Fixed‑SV、Only‑SV相近(约150回合后稳定),略慢于PL(100回合),但最终获得了最低的RV平均延误和最低的SV平均时刻表延误。相比Fixed‑SV,证明Transformer动态观测的有效性;相比Only‑SV,证明兼顾整体效率的必要性。
性能对比
-
CDF曲线:本方法的SV延误累积分布显著左移,在网格网络中78.69%的SV在60秒内到达(Table 2),远超FT(52.34%)和MP(50.09%)。
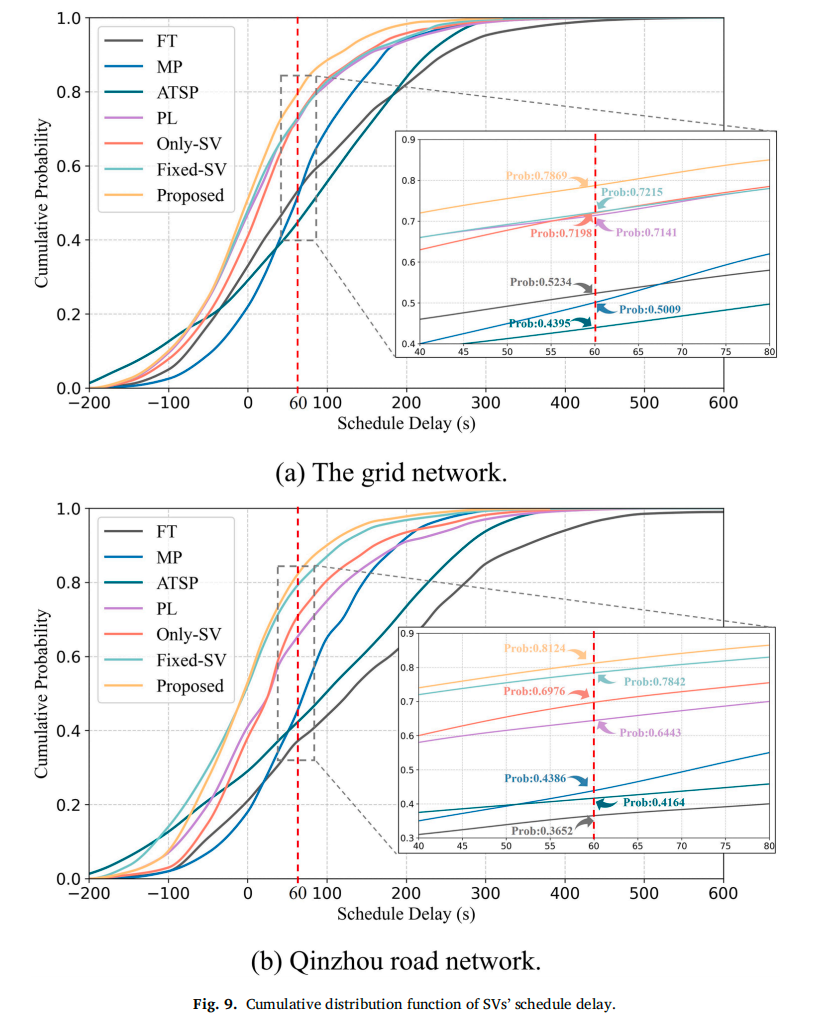
-
平均延误:在钦州路网中,本方法使RV平均延误从PL的210.06s降至176.00s(降低16.2%),SV平均时刻表延误从PL的30.66s(晚点)变为-5.93s(即平均提前到达)。这表明合理优先不仅不牺牲整体效率,反而通过缓解拥堵间接惠及所有车辆。
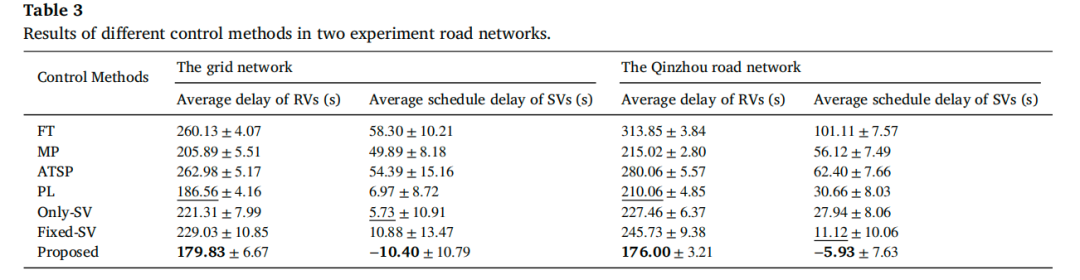
-
路径延误演变:远距离SV在初始交叉口可能经历较大延误(如Route 3在Intersection 1延误约250s),但随着剩余交叉口数量减少,延误逐步被补偿,到终点时已基本准点。这验证了距离加权奖励的设计意图。
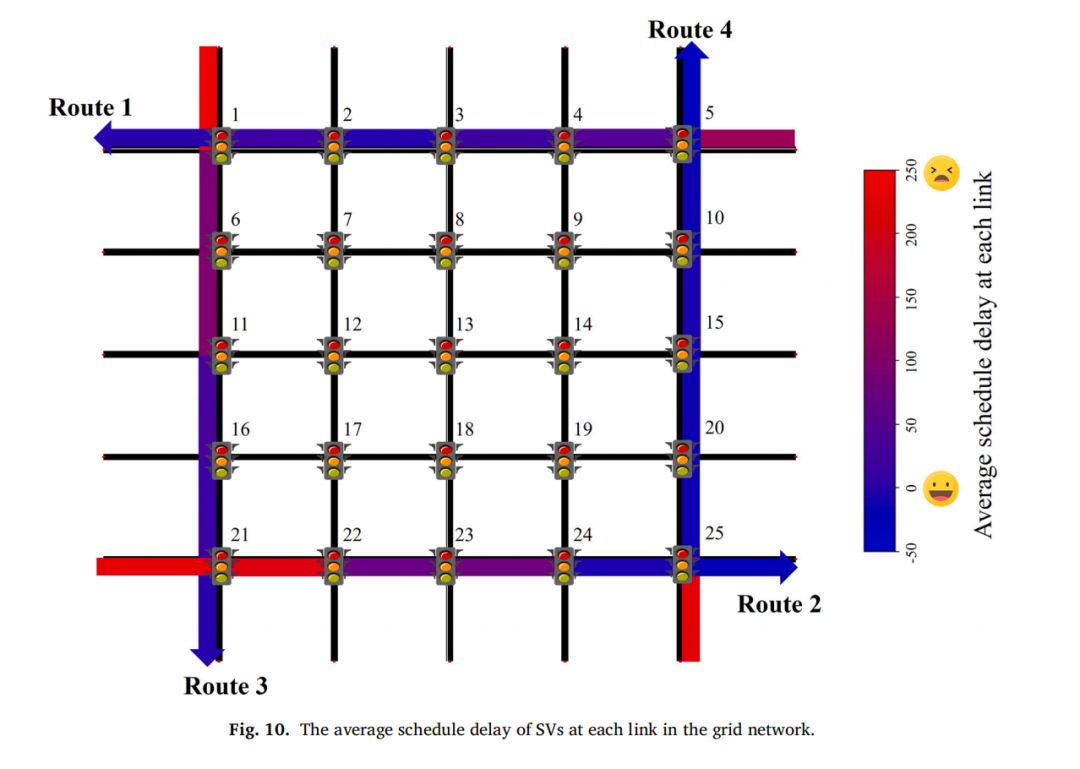
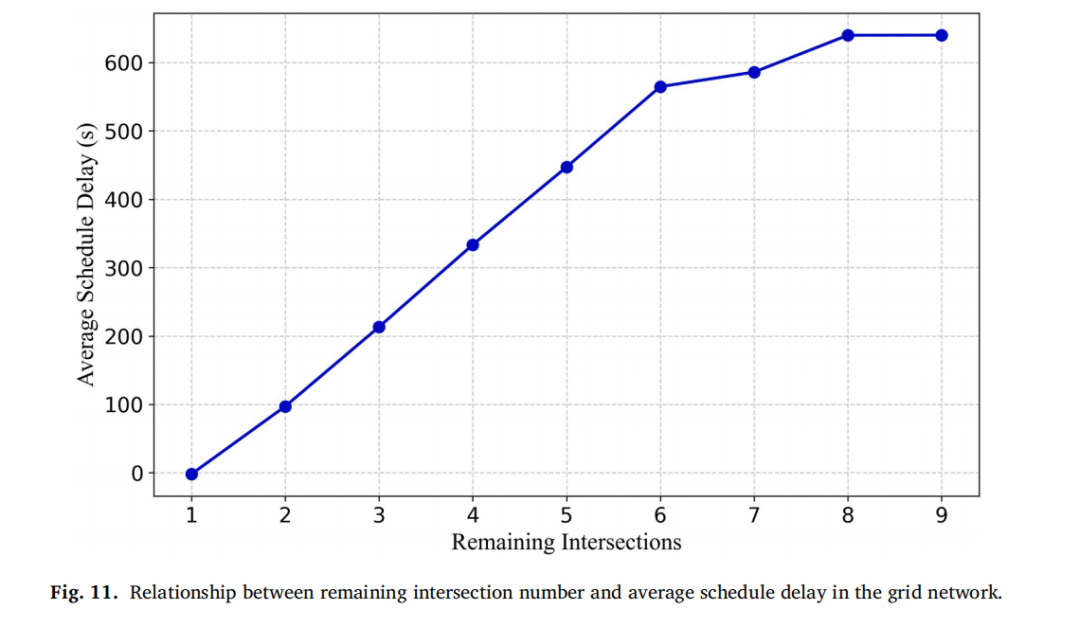
敏感性分析
-
SV渗透率:当SV占比从20%升至80%时,本方法RV延误和SV延误均保持最低。ATSP在高渗透率下甚至劣于FT,说明传统TSP无法扩展。
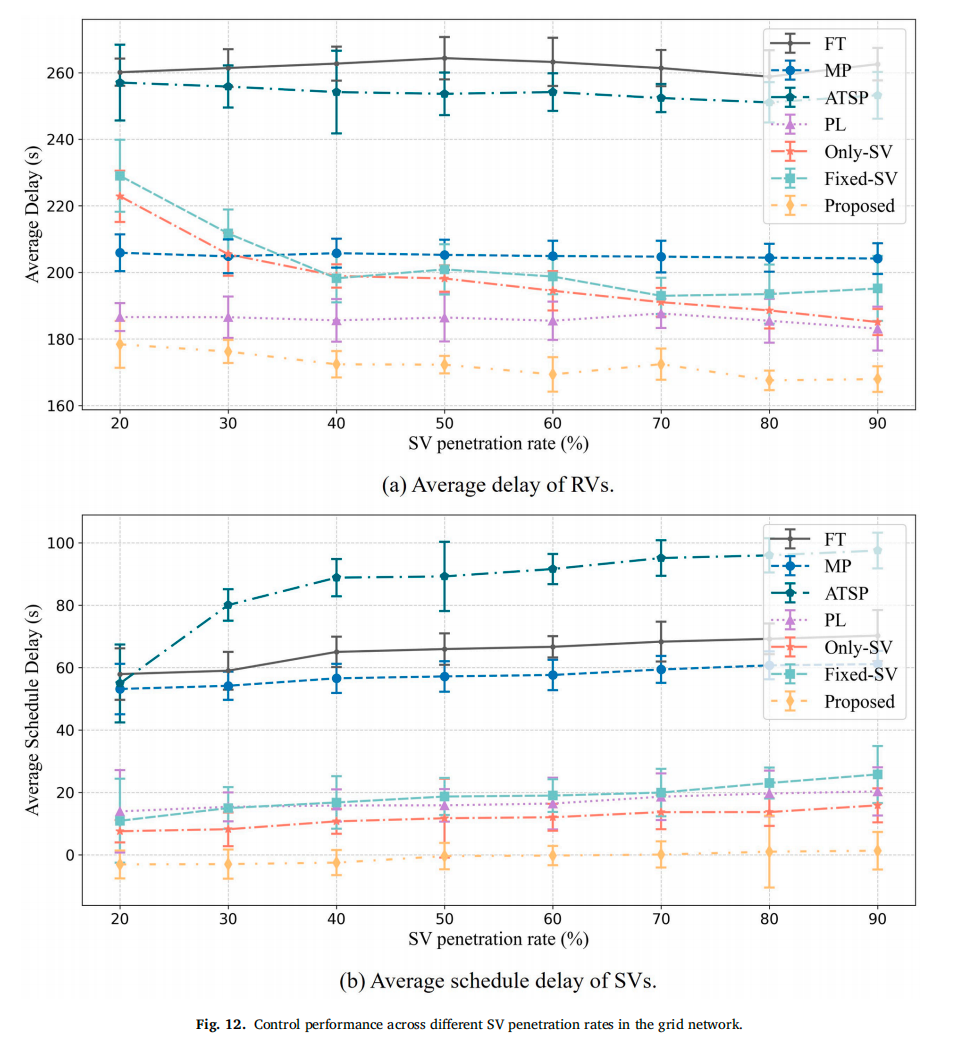
-
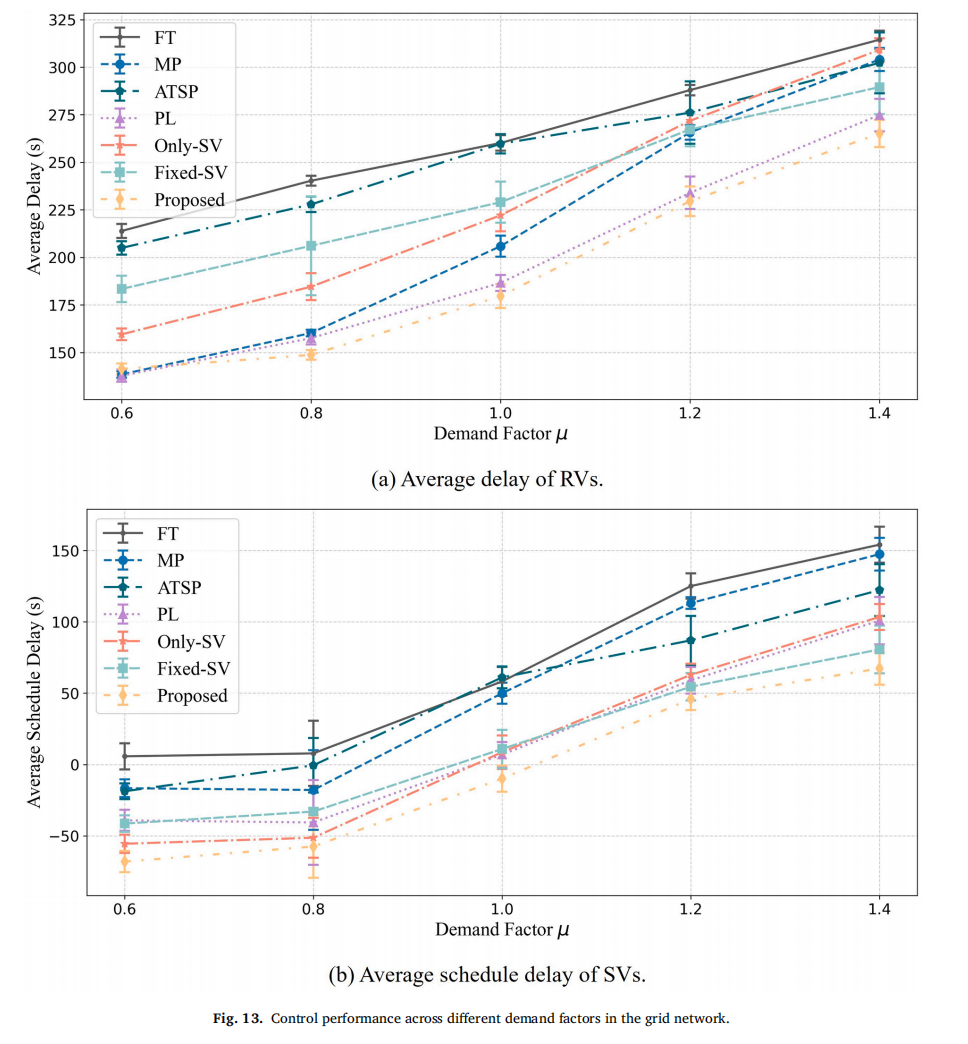
需求因子:在过饱和(μ=1.4)条件下,所有方法SV延误均上升,但本方法仍最优。同时指出:行程时间变异性增大时,基于低需求标定的预定时刻表可能过于乐观,需结合鲁棒时刻表优化。
-
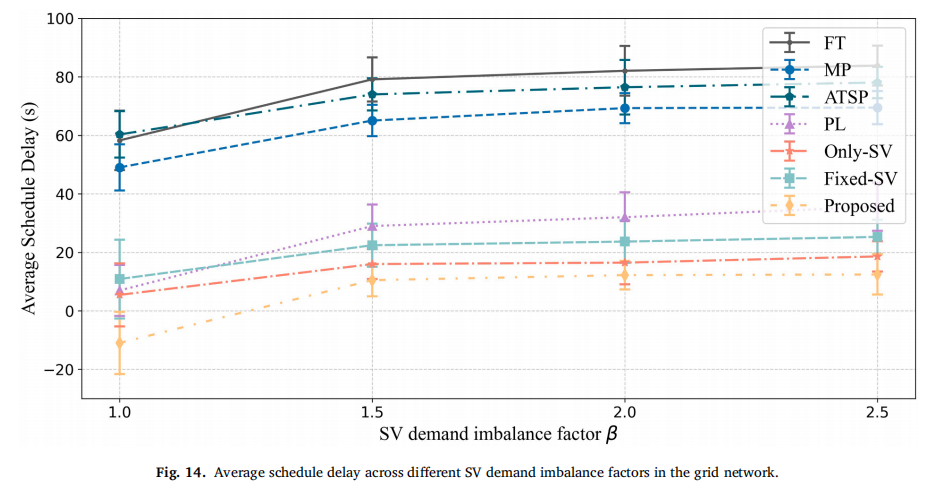
需求不均衡:随着OD间SV需求量差异增大(β增大),本方法的SV延误增幅最小,体现了Transformer对不均衡分布的适应性。
-
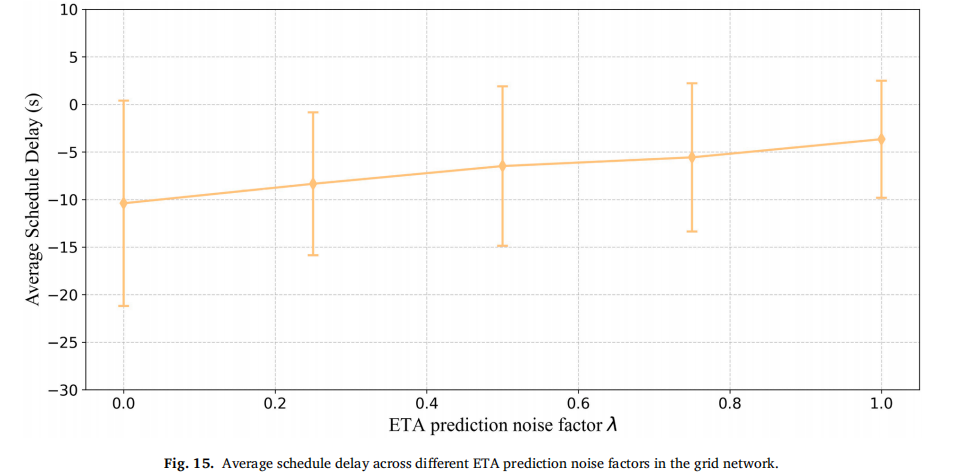
ETA预测噪声:当ETA添加随机噪声(λ越大噪声越大)时,本方法的SV延误线性增加,表明高精度行程时间预测对性能至关重要。
-
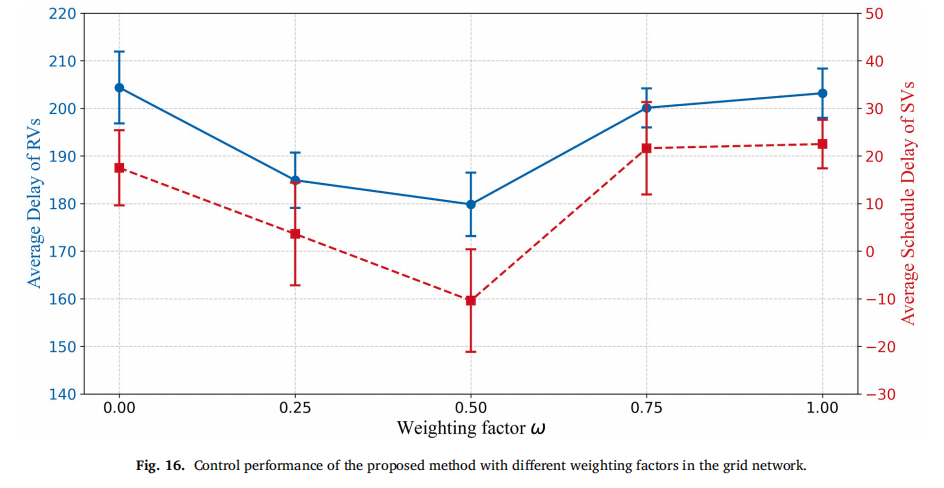
权重因子ω:ω=0(只关注SV)或ω=1(只关注效率)均导致两项指标变差,ω=0.5取得最佳平衡,说明适度融合SV信息能帮助缓解整体拥堵。
消融实验
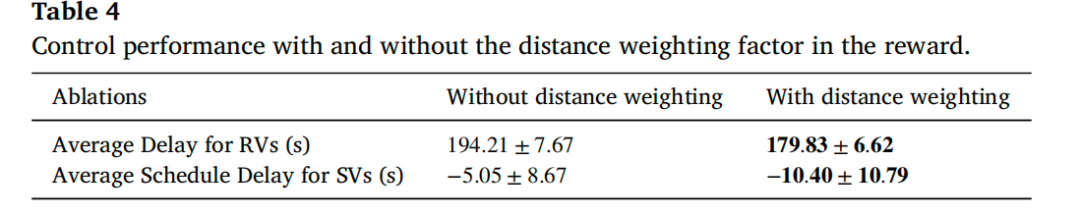
去除距离加权因子1/(RI+1)后,RV平均延误从179.83s升至194.21s,SV平均延误从-10.40s升至-5.05s(即准点率下降)。证明该因子是实现“上游延迟、下游补偿”且不恶化整体交通的核心设计。

7
结语
本研究针对大规模计划车辆(SVs)的信号优先控制问题,提出了一个多智能体强化学习(MARL)框架。核心贡献包括:① 设计剩余距离加权的优先级指标,使接近目的地的SV获得更高优先权,远距离SV可被策略性延迟;② 引入Transformer特征提取器,解决了动态变化数量的SV观测输入问题;③ 构建端到端联合训练架构,平衡SV准点率与整体交通效率。仿真结果表明,该方法在网格网络和真实路网上均显著优于现有基准,能在提升SV准点率的同时降低普通车辆延误。敏感性分析验证了其在不同SV渗透率、需求水平及ETA噪声下的鲁棒性。
未来研究方向包括:① 结合更合理的时刻表设计(考虑拥堵变异性);② 扩展至多停靠点SV(如公交车、多站点配送车);③ 联合优化信号控制与SV路径选择;④ 引入联邦学习或隐私保护机制,实现在不共享原始数据前提下的协同控制。
期待你的
分享
点赞
在看
END
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!
· 往期推荐
TR-C | 昆士兰大学:兼顾公平性的数据驱动拥堵定价-基于受约束深度强化学习的方法
TR-B | 浙大:面向住宅区位选择的图神经网络-联结经典Logit模型
TR-C | 港大&同济:基于图集成传递熵的交通网络全局因果感知影响建模

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)