
AI Agent 知识库建设全景指南(2026)完整版
例如输入"张三是小米公司的工程师,负责 RAG 系统开发",Extract 阶段会识别出实体:张三(人)、小米(组织)、RAG 系统(产品),以及关系:张三→就职于→小米、张三→负责→RAG 系统。它的核心价值不是性能(pgvector 的搜索速度不如专用向量库),而是简单性:你可以在同一张表里存用户信息和对应的向量,用标准 SQL 做联表查询,复用已有的备份、权限、事务机制。而 Mem0 是完全

系统梳理 2026 年 AI Agent 知识库建设的核心技术、主流开源框架与落地方案,覆盖记忆架构、RAG 演进、Graph RAG 实现、向量数据库选型与技术实践全流程。
一、为什么 AI Agent 需要专属知识库
传统 RAG 仅解决"信息检索"问题,但 Agent 需要的是能随时间演化的动态记忆,就像人类大脑既能检索事实,又能记住昨天的对话、形成习惯。
Agent 知识库的三大核心问题:
-
跨会话连贯性:下次对话还记得上次的偏好和进度
-
知识实时更新:新事件发生后记忆要随之更新,而非固化在训练数据里
-
推理与检索融合:不仅找到相关文档,还要理解文档间的关系
二、Agent 记忆四层架构详解
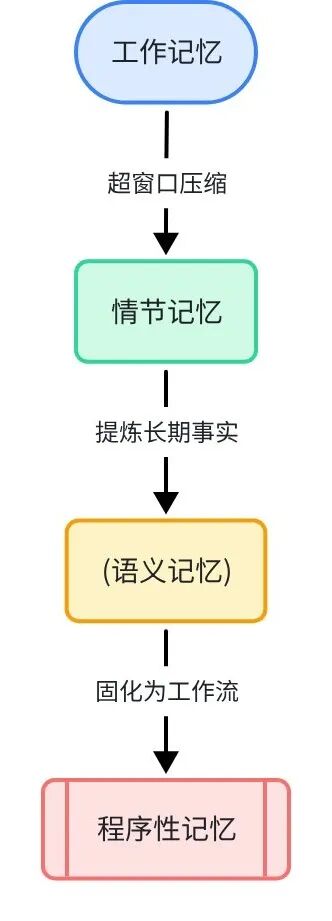
借鉴认知科学,Agent 记忆从短期到长期分为四个层次,逐层积累、相互转化。
|
层次 |
名称 |
存储介质 |
时效 |
典型容量 |
|---|---|---|---|---|
|
L1 |
工作记忆 |
LLM Context |
单次会话 |
8k–128k token |
|
L2 |
情节记忆 |
向量数据库 |
数天–数月 |
无限(按需检索) |
|
L3 |
语义记忆 |
图数据库 + 向量库 |
永久 |
无限 |
|
L4 |
程序性记忆 |
工具定义 / 代码库 |
永久 |
无限 |
层间转换机制:
-
工作记忆 → 情节记忆:对话超出 token 上限时,历史轮次被压缩摘要写入向量库
-
情节记忆 → 语义记忆:反复出现的事实被提炼成实体-关系三元组,存入知识图谱
-
语义记忆 → 程序性记忆:高频操作被封装成工具函数或 Agent Skill,固化为可调用能力
三、2026 年三条技术路径
2026 年 AI Agent 知识库建设呈现三条清晰的技术分岔:轻量化路径适合快速落地,图谱增强路径适合深度推理,Agentic 自适应路径代表前沿方向。
路径一:轻量化向量检索路径
适合:中小型项目、快速验证、资源有限的团队
核心工具:Chroma / Qdrant + OpenAI Embedding + LangChain
将文档按 512 token 分块,附加 64 token 重叠,生成向量后存入本地 Chroma,通过相似度检索召回 Top-5 片段,注入 LLM 上下文生成回答。整个链路无外部依赖,本地可运行。
路径二:图谱增强推理路径
适合:需要多跳推理、实体关系复杂的知识库场景
核心工具:LightRAG / Cognee + Neo4j + 向量库双路检索
在向量检索的基础上,额外构建知识图谱(自动提取实体、关系、属性)。查询时同时走向量路和图谱路,融合两路结果。对于"A 和 B 有什么关系?"这类多跳问题,图谱路的准确率显著高于纯向量路。
路径三:Agentic 自适应路径
适合:复杂任务分解、需要 Agent 自主规划检索策略的场景
核心工具:LangGraph + Mem0 + 多工具 Agent
Agent 不再被动接受检索结果,而是主动决策:是否需要检索、检索什么关键词、是否需要追加检索、是否调用外部工具。记忆层由 Mem0 维护跨会话状态,Agent 可"记住"用户之前的任务上下文。
三条路径对比
|
维度 |
轻量向量路径 |
图谱增强路径 |
Agentic 自适应路径 |
|---|---|---|---|
|
上手难度 |
低 |
中 |
高 |
|
推理深度 |
浅(单跳) |
深(多跳) |
自适应 |
|
运维成本 |
低 |
中 |
高 |
|
准确率 |
中 |
高 |
最高 |
|
推荐场景 |
快速验证 |
企业知识库 |
复杂 Agent 系统 |
四、RAG 技术演进四代
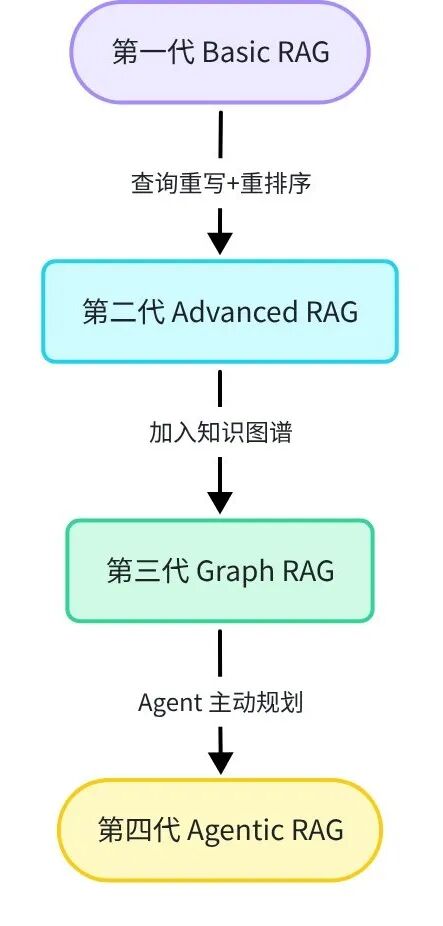
从基础向量检索到 Agent 自主规划检索,RAG 正经历四代范式升级。
|
代次 |
核心技术 |
检索方式 |
典型工具 |
适用场景 |
|---|---|---|---|---|
|
第一代 Basic RAG |
向量相似度检索 |
单次 Embedding 查询 |
LlamaIndex 基础版 |
简单 QA |
|
第二代 Advanced RAG |
查询重写 + 重排序 |
多路召回 + Cross-Encoder |
Cohere Rerank |
复杂文档问答 |
|
第三代 Graph RAG |
知识图谱 + 向量 |
图遍历 + 语义检索 |
LightRAG、Cognee |
多跳推理 |
|
第四代 Agentic RAG |
Agent 主动规划 |
自主决策检索策略 |
LangGraph + RAG |
复杂任务分解 |
Agentic RAG 代码示例:Agent 自主判断何时检索、检索什么、是否需要追加检索:
五、主流 Agent 记忆与 RAG 框架全景
2026 年已形成"无代码工具 + 轻量 SDK + 图谱专项"三层生态。以下是 8 个主流框架的详细对比与使用建议。
|
框架 |
定位 |
记忆类型 |
图谱能力 |
学习曲线 |
推荐指数 |
|---|---|---|---|---|---|
|
LangChain |
通用 Agent 框架 |
工作记忆 + 向量 |
弱 |
中 |
⭐⭐⭐⭐ |
|
LlamaIndex |
文档检索专项 |
索引化向量记忆 |
中 |
中 |
⭐⭐⭐⭐ |
|
Mem0 |
跨会话记忆 SDK |
语义记忆 + 图谱 |
中(v1.1+) |
低 |
⭐⭐⭐⭐⭐ |
|
Cognee |
知识图谱构建 |
语义 + 图谱 + 时序 |
强 |
中 |
⭐⭐⭐⭐ |
|
LightRAG |
图谱 RAG 框架 |
语义 + 图谱双路 |
强 |
低 |
⭐⭐⭐⭐⭐ |
|
RAGFlow |
企业文档解析 |
向量记忆 |
弱 |
低(可视化) |
⭐⭐⭐⭐ |
|
Dify |
低代码 Agent 平台 |
向量记忆 |
弱 |
极低 |
⭐⭐⭐⭐ |
|
AnythingLLM |
个人知识库工具 |
向量记忆 |
弱 |
极低 |
⭐⭐⭐ |
框架选型建议
-
快速原型:AnythingLLM → 零代码,拖拽即用,5 分钟搭建本地知识库
-
生产级记忆:Mem0 → 提供 Python/JS SDK,云端托管,1 行代码接入跨会话记忆
-
深度文档理解:RAGFlow → 支持 PDF 版式解析、表格提取,适合合同、报告类文档
-
知识图谱推理:LightRAG 或 Cognee → 两者均支持向量+图谱双路,LightRAG 上手更快,Cognee 图谱更丰富
-
企业多人协作:Dify → 可视化 Workflow 编排,支持多模型切换,适合非技术团队
-
自定义工程:LangChain + LlamaIndex → 灵活度最高,适合有工程能力的团队深度定制
六、向量数据库选型
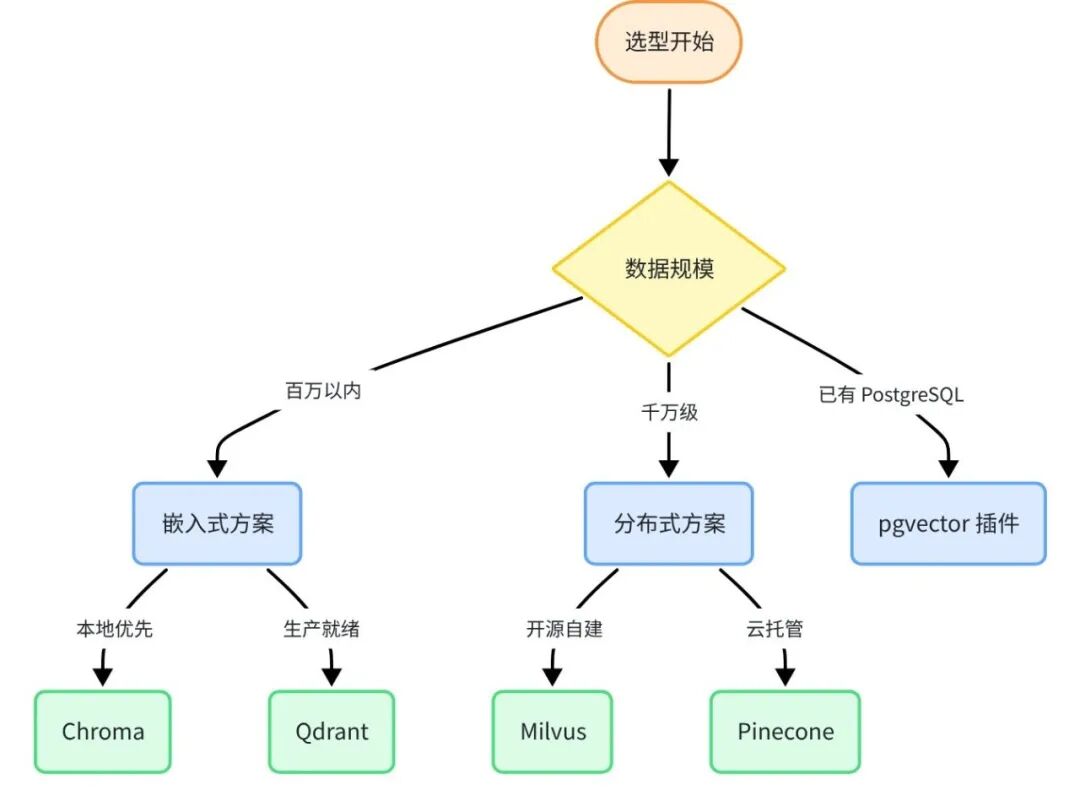
按数据规模和部署方式,从决策树快速定位最合适的向量存储方案。
|
数据库 |
部署方式 |
数据量级 |
特点 |
推荐场景 |
|---|---|---|---|---|
|
FAISS |
本地库 |
百万级 |
极致速度,无持久化 |
原型验证 |
|
Chroma |
本地/云 |
百万级 |
开箱即用,Python 友好 |
小型项目 |
|
Qdrant |
本地/云 |
千万级 |
过滤能力强,Rust 实现 |
中型生产 |
|
Milvus |
分布式 |
亿级 |
企业级,云原生 |
大规模生产 |
|
pgvector |
PostgreSQL 插件 |
千万级 |
与现有 PG 无缝集成 |
已有 PG 的团队 |
|
Weaviate |
本地/云 |
亿级 |
多模态,GraphQL |
多模态场景 |
各向量数据库详解
FAISS(Facebook AI Similarity Search)
FAISS 是 Meta 开源的纯内存向量检索库,不是一个独立的数据库服务,而是一组高效的索引算法集合。它的核心优势是速度:在 100 万维度的向量集合上,毫秒级返回最近邻结果。但 FAISS 没有持久化机制,重启后数据丢失;也没有过滤条件支持,无法按用户 ID 或标签筛选。因此 FAISS 适合用于原型验证和算法研究,生产环境中一般封装在 LangChain 的 FAISS VectorStore 里做快速演示。
Chroma
Chroma 是专为 AI 应用设计的开源向量数据库,API 极其简洁——5 行 Python 代码就能完成从创建集合到查询的全流程。Chroma 支持本地嵌入式模式(数据存在本地文件),也支持作为独立服务运行。它内置了元数据过滤(where 条件),可以按 user_id、source 等字段筛选。Chroma 的局限是单机性能上限约 100 万条,超过后查询延迟明显上升,不适合大规模生产。
Qdrant
Qdrant 是用 Rust 编写的高性能向量数据库,在过滤能力上是同类产品中最强的。它支持复杂的布尔条件组合(must/should/must_not),可以在向量搜索的同时做精确的元数据过滤,且过滤不影响检索速度(使用 HNSW 索引的同时维护 payload 索引)。Qdrant 提供本地部署和 Qdrant Cloud 两种模式,Rust 底层使得它的内存占用远低于 Java 系的同类产品。推荐用于需要多租户隔离(按 user_id 过滤)的中型生产环境。
Milvus
Milvus 是 Zilliz 开源的分布式向量数据库,专为亿级向量规模设计。它采用存储计算分离架构,支持水平扩展,内置多种索引类型(HNSW、IVF_FLAT、IVF_SQ8 等)可按场景选择。Milvus 2.x 版本支持标量过滤、多向量混合检索,并提供 Attu 可视化管理界面。代价是部署复杂,依赖 etcd、MinIO、Pulsar 等组件,适合有运维能力的大型企业。
pgvector
pgvector 是 PostgreSQL 的向量搜索扩展插件,一行 CREATE EXTENSION vector 就能让现有 PG 数据库支持向量存储和 ANN 搜索。它的核心价值不是性能(pgvector 的搜索速度不如专用向量库),而是简单性:你可以在同一张表里存用户信息和对应的向量,用标准 SQL 做联表查询,复用已有的备份、权限、事务机制。如果团队已经在用 PostgreSQL,pgvector 是最低成本的向量检索方案,Mem0 的默认存储后端就是 pgvector。
Weaviate
Weaviate 是原生支持多模态的向量数据库,可以对文本、图片、音频的混合查询做向量化存储。它提供 GraphQL 查询接口,支持跨 class(类似跨表)的关联查询。Weaviate 内置了向量化模块(可对接 OpenAI、Cohere、HuggingFace),无需外部 Embedding 服务。适用于需要同时检索文本和图片的多模态 Agent 场景。
选型决策逻辑
|
优先考虑因素 |
推荐数据库 |
理由 |
|---|---|---|
|
快速验证,不想运维 |
Chroma(本地) |
零配置,pip 安装即用 |
|
已有 PostgreSQL 环境 |
pgvector |
无需新增基础设施 |
|
需要多租户 user_id 过滤 |
Qdrant |
过滤+向量检索同时高效 |
|
数据量超千万,云原生 |
Milvus |
分布式扩展,企业级稳定性 |
|
多模态(图文混合)场景 |
Weaviate |
原生多模态,GraphQL 查询 |
|
算法研究/速度基准测试 |
FAISS |
纯 in-memory,速度最快 |
常见配置参数说明
向量数据库选型后,还需要关注三个核心参数:
-
向量维度(dimension):必须与 Embedding 模型输出维度严格匹配。text-embedding-ada-002 是 1536 维,text-embedding-3-large 是 3072 维,BGE-large-zh 是 1024 维。维度不匹配会直接报错。
-
索引类型:HNSW(Hierarchical Navigable Small World)是目前综合性能最好的 ANN 索引,检索速度快、召回率高,大多数场景首选。IVF 系列更省内存,适合超大规模数据集。
-
距离度量(metric):Cosine(余弦相似度)适合文本语义相似,是 RAG 场景的默认选择;L2(欧氏距离)适合图像特征向量;IP(内积)适合已归一化向量。
七、Cognee 深度实践
Cognee 通过 Extract-Cognify-Load 三阶段构建知识图谱,recall 函数自动路由语义、图谱、时序三路检索。
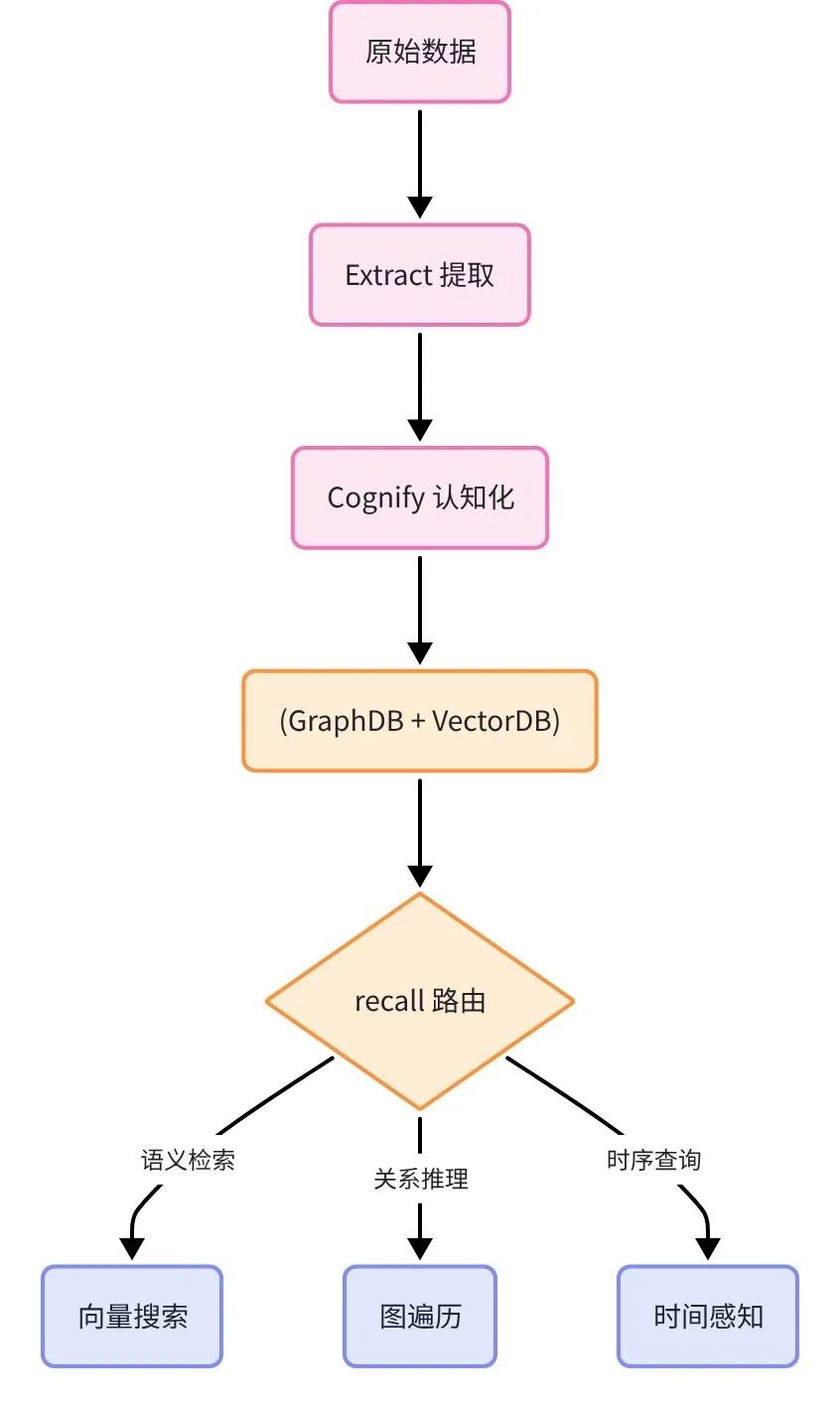
ECL Pipeline 三阶段:
-
Extract(提取):解析文档结构,识别实体和关系
-
Cognify(认知化):用 LLM 推断隐式关系,构建知识图谱
-
Load(加载):同时写入 GraphDB 和 VectorDB,支持双路检索
ECL 三阶段详解
Cognee 的核心流程是 Extract → Cognify → Load,三个阶段共同完成从原始文档到可查询知识图谱的转变。
Extract(提取)阶段
这一阶段的任务是把非结构化文档解析成结构化片段。Cognee 会对输入文档做分块(chunking),然后用 NLP 技术识别每个片段中的实体(人名、组织、产品、概念等)和实体之间的关系。例如输入"张三是小米公司的工程师,负责 RAG 系统开发",Extract 阶段会识别出实体:张三(人)、小米(组织)、RAG 系统(产品),以及关系:张三→就职于→小米、张三→负责→RAG 系统。
Cognify(认知化)阶段
这是 Cognee 区别于传统 RAG 的核心步骤。Cognify 不仅保留显式关系,还会调用 LLM 推断文档中的隐式关联——两个实体虽然没有直接出现在同一句话里,但通过上下文可以推断出潜在关系。例如文档前半段讲 A 公司使用 B 技术,后半段讲 C 技术是 B 技术的竞争替代品,Cognify 会推断出"A 公司可能会考虑 C 技术"这一隐式关联,并将其写入图谱。这个推断过程让 Cognee 的知识图谱比简单的实体抽取更"有智慧"。
Load(加载)阶段
将 Cognify 阶段产出的实体、关系、推断三元组同时写入两个存储:图数据库(默认 NetworkX,支持 Neo4j)和向量数据库(存储每个实体/关系的 Embedding)。双路存储的好处是查询时可以灵活组合:向量路径擅长"找相似",图路径擅长"找关联链路",两路结果融合后召回率显著高于单路。
recall 函数的三路检索
Cognee 的 cognee.search() 函数内部实现了三路并行检索:
-
语义路径:用查询语句的 Embedding 在向量库中做相似度检索,找出语义最相关的实体和文档片段
-
图谱路径:将查询中的关键实体作为起点,在知识图谱中做广度优先或深度优先遍历,找出多跳相关的实体和关系链
-
时序路径:按时间戳排序,优先返回最新写入的记忆(适合"最近发生了什么"类查询)
三路结果会经过去重和重排序后返回,Cognee 自动选择最相关的答案组合。
Cognee 与其他框架的实际差异
|
对比维度 |
Cognee |
LightRAG |
LangChain |
|---|---|---|---|
|
图谱构建方式 |
LLM 推断 + NLP 抽取 |
LLM 抽取,更轻量 |
需手动构建或接入 Neo4j |
|
上手复杂度 |
中(需要理解 ECL) |
低(3 行代码) |
低到高(视需求而定) |
|
图谱深度 |
深(含隐式推断) |
中(显式关系为主) |
取决于自定义程度 |
|
适用场景 |
深度语义理解、知识推理 |
快速上手图谱增强 RAG |
通用场景、快速集成 |
|
生产成熟度 |
早期生产(活跃迭代中) |
早期生产 |
成熟 |
使用建议
Cognee 最适合以下场景:文档之间关联关系复杂(如法律条文、医学文献、企业知识库),需要 Agent 回答"A 与 B 有何关联"或"X 是通过什么路径影响 Y 的"这类多跳推理问题。如果只是做简单的"找最相关文档",用 Chroma + OpenAI Embedding 的基础 RAG 就够了,引入 Cognee 反而增加了不必要的复杂度。
注意事项:Cognee 的 Cognify 阶段每个 chunk 都会调用 LLM,处理大型文档库(>10 万字)时 API 费用较高,建议在后台异步处理,不要在用户请求路径上同步触发图谱构建。
八(续)、Mem0 生产实践
Mem0 在 MemGPT 基准测试中,准确率(91.4%)和延迟均优于 OpenAI Memory。
|
指标 |
Mem0 |
OpenAI Memory |
|---|---|---|
|
准确率 |
91.4% |
73.1% |
|
延迟 |
低(ms 级) |
中(秒级) |
|
可控性 |
完全可控 |
不可自定义 |
|
图谱能力 |
支持(v1.1+,图谱记忆) |
不支持 |
Mem0 核心架构
Mem0 的设计理念是"让 Agent 像人一样记住重要的事"。它并不是把所有对话都存下来,而是从对话中提炼出有价值的信息(用户偏好、事实陈述、任务结果),形成结构化记忆,供后续会话检索使用。
Mem0 的内部架构分为三层:
-
提取层:每次对话结束后,Mem0 调用 LLM 判断本轮对话是否包含值得记忆的信息,并将其总结为简短的记忆条目(如"用户偏好使用 Python 而非 JavaScript")
-
存储层:记忆条目以向量形式存入向量数据库(默认 pgvector),同时在 v1.1+ 版本中可选择写入图数据库(实体关系图谱)
-
检索层:用户发起新对话时,Mem0 自动用对话内容检索相关历史记忆,将检索结果注入 LLM 的 system prompt,使 LLM 能"记住"用户
记忆的生命周期
Mem0 对记忆的管理不是简单的"增加",而是有完整的更新逻辑:
-
新增记忆:对话中出现全新信息时,直接写入新条目
-
更新记忆:对话中出现与已有记忆矛盾的信息时(如用户说"我现在改用 TypeScript 了"),Mem0 会自动更新旧记忆而非堆积矛盾信息
-
确认记忆:重复出现相同信息时,提升该记忆的置信度分数,不重复写入
这个机制使得 Mem0 的记忆库不会无限膨胀,且始终保持"最新状态"的用户画像。
生产环境最佳实践
1. 多用户隔离
每个用户必须使用独立的 user_id。Mem0 的所有操作(add/search/get_all)都基于 user_id 隔离,不同用户之间的记忆完全隔离,不存在数据泄露风险。
2. 选择合适的 LLM 做记忆提取
记忆提取不需要用最贵的模型。推荐用 gpt-4o-mini 做提取(速度快、成本低),用 gpt-4o 做最终回答生成。Mem0 支持为提取和推理分别配置不同的 LLM。
3. 搜索结果的使用方式
Mem0 的 search() 返回按相关性排序的记忆列表。建议取 Top-5 到 Top-10 条注入 system prompt,格式如下:
用户历史记忆(注入 system prompt 示例):
-
用户偏好 Python,不喜欢 JavaScript
-
用户在一家金融科技公司工作
-
上次讨论了 RAG 系统的向量数据库选型
不要将所有记忆全量注入,否则会超出 context 限制且引入噪音。
4. 定期记忆审计
Mem0 提供 get_all(user_id) 接口,可以查看某用户的所有记忆条目。建议定期(每月)对长期用户的记忆做人工审计,删除明显过时或错误的条目,防止记忆"腐烂"影响回复质量。
Mem0 vs OpenAI Memory 的深层差异
两者表面上都是"让 AI 记住用户",但实现方式和控制权完全不同:
OpenAI Memory 是黑盒——你无法查看它存了什么,无法手动修改,也无法将记忆迁移到其他系统。而 Mem0 是完全透明的开源方案,你可以随时查询、修改、删除任意用户的记忆,记忆数据存在你自己的数据库里,不依赖任何第三方服务。这对于需要数据合规(GDPR、个人信息保护法)的场景尤为重要。
八、Graph RAG 实现示例
同一查询同时走向量检索和图谱遍历,结果融合后返回比纯向量检索更完整的答案。
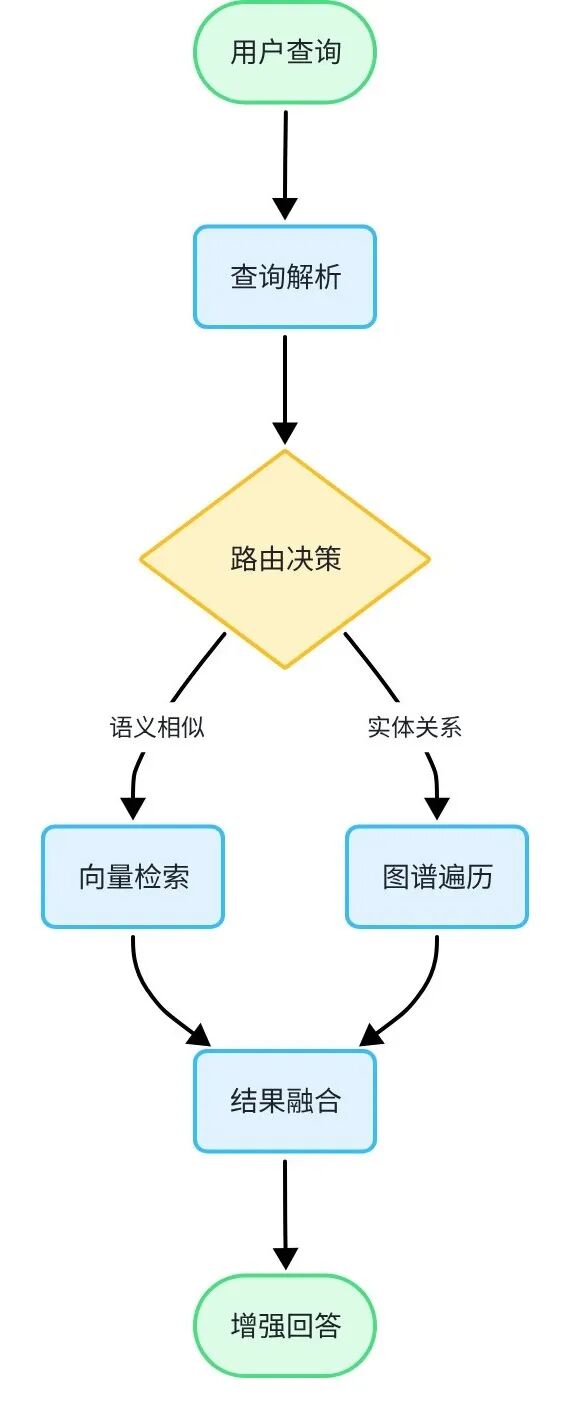
### Graph RAG 的核心原理
传统 RAG(向量检索)的本质是"找相似":把查询向量化后,在向量空间里找最近的文档片段。这种方式在单跳问题(直接问某个事实)上表现很好,但对多跳问题("A 通过什么方式影响了 B?")力不从心,因为向量相似度无法表达实体间的关系链。
Graph RAG 在向量检索的基础上增加了一条图谱检索路径:先从文档中提取实体和关系,构建知识图谱,查询时同时走两条路——向量路找相似内容,图谱路找关联链路,两路结果融合后给 LLM,回答质量显著提升。
下·
### LightRAG 的查询模式
LightRAG 是目前最流行的轻量级 Graph RAG 实现,它提供四种查询模式,覆盖不同的信息需求:
|
查询模式 |
检索方式 |
适用场景 |
示例问题 |
|---|---|---|---|
|
naive |
纯向量相似度 |
简单事实查询 |
"什么是 HNSW 索引?" |
|
local |
查询实体的直接邻居节点 |
单实体属性查询 |
"Qdrant 支持哪些索引类型?" |
|
global |
跨社区的图谱全局搜索 |
宏观主题查询 |
"2026 年 RAG 领域的主要趋势是什么?" |
|
hybrid |
local + global + 向量三路融合 |
复杂多跳推理 |
"LightRAG 和 Cognee 在图谱构建上有何本质区别?" |
日常使用建议:简单问答用 naive 或 local(速度快),需要深度分析用 hybrid(质量最高但耗时较长,需要多次 LLM 调用)。
Microsoft GraphRAG 的社区发现机制
Microsoft GraphRAG 与 LightRAG 的最大区别在于"社区发现"(Community Detection)。它会对知识图谱做图聚类,把关联紧密的实体归为一个"社区",并为每个社区生成一个摘要报告(Community Report)。
查询时,GraphRAG 先在社区摘要层做检索,再在实体层做精细检索,形成两级检索结构。这种设计对大型知识库(百万级实体)特别有效,可以先用社区报告快速定位相关领域,再在局部图谱里深挖细节。代价是索引构建时间长(社区发现和报告生成都需要大量 LLM 调用)。
LightRAG vs Microsoft GraphRAG 对比
|
对比维度 |
LightRAG |
Microsoft GraphRAG |
|---|---|---|
|
索引构建速度 |
快(分钟级) |
慢(可能需要数小时) |
|
查询质量 |
高(local/global/hybrid) |
高(社区摘要+实体双层) |
|
适用知识库规模 |
万级实体以内 |
百万级实体,超大规模 |
|
上手难度 |
低,3 行代码上手 |
中,需要配置管道参数 |
|
API 费用 |
中(构建时调用 LLM) |
高(社区发现需大量 LLM 调用) |
|
开源状态 |
完全开源 |
开源(Microsoft 维护) |
|
最佳适用场景 |
中小型知识库,快速部署 |
企业级大型知识库,需要宏观分析 |
双路检索的融合策略
Graph RAG 的向量路和图谱路的结果需要融合,常见的融合策略有三种:
-
拼接融合:直接将两路结果拼接后注入 LLM,由 LLM 自行判断哪部分更相关。实现最简单,适合快速验证。
-
分数加权融合:向量相似度分数和图谱路径长度(跳数越少权重越高)做加权平均,按融合分数重排序。需要调参,效果更稳定。
-
互补融合:先用向量路找到最相关内容,再用图谱路找到向量路遗漏的关联实体,两者互补。适合知识库覆盖度高的场景。
实践中最常用的是拼接融合(LightRAG 默认策略),在大多数场景下已经够用。
九、完整 Agent 记忆运行流程
用户输入经工作记忆、RAG 检索、生成回复,重要事实自动写入长期语义记忆,实现跨会话记忆持久化。

流程各阶段解析
① 工作记忆阶段:每次用户输入先进入工作记忆(即 LLM 的 context window)。工作记忆是 Agent 的"短时记忆",容量有限(通常 8k–128k token)。
② Token 超限压缩:当上下文接近 token 上限时,触发记忆压缩。系统将早期对话提炼成摘要,写入情节记忆(向量数据库),清空工作记忆缓冲区,保留最近 N 轮对话继续推理。
③ RAG 检索触发:推理过程中,如果 LLM 判断需要外部知识,则触发 RAG 检索——向向量库发出语义查询,召回相关文档片段,注入当前上下文后继续生成。
④ 记忆写入策略:生成回复后,系统判断是否产生了"重要事实"(如用户偏好、实体关系、任务结果)。重要事实被提炼并写入语义记忆(长期知识库),供后续会话检索使用。
最佳实践
-
分层存储:短期用 Redis 或内存缓存,长期用向量数据库(Qdrant/pgvector)
-
记忆去重:写入前先检索相似记忆,避免重复存储同一信息
-
过期策略:为记忆设置 TTL 或重要性分数,定期清理低价值记忆
-
隐私保护:敏感信息(密码、个人身份)不应写入持久化记忆
十、Memoria:记忆版本管理与审计
Memoria 是一个专注于记忆版本控制的框架,类似"记忆的 Git"——每次记忆更新都会创建版本快照,支持回溯到任意历史状态、对比记忆变化、审计记忆修改来源。
核心能力
|
能力 |
说明 |
应用场景 |
|---|---|---|
|
版本快照 |
每次 add/update 自动创建版本 |
追踪记忆演化轨迹 |
|
历史回溯 |
恢复到任意历史版本的记忆状态 |
修复错误记忆 |
|
变更对比 |
diff 两个版本之间的记忆差异 |
审计用户状态变化 |
|
多用户隔离 |
每个 user_id 独立版本树 |
多租户场景 |
|
记忆标注 |
为记忆打标签(来源、可信度) |
知识质量管理 |
适用场景
-
合规审计:金融、医疗等需要记录 AI 记忆修改历史的合规场景
-
A/B 测试:对比不同记忆策略下 Agent 的表现差异
-
记忆纠错:发现 Agent 记忆出错后,精确回溯到问题出现前的状态
-
多版本并行:为同一用户维护多套记忆(如工作版 vs 个人版)
与其他框架的对比
|
维度 |
Memoria |
Mem0 |
标准向量库 |
|---|---|---|---|
|
版本控制 |
完整 Git 语义 |
无 |
无 |
|
检索性能 |
中 |
高 |
高 |
|
存储开销 |
高(存多版本) |
低 |
低 |
|
审计能力 |
完整 |
有限 |
无 |
|
适用场景 |
合规/审计 |
通用记忆 |
大规模检索 |
十一、2026 技术趋势前瞻
趋势一:记忆即服务(Memory-as-a-Service)
记忆层正从框架内置能力演变为独立的云服务。Mem0 Cloud、Zep Cloud 等平台提供托管式记忆 API,开发者无需自建向量库和图数据库,通过 REST API 即可接入生产级记忆能力。
影响:记忆能力的门槛大幅降低,中小团队可在 1 天内为现有 Agent 添加跨会话记忆。
趋势二:多模态记忆普及
2026 年,记忆系统开始支持图像、音频、视频的嵌入与检索。用户与 Agent 的交互历史不再局限于文本,产品截图、语音笔记也可以被记忆和检索。
代表框架:Weaviate(多模态向量)、GPT-4V 驱动的视觉记忆提取
影响:客服 Agent 可以记住用户上传的截图内容,教育 Agent 可以记录学生的手写作业。
趋势三:图谱记忆成为标配
知识图谱不再是"高端可选项",而是生产级 Agent 的标配。LightRAG、Cognee、Mem0 v1.1+ 都已内置图谱能力。图谱记忆使 Agent 能够回答"A 和 B 有什么关系"这类需要推理的问题,而非只能回答"A 是什么"。
影响:RAG 的召回准确率预计提升 30–50%,尤其在多跳推理场景。
趋势四:隐私计算与本地记忆
随着数据合规要求收紧(GDPR、中国《个人信息保护法》),本地化部署记忆系统成为企业刚需。Chroma、Qdrant、pgvector 的本地部署方案将更加成熟,联邦学习和差分隐私技术将被引入记忆系统。
影响:金融、医疗行业将出现大量本地化 Agent 记忆方案,数据完全不出企业边界。
趋势五:Agent 记忆的标准化协议
目前各框架的记忆接口各自为政。2026 年,类似 OpenAI Function Calling 规范,社区正推动统一的 Agent Memory Protocol(AMP),使不同框架的记忆模块可以互操作。
影响:开发者可以在 LangChain、LlamaIndex、Dify 之间无缝切换记忆后端,避免厂商锁定。
2026 技术成熟度概览
|
技术方向 |
当前成熟度 |
2026 预期 |
行动建议 |
|---|---|---|---|
|
向量 RAG |
成熟 |
标配 |
立即落地 |
|
图谱 RAG |
早期生产 |
主流 |
开始探索 |
|
多模态记忆 |
实验阶段 |
早期生产 |
关注跟进 |
|
记忆版本管理 |
早期 |
企业需求 |
有合规需求时采用 |
|
Memory-as-a-Service |
商用可用 |
主流 |
适合快速上手 |
|
隐私计算记忆 |
研究阶段 |
企业试点 |
合规敏感行业优先 |
十二、技术选型速查指南
根据团队规模和核心需求,沿决策树快速找到最合适的技术组合。
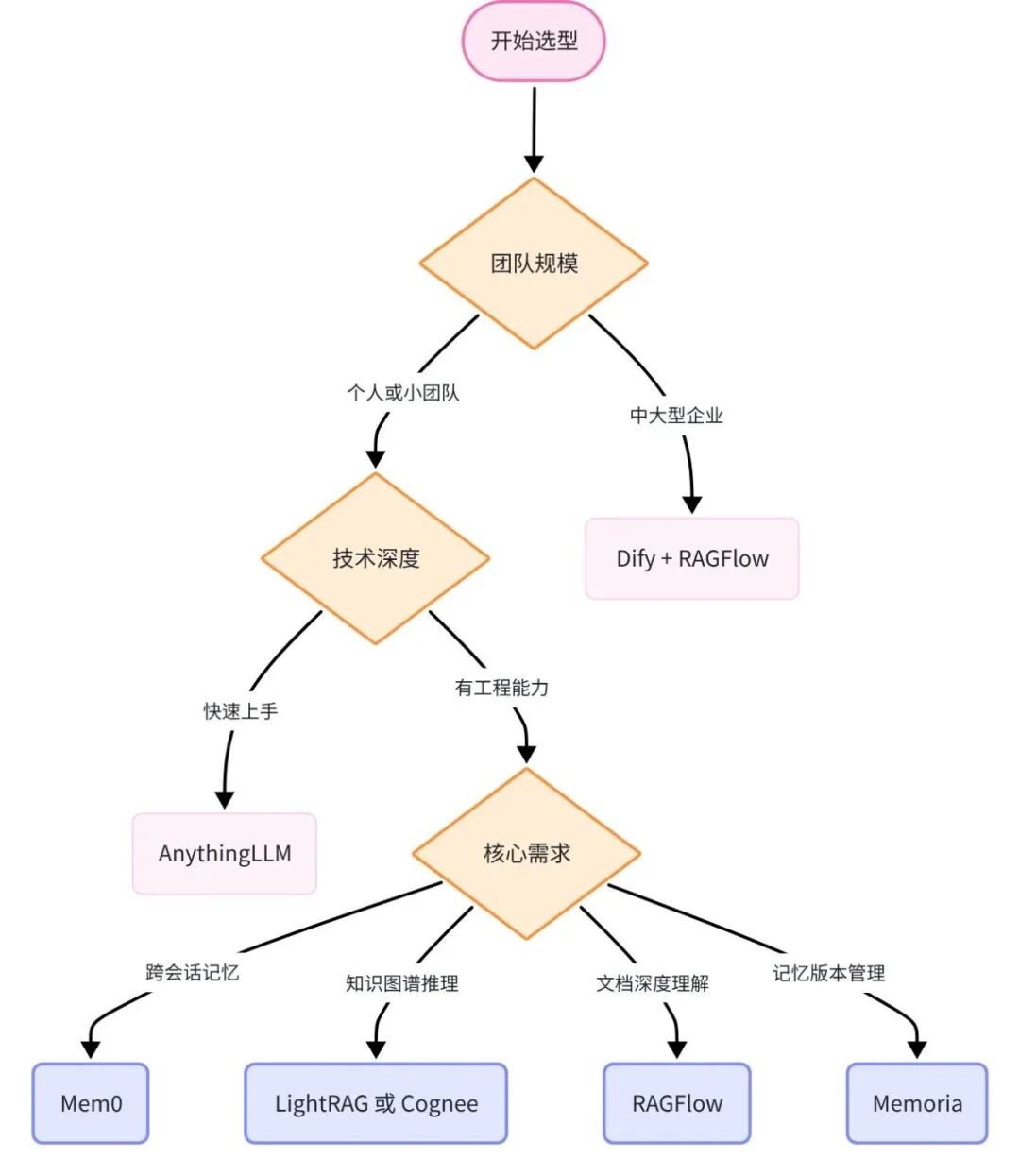
|
场景 |
推荐方案 |
理由 |
|---|---|---|
|
快速验证 / 个人项目 |
AnythingLLM + Chroma |
零配置,5 分钟上手 |
|
跨会话用户记忆 |
Mem0 + pgvector |
生产级,低延迟 |
|
企业文档智能问答 |
RAGFlow + Milvus |
深度文档解析 |
|
知识图谱推理 |
LightRAG 或 Cognee |
图谱 + 向量双路 |
|
大规模企业部署 |
Dify + RAGFlow |
可视化管理,易维护 |
|
记忆版本管理 |
Memoria |
审计、回溯需求 |
|
国内合规私有化 |
MaxKB + Milvus |
国产,数据不出境 |
十三、常见踩坑总结与解决方案
坑 1:Embedding 模型与 chunk size 不匹配
现象:检索召回率低,明明知识库有相关内容,但检索不到。
根因:text-embedding-ada-002 最优 chunk size 为 256–512 token,text-embedding-3-large 可达 1024 token。chunk 太大会稀释关键信息,chunk 太小会丢失上下文。
解决方案:根据 embedding 模型选择匹配的 chunk size,ada-002 推荐 512,并保留 64 token 重叠区间。
坑 2:记忆写入频率过高导致噪音积累
现象:Agent 记忆越来越多,但回复质量反而下降,出现记忆混乱、前后矛盾。
根因:每轮对话都写入记忆,导致大量低价值信息("好的"、"谢谢")污染记忆库。
解决方案:在写入前过滤低价值内容,只保留包含实体、偏好、事实的消息。消息长度 < 20 字且不含关键词的一律跳过。
坑 3:向量数据库未设置过滤条件,多用户数据混乱
现象:用户 A 能检索到用户 B 的私人数据,隐私泄露。
根因:插入向量时未打用户 ID 标签,检索时也未过滤。
解决方案:插入时必须在 payload 中附加 user_id 字段,检索时用 must 条件强制过滤,确保每次检索只返回当前用户的数据。
坑 4:Graph RAG 图谱实体消歧失败
现象:知识图谱中出现大量重复实体("GPT-4"、"gpt4"、"GPT4" 被识别为三个不同实体)。
根因:LLM 提取实体时没有统一归一化规则。
解决方案:在实体写入图谱前,增加归一化后处理步骤——统一大小写、去除连字符变体、维护常见别名映射表(如 gpt4 → GPT-4)。
坑 5:RAG 检索结果重排序后反而变差
现象:加了 Reranker 之后,检索效果反而不如只用向量相似度。
根因:Reranker 模型(如 cross-encoder/ms-marco-MiniLM-L-6-v2)是为英文优化的,中文场景表现差。
解决方案:中文场景使用 BAAI/bge-reranker-v2-m3(支持中英双语),配合 normalize=True 得到归一化分数,保留 Top-K 重排后结果。
坑 6:长文档分块后语义断裂
现象:检索结果虽然相关,但片段不完整,LLM 无法基于它生成高质量回答。
根因:按固定大小切割,断在了句子甚至词语中间。
解决方案:使用 RecursiveCharacterTextSplitter 配合中文分隔符列表(["\n\n", "\n", "。", "!", "?", ";"]),优先按段落切,实在没有段落再按句子切,并增大 chunk_overlap 到 128 保持上下文连贯。
坑 7:Cognee/LightRAG 首次构建图谱耗时过长
现象:插入 1 万字文档需要 10 分钟,严重影响生产体验。
根因:每个 chunk 都调用 LLM 提取实体关系,API 费用高且串行执行慢。
解决方案:
-
使用
asyncio.gather并发调用 LLM,将串行改为并发(提速 5–10 倍) -
图谱构建用小模型(
gpt-4o-mini),最终推理用大模型(gpt-4o) -
增量更新策略:只对新增/修改的文档重新构建,已有图谱保持不变

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)