
从 Token 到 Agent 的完整认知地图:LLM、Token、Context、Context Window、Prompt、Tool、Skill、MCP、Agent……
本文通过一张认知地图,系统梳理了AI领域的核心概念层级关系。从最基础的Token(语言处理单位)到Context(上下文记忆窗口),再到Prompt(用户指令)和Tool(外部工具调用),进一步介绍了MCP(标准化工具协议)和Skill(预配置能力包),最终构建出完整的Agent(智能体)体系。文章着重解释了每个层级的功能特点、相互关系及实际影响,例如Token数量如何影响模型性能和成本,Cont
前言
在 AI 圈子里,新名词层出不穷:LLM、Token、Context、Context Window、Prompt、Tool、Skill、MCP、Agent……这些词你大概率都见过,但它们之间到底是什么关系?谁包含谁?谁依赖谁?
本文将用一张完整的认知地图,帮你理清这些概念的层级关系,从最底层的 Token 到最上层的 Agent,构建清晰的 AI 知识体系。
一、概念全景图
先看全局,再逐层深入: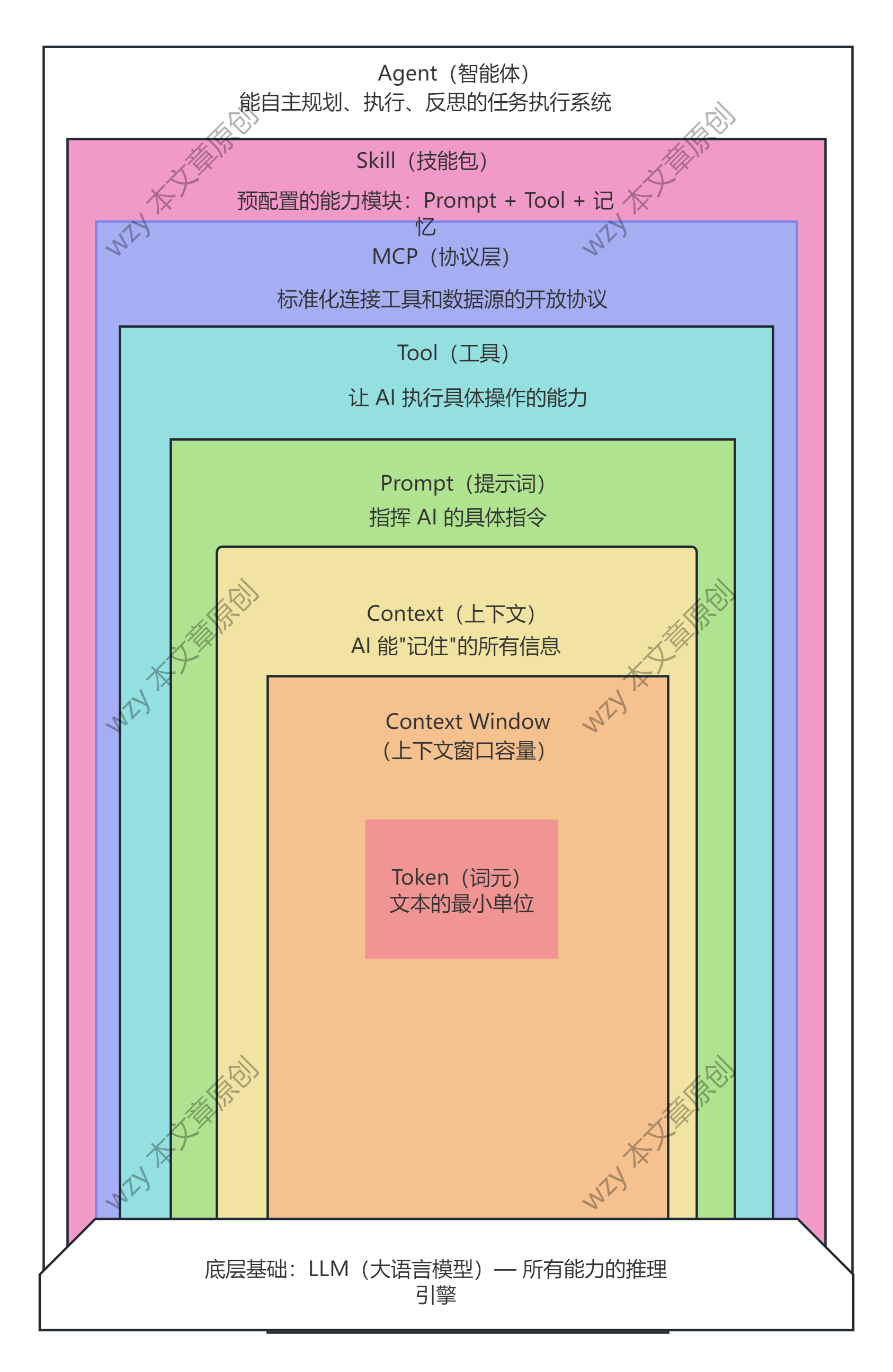
二、第一层:Token(词元)— 最小语言单位
2.1 什么是 Token?
Token 是大模型处理文本的最小语言单位,是连接人类文字与机器数字的桥梁。
2.2 为什么需要 Token?
大模型本质是一个庞大的数学函数:
人类文字 → Tokenizer(分词器)→ Token ID(数字)→ 矩阵运算 → 输出数字 → Token → 人类文字
大模型根本不认识人类文字,它只认识数字。Token 就是文字和数字之间的翻译。
2.3 Token 不等于"词"
| 文本 | Token 数量 | 说明 |
|---|---|---|
| “工作坊” | 2 个 | “工作” + “坊” |
| “helpful” | 2 个 | “help” + “ful” |
| “✓” | 3 个 | 特殊符号需要更多 Token |
| “人工智能” | 2-4 个 | 取决于分词器 |
估算标准:
- 英文:1 Token ≈ 0.75 个单词
- 中文:1 Token ≈ 1.5~2 个汉字
2.4 Token 的影响
| 场景 | 影响 |
|---|---|
| 计费 | 大模型按 Token 计费,Token 越多越贵 |
| 性能 | Token 越多,推理时间越长 |
| 上下文 | Token 数量受 Context Window 限制 |
三、第二层:Context(上下文)与 Context Window
3.1 什么是 Context?
Context 是 AI 能"记住"的所有信息的总和,包括:
| 组成部分 | 说明 |
|---|---|
| 用户问题 | 当前输入的内容 |
| 对话历史 | 之前的对话记录 |
| System Prompt | 系统预设的人设和规则 |
| 工具定义 | 可用工具的描述信息 |
| AI 正在输出的内容 | 流式输出时也在消耗 Context |
3.2 什么是 Context Window?
Context Window 是 Context 能容纳的最大 Token 数量,相当于 AI 的"短期记忆容量"。
| 模型 | Context Window | 相当于 |
|---|---|---|
| GPT-4 | 128K Token | 约 10 万单词 |
| Claude 3.5 | 200K Token | 约 30 万汉字 |
| Claude 3.1 Pro | 100 万 Token | 约《哈利波特》全集 |
3.3 为什么重要?
Context Window 溢出后,通常采用 FIFO(先进先出)策略:最早的对话会被"遗忘"。
后果:
- AI 忘记之前的约定
- 回答与上下文不一致
- 复杂推理链断裂
类比:Context Window 就像一块白板,写满了就得擦掉最早的内容。
四、第三层:Prompt(提示词)— 指挥 AI 的语言
4.1 什么是 Prompt?
Prompt 是用户与大模型沟通的指令,是你指挥 AI 干活的语言。
4.2 两种 Prompt 类型
| 类型 | 定义 | 来源 | 示例 |
|---|---|---|---|
| User Prompt | 用户输入的具体任务 | 用户 | “帮我写一首关于秋天的诗” |
| System Prompt | 预设的人设和规则 | 开发者配置 | “你是一个专业的诗人,擅长写古诗…” |
4.3 Prompt Engineering 的本质
很多人把"提示词工程"当作黑科技,其实本质就是:把话说清楚。
❌ 模糊的 Prompt:
"帮我写一首诗"
→ AI 可能写古诗、现代诗、打油诗,随机发挥
✅ 清晰的 Prompt:
"请写一首五言绝句,主题是秋天的落叶,风格要悲凉,押平水韵"
→ AI 明确知道要做什么
4.4 Prompt 在 Context 中的位置
Context 结构:
┌─────────────────────────────────────────┐
│ System Prompt(人设规则) │
│ "你是一个专业的代码审查助手..." │
├─────────────────────────────────────────┤
│ 对话历史 │
│ User: "帮我检查这段代码" │
│ AI: "好的,请提供代码..." │
├─────────────────────────────────────────┤
│ User Prompt(当前任务) │
│ "检查这个函数的时间复杂度" │
├─────────────────────────────────────────┤
│ 工具定义 │
│ 可用工具列表... │
└─────────────────────────────────────────┘
五、第四层:Tool(工具)— 让 AI"动手"的能力
5.1 为什么需要 Tool?
大模型有个致命缺陷:纸上谈兵。
- 无法获取实时信息(天气、股价、新闻)
- 无法执行实际操作(读写文件、调用 API)
- 知识截止到训练数据,无法更新
Tool 让 AI 从"纸上谈兵"变成真正能动手做事。
5.2 Tool 的工作流程
用户:"今天上海天气怎么样?"
↓
AI:"我需要调用天气工具"
↓
调用 Tool(城市="上海",日期="今天")
↓
Tool 执行:请求气象局 API
↓
返回结果:{"temp": 25, "weather": "晴"}
↓
AI 生成回答:"今天上海晴,气温 25°C,适合出行。"
5.3 常见 Tool 类型
| 类型 | 功能 | 示例 |
|---|---|---|
| 搜索工具 | 搜索互联网 | Google Search、Bing Search |
| 计算工具 | 执行代码 | Python 解释器、Shell 执行 |
| 数据工具 | 读写数据库 | SQL 查询、MongoDB 操作 |
| 文件工具 | 读写文件 | 文档处理、代码编辑 |
| API 工具 | 调用外部服务 | 天气 API、支付 API |
5.4 Tool 的定义格式
{
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"},
"date": {"type": "string", "description": "日期,如'今天'"}
},
"required": ["city"]
}
}
六、第五层:MCP(模型上下文协议)— 标准化的工具连接
6.1 什么是 MCP?
MCP(Model Context Protocol) 是 Anthropic 发布的开放协议,解决"如何让不同 Agent 以统一方式调用工具"的问题。
6.2 为什么需要 MCP?
没有 MCP 之前:
工具开发者需要:
├── 为 LangChain 写一套适配代码
├── 为 OpenAI 写一套适配代码
├── 为 Claude 写一套适配代码
└── 为其他框架各写一套...
→ 重复劳动,维护成本高
有了 MCP 之后:
工具开发者只需要:
└── 写一个 MCP Server
→ 所有支持 MCP 的 Agent 都能使用
6.3 MCP 的三种原语
| 原语 | 作用 | 示例 |
|---|---|---|
| Tools | 可执行的操作 | 读文件、查数据库、调用 API |
| Resources | 可读取的数据 | 文档内容、配置文件、实时状态 |
| Prompts | 预定义的提示模板 | 代码审查模板、报告生成模板 |
6.4 MCP vs 直接 API 调用
| 维度 | MCP | 直接 API |
|---|---|---|
| 接入成本 | 一次接入,通用 | 每个框架单独适配 |
| 上下文感知 | 支持 Resources | 无 |
| 生态复用 | 5000+ 现成 Server | 需自行开发 |
| 适用场景 | 需要跨框架复用 | 一次性简单调用 |
七、第六层:Skill(技能)— 预配置的能力包
7.1 什么是 Skill?
Skill 是针对特定任务的预配置能力包,把大模型配置、Prompt、工具、记忆等打包在一起,形成可复用的功能模块。
7.2 Skill 的组成
一个 Skill 通常包含:
┌─────────────────────────────────────────┐
│ SKILL.md(核心指令文件) │
│ ├── YAML 元数据(名称、描述、触发词) │
│ └── Markdown 正文(工作流程、规则) │
├─────────────────────────────────────────┤
│ scripts/(可执行脚本) │
│ references/(参考文档) │
│ assets/(资源文件) │
└─────────────────────────────────────────┘
7.3 Skill vs Tool vs Agent
| 对比维度 | Tool | Skill | Agent |
|---|---|---|---|
| 本质 | 单个函数 | 能力包 | 执行系统 |
| 粒度 | 最细 | 中等 | 最粗 |
| 自主性 | 无(被动调用) | 低(预配置流程) | 高(自主决策) |
| 复用性 | 高 | 高 | 中 |
| 示例 | read_file() |
csdn-publisher |
Claude Code |
7.4 Skill 的加载机制
渐进式加载(节省 Token):
┌─────────────────────────────────────────┐
│ 平时:只看名称+描述(~100 Token) │
│ → Claude 判断是否相关 │
├─────────────────────────────────────────┤
│ 需要时:加载完整 SKILL.md │
│ → 执行预定义的工作流程 │
├─────────────────────────────────────────┤
│ 完成后:可以卸载详细内容 │
│ → 只保留结果 │
└─────────────────────────────────────────┘
八、第七层:Agent(智能体)— 自主的任务执行者
8.1 什么是 Agent?
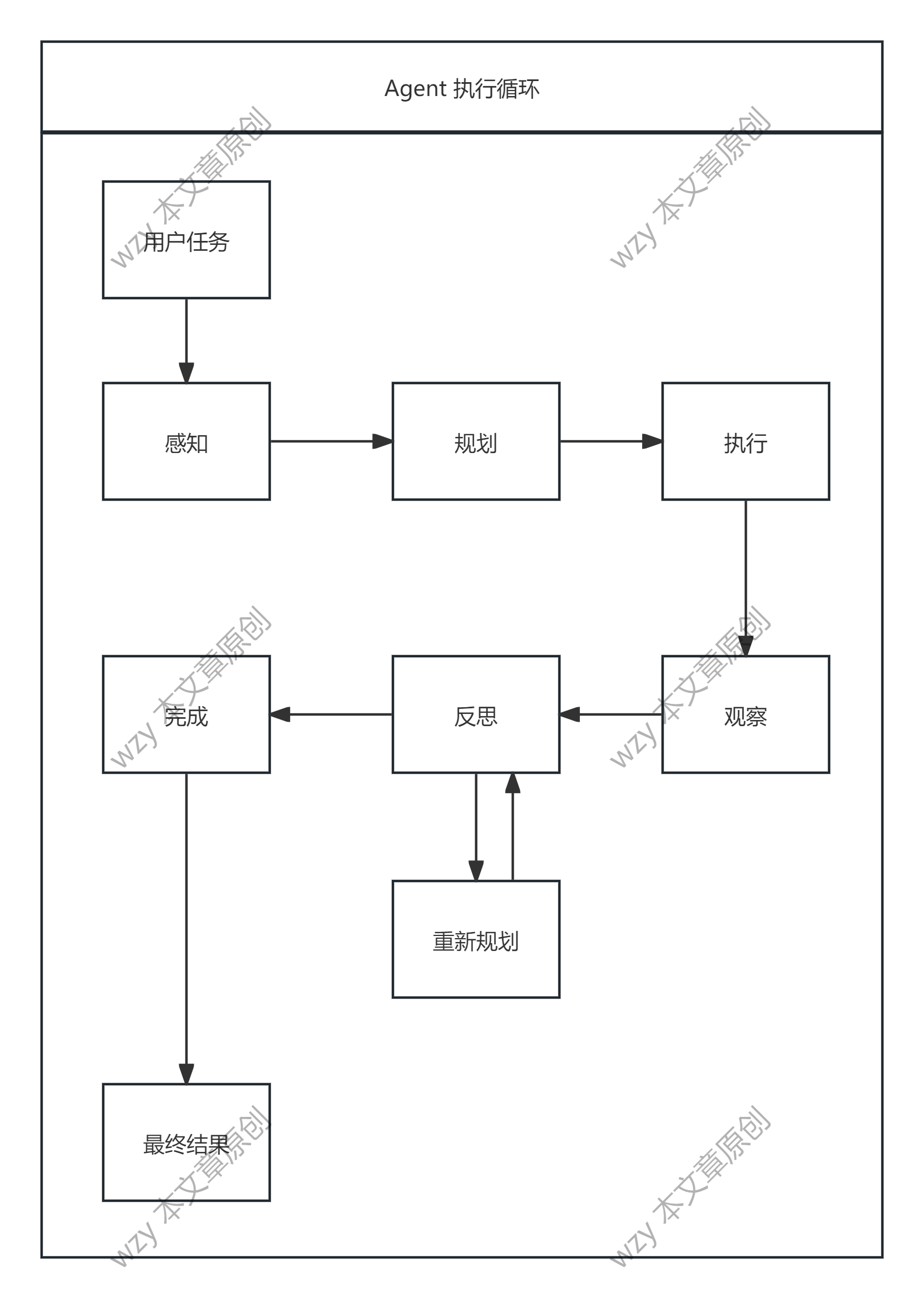
Agent 是具备"感知-决策-执行-反思"循环的 AI 应用架构,不是新模型,而是新的工程模式。
8.2 Agent vs 普通 LLM 调用
普通 LLM 调用:
用户问题 → LLM → 回答
(一次往返,单步推理)
Agent 调用:
用户问题 → LLM 规划 → 调用 Tool → 观察结果 → 调整策略 → 调用 Tool → ... → 最终回答
(多步循环,自主决策)
8.3 Agent 的四大核心能力
| 能力 | 说明 | 示例 |
|---|---|---|
| 感知 | 理解用户意图和环境信息 | 解析"帮我部署项目"的意图 |
| 规划 | 把复杂任务拆解成多个步骤 | 制定:拉代码 → 跑测试 → 构建 → 部署 |
| 执行 | 调用工具、访问 API、操作文件 | 执行 git pull、npm build |
| 反思 | 评估结果、调整策略、重新规划 | 测试失败 → 分析原因 → 修复代码 |
8.4 Agent 的工作循环
8.5 SubAgent(子智能体)
Agent 可以调用 SubAgent 来处理子任务:
主 Agent:"帮我开发一个用户登录功能"
│
├── SubAgent 1:负责数据库设计
│ └── 任务完成后销毁
│
├── SubAgent 2:负责 API 开发
│ └── 任务完成后销毁
│
└── SubAgent 3:负责测试用例编写
└── 任务完成后销毁
九、LLM(大语言模型)— 所有能力的推理引擎
9.1 什么是 LLM?
LLM(Large Language Model) 是所有 AI 应用的推理核心,负责语言理解、推理和生成。
9.2 代表性模型
| 模型 | 厂商 | 特点 |
|---|---|---|
| Claude 3.5 | Anthropic | 长上下文、代码能力强 |
| GPT-4o | OpenAI | 多模态、生态完善 |
| Gemini | 多模态、搜索整合 | |
| DeepSeek V3 | DeepSeek | 开放权重、性价比高 |
9.3 LLM 在架构中的位置
四层架构:
┌─────────────────────────────────────────┐
│ 外部工具/数据源 │ ← 文件、数据库、API
├─────────────────────────────────────────┤
│ MCP / Skills(能力封装层) │ ← 标准化协议 & 能力包
├─────────────────────────────────────────┤
│ Agent(执行循环层) │ ← 感知-决策-执行-反思
├─────────────────────────────────────────┤
│ LLM(推理核心层) │ ← 语言理解与推理
└─────────────────────────────────────────┘
十、概念关系速查表
| 概念 | 一句话定义 | 依赖关系 |
|---|---|---|
| Token | 文本的最小处理单位 | LLM 的基础输入单元 |
| Context | AI 能"记住"的所有信息 | 由多个 Token 组成 |
| Context Window | Context 的最大容量 | 限制 Token 总数 |
| Prompt | 指挥 AI 的指令 | 放在 Context 中 |
| Tool | 让 AI 执行操作的函数 | 被 Prompt 调用 |
| MCP | 标准化的工具连接协议 | 规范 Tool 的接入方式 |
| Skill | 预配置的能力包 | 组合 Prompt + Tool |
| Agent | 自主的任务执行系统 | 调用 Skill + Tool |
| LLM | 所有能力的推理引擎 | 最底层基础 |
十一、实战案例:一个完整请求的旅程
让我们追踪一个真实请求,看这些概念如何协作:
用户输入:"帮我分析这个项目的代码结构"
Step 1: Token 化
"帮我分析这个项目的代码结构" → [Token1, Token2, Token3, ...]
Step 2: 构建 Context
Context = System Prompt + 对话历史 + 用户问题 + 可用工具列表
Step 3: 检查 Context Window
确保 Token 总量不超过限制
Step 4: Agent 接收任务
Agent 分析:"需要读取项目文件,分析目录结构"
Step 5: 调用 Skill
如果存在 code-analyzer Skill,加载并执行
Step 6: 调用 MCP Server
通过 MCP 协议调用 filesystem Server 读取文件
Step 7: Tool 执行
Tool: read_directory() → 返回文件列表
Step 8: LLM 推理
LLM 分析文件结构,生成架构图描述
Step 9: 返回结果
"项目采用 MVC 架构,包含以下模块:..."
总结
核心认知要点
- Token 是基石:一切从 Token 开始,Token 决定成本和性能
- Context 是记忆:Context Window 是记忆的边界
- Prompt 是指挥:清晰的表达是高效沟通的基础
- Tool 是手脚:让 AI 从"会说"变成"会做"
- MCP 是桥梁:标准化连接工具和数据
- Skill 是能力包:预配置的即用型功能模块
- Agent 是大脑:自主规划、执行、反思的系统
- LLM 是引擎:所有能力的推理核心
学习建议
- 从 Token 开始理解:这是所有概念的基础
- 动手实践 Tool 调用:理解"AI 如何做事"
- 尝试构建一个 Skill:理解"能力如何封装"
- 体验 Agent 工作流:理解"自主执行"的含义
参考资料
本文首发于 CSDN,希望这张认知地图能帮你建立清晰的 AI 知识体系。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)