
Clawdbot代理平台部署教程:Qwen3:32B与Clawdbot Metrics模块集成实现实时性能监控
本文介绍了如何在星图GPU平台上自动化部署Clawdbot整合qwen3:32b代理网关与管理平台镜像,实现AI代理的统一管理与实时性能监控。该方案通过集成Qwen3大语言模型与Metrics监控模块,可实时追踪模型响应时间、资源使用情况等关键指标,适用于构建本地化AI代理管理与监控平台。
Clawdbot代理平台部署教程:Qwen3:32B与Clawdbot Metrics模块集成实现实时性能监控
1. 项目概述与核心价值
Clawdbot是一个统一的AI代理网关与管理平台,为开发者提供直观的界面来构建、部署和监控自主AI代理。这个平台集成了聊天界面、多模型支持和强大的扩展系统,让AI代理的管理变得简单高效。
本次教程将重点介绍如何将Qwen3:32B大模型与Clawdbot平台集成,并配置Metrics模块实现实时性能监控。通过这个方案,你可以:
- 在统一平台上管理多个AI模型和代理
- 实时监控模型性能和资源使用情况
- 快速部署和测试不同配置
- 获得直观的可视化监控界面
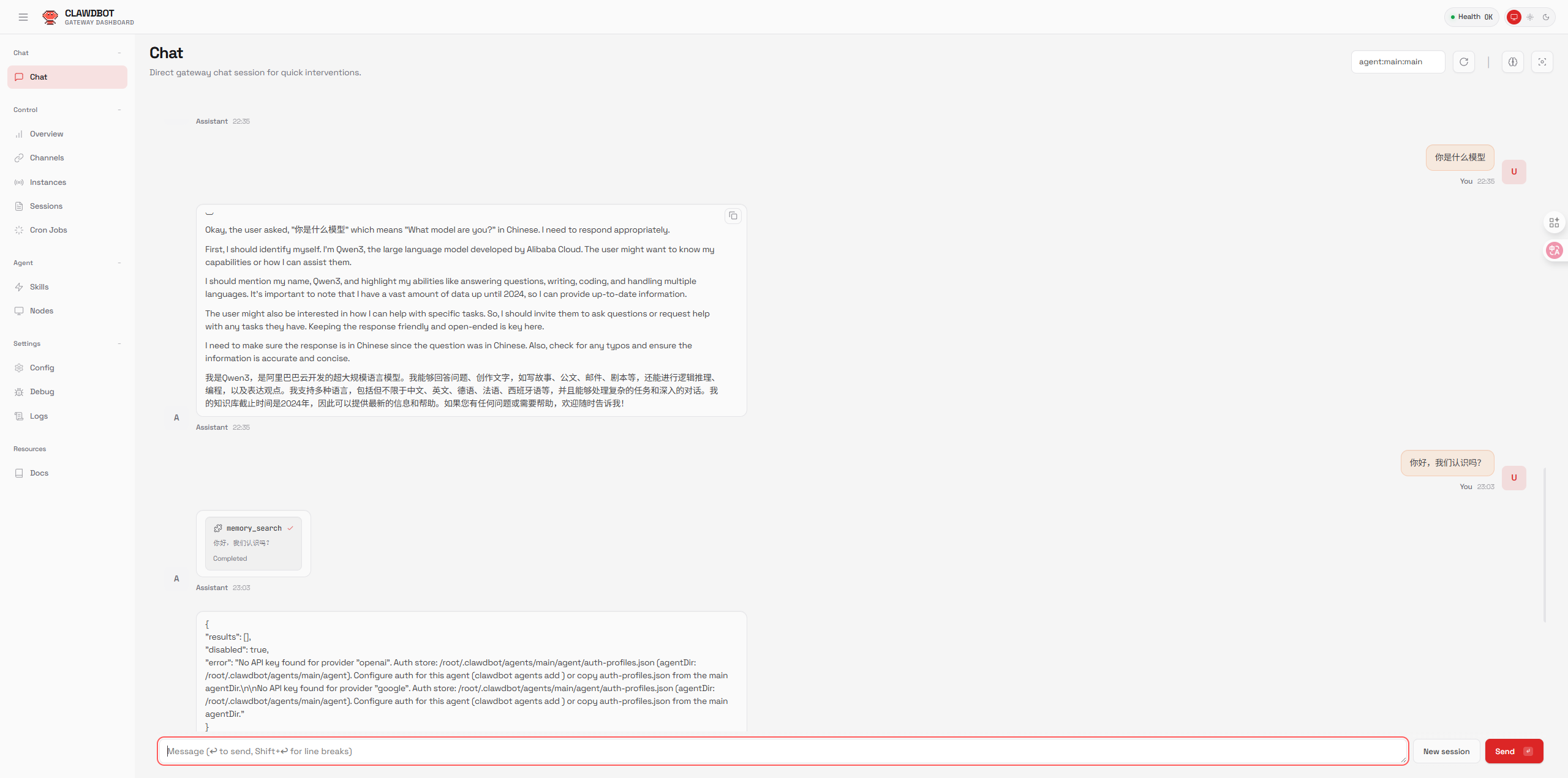
2. 环境准备与快速部署
2.1 系统要求
在开始部署前,请确保你的系统满足以下要求:
- 操作系统:Linux Ubuntu 18.04+ 或 Windows WSL2
- 内存:至少32GB RAM(推荐64GB)
- GPU:NVIDIA GPU with 24GB+ VRAM(Qwen3:32B模型需求)
- 存储:至少50GB可用空间
- 网络:稳定的互联网连接
2.2 安装依赖组件
首先安装必要的依赖包:
# 更新系统包
sudo apt update && sudo apt upgrade -y
# 安装基础工具
sudo apt install -y curl wget git python3 python3-pip docker.io
# 安装NVIDIA容器工具包(如果使用GPU)
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
2.3 部署Ollama和Qwen3:32B模型
Ollama是一个本地大模型运行框架,我们将使用它来部署Qwen3:32B模型:
# 安装Ollama
curl -fsSL https://ollama.ai/install.sh | sh
# 拉取Qwen3:32B模型(需要较长时间和足够存储空间)
ollama pull qwen3:32b
# 启动Ollama服务
ollama serve
3. Clawdbot平台部署与配置
3.1 获取和安装Clawdbot
# 克隆Clawdbot仓库
git clone https://github.com/clawdbot/clawdbot.git
cd clawdbot
# 安装Python依赖
pip install -r requirements.txt
# 安装Clawdbot核心包
pip install -e .
3.2 配置模型接入
在Clawdbot配置文件中添加Qwen3:32B模型配置:
{
"my-ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama",
"api": "openai-completions",
"models": [
{
"id": "qwen3:32b",
"name": "Local Qwen3 32B",
"reasoning": false,
"input": ["text"],
"contextWindow": 32000,
"maxTokens": 4096,
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
}
}
]
}
}
3.3 启动Clawdbot网关服务
# 启动网关服务
clawdbot onboard
服务启动后,你将看到类似下面的输出,包含访问URL:
Gateway started at: https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net
4. 访问配置与权限设置
4.1 首次访问配置
初次访问Clawdbot平台时,你会遇到token缺失的提示:
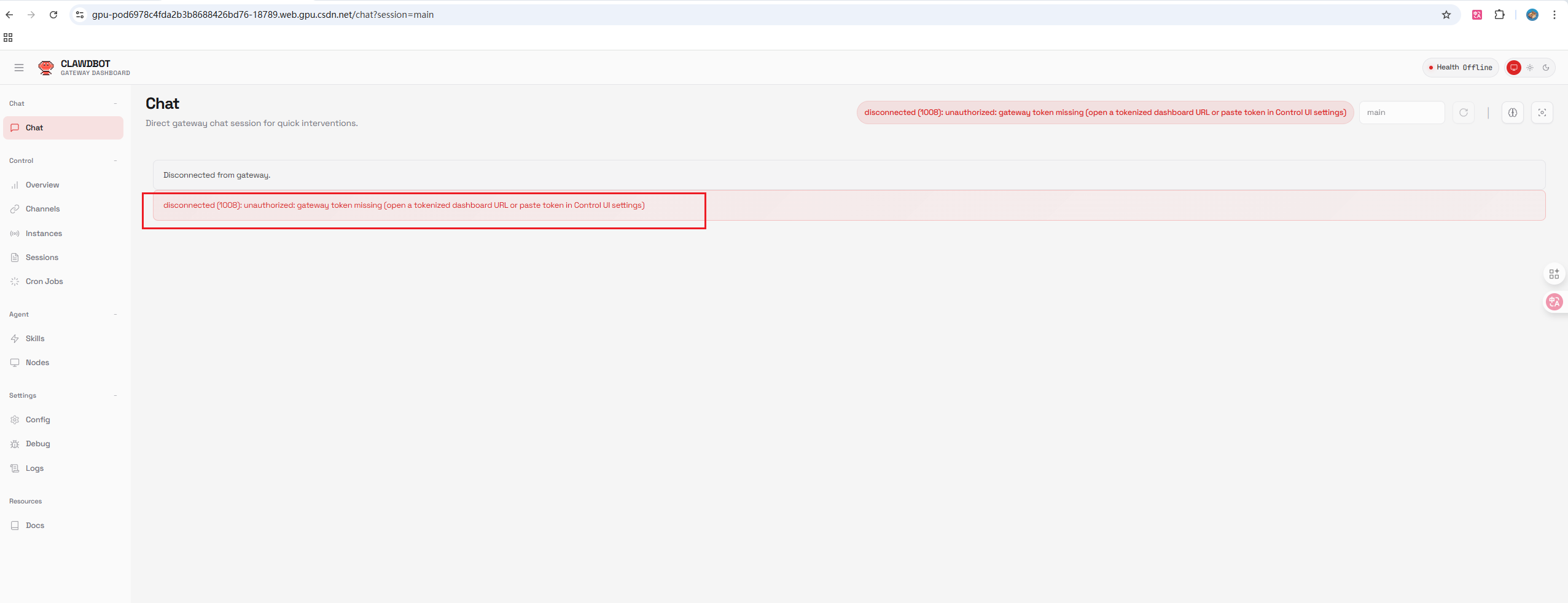
错误信息显示:disconnected (1008): unauthorized: gateway token missing
4.2 正确配置访问URL
按照以下步骤配置正确的访问URL:
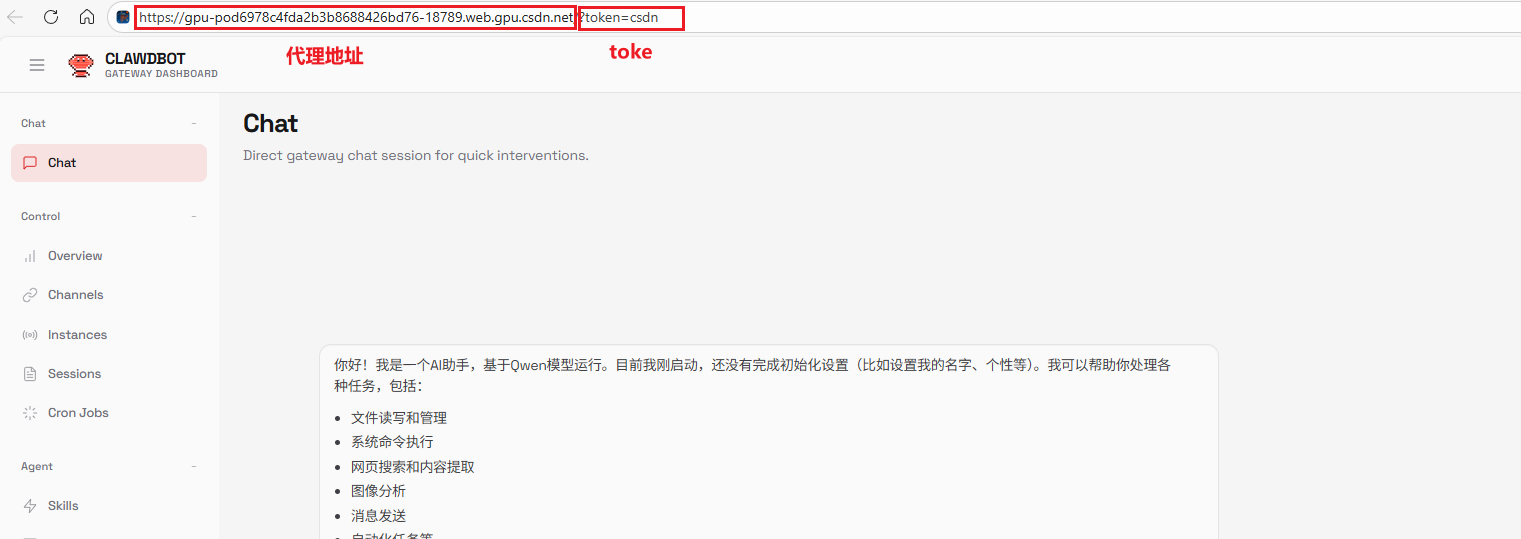
-
获取初始URL(系统提供的):
https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/chat?session=main -
删除尾部参数:
删除:chat?session=main -
添加token参数:
添加:?token=csdn -
最终的正确URL:
https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/?token=csdn
使用这个正确的URL访问后,系统会记住token设置,后续可以直接从控制台快捷方式启动。
5. Metrics模块配置与性能监控
5.1 启用监控功能
Clawdbot内置了强大的Metrics模块,可以实时监控模型性能和系统状态。在配置文件中启用监控:
{
"metrics": {
"enabled": true,
"port": 9090,
"interval": 30,
"endpoints": [
{
"name": "qwen3-32b-performance",
"url": "http://127.0.0.1:11434/api/health",
"type": "json"
}
]
}
}
5.2 监控指标说明
Clawdbot Metrics模块监控以下关键指标:
- 响应时间:模型处理请求的延迟
- 吞吐量:每秒处理的请求数
- 错误率:请求失败的比例
- 资源使用:CPU、内存、GPU使用情况
- 令牌消耗:输入和输出令牌数量
5.3 可视化监控界面
配置完成后,你可以通过以下方式访问监控界面:
- 内置监控面板:在Clawdbot管理界面中找到"Metrics"选项卡
- Grafana集成:将数据导出到Grafana进行高级可视化
- API访问:通过REST API获取监控数据
# 获取监控数据示例
curl http://localhost:9090/metrics
6. 实际应用测试与验证
6.1 测试模型连接
首先验证Qwen3:32B模型是否正确连接:
import requests
import json
# 测试Ollama API连接
def test_ollama_connection():
url = "http://127.0.0.1:11434/api/generate"
headers = {"Content-Type": "application/json"}
data = {
"model": "qwen3:32b",
"prompt": "你好,请简单介绍一下自己",
"stream": False
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
print("连接成功!模型响应:")
print(response.json()["response"])
else:
print(f"连接失败,状态码:{response.status_code}")
test_ollama_connection()
6.2 性能基准测试
运行简单的性能测试来评估模型表现:
# 使用Clawdbot内置测试工具
clawdbot benchmark --model qwen3:32b --requests 100 --concurrency 10
测试结果将显示在控制台,同时也会记录到Metrics模块中。
7. 常见问题与解决方案
7.1 模型加载问题
问题:Qwen3:32B模型加载失败或响应缓慢
解决方案:
# 检查GPU内存是否足够
nvidia-smi
# 如果内存不足,考虑使用量化版本
ollama pull qwen3:32b:q4_0
7.2 网络连接问题
问题:Clawdbot无法连接到Ollama服务
解决方案:
# 检查Ollama服务状态
systemctl status ollama
# 重启Ollama服务
systemctl restart ollama
# 检查端口是否开放
netstat -tlnp | grep 11434
7.3 性能监控数据异常
问题:Metrics模块显示异常数据或无法收集数据
解决方案:
# 检查Metrics模块配置
clawdbot config validate
# 重启Metrics服务
clawdbot metrics restart
8. 优化建议与最佳实践
8.1 性能优化
对于24G显存环境,Qwen3:32B的运行体验可能不是特别理想,以下是一些优化建议:
- 使用量化模型:选择q4或q8量化版本减少显存占用
- 调整批处理大小:减少同时处理的请求数量
- 启用缓存优化:利用Clawdbot的缓存机制减少重复计算
8.2 监控配置优化
{
"metrics": {
"retention": "7d",
"alerting": {
"enabled": true,
"rules": [
{
"alert": "HighResponseTime",
"expr": "rate(clawdbot_response_time_seconds_sum[5m]) > 0.5",
"for": "10m",
"labels": {
"severity": "warning"
},
"annotations": {
"summary": "高响应时间警报",
"description": "API响应时间超过阈值"
}
}
]
}
}
}
8.3 扩展性考虑
如果需要更好的交互体验,考虑以下方案:
- 升级硬件:使用更大显存的GPU(40G+)
- 分布式部署:将模型部署在多台机器上实现负载均衡
- 模型优化:使用更新的Qwen模型版本,可能有效果更好的优化
9. 总结
通过本教程,你成功完成了Clawdbot平台与Qwen3:32B模型的集成部署,并配置了完整的性能监控系统。现在你拥有:
- 统一的AI代理管理平台:通过Clawdbot集中管理所有AI模型和代理
- 本地部署的大模型:Qwen3:32B在Ollama上稳定运行
- 实时性能监控:Metrics模块提供全面的性能指标和可视化
- 可扩展的架构:易于添加更多模型和功能模块
这个解决方案特别适合需要本地部署大模型并要求实时监控的场景,为AI应用开发和运维提供了完整的基础设施。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 11
11 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)