
从 OpenClaw 源码解析:如何构建一个 Agent
OpenClaw 是一个跑在生产环境里的 AI Agent 框架,代码量不小,但核心就四个模块——执行循环、工具系统、记忆系统、插件系统。OpenClaw 的 73 个扩展——Discord 通道、Anthropic Provider 这些——全走统一的插件 SDK,没有硬编码的特殊通道。里动态拼装——运行时信息(OS、时区、模型名)、可用工具列表、通道能力描述、用户自定义指令,按需注入。):对话
本文假设你熟悉 TypeScript 和 LLM API 的基本概念。如果你还不了解 Function Calling,建议先阅读 OpenAI Tool Use 文档。
https://platform.openai.com/docs/guides/function-calling
OpenClaw 是一个跑在生产环境里的 AI Agent 框架,代码量不小,但核心就四个模块——执行循环、工具系统、记忆系统、插件系统。这篇文章把每个模块拆开看看里面怎么写的,最后整理一份自己做 Agent 时可以参考的清单。
一、先看全景

开始翻代码之前,先搞清楚 OpenClaw 大概长什么样。一句话说:
Gateway 接收消息 → Agent 循环调用 LLM + 工具 → 记忆系统提供上下文 → 插件扩展一切。
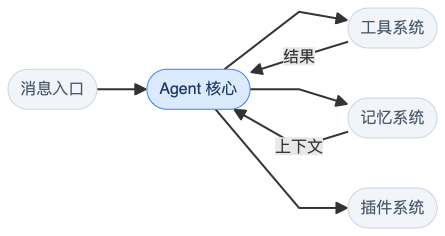
四个模块各管各的,耦合度不高。后面逐个看,先扫一眼目录结构:
|
目录 |
一句话说明 |
|---|---|
src/agents/ |
Agent 执行循环、工具注册、模型管理 |
src/memory/ |
记忆索引、嵌入向量、混合检索 |
src/gateway/ |
WebSocket 网关、认证、RPC |
src/plugin-sdk/ |
插件 SDK、Hook 系统 |
src/channels/ |
通道抽象层(状态机、路由、线程绑定) |
extensions/ |
73 个插件(通道 / LLM Provider / 工具扩展) |
二、Agent 核心循环

很多教程里的 Agent 就是一个 while 循环加一次 LLM 调用。但真跑在线上的 Agent,得处理网络抖动、API 限流、上下文爆掉、工具死循环这些破事。OpenClaw 的核心入口在 src/agents/pi-embedded-runner/run.ts。
2.1 主干逻辑
把容错代码全去掉,核心循环其实就这点东西:
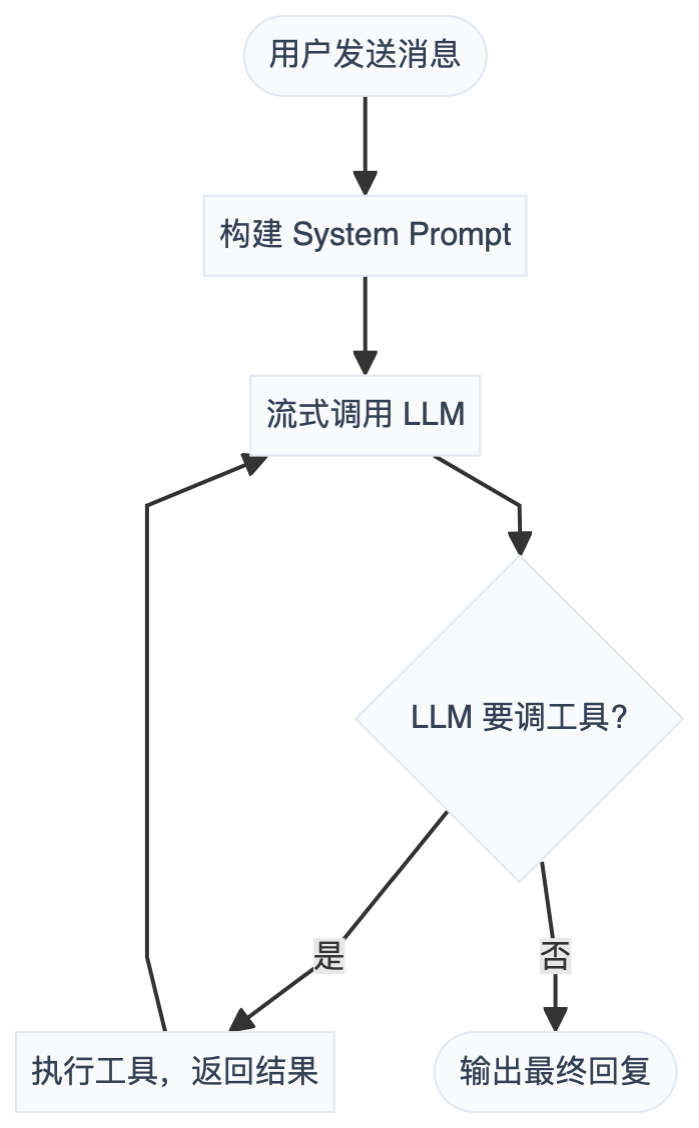
LLM 决定要不要调工具,调了就把结果喂回去,来回循环,直到 LLM 觉得可以直接回复了。这个"工具循环"是所有 Agent 框架的共同骨架。
2.2 加上容错
实际跑起来,上面的循环随时可能断。OpenClaw 加了三层防护:
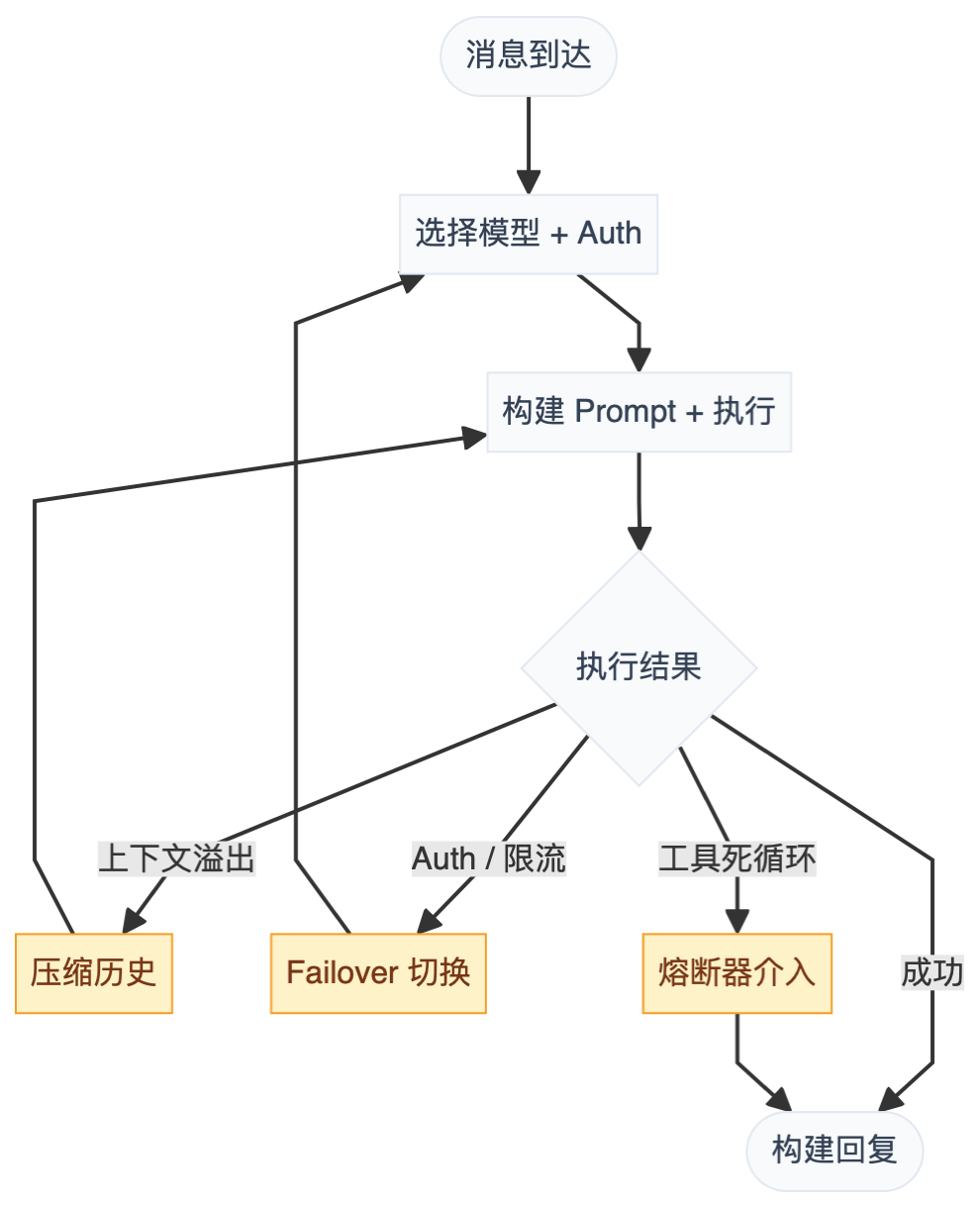
分别是:
-
上下文压缩(
compact.ts):对话太长超出模型窗口时,用 Context Engine 对历史做摘要,保留关键信息,不是直接砍掉前面的消息。 -
模型 Failover(
run.ts):Auth 过期、API 限流、余额不足,自动冷却当前 Auth Profile,换一个继续。整个重试循环上限 160 次,Auth 还能提前 5 分钟自动续期。 -
工具熔断器(
tool-loop-detection.ts):用 30 次调用的滑动窗口检测三种异常——同一工具反复调、两个工具乒乓互调、轮询类工具没进展。10 次注入警告提示词,20 次强制提示停下,30 次直接终止。
2.3 流式处理
Agent 不会等 LLM 把整段话说完才动,而是通过事件订阅(pi-embedded-subscribe.ts)边收边处理。核心状态大概长这样:
// src/agents/pi-embedded-subscribe.ts — 简化后的核心状态
{
assistantTexts: string[] // 逐步累积的回复文本
toolMetas: ToolMetaEntry[] // 每次工具调用的元数据
blockBuffer: string // 流式分块缓冲区
blockState: {
thinking: boolean // 当前是否在 <think> 标签内
final: boolean // 当前是否在 <final> 标签内
}
messagingToolSentTexts: string[] // 已通过消息工具发送的文本(去重用,上限 200 条)
}事件处理器监听 message_start / message_update / message_end / tool_execution_start / tool_execution_end 这些事件,在语义边界处切分文本块推给用户。所以用户不用等 Agent 跑完所有工具调用才看到第一个字。
三、工具系统
LLM 只会生成文本,工具系统让它能读写文件、跑命令、搜网页、发消息——光会说不行,还得能干活。
3.1 工具长什么样
一个工具就是一个 JSON Schema 加一个执行函数,没什么花活:
// src/agents/tools/ 下的典型工具定义
{
name: "web_search", // LLM 看到的工具名
description: "Search the web", // LLM 据此判断何时调用
parameters: Type.Object({ // JSON Schema,LLM 按此生成参数
query: Type.String()
}),
async execute(toolCallId, args, signal) {
const results = await search(args.query)
return { content: [{ type: "text", text: results }] }
}
}src/agents/openclaw-tools.ts 注册了所有内置工具,按能力域分类:
|
能力域 |
代表工具 |
做什么 |
|---|---|---|
|
文件操作 |
read
, |
读写代码和配置文件 |
|
命令执行 |
exec
, |
在沙箱中运行 Shell 命令 |
|
Web 交互 |
web_search
, |
搜索引擎查询、浏览器自动化 |
|
消息通信 |
message
, |
向 Discord / Slack 等通道发消息 |
|
多媒体 |
image_generate
, |
图像生成、语音合成 |
|
子 Agent |
sessions_spawn |
派生子 Agent 执行子任务 |
3.2 安全管线
工具不是 LLM 说调就能调的,每次调用都要过一条管线:

-
权限检查(
tool-policy.ts):cron这种工具只有 Owner 能调,其他人直接拒绝。 -
策略过滤:根据消息来源和模型 Provider 的兼容性,动态裁剪可用工具列表。
-
循环检测(
tool-loop-detection.ts):就是前面说的 30 次滑动窗口熔断器。 -
沙箱执行:
exec类工具跑在隔离沙箱里,改文件、跑系统命令这种操作需要用户点确认。
3.3 动态注册
除了内置工具,插件可以根据运行时状态动态注册:
api.registerTool((ctx: OpenClawPluginToolContext) => {
if (!ctx.config.featureEnabled) return null // 条件不满足时不注册
return {
name: "conditional_tool",
parameters: Type.Object({ query: Type.String() }),
async execute(toolCallId, args) { /* ... */ }
}
})工具集可以根据用户配置、通道类型、模型能力等条件灵活调整,不用一股脑全暴露给 LLM。
四、记忆系统

没有记忆的 Agent 每次对话都是从头来。记忆系统让 Agent 能跨会话记住用户偏好、项目背景和之前做过的决定。OpenClaw 的记忆系统是整个项目里最有意思的部分。
4.1 就两件事:存和取
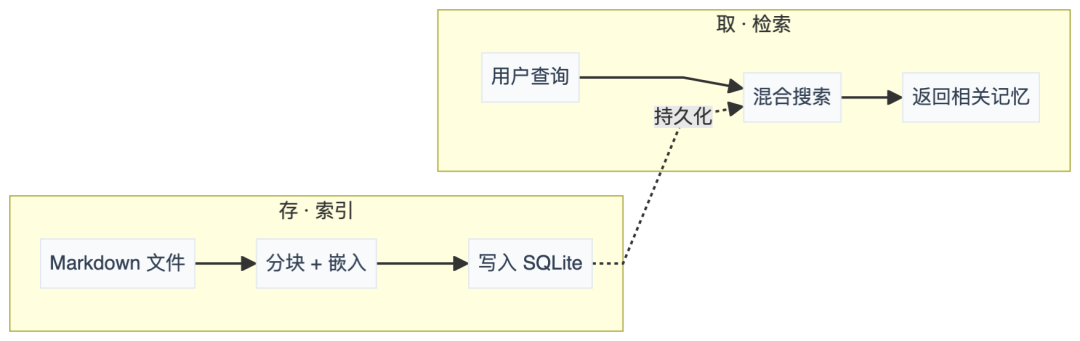
看着简单,但每个环节都有不少细节。
4.2 存:从 Markdown 到向量
数据从哪来
两个来源:
-
memory 源:工作区中的
MEMORY.md和memory/*.md文件,通常由用户或 Agent 主动维护 -
sessions 源:Agent 的历史会话记录(JSONL 格式),自动采集
索引管线
文件发现后,经过变更检测、分块、嵌入、写入四个阶段:
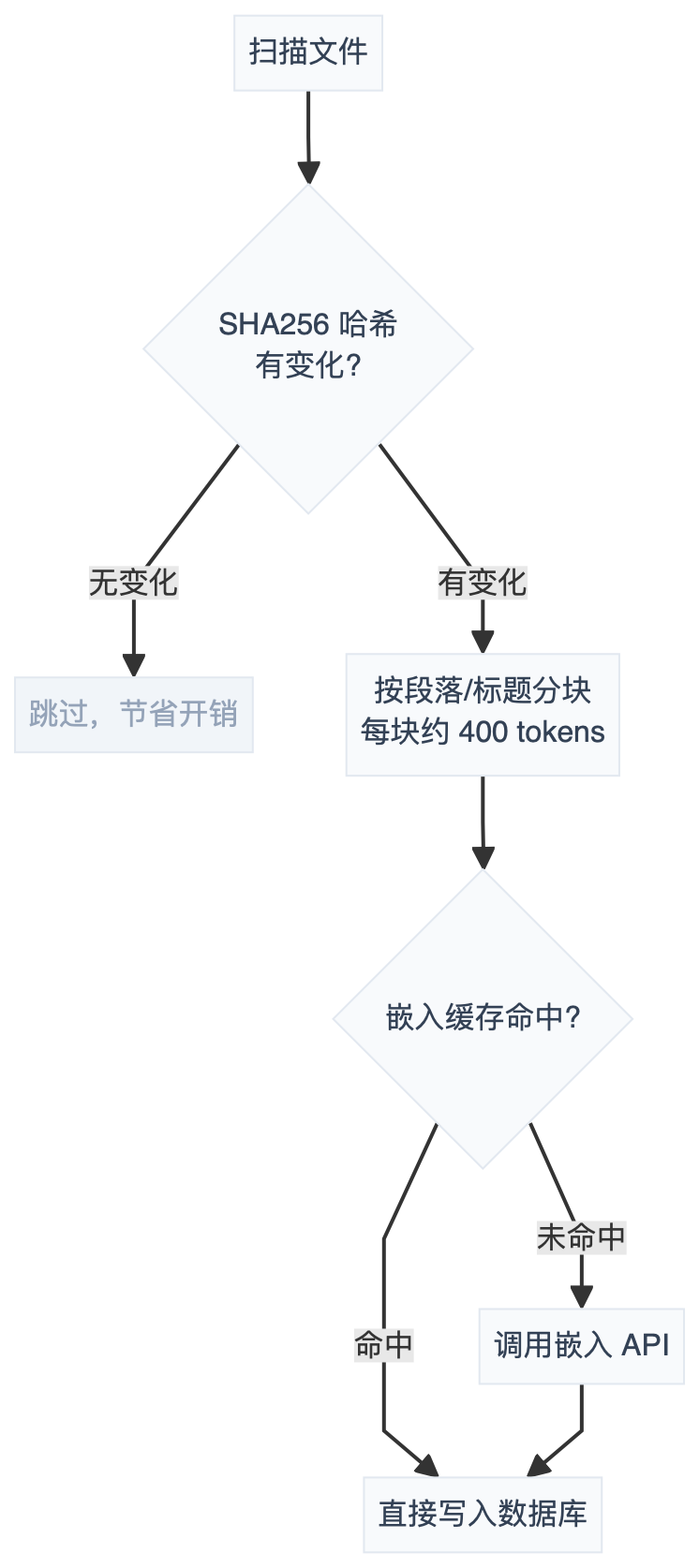
几个值得注意的点:
-
增量索引:用 SHA256 哈希检测文件有没有变,只处理改过的文件,不用每次全量重建。
-
嵌入缓存:
embedding_cache表按内容哈希去重,同样的文本不会重复调嵌入 API。缓存满了自动清理旧的。 -
Batch 处理:支持 OpenAI / Gemini / Voyage 的 Batch API 批量生成向量。Batch 连续挂 2 次就自动退回逐条调用,不影响整体可用性。
存在哪:SQLite Schema
每个 Agent 有自己的 SQLite 数据库:~/.openclaw/memory/{agentId}.sqlite。为什么用 SQLite 不用 Pinecone / Milvus?很简单——不需要额外装数据库服务,一个文件就是全部记忆,拷到另一台机器直接能用。sqlite-vec 扩展的向量搜索性能对这个场景完全够。
核心表结构(省略了部分字段):
-- 分块存储:文本 + 嵌入向量
CREATETABLE chunks (
idTEXT PRIMARY KEY, -- SHA256(source:path:line:hash:model)
pathTEXTNOTNULL, -- 源文件路径
sourceTEXTNOTNULL, -- 'memory' | 'sessions'
start_line INTEGERNOTNULL,
end_line INTEGERNOTNULL,
textTEXTNOTNULL, -- 分块原文
embedding TEXTNOTNULL, -- 向量,JSON float 数组
updated_at INTEGERNOTNULL
);
-- 向量索引:sqlite-vec 虚拟表
CREATEVIRTUALTABLE chunks_vec USING vec0(
idTEXT PRIMARY KEY,
embedding FLOAT[N] -- N = 嵌入维度(如 OpenAI 为 1536)
);
-- 全文索引:FTS5
CREATEVIRTUALTABLE chunks_fts USING fts5(text, id UNINDEXED, ...);
-- 嵌入缓存:按内容哈希去重
CREATETABLE embedding_cache (
provider TEXT, modelTEXT, provider_key TEXT, hashTEXT,
embedding TEXT, dims INTEGER, updated_at INTEGER,
PRIMARY KEY (provider, model, provider_key, hash)
);三张表分工明确:chunks 存原始数据,chunks_vec 做向量近邻搜索,chunks_fts 做关键词全文检索。
4.3 取:混合检索
纯向量搜索擅长语义匹配("怎么部署"能匹配到"上线流程"),但会漏掉精确关键词;纯全文搜索反过来。OpenClaw 把两者拼在一起,再加上时间衰减和去重排序,形成四步检索管线:
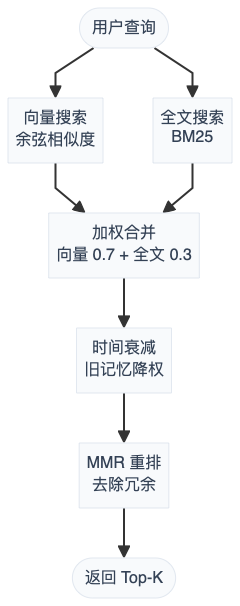
每一步在干什么:
Step 1 — 向量搜索:通过 sqlite-vec 计算查询向量与每个 chunk 向量的余弦相似度,返回 [0, 1] 范围的得分。
Step 2 — 全文搜索:FTS5 返回 BM25 排名(负数),归一化为 [0, 1]:
Step 3 — 加权合并:语义匹配权重给高一点,因为多数查询是模糊意图不是精确关键词:
Step 4 — 后处理:
-
时间衰减(
temporal-decay.ts): ,半衰期 30 天。带日期的文件(比如memory/2026-03-15.md)会随时间降权,MEMORY.md这种常驻文件不受影响。 -
MMR 重排(
mmr.ts): 。用 Jaccard 相似度衡量候选结果之间的重复度,避免返回一堆内容差不多的片段。
最终返回的结果结构:
type MemorySearchResult = {
path: string; // 来源文件
startLine: number; // 分块起始行
endLine: number; // 分块结束行
score: number; // 综合得分 [0, 1]
snippet: string; // 截断到 700 字符的摘要
source: "memory" | "sessions";
};4.4 嵌入提供商
支持 6 种嵌入提供商。auto 模式按优先级依次试,Ollama 得手动指定:
|
优先级 |
Provider |
类型 |
Batch API |
默认模型 |
|---|---|---|---|---|
|
1 |
Local |
本地 |
- |
embeddinggemma-300m |
|
2 |
OpenAI |
远程 |
✅ |
text-embedding-3-small |
|
3 |
Gemini |
远程 |
✅ |
text-embedding-004 |
|
4 |
Voyage |
远程 |
✅ |
voyage-3 |
|
5 |
Mistral |
远程 |
- |
mistral-embed |
|
手动 |
Ollama |
本地 |
- |
nomic-embed-text |
4.5 降级策略
记忆系统最实用的一点:不要求所有组件都正常,能用多少用多少。
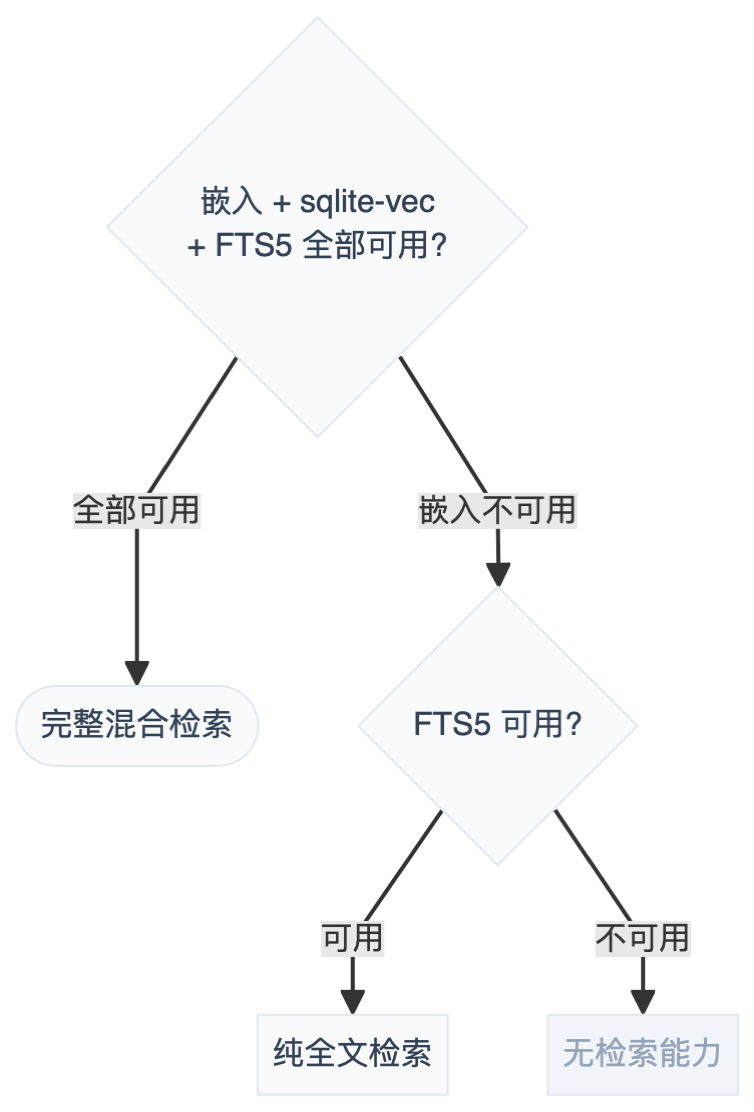
没有嵌入 API Key,关键词搜索照样能用;sqlite-vec 加载失败,FTS5 兜底。比起"缺一个组件就整个报错",这种做法靠谱得多。
4.6 实时同步
记忆不是建好就完事了,文件在改、新对话在产生,索引得跟上:
-
文件监听:Watch
MEMORY.md和memory/**/*.md,变更后防抖 1.5s 触发重新索引 -
会话监听:订阅 Session Transcript 更新事件,防抖 5s 后增量索引新内容
-
同步时机:搜索前自动同步(确保结果最新)、会话开始时同步、可配置定时同步
-
并发控制:4 路并行索引处理,Session 写锁防止并发冲突
五、插件系统
OpenClaw 的 73 个扩展——Discord 通道、Anthropic Provider 这些——全走统一的插件 SDK,没有硬编码的特殊通道。
5.1 插件生命周期

-
发现:从 bundled(内置)、global(全局安装)、workspace(工作区)三个位置扫描插件
-
加载:通过
jiti动态导入插件模块,支持 TypeScript 直接加载 -
注册:插件调用 SDK API 注册工具、Hook、CLI 命令和后台服务
-
激活:所有插件注册完毕后,统一激活插件注册表(缓存上限 128 条)
5.2 两种插件形态
通用插件——注册工具和 Hook:
definePluginEntry({
id: "my-plugin",
name: "My Plugin",
register(api) {
api.registerTool({ name: "my_tool", ... })
api.on("before_agent_start", async () => {
return { prependContext: "注入额外上下文" }
})
}
})通道插件——接入新的消息通道:
defineChannelPluginEntry({
id: "discord",
plugin: discordPlugin, // 实现 ChannelPlugin 接口
setRuntime: setDiscordRuntime, // 接收运行时能力
registerFull: registerHooks // 注册通道特有的 Hook 和工具
})5.3 25 个 Hook
插件可以在 Agent 生命周期的 25 个节点插入自己的逻辑。不用 fork 核心代码就能改 Agent 的行为:
|
阶段 |
代表 Hook |
典型用途 |
|---|---|---|
|
模型选择 |
before_model_resolve
, |
覆盖默认模型、注入系统上下文 |
|
LLM 交互 |
llm_input
, |
审计日志、内容过滤、token 统计 |
|
工具调用 |
before_tool_call
, |
调用拦截、结果持久化 |
|
消息处理 |
message_received
, |
消息预处理、格式转换、发送确认 |
|
会话管理 |
session_start
, |
初始化、清理、压缩前干预 |
|
子 Agent |
subagent_spawning
, |
子任务分发策略、结果汇总 |
|
网关 |
gateway_start
, |
服务启停时的资源管理 |
六、Gateway
Gateway 是 Agent 和外面世界之间的中间层。不管消息从 Discord、Slack、Telegram 还是 Web UI 来,都统一走 Gateway 路由到 Agent。
6.1 结构
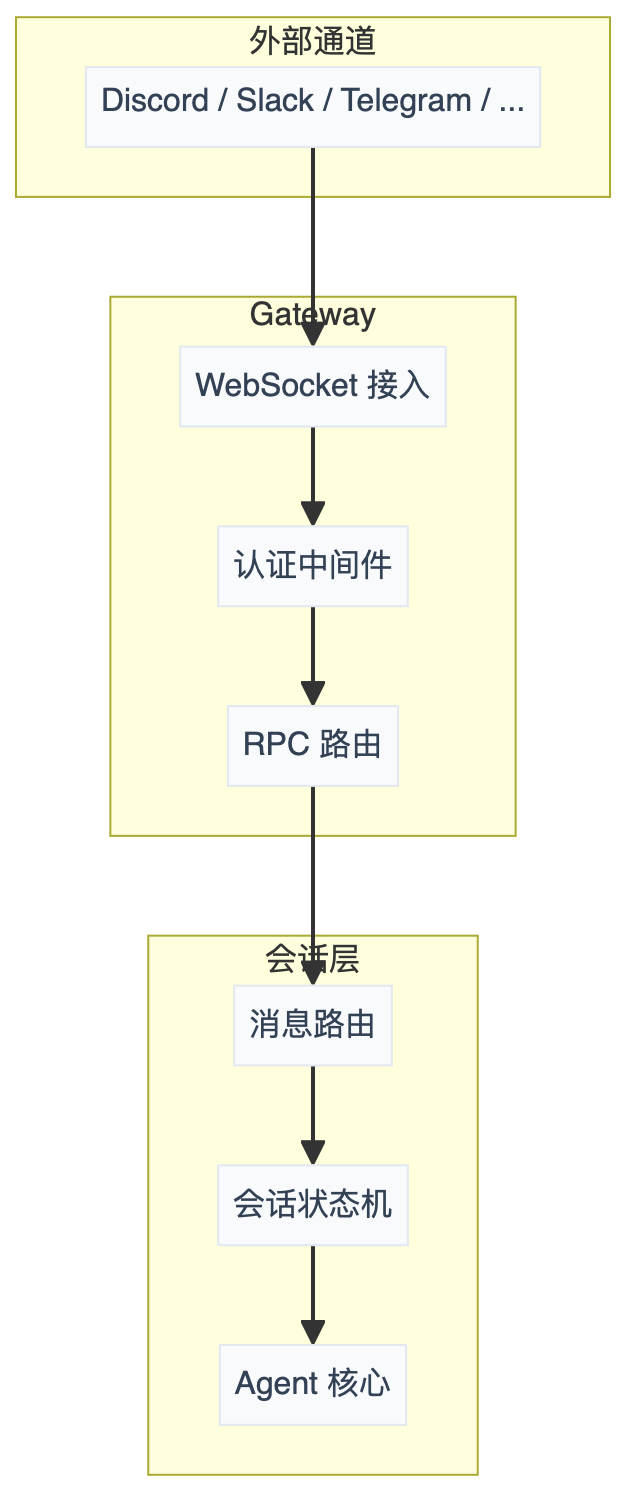
6.2 一条消息的旅程
比如用户在 Discord 里发了一句话,到 Agent 回复,中间经过这些环节:

其中会话状态机(src/channels/run-state-machine.ts)比较关键。每个会话有自己的状态:idle → running → drafting → completed,保证同一个会话不会被并发请求搞乱。通道健康监控(channel-health-monitor.ts)一直在检测各通道连接状态,断了自动重连。
七、做 Agent 的路线图
前面六章看完了 OpenClaw 怎么做的,这章整理一下:如果自己从零开始做一个 Agent,按什么顺序推进比较合理。
7.1 先搭核心循环
这是 Agent 的骨架,最小可用版本。需要三个东西:

System Prompt 构建器:别把 System Prompt 写死。OpenClaw 在 system-prompt.ts 里动态拼装——运行时信息(OS、时区、模型名)、可用工具列表、通道能力描述、用户自定义指令,按需注入。同一个 Agent 在不同环境下表现才能一致。
LLM 调用层:一定要用流式(streaming)不要用阻塞调用。OpenClaw 通过事件订阅(pi-embedded-subscribe.ts)实时处理 text_delta 和 tool_call 事件,用户能马上看到输出,不用干等。
工具循环:LLM 返回 tool_use 就执行对应工具,把结果作为 tool_result 喂回去,直到 LLM 不再请求工具。这个循环所有 Agent 框架都一样。
7.2 加容错
裸循环跑 demo 没问题,上线必须加容错。按重要程度排:
|
容错机制 |
解决什么问题 |
OpenClaw 的实现 |
|---|---|---|
|
上下文压缩 |
对话太长,超出模型窗口 |
compact.ts
调用 Context Engine 做摘要压缩 |
|
Auth Failover |
API Key 过期、限流、计费失败 |
run.ts
自动切换备用 Auth Profile / 备用模型 |
|
工具熔断器 |
Agent 陷入工具调用死循环 |
tool-loop-detection.ts
滑动窗口 + 三级熔断 |
|
流式去重 |
消息工具和直接回复内容重复 |
pi-embedded-subscribe.ts
跟踪已发送文本 |
上下文压缩是最容易被忽略但最要命的。没有它,长对话必崩。OpenClaw 的做法是溢出时用 Context Engine 对历史做摘要,保留关键信息后重试,不是简单砍掉前面的消息。
7.3 做记忆
这是让 Agent 从"一次性对话"变成"持续助手"的关键一步。OpenClaw 的方案可以直接抄:
最小实现:
-
选个嵌入模型(
text-embedding-3-small便宜够用) -
SQLite + sqlite-vec 存向量(不用搭 Milvus,省事)
-
加 FTS5 全文索引兜底
-
混合检索:
0.7 × 向量得分 + 0.3 × BM25 得分
进阶:
-
增量索引(SHA256 变更检测),不用每次全量重建
-
嵌入缓存(按内容哈希去重),少调几次 API
-
时间衰减让旧记忆自然淡出
-
MMR 重排保证结果不重复
-
降级策略:嵌入挂了用 FTS,FTS 也挂了就不检索,但 Agent 本身不能挂
为什么不用向量数据库服务? 单用户或小团队的 Agent,SQLite 够了。一个 .sqlite 文件就是全部记忆,拷到另一台机器就能跑。等真需要多租户、分布式检索的时候再迁移不迟。
7.4 设计工具安全策略
Agent 能调工具就意味着能产生副作用——写文件、发消息、跑命令。安全策略不是可选的。
OpenClaw 的分层做法可以参考:
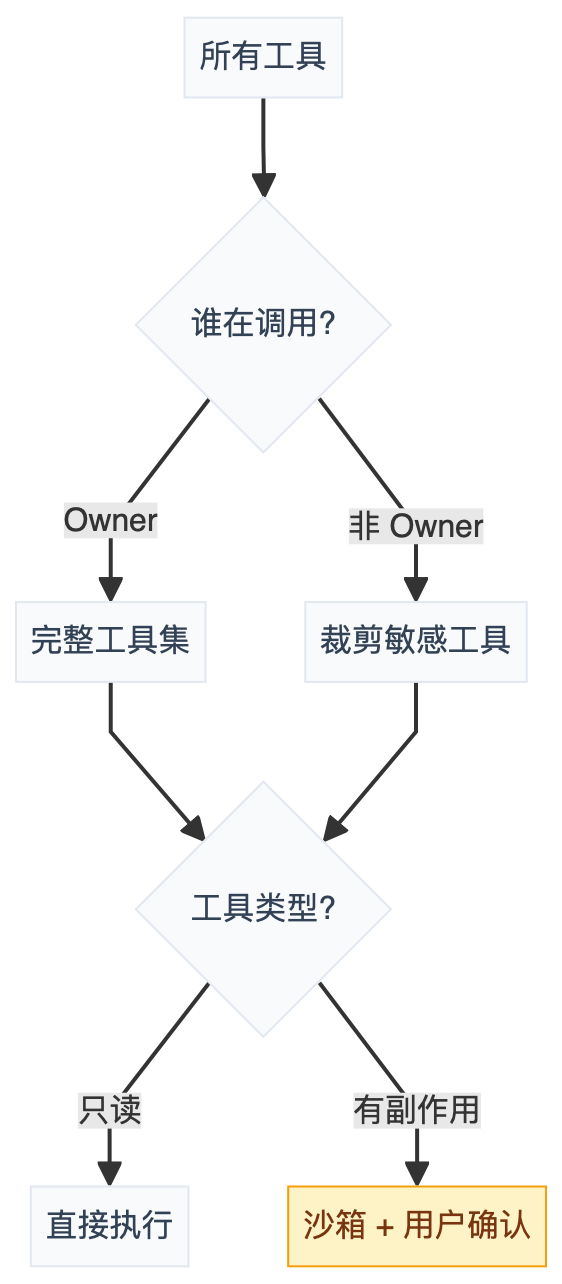
一句话:只读的放行,有副作用的隔离并确认。再加上循环检测熔断器兜底就行。
7.5 开放扩展
Agent 要支持新通道、新工具、新 Provider 的时候,不该每次都改核心代码。OpenClaw 的插件系统可以参考:
-
定义 Hook 点:在核心流程的关键位置(模型选择、Prompt 构建、工具调用前后、消息收发)暴露 Hook,让插件能插入逻辑。
-
统一注册 API:
registerTool()、registerHook()、registerService()三个方法覆盖大部分扩展场景。 -
运行时能力注入:通过
PluginRuntime把核心能力(配置读写、媒体处理、子 Agent 管理)暴露给插件,不让插件直接碰内部模块。
不用一开始就做 25 个 Hook。先从几个高频的开始:before_prompt_build(注入上下文)、before_tool_call / after_tool_call(工具拦截)、message_received(消息预处理)。后面按需加。
7.6 总结成表
上面的路线图压缩一下:
|
阶段 |
要做的事 |
OpenClaw 对应实现 |
优先级 |
|---|---|---|---|
|
骨架 |
工具循环 + 流式输出 |
attempt.ts
+ |
P0 |
|
骨架 |
动态 System Prompt |
system-prompt.ts |
P0 |
|
容错 |
上下文压缩 |
compact.ts |
P0 |
|
容错 |
Auth / 模型 Failover |
run.ts
重试循环 |
P1 |
|
容错 |
工具循环熔断 |
tool-loop-detection.ts |
P1 |
|
记忆 |
SQLite + 向量 + FTS |
memory/manager.ts
+ |
P1 |
|
记忆 |
混合检索 + 降级 |
hybrid.ts
+ |
P1 |
|
安全 |
工具权限 + 沙箱 |
tool-policy.ts
+ |
P1 |
|
扩展 |
插件 SDK + Hook |
plugin-sdk/core.ts |
P2 |
|
扩展 |
多通道接入 |
gateway/server.ts
+ |
P2 |
P0 是最小可用版本要有的,P1 是上线前得补的,P2 是用户量上来之后再考虑的。
附录:核心文件速查
|
你想了解... |
去看这个文件 |
|---|---|
|
Agent 主循环 |
src/agents/pi-embedded-runner/run.ts |
|
单次 LLM 调用 + 工具循环 |
src/agents/pi-embedded-runner/run/attempt.ts |
|
流式事件处理 |
src/agents/pi-embedded-subscribe.ts |
|
System Prompt 构建 |
src/agents/pi-embedded-runner/system-prompt.ts |
|
上下文压缩 |
src/agents/pi-embedded-runner/compact.ts |
|
工具注册 |
src/agents/openclaw-tools.ts |
|
工具安全策略 |
src/agents/tool-policy.ts |
|
工具循环检测 |
src/agents/tool-loop-detection.ts |
|
记忆管理器 |
src/memory/manager.ts |
|
混合检索算法 |
src/memory/hybrid.ts |
|
向量存储 |
src/memory/sqlite-vec.ts |
|
嵌入提供商工厂 |
src/memory/embeddings.ts |
|
时间衰减 |
src/memory/temporal-decay.ts |
|
MMR 重排 |
src/memory/mmr.ts |
|
插件 SDK |
src/plugin-sdk/core.ts |
|
Gateway 服务器 |
src/gateway/server.ts |
|
消息路由 |
src/routing/resolve-route.ts |
|
会话状态机 |
src/channels/run-state-machine.ts |

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)