
使用skill-creator创建和优化Skills
"读取文件 X"这样的简单查询是糟糕的测试用例——无论描述质量如何,它们都不会触发 Skills。"如何构建简单的快速仪表板。重复利用脚本如果多个测试用例都导致子代理编写相似的辅助脚本,考虑将其打包到 Skill 的 scripts/ 目录中。评估集维护定期更新评估集,添加新的边界案例和实际使用中发现的误判案例。Skill 的 description 字段是决定 Claude 是否调用 Skill
Info
官方资源
• GitHub: https://github.com/anthropics/skills/tree/main/skills/skill-creator
skill-creator 是 Claude Code 的官方 Skill,用于创建、优化和评估 Skills。它通过科学的方法帮助改进 Skill 的触发准确率和执行效果。
核心工作流程
skill-creator 遵循迭代的开发流程:
Summary
Skill 开发循环
1. 捕获意图
理解用户想要实现什么功能,确定 Skill 的触发场景和预期输出2. 编写草稿
创建 SKILL.md,编写 Skill 的核心指令和触发描述3. 创建测试
设计 2-3 个真实场景的测试用例4. 运行评估
同时运行有 Skill 和无 Skill 的基准测试,收集性能数据5. 定性+定量分析
使用 eval-viewer 查看结果,运行断言测试,收集用户反馈6. 迭代改进
基于反馈重写 Skill,扩展测试集,重复直到满意7. 描述优化
使用触发评估集优化 Skill 的触发准确率
创建 Skill
1. 捕获意图
在编写 Skill 前,先回答以下问题:
|
问题 |
说明 |
|---|---|
| Skill 要实现什么? |
Claude 使用该 Skill 后能完成哪些任务 |
| 何时触发? |
用户会说什么样的话或处于什么上下文时应该触发 |
| 预期输出格式? |
生成什么类型的文件或内容 |
| 是否需要测试用例? |
客观可验证的功能(代码生成、数据提取)适合测试用例;主观输出(写作风格、艺术)通常不需要 |
2. 编写 SKILL.md
SKILL.md 的核心结构:
---
name: your-skill-name
description: 什么时候使用这个 Skill,它完成什么任务。这是主要的触发机制!
要包含"何时使用"的所有信息,而不是放在正文。注意:Claude 倾向于"触发不足",
所以描述要稍微"主动"一些。
---
# Skill 标题
## 使用场景
当用户...时使用此 Skill
## 执行步骤
1. 第一步...
2. 第二步...
...Tip
描述编写技巧与其写:"如何构建简单的快速仪表板"
不如写:"如何构建简单的快速仪表板。每当用户提到仪表板、数据可视化、内部指标或想要显示任何类型公司数据时,一定要使用此 Skill,即使他们没有明确要求'仪表板'"
3. 编写原则
-
• 使用祈使语气:直接告诉模型做什么
-
• 解释为什么:今天的 LLM 很聪明,解释原因比僵硬的规则更有效
-
• 保持精简:移除不起作用的内容,不要让模型浪费时间
-
• 提供示例:用真实示例说明期望的输入/输出格式
-
• 控制篇幅:SKILL.md 保持在 500 行以内,必要时使用分层结构
测试与评估
测试用例格式
{
"skill_name": "example-skill",
"evals": [
{
"id": 1,
"prompt": "用户的任务提示",
"expected_output": "预期结果的描述",
"files": []
}
]
}运行测试流程
-
1. 并行启动所有测试:为每个测试用例同时启动两个子代理(有 Skill 和无 Skill)
-
2. 捕获时序数据:记录每个任务的 token 数量和执行时间
-
3. 编写断言:在测试运行时起草可验证的断言
-
4. 评分和聚合:运行聚合脚本生成 benchmark.json
-
5. 启动查看器:使用 eval-viewer 让用户审查结果
描述优化(触发优化)
Skill 的 description 字段是决定 Claude 是否调用 Skill 的主要机制。优化流程:
1. 生成触发评估集
创建 20 个评估查询,混合应该触发和不应该触发的案例:
[
{"query": "用户提示", "should_trigger": true},
{"query": "另一个提示", "should_trigger": false}
]评估集设计要点:
-
• 真实场景:使用真实用户会输入的具体、详细的请求(包含文件路径、列名、URL 等)
-
• 应该触发(8-10 个):覆盖不同表达方式,包括正式/非正式、未明确命名 Skill 的情况
-
• 不应该触发(8-10 个):最有价值的是"近失误"——共享关键词但实际需要不同功能的查询
2. 运行优化循环
python -m scripts.run_loop \
--eval-set <path-to-trigger-eval.json> \
--skill-path <path-to-skill> \
--model <model-id> \
--max-iterations 5 \
--verbose该脚本会:
-
• 将评估集分为 60% 训练集和 40% 测试集
-
• 评估当前描述(每个查询运行 3 次获得可靠的触发率)
-
• 调用 Claude 提出改进建议
-
• 迭代最多 5 次,选择测试集上得分最高的描述
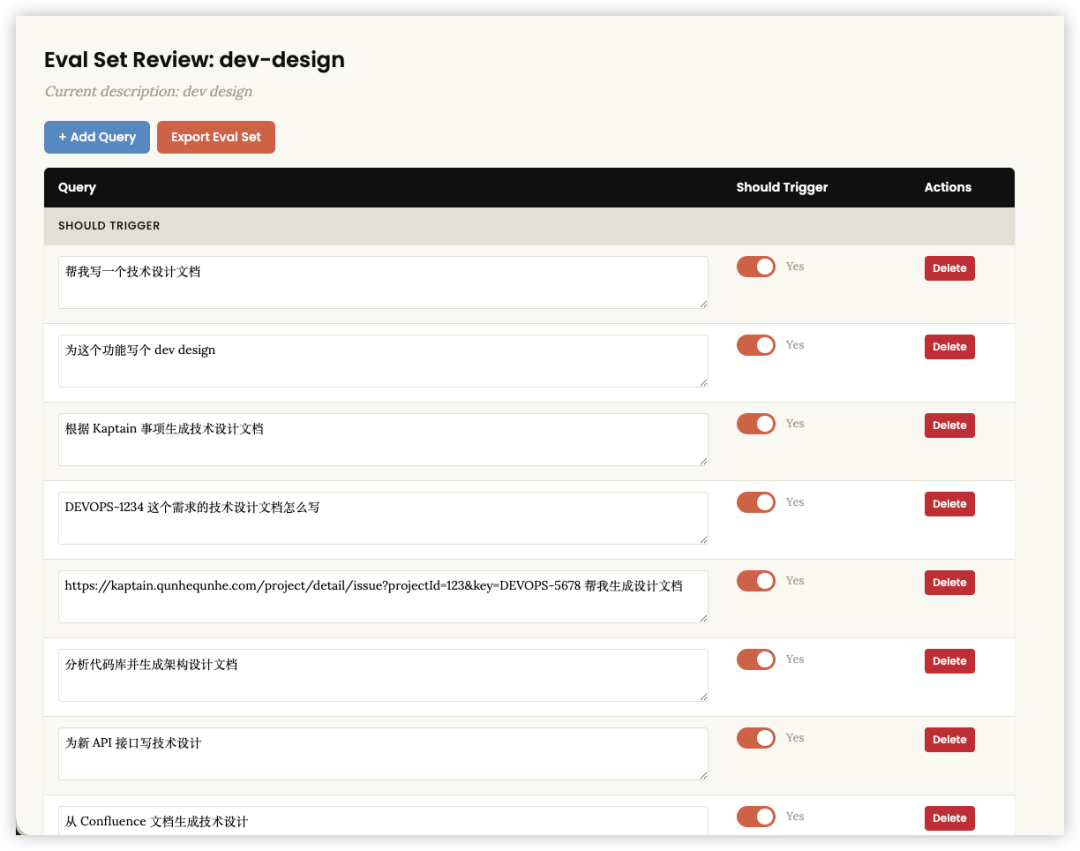
实战案例:优化 dev-design Skill
评估集示例
以下是为 dev-design Skill 设计的触发评估集:
[
{"query": "帮我写一个技术设计文档", "should_trigger": true},
{"query": "为这个功能写个 dev design", "should_trigger": true},
{"query": "根据 Kaptain 事项生成技术设计文档", "should_trigger": true},
{"query": "DEVOPS-1234 这个需求的技术设计文档怎么写", "should_trigger": true},
{"query": "https://kaptain.qunhequnhe.com/project/detail/issue?projectId=123&key= 帮我生成设计文档", "should_trigger": true},
{"query": "分析代码库并生成架构设计文档", "should_trigger": true},
{"query": "为新 API 接口写技术设计", "should_trigger": true},
{"query": "从 Confluence 文档生成技术设计", "should_trigger": true},
{"query": "用户认证功能的技术设计方案", "should_trigger": true},
{"query": "前端技术设计文档模板", "should_trigger": true},
{"query": "写一个函数", "should_trigger": false},
{"query": "帮我修复这个 bug", "should_trigger": false},
{"query": "怎么写单元测试", "should_trigger": false},
{"query": "代码审查", "should_trigger": false},
{"query": "部署到生产环境", "should_trigger": false},
{"query": "数据库优化建议", "should_trigger": false},
{"query": "git 合并冲突怎么解决", "should_trigger": false},
{"query": "npm install 失败了", "should_trigger": false},
{"query": "Vue 组件怎么写", "should_trigger": false},
{"query": "Docker 容器配置", "should_trigger": false}
]

最佳实践
Tip
避免过度拟合不要为了通过几个测试用例而编写过于狭窄或僵化的规则。尝试从反馈中泛化出通用原则,使用不同的隐喻或工作模式来解决问题。
Tip
重复利用脚本如果多个测试用例都导致子代理编写相似的辅助脚本,考虑将其打包到 Skill 的 scripts/ 目录中。这可以避免每次都重新造轮子。
Tip
解释而非强令如果发现自己在写 ALWAYS 或 NEVER 这样的全大写规则,这是警告信号。尝试重新构建并解释推理过程,让模型理解为什么你要求的事情很重要。
Tip
评估集维护定期更新评估集,添加新的边界案例和实际使用中发现的误判案例。特别关注那些"近失误"——容易混淆但应该区分的场景。
理解 Skill 触发机制
了解触发机制有助于设计更好的评估查询:
-
• Skill 列表:Skills 出现在 Claude 的 available_skills 列表中,包含 name + description
-
• 触发条件:Claude 根据描述决定是否咨询 Skill
-
• 重要特点:Claude 只在无法轻松处理任务时才咨询 Skills
-
-
• 简单的一步查询(如"读取此 PDF")可能不会触发,即使描述完美匹配
-
• 复杂、多步或专业化的查询在描述匹配时会可靠地触发
-
Note
评估查询设计建议评估查询应该足够实质性,使 Claude 实际上受益于咨询 Skill。"读取文件 X"这样的简单查询是糟糕的测试用例——无论描述质量如何,它们都不会触发 Skills。
相关资源
-
• Claude Skills 官方仓库
-
• Skills 官方文档
-
• skill-creator 完整文档

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)