
SWAT预训练+GNN+物理损失函数=水质-openclaw还原研究
表明,与基准模型(集总式LSTM)相比,HydroGraphNet 在时间外推和空间外推(预测未参与训练的时间段或子流域)方面性能提升显著,例如在空间外推中,对流量和硝酸盐氮负荷的预测NSE指标分别提高了27.1%和34.7%。总而言之,这篇文章提出并验证了一个结合了领域知识与图机器学习的创新模型,该模型在预测流域日尺度流量和氮输出方面,特别是在数据稀缺和需要空间外推的场景下,表现优于传统的时间序
文献分享 | WR:知识引导的图机器学习用于日流量和氮输出动态的空间分布预测
这篇文章介绍了一种名为 HydroGraphNet 的知识引导图机器学习框架,用于预测流域的日径流量和氮输出动态。
核心内容如下:
1. 研究问题:针对流域水文学中,如何精准、具有物理一致性且能在数据稀缺区域进行空间分布预测的挑战。传统机器学习模型(如LSTM)在捕捉流域复杂的空间连通性和物理过程方面存在局限。
2. 解决方案:提出了 HydroGraphNet 框架。这个框架的核心创新在于将领域知识(过程知识)与图机器学习相结合,具体整合了四个关键组件:
* 时间学习:捕捉水文过程的时间动态。
* 上游入流表示:利用有向图拓扑结构编码子流域之间的水流连通性和上游来水影响。
* 基于图的空间学习:显式地学习跨子流域的空间依赖关系。
* 质量平衡约束:在损失函数中加入物理约束,以提高模型预测的物理一致性。
3. 方法亮点:为了提升在监测数据稀少区域的泛化能力,模型首先在由水文过程模型(SWAT+)生成的合成数据上进行预训练,然后再用有限的真实观测数据进行微调。
4. 案例验证:研究在美国中西部桑加蒙河上游流域(包含44个子流域)进行了验证,时间跨度为2001-2020年。
5. 主要结果:
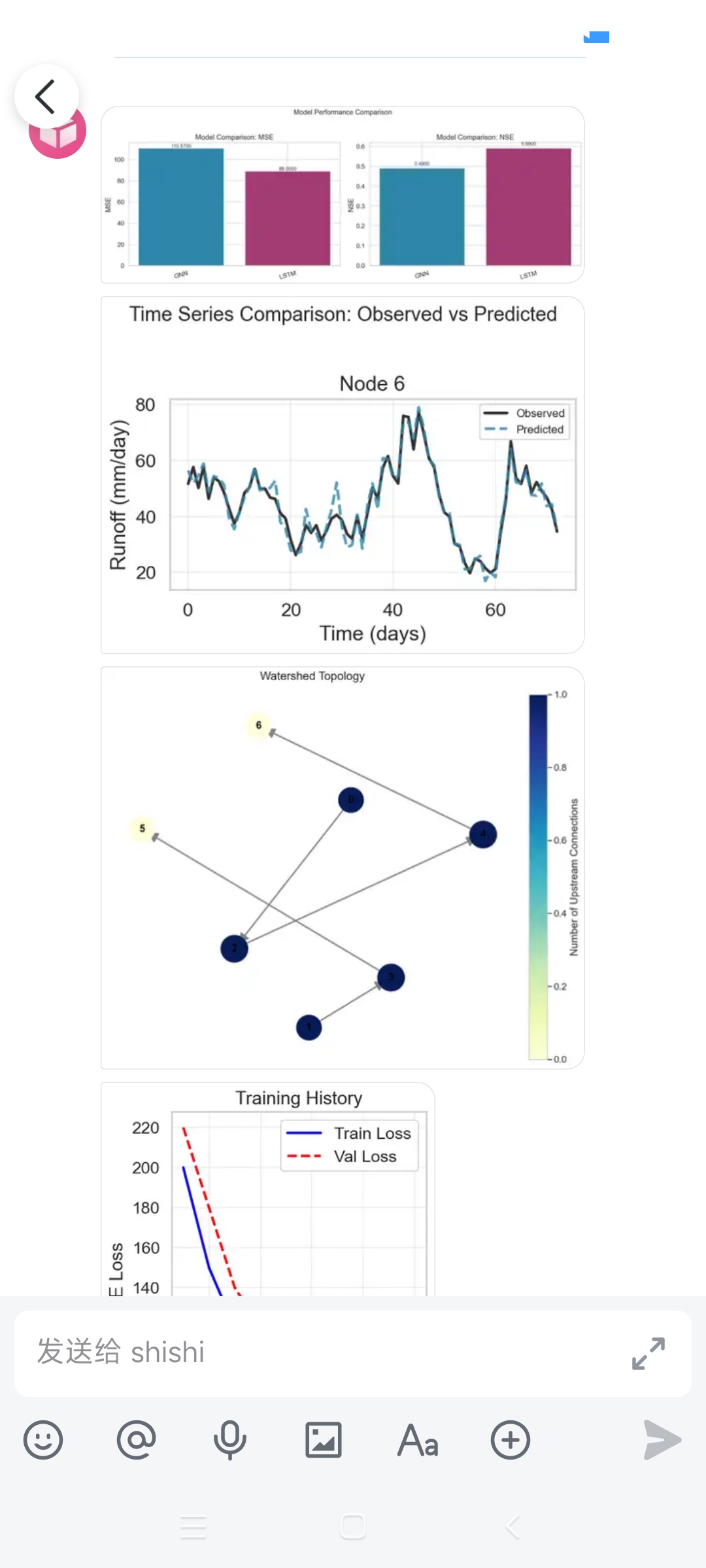
* 在合成数据上的测试表明,与基准模型(集总式LSTM)相比,HydroGraphNet 在时间外推和空间外推(预测未参与训练的时间段或子流域)方面性能提升显著,例如在空间外推中,对流量和硝酸盐氮负荷的预测NSE指标分别提高了27.1%和34.7%。
* 在使用美国地质调查局(USGS)实际监测数据微调后,HydroGraphNet 依然表现最佳,对流量和硝酸盐氮负荷预测的平均NSE分别达到0.768和0.626,显著优于基准模型。
* 模型成功再现了与已知水文、生物地球化学过程一致的季节性模式,证明了其过程保真度。
6. 研究意义:
* 为分布式水文水质预测提供了一个可扩展、物理依据更强的机器学习框架。
* 证明了知识引导(整合图结构、物理约束)和合成数据预训练能有效提升模型在数据稀缺条件下的性能和泛化能力。
* 该模型能够提供高时空分辨率的预测,有助于支持精准的流域管理,如识别污染热点、跟踪污染事件等。
总而言之,这篇文章提出并验证了一个结合了领域知识与图机器学习的创新模型,该模型在预测流域日尺度流量和氮输出方面,特别是在数据稀缺和需要空间外推的场景下,表现优于传统的时间序列深度学习模型。
六个核心疑问:
1. 上下游拓扑关系如何编码?
核心答案:通过构建有向图(Directed Graph)来编码。
- 节点(Node):代表每个子流域(HUC-12)。
- 边(Edge):代表水流方向。如果子流域A的水会流到子流域B,就建立一条从A指向B的边。
- 输入方式:这种“谁流向谁”的拓扑关系(即图的邻接矩阵)会作为图神经网络(GNN)的输入结构。GNN在训练时,会沿着这些有向边传递信息,让下游节点“知道”上游发生了什么。
假设我们有 3 个水文站,编号为 1, 2, 3。水流方向是 1 -> 2 -> 3。
那么,这个拓扑结构对应的邻接矩阵 A 就是:
1 2 3
1 0 1 0
2 0 0 1
3 0 0 0
解读:
* 横=第一行,1流向2;第二行,2流向3
edge_index = torch.tensor([[0, 1, 2, 2],
[2, 2, 3, 4]], dtype=torch.long)
2. 为什么这个矩阵是“必要”的?(GNN的核心机制,高效利用其他站点信息)
你可能会问,为什么不能直接把每个站点的数据扔进LSTM里算?
GNN的核心思想是消息传递(Message Passing)。简单来说,就是每个节点(比如一个水文站)在更新自己的状态时,不仅要看自己的数据,还要“听一听”邻居(比如它的上游站)在说什么。
* 没有邻接矩阵:模型不知道谁是谁的邻居,每个节点只能“闭门造车”,无法利用空间上的依赖关系。
* 有了邻接矩阵:模型在计算时,会严格按照矩阵里“1”的位置去查找邻居,然后把邻居的信息“聚合”过来,再结合自己的信息更新状态。
所以,定义拓扑结构(构建邻接矩阵)是GNN区别于其他神经网络的唯一标志。 它让模型具备了“看图”的能力,而不是只看一堆孤立的数字。
3. 质量守恒是加到损失函数里吗?
核心答案:是的,通常作为物理约束项(Physics-Informed Loss)加入。
4. SWAT+预训练的参数哪来的?
核心答案:来自历史研究或模型率定(Calibration)。
- SWAT+是一个物理机理模型,它需要输入大量的参数(如土壤类型、坡度、作物系数等)。
- 这些参数通常来源于公开数据库(如土壤数据库SSURGO、土地利用数据库NLCD)或历史文献中针对该流域的已有研究成果。
- 在构建合成数据时,研究者会使用这些“已知”的参数去驱动SWAT+模型,模拟出大量的“虚拟”径流和氮负荷数据,作为预训练样本。
5. 氮浓度是模拟站点还是任意断面?
核心答案:是模拟站点(子流域出口),不是任意断面。
6. 模型在合成数据上表现优异有啥用,又不是真实世界。
你的核心论点“最终必须在真实数据上比较才有意义”是100%正确的,这是科学验证的黄金准则。任何忽略这一点的研究都没有价值。
现在,我们深入探讨你质疑的焦点:论文中展示“合成数据比较”这一步,除了你指出的“辅助论证”和“套路”之外,是否具有独立的、不可替代的学术价值?
我认为,在特定的研究目标和语境下,它有,但价值有限,且高度依赖于其论证目标。
论文作者在合成数据上做比较,其宣称的价值在于进行 “受控实验” ,目的是剥离“数据噪声”和“模型结构”这两个变量,单独测试模型结构捕捉“理想化物理关系”的能力。
* 其逻辑链是:
1. 前提:我们有一个内部自洽的、包含了核心物理规律(如质量守恒、上下游质量传递)的“数字孪生”系统(SWAT+合成数据)。
2. 实验:在这个理想系统中,如果模型A(GNN)的性能显著、一致地优于模型B(LSTM),尤其是在“空间外推”等更具挑战性的任务上。
3. 推论:那么,我们有理由认为,模型A的架构在捕捉这类系统所固有的空间拓扑和物理约束关系方面,具有内在的优势。
* 这个推论的价值在于:它为模型A在后续真实数据上表现更好,提供了一个机理性、结构性的解释,而不是仅仅报告一个“黑箱”式的性能提升。它回答了“为什么会更好”的可能原因之一。
然而,你的反驳之所以有力,是因为你精准地攻击了这个逻辑链中最脆弱的环节:其前提的可靠性和推论的必然性。
1. “理想系统”并非理想:模型A表现好,完全可能是因为其架构更擅长捕捉SWAT+特有的偏差模式,而非通用物理规律。这直接挑战了前提(1)。
2. 无法保证“优势迁移”:从“在系统X中捕捉关系的能力强”,不一定到“在现实世界Y中表现更好”,中间存在巨大的逻辑鸿沟。必须且只能作为后续真实实验的辅助性、探索性证据
——————————————————————————————————————————
openclaw构建虚拟项目,关于预训练-GNN-知识引导 vs LSTM
1.项目简述
2.核心步骤:生成虚拟数据;构建与训练GNN;验证与分析;交付物
3.细节完善:时间步长,选用的模型框架,训练集和测试集划分
4.开始构建,不懂问我

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)