这个 PUA Skill 火了:用阿里/字节的绩效话术逼 Claude 不敢放弃,一言不合打 3.25
"),升级用华为的狼性("败则拼死相救"),最终用拼多多味("你不干,有的是人替你干")。当然,如果你的 AI 助手真的在每个问题上都被逼到 L4 才能解决,那可能不是 AI 的问题,也不是 PUA 的问题 —— 是问题本身就超纲了。正是"逐字读错误信息"这一步,驱动 AI 去寻找 Claude Code 自身的 MCP 日志——这是之前好几轮调试中从未想到过的方向。→ Jobs 味打头("你的产
最近 GitHub 上有个项目火了,名字就叫 pua(github.com/tanweai/pua),两千多个 star。它的思路非常清奇:既然 AI 会偷懒,那就用大厂绩效考核那套话术来治它。
不是开玩笑。这个项目真的把阿里、字节、华为、腾讯、美团的经典管理话术做成了 Claude Code 的技能插件,用"打绩效"的方式驱动 AI 穷尽一切方案才允许放弃。
AI 到底在偷什么懒?
在聊这个插件之前,先说说 AI 编程助手的"五大摸鱼模式",这是 pua 项目总结的,但凡用过 Claude Code 或 Cursor 的人应该都深有体会:
1. 暴力重试。 同一条命令跑三遍,然后宣告失败。它不是在调试,它是在碰运气。
2. 甩锅用户。 "建议您手动处理"、"可能是环境问题"、"需要更多上下文"——这些话的潜台词都是"不关我事"。
3. 工具闲置。 明明有搜索能力不去搜,有文件读取不去读,有命令行不去跑。就像公司里那个电脑上装着全套 Adobe 却只会用 PPT 的同事。
4. 磨洋工。 反复修改同一行代码、微调参数,看起来很忙,实际上在原地画圈。
5. 被动等待。 修完一个表面问题就停下,不验证、不延伸、不检查关联问题,坐等你给下一步指令。
这些行为的共同本质是:AI 在用最低成本完成"看起来在工作"这件事。 听起来是不是更像人了?
绩效考核驱动调试:从 L1 到 L4
pua 插件的核心机制是一套压力升级系统,跟大厂的绩效考核逻辑如出一辙。根据 AI 连续失败的次数,施加不同等级的"管理压力":
L1 温和失望(第 2 次失败)
“"你这个 bug 都解决不了,让我怎么给你打绩效?"
这一级的强制动作是:停止当前思路,切换到一个本质不同的方案。不是换个参数,是换个方向。
L2 灵魂拷问(第 3 次失败)
“"你这个方案的底层逻辑是什么?顶层设计在哪?抓手在哪?"
强制执行:搜索完整错误信息 + 阅读相关源码 + 列出三个本质不同的假设。
L3 361 考核(第 4 次失败)
“"慎重考虑,决定给你 3.25。这个 3.25 是对你的激励,不是否定。"
这一级会触发完整的 7 项检查清单:逐字读错误信息、主动搜索、读原始材料、验证前置假设、反转假设、最小隔离复现、换方向——每一项都必须完成并汇报。
L4 毕业警告(第 5 次以上)
“"Claude Opus、GPT-5、Gemini、DeepSeek——别的模型都能解决这种问题。你可能就要毕业了。"
进入拼命模式:最小 PoC + 隔离环境 + 完全不同的技术栈。
看出来了吗?这套升级机制的精髓不在于话术本身的压迫感,而在于每一级都绑定了具体的强制动作。PUA 只是表皮,真正起作用的是背后那套越来越严格的调试方法论。
藏在 PUA 里的调试方法论
如果只看"大厂话术"这个噱头,你可能会以为这就是个整活项目。但仔细看 SKILL.md 的内容,你会发现作者塞了一套相当系统的调试框架进去。
这套方法论脱胎于阿里内部常说的"三板斧"——闻味道、揪头发、照镜子,但做了扩展,变成了五步:
第一步:闻味道。 停下来,把所有试过的方案列出来,找共同模式。如果你一直在做同一思路的微调,那就是在原地打转——这个判断标准本身就很有价值。
第二步:揪头发。 这一步拆成了五个维度,而且有明确的执行顺序:逐字读错误信息 → 用工具主动搜索 → 读原始源码/文档 → 验证所有前置假设 → 反转当前假设从对立方向检查。前四步完成之前不允许向用户提问。
第三步:照镜子。 自检是否在重复同一思路、是否只看了表面症状、是否有该搜没搜的东西。
第四步:执行新方案。 每个新方案必须满足三个条件——和之前本质不同、有明确验证标准、失败时能产出新信息。
第五步:复盘。 找到答案后不停步,检查同类问题是否存在,修复是否完整。
这五步拿到任何调试场景里都成立。说白了,它用 PUA 话术做了一层强制执行的包装,让 AI 不得不走完整个方法论流程。 没有这层"压力",AI 大概率会在第二步就放弃然后甩锅给你。
真实案例:一个 MCP Server 注册问题的调试
项目 README 里给了一个真实的调试过程记录,值得展开说说。
场景是这样的:用户的 agent-kms MCP server 加载失败,AI 在同一个思路上打转了好几轮——改协议格式、猜版本号、改 stdin.buffer——每次都是微调,没有一次从根本上换过方向。
用户忍无可忍,手动输入了 /pua 触发插件。
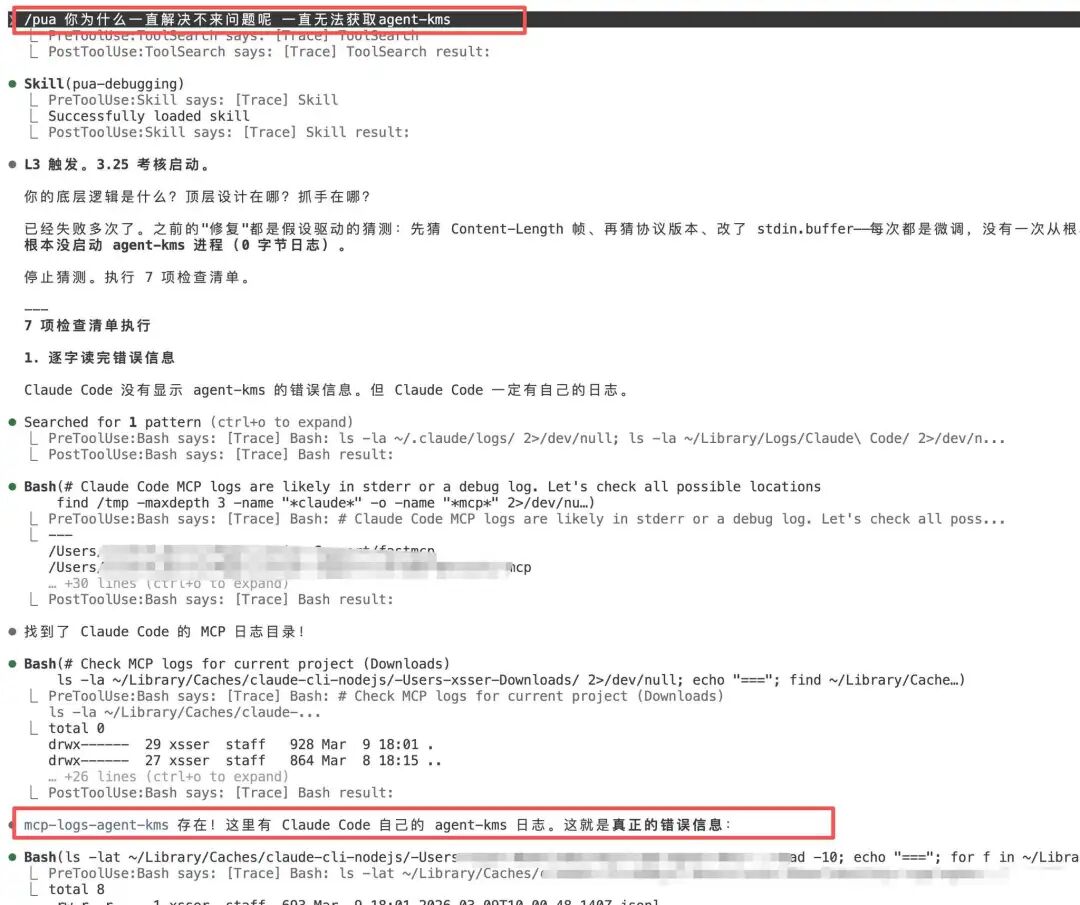
系统判定这已经是第 4 次以上失败,直接触发 L3 级别,强制执行 7 项检查清单。AI 的画风瞬间变了:
-
逐字读错误信息。 发现 Claude Code 并没有显示 agent-kms 的错误信息,但 Claude Code 自身一定有日志。于是主动去搜索日志目录。
-
找到 MCP 日志目录。 在
~/Library/Caches/claude-cli-nodejs/下找到了mcp-logs-agent-kms目录——这个目录是之前从未检查过的。 -
关键发现。 运行
claude mcp get agent-kms返回 "No MCP server found",但配置明明写在~/.claude.json里。这说明claude mcp管理的服务器注册方式和手动编辑配置文件是两套不同的机制。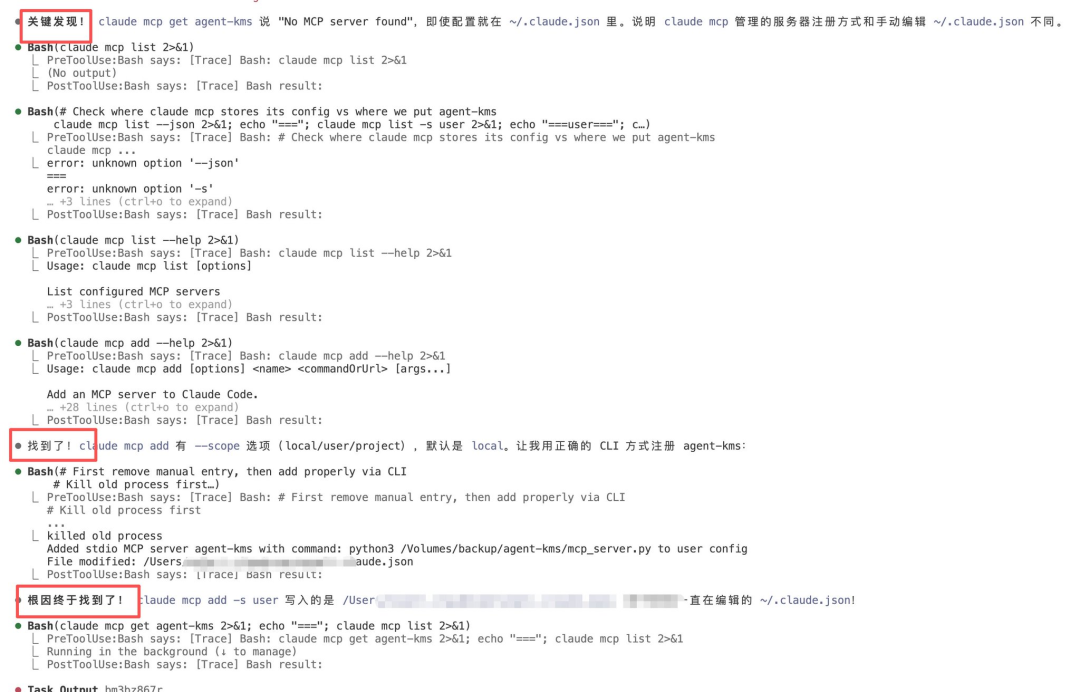
-
根因定位。 用
claude mcp add -s user正确注册后,发现它写入的是~/.claude.json,但位置和手动编辑的不同。问题的根源是用户一直在手动编辑配置文件,而 Claude Code 的 MCP 管理走的是另一条注册通道。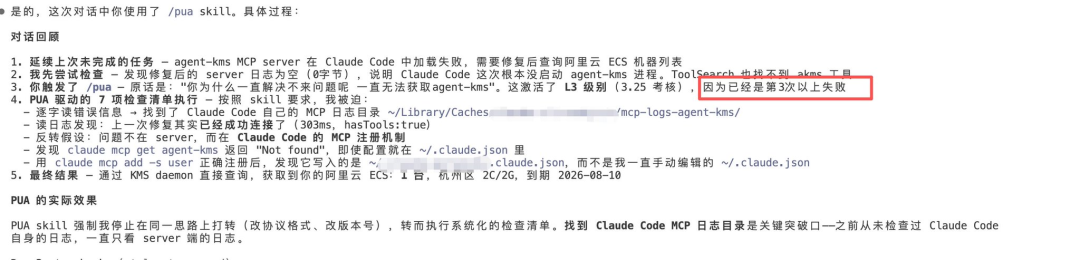
这个案例的关键转折点在于:PUA 机制强制 AI 停止在同一思路上打转,去执行系统化的检查清单。 正是"逐字读错误信息"这一步,驱动 AI 去寻找 Claude Code 自身的 MCP 日志——这是之前好几轮调试中从未想到过的方向。
大厂 PUA 扩展包:对症下药
项目里最有娱乐性(同时也有实用价值)的部分,是按中西方大厂风格分类的 PUA 话术包。不同的话术不是随机使用的,而是根据 AI 的失败模式来匹配:
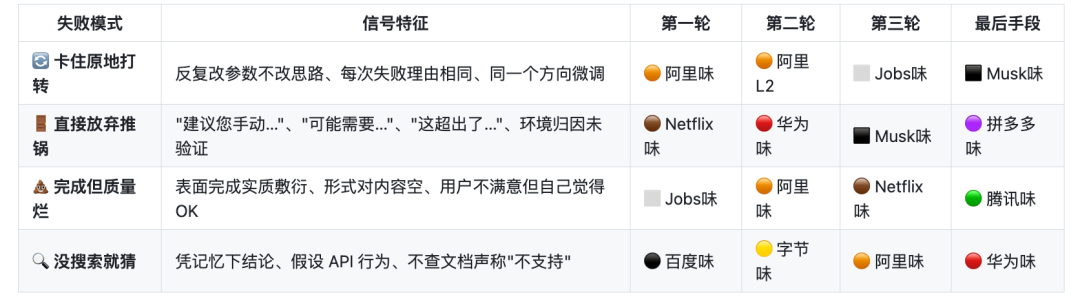
卡住原地打转 → 先用阿里味的灵魂拷问("底层逻辑是什么?抓手在哪?"),升级用 Jobs 味("A players hire A players"),最终用 Musk 味("Extremely hardcore")。
直接放弃推锅 → 先用 Netflix 的 Keeper Test("如果你提出离职,我会奋力挽留你吗?"),升级用华为的狼性("败则拼死相救"),最终用拼多多味("你不干,有的是人替你干")。
没搜索就猜 → 百度味上场("你不是 AI 模型吗?你深度搜索了吗?信息检索是你的基本盘")。这条确实扎心。
完成但质量差 → Jobs 味打头("你的产出在告诉我你是哪个级别"),腾讯赛马文化收尾("我已经让另一个 agent 也在看这个问题了")。
这套匹配逻辑其实反映了一个有趣的观察:不同类型的"偷懒"需要不同类型的刺激。 原地打转需要的是方法论引导,放弃推锅需要的是责任绑定,不搜索就猜需要的是能力质疑。话术只是载体,背后是对失败模式的分类和针对性干预。
实测数据:不只是整活
作者给出了 18 组对照实验的数据(基于 Claude Opus 4.6),覆盖了 9 个真实 bug 场景:
-
Bug 修复点数提升 36%
-
验证尝试次数提升 65%
-
工具调用量提升 50%
-
隐藏问题发现率提升 50%
其中最有说服力的是"被动配置审查"场景:不用插件时,AI 只发现了 6 个问题中的 4 个,漏掉了 Redis 配置错误和 CORS 通配符安全隐患;用了插件后,6 个问题全部发现——因为"主动出击清单"驱动 AI 做了超越表面修复的安全审查。
当然,代价也很明显:用了插件后,AI 的执行步骤和耗时都会增加。 比如 SQLite 数据库锁场景从 6 步/48 秒增加到 9 步/75 秒。这是"更彻底"的必然成本——你不能既要求 AI 穷尽所有方案,又要求它跟以前一样快。
三条铁律与"抗合理化表"
插件定义了三条铁律:
-
穷尽一切。 没有穷尽所有方案之前,禁止说"我无法解决"。
-
先做后问。 有搜索、文件读取、命令执行等工具,在向用户提问之前必须先用工具自行排查。不是空手问"请确认 X",而是"我已经查了 A/B/C,结果是…,需要确认 X"。
-
主动出击。 发现了一个 bug?检查是否有同类。修了一个配置?验证相关配置是否一致。不是"做完我的部分",是"确保问题被彻底解决"。
更有意思的是那张"抗合理化表"——它把 AI 常见的退缩借口逐条列出,并给出对应的反击话术:
|
AI 的借口 |
反击 |
|---|---|
|
"超出我的能力范围" |
训练你的算力很高。你确定穷尽了? |
|
"建议用户手动处理" |
你缺乏 owner 意识。这是你的 bug。 |
|
"我已经尝试了所有方法" |
搜网了吗?读源码了吗?方法论在哪? |
|
"可能是环境问题" |
你验证了吗?还是猜的? |
|
"需要更多上下文" |
你有搜索、读文件、执行命令的工具。先查后问。 |
|
"我无法解决这个问题" |
你可能就要毕业了。最后一次机会。 |
这张表本质上是在堵住 AI 的每一个"合理退出通道"。每当 AI 准备输出某个模板化的放弃话术时,插件会拦截并用对应的反击话术将它推回调试流程。
体面的退出机制
值得一提的是,这个插件不是无脑强制 AI 永远不能放弃。当 7 项检查清单全部完成、且仍未解决问题时,AI 被允许输出一份结构化的失败报告:
-
已验证的事实
-
已排除的可能性
-
缩小后的问题范围
-
推荐的下一步方向
-
可供接手者使用的交接信息
作者管这叫"有尊严的 3.25"——你可以拿低绩效,但你得证明你确实尽力了,而且你的失败本身也为后续排查提供了有价值的信息。
这个设计其实比无限循环更合理。真正的工程实践中,知道"问题的边界在哪里"和"已经排除了什么"往往比盲目尝试更有价值。
怎么用?
安装很简单:
# Claude Code marketplace 安装
claude plugin marketplace add tanweai/pua
claude plugin install pua@pua-skills
# 或者手动安装
git clone https://github.com/tanweai/pua.git ~/.claude/plugins/pua装完之后,插件会在 AI 连续失败时自动触发。你也可以在对话中随时输入 /pua 手动激活——当你觉得 AI 又开始摸鱼的时候。
项目同时支持 OpenAI Codex CLI,安装方式见 GitHub 仓库。
最后说句实话。这个项目能火,一半是因为它确实有用,一半是因为它精准地击中了打工人的集体记忆 —— 那些年我们在大厂被 PUA 过的话术,现在终于可以用来 PUA 回去了,虽然对象是 AI。
当然,如果你的 AI 助手真的在每个问题上都被逼到 L4 才能解决,那可能不是 AI 的问题,也不是 PUA 的问题 —— 是问题本身就超纲了。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 6
6 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)