
Skill 比 MCP 省 99% 的 Token,MCP 不是银弹,是 Token 黑洞
网上以及有网友遭遇过一个血的教训了,某企业因未清理对话历史,单次请求携带了 50 万 Token 的上下文,一次对话就烧掉几十元。当我们登录网站后,服务器生成一串随机字符串(Token)作为我们的“通行证”,之后我们每次点击请求浏览器或代码都可能带上它,这样服务器就知道“哦,是草哥呀”。接下来,我们就一起来看看 Token、MCP、Skill 等技术概念之间的计费玄机,以及 AI 时代的“省钱密码
往期热门文章:
1、代码提交数为 0,123 个 CVE 安全漏洞,MySQL 正在“自杀”
2、阿里开源项目!属于Java开发者的智能体框架!
3、Spring让Java慢了30倍,JIT、AOT等让Java比Python快13倍,比C慢17%
4、Spring 7.0.4 杀疯了,40 个新特性、15 个 Bug 修复、1 个死锁终结!
5、IntelliJ IDEA 2026发布:被开发者催了 6 年,这个细节终于修了!Skill 比 MCP 省 99% 的 Token,MCP 不是银弹,是 Token 黑洞。
接下来,我们就一起来看看 Token、MCP、Skill 等技术概念之间的计费玄机,以及 AI 时代的“省钱密码”。
Web 会话 Token
Token 一词,对程序员来说,应该并不陌生。在 web 中,token 就相当于我们的“临时身份证”。
它是一种身份验证机制。当我们登录网站后,服务器生成一串随机字符串(Token)作为我们的“通行证”,之后我们每次点击请求浏览器或代码都可能带上它,这样服务器就知道“哦,是草哥呀”。
这类 Web 会话中的 token 有以下特点。
-
一次性生成,多次使用。登录时消耗计算资源生成,后续请求几乎零成本
-
体积小巧。通常只有几十到几百字节
-
安全导向。用于身份验证和权限校验,与AI计算无关
AI Token
而 AI 中的 token,是大模型的“计价货币”。
它是大模型处理文本的最小单位。大家可以理解为Token 是 AI 的“脑细胞”,每处理一个 Token,模型就要进行一次计算。
也就是说,AI 中的 token 代表着计算量。
它和 Web 中会话 Token 有着关键区别。
|
维度 |
Web Session Token |
AI Token |
|---|---|---|
|
本质 |
身份凭证 |
计算单位 |
|
计费方式 |
免费(或极低成本) |
按量计费,直接关联成本 |
|
数量级 |
单次请求 1 个 |
单次请求数百至数百万个 |
|
生命周期 |
持续有效(小时/天) |
每次请求独立计算 |
需要注意的是,AI 中的 Token 的消耗是双向的。我们输入的 Prompt 算 Token,模型输出的回答也算 Token。而且通常输出比输入更贵(例如 Claude 3.5 Sonnet 输出 Token 的价格是输入的 5 倍)。
AI Token 是如何计算的?
大伙对 AI 中的 token 不好理解,其中一个原因是,它的计算方式不是一个简单的算式。
Tokenization
Token 不是简单的“字数”。不同语言的 Token 效率差异巨大,但都有对应的 Tokenization 对文本进行“艺术切分”。
-
英文:1 个 Token ≈ 0.75 个单词(“ChatGPT”可能是 1-2 个 Token)
-
中文:1 个汉字 ≈ 1-2 个 Token(技术文档中通常按 1.5 个计算)
-
代码:符号、缩进都会占用 Token,一段 Python 代码的 Token 数可能是字符数的 1.5 倍
三者的实例对比简化如下。
英文:"Hello world" = 2 Tokens
中文:"你好世界" = 4-6 Tokens
代码:"def hello():" = 4-5 Tokens计费公式
以 DeepSeek、元宝、阿里云百炼等平台为例,计费公式通常为:总费用 = (输入Token数 × 输入单价 + 输出Token数 × 输出单价) / 1,000,000。
不同模型的单价差异也非常巨大。
|
模型 |
输入单价(元/百万Token) |
输出单价(元/百万Token) |
|---|---|---|
|
通义千问-Max |
2.4 |
9.6 |
|
DeepSeek-V3 |
2.0 |
8.0 |
|
GPT-4 级别 |
30+ |
60+ |
网上以及有网友遭遇过一个血的教训了,某企业因未清理对话历史,单次请求携带了 50 万 Token 的上下文,一次对话就烧掉几十元。后来发现账户余额下降过快,通过巨额欠费账单才发现的。
Skill vs MCP
MCP 先出生,Skill 后出生。两者对 Token 的消耗是“左右互搏”。
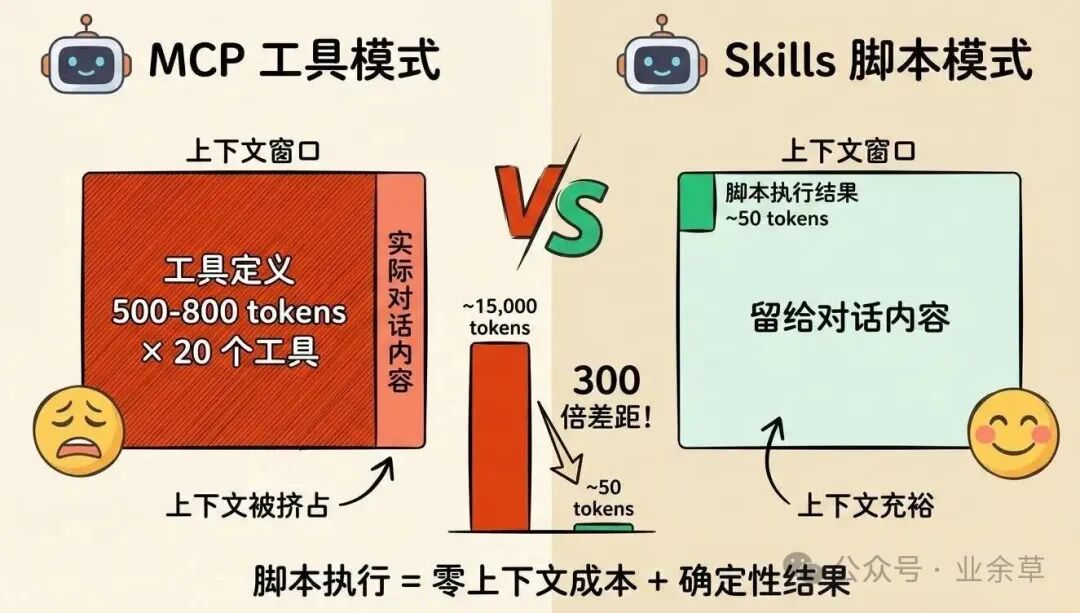

MCP 能力强但吃 Token
MCP 模型上下文协议是 Anthropic 推出的开放协议,旨在让 AI 统一调用外部工具(如查数据库、发邮件、操作 GitHub)。但它的致命伤是 Token 消耗。
MCP 的 Token 陷阱是,当启动 MCP 时,所有工具的定义文档会被一次性加载到上下文中。这包括:
-
工具名称和描述
-
参数列表(JSON Schema)
-
返回值格式
-
错误处理规范
老外网友对Claude 3.5 Sonnet的实测数据https://atalupadhyay.wordpress.com/2025/11/11/mcp-token-problem-building-efficient-ai-agents-with-skills显示:
-
5 个标准 MCP 服务器(GitHub、Slack、Google Drive 等)≈
97000 Token -
这占了 Claude 3.5 Sonnet(20 万上下文)的
48% -
还没开始对话,一半上下文就被“吃”掉了
更糟糕的是中间结果传递。当你让 AI “从 Google Drive 下载会议纪要并上传到 Salesforce”时,会议内容会在 AI 上下文中流转两次,一份 2 小时的会议记录可能额外消耗 5 万 Token。
Skill 技能
Skill 是 Anthropic 推出的新特性,是一个精打细算的“轻量级选手”,它本质上是一种按需加载的能力包。
Skill 的 Token 优势如下所示。
-
启动时:只加载简短描述(约 12 Token)
-
使用时:才加载完整指令和代码(约 300 Token)
-
Token 节省率:99.6%
来自老外的对比实验https://intuitionlabs.ai/articles/claude-skills-vs-mcp显示:
|
方案 |
启动Token |
使用时Token |
总消耗 |
|---|---|---|---|
|
MCP传统方式 |
2,800 |
2,800(持续占用) |
高且固定 |
|
Skill方式 |
12 |
311(按需加载) |
低且弹性 |
MCP vs Skill 谁更费 Token?
我们直接说结论吧,MCP 更费 Token,但 Skill 并非万能。
MCP 费 token,为什么还有人用?因为它有它的优点。
-
标准化:统一协议,跨平台兼容
-
实时数据:能获取最新信息(股价、天气等)
-
精确控制:工具行为可预测,适合企业级审计
对应的 Skill 也有不少优点。
-
极致省 Token:适合高频、重复性任务
-
快速响应:无需等待外部服务器
-
隐私安全:数据不流出模型上下文
现在,整个 AI 社区以及达成了共识。二者不是替代关系,而是互补关系。MCP 用于探索“能做什么”,Skill 用于高效执行“已知怎么做”或“具体应该这样做”。
MCP 的 Token 优化策略
既然 MCP 必不可少,如何降低其 Token 消耗呢?
目前业界已探索出多种方案,下面我们一起来看看。
Code Execution 模式
该模式是 Anthropic 官方方案。核心思想是让 AI 写代码调用 MCP,而不是直接调用。
测试的效果https://www.anthropic.com/engineering/code-execution-with-mcp表明,Token 消耗从 150000 降至 2000,节省 98.7%。
Code Execution 模式的原理总结如下。
-
传统方式:AI → 调用工具 → 接收结果 → 调用下一个工具(所有中间结果都过 AI 上下文)
-
Code 模式:AI 生成脚本 → 脚本直接串联多个工具 → AI 只看最终结果
Dynamic Toolsets(动态工具集)
Dynamic Toolsets 动态工具集,Speakeasy 提出的优化方案如下。
-
语义搜索:不加载所有工具定义,只加载与用户意图相关的工具
-
分类大纲:提供工具类别索引,让 AI 按需深度检索
-
效果:输入 Token 减少 96.7%,总 Token 减少 96.4%
更多细节参考https://www.speakeasy.com/blog/how-we-reduced-token-usage-by-100x-dynamic-toolsets-v2。
节省 Token 的六大实战技巧
基于社区最佳实践,我总结以下省钱秘籍,供大家参考。
Prompt 压缩
效果立竿见影,去除冗余词汇。
优化前:"请按照以下非常重要的步骤操作:第一步、第二步、第三步"
优化后:"步骤:1. 2. 3."
节省:18 Tokens → 8 Tokens(节省55%)使用结构化格式。
-
用 JSON 代替自然语言描述
-
用缩写(API 代替 Application Programming Interface)
-
删除礼貌用语("请"、"谢谢")
上下文管理
管理好你的上下文,防“历史包袱”。这里面的一个致命误区是,AI 应用默认携带完整对话历史,导致 Token 指数级增长。
对应的解决方案如下。
-
定期清理对话记录:每次新任务前清除无关历史
-
使用摘要机制:将长篇对话总结为 100 字摘要,替代原始内容
-
滑动窗口:只保留最近 N 轮对话
缓存机制
对于高频重复查询(如“查询公司最新股价”),可以实施“多级缓存”,这也是重复任务的救星。
用户提问 → Redis 缓存(精确匹配)→ 语义缓存(相似问题)→ 调用模型某在线教育平台的 AI 作文批改系统,采用该方案后,效果显著。命中率 99% 时,成本降低 99%。
模型路由
好钢用在刀刃上,不是所有任务都需要 GPT-5。可以建立智能路由策略。
-
简单任务(问答、翻译):用轻量模型(GPT-3.5 / Claude Haiku)
-
复杂任务(推理、编程):用旗舰模型(GPT-5 / Claude Opus)
-
预估节省:70% 的任务可用轻量模型处理,成本降低 80%
异步与批处理
实时调用 vs 批处理。
-
实时:1000 次请求 × 3 秒等待 = 50 分钟,成本 $50
-
批处理:vLLM 一次生成 1000 个结果 = 8 分钟,成本 $8
这个就相当于 sql 的批量插入语句一样,相比循环单个插入,更有性价比。
某些场景下节省比例高达 84%。
监控与告警
做好监控,防“账单刺客”,也防小人。必须建立的监控指标。
-
按团队/项目的 Token 消耗分布
-
异常检测(单小时成本超过平均值 3 倍时告警)
-
成本归因(识别“Token 大户”)
已经有不少老外,做了真实案例。某团队通过监控发现,一个未关闭的调试循环每小时消耗 $200,及时止损。
Token 经济的演进
写到这里,我想去了 AI 圈常说的一句话:你的模型能力很强,但你的账单余额不足。
所以,随着 AI Agent 的普及,Token 管理正从“优化选项”变为“核心竞争力”。
目前有几个值得关注的趋势,供大家参考!
-
上下文压缩技术:模型自动压缩历史对话,保持关键信息的同时减少 Token。
-
专用小模型:针对特定任务训练轻量模型(如代码审查专用模型),Token 效率提升 10 倍
-
边缘计算:简单推理下沉到本地设备,只有复杂任务调用云端大模型
结语
理解 Token,就是理解 AI 时代的“成本结构”。无论是 Web 开发者还是 AI 产品经理,都需要建立 Token 敏感度。
善用 Prompt 压缩和上下文清理,月省 $50 不是梦。在 MCP 和 Skill 之间找到平衡点,JVM 调优面试题已变为 Token 优化策略类面试题。
毕竟,最优雅的 AI 应用,不是用最强大的模型,而是用最高效的方式解决问题。
参考资料
-
Atal Upadhyay《MCP Token Problem: Building Efficient AI Agents with Skills》
https://atalupadhyay.wordpress.com/2025/11/11/mcp-token-problem-building-efficient-ai-agents-with-skills/ -
Speakeasy《Reducing MCP token usage by 100x》
https://www.speakeasy.com/blog/how-we-reduced-token-usage-by-100x-dynamic-toolsets-v2 -
IntuitionLabs《Claude Skills vs. MCP: A Technical Comparison》
https://intuitionlabs.ai/articles/claude-skills-vs-mcp -
Anthropic《Code execution with MCP: building more efficient AI agents》
https://www.anthropic.com/engineering/code-execution-with-mcp -
Skywork AI《Claude Skills vs MCP vs General LLM Tools》
https://skywork.ai/blog/ai-agent/claude-skills-vs-mcp-vs-llm-tools-comparison-2025/ -
CData《Claude Skills vs MCP: Better Together》
https://www.cdata.com/blog/claude-skills-vs-mcp-better-together-with-connect-ai -
AgiFlow《token-usage-metrics》
https://github.com/AgiFlow/token-usage-metrics
往期热门文章:
1、利用闲置 Mac 从零部署 OpenClaw 教程 2、一款高性能、无侵入的 Java 性能监控神器 3、Spring Boot 4.0 全面拥抱 Jackson 3!小心有坑~ 4、为什么大厂一般不推荐使用@Transactional? 5、又一款开源、强大的工作流自动化神器,吃到细糠了! 6、JDK25都出来了,但为什么很多公司还在坚持用JDK8? 7、15 万个 ClawdBot 涌进 AI 社交网站,但人类只能围观。 8、Spring6.0+Boot3.0:秒级启动、万级并发的开发新姿势 9、一款开源、现代化的数据库备份利器 10、这两个网站,一个可以当时间胶囊,一个充满了赛博菩萨。


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)