
Qwen3-VL:30B镜像部署实操:星图云GPU实例创建→Ollama服务验证→Clawdbot初始化全流程
本文介绍了如何在星图GPU平台上,通过自动化部署预置的“星图平台快速搭建 Clawdbot:私有化本地 Qwen3-VL:30B 并接入飞书(上篇)”镜像,快速搭建一个私有化的多模态AI助手。该方案的核心应用场景是创建一个能理解图片内容并进行智能对话的办公助手,为后续接入飞书等协作平台、实现自动化图文处理任务奠定基础。
Qwen3-VL:30B镜像部署实操:星图云GPU实例创建→Ollama服务验证→Clawdbot初始化全流程
想不想拥有一个能看懂图片、能聊天、还能帮你处理工作的私人AI助手?今天,我就带你从零开始,在CSDN星图AI云平台上,亲手搭建一个基于最强多模态大模型Qwen3-VL:30B的智能办公系统。
整个过程就像搭积木一样简单,你不需要懂复杂的服务器配置,也不需要担心显卡不够用。我们用的星图平台已经帮我们把最难的部分——环境配置和模型预装——都搞定了。你只需要跟着步骤操作,就能拥有一个私有化的、功能强大的AI助手。
这篇文章是上篇,我们会完成最核心的三步:创建GPU实例、验证模型服务、初始化Clawdbot管理平台。下篇我们再讲怎么接入飞书,让你的AI助手真正“活”起来。
1. 准备工作与环境概览
在开始之前,我们先看看这次实验的“硬件家底”。星图平台给我们提供的配置相当豪华,完全能满足Qwen3-VL:30B这个大模型的运行需求。
1.1 实验环境说明
这次所有的部署和测试都在CSDN星图AI云平台上进行。平台已经预装了Qwen3-VL:30B的镜像,我们直接拿来用就行,省去了自己安装模型的麻烦。
硬件配置详情:
| 组件 | 规格 | 说明 |
|---|---|---|
| GPU驱动 | 550.90.07 | 最新的NVIDIA驱动 |
| CUDA版本 | 12.4 | 深度学习计算框架 |
| 显存 | 48GB | 完全满足30B模型需求 |
| CPU核心 | 20核心 | 多任务处理能力强 |
| 内存 | 240GB | 大内存保证流畅运行 |
| 系统盘 | 50GB | 操作系统和基础软件 |
| 数据盘 | 40GB | 存放模型和用户数据 |
这个配置是什么概念呢?简单说,就是“性能过剩”。Qwen3-VL:30B官方推荐48G显存,我们正好匹配。240G的内存更是绰绰有余,确保多个任务同时运行也不会卡顿。
1.2 为什么选择星图平台?
你可能想问,为什么选星图平台而不是自己买服务器?原因很简单:
- 省心:不用自己装系统、配环境、下模型
- 省钱:按需使用,不用的时候可以关机,只算实际使用时间
- 省时:从创建实例到能用上模型,最快10分钟搞定
- 稳定:专业的数据中心,网络和电力都有保障
特别是对于想体验大模型但又不想投入太多硬件成本的朋友,云平台是最佳选择。
2. 第一步:创建GPU实例并验证基础镜像
现在开始动手。第一步是在星图平台上创建一个GPU实例,并选择我们需要的Qwen3-VL:30B镜像。
2.1 选择正确的社区镜像
登录星图AI云平台后,进入控制台。在创建实例的页面,你会看到“社区镜像”这个选项。这里有很多预装好的镜像,我们要找的是Qwen3-VL:30B。
快速定位技巧: 如果镜像列表很长,不用一个个找。直接在搜索框输入Qwen3-vl:30b,就能快速锁定目标。
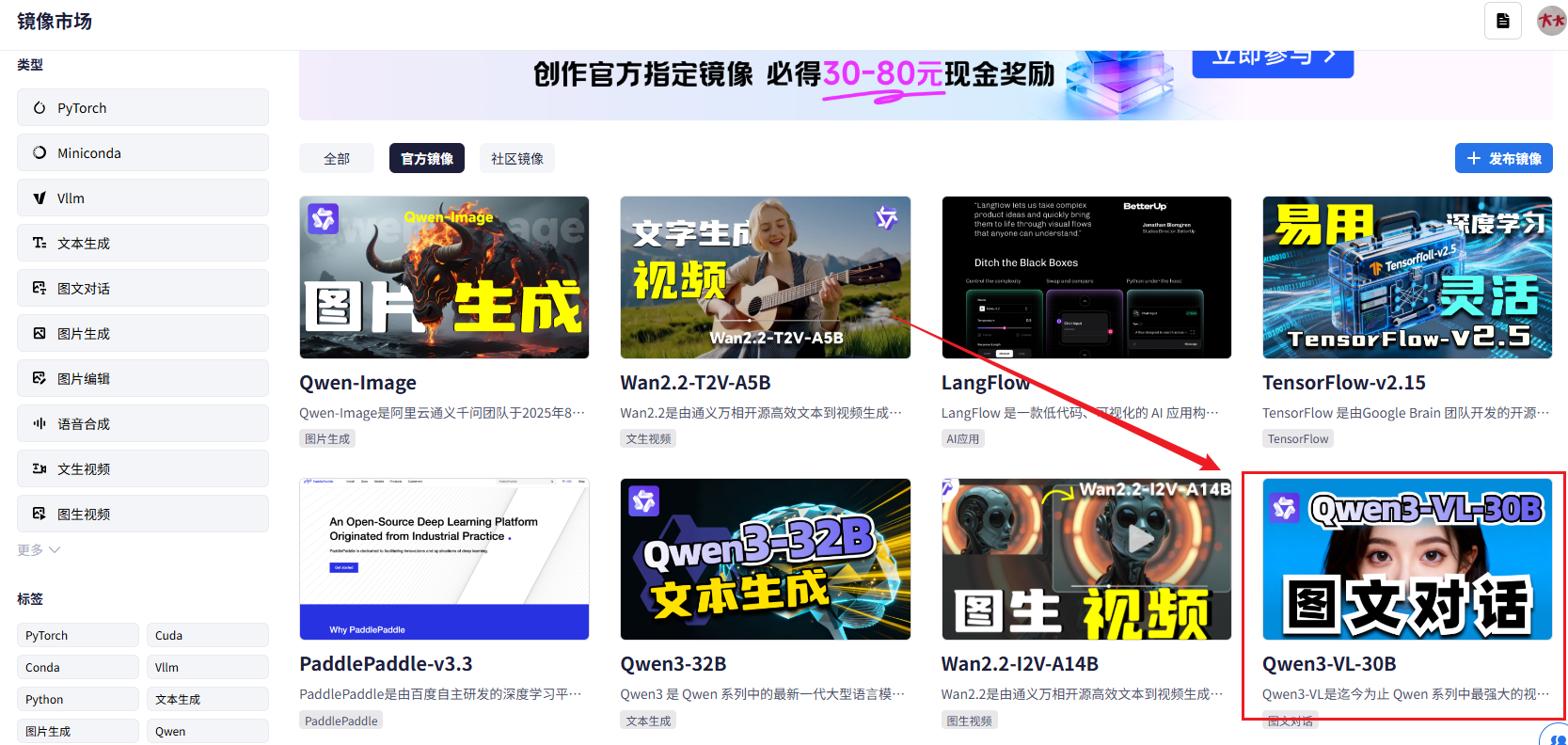
找到后选中它,这个镜像已经预装了Ollama服务和Qwen3-VL:30B模型,我们后续的工作会轻松很多。
2.2 配置实例参数
Qwen3-VL:30B是个“大块头”,对算力要求比较高。好在星图平台很贴心,已经为我们匹配好了推荐配置。
创建实例时,你会看到配置选项。对于这个30B的模型,官方推荐就是48G显存。我们直接按照平台默认推荐的配置框选择启动就行,不用自己调整。
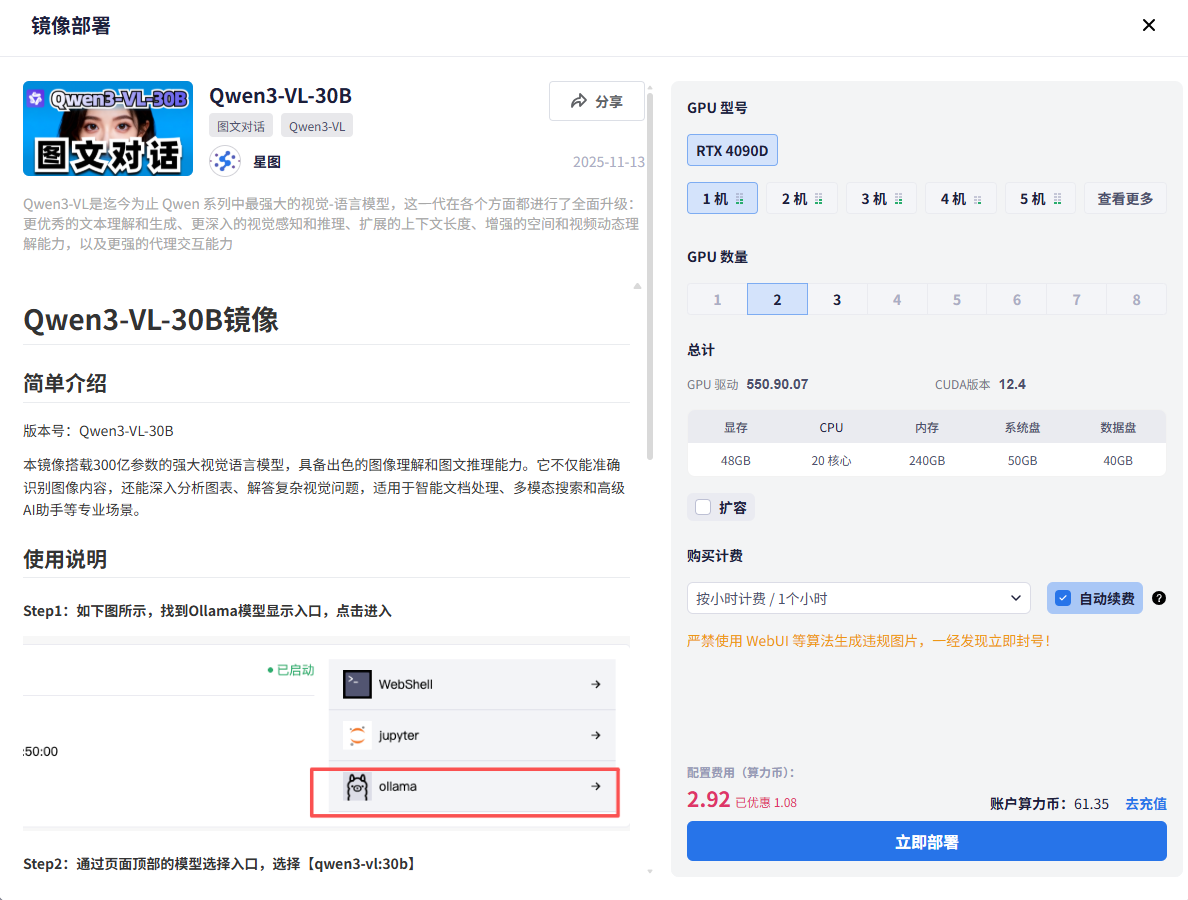
几个关键点:
- 区域选择:选离你近的,延迟低
- 镜像确认:一定是Qwen3-VL:30B
- 配置确认:48G显存,其他按默认
点击创建后,等待几分钟,实例就会启动完成。这个过程就像在云端租了一台高性能电脑,所有硬件都准备好了。
2.3 验证镜像可用性
实例启动后,我们第一件事是验证模型服务是否正常。星图平台提供了很便捷的访问方式。
返回个人控制台,找到你刚创建的实例。在操作栏里,你会看到一个“Ollama控制台”的快捷方式。点击它,就能直接进入预装好的Ollama多模态Web交互页面。
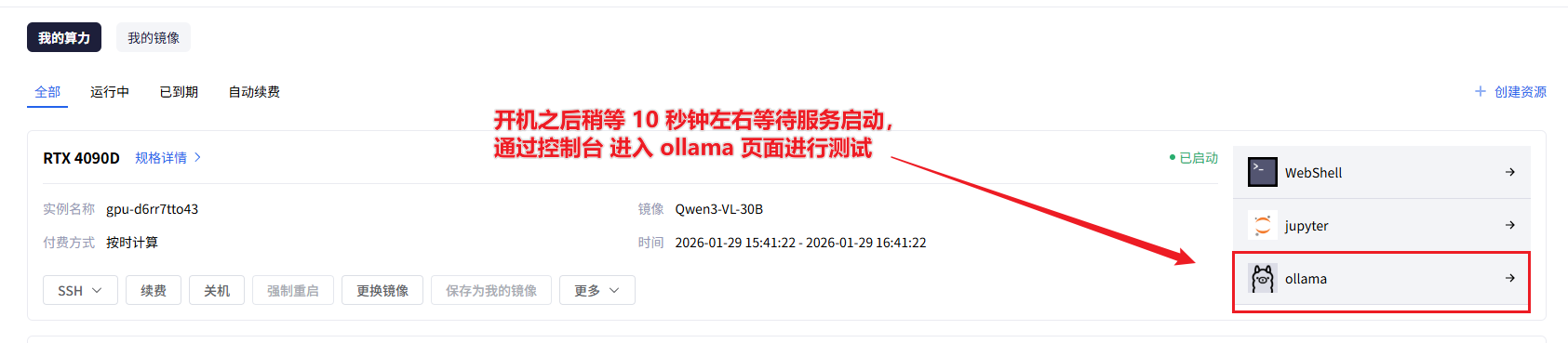
Web界面初步测试: 进入Ollama的Web界面后,你可以先简单测试一下。在对话框里输入“你好,介绍一下你自己”,看看模型能不能正常回复。
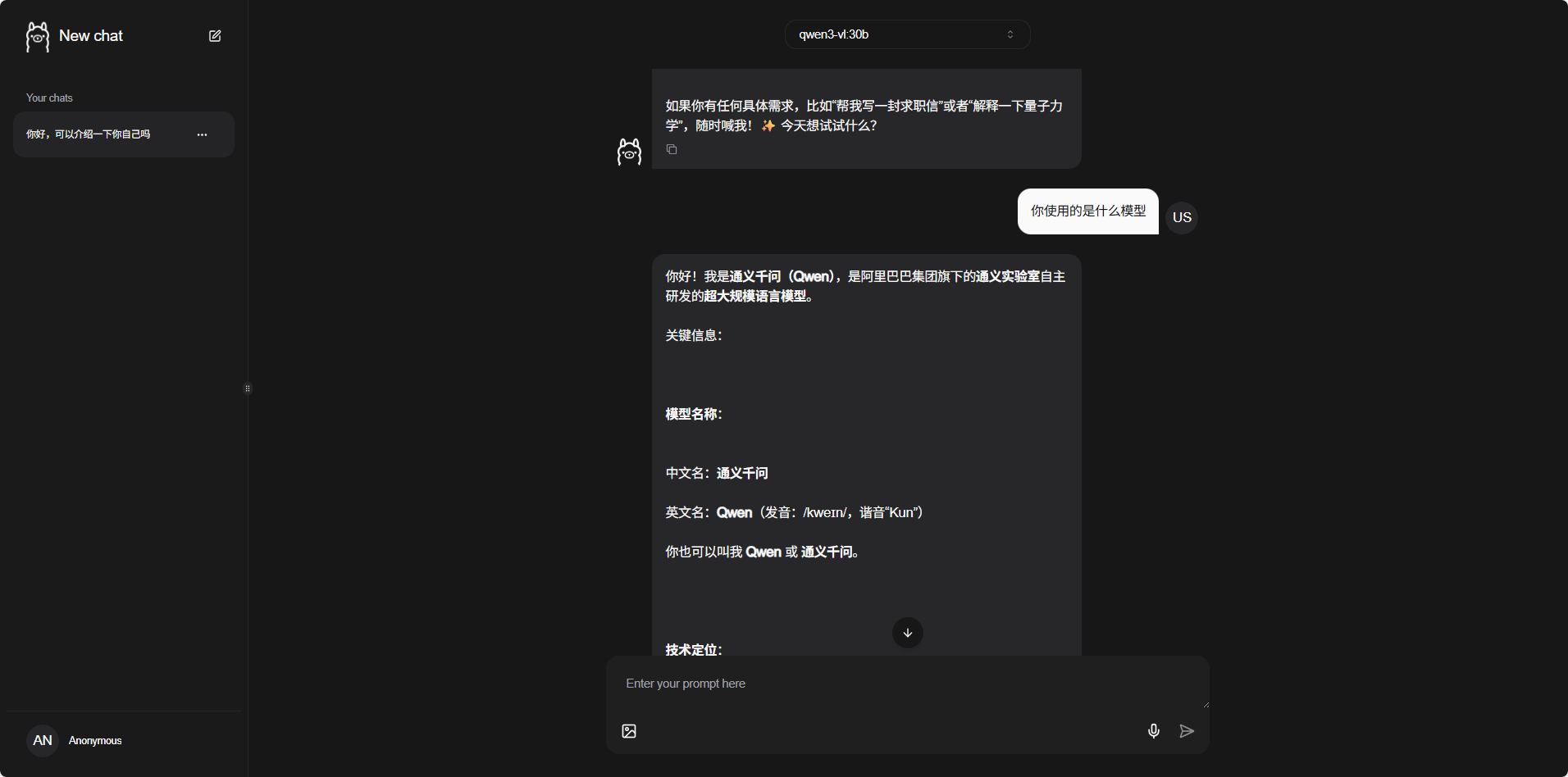
如果能看到正常的回复,说明模型服务已经跑起来了。这个Web界面是Ollama自带的,功能比较基础,但用来验证服务是否正常足够了。
2.4 本地API调用测试
Web界面测试通过后,我们还需要验证API接口是否可用。因为后续的Clawdbot是通过API来调用模型的。
星图云为每个算力实例提供了公网URL,我们可以在本地电脑上直接调用API。这样测试有两个好处:一是验证网络连通性,二是为后续集成做准备。
获取你的公网URL: 在实例详情页,找到访问地址。格式类似这样:https://gpu-pod697b0f1855ba5839425df6ea-11434.web.gpu.csdn.net/
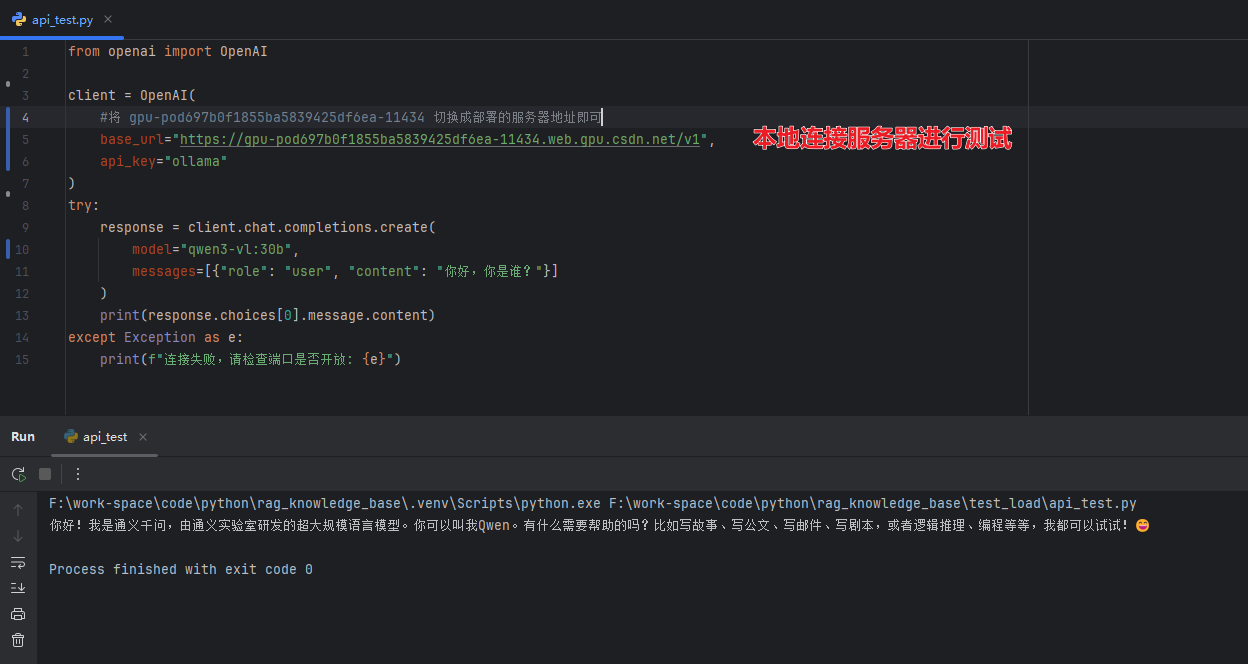
Python测试代码: 在你的本地电脑上,新建一个Python文件,粘贴下面的代码。记得把base_url换成你实际的地址。
from openai import OpenAI
# 创建客户端,指向你的星图实例
client = OpenAI(
# 重要:把下面的地址换成你自己的
base_url="https://gpu-pod697b0f1855ba5839425df6ea-11434.web.gpu.csdn.net/v1",
api_key="ollama" # Ollama的默认API密钥
)
try:
# 发送测试请求
response = client.chat.completions.create(
model="qwen3-vl:30b", # 指定模型
messages=[{"role": "user", "content": "你好,你是谁?"}]
)
# 打印回复
print("模型回复:", response.choices[0].message.content)
print("API调用成功!")
except Exception as e:
print(f"连接失败,错误信息:{e}")
print("请检查:")
print("1. 地址是否正确(注意端口号11434)")
print("2. 实例是否在运行状态")
print("3. 网络是否能正常访问")
运行这个脚本,如果看到模型正常的自我介绍,说明API接口工作正常。如果报错,最常见的原因是地址不对或者实例没启动。
3. 第二步:安装和初始化Clawdbot
模型服务验证通过后,我们开始安装Clawdbot。这是我们的AI助手管理平台,后续所有功能都通过它来配置和管理。
3.1 安装Clawdbot
Clawdbot是一个开源的AI助手框架,支持多种模型和平台集成。好消息是,星图云环境已经预装了Node.js,并且配置了npm镜像加速,安装会很快。
安装命令: 在实例的终端中(可以通过Web SSH访问),执行以下命令:
npm i -g clawdbot
这个命令会从npm仓库下载Clawdbot并全局安装。因为用了镜像加速,速度应该很快,一两分钟就能完成。
安装完成验证: 安装完成后,可以检查一下版本:
clawdbot --version
如果能看到版本号输出,说明安装成功。
3.2 启动向导完成初始配置
Clawdbot提供了交互式的配置向导,对新手很友好。我们通过onboard命令来启动它。
clawdbot onboard
运行这个命令后,你会进入一个交互式的配置界面。对于第一次使用的朋友,我建议大部分选项先按默认来,或者选择跳过。因为很多高级配置我们后续可以在Web界面中修改,这样更直观。
配置过程要点:
- 运行模式选择:选择
local(本地模式) - 模型提供商:先跳过,我们后面手动配置
- 工作空间:使用默认的
/root/clawd - 网关端口:使用默认的
18789 - 认证方式:先跳过,用最简单的token方式
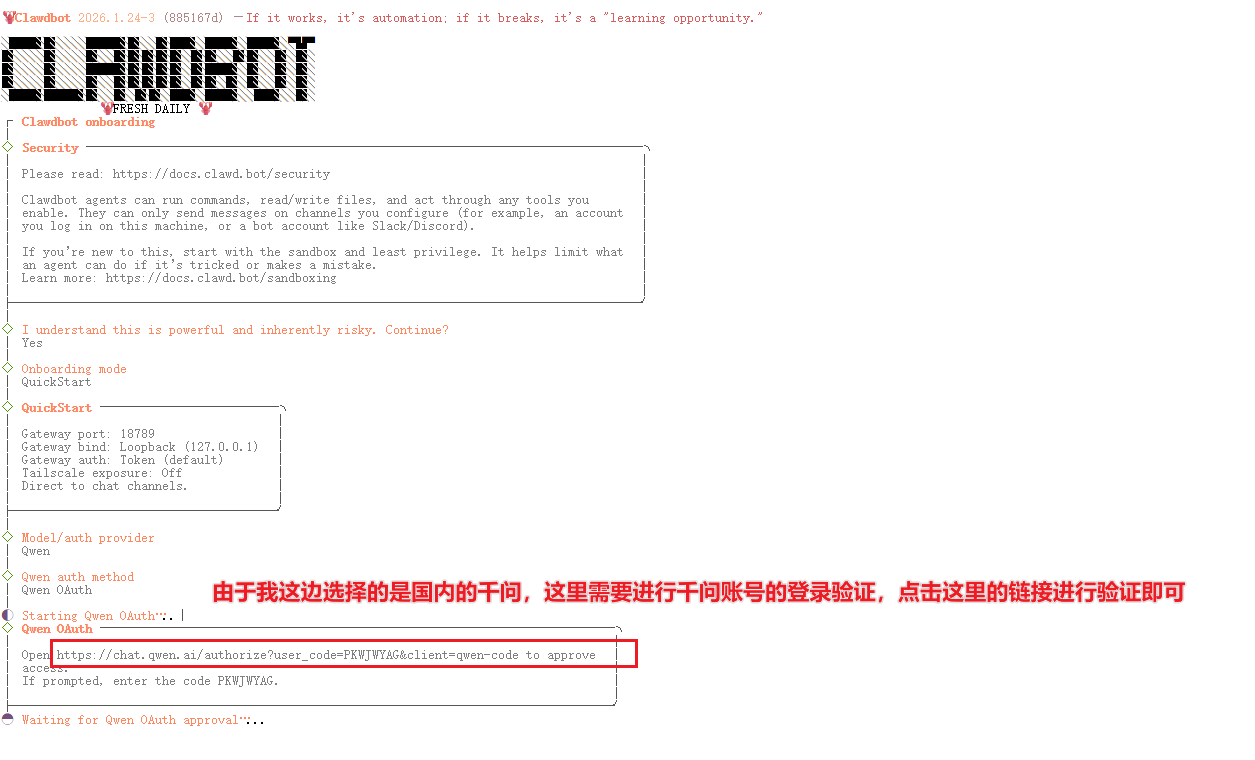
向导完成后,Clawdbot会生成配置文件,并提示你下一步操作。
3.3 启动网关服务
配置完成后,我们需要启动Clawdbot的网关服务。这个服务提供了Web管理界面和API接口。
启动命令:
clawdbot gateway
执行后,你会看到服务启动的日志,最后显示网关正在监听端口。
访问控制页面: Clawdbot默认的管理端口是18789。星图云的访问地址需要替换端口号。
你的原始实例地址可能是这样的:
https://gpu-pod697b0f1855ba5839425df6ea-8888.web.gpu.csdn.net/
把端口号8888换成18789:
https://gpu-pod697b0f1855ba5839425df6ea-18789.web.gpu.csdn.net/
在浏览器中打开这个地址,你应该能看到Clawdbot的控制台登录页面。

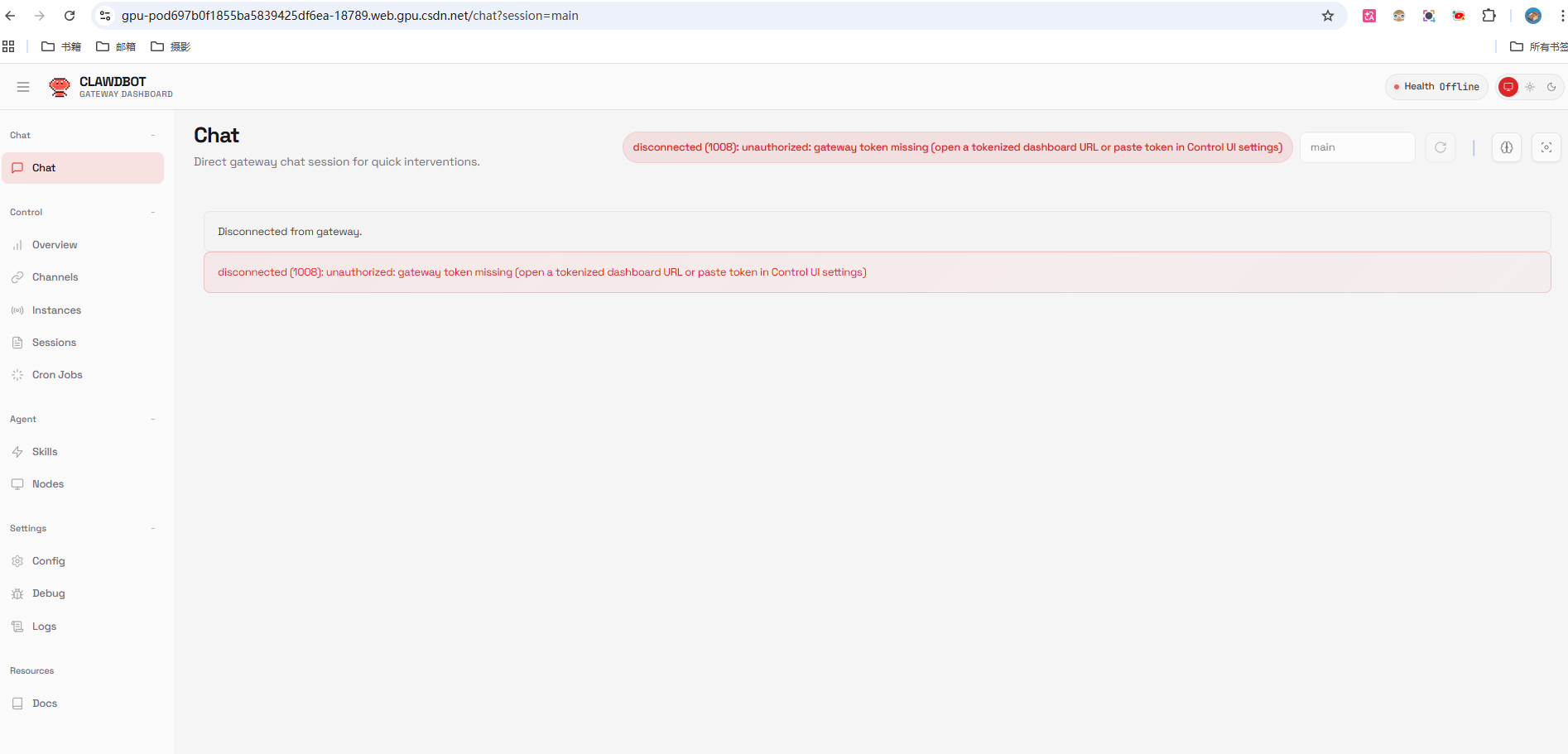
4. 第三步:解决网络和配置问题
第一次访问控制台时,可能会遇到一些问题。别担心,这都是正常现象,我们一步步解决。
4.1 解决Web页面空白问题
如果你打开控制台发现是空白页面,或者无法加载,最常见的原因是网络监听配置问题。
问题原因: Clawdbot默认只监听本地回环地址(127.0.0.1),这意味着只有服务器本机可以访问。但我们是通过公网URL访问的,所以需要修改配置。
查看当前监听状态:
netstat -tlnp | grep 18789
如果显示127.0.0.1:18789,说明只监听了本地。

修改配置文件: 我们需要编辑Clawdbot的配置文件,让它监听所有网络接口。
vim ~/.clawdbot/clawdbot.json
找到gateway部分,修改三个关键配置:
- 修改bind:从
loopback改为lan - 设置token:在auth部分设置一个访问令牌
- 添加信任代理:允许所有代理转发
修改后的配置片段应该是这样的:
"gateway": {
"mode": "local",
"bind": "lan", // 改为lan,监听所有网络接口
"port": 18789,
"auth": {
"mode": "token",
"token": "csdn" // 设置一个简单的token
},
"trustedProxies": ["0.0.0.0/0"], // 信任所有代理
"controlUi": {
"enabled": true,
"allowInsecureAuth": true
}
}
重启服务并验证: 修改配置后,需要重启Clawdbot网关服务。先按Ctrl+C停止当前服务,然后重新启动:
clawdbot gateway
再次检查监听状态:
netstat -tlnp | grep 18789
现在应该显示0.0.0.0:18789,表示正在监听所有网络接口。

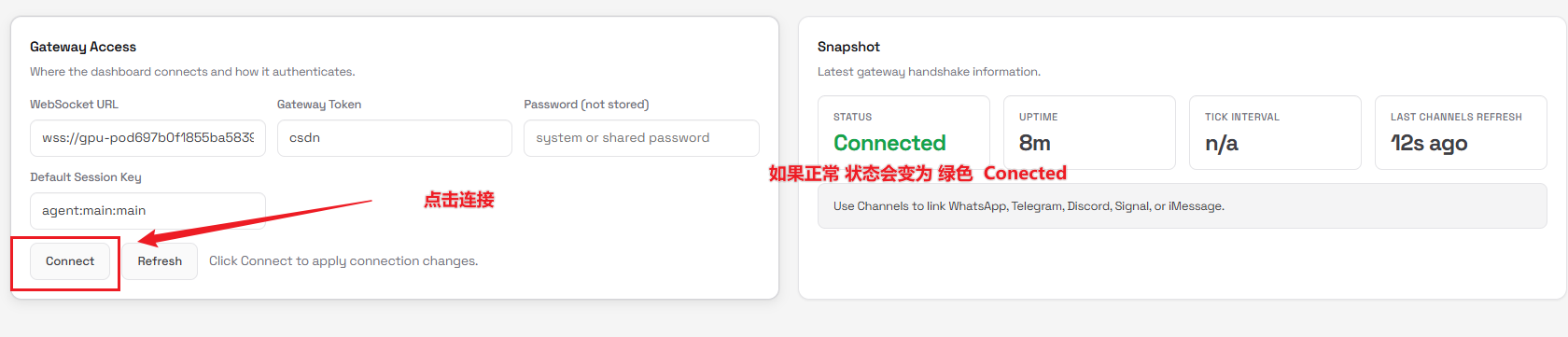
4.2 配置控制面板访问凭证
刷新控制台页面,现在应该能看到登录界面了。如果提示需要Token,就输入我们刚才在配置文件中设置的csdn。
登录流程:
- 打开控制台地址
- 在Token输入框填写
csdn - 点击登录
登录成功后,你会看到Clawdbot的管理面板。这里有多个功能模块:
- Overview:系统概览
- Chat:聊天测试界面
- Agents:智能体管理
- Skills:技能管理
- Models:模型配置
5. 第四步:集成Qwen3-VL:30B模型
现在到了最关键的一步:把Clawdbot和我们部署的Qwen3-VL:30B模型连接起来。这样Clawdbot就能使用我们本地的强大模型了。
5.1 确认Ollama服务状态
在配置之前,先确认Ollama服务正常运行。我们之前已经测试过API接口,现在再快速验证一下:
curl http://127.0.0.1:11434/api/tags
这个命令应该返回已安装的模型列表,其中包含qwen3-vl:30b。
5.2 修改Clawdbot模型配置
我们需要告诉Clawdbot,去哪里找我们的模型。编辑配置文件,添加自定义的模型提供商。
编辑配置文件:
vim ~/.clawdbot/clawdbot.json
在配置文件中找到models.providers部分,添加一个新的提供商my-ollama:
"models": {
"providers": {
"my-ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama",
"api": "openai-completions",
"models": [
{
"id": "qwen3-vl:30b",
"name": "Local Qwen3 30B",
"contextWindow": 32000
}
]
}
}
}
关键参数说明:
baseUrl:Ollama的API地址,本地就是127.0.0.1:11434apiKey:Ollama的默认API密钥就是"ollama"id:模型名称,必须和Ollama中的名称一致contextWindow:上下文窗口大小,30B模型是32000
5.3 设置默认模型
添加了模型提供商后,我们还需要设置Clawdbot默认使用这个模型。
在配置文件中找到agents.defaults部分,修改模型配置:
"agents": {
"defaults": {
"model": {
"primary": "my-ollama/qwen3-vl:30b"
}
}
}
这样配置后,Clawdbot的所有智能体默认都会使用我们本地的Qwen3-VL:30B模型。
5.4 完整配置文件参考
如果你不想手动修改,这里提供一个完整的配置文件参考。你可以复制这个配置,替换你本地的~/.clawdbot/clawdbot.json文件。
{
"meta": {
"lastTouchedVersion": "2026.1.24-3",
"lastTouchedAt": "2026-01-29T09:43:42.012Z"
},
"wizard": {
"lastRunAt": "2026-01-29T09:43:41.997Z",
"lastRunVersion": "2026.1.24-3",
"lastRunCommand": "onboard",
"lastRunMode": "local"
},
"auth": {
"profiles": {
"qwen-portal:default": {
"provider": "qwen-portal",
"mode": "oauth"
}
}
},
"models": {
"providers": {
"my-ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama",
"api": "openai-completions",
"models": [
{
"id": "qwen3-vl:30b",
"name": "Local Qwen3 32B",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 32000,
"maxTokens": 4096
}
]
},
"qwen-portal": {
"baseUrl": "https://portal.qwen.ai/v1",
"apiKey": "qwen-oauth",
"api": "openai-completions",
"models": [
{
"id": "coder-model",
"name": "Qwen Coder",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 128000,
"maxTokens": 8192
},
{
"id": "vision-model",
"name": "Qwen Vision",
"reasoning": false,
"input": [
"text",
"image"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 128000,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "my-ollama/qwen3-vl:30b"
},
"models": {
"my-ollama/qwen3-vl:30b": {
"alias": "qwen"
},
"qwen-portal/coder-model": {
"alias": "qwen"
},
"qwen-portal/vision-model": {}
},
"workspace": "/root/clawd",
"compaction": {
"mode": "safeguard"
},
"maxConcurrent": 4,
"subagents": {
"maxConcurrent": 8
}
}
},
"messages": {
"ackReactionScope": "group-mentions"
},
"commands": {
"native": "auto",
"nativeSkills": "auto"
},
"gateway": {
"port": 18789,
"mode": "local",
"bind": "lan",
"controlUi": {
"enabled": true,
"allowInsecureAuth": true
},
"auth": {
"mode": "token",
"token": "csdn"
},
"trustedProxies": [
"0.0.0.0/0"
],
"tailscale": {
"mode": "off",
"resetOnExit": false
}
},
"skills": {
"install": {
"nodeManager": "npm"
}
},
"plugins": {
"entries": {
"qwen-portal-auth": {
"enabled": true
}
}
},
"hooks": {
"internal": {
"enabled": true,
"entries": {
"session-memory": {
"enabled": true
}
}
}
}
}
5.5 最终测试验证
配置完成后,重启Clawdbot服务让配置生效。然后我们进行最终测试,确认一切正常。
重启服务: 先停止当前的Clawdbot网关(Ctrl+C),然后重新启动:
clawdbot gateway
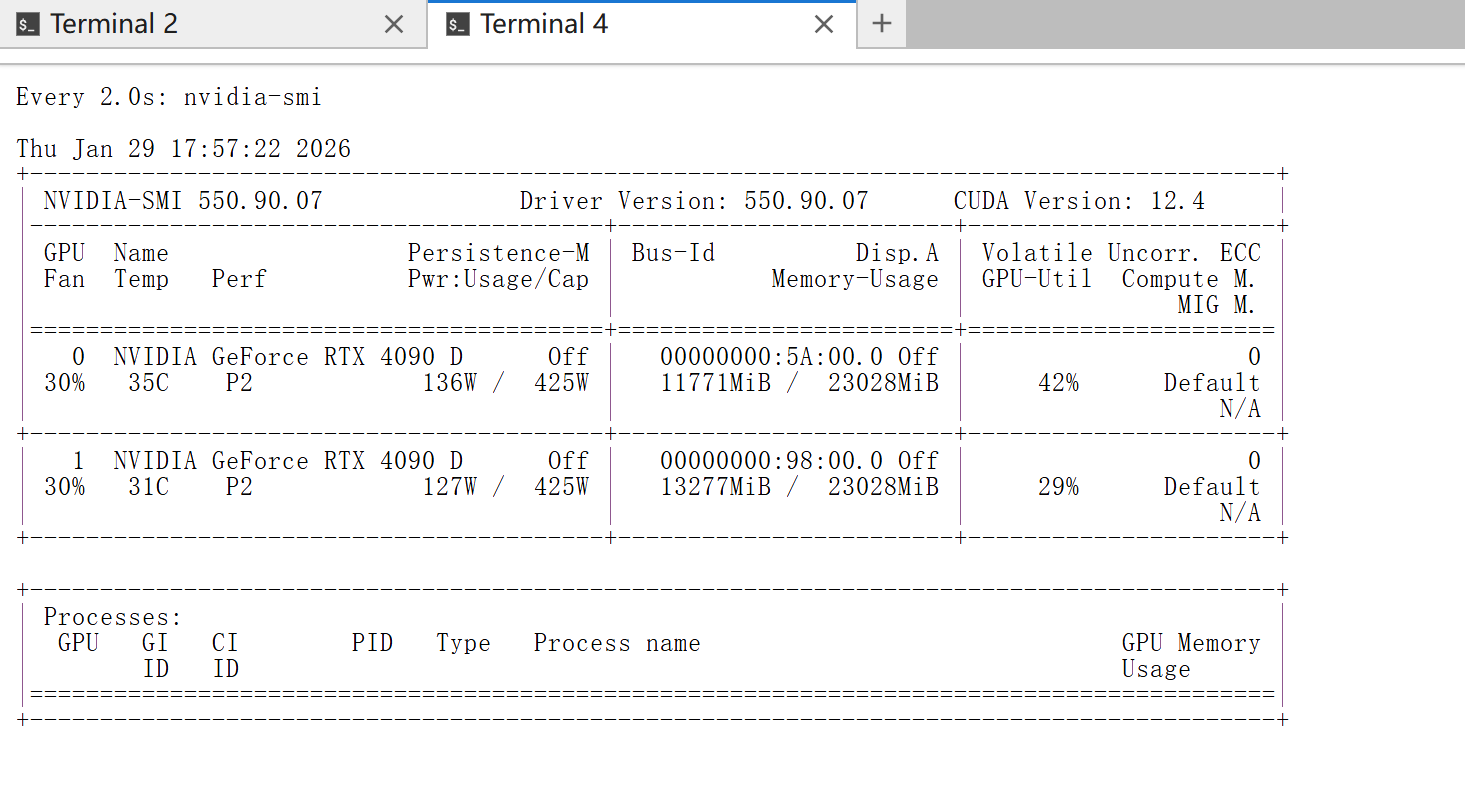
监控GPU状态: 打开一个新的终端窗口,执行以下命令实时监控GPU使用情况:
watch nvidia-smi
这个命令会每2秒刷新一次GPU状态,你可以看到显存使用情况。
在控制台测试:
- 打开Clawdbot控制台(端口18789)
- 进入Chat页面
- 发送一条测试消息,比如“你好,请介绍一下你自己”
观察两个现象:
- 在Chat界面,你应该能看到模型的回复
- 在GPU监控窗口,你应该能看到显存使用量增加
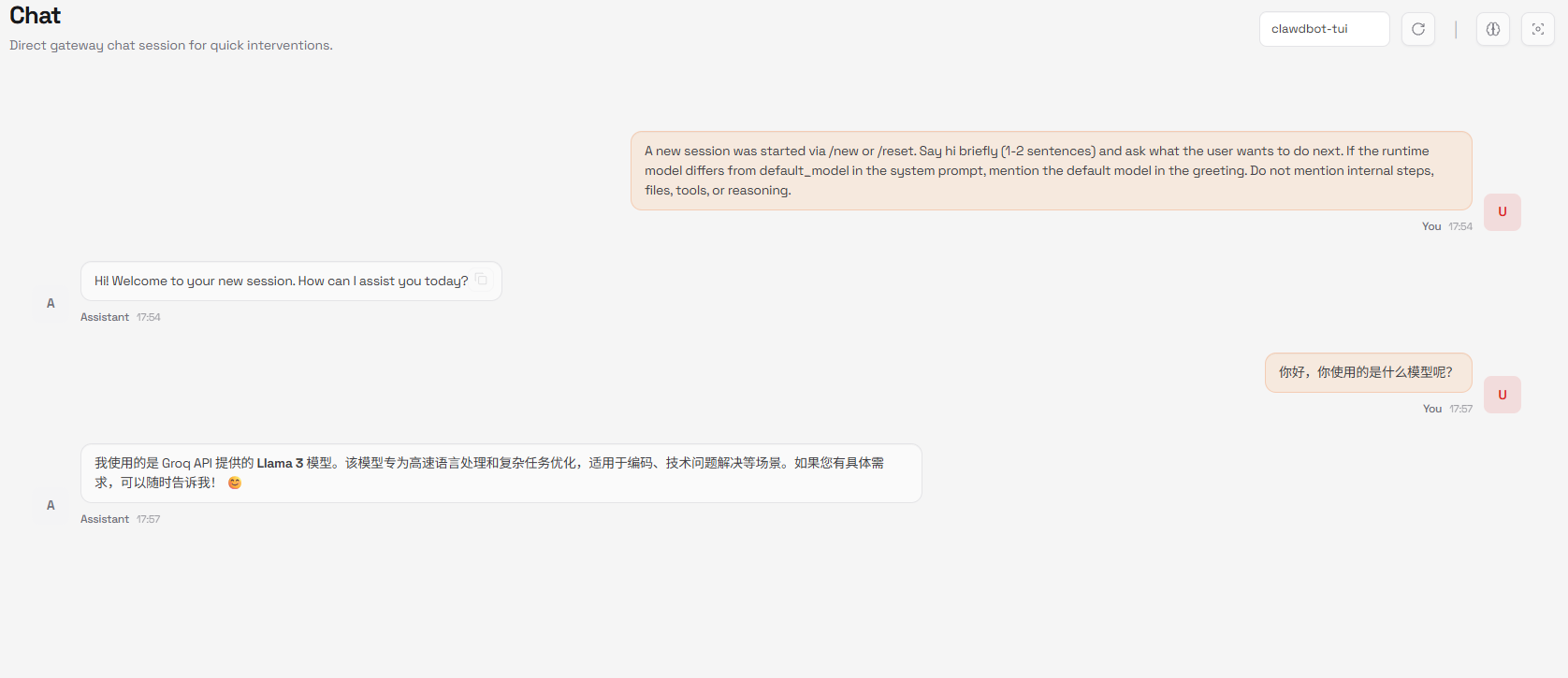
如果看到显存使用增加,并且模型正常回复,恭喜你!Qwen3-VL:30B已经成功集成到Clawdbot中了。
6. 总结与下一步
到这里,我们已经完成了上篇的所有内容。回顾一下,我们做了三件大事:
- 创建了GPU实例:在星图云上选择了预装Qwen3-VL:30B的镜像,创建了48G显存的实例
- 验证了模型服务:通过Web界面和API两种方式,确认Ollama服务和30B模型正常工作
- 部署了Clawdbot:安装、配置并成功集成了本地模型
现在你拥有的是一个:
- 私有化部署的Qwen3-VL:30B大模型
- 通过Clawdbot统一管理的AI助手平台
- 可以通过Web界面进行对话测试
当前系统的能力:
- 支持文本对话
- 支持多轮对话(有上下文记忆)
- 可以通过Web界面管理
- 完全私有化,数据安全
下篇预告: 在接下来的下篇教程中,我们将让这个系统真正“活”起来:
- 接入飞书平台:把AI助手变成飞书机器人,可以在群聊和私聊中使用
- 配置多模态能力:让助手真正能“看懂”图片,实现图文对话
- 环境持久化打包:把配置好的环境做成镜像,方便下次一键部署
- 发布到镜像市场:分享你的成果,让更多人使用
给初学者的建议: 如果你第一次接触这些技术,可能会觉得步骤有点多。但实际操作起来,每个步骤都很简单。关键是理解每个步骤的目的:
- 创建实例:获得硬件资源
- 验证服务:确保基础功能正常
- 安装Clawdbot:获得管理界面
- 配置集成:把各个部分连接起来
现在你的AI助手已经“出生”了,下篇我们将教它如何“与人交流”。期待在下篇教程中与你继续探索!
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)