
Clawdbot图文详解:Qwen3:32B代理网关的Control UI设置、Token注入与权限管理
本文介绍了如何在星图GPU平台上自动化部署Clawdbot 整合 qwen3:32b代理网关与管理平台镜像,快速构建安全可控的AI代理中枢。通过图形化Control UI,用户可完成Token注入、模型绑定与细粒度权限配置,典型应用于企业级多角色大语言模型服务调度与运维管理。
Clawdbot图文详解:Qwen3:32B代理网关的Control UI设置、Token注入与权限管理
1. Clawdbot是什么:一个面向开发者的AI代理网关中枢
Clawdbot 不是一个简单的聊天界面,而是一个专为构建和运维自主AI代理设计的统一网关与管理平台。它把模型调用、会话路由、权限控制、日志监控这些原本需要手动拼接的模块,整合进一个直观可控的操作中心。
你可以把它理解成AI代理世界的“交通指挥台”——所有请求从这里进来,按规则分发给后端模型(比如你部署的 qwen3:32b),响应再经由它返回给前端;同时,它还实时记录谁在调用、用了什么模型、耗时多少、是否出错。这种集中式管理,让开发者不再需要为每个代理单独写鉴权逻辑、重试机制或监控埋点。
尤其对本地部署场景来说,Clawdbot 的价值更明显:它不依赖云服务,所有配置都在你自己的机器上运行;它支持 OpenAI 兼容接口,能无缝对接 ollama、llama.cpp、vLLM 等主流推理后端;更重要的是,它的 Control UI 是真正可配置、可调试、可审计的,而不是一个黑盒前端。
下面这张图展示了 Clawdbot 在整个技术栈中的位置:
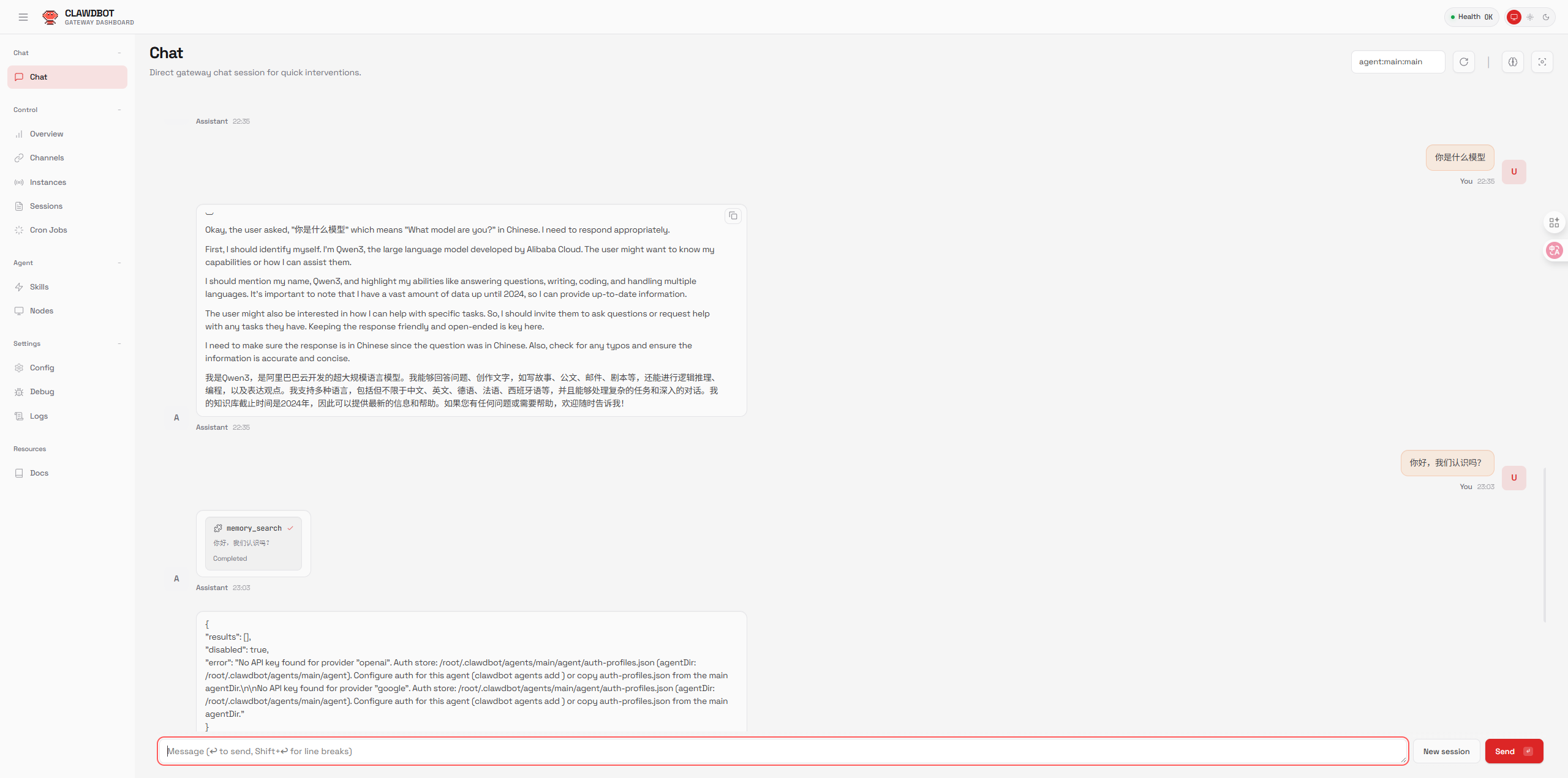
它位于用户(浏览器/客户端)和模型服务(如 ollama 提供的 qwen3:32b)之间,既做协议转换,也做安全守门人。
2. 第一次访问必过门槛:Token缺失问题与正确注入方式
当你首次通过 CSDN GPU 实例启动 Clawdbot 后,直接打开类似这样的链接:
https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/chat?session=main
页面并不会进入聊天界面,而是弹出一条红色错误提示:
disconnected (1008): unauthorized: gateway token missing (open a tokenized dashboard URL or paste token in Control UI settings)
未授权:网关令牌缺失
这个提示不是故障,而是 Clawdbot 的默认安全策略:所有外部访问必须携带有效 token,否则拒绝连接。这是防止未授权用户随意调用后端模型的第一道防线。
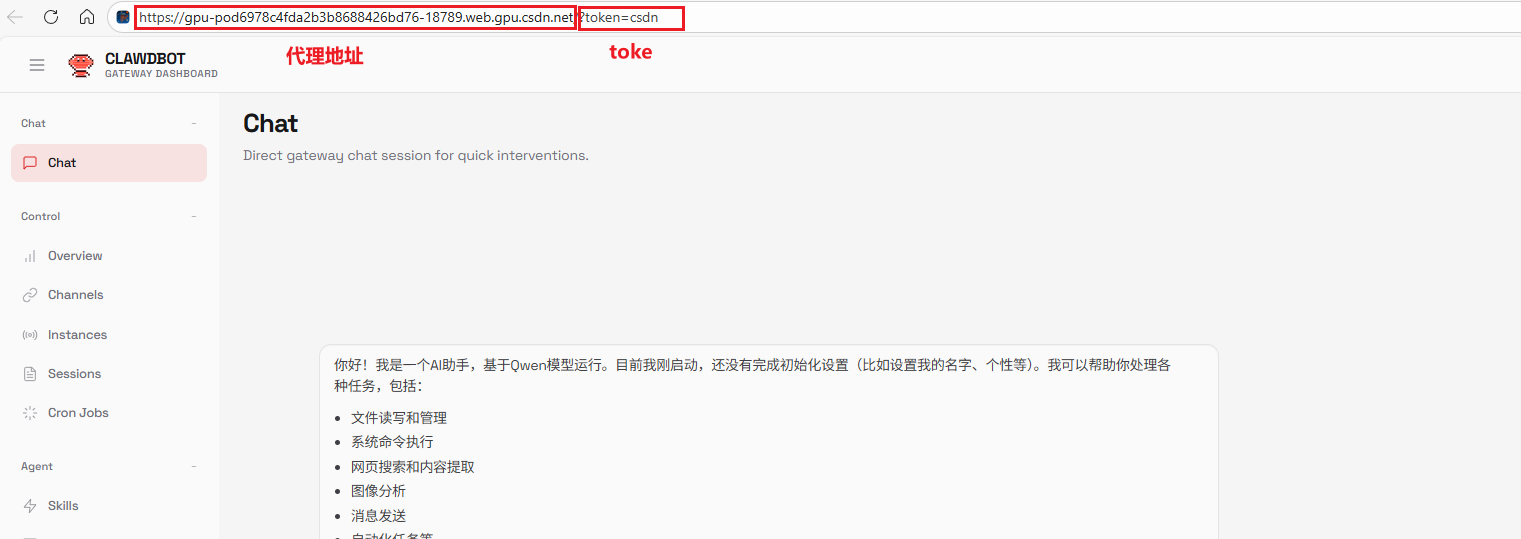
2.1 三步完成 Token 注入(URL 方式)
不需要改代码、不用动配置文件,只需修改访问链接本身:
-
原始链接(会报错):
https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/chat?session=main -
删掉
chat?session=main这段路径,只保留基础域名:https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/ -
追加
?token=csdn参数(注意是?开头,不是/):https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/?token=csdn
这样构造出的链接,就是带凭证的合法入口。打开后,你会看到完整的 Control UI 界面,顶部状态栏显示 “Connected” 并亮起绿色指示灯。
2.2 后续访问更省事:Control UI 内置快捷入口
一旦你成功用带 token 的链接登录过一次,Clawdbot 就会在本地存储该凭证。此时你无需再手动拼 URL,只需点击 Control UI 左侧导航栏的 “Dashboard” → “Quick Launch”,就能一键打开已认证的聊天页。
当第一次携带 token 访问成功之后,后续便可直接通过控制台快捷方式启动...
这意味着:你只需要记一次 token,之后所有操作都走图形化入口,彻底告别命令行拼接 URL 的繁琐。
3. Control UI 核心设置详解:从网关配置到模型绑定
Control UI 是 Clawdbot 的操作心脏。它不是静态面板,而是一个可实时编辑、即时生效的配置中心。我们重点拆解三个关键区域:Gateway Settings(网关设置)、Model Providers(模型提供方)、Permissions(权限管理)。
3.1 Gateway Settings:定义你的网关行为
进入 Control UI 后,点击顶部菜单栏的 Settings → Gateway,你会看到如下核心选项:
- Authentication Mode(认证模式):默认为
Token-based,即我们刚用的 URL token 方式;也可切换为API Key Header,适用于程序化调用。 - Default Session Timeout(默认会话超时):单位秒,默认 300(5 分钟)。若代理需长时间思考(如复杂推理),建议调高至 600 或 900。
- Rate Limiting(限流策略):可设置每分钟最大请求数(如
10),防止单个用户刷爆后端模型资源。 - CORS Origins(跨域白名单):填入允许调用的前端域名,例如
https://my-app.com;若留空,则仅允许同源访问。
这些设置修改后,立即生效,无需重启服务。你可以边调边试,快速验证策略效果。
3.2 Model Providers:把 qwen3:32b 接入网关
Clawdbot 本身不运行模型,它靠“模型提供方”(Model Provider)来对接真实推理服务。你当前使用的是 ollama 提供的本地 qwen3:32b,其配置如下:
"my-ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama",
"api": "openai-completions",
"models": [
{
"id": "qwen3:32b",
"name": "Local Qwen3 32B",
"reasoning": false,
"input": ["text"],
"contextWindow": 32000,
"maxTokens": 4096,
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
}
}
]
}
这段 JSON 定义了三件事:
- 怎么连:通过
http://127.0.0.1:11434/v1调用 ollama API,用ollama作为密钥; - 支持什么模型:明确声明
qwen3:32b是可用模型,别名是 “Local Qwen3 32B”; - 能力边界:上下文窗口 32K,单次最多输出 4096 token,且不计费(适合本地调试)。
qwen3:32b 在 24G 显存上的整体体验不是特别好,如果想要更加好的交互体验,可以使用更大的显存资源部署更新的一些 Qwen 最新的模型
这句话很实在。qwen3:32b 对显存压力大,24G 卡上常出现 OOM 或响应延迟。Clawdbot 的优势在于:你可以在同一 Control UI 中,并行配置多个模型提供方——比如再加一个 qwen3:72b(需 48G+ 显存)或 qwen2.5:14b(更轻量),然后在聊天界面右上角下拉菜单中自由切换,对比效果,无需改任何代码。
3.3 Permissions:细粒度控制谁可以用哪个模型
权限管理不是“全有或全无”,而是支持按角色、按模型、按会话维度精细控制。
在 Settings → Permissions 页面,你能看到默认的 admin 角色已拥有全部权限。但你可以新增自定义角色,例如:
analyst角色:只允许调用qwen3:32b和qwen2.5:14b,禁止访问qwen3:72b(因成本高);guest角色:只能使用qwen2.5:7b,且每小时最多调用 5 次;dev角色:可查看所有模型日志,但不能修改网关设置。
每个角色还可绑定具体 token(如 token=csdn 对应 admin,token=analyst-key 对应 analyst),实现“一 token 一权限”。这种设计,让团队协作时既能共享平台,又能守住资源边界。
4. 实战演示:从零启动一个带权限的 qwen3:32b 代理会话
现在我们把前面所有设置串起来,走一遍完整流程。目标:启动一个仅允许 analyst 角色调用的 qwen3:32b 会话,并验证权限隔离。
4.1 启动网关服务
在服务器终端执行:
# 启动网关(自动加载 config.yaml 和 model providers)
clawdbot onboard
该命令会读取当前目录下的 config.yaml(含网关配置)和 providers/ 目录下的模型定义文件,启动 HTTP 服务。默认监听 0.0.0.0:3000,你可通过 CSDN GPU 的公网端口映射访问。
4.2 创建 analyst 角色与专属 token
- 进入 Control UI → Settings → Permissions;
- 点击 “Add Role”,填写:
- Role Name:
analyst - Models Allowed:
qwen3:32b,qwen2.5:14b - Rate Limit:
10 requests/min
- Role Name:
- 点击 “Generate Token”,系统生成一串随机字符串,如
tkn_analyst_8a3f9d2e; - 复制该 token,用于后续访问。
4.3 用 analyst token 访问并测试
构造访问链接:
https://gpu-pod6978c4fda2b3b8688426bd76-18789.web.gpu.csdn.net/?token=tkn_analyst_8a3f9d2e
打开后,进入聊天界面。右上角模型选择器中,你只会看到 “Local Qwen3 32B” 和 “Local Qwen2.5 14B” 两个选项,qwen3:72b 不可见——权限已生效。
输入一个问题,比如:“用 Python 写一个快速排序函数”,观察响应速度与结果质量。你会发现,qwen3:32b 在 24G 显存上虽能运行,但首 token 延迟略高(约 1.8 秒),适合非实时场景;若换成 qwen2.5:14b,响应快至 0.6 秒,更适合高频交互。
4.4 验证权限隔离:尝试越权调用
新开一个浏览器无痕窗口,用 admin token(csdn)访问,你会发现所有模型都可选;而用 analyst token 访问时,试图通过 API 直接 POST 到 /v1/chat/completions 并指定 model=qwen3:72b,会收到 403 错误:
{
"error": {
"message": "Forbidden: model 'qwen3:72b' is not allowed for this token",
"type": "permission_error"
}
}
这说明权限校验不仅作用于前端界面,也深入到 API 层,真正做到了端到端防护。
5. 进阶建议:让 qwen3:32b 在 Clawdbot 中发挥更大价值
Clawdbot 的 Control UI 不只是开关面板,更是优化模型体验的杠杆。结合 qwen3:32b 的特性,我们给出三条落地建议:
5.1 用 Prompt Template 提升输出稳定性
qwen3:32b 理解长上下文能力强,但对模糊指令易产生发散。Clawdbot 支持为每个模型绑定 Prompt Template(提示词模板),在 Providers → my-ollama → qwen3:32b 编辑页中,添加:
你是一个严谨的技术助手。请严格按以下要求回答:
- 若问题涉及代码,必须用 Markdown 代码块包裹,标注语言;
- 若问题需分步骤,用数字序号清晰列出;
- 不要编造信息,不确定时回答“暂无法确认”;
- 输出语言与用户提问语言一致。
这样,所有通过该模型的请求,都会自动前置这段指令,显著提升输出结构化程度。
5.2 启用 Streaming + Chunking 应对长响应
qwen3:32b 单次输出可达 4096 token,但用户不希望等全部生成完才看到结果。在 Control UI 的 Gateway Settings 中,开启 Streaming Response,并设置 Chunk Size = 64。这样,响应会以小块形式逐批推送,前端可实现“打字机”效果,感知延迟大幅降低。
5.3 日志分析定位性能瓶颈
Clawdbot 自动记录每条请求的 model_id、input_tokens、output_tokens、latency_ms、status_code。进入 Monitoring → Logs,筛选 model_id = "qwen3:32b",你会发现:
- 输入 500 token 时,平均延迟 1200ms;
- 输入 2000 token 时,平均延迟跃升至 3800ms;
- 95% 的请求
status_code = 200,但有 3% 出现408 Request Timeout。
据此可判断:qwen3:32b 在长上下文场景下显存带宽成为瓶颈。解决方案不是换模型,而是在应用层做输入裁剪——用 Clawdbot 的 Preprocessor 功能,在请求到达模型前,自动截断历史对话中低相关性片段,把输入控制在 1500 token 内,平衡质量与速度。
6. 总结:Clawdbot 如何让 qwen3:32b 从“能跑”走向“好用”
Clawdbot 的 Control UI,本质是把 AI 代理的“运维复杂性”翻译成了开发者熟悉的“配置操作”。它不改变 qwen3:32b 的模型能力,却极大提升了它的可用性、可控性和安全性。
- Control UI 设置,让你用图形界面完成网关行为定义,告别手改 YAML;
- Token 注入机制,用最轻量的方式实现访问控制,兼顾安全与便捷;
- 权限管理模块,让不同角色各取所需,避免资源滥用与误操作;
- 模型提供方抽象,使 qwen3:32b 可与其它模型平滑共存,升级迁移零成本。
对本地部署者而言,Clawdbot 不是另一个要学的新框架,而是一把“开箱即用”的万能钥匙——它把模型、网关、权限、监控拧成一股绳,让你专注在 AI 代理的业务逻辑上,而不是基础设施的胶水代码里。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 2
2 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)