
基于BOW的图像检索(含matlab源码)
因为发现网上没有人写这个,于是就写了一篇。以最基本的颜色直方图为例,采用BOW算法完成图像检索。源码发布在: https://github.com/zxwsbg/Bow-Retrival如果本文对你有帮助,请给我的项目一个star。准备工作测试数据集开发环境:matlab...
因为发现网上没有人写这个,于是就写了一篇。以最基本的颜色直方图为例,采用BOW算法完成图像检索。
源码发布在: https://github.com/zxwsbg/Bow-Retrival
如果本文对你有帮助,请给我github的项目一个star!!!
转载请注明原作者!!!
准备工作
- 如果你在github上下载了源码的话,可以直接使用,无需再去数据集
- 测试数据集:http://wang.ist.psu.edu/docs/related/
- 开发环境:matlab
- 将测试数据集
test1和代码放在同一个文件夹下,如下图
step1 提取特征
对于一张图片,以384256为例。那么利用imread读取图片后,就会获得一个384256*3的矩阵,最后的3表示RGB分量。
出于简单考虑,本文就以YUV分量为特征,将提取出来的RGB分量一步转化为YUv,然后再利用cell存储每张图片的特征。
for i = 1:ImgNum
ImgName = [ImgFolder int2str(i-1)];
ImgName = [ImgName '.jpg'];
disp(i);
RGBImg = imread(ImgName);
YUVImg = rgb2ycbcr(RGBImg);
ImgInfo{i} = YUVImg;
end
step2 挑选特征
我们以一张384*256的照片为例,因为要聚类,不可能把一整张图片直接放进去,需要进行预处理。由于我们的特征是颜色直方图,所以处理特征也很简单。
- 将一张图片分成若干个8*8的小块;
- 将每一个8*8的小块平铺成一个1*64的向量
这样处理之后,一张384*256的原矩阵就转化成了一个1536*64的新矩阵,第一行对应的就是第一个8*8的块平摊下来。这一步用循环会比较蠢,但是我懒得去找对应的矩阵变换的函数了 。
function y=Func_divide(x,BlockSize)
y = [];
n = size(x,1)/8;
m = size(x,2)/8;
for i = 1:n
for j = 1:m
posx = (i-1)*BlockSize+1; %某个8*8的块起始位置横坐标
posy = (j-1)*BlockSize+1; %某个8*8的块起始位置纵坐标
temp = x(posx:posx+BlockSize-1,posy:posy+BlockSize-1);
temp = reshape(temp',1,BlockSize*BlockSize); %求转置来横着拼
% 平铺
y = [y;temp];
end
end
end
在处理完所有图片后,每张图片都有一个153664的矩阵,把它们纵向拼接后,1000张就是153600064的矩阵,这在聚类的时候一下子塞进去太大了。根据大数定律,我们只需要从中挑选一部分去聚类就行了。假如我们挑选20%,最终的聚类矩阵就只有307200*64这么大,这样速度会快很多。
step3 聚类
这是最为核心的一步,我来细细的讲解一下这一步的中心思想。
SelecHist就是刚刚挑选出来的那个矩阵,clusterNum是类心数,可以自己设定,这里以100为例。
聚类的意思就是生成100个类心,然后之前307200*64的矩阵,每一行都归到一个类心里面去。比如第一行的64维向量分到了第4类,第二行的64维向量分到了第78类(这些都是我口糊的)。
[Idx,C] = kmeans(SelectHist,clusterNum);
- Idx: 307200*1的矩阵,表示每一行最后去了哪个类(这里没啥用);
- C:类心坐标,是一个100*64的矩阵,第i行表示第i个类心的坐标。因为特征是64维的,所以类心坐标自然也是64维的,不要想当然的认为坐标都是二维的。
step4 分类
在得到上一步的类心矩阵C后,我们就要开始分类了。
大家是否还记得第二步提出了每一张图片的1536*64的特征,没错,那个要保存下来。
我们对于1000张图片的每一个1536*64的矩阵,再到每一行的64维向量,都要把它分到之前那100个类中的一个去。这里利用距离计算函数pdist2计算它离哪个类心最近,就把它分到那一类里面去。
现在我们得到了一个矩阵,就是每一行属于第几个类,我们所需要做的,就是对每一张图片形成频数直方图。
这一步可能很难理解,但我简要的说一下,该直方图的横坐标是100,表示这100个类,纵坐标是该图片有多少块属于这一个类。
举一个极端的例子,在之前分类的时候,有1535个分到了第1类,剩下一个去了第2类。那么这张图片的频数直方图中,横坐标1的直方图对应高度就是1535,横坐标2的直方图对应高度就是1。
为了提高准确性,代码顺手将提取到的直方图归一化了。
for i = 1:ImgNum;
similarDistances = pdist2(cell2mat(LocalHist_Y(i)),C);
[minElements,idx] = min(similarDistances,[],2);
bins = 0.5:1:clusterNum+0.5;
hist = histogram(idx,bins);
Features = hist.Values;
Final_Hist(i,:) = Features;
end
step5 计算直方图距离
到这里已经差不多结束了,我们对每张图片都有了一个频数直方图,众所周知,直方图可以看成二维的矩阵。
我们所要做的就是直接比较这1000张图片对应直方图的距离,然后排个序。
%% 计算各图片与其它图片间的距离
Hist_Dist=[];
for i=1:ImgNum
for j=1:ImgNum
a = Final_Hist(i,:);
b = Final_Hist(j,:);
similarDistance(j) = pdist2(a,b,'cityblock');
end
Hist_Dist = [Hist_Dist;similarDistance];
end
step6 检索
我们已经得到了1000张图片的图片与图片之间的距离,于是我们想测试一下。
以第436张图片为例,检索出来的效果是这样的,看上去还不错。
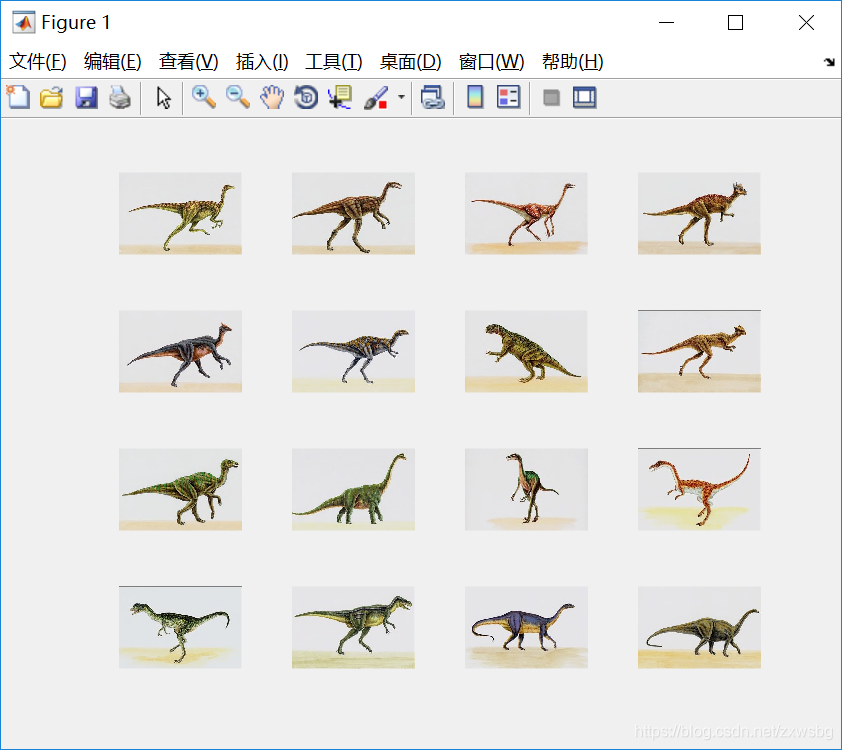
%% 测试
Img = 436;
temp = Hist_Dist(Img,:);
[Y,I] = sort(temp);
k = 16; %前15相似
for i = 1:k
ImgFolder = './test1/';
ImgName = [ImgFolder int2str(I(i)-1)];
ImgName = [ImgName '.jpg'];
subplot(4,4,i);
imshow(ImgName);
end
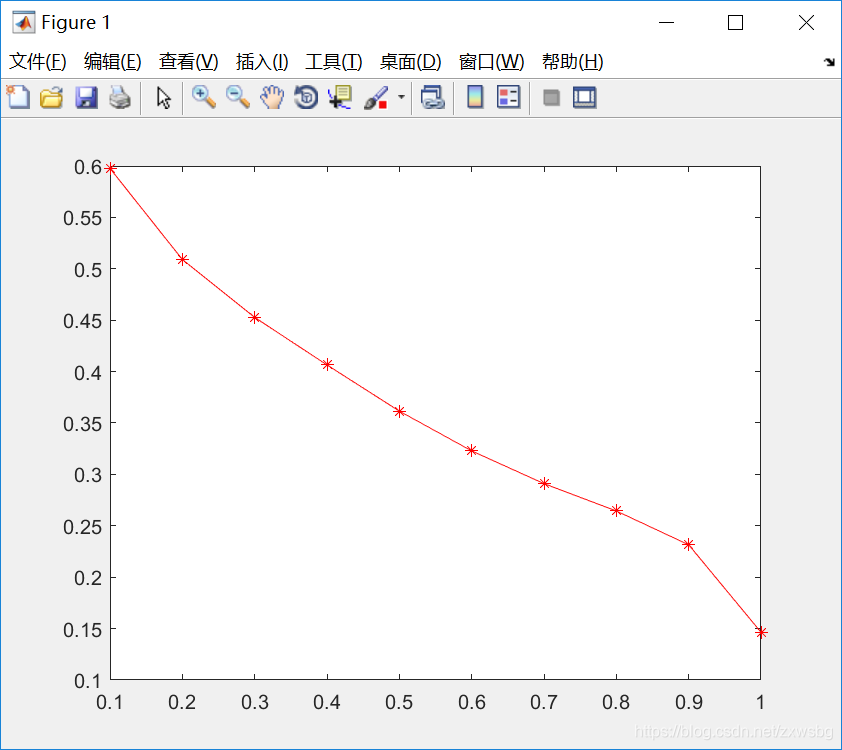
本着科学的角度,我们计算该检索方法的Presicion-Recall值,如果不知道的话,可以去百度一下。它的曲线如下图所示,看上去并不咋样,说明这并不是一个好的特征。计算Presicion-Recall的函数是别人提供的,不用具体分析,对每个数据集的计算方法都不一样。
友情提示
- 计算某些特征的时间特别长,这里建议先存下来,后续要用的时候直接读取即可;
- kmeans的类心数量、聚类、类心选取都可以自己设定,建议参考matlab相关部分文档;
- 特征不一定要选择颜色直方图,类似的特征有很多,这只是最简单的一个;
- 图片每一百张是一类,相信你们也能看出来。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)