
MYSQL学习笔记06:列属性[NULL,default,comment],主键,自增长,唯一键,数据库设计规范[范式(1NF,2NF,3NF),逆规范化],表关系[1V1,1VN,NVN]
列属性列属性又称为字段属性.在mysql中一共有6个属性:null,默认值,列描述,主键,唯一键和自增长.NULL属性NULL属性代表字段为空.如果对应的值为yes表示该字段允许为null,注意:1. 设计表的时候尽量不要让数据为空.2. mysql记录长度为65535字节,如果一个表中有字段允许为null,那么系统就会设计保留1个字节来存储null,最终有效存...
列属性
列属性又称为字段属性.
在mysql中一共有6个属性:null,默认值,列描述,主键,唯一键和自增长.
NULL属性
NULL属性代表字段为空.

如果对应的值为yes表示该字段允许为null,
注意:
1. 设计表的时候尽量不要让数据为空.
2. mysql记录长度为65535字节,如果一个表中有字段允许为null,那么系统就会设计保留1个字节来存储null,最终有效存储长度为65534个字节.
默认值
default:默认值,当字段被设计的时候,如果允许默认条件下,用户不进行数据的插入,那么就可以使用事先准备好的数据来填充.填充的通常是NULL.

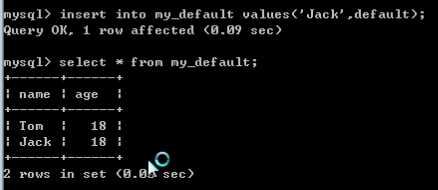
测试:不给当前字段提供数据,看默认值是否生效.

如上图,同一行只指定name值,关联的age被系统自动赋予默认值18.
default关键字的另一层使用:显示的告知字段使用默认值:在进行数据插入的时候,对字段值直接使用default.
列描述:
comment,是专门用于给开发人员进行维护的一个注释说明.
基本语法:comment '字段描述';

查看comment须用查看创建表语句:
 \
\
主键
顾名思义:主要的键.primary key,在一张表中有且只有1个主键,里面的值具有唯一性,.
创建主键
1.随表创建
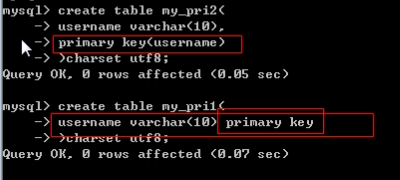
系统提供了2种增加主键的方式
方案一,直接在需要当做主键的字段之后,增加primary key属性来确定主键
方案二,在所有字段之后增加primary key选项: primary key(字段信息)
2.创建表后增加
基本语法:alter table 表名 add primary key(字段);

查看主键
方案1:查看表结构

方案2:查看表的创建语句

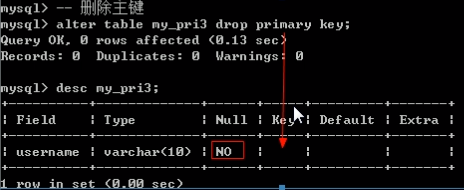
删除主键
基本语法:alter table 表名 drop primary key;
复合主键:
案例:有一张学生选修课表:一个学生可以选修多个选修课,一个选修课也可以由多个学生来选;但一个学生在一个选修课中只有一个成绩.

主键约束
主键一旦增加,那么对对应的字段有数据要求:
1. 当前字段对应的数据不能为空;
2. 当前字段对应的数据不能有任何重复

如上插入3条合理数据,每个学生和每门课程结合,由于复合主键的设置,每个学生每门课程只可能有1个成绩,系统不允许再出现同一学生同一课程的成绩
如下:我们故意插入一条重复的新数据2号学生和1号课程的成绩98,由于表中已经存在2号学生和1号课程的成绩90,系统提示重复点"2号学生-1号课程",不允许再插入,即每个学生每门课程只允许有一个成绩:

主键分类
主键分类采用的是主键对应的字段的业务意义分类
业务主键:主键所在的字段,具有业务意义(学生ID,课程ID)
逻辑主键:自然增长的整型(应用广泛)
自动增长
自动增长:auto_increment属性会让该字段自动增长.
通常自增长用于逻辑主键.
原理
1. 在系统中有维护一组数据,用来保存当前使用了自动增长属性的字段,记住当前对应的数据值,再给定一个指定的步长
2.当用户进行数据插入的时候,如果没有给定值,系统在原始值上再增加步长变成新的数据
3. 自动增长的触发:给定属性的字段没有提供值
4. 自动增长只适用于数值.
使用自动增长
基本语法:在指定字段之后增加一个属性aauto_increment


插入数据:触发自动增长--不能给定具体的值(auto_increment属性字段)
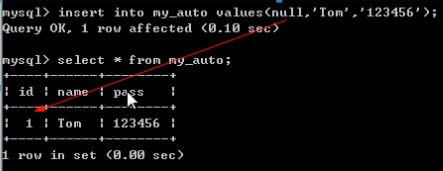
以上代码解释:插入数据时,用户给予自增长字段null值,即用户不给自增长字段赋值,则插入数据时自增长字段自动触发自增长.虽然插入时给与null值,似乎与自增长主键字段不能为null冲突,实际上系统最终给自增长字段自增长赋值了,最终其值为1而并不是null.
请一定注意!即插入数据时用户语句中给予自增长字段null值并不是真正赋值null给它,而是为了触发系统自增长,让系统自动赋予自增长字段真正的自增长后的值.
修改自动增长
1. 查看自增长:自增长一旦触发使用之后,会自动在表选项中增加一个选项(一张表最多只能拥有1个自增长)

2. 手工修改自增长值:如上图,下一个auto_increment值为2,属于表选项,那么我们可以通过修改表结构的表选项来实现:
alter table 表名 auto_increment=值;

删除自动增长
修改自增长字段,不指定auto_increment属性,即删除自增长属性.
alter table 表名 modify 自增长字段 其他属性;
//注意属性中不指定auto_increment属性即完成删除自增长,本身是主键的也不用再指定主键.因主键已存在.

初始设置
在系统中有一组变量用来维护自增长的初始值和步长
show varvariables like 'auto_increment%';

细节问题:
1. 一张表只有1个自增长:自增长会上升到表选项中(肯定不允许出现多个自增长以免出现多个自增长表选项)
2. 如果数据插入中没有触发自增长(给定了数据),那么自增长不会表现.


如上图,当前的下一个自动自增长值应该为2,我们如果指定id为3:

我们手工指定id为3,这样就不会触发系统自动自增长,同时系统自动将下一个自增长值设置为4.
3. 自增长值在修改的时候,可以比已有的值大,但不能小于等于已有的值.

如上代码,当前下一自增长值为21,我们修改自增长值为10,则修改无效.
唯一键
unique key,用来保证对应的字段中的数据唯一的.
主键也可以用来保证字段数据唯一性,但是一张表只有一个主键.
1. 唯一键在一张表中可以有多个.
2. 唯一键允许字段数据为null,null可以有多个(null不参与比较)
创建唯一键
1. 直接在字段之后增加唯一键标识符:unique [key]
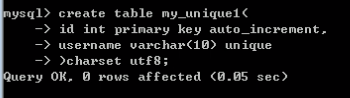
2. 在所有的字段之后使用 unique key(字段1,字段2,字段3...); //因为一张表可以有多个unique key
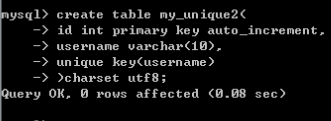
3.在创建完表后,也可以增加唯一键:alter table 表名 add unique key(字段1,字段2,字段3..);
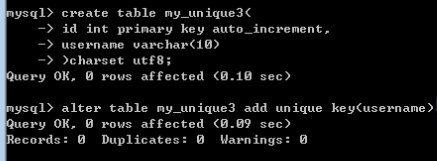
查看唯一键
通过查看表结构来查看唯一键
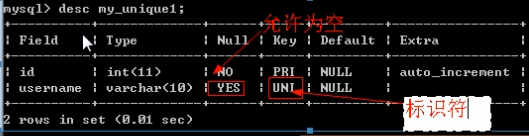
唯一键效果:在不为空的情况下,不允许重复.

如上代码,null可以重复,非null值禁止重复.
在查看表创建语句时,会看到与主键不同的一点,多出一个"名字"
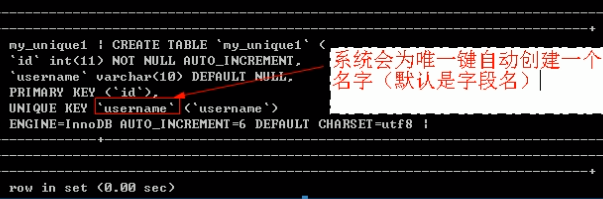
删除唯一键
一个表中允许存在多个唯一键:假设命令为主键一样:alter table 表名 drop unique key;那么该删哪个主键?所以这是错误的
index关键字:索引,唯一键是索引一种(提升查询效率)
删除的基本语法: alter table 表名 drop index 唯一键名字;

修改唯一键:先删除,后增加
复合唯一键
唯一键可以和主键一样,可以使用多个字段来共同保证唯一性
一般主键都是单一字段(逻辑主键),而其他需要唯一性的内容都是由唯一键来处理.
数据库设计规范
(https://www.bilibili.com/video/av30169480/?p=59)


范式
(https://www.bilibili.com/video/av30169480/?p=60)

第一范式
定义:第一范式(1NF), 在设计表存储数据的时候,如果表中设计的字段存储的数据,在取出来使用之前还需要额外的处理(拆分),就不符合1NF,第一范式就是处理数据颗粒度大的问题


总结:
1. 要满足1NF就是要保证数据在实际使用的时候不用对字段数据进行二次拆分
2. 1NF的核心就是数据要有原子性(不可拆分)

(https://www.bilibili.com/video/av30169480/?p=61)
第二范式
定义:第二范式2NF,在数据表的设计过程中,如果有复合主键(多字段主键),且表中有字段并不是由整个主键来确定,而是依赖主键中的某个字段(主键的部分):存在字段依赖主键的部分的问题,称之为部分依赖.第二范式就是要解决表设计不允许出现部分依赖


总结:
1. 第二范式就是解决字段部分依赖主键的问题,也就是主键为复合主键
2.在实际开发中几乎不用复合主键,因此可以完美避免违背第二范式.

(https://www.bilibili.com/video/av30169480/?p=62)
第三范式
定义:第三范式3NF,理论上讲,应该一张表中的所有字段都应该直接依赖主键(逻辑主键:代表的是业务主键).如果表设计中存在一个字段,并不直接依赖主键,而是通过某个非关键字段依赖,最终实现依赖主键:把这种不直接依赖主键,而是依赖非主键字段的依赖关系称之为传递依赖.第三范式就是要解决传递依赖的关系.
1.第三范式的解决方案:如果某个表中有字段依赖非主键字段,而被依赖字段依赖主键,我们就应该将这种非主键依赖关系进行分离,单独形成一张表.


总结
1.第三范式是不允许传递依赖:即有字段依赖非主键字段
2.消除传递依赖的方案就是将相关数据对应创建一张表.

(https://www.bilibili.com/video/av30169480/?p=63)
逆规范化
定义:逆规范化就是在考虑查询效率和数据冗余的时候,为了提升查询效率而选择牺牲磁盘空间,适当的增加数据冗余.

总结
1. 逆规范化是一种不符合设计范式的设计方式
2. 逆规范化的存在价值是用来衡量查询效率与数据冗余之间的代价问题
表关系
(https://www.bilibili.com/video/av30169480/?p=64)
表关系:表与表之间(实体)有什么样的关系,每种关系应该如何设计表结构
一对一

一张表中的一条记录与另一张表中最多有一条明确的关系:通常,此设计方案保证两张表中使用同样的主键即可


总结
1. 一对一关系的设计原则就是在附表(从表)中主键与主表中主键保持一致
2. 实现方式就是在进行数据写入的时候,同时写入(或者在主表写入后拿到主键ID,从表主动写入对应ID)

(https://www.bilibili.com/video/av30169480/?p=65)
一对多/多对一
定义:一对多/多对一,就是意味着有一张表中,要保留与另外一张表中数据的关系.关系细节就是一张表中的一条记录对应另外一张表中的多条记录.
1.设计老师表和学生表

2. 以上两张表没有任何关系.所以就意味着不能通过关系来实现彼此之间的关联查询.
老师与学科是多对一的关系,多对一关系的设计核心就是在多关系表(老师)中增加1个字段指向1关系表(学科)的主键.

3. 建立了关系后,就可以通过讲师表中的学科ID来确定关系数据
- 可以在讲师表中判定出那些讲师属于哪个学科
- 可以统计出学科各自有多少个讲师
总结
多对一/一对多是关系设计时很常见的一种关系,设计的原则就是在多关系表中增加一个字段指向一关系表的主键(限定关系为外键)

(https://www.bilibili.com/video/av30169480/?p=66)
多对多
定义:多对多关系,指一张表中的一条记录在另一张表中匹配到多条记录;反之也一样.
多对多的关系如果按照多对一的关系维护:就会出现一个字段中有多个其他表的主键,在访问的时候就会带来不便.
既然通过两张表自己增加字段解决不了问题,那么就通过[第三张表]来解决.
1.定义学生表和老师表

2. 以上两张表都是独立的表,没有任何关系.如果需要确立明确的关系,希望通过表能够确定老师教过哪些学生,学生听过哪些老师的课就比较麻烦了.

3. 设计思路:增加中间表,来维护彼此之间的关系.同时利用中间表形成与老师表和学生表的多个多对一关系:中间表要实现的就是完成学生与老师的对应关系.

总结:
1. 多对多关系在二维数据中没有办法直接对应实现(可以实现,但不满足1NF)
2. 多对多关系的实现方式,就是将两张多表的对应关系通过第三张表维护,从而形成数据库表与中间表之间形成多个一对多关系.
实例:师生关系
1. 1个老师教过多个班级的学生;
2. 1个学生听过多个老师讲课.
首先得有两张表:老师表和学生表.
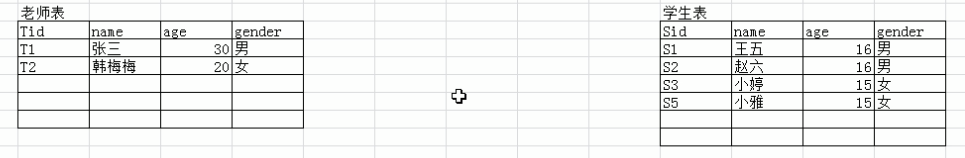
从中间设计一张表:维护两张表对应的联系,每一种联系都包含
多对多解决方案:增加一个中间表,让中间表与对应的其他表形成两个多对一的关系:多对一的解决方案是在"多"表中增加"一"表对应的主键字段.

无需安装部署,在线快速体验 Byzer
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)